Ausdrücke erstellen
Was finden Sie hier?
Informationen zum Erstellen von Ausdrücken
Ausdrücke werden in XM Discover verwendet, um Filter Ihre Daten und Transformation Datenfelder. Sie können beispielsweise Ausdrücke verwenden, um die Formatierung von Datumsfeldern zu ändern, Daten für leere Datensätze auszuwerten und mathematische Berechnungen durchzuführen.
Ausdrücke können 4 Komponenten enthalten:
- Konstanten: Sie können konstante Zahlen, Textzeichenfolgen und Datumsangaben verwenden, um Mathematik- und Vergleich auszuführen.
- Felder: Sie können numerische, Text- und Datumsfelder verwenden, die über einen bestimmten Datenkonnektor verfügbar sind, um Mathematik- und Vergleich für diese Felder auszuführen.
- Funktionen: Sie können Funktionen verwenden, um Transformationen für Ihre Felder und Konstanten durchzuführen.
- Operatoren: Sie können Operatoren verwenden, um mathematische Operation durchzuführen und Ihre Felder und Konstanten zu vergleichen.
Konstanten
Konstanten sind Zahlen, Textzeichenfolgen und Datumsangaben, mit denen Sie mathematische Operation und Vergleiche durchführen können. Sie können beispielsweise ein konstantes Datum verwenden, z. B. das Datum, an dem Sie Ihre jährliche CX gestartet haben, um zu berechnen, wie alt die Antwort eines Umfrage ist.
Hinweise zur Verwendung von Konstanten:
- Bei Textstrings wird zwischen Groß- und Kleinschreibung unterschieden. Verwenden Sie die Funktionen UPPER oder LOWER als Behelfslösung für die Berücksichtigung von Groß- und Kleinschreibung.
- Textzeichenfolgen und Datumsangaben müssen in Anführungszeichen gesetzt werden.
- Zahlen benötigen keine Anführungszeichen (eine Zahl in Anführungszeichen wird als Text behandelt).
Felder
Felder sind die Datenfelder, die über Ihren eingehenden Datenkonnektor verfügbar sind. Dazu gehören numerische Felder, Textzeichenfolgen und Datumsfelder, mit denen Sie mathematische Operation und Vergleiche durchführen können. Wenn Ihr Datenset beispielsweise ein Feld für den Geburtstag eines Kunden enthält, können Sie berechnen, wie alt der Kunde ist.
Um ein Feld hinzuzufügen, ziehen Sie es aus dem Felder auf der Registerkarte Ausdruck Kasten.
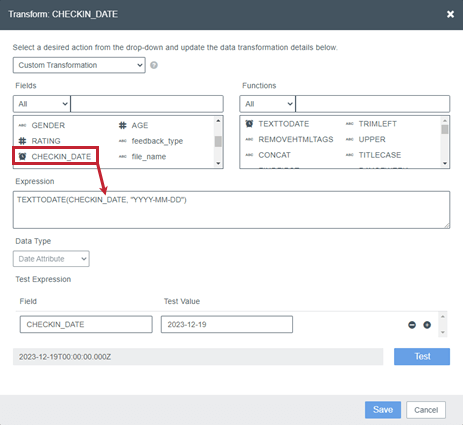{kind=link}

Feldtypen sind mit den folgenden Symbolen beschriftet:
-
für Datumsfelder
-
für numerische Felder
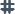
-
für Text- und ausführliche Felder

Funktionen
Sie können die in diesem Abschnitt aufgeführten numerischen Funktionen, Textfunktionen und Datumsfunktionen verwenden.
Um eine Funktion hinzuzufügen, ziehen Sie sie aus dem Funktionen auf der Registerkarte Ausdruck Kasten.
{kind=link}

Funktionstypen sind mit folgenden Symbolen beschriftet:
-
für Datumsfunktionen
-
für numerische Funktionen
-
für Textfunktionen

ABS
Gibt den absoluten Wert einer Zahl zurück.
Syntax: ABS(number)
Beispiel: ABS(-22) löst auf 22 auf.
COALESCE
Gibt den ersten Nicht-Null-Wert in einer Liste zurück.
Tipp: Eine leere Zeichenfolge wird als Null betrachtet. Wenn alle Werte Null sind, gibt die Funktion auch Null zurück.
Syntax: COALESCE(Wert1, Wert2, Wert3)
Beispiel: COALESCE(“”, “”, “Jane”, “”, “Paul”) löst mit Jane auf.
CEILING
Gibt den aufgerundeten Wert einer Zahl zurück.
Syntax: CEILING(number)
Beispiel: CEILING(21.2) löst sich auf 22.
CONCAT
Verknüpft mehrere Textzeichenfolgen zu einem.
Syntax: CONCAT(“string 1”, “string 2”, “string 3”)
Beispiel: CONCAT(“Hello”, “, “, “John”) löst in Hello, John auf.
CONTAINS
Gibt “true” zurück, wenn eine Textzeichenfolge (“innerhalb von Text”) eine andere Textzeichenfolge (“text suchen”) enthält. Andernfalls wird false zurückgegeben.
Syntax: CONTAINS(“in text”, “find text”)
Beispiel: CONTAINS(“eins, zwei, drei”, “zwei”) wird als wahr aufgelöst.
CONVERT_TO_TIMEZONE
Konvertiert Datum und Uhrzeit von einer Zone in eine andere.
Syntax: CONVERT_TO_TIMEZONE(“Datum und Uhrzeit”, “Zone, aus der konvertiert werden soll”, “Zone, in die konvertiert werden soll”)
Hinweise zur Datumsformatierung:
- Geben Sie die Zeitzonen über ihre tz-Datenbanknamen an.
- Geben Sie das Datum und die Uhrzeit in an. ISO 8601 oder als JJJJ-MM-TT hh:mm:ss.
- Wenn Datum und Uhrzeit mit Zone bereitgestellt werden, werden sie zugunsten des Parameters “Zone, aus der konvertiert werden soll” ignoriert.
- Das konvertierte Datum verwendet das ISO-8601-Format. Verwenden Sie die Funktion TODATE, wenn Sie dies ändern müssen.
Beispiel: CONVERT_TO_TIMEZONE(2020-03-19 15:15:00, “Europe/London”, “Europe/Berlin”) löst auf 2020-03-19T16:15:00Z.
DATETONUMBER
Konvertiert ein Datumsfeld in einen Unix-Zeitstempel.
Tipp: Unix-Zeitstempel ist die Anzahl der Millisekunden, die seit dem 1. Januar 1970 vergangen sind.
Syntax: DATETONUMBER(“date”)
Tipp: Eine umgekehrte Funktion namens NUMBERTODATE ist verfügbar.
Beispiel: DATETONUMBER(“2020-10-20T09:12:00.670Z”) wird in 1603185120670 aufgelöst.
DATETOTEXT
Konvertiert ein Datumsfeld in eine Datumszeichenfolge im angeforderten Format.
Syntax: DATETOTEXT(“date”, “date format”)
Beispiel: DATETOTEXT(NOW(), “MMMM DD YYYY, h:mm:ss”) wird bis 29. April 2020, 3:21:05 aufgelöst.
DAYOFWEEK
Gibt den Wochentag zurück, der einem Datum entspricht.
Syntax: DAYOFWEEK(“date”)
Beispiel: DAYOFWEEK(“2019-12-19T20:16:05.602Z”) löst auf Donnerstag.
DYNAMICLOOKUP
Ersetzt die Feldwerte mithilfe einer dynamisch geladenen Lookup-Tabelle. Lookup-Werte werden dem Feld entnommen, das im ersten Argument (“Feldname”) angegeben ist.
Syntax: DYNAMICLOOKUP(“Feldname”, “Wert”)
Tipp: Transformationen innerhalb der Funktion DYNAMICLOOKUP sind nicht zulässig.
Beispiel: DYNAMICLOOKUP(“QID15”, “10”) wird in “Hervorragend” aufgelöst.
ELEMENTOFARRAY
Extrahieren Sie den n-ten Wert aus einem Array, und ordnen Sie dann Array-Werte Attributen in XM Discover zu.
Syntax: ELEMENTOFARRAY([“Array-Element 1”, “Array-Element 2”, “Array-Element 3”], Zahl)
Hinweise:
- Wenn die Eingabe kein Array ist, gibt die Funktion einen Fehler aus.
- Wenn die Zahl größer als die Größe eines Arrays ist, gibt die Funktion Null zurück. Zahlen in aufsteigender Reihenfolge beginnen bei 0.
Tipp: Diese Funktion ist besonders für XM Discover Link Connector-Jobs nützlich.
Beispiel: ELEMENTOFARRAY([“a”, “b”, “c”], 1) wird in b aufgelöst.
FELD
Verschalungen von Feldnamen, die Leerzeichen oder Punkte enthalten.
Syntax: FIELD(“Feldname”)
Beispiel: FIELD(“Text Processed”) gibt den Wert des Feldes “Text Processed” zurück.
FIND
Sucht eine Textzeichenfolge (“find text”) innerhalb einer anderen Textzeichenfolge (“innerhalb text”) und gibt die Nummer der Startposition von “find text” ab dem ersten Zeichen von “Within text” (beginnend mit 1) zurück.
Ermöglicht die Angabe der Reihenfolge des Zeichens in “innerhalb von Text”, bei dem die Suche gestartet werden soll (beginnend bei 1). Wenn Sie order_number weglassen, wird davon ausgegangen, dass es sich um 1 handelt.
Gibt -1 zurück, wenn “Text suchen” nicht in “Innerhalb von Text” gefunden wird.
Syntax: FIND(“find text”, “Within text”, order_number)
Tipp: Bei der Funktion wird zwischen Groß- und Kleinschreibung unterschieden. Wenn Sie eine Suche ohne Beachtung der Groß-/Kleinschreibung durchführen möchten, verwenden Sie die Funktion SEARCH.
Beispiel: FIND(“easy”, “easy come, easy go”, 3) löst auf 12 auf.
FINDFIRST
Sucht das erste Vorkommen einer Textzeichenfolge (“find text”) innerhalb einer anderen Textzeichenfolge (“innerhalb text”) und gibt die Nummer der Startposition von “find text” ab dem ersten Zeichen von “Within text” (beginnend bei 1) zurück.
Tipp: Bei der Funktion wird zwischen Groß- und Kleinschreibung unterschieden; gibt -1 zurück, wenn “find text” nicht in “Within text” gefunden wird.
Syntax: FINDFIRST(“in text”, “find text”)
Beispiel: FINDFIRST(“easy come, easy go”, “easy”) löst sich auf 1.
FINDLAST
Sucht das letzte Vorkommen einer Textzeichenfolge (“find text”) innerhalb einer anderen Textzeichenfolge (“innerhalb text”) und gibt die Nummer der Startposition von “find text” ab dem ersten Zeichen von “Within text” (beginnend bei 1) zurück.
Tipp: Bei der Funktion wird zwischen Groß- und Kleinschreibung unterschieden; gibt -1 zurück, wenn “find text” nicht in “Within text” gefunden wird.
Syntax: FINDLAST(“in text”, “find text”)
Beispiel: FINDLAST(“easy come, easy go”, “easy”) löst sich auf 12.
FLOOR
Gibt den abgerundeten Wert einer Zahl zurück.
Syntax: FLOOR(number)
Beispiel: FLOOR(21.9) löst sich auf 21.
GENERATE_ID
Generiert eine eindeutige ID. Diese Funktion benötigt keine zusätzlichen Parameter.
Syntax: GENERATE_ID()
Beispiel: GENERATE_ID() wird in 5ecfdd3fdd4ca4f23c5f2602 aufgelöst.
GETDAYSBETWEEN
Gibt die Anzahl der Tage zwischen zwei Datumsangaben zurück.
Syntax: GETDAYSBETWEEN(“Startdatum”, “Enddatum”)
Beispiel: GETDAYSBETWEEN(“2019-12-19T20:16:05.602Z”, “2019-12-24T20:16:05.602Z”) löst auf 5 auf.
GETHOURSBETWEEN
Gibt die Anzahl der Stunden zwischen zwei Datumsangaben zurück.
Syntax: GETHOURSBETWEEN(“Startdatum”, “Enddatum”)
Beispiel: GETHOURSBETWEEN(“2019-12-19T20:16:05.602Z”, “2019-12-24T20:16:05.602Z”) löst auf 120 auf.
GETMINUTESBETWEEN
Gibt die Anzahl der Minuten zwischen zwei Datumsangaben zurück.
Syntax: GETMINUTESBETWEEN(“Startdatum”, “Enddatum”)
Beispiel: GETMINUTESBETWEEN(“2019-12-19T20:16:05.602Z”, “2019-12-24T20:16:05.602Z”) löst 7200 auf.
WENN
Gibt einen Wert zurück, wenn die Aussage wahr ist, und einen anderen, wenn die Aussage falsch ist.
Syntax: IF(statement, “value if true”, “value if false”)
Beispiel: IF(3 > 2, “größer”, “nicht größer”) wird in größer aufgelöst.
ISBLANK
Gibt TRUE zurück, wenn ein Feld leer ist, und FALSE, wenn ein Feld nicht leer ist.
Syntax: ISBLANK(“Feldname”)
Tipp: Da ISBLANK eine boolesche Funktion ist, können Sie sie nicht direkt auf ein Attribut übernehmen. Verwenden Sie sie als Teil eines Ausdrucks, der das Ergebnis im richtigen Format (Datum, Zahl oder Text) zurückgibt.
Beispiel: Ermitteln Sie ein leeres Feld, und geben Sie das Ergebnis als Textzeichenfolge zurück. IF(ISBLANK(“”), “leer”, “gefüllt”) wird in leer aufgelöst.
Beispiel: Ermitteln Sie ein nicht leeres Feld, und geben Sie das Ergebnis als Zahl zurück. IF(ISBLANK(“John”), 0, 1) wird in 1 aufgelöst.
JOINARRAY
Verknüpft ein Array von Elementen in einer einzelnen Zeichenfolge mit einem angegebenen Trennzeichen.
Synax: JOINARRAY(array, separator iter, escape, skipNull, removeDuplicates)
In der oben genannten Syntax:
- Array: Array von zu verknüpfenden Zeichenfolgen oder Zahlen.
- Trennzeichen: Trennzeichen, das beim Verknüpfen des Arrays verwendet werden soll.
- Escape: Wenn wahr, werden Elemente in Anführungszeichen beibehalten.
- skipNull: Wenn wahr, werden Elemente übersprungen, die null sind.
- removeDupliziert: Wenn wahr, entfernen Sie duplizieren Elemente.
Beispiel: JOINARRAY([“a”, “b”, “c”], “-“) wird in “a-b-c” aufgelöst.
LEN
Gibt die Anzahl der Buchstaben in einer Textzeichenfolge zurück.
Syntax: LEN(“text”)
Beispiel: LEN(“Count me if you can”) löst auf 19.
Syntax: LEN([“text1”, text2])
Beispiel: LEN([“text1”, text2]) wird in 2 aufgelöst.
LOWER
Konvertiert Text in Kleinbuchstaben.
Syntax: LOWER(“text”)
Beispiel: LOWER(“HELLO”) löst auf Hallo.
MD5HASH
Wendet den MD5-Hash auf die Eingabedaten an, um anhand dieser Daten eindeutige IDs zu generieren.
Syntax: MD5HASH(“text”)
Beispiel: MD5HASH(“Hello”) wird in 543d4abcdc64a9a377c959e4b6e35574 aufgelöst.
MID
Gibt eine bestimmte Anzahl von Zeichen aus einer Textzeichenfolge zurück, beginnend an der von Ihnen angegebenen Position.
Die Position (order_number) beginnt bei 1.
Syntax: MID(“text”, order_number, Characs_number)
Beispiel: Gibt 8 Zeichen ab dem ersten Zeichen zurück. MID(“Übung macht perfekt”, 1, 8) löst sich auf zu üben.
Beispiel: Gibt 8 Zeichen ab dem 16. Zeichen zurück. MID(“Übung macht perfekt”, 16, 8) löst sich auf perfekt.
MOD
Gibt den Rest zurück, wenn eine Zahl durch einen Divisor geteilt wird.
Tipp: Das Ergebnis hat das gleiche Vorzeichen wie eine Zahl.
Syntax: MOD(number, divisor)
Beispiel: MOD(7, 4) löst sich auf 3.
JETZT
Gibt das aktuelle Datum und die aktuelle Uhrzeit zurück. Diese Funktion benötigt keine zusätzlichen Parameter.
Syntax: NOW()
Beispiel: NOW() löst auf 2020-01-29T13:35:09.956Z auf.
NUMBERTODATE
Konvertiert einen Unix-Zeitstempel in ein Datumsfeld. Der Unix-Zeitstempel ist die Anzahl der Millisekunden, die seit dem 1. Januar 1970 vergangen sind.
Syntax: NUMBERTODATE(number)
Tipp: Es steht eine Rückwärtsfunktion namens DATETONUMBER zur Verfügung.
Beispiel: NUMBERTODATE(1603185120670) wird auf 2020-10-20T09:12:00.670Z aufgelöst.
NUMBERTOTEXT
Konvertiert eine Zahl in Text.
Syntax: NUMBERTOTEXT(number)
Beispiel: NUMBERTOTEXT(21) wird in 21 aufgelöst.
POW
Gibt das Ergebnis von x potenziert mit y zurück.
Syntax: POW(x, y)
Beispiel: POW(2, 4) wird in 16 aufgelöst.
PROPERCASE
Großschreibung des ersten Buchstabens einer Textzeichenfolge.
Syntax: PROPERCASE(“text”)
Beispiel: PROPERCASE(“Übung macht perfekt”) löst auf Übung macht perfekt.
RANDOM
Gibt eine zufällige reelle Zahl zwischen 0 und 1 zurück. Diese Funktion benötigt keine zusätzlichen Parameter.
Syntax: RANDOM()
Beispiel: RANDOM() wird auf 0.7669519868005736 aufgelöst.
RANDOMBETWEEN
Gibt eine zufällige Ganzzahl zwischen zwei Zahlen zurück.
Tipp: Diese Funktion kann die minimale und maximale Anzahl zurückgeben.
Syntax: RANDOMBETWEEN(minimale Anzahl, maximale Anzahl)
Beispiel: RANDOMBETWEEN(1, 10) wird in 2 aufgelöst.
REMOVEHTMLTAGS
Entfernt HTML aus einer Textzeichenfolge.
Syntax: REMOVEHTMLTAGS(“text”)
Beispiel: REMOVEHTMLTAGS(“<html>Hallo</html>”) löst sich zu Hallo.
ERSETZEN
Ersetzt einen Teil eines Textstrings (“alter Text”) durch einen anderen Textstring (“neuer Text”), eine festgelegte Anzahl (number_of_replacements) basierend auf der Anzahl der Vorkommen von “old text” innerhalb von “text” (nonence_number).
Syntax: REPLACE(“text”, “old text”, “new text”, nonence_number, case_sensitive, number_of_replacements)
Beispiel: REPLACE(“innerhalb der Box denken”, “innen”, “außen”, 1, falsch, 1) löst das Denken außerhalb der Box auf.
REPLACEBYINDEX
Ersetzt einen Teil einer Textzeichenfolge (“alter Text”) durch eine andere Textzeichenfolge (“neuer Text”), basierend auf der Anzahl der Zeichen, die Sie angeben.
Die Position (order_number) beginnt bei 1.
Syntax: REPLACE(“alter Text”, order_number, zeichens_number, “new text”)
Beispiel: REPLACEBYINDEX(“innerhalb der Box denken”, 7, 6, “außen”) löst auf, dass außerhalb der Box gedacht wird.
REPLACEBYREGEXP
Ersetzt Textwerte durch reguläre Ausdrücke.
Tipp: Ein regulärer Ausdruck ist eine Folge von Zeichen, die ein Suchmuster definieren. Eine kurze Einführung finden Sie unter Reguläre .NET-Ausdrücke von Microsoft.
Achtung: Kundeneigene Quelltextfunktionen werden unverändert bereitgestellt und erfordern Programmierkenntnisse zur Implementierung. Der Qualtrics Support bietet keinerlei Hilfestellung oder Beratung im Zusammenhang mit eigenem Programmcode an. Sie können immer versuchen, unsere Community mit dedizierten Benutzern. Wenn Sie mehr über unsere Services für kundenspezifisches Coding erfahren möchten, Kontakt Ihren Qualtrics Benutzerkonto Executive.
Syntax: REPLACEBYREGEXP(“text”, “regulärer Ausdruck für Musterabgleich”, “regulärer Ausdruck für Ersatzwert”)
Tipp: Sonderzeichen wie linksseitige Schrägstriche (\), doppelte Anführungszeichen (“) und einfache Anführungszeichen (‘) müssen maskiert werden (d.h. vor ihnen muss ein umgekehrter Schrägstrich hinzugefügt werden). Wenn Sie beispielsweise das Muster verwenden möchten, das mit einem Leerzeichen (\s) übereinstimmt, müssen Sie es mit einem zusätzlichen umgekehrten Schrägstrich (\\s) maskieren.
Beispiel: REPLACEBYREGEXP(“Clarabank UK”, “(.)\\s(.)”, “$1;$2”) wird in Clarabank;UK aufgelöst.
ROUND
Gibt den Wert einer Zahl zurück, die auf die nächste Ganzzahl gerundet wurde.
Syntax: ROUND(number)
Beispiel: ROUND(22.5) löst auf 23 auf.
SUCHE
Sucht eine Textzeichenfolge (“find text”) innerhalb einer anderen Textzeichenfolge (“innerhalb text”) und gibt die Nummer der Startposition von “find text” ab dem ersten Zeichen von “Within text” (beginnend mit 1) zurück.
Ermöglicht die Angabe der Reihenfolge des Zeichens in “innerhalb von Text”, bei dem die Suche gestartet werden soll (beginnend bei 1). Wenn Sie order_number weglassen, wird davon ausgegangen, dass es sich um 1 handelt.
Gibt -1 zurück, wenn “Text suchen” nicht in “Innerhalb von Text” gefunden wird.
Syntax: SEARCH(“find text”, “Within text”, order_number)
Tipp: Bei der Funktion wird nicht zwischen Groß- und Kleinschreibung unterschieden. Wenn Sie eine Suche mit Beachtung der Groß-/Kleinschreibung durchführen möchten, verwenden Sie die Funktion FIND.
Beispiel: SEARCH(“EASY”, “easy come, easy go”, 3) löst auf 12 auf.
SPLIT
Teilt eine bestimmte Zeichenfolge basierend auf einem angegebenen Trennzeichen in ein Array von Teilzeichenfolgen auf. Diese Funktion kann als Parameter für JOINARRAY- oder ELEMENTOFARRAY-Funktionen verwendet werden, da der Ausgabewert eine Zeichenfolge sein muss.
Syntax: SPLIT(“string_to_split”, “_”)
Beispiel: SPLIT(“firstname_lastname”, “_”) aufgelöst in [“firstname”, “lastname”]
SUBSTITUT
Ersetzt “alter Text” durch “neuer Text” in einem Textstring.
Ermöglicht die Angabe, welches Vorkommen von “altem Text” Sie ersetzen möchten. Wenn Sie nonence_number angeben, wird nur die Instanz von “old text” ersetzt. Andernfalls wird jedes Vorkommen von “altem Text” im Text in “neuer Text” geändert.
Syntax: SUBSTITUTE(“text”, “old text”, “new text”, nonence_number)
Beispiel: Ersetzen Sie das erste Vorkommen von “1” durch “2”. SUBSTITUTE(“Quartal 1, 2019”, “1”, “2”, 1) wird in Quartal 2, 2019 aufgelöst.
Beispiel: Zweites Vorkommen von “1” durch “2” ersetzen. SUBSTITUTE(“Quartal 1, 2019”, “1”, “2”, 2) wird in Quartal 1, 2029 aufgelöst.
Beispiel: Ersetzen Sie jedes Vorkommen von “1” durch “2”: SUBSTITUTE(“Quartal 1, 2019”, “1”, “2”) wird in Quartal 2, 2029 aufgelöst.
SUBSTR
Gibt einen Teil einer Textzeichenfolge zurück, beginnend mit dem ersten Zeichen der Zeichenfolge und bis zur angegebenen Anzahl von Zeichen (beginnend mit 1).
Syntax: SUBSTR(“text”, order_number)
Beispiel: SUBSTR(“Übung macht perfekt”, 9) löst sich in die Praxis.
TITLECASE
Großschreibung des ersten Buchstabens jedes Wortes in einer Textzeichenfolge.
Syntax: TITLECASE(“text”)
Beispiel: TITLECASE(“Übung macht perfekt”) löst sich auf Übung macht perfekt.
TEXTTODATE
Konvertiert eine Datumszeichenfolge in ein Datumsfeld im folgenden Format: JJJJ-MM-TTThh:mm:ssZ.
Syntax: TEXTTODATE(“date”, “date format”)
Tipp: Das Datumsformat muss dem in der Zeichenfolge verwendeten Format entsprechen. Beide Parameter sind erforderlich.
Beispiel: TEXTTODATE(“2019-12-19”, “YYYY-MM-DD”) wird auf 2019-12-19T00:00:00.000Z aufgelöst.
TEXTTONUMBER
Konvertiert Text in Zahl.
Syntax: TEXTTONUMBER(text)
Beispiel: TEXTTONUMBER(21) bis 21.
ÜBERSETZEN
Übersetzt eingehende Daten.
Syntax: TRANSLATE ("Sprachcode ", " Ziel ", "Text").
Hinweise:
- Diese Funktion steht nur für Abrechnungen mit API für Google Translate
- Eine vollständige Liste der unterstützten Sprachcodes finden Sie unter. Dokumentation zu Google Cloud Translation.
Beispiel: TRANSLATE (“en”, “es”, “Hello world”) löst sich auf Hola mundo.
TRIMLEFT
Entfernt Leerzeichen am linken Ende einer Textzeichenfolge.
Syntax: TRIMLEFT(“text”)
Beispiel: TRIMLEFT(” hello”) löst sich auf hello.
TRIMRIGHT
Entfernt Leerzeichen am rechten Ende einer Textzeichenfolge.
Syntax: TRIMRIGHT(“text”)
Beispiel: TRIMRIGHT(“hello “) löst sich auf hello.
UPPER
Konvertiert Text in Großbuchstaben.
Syntax: UPPER(“text”)
Beispiel: UPPER(“hello”) löst auf HELLO auf.
Operatoren
Sie können die in den folgenden Tabellen aufgeführten arithmetischen Operatoren und Vergleich verwenden.
Arithmetische Operatoren
| Operator | Beschreibung |
|---|---|
| + | Hinzufügen |
| – | Subtrahieren oder Negieren |
| * | Multiplizieren |
| / | Dividieren |
Der folgende Ausdruck gibt beispielsweise den Durchschnitt der beiden numerischen Werte zurück.
(RATING1 + RATING2) / 2
Vergleich
| Operator | Beschreibung |
|---|---|
| == | Gleich |
| > | Größer als |
| < | Kleiner als |
| >= | Größer oder gleich |
| <= | Kleiner oder gleich |
| != | Ungleich |
Der folgende Ausdruck gibt beispielsweise “schlechte Bewertung” zurück, wenn RATING kleiner oder gleich 3 ist, und “gute Bewertung”, wenn RATING größer als 3 ist.
IF(RATING <= 3, “schlechte Bewertung”, “gute Bewertung”)
Logische Operatoren
Verwenden Sie logische Operatoren, um mehrere Bedingungen anzugeben, wenn Sie die IF-Funktion oder Jobfilter verwenden.
Tipp: Stellen Sie sicher, dass Sie logische Operatoren in Kleinbuchstaben verwenden.
| Operator | Beschreibung |
|---|---|
| und | Bedingung ist wahr, wenn alle durch „und“ getrennten Bedingungen wahr sind. |
| ist enthalten in | Bedingung ist wahr, wenn es eine Übereinstimmung mit einem der aufgelisteten Werte gibt. Syntax: in[“Wert 1”, “Wert 2”, “Wert 3”]
|
| oder | Bedingung ist wahr, wenn eine der durch „oder“ getrennten Bedingungen wahr ist. |
Der folgende Ausdruck gibt beispielsweise “Mittelmeer” zurück, wenn das Feld COUNTRY einen der angegebenen Werte enthält. Andernfalls wird “Non-Metiterranean” zurückgegeben.
IF(LOWER(LAND) in [“france”, “portugal”, “italy”, “spain”, “greece”, “malta”, “cyprus”], “Mediterranean”, “Non-Mediterranean”)
Syntaxtipps
Gehen Sie wie folgt vor, um ungültige Ausdrücke zu vermeiden:
- Wenn Sie mehrere Funktionen in einem Ausdruck kombinieren, stellen Sie sicher, dass die Anzahl der öffnenden und schließenden Klammern übereinstimmt. Beispiel: IF(GETDAYSBETWEEN(feedback_date, response_date) > 3, “verzögert”, “nicht verzögert”).

- Für jede im Ausdruck verwendete Funktion müssen alle erforderlichen Argumente vorhanden sein. Beispielsweise erfordert die TODATE-Funktion, dass sowohl die Datums- als auch die Datumsformatargumente korrekt funktionieren.
- Stellen Sie sicher, dass Sie den richtigen Datentyp verwenden, der von einer Funktion oder einer arithmetischen oder Vergleich unterstützt wird. Beispielsweise benötigt die ABS-Funktion eine Zahl, um korrekt zu funktionieren, und funktioniert nicht für ein Text- oder Datumsfeld.
- Wenn in Ihrem Ausdruck Punkte (“.”) enthalten sind, schließen Sie sie mit der FIELD-Funktion und Anführungszeichen (entweder ‘einfach’ oder “doppelt”) um. Wenn Sie beispielsweise ein Feld mit dem Namen „agentParticipants.0.agentLoginName“ haben, verpacken Sie es wie folgt in eine potenzielle Transformation:
IF(CONTAINS(LOWER(FIELD(“agentParticipants.0.agentLoginName”)), “bot”),”YES”, “NO”).
Großartig! Vielen Dank für die Rückmeldung!
Vielen Dank für die Rückmeldung!