Lavorare con i risultati dei driver (Studio)
Cosa puoi trovare in questa pagina
Su come lavorare con Driver Risultati
Dopo aver creato un driver e averlo eseguito per trovare i driver nei dati, è possibile accedere e visualizzare i risultati dei driver, visualizzare le misure statistiche per valutare la qualità del modello predittivo, impostare un volume minimo per i driver e nascondere e nascondere i driver.
Accessibilità ai risultati dei driver
Dopo aver creato un driver e aver trovato i driver nei dati, è possibile accedere ai risultati dei driver per i dati nella finestra Risultati driver.
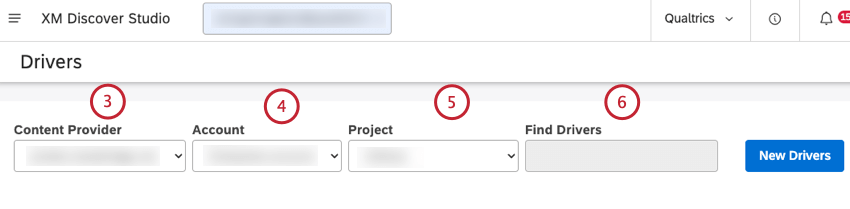
Consiglio Q: è possibile inserire il nome del driver nella casella Trova driver per trovarlo.
Visualizzazione dei risultati dei driver
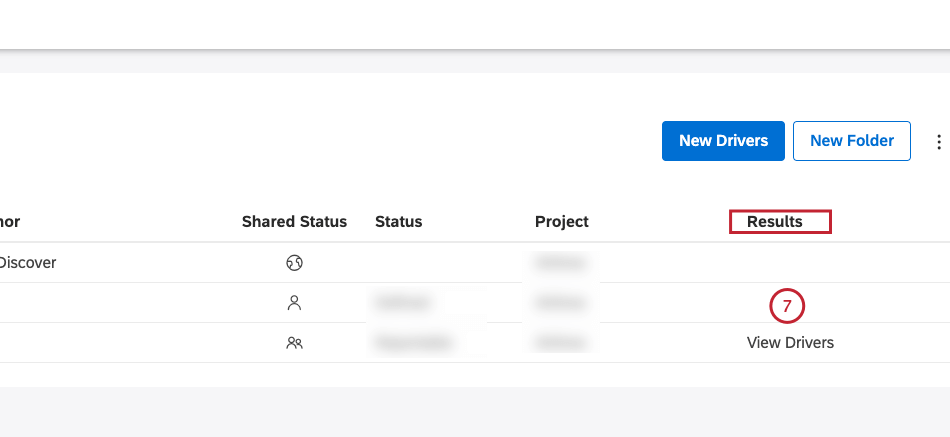
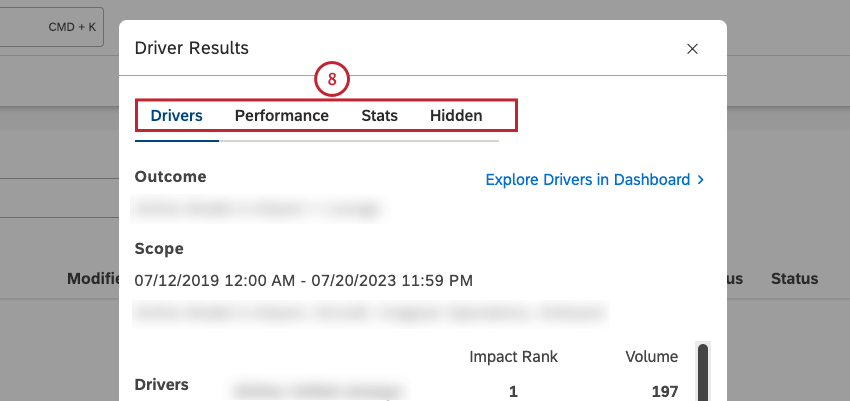
Dopo aver effettuato l’accesso ai risultati dei driver, è possibile visualizzare i risultati dei driver nella scheda Driver della finestra Risultati driver. È inoltre possibile eseguire il drill sui feedback correlati nell’Esplora documenti, visualizzare i driver inversi, esplorare i driver in un dashboard e nascondere e nascondere i driver.
Nella scheda Driver è possibile visualizzare le seguenti informazioni:
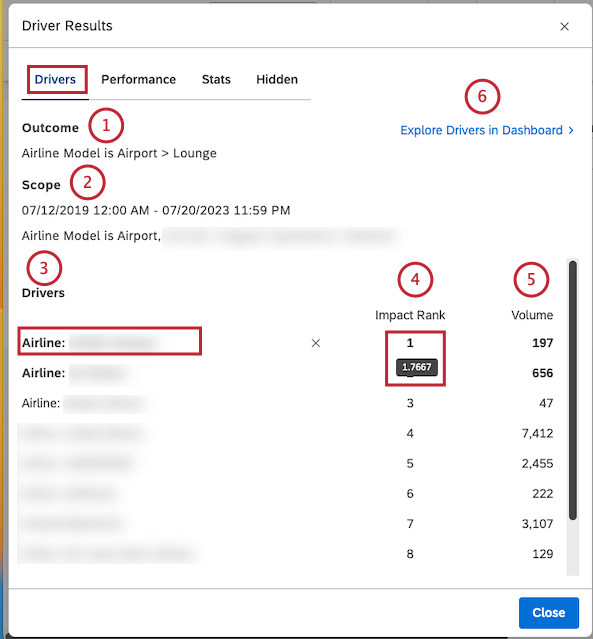
Consiglio Q: fare clic sul nome del driver per visualizzare i feedback in Esplora documenti.
Consiglio Q: passate il mouse sul numero nella colonna Classifica dell’impatto per visualizzare il punteggio dell’impatto.
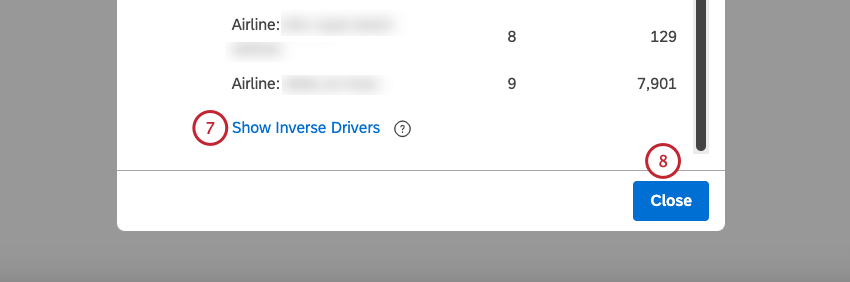
Consiglio Q: i driver inversi prevedono l’opposto binario del risultato definito. Quando si verificano i driver inversi, è meno probabile che si verifichi il risultato iniziale. Quando si sta esplorando un risultato negativo, i driver sono le cose da evitare, mentre i driver inversi sono le cose da cercare.
Impatto Classifica
Il grado di impatto è il numero di tutti i driver ordinati in base al punteggio di impatto. La classificazione dell’impatto assegna una priorità ai driver in base alla loro capacità di prevedere l’esito definito. Un pilota con un grado 1 ha più potere indicativo di un pilota con un grado 2 o superiore.
Il rango d’impatto deriva dal punteggio d’impatto, una metrica che misura la potenza di un driver nel predire il risultato scelto. Il punteggio d’impatto è il prodotto di un modello unico di apprendimento automatico generato per i conducenti.
Il punteggio dell’impatto è normalizzato, ovvero è relativo ad altri piloti nella stessa ricerca di piloti. I valori del punteggio d’impatto sono perlopiù compresi tra -1 e 1.
Suggerimenti per il punteggio d’impatto
Quando si analizzano i conducenti in base al punteggio di impatto, seguire i seguenti suggerimenti:
- Non fissatevi sui valori decimali del punteggio d’impatto: L’intento principale dei valori decimali del punteggio d’impatto è quello di classificare e differenziare i driver più forti da quelli più deboli. I valori decimali non forniscono di per sé significatività statistica.
- Prestare attenzione ai driver con punteggio di impatto prossimo o superiore a 1: i driver con un valore di impatto prossimo o superiore a 1 sono predittori più forti del risultato.
- Altrettanto importante è prestare attenzione ai driver con un punteggio di impatto prossimo o inferiore a -1 (driver inversi): I driver con un punteggio di impatto vicino o inferiore a -1 sono predittori più forti dell’opposto binario del vostro risultato. Si tratta dei cosiddetti driver inversi. Ad esempio, se si cercassero i driver delle valutazioni dei detrattori, un forte valore negativo sarebbe un driver per i non detrattori, o per i passivi e i promotori.
- Considerate il punteggio di impatto come una metrica non lineare: Per esempio, un punteggio di impatto di 0,4 è più del doppio di un punteggio di impatto di 0,2.
- Tenere presente che il punteggio d’impatto è normalizzato: L’impatto della normalizzazione è che la rimozione dei risultati dei successivi ricalcoli dei conducenti comporterà probabilmente un aumento o una diminuzione dei valori del punteggio d’impatto di altri conducenti. Ad esempio, l’eliminazione di un driver molto forte comporta la necessità di fare previsioni con i dati rimanenti, con il risultato che altri driver possono diventare più o meno importanti.
- Differenziare i driver in base a una seconda metrica come la % totale, l’analisi del sentiment o l’impegno: Ad esempio, se due driver diversi hanno lo stesso punteggio di impatto ma percentuali di totale molto diverse, è probabile che si voglia concentrare l’esplorazione sul driver più diffuso.
Esplorazione dei driver in un Dashboard
È possibile aggiungere un widget di dispersione raggruppato per autisti a qualsiasi dashboard o a un nuovo dashboard.
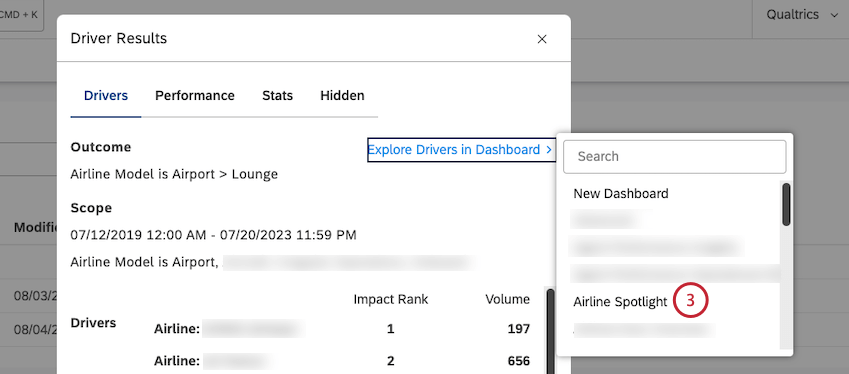
Consiglio Q: per aggiungere un widget di dispersione a una nuova dashboard, fare clic su Nuova dashboard nella parte superiore della lista.

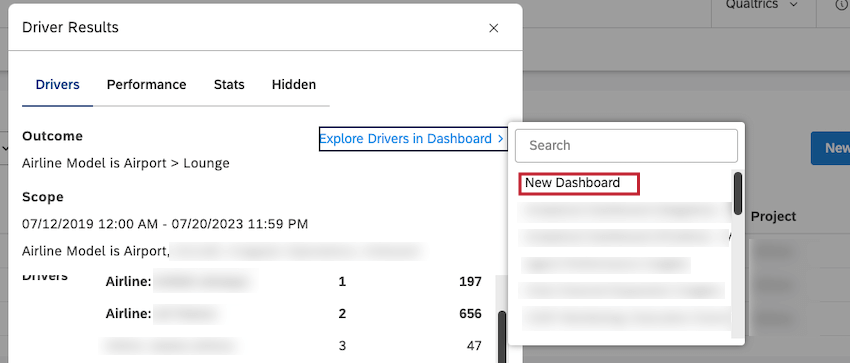
- Intervallo di date: Come nell’ambito dell’indagine
- Filtri: Sincronizzati con il driver
- Calcolo dell’asse verticale: Punteggio dell’impatto
- Calcolo dell’asse orizzontale: Volume
- Gruppo da: Autisti
Nascondere e non nascondere i driver nei risultati dei driver
Dopo aver avuto accesso ai risultati dei driver, è possibile visualizzarli e nascondere quelli non utili per l’analisi.
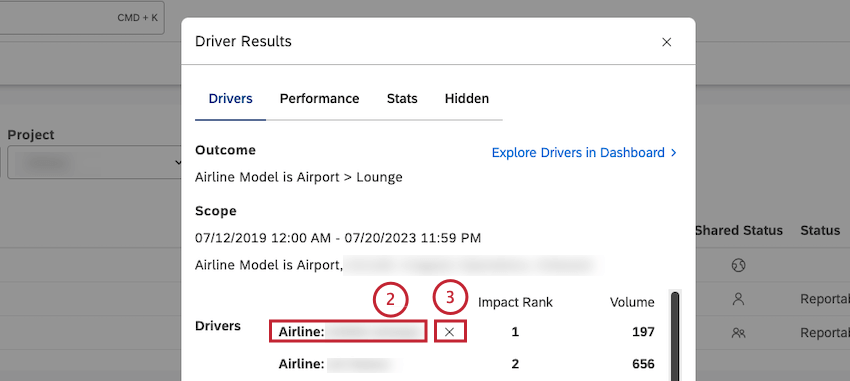
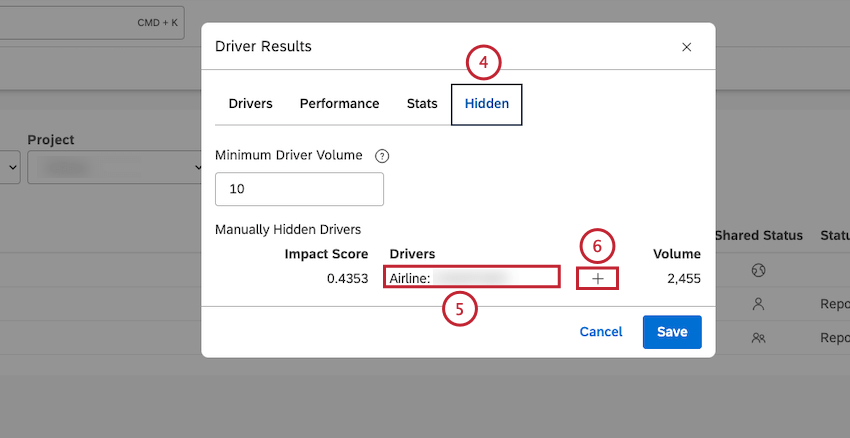
Consiglio Q: i driver nascosti non appaiono nella scheda Driver e nei widget in cui sono utilizzati. Nella scheda Nascosti è possibile visualizzare una lista di driver che sono stati nascosti manualmente.
Valutatore delle performance del modello
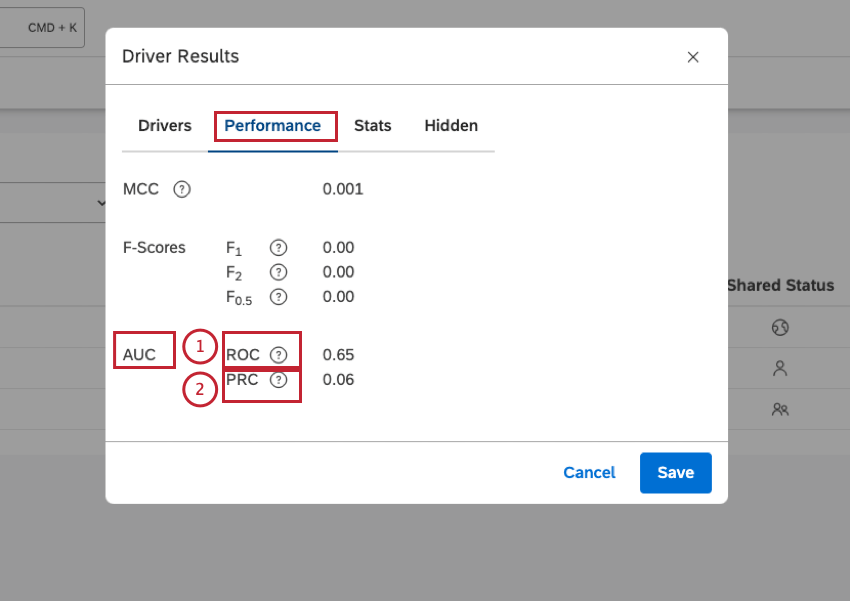
Dopo aver avuto accesso ai risultati dei driver, è possibile visualizzare le misure statistiche per valutare la qualità del modello predittivo nella scheda Performance della finestra Risultati driver:
Visualizzazione dei risultati del driver in formato JSON
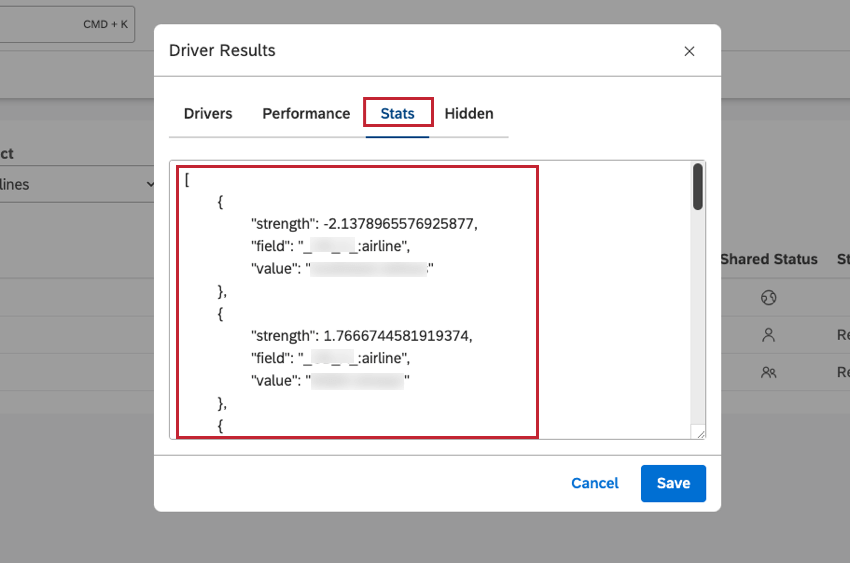
Dopo aver avuto accesso ai risultati del driver, è possibile visualizzare i risultati del driver in formato JSON nella scheda Statistiche della finestra Risultati del driver . È utile per la risoluzione dei problemi.
{kind=link}

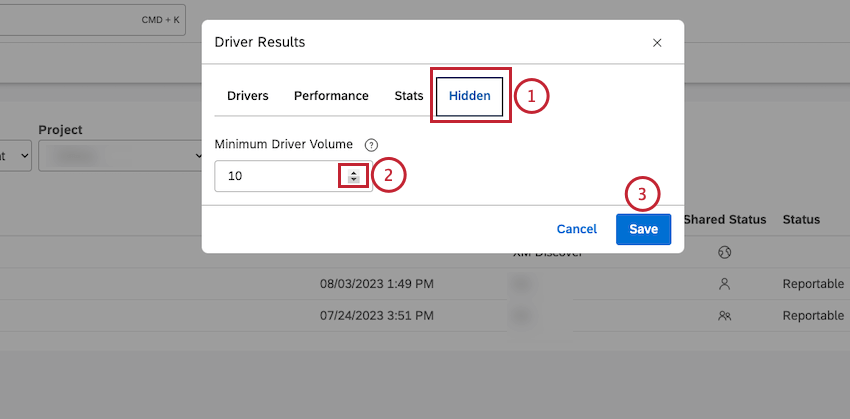
Impostazione del volume minimo per gli autisti
Dopo aver avuto accesso ai risultati dei driver, è possibile definire il numero minimo di documenti che qualificano ogni potenziale driver per la valutazione.
L’analisi dei driver prevede di campionare il milione di documenti fino a 50.000 documenti randomizzati e di utilizzare tale campione per trovare i driver. Se l’ambito contiene meno di 50.000 documenti, non viene effettuato alcun campionamento. Ciò significa che se l’ambito è superiore a 50.000 documenti, è possibile che la seconda volta che si esegue l’operazione si ottengano driver leggermente diversi (a parità di altre condizioni) a causa del campionamento. Tuttavia, questo ha di solito un impatto maggiore sugli articoli a basso volume, che sono probabilmente i meno preziosi.
I potenziali conducenti con volumi molto bassi possono essere sottorappresentati o sovrarappresentati nei set di dati del campione. Si consiglia di filtrare questi driver dai grafici utilizzando una soglia minima di volume. Tenete presente, tuttavia, che questi driver di piccolo volume possono essere utili per identificare piccoli gruppi di clienti che necessitano di risposte tattiche.
È inoltre possibile che i punteggi d’impatto subiscano lievi variazioni a causa delle naturali variazioni di campionamento. Un’altra potenziale causa di questo problema è il caricamento o la rimozione di dati dal progetto entro i termini specificati
Consiglio Q: in alternativa, è possibile inserire un numero nella casella.
È fantastico! Grazie per il tuo feedback!
Grazie per il tuo feedback!