データの変換(コネクター)
このページの内容
Discoverでのデータ変換について
XM Discoverにインポートする前に、受信データを変換することができます。データのクリーニングやデータ形式の変更が必要な場合に便利です。
データ変換にアクセスする:
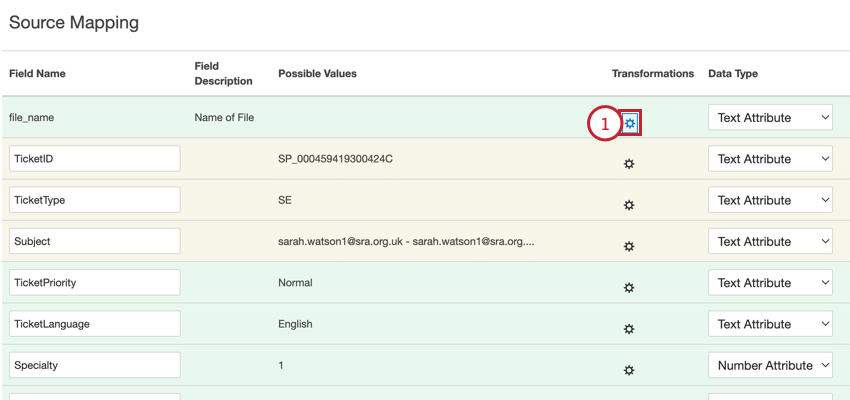
Qtip:既存のジョブのデータ変換を更新したい場合は、ジョブオプションメニューからデータマッピングを選択してください。
注意: 歯車のアイコンの次へ数字がある場合は、すでにそのフィールドに変形が適用されていることを意味します。新しい変身を追加すると、それは古い変身と置き換わる。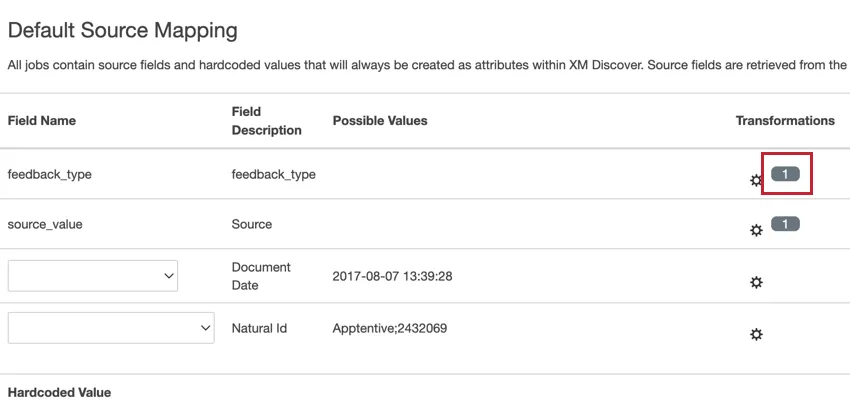
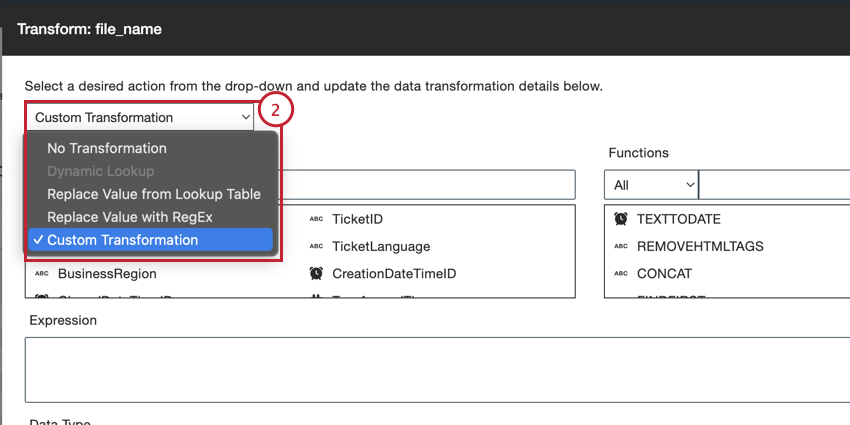
- 変換しない:インポートされたフィールドを変換しない。
- ダイナミック・ルックアップ:このオプションはルックアップ・フィールドにのみ使用できる。このフィールドを選択すると、ルックアップテーブルからそのフィールドの最新のルックアップ値が適用される。
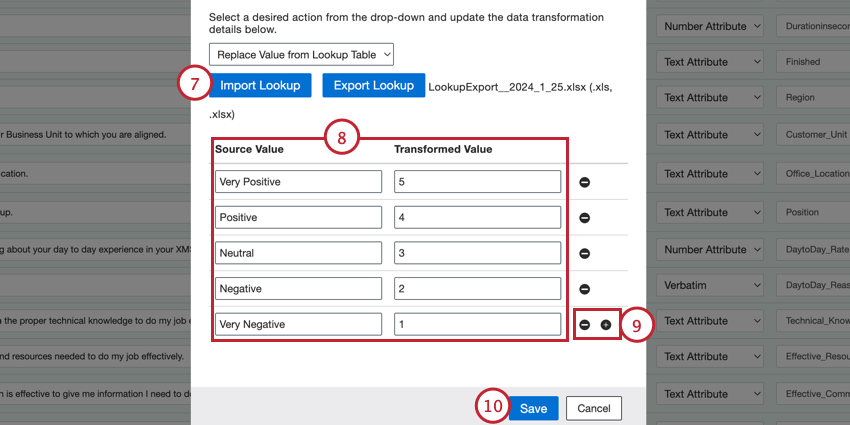
- ルックアップテーブルから値を置換:ソース値と置換値のペアを定義する。
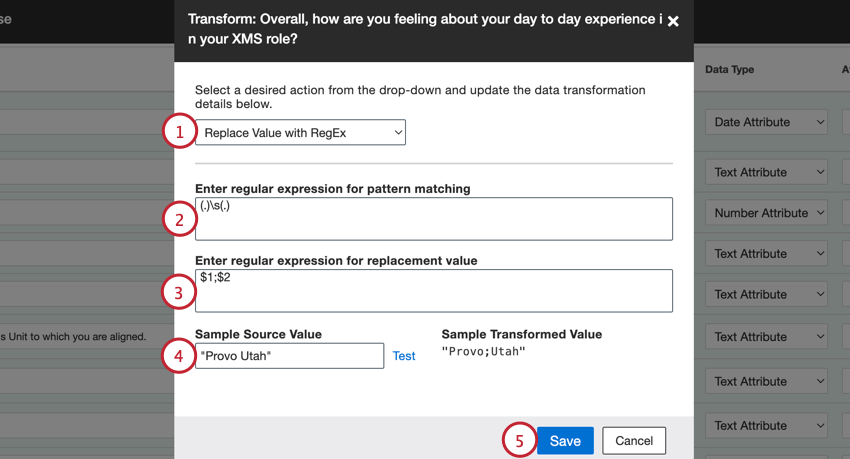
- RegExで値を置き換える:パターン・マッチと置換値のための正規表現(regex)を定義する。
- カスタム・トランスフォーメーション:様々な関数や式を使って独自の変換を構築。
注意: 変換は、将来インポートされる新しいデータにのみ適用されます。過去のデータは影響を受けない。履歴データを更新するには、そのジョブのデータを取得します。
ダイナミック・ルックアップ
このオプションは、接続されたデータソースのルックアップテーブルを参照するデータフィールドにのみ使用できます。XM Discoverに正しいデータがインポートされるように、動的ルックアップ式を指定できます。
例: 例えば、DYNAMICLOOKUP(“QID15”, “10”)という式は、データソースのQID15フィールドを検索し、10番目のエントリーを送信する。このフィールドは、1が「非常に否定的」で10が「非常に肯定的」である1~10スケールのアンケート調査に対応しているため、この表現は “非常に肯定的 “となる。
ルックアップテーブルから値を置換
どのソースフィールドにもルックアップを追加して、XM Discoverプロジェクトに送信される値をより正確にコントロールすることができます。ルックアップテーブルを使用すると、XM Discoverに保存する際に置き換えられるソース値を定義できます。
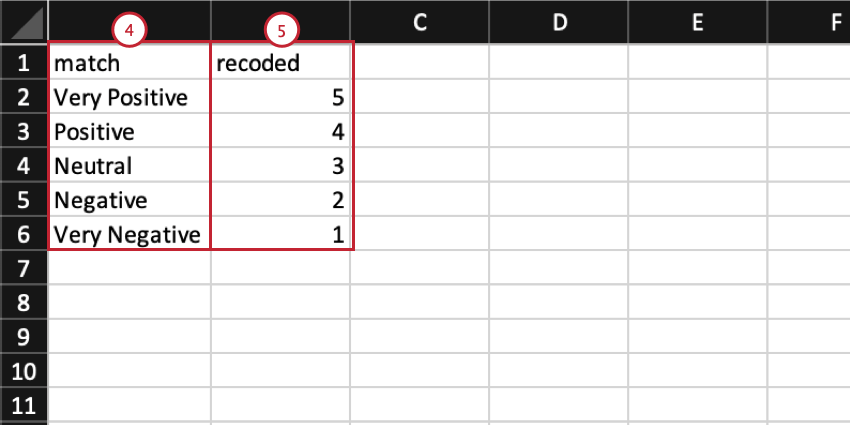
例: このオプションを使用して、アンケート調査の回答形式を変更することができます。例えば、サービス評価をアップロードする際、数値形式(1から5まで)とテキスト形式(Very NegativeからVery Positiveまで)を切り替えることができます。
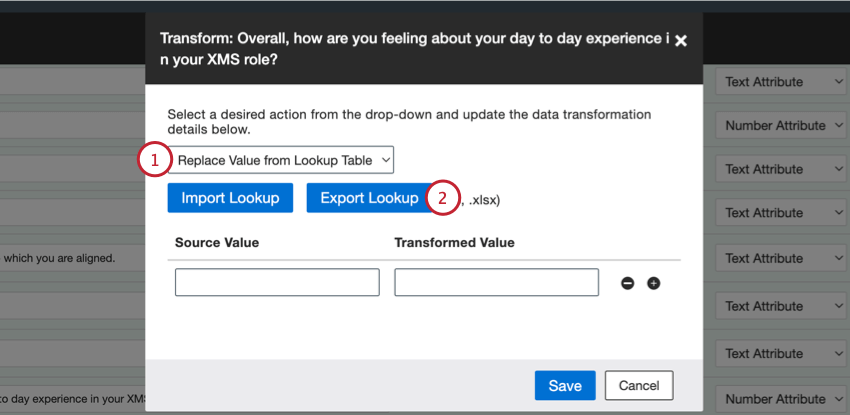
Qtip:ルックアップファイルを使ってルックアップを追加することをお勧めします。ルックアップを手動で追加したい場合は、ステップ8に進んでください。
RegExで値を置き換える
正規表現(regex)を使って入力データの値を置き換えることができるので、XM Discoverプロジェクトに読み込む前にデータをきれいにすることができます。
注意: カスタムコーディング機能はそのまま提供され、実装するにはプログラミングの知識が必要です。Discoverサポートでは、カスタムコーディングに関するサポートやコンサルティングは行っておりません。その代わり、クアルトリクスXMコミュニティの経験豊富なユーザーにいつでも質問できます。カスタムコーディングサービスの詳細をお知りになりたい場合は、エグゼクティブ営業担当までご連絡ください。
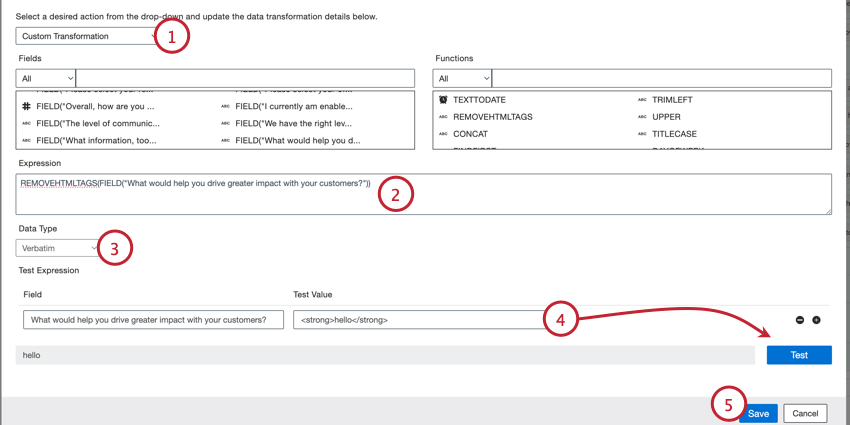
カスタム・トランスフォーム
独自のカスタム式を使用して入力データを変換できます。カスタム変換により、日付フォーマットの変更、フィールドの結合、先頭のゼロの削除など、さまざまなタイプのデータ操作が可能になります。
Qtip:追加の例として、カスタム変換の例をご覧ください。
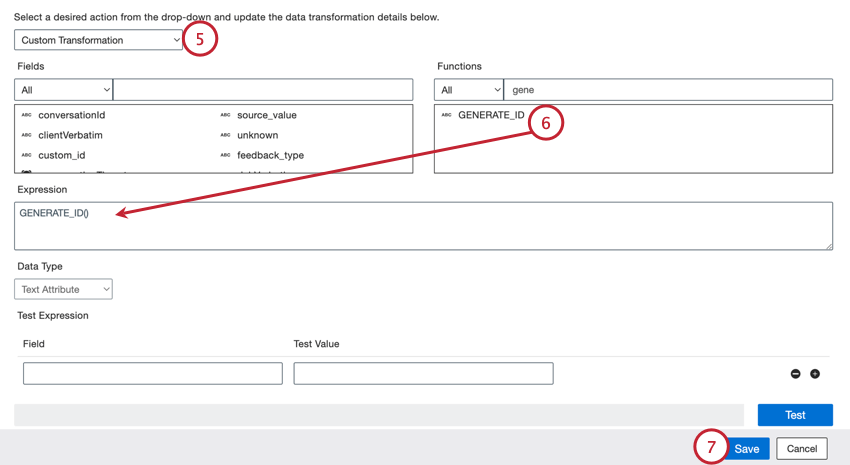
自然なIDの自動生成
XM Discoverにデータをアップロードする際、ドキュメントに固有IDが含まれていない場合があります。固有IDは、重複したドキュメントを識別するのに役立つ重要なフィールドです。アップロードされたデータには、自然IDとして使用するための一意の識別子が必要です。このセクションでは、カスタム変換を使用してデータをマッピングする際に、自然なIDを設定する方法について説明します。
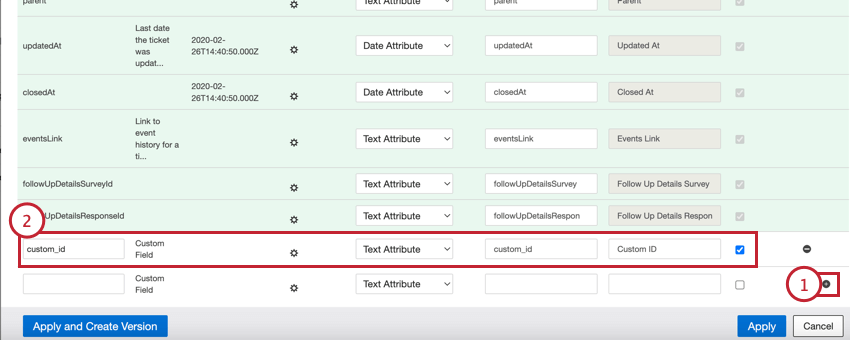
- フィールド名:フィールド名を入力します。
- データタイプ:データ型:ドロップダウンメニューから「テキスト属性」を選択。
- 属性名:”フィールド名 “と同じにしておく。
- 属性表示名:必要であれば、より使いやすいフィールド表示名を入力する。
- レポート可能:このチェックボックスを有効にする。レポートに自然IDを使用できるように、これを選択する必要があります。
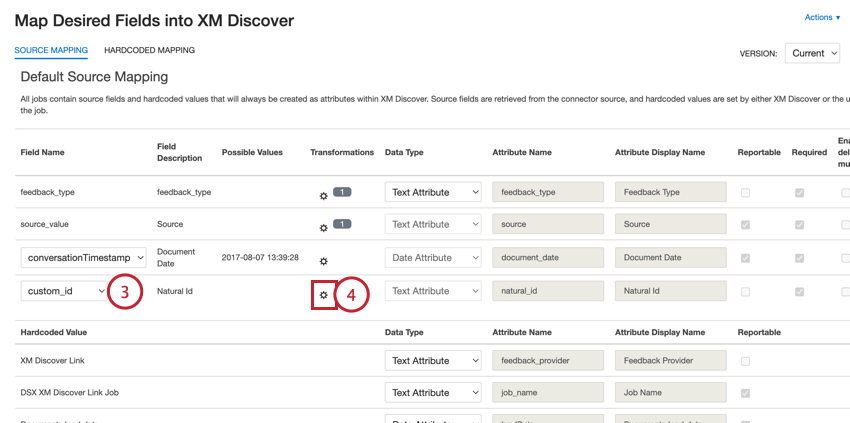
Qtip:適用を クリックしてマッピングを保存してください。
これで、アップロードされた文書にはランダム化されたIDが付与されます。
特定の文書の日付を設定する
XM Discoverにデータをアップロードする際、ドキュメントには複数の日付フィールドが含まれている場合もあれば、まったく含まれていない場合もあります。アップロードするデータには、文書の日付として使用する日付フィールドが必要です。このセクションでは、カスタム変換を使用してデータをマッピングする際に、ドキュメントの日付を設定する方法について説明します。
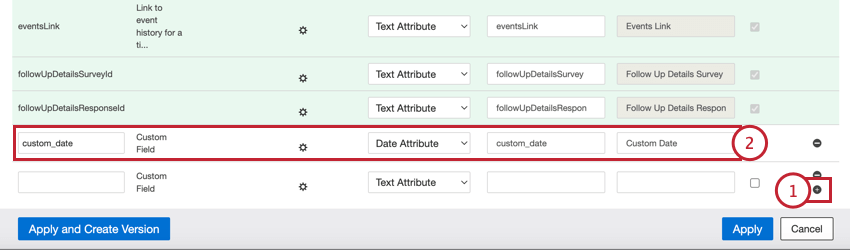
- フィールド名:フィールド名を入力します(例:custom_date)。
- データ・タイプ:データ型:ドロップダウンメニューから「日付属性」を選択。
- 属性名:フィールド名」と同じにしてください(例:custom_date)。
- 属性表示名:必要であれば、フィールドにより使いやすい表示名を追加する。
- レポート可能:このチェックボックスを有効にする。Discoverレポートで日付を文書化する場合は、これを選択する必要があります。
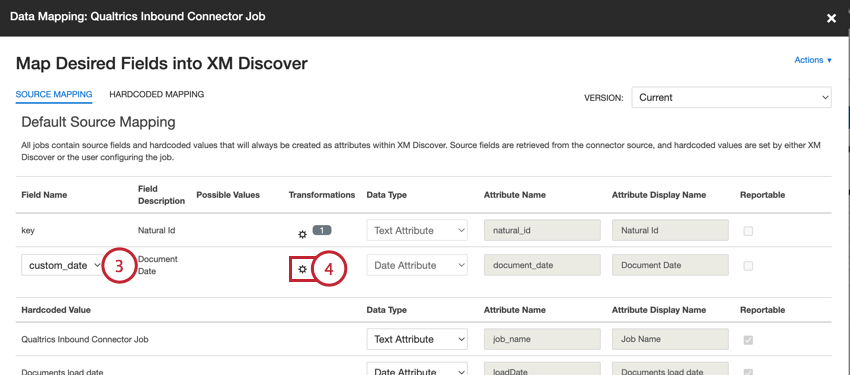
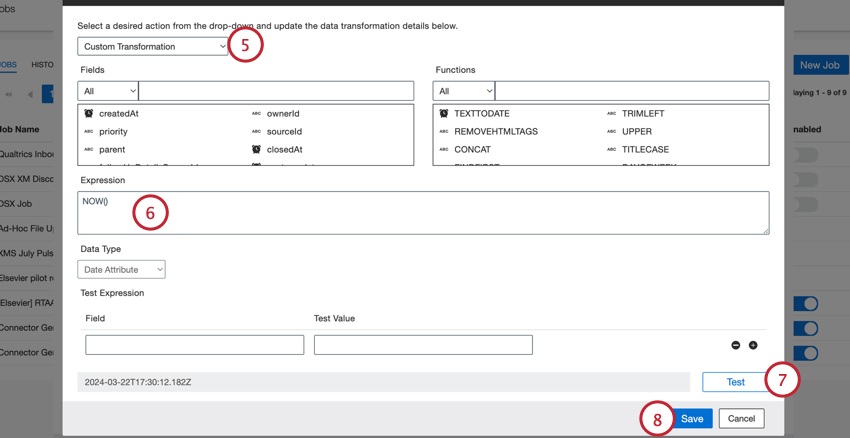
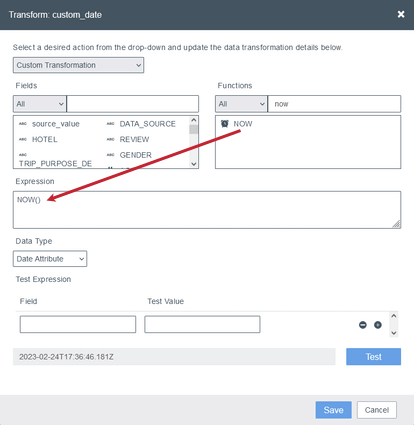
- ロード時間を使用します:文書がXM Discoverにアップロードされた日付を使用するには、[関数]セクションから[式]ボックスにNOW()関数をドラッグします。
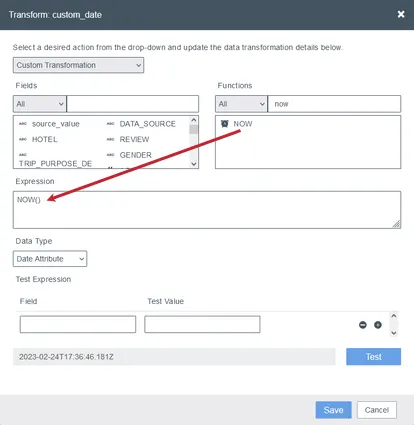
- ハードコードされた値を使用します:特定の日付を使用するには、FunctionsセクションからTEXTTODATE()関数をExpressionボックスにドラッグし、括弧内に日付と日付形式を指定します。
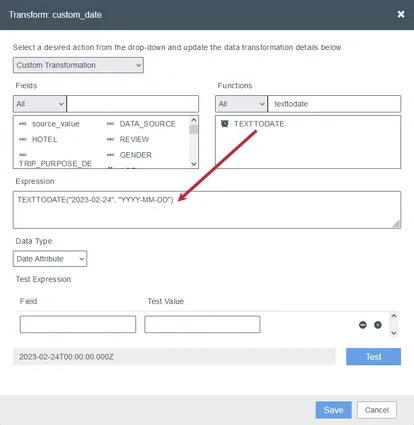 Qtip:いずれの場合も、結果の日付はYYYY-MM-DDThh:mm:ssZのフォーマットを使用します。
Qtip:いずれの場合も、結果の日付はYYYY-MM-DDThh:mm:ssZのフォーマットを使用します。
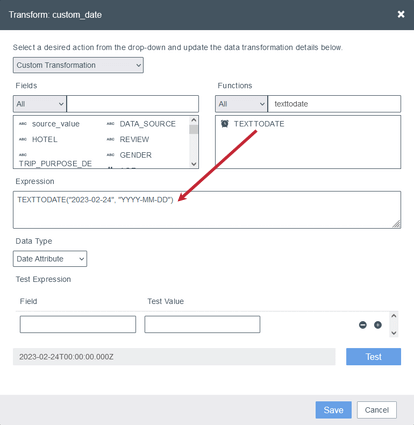
Qtip:適用をクリックしてデータマッピングを保存してください。
カスタム変換の例
このセクションでは、カスタム変換を使用してデータを操作する方法の例をいくつか取り上げます。
カスタムソース値の割り当て
目標:「元のアンケート」属性にカスタムテキスト値(「4月アンケート調査」)を割り当てる。
どのようにソース」フィールドに以下の変換を適用する(テキスト値を引用符で囲むだけ):
例:“4月アンケート調査”
“姓,名 “を “名,姓 “に変更
目標:名前の書式を “姓,名 “から “名,名 “に変更し、すべての単語の頭文字を大文字にする。
どのように:
PROPERCASE(REPLACEBYREGEXP(NAME, “(.*),(.*)”, “$2 $1”))。
例: “harris,george “は “George Harris “となります。
日付のUTCからCSTへの変換
タイミング:日付フィールドをUTCタイムゾーンからCSTタイムゾーンに変換する。
どのように:次の変換をEND_DATEフィールドに適用する:
CONVERT_TO_TIMEZONE(END_DATE, “Etc/UTC”, “America/Chicago”)
例: 「2021-03-11 15:15:00」(ロンドン時間)は「2021-03-11T09:15:00Z」(シカゴ時間)になります。
Qtip:日付フィールドがUnixエポックタイムで指定されている場合、まずISO 8601フォーマットに変換する必要があります。
hh:mm:ssを分に変換する
ゴール:時間をhh:mm:ss形式から分単位に変換する。
どのように:次の変換を適用:
GETMINUTESBETWEEN(TEXTTODATE(“1970-01-01”, “YYYY-MM-DD”), CONCAT(“1970-01-01T”, MY_TIME))
例:12時12分30秒は732.5となる。
秒単位のUnixエポックタイムをISO 8601に変換する
目的:Unixのエポック・タイムスタンプ(秒)をISO 8601の日付フォーマットに変換する。
Qtip:日付がミリ秒単位の数値(1588253075000など)であれば、変換せずに日付フィールドとして使用できます。それを日付属性としてマッピングすればうまくいく。ただし、タイムゾーンを変更する必要がある場合は、まずISO 8601に変換する必要がある。
秒をミリ秒に変換し、ミリ秒を ISO 8601 日付に変換します。
NUMBERTODATE(TEXTTONUMBER(CONCAT(MY_DATE, “000”)))
例:1588253075は2020-04-30T13:24:35.000Zとなる。
何かが配列の中にあるかどうかに基づいて値を導出する
ゴール:州名をチェックし、リストされた州のいずれかに一致する場合は、「DMVエリア」の値を割り当てる。それ以外は “その他の州 “とする。
どのようにAREAというカスタム・テキストフィールドを追加し、以下の変換を適用する。
IF(LOWER(STATE) in [“md”, “dc”, “va”], “DMV Area”, “Other States”)
Qtip:LOWER関数を使うことで、この条件は大文字と小文字を区別しないので、この場合は “dc “と “DC “の両方がtrueとしてカウントされることに注意。
例: STATE=”MD “はAREA=”DMV Area “になります。
ページタイトルから記事名を抽出する
目的:ページタイトルの最後の「|」の区切り線の後にある記事名を抽出する。
どのように:次の変換をページ・タイトル・フィールドに適用する:
TRIMRIGHT(MID(PAGE_TITLE,FINDLAST(PAGE_TITLE,”|”)+1,1000))
例: “news|world|記事名” は “記事名” となる。
姓と名を1つのフィールド名に結合する
目標:FIRST_NAMEフィールドとLAST_NAMEフィールドを新しいFULL_NAMEフィールドに統合し、すべての単語の最初の文字を大文字にする。
どのようにFULL_NAMEというカスタム・テキスト・フィールドを適用し、以下の変換を適用する:
PROPERCASE(CONCAT(FIRST_NAME, ” “, LAST_NAME))
例: FIRST_NAME=”paul” LAST_NAME=”jones” は FULL_NAME=”Paul Jones” になります。
2つのVerbatimを結合し、結合したVerbatimのみをロードする。
目的:2つの逐語訳フィールドVERBATIM1とVERBATIM2を新しいVERBATIM3フィールドに結合し、結合された逐語訳のみをXM Discoverにロードする。
どのように以下のステップを実行してください:
例: VERBATIM1=”部屋は居心地が良かった。”とVERBATIM2=”ルームサービスは良かった。”はVERBATIM3=”部屋は居心地が良かった。”になります。ルームサービスは良かった。
多変数ロールアップ
目標:1つの質問に対する回答が複数の属性にまたがっている場合、複数変数のロールアップを作成する。データセットに複数の「yesかno」属性があり、顧客のメンバーシップのレベルが異なるとする:
- QID2_1 シルバー用
- QID2_2 ゴールド用
- QID2_3 プラチナ用
すべての「はい」回答を1つの新しい属性にまとめて、顧客のメンバーシップ・レベルを示すことができます。
どのように:以下の変換を適用:
TRIMRIGHT(CONCAT(IF(QID2_1==”Yes”, “Silver”, “”), IF(QID2_2==”Yes”, “Gold”, “”), IF(QID2_3==”Yes”, “Platinum”, “”)))
例: QID2_1=”No”、QID2_2=”Yes”、QID2_3=”No “は、LOYALTY_LEVEL=”Gold “となる。
先頭文字の削除
目的:文字列の最初の文字を削除する。
どのように:次の変換を適用する:
REPLACEBYINDEX(MY_NUMBER, 1, 1, “”)
例: “x00085524821587582371 “は “00085524821587582371 “となります。
先頭のゼロを取り除く
目的:数値の先頭のゼロを取り除く。
どのように:
CONCAT(TEXTTONUMBER(MY_NUMBER), “”)
数値の場合、次の変換を適用する。
TEXTTONUMBER(MY_NUMBER)
例: 「000123456 “は “123456 “になります。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!