The Confusion Matrix & Precision-Recall Tradeoff
Was finden Sie hier?
Die Matrix und das Präzisionsrückrufdiagramm helfen Ihnen dabei, die Genauigkeit Ihres Modells zu beurteilen.
Konfusionsmatrix
Nehmen wir an, Sie überlegen, Kunden, die wahrscheinlich zurückkehren, einen zusätzlichen Zuckerwürfel zu geben. Aber natürlich möchten Sie vermeiden, Zuckerwürfel unnötig auszugeben, also geben Sie sie nur Kunden, die laut Modell mindestens 30 % wahrscheinlich zurückkehren.
Wenn Sie einige neue Kunden spazieren …
| CustomerID | Alter | Geschlecht |
|---|---|---|
| … | … | … |
| 324 | 54 | Weiblich |
| 325 | 23 | Weiblich |
| 326 | 62 | Männlich |
| 327 | 15 | Weiblich |
| … | … | … |
… könnten Sie unser Regressionsmodell verwenden, um vorherzusagen, wie wahrscheinlich es wäre, dass sie zurückkehren…
| CustomerID | Alter | Geschlecht | Geschätzte Rücknahmewahrscheinlichkeit des Modells |
|---|---|---|---|
| … | … | … | … |
| 324 | 54 | Weiblich | 34 % |
| 325 | 23 | Weiblich | 24 % |
| 326 | 62 | Männlich | 65% |
| 327 | 15 | Weiblich | 7 % |
| … | … | … | … |
… und entscheiden, Kunden mit einer Wahrscheinlichkeit von mindestens 30 % als “Will return” zu klassifizieren und ihnen Zuckerwürfel zu geben:
| CustomerID | Alter | Geschlecht | Geschätzte Rücknahmewahrscheinlichkeit des Modells | Modellprognose (30 % Cut-Off) |
|---|---|---|---|---|
| … | … | … | … | … |
| 324 | 54 | Weiblich | 34 % | Wird zurückgeben |
| 325 | 23 | Weiblich | 24 % | Won’t |
| 326 | 62 | Männlich | 65 % | Wird zurückgeben |
| 327 | 15 | Weiblich | 7 % | Won’t |
| … | … | … | … | … |
Um besser zu verstehen, wie genau unser Modell ist, können Sie das Modell jedoch auf die Datenpunkte übernehmen, die Sie bereits haben, wo Sie bereits wissen, ob der Kunde schließlich zurückgesendet hat…
| CustomerID | Alter | Geschlecht | Geschätzte Rücknahmewahrscheinlichkeit des Modells | Modellprognose (30 % Cut-Off) | Zurückgegeben |
|---|---|---|---|---|---|
| 1 | 21 | Männlich | 44 % | Wird zurückgeben | Zurückgegeben |
| 2 | 34 | Weiblich | 4 % | Won’t | Zurückgegeben |
| 3 | 13 | Weiblich | 65 % | Wird zurückgeben | War nicht |
| 4 | 25 | Weiblich | 27 % | Won’t | War nicht |
| … | … | … | … | … | … |
… und bewerten Sie, wie genau die Daten sind…
| CustomerID | Alter | Geschlecht | Geschätzte Rücknahmewahrscheinlichkeit des Modells | Modellprognose (30 % Cut-Off) | Zurückgegeben | Prognosegenauigkeit |
|---|---|---|---|---|---|---|
| 1 | 21 | Männlich | 44 % | Wird zurückgeben | Zurückgegeben | Korrekt |
| 2 | 34 | Weiblich | 4 % | Won’t | Zurückgegeben | Fehlerhaft |
| 3 | 13 | Weiblich | 65 % | Wird zurückgeben | War nicht | Fehlerhaft |
| 4 | 25 | Weiblich | 27 % | Won’t | War nicht | Korrekt |
| … | … | … | … | … | … | … |
… und dann weiter in die folgenden Kategorien unterteilen:
- Richtig positiv: Klassifiziert vom Modell als “Will return” und hatte tatsächlich “Returned” in der Realität.
- Falsch positiv: Klassifiziert vom Modell als “Will return”, aber tatsächlich “Didn’t return” in der Realität.
- Richtig negativ: Klassifiziert vom Modell als “Won’t return” und tatsächlich “Didn’t return” in der Realität.
- Falsch negativ: Vom Modell als “Won’t return” klassifiziert, aber tatsächlich “Returned” in der Realität.
| CustomerID | Alter | Geschlecht | Geschätzte Rücknahmewahrscheinlichkeit des Modells | Modellprognose (30 % Cut-Off) | Zurückgegeben | Prognosegenauigkeit | Genauigkeitstyp |
|---|---|---|---|---|---|---|---|
| 1 | 21 | Männlich | 44 | Wird zurückgeben | Zurückgegeben | Korrekt | Richtig positiv |
| 2 | 34 | Weiblich | .04 | Won’t | Zurückgegeben | Fehlerhaft | Falsch negativ |
| 3 | 13 | Weiblich | 65 | Wird zurückgeben | War nicht | Fehlerhaft | Falsch positiv |
| 4 | 25 | Weiblich | .27 | Won’t | War nicht | Korrekt | Richtig negativ |
| … | … | … | … | … | … | … | … |
Schließlich könnten Sie all diese Arbeit in Präzision und Erinnerung zusammenfassen.
Genauigkeit:
- Von denen, die als “Will return” eingestuft sind, welcher Anteil hat eigentlich getan?
- Richtig positiv / (Wahr positiv + Falsch positiv)
Rückruf:
- Erinnern: Von denen, die tatsächlich “zurückgekehrt” waren, welcher Anteil wurde so eingestuft?
- Richtig positiv / (Wahr positiv + Falsch negativ)
Bessere Modelle haben höhere Werte für Präzision und Rückruf.
- Sie können sich ein Modell mit 94 % Präzision (fast alle als “Will return” do in der Tat identifiziert) und 97 % Rückruf (fast alle, die “zurückgegeben” wurden als solche identifiziert) vorstellen.
- Ein schwächeres Modell kann 95 % Präzision haben, aber 50 % erinnern sich (wenn es jemanden als “Will return” identifiziert, ist es weitgehend korrekt, aber es kennzeichnet falsch “Won’t return” die Hälfte derjenigen, die tatsächlich später “Return” getan haben).
- Oder vielleicht hat das Modell 60% Präzision und 60% Rückruf.
Diese Zahlen sollten Ihnen einen guten Eindruck davon vermitteln, wie genau Ihr Modell ist, auch wenn Sie nie tatsächlich Vorhersagen treffen möchten.
Präzision vs. Rückrufkurve
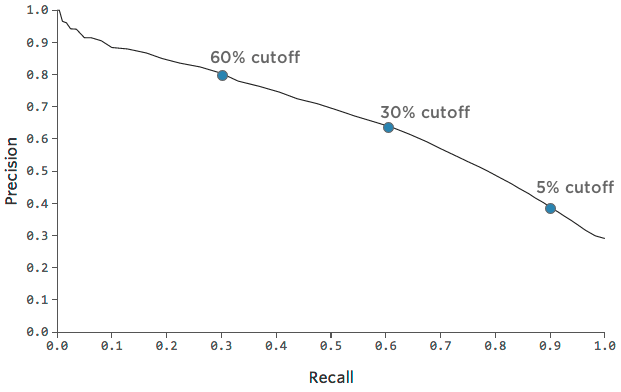
Innerhalb eines Modells können Sie auch entscheiden, ob Sie die Genauigkeit oder den Rückruf hervorheben möchten. Vielleicht sind Sie sehr kurz mit Zuckerwürfeln und möchten sie nur Leuten ausgeben, die Sie sehr zuversichtlich sind, werden zurückkehren, also entscheiden Sie, sie nur Kunden zu geben, die wahrscheinlich 60 % zurückkehren (statt 30 %).
Unsere Präzision wird steigen, weil du nur dann Zuckerwürfel aushändigst, wenn du wirklich zuversichtlich bist, dass jemand zurückkehrt. Unser Rückruf wird untergehen, weil es viele Leute geben wird, die letztendlich “zurückkehren”, denen Sie nicht zuversichtlich genug waren, einen Zuckerwürfel zu geben.
Präzision: 62% —> 80%
Rückruf: 60% —> 30%
Oder, wenn Sie sich reich an Zuckerwürfeln fühlen, können Sie sie jedem geben, der mindestens 10 % Chance hat, ein Rückkehrer zu sein.
Präzision: 62% —> 40%
Rückruf: 60% —> 90%
Sie können diesen Kompromiss zwischen Präzision und Rückruf mit diesem Diagramm verfolgen:
{kind=link}
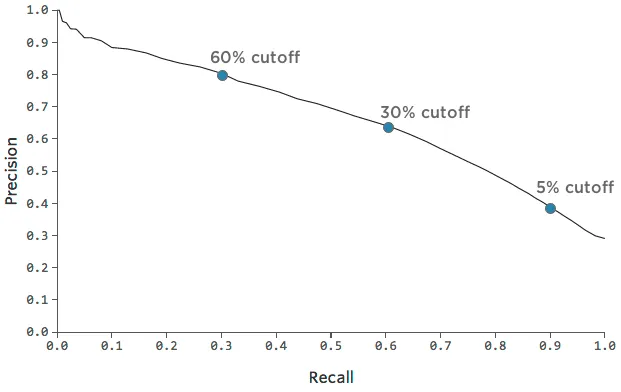
Es kann hilfreich sein, einen Punkt im Diagramm auszuwählen, der eine schöne Mischung aus Präzision und Rückruf darstellt, und dann ein Gefühl dafür zu bekommen, wie genau das Modell an diesem Punkt ist.
FAQs
Wie erstelle ich eine neue Stats iQ-Variable?
Wie erstelle ich eine neue Stats iQ-Variable?
Welche Optionen gibt es für die Analyse meiner Daten in Stats iQ?
Welche Optionen gibt es für die Analyse meiner Daten in Stats iQ?
- Beschreiben: Wenn Sie eine Variable aus der Liste auswählen und dann auf Beschreiben klicken, erhalten Sie eine Visualisierung der in dieser Variablen enthaltenen Daten. Verwenden Sie diese Option, wenn Sie sehen möchten, wie die Daten für eine bestimmte Variable verteilt werden.
- Verknüpfen: Wenn Sie zwei Variablen auswählen und dann auf Verknüpfen klicken, wird eine statistische Analyse der Beziehung zwischen den beiden Variablen ausgeführt. Verwenden Sie diese Option, wenn Sie wissen möchten, wie stark zwei Variablen korrelieren.
- Pivot-Tabelle: Wenn Sie zwei oder mehr Variablen auswählen und auf Pivot-Tabelle klicken, wird eine Tabelle erstellt, in der die Werte der Variablen als Zeilen und Spalten angezeigt werden. Die Zellen können so eingestellt werden, dass eine Vielzahl verschiedener Informationen angezeigt werden, einschließlich Spalten- und Zeilenprozentsatz, Summe und Abweichung. Verwenden Sie diese Option, wenn Sie die Überlappung bestimmter Werte eines Variablensatzes vergleichen möchten.
- Regression: Wenn Sie zwei Variablen auswählen und auf Regression klicken, wird die mathematische Beziehung zwischen den Variablen hergestellt. Verwenden Sie diese Option, wenn Sie Werte für eine Variable basierend auf den Werten einer anderen prognostizieren möchten.
- Cluster: Wenn Sie zwei bis zehn demografische Variablen auswählen und auf Cluster klicken, werden Gruppierungen von Merkmalen angezeigt, die am wahrscheinlichsten zusammen auftreten. Auf diese Weise werden die in Ihren Daten erfassten Populationssegmente angezeigt.
Ich weiß nicht, was dieser statistische Begriff bedeutet. Können Sie es mir sagen?
Ich weiß nicht, was dieser statistische Begriff bedeutet. Können Sie es mir sagen?
- Statistische Tests: ANOVA, T-Test und Chi-Quadrat sind alle statistischen Tests, die Stats iQ durchführt, um zu prüfen, ob die Beziehung zwischen zwei Variablen signifikant ist. Diese Tests werden verwendet, um einen P-Wert zu generieren.
- P-Wert: Dieser Wert gibt die Wahrscheinlichkeit an, dass die beobachteten Ergebnisse angezeigt werden, wenn keine Korrelation zwischen den Variablen vorhanden ist. Ein niedrigerer P-Wert bedeutet mehr korrelierte Daten.
- Effektgröße: Die Effektgröße ist ein Maß dafür, wie groß die Korrelation zwischen zwei Variablen ist. Dies wird je nach Art des durchgeführten statistischen Tests unterschiedlich gemessen. Beispiele sind Cohen’s d, Pearson’s r und Cramer’s v. Je größer der Wert der Effektgröße, desto korrelierender sind die Variablen.
Wie filtere ich die Daten, die in Stats iQ angezeigt werden?
Wie filtere ich die Daten, die in Stats iQ angezeigt werden?
Wie kann ich meine neuen Antworten in Stats iQ anzeigen?
Wie kann ich meine neuen Antworten in Stats iQ anzeigen?
Wie werden Analysekarten in meinem Stats iQ-Arbeitsbereich bestellt?
Wie werden Analysekarten in meinem Stats iQ-Arbeitsbereich bestellt?
Was ist Stats iQ? / Wo ist Statwing?
Was ist Stats iQ? / Wo ist Statwing?
Was mache ich, wenn meine Daten nicht ordnungsgemäß geladen werden?
Was mache ich, wenn meine Daten nicht ordnungsgemäß geladen werden?
Großartig! Vielen Dank für die Rückmeldung!
Vielen Dank für die Rückmeldung!