Rスクリプト
このページの内容
注意: すべてのStats iQユーザーがアクセスできる機能ではありません。この機能にご興味のある方は、営業担当までご連絡ください。
Rスクリプトについて
Rは、柔軟で強力な分析のために広く使用されている統計プログラミング言語です。Stats iQのRコーディングでは、複数の分析スクリプトから選択することができ、Rをより簡単かつ効率的に使用することができます。
Rコード用スクリプトの選択
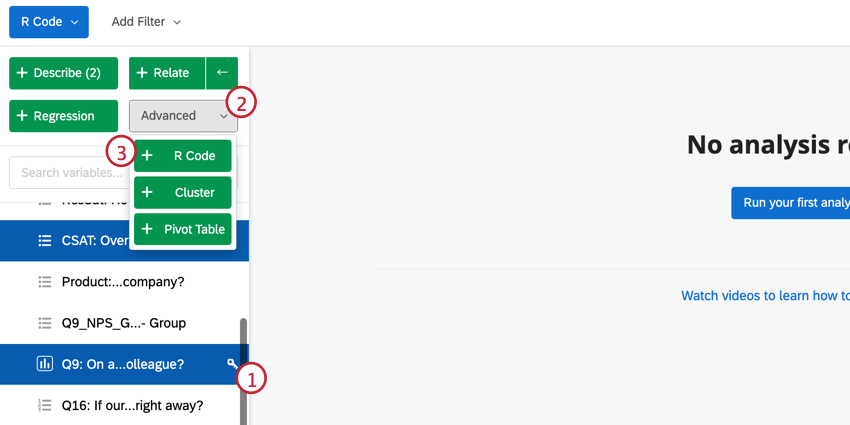
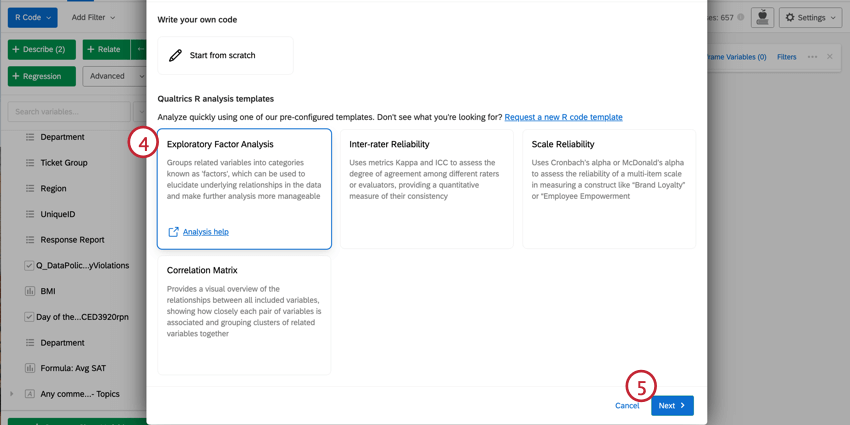
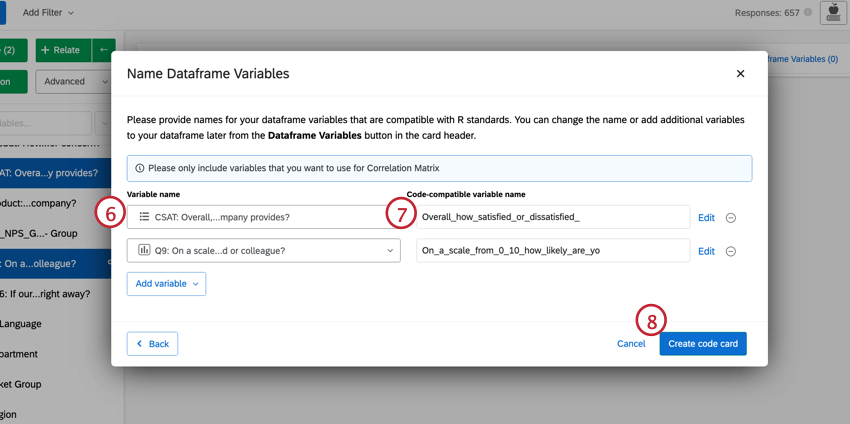
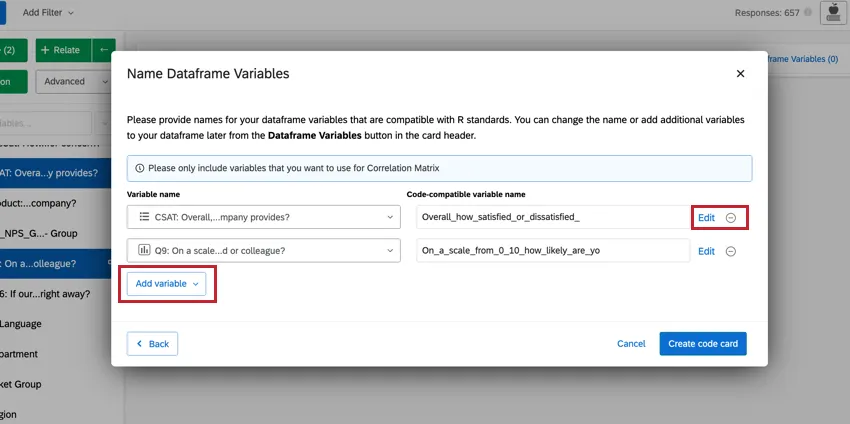
Qtip: このウィンドウから、選択した変数を直接変更することができます。識別値を割り当て編集するには、Editをクリックします。変数を削除したい場合は、(-)アイコンをクリックします。新しい変数を追加したい場合は、左下のAdd variableをクリックする。
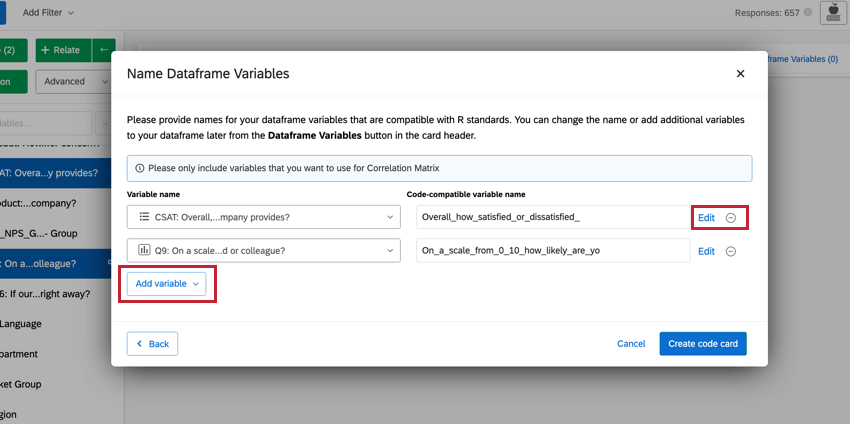
構成済みRコードスクリプトのナビゲーション
あなたのスクリプトは、Rコードカードのコードセクションに貼り付けられます。このコードには、選択した分析を生成するためのコマンドとともにアドバイスが含まれている。分析を実行するには、Run Allをクリックします。結果は右側の出力ボックスに表示されます。
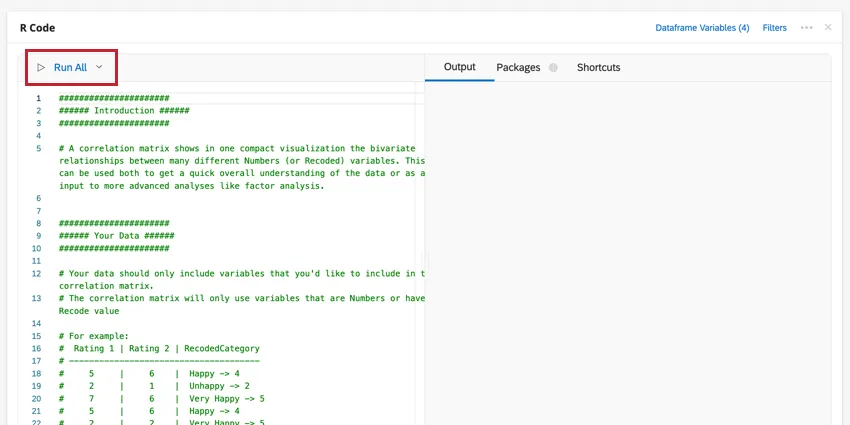
右上のオプションをクリックすると、データフレームの変数を編集したり、分析にフィルタを追加することができます。三点メニューをクリックすると、コードカードにメモを追加したり、分析結果をコピーしたり、フルスクリーンでカードを開くことができます。
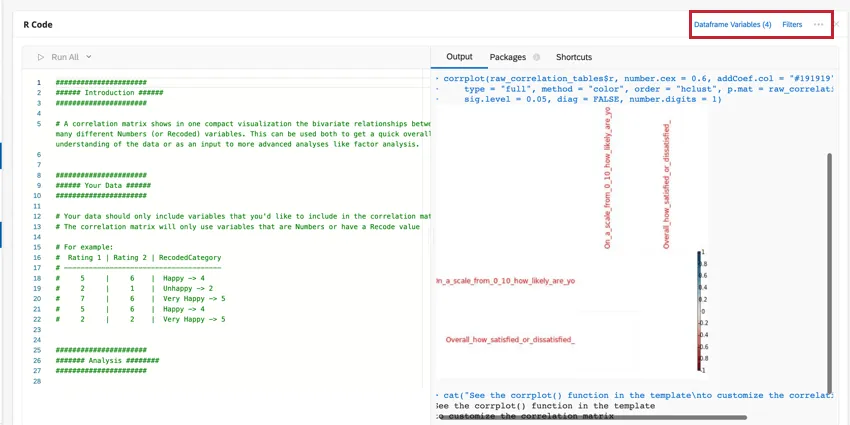
ショートカット
キーボードショートカットを使えば、Rコードカードをより効率的に操作できる。ショートカットを クリックすると、可能なアクションのリストが表示されます。
パッケージ
Stats iQのRコーディングには、分析に使用される数百もの最も一般的なRパッケージがプリインストールされています。カードの右半分にある「パッケージ」タブをクリックすると、利用可能なパッケージのリストが表示されます。パッケージの使用に関する詳細は、 Stats iQのRコーディング を参照してください。
尺度の信頼性
尺度の信頼性は、多項目尺度の項目が構成要素をどの程度確実に測定できるかをアセスメントします。言い換えれば、同じ質問を用いて同じことを測定した場合、確実に同じような結果が出るのだろうか?そうであれば、今後見られる変化は、アンケート調査対象者の変化やスコア向上のための介入によるものだと確信できる。
信頼性尺度の解釈
尺度の信頼性の尺度は0から1の間で、基本的には尺度の全項目間の相関を集約したものである。
信頼性の尺度として広く用いられているクロンバックのアルファは、ある仮定により信頼性を過小評価することが多い。マクドナルドのオメガは、こうした欠点を回避している。私たちはデフォルトでマクドナルドのオメガを使っているが、クロンバックのアルファは今でも広く受け入れられている。
結果の数字を解釈する唯一の正しい方法はないが、オメガの経験則を以下に示す:
| 0.65未満 | 非常に不満足 |
| 0.65 | 可 |
| 0.8 | とてもよい |
信頼できるスケールが受け入れられない場合、データセットを改善するためのいくつかのオプションがあります:
- オメガやアルファを下げているものを取り除く。
- 2つの異なる構成要素が測定されている可能性がある。もしそうであれば、変数を2つのグループに分け、それぞれについてこの分析を実行すれば、最初の分析よりも高い信頼性スコアが得られるだろう。出力の相関マトリックスを評価するか、探索型因子分析スクリプトを使用して、データからどのようなグループ分けが自然に出てくるかを見ることによって、これを探索することができます。
- 最終的には、アンケートを修正して再度実施する必要があるかもしれません。他の項目との相関が低い項目は、明確化または再作業が必要かもしれないし、他の項目を追加する必要があるかもしれない。
非常に高い結果(例えば0.95)は、尺度に問題があることを示すこともあり、通常は、項目数がそれほど多くなくても、信頼性の高い尺度ができる可能性があります。このような場合は、尺度から有用性の低い項目を削除し、分析を再実行することをお勧めします。
項目レベルの統計の解釈
スクリプトは、まず全体的な信頼性測定を実行し、次に各変数について1回の反復を実行する。項目ごとの信頼性分析の目的は、どの項目が尺度の構築に最も役立つかを理解することである。Stats iqは以下のような表を出力する。
マクドナルド総合オメガ:0.71
| N | 平均 | 項目-全体相関 | マクドナルド・オメガ(撤去された場合 | |
| A1 | 2784 | 4.59 | 0.31 | 0.72 |
| A2 | 2773 | 4.80 | 0.56 | 0.69 |
| A3 | 2774 | 4.60 | 0.59 | 0.61 |
| … | … | … | … | … |
- 一般的な目標は、より少ないアイテム数でより高いマクドナルド・オメガを持つことである。つまり、もし研究者が新しい尺度を作るとしたら、A1を外した方がオメガ値が高くなるからだ。
- 取り除くと信頼性が低下する項目のRESTは、研究者の判断に委ねられる。例えば、アンケート調査の疲労を懸念している場合、変数の削除を決定する際に、信頼性の低下をより大きく許容するかもしれません。
- 項目-全体相関は、その項目と他のすべての項目の平均との相関である。項目-全体相関が低いということは、その変数が基礎となる構成要素を十分に代表していないことを示唆する。最も一般的な経験則では、項目-総相関が0.3以下のものは疑ってかかるべきであり、特に項目数が多い場合は信頼性指標が人為的に膨れ上がる。
項目を削除する場合は、他の項目を削除するかどうかを決定する前に、他のすべての統計を再実行する必要があります。Stats iqでは、これはカード全体から変数を取り除くことを意味し、残りは自動的に行われます。
項目間相関マトリックス
項目間相関マトリックスは、分析の各変数と他の各変数との相関を示す。例えば、ある変数が他の変数と非常に高い相関がある場合(例えば0.9)、それらの質問は冗長である可能性があり、それらを削除しても信頼性に与える影響はわずかです。
平均項目間相関は、マトリックスの数値の平均である。数値が高いほど、冗長な項目があり、削除できる可能性があることを示唆している。一般的に、変数は0.2~0.4の範囲にあるべきである。
Qtip: 平均項目間相関は、全体的な信頼性スコアに関する有用な情報を提供します。例えば、項目数が少なく(例えば3項目)、信頼性スコアが低く、平均項目間相関が高い場合、項目間の相関がないというより、項目数が少ないことが原因である可能性があります。
その他のリソース
- Stats iqの信頼性分析は、semTools RパッケージのcompRelSem()関数によって実行されます。様々な高度な設定については、ドキュメントに記載されている。信頼性分析を実行するために、これらの設定を使用したり理解したりする必要はない。
- 相関マトリックスはcorrplot Rパッケージのcorrplot()関数で実行される。様々な高度な設定やカスタマイズについては、ドキュメントやこのウォークスルーで説明されている。
評価者間信頼性
評価者間信頼性(IRR)は、2人以上の評価者がその評価にどの程度同意するかを評価するために用いられる。たとえば、3人の異なるコーダーが、あるテキストコメントを肯定的、中立的、否定的な感情を持っているとアセスメントするかもしれない。
評価者間信頼性の尺度
IRRは、データの構造に基づいてわずかに異なる指標を用いて評価される。例えば、2人の評価者の相互信頼性を分析する場合、3人の評価者の相互信頼性とは若干異なる評価尺度を用いることになる。
Stats iqは、データに適した測定基準を自動的に選択します。
結果の解釈
KappaまたはICC指標は、0から1の間の主な出力であり、評価者がどの程度ウェルビーイングであるかを示す。Kappaの解釈については、以下の範囲を推奨する:
| 0.75対1 | 優れている |
| 0.6から0.75 | 良好 |
| 0.4 から 0.6 | まあよい |
| 0.4以下 | 不良 |
その他のリソース
- この信頼性分析は、IRR Rパッケージの関数によって実行される。様々な高度な設定については、ドキュメントに記載されている。この分析を実行するために、これらの設定を使用したり理解したりする必要はない。
探索的因子分析
探索型因子分析(EFA)は、多数の変数をより小さく、より管理しやすい要約「因子」の集合に減らすのを助ける統計的手法である。これにより、解釈、コミュニケーション、さらなる分析(回帰分析など)が格段に容易になる。EFAは通常、このようなステップを踏む:
結果は、名前付き因子とその構成アンケート調査項目のセットである。これらの要因は、さらなる分析のための概念的枠組みとして機能したり、データに遡って適用することができる。
例: 私の部屋は清潔だった」、「ホテルの他の部分は清潔だった」、「私の部屋には必要なものがすべて揃っていた」という項目が同じ因子にある場合、これらの項目を平均し、「部屋の質」という概要レポートで報告することができます。
ダイアグノスティックス
スクリプトはまず、データがEFAに適しているかどうかを確認するために一連の診断を実行する:
- サンプルサイズ:一般的に、項目に対する回答の比率は 10:1 を推奨する。例えば、10個の質問がある場合、少なくとも100人の回答者が必要です。
- バートレットの球形性の検定.この検定は,項目が有用に因子にグループ化されるのに十分な相関があるかどうかを評価する.これに失敗した場合、他の項目との相関が十分でない項目がいくつかある可能性が高い。相関関係のない項目を分析から除外したり、関連する項目をアンケートに追加したりすることもできます。
- 決定基:決定因子は,項目が因子に有用にグループ化されるには相関が高すぎるかどうかを評価する.この診断に失敗した場合、要因に分けるには互いに類似しすぎている項目がある可能性が高い。アンケート調査項目をより明確に編集することを検討する。
- カイザー・マイヤー・オルキン (KMO) 測定: この測定は、アンケート調査項目が意味のある要因にグループ化するのに十分な共通点があるかどうかをチェックします。この診断に合格するということは、アンケートの回答には多くの共通点があり、うまくグループ化できるということです。そうでなければ、項目はカテゴリーにクラスタ化されない。この診断に失敗した場合は、より類似したテーマを把握できるようにアンケート調査項目を修正し、他の項目との関係が明確でない項目を削除することを検討するとよいでしょう。
要因の選択
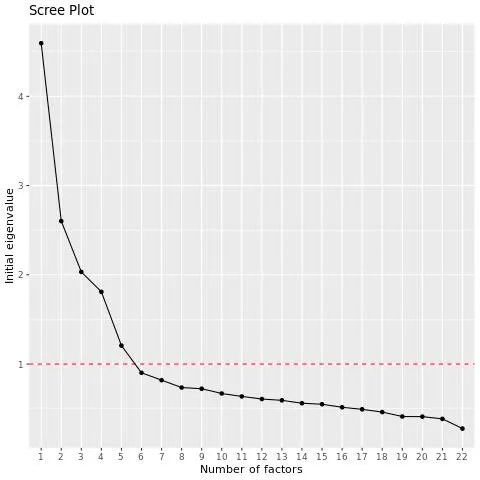
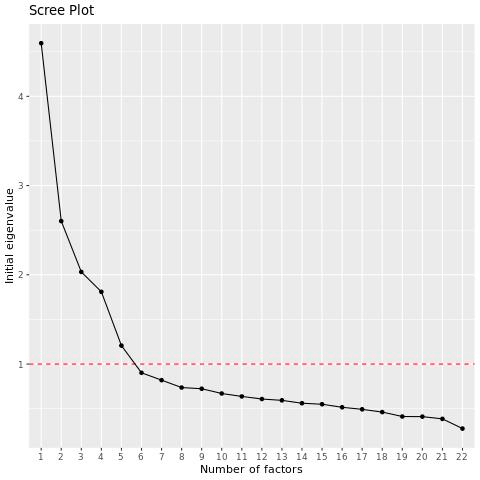
EFAのポイントは、多くの変数を分析に有用な比較的少数の変数に絞り込むことなので、自分に合ったグループ分けを見つけるために、因子の数を変えて何度か因子分析を実行する必要があるかもしれません。EFAスクリプトは、それらの固有値を使用して因子の数を示唆する。
Qtip: 固有値は,因子と変数の間のr2乗値を合計することによって,因子が作成された元の変数と相関する度合いを測定する.例えば、因子とQ1のr2乗が0.8、因子とQ2のr2乗が0.5の場合、固有値は1.3となる。一般に、固有値が1以上の因子を使用すべきである。EFAスクリプトは、このベンチマークを使って因子の数を提案する。
EFAスクリプトは、変数の固有値を降順に示すscreeプロットを出力する。チャートの “エルボー “の前にいくつのファクターが発生するかは、チャートで調べることができる。
例: この例では、4番目の変数の後に大きな落ち込みがあり、5番目の変数の後にさらに大きな落ち込みがある。デフォルトでは、スクリプトはここで5つの因子を使用しますが、4つの因子でも実行し、結果を比較するとよいでしょう。
{kind=link}
{kind=link}
{kind=link}
要因の命名
EFAを実行した後、各変数を因子に割り当てる。各要因に名前をつけておくと、その要因について話すときの略語になり、調査結果をよりアクセシビリティの高いものにすることができる。ここでのテーマは、複雑なデータを理解しやすいいくつかのテーマに単純化することである。
以下は、ファクターの命名に関するガイドラインである:
- 記述的であること:グループ内の変数を要約する共通のテーマを捉えるようにする。
- シンプルに:ファクター名はわかりやすく、コミュニケーションしやすいものでなければならない。専門用語や複雑すぎる言い回しは避ける。
- 読者を考慮する:因子名は、あなたの分析を使う人々にとって意味のあるものでなければなりません。例えば、「清潔さ」はホテルのマネージャーにとっても、宿泊客にとっても意味のあることだろう。
- 一貫性:アンケート調査やデータセットが異なるドメインや被評価者にまたがる場合は、因子名に一貫性を持たせてください。
関連指標および測定基準
因子負荷量表は、EFAの重要なアウトプットの1つである。与えられた変数-因子の組の因子負荷は、その変数と因子の間の相関である。変数がある因子に対して高い因子負荷を持っている場合、その質問はその因子に強く結びついていることを意味する。
一意性とは、特定の変数に固有で、他の変数と共有されない分散の部分である。一意性の値は、0 から 1 の範囲で、より高い値は、変数が一意であり、どの要因にもうまく適合しないことを示す。.
一般に、因子負荷量が0.3以上、または一意性が0.7以上の場合は、変数を除去することが推奨されます。
結果の活用
因子分析は反復プロセスなので、自分に合ったグループ分けを見つけるために、因子の数を変えて何度か実行する必要があるかもしれない。ほとんどの研究者にとって、キーとなる収穫は、データに新しいインサイトを提供できる要因のグループ分けを見つけることですが、回帰分析やクラスタ分析など、その後の分析でこれらの要因を新しい変数として使用することができます。 例えば、ITにグループ化されたすべての変数の平均値を取る新しい変数を、各要因ごとに作成することができます。
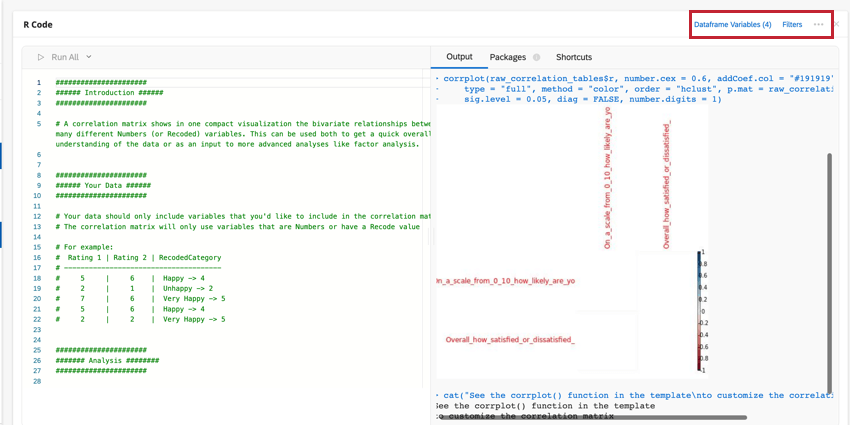
相関関係マトリックス
相関マトリックスは、提供された変数の各組間の相関を示す表である。この表はデフォルトでピアソンのrを使って相関を測定しているが、必要ならスピアマンのrhoに変更することもできる。
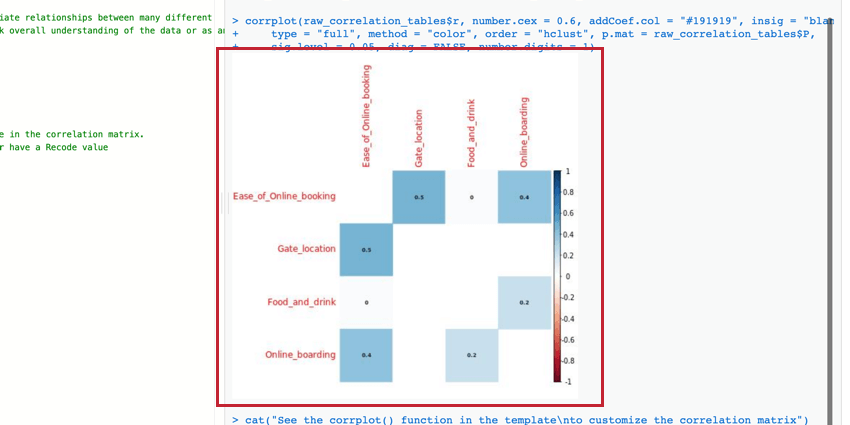{kind=link}
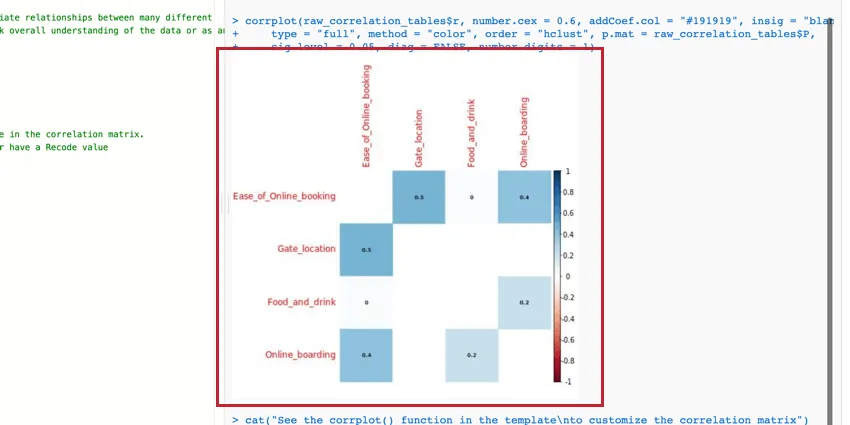
corrplot()関数のパラメータを編集して表を修正し、読みやすくすることができる。詳しくは、Rの公式チュートリアルとドキュメントをご覧ください。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!