
Synthetic research works when the data it produces holds up to the same analytical scrutiny as human panel data. When it doesn't, teams make decisions with false confidence — and that gap between what the data appears to show and what it can actually support has real consequences for the business outcomes they're trying to drive.
At Qualtrics, we intentionally built our foundational synthetic model to hold up under rigorous statistical scrutiny. Understanding why that matters requires looking at how most synthetic research tools are built today, and where their underlying architecture limits what they can deliver.
Where general-purpose AI models fall short in synthetic research
A general-purpose LLM generates responses by predicting what text is most probable given a particular input. When you ask one to simulate a respondent ("respond like a 28-year-old who works in manufacturing in the midwest"), it produces answers that reflect cultural patterns and linguistic norms baked into its training data, largely derived from the internet. For early hypothesis generation, that can be genuinely useful.
The problem surfaces when researchers attempt to use that output for quantitative analysis. Real survey populations produce data with natural variance — inconsistencies between stated and derived preferences, non-linear response patterns, the distributional noise that reflects how humans actually make decisions under uncertainty.
General-purpose models flatten that variance. Responses cluster around what the persona "typically" believes rather than distributing the way a real sample would. Run those outputs through factor analysis, clustering, or key drivers analysis and the data often lacks the structural integrity those methods require.
There are techniques researchers can use to work around the limitations of a general-purpose model, and understanding the differences between them helps explain why the outputs vary so significantly across tools in the market today.
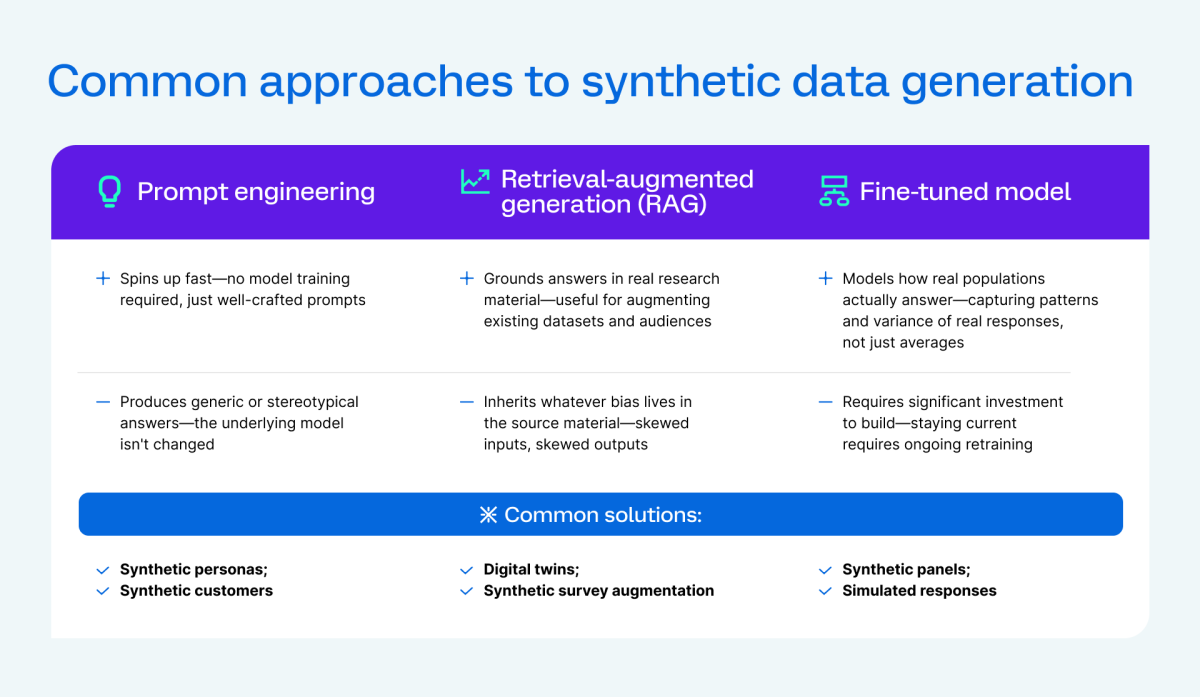
Common approaches to synthetic data generation
Most products on the market today fall into one of three categories:
Synthetic personas built on prompt engineering direct the model to adopt an audience profile through a combination of user and system-level instructions. These tools are typically marketed as AI personas or conversational focus groups, and they have genuine utility for early qualitative exploration and hypothesis generation. Where they fall short is in quantitative simulation — without deeper model customization, responses cluster around cultural archetypes rather than reflecting the authentic variance of a real population.
Digital twins built on retrieval-augmented generation (RAG) go a step further by grounding the model in a curated database of documents, interview transcripts, or prior research data, which produces more varied and realistic-looking outputs. RAG is particularly useful for niche audiences where real human data can anchor the model's responses more precisely. The limitation is that any bias present in the retrieval database carries through to the synthetic outputs — and if the underlying data comes from a narrow population, the model risks generating responses in an echo chamber. Like prompt engineering, RAG adds a layer of specificity without modifying the model itself.
Fine-tuned LLM models are built differently from the ground up. Rather than shaping or supplementing a general-purpose model, fine-tuning retrains an LLM on a curated dataset of real human survey behavior, changing how it generates responses at a structural level. The resulting model learns to reproduce the statistical behavior of real survey respondents, rather than simply simulating what a persona would say.
How Qualtrics built its model for synthetic research
Fine-tuning is the investment Qualtrics made before bringing synthetic audiences to customers. Rather than adapting a general-purpose model through prompting or RAG alone, the team developed a foundational model trained specifically on anonymized market research data, optimized to generate survey responses that hold up under rigorous statistical scrutiny. The model preserves response complexity and data relationships, ensuring synthetic data that supports the same rigorous analyses as human survey data. Testing proved the Qualtrics model is 12x more accurate than general-use LLMs in predicting human response to survey research.
That kind of development takes time and significant training data, and remains relatively uncommon across the industry. It's also why the quality difference between fine-tuned synthetic data and prompt-engineered alternatives tends to become visible quickly when the analysis gets serious.
How the full architecture works better together
Fine-tuning forms the core of Qualtrics' approach to synthetic audiences, but it works alongside the other methods rather than replacing them.
- A fine-tuned model provides the structural foundation: the response variability and behavioral depth that make synthetic data statistically defensible.
- Prompt engineering then guides how that model interacts with each specific survey instrument, maintaining the appropriate context and persona characteristics throughout data collection.
- RAG can supplement the foundation by grounding responses in current market information, helping ensure that outputs reflect recent developments rather than relying solely on historical training data.
The combination is meaningful because each method addresses a different dimension of the problem. Fine-tuning handles structural validity. Prompt engineering handles contextual accuracy. RAG handles population nuance. Relying on any one of them alone leaves gaps that show up in the data.
What this means for research teams
For insights leaders managing pressure to deliver faster without compromising the rigor that their credibility depends on, the quality of the underlying model is critical. Synthetic data that can't survive statistical scrutiny doesn't accelerate research timelines in any meaningful sense — it just produces decisions that look fast and turn out to be wrong
Qualtrics built its synthetic research capabilities to work alongside human panels and existing analysis tools within a single platform, so teams can apply the right method for each study without managing separate vendor relationships or re-integrating data across tools. The goal is to give researchers more flexibility without asking them to trade validity for speed.
The investment Qualtrics has made in foundational model development is what makes the output trustworthy enough to act on.


