自動化トピックス
このページの内容
自動化トピックについて
共通のトピックやテーマについて分析したいテキストのやり取りがありますか?人工知能 (AI) を使用してトピック階層を構築することで、トピックモデルを Jumpstart できます。非構造化顧客データ、ユースケース、ペルソナ、業界、その他のコンテキスト情報など多様性のある入力セットを使用して、AIを活用してトピック階層を構築し、ビジネスのユースケースにとって最も重要なテーマを特定することができます。
ヒント:このページでは、クアルトリクスで自動トピックモデルを作成する方法について説明します。XM DiscoverでAIアシストモデルを構築する方法については、「XM Discoverのトピック階層ジェネレーター」を参照してください。
要件
ユーザー権限
AIを使用してトピックモデルを構築するには、アカウントでAutomated Text Analytics ユーザー権限を有効にする必要があります。このパーミッションが無効の場合、ナビゲーションメニューに「Text Analytics」セクションは表示されません。
対応データ
以下のクアルトリクスプロジェクトタイプの非構造化データを分析できます:
-
- アンケートプロジェクト
- インポートされたデータプロジェクト
- オンライン評価管理プロジェクト
- 電子メール・データ・プロジェクト
- チャット・データ・プロジェクト
- ヴォイス・プロジェクト
ヒント:AI を使用して、EX プロジェクト (Engage など) に基づいてトピックモデルを構築することはできません。
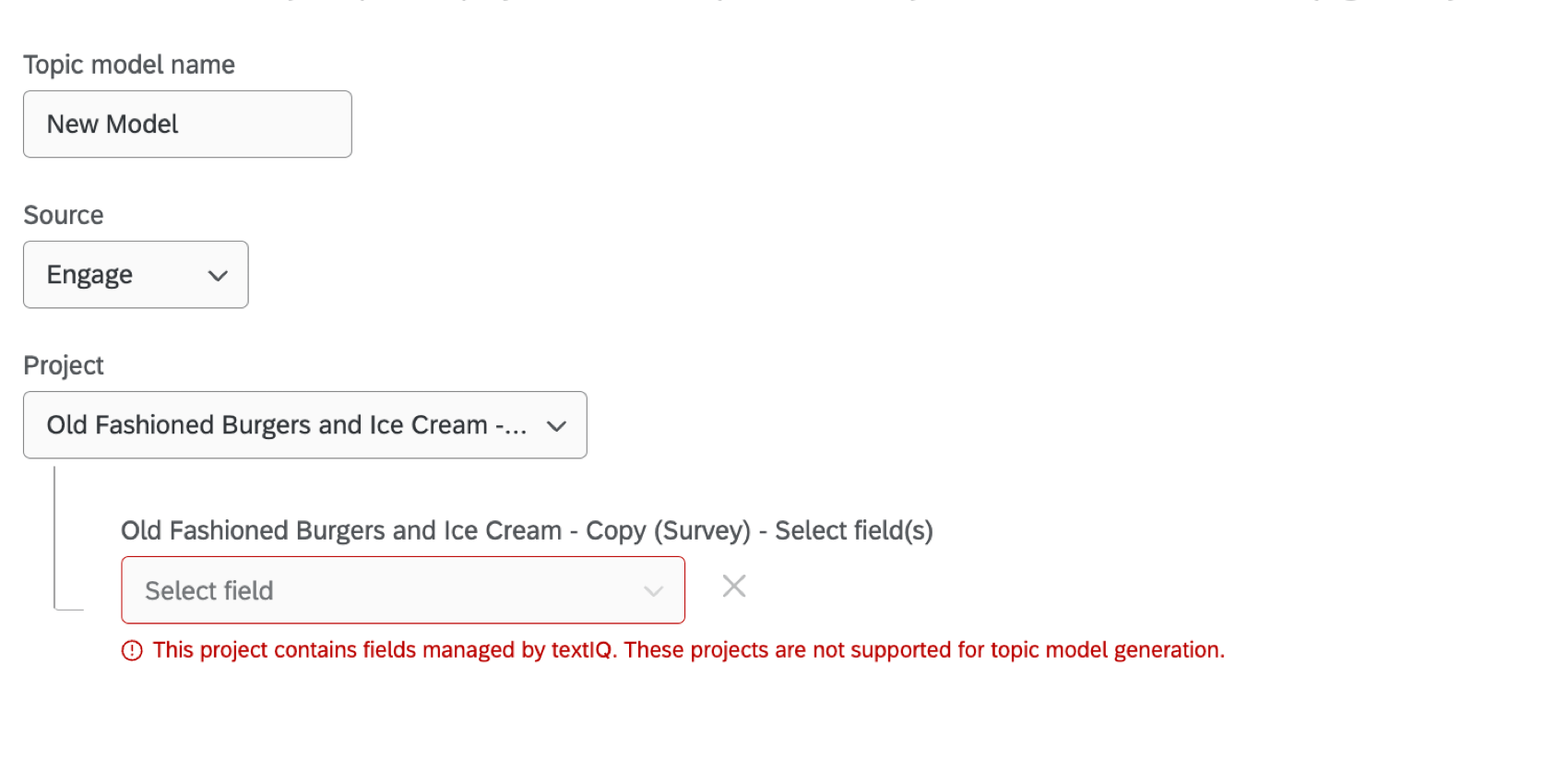
プロジェクトに自動トピックモデルを作成できるのは、そのプロジェクトに TEXT iQ モデルがまだ関連付けられていない場合に限られます。これには、データモデラーを使用してプロジェクトのText iQタブまたはダッシュボードのText iQセクションの両方で作成されたモデルも含まれます。不適格なプロジェクトを選択すると、そのプロジェクトにはすでに[iQ]フィールドがあるという警告が表示されます。
{kind=link}

ヒント:すでにText iQで分析されたプロジェクトを使用したい場合、あなたはしなければなりません:
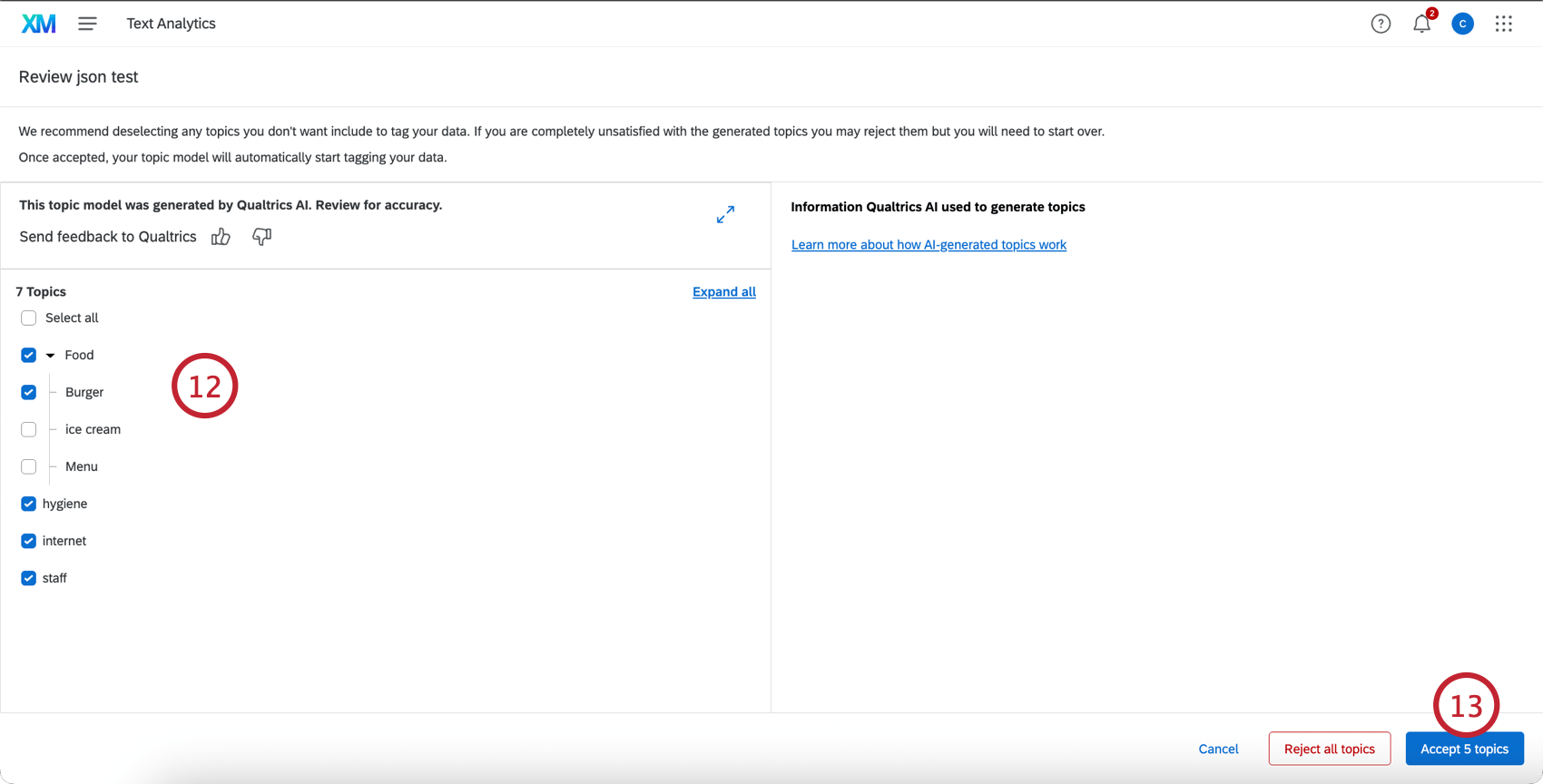
トピック・モデルの生成
ヒント:XM Discoverのデータを使用してモデルを生成する手順については、XM DiscoverのTopic Hierarchy Generatorを参照してください。
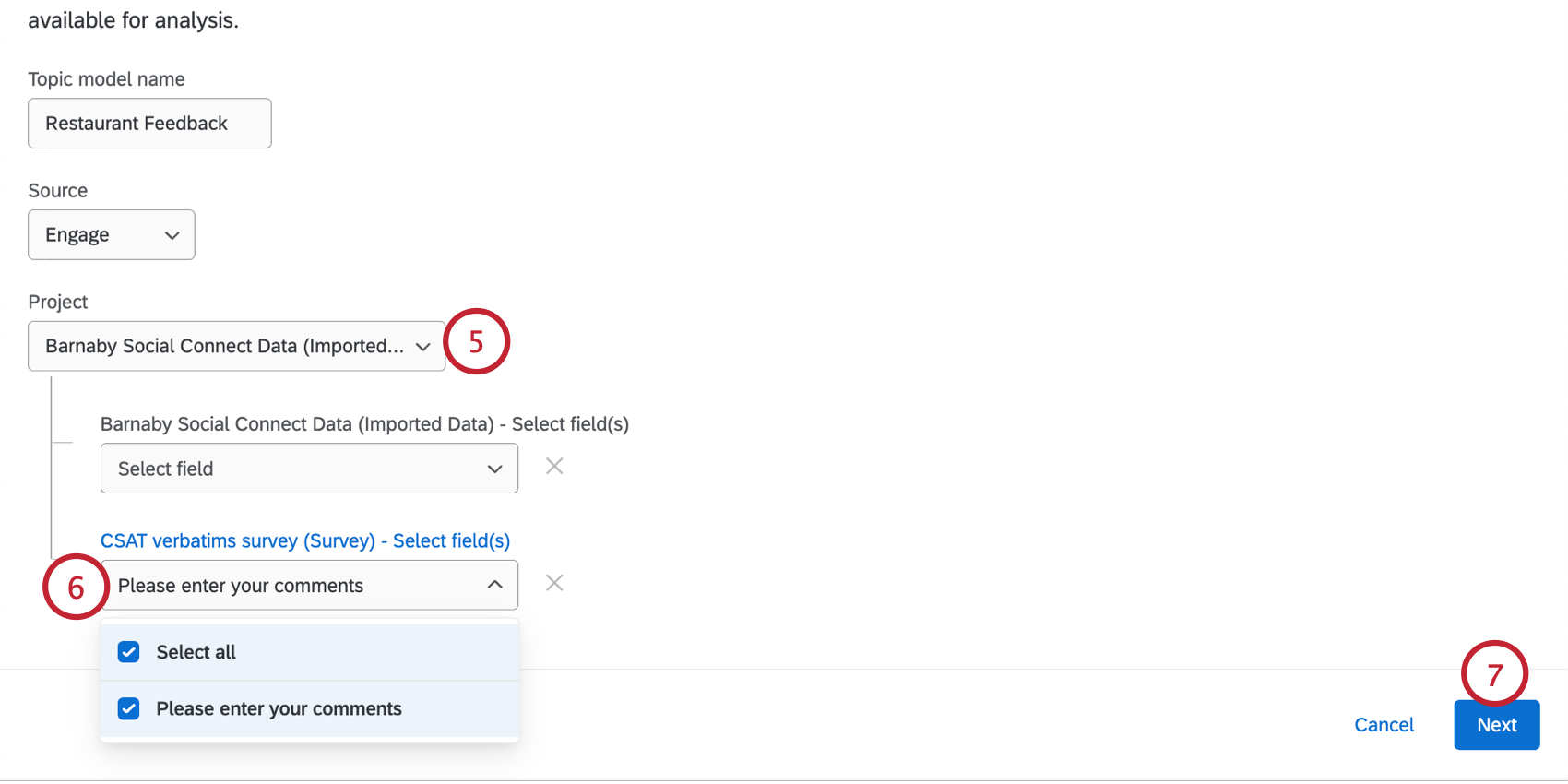
ヒント:ここで選択できるデータについては、上記の「必要条件」のセクションを参照してください。
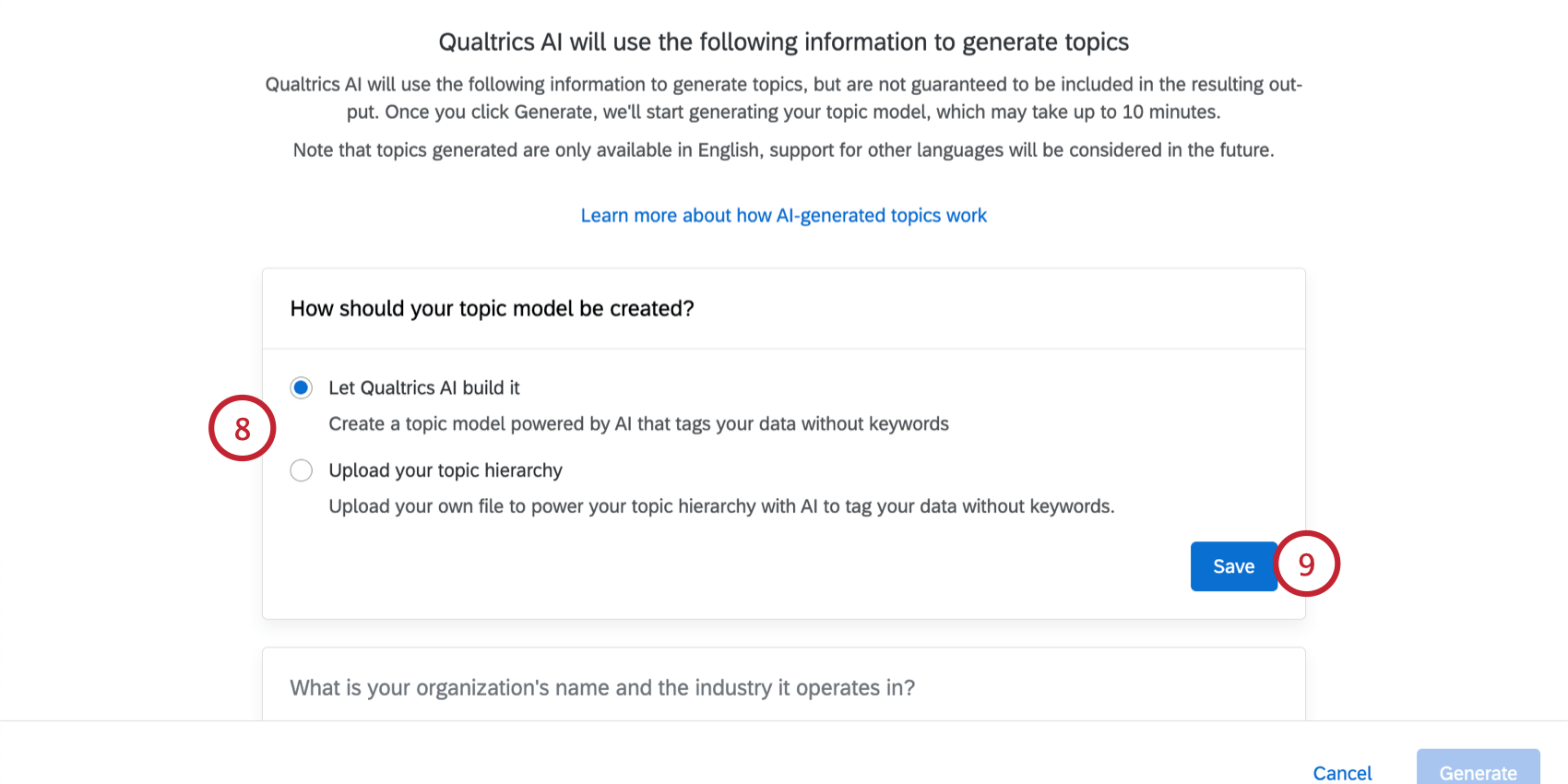
ヒント:「トピック階層をアップロードする」オプションは、新しい階層を生成する代わりに、既存のトピック階層を JSON 形式で再利用する場合に便利です。
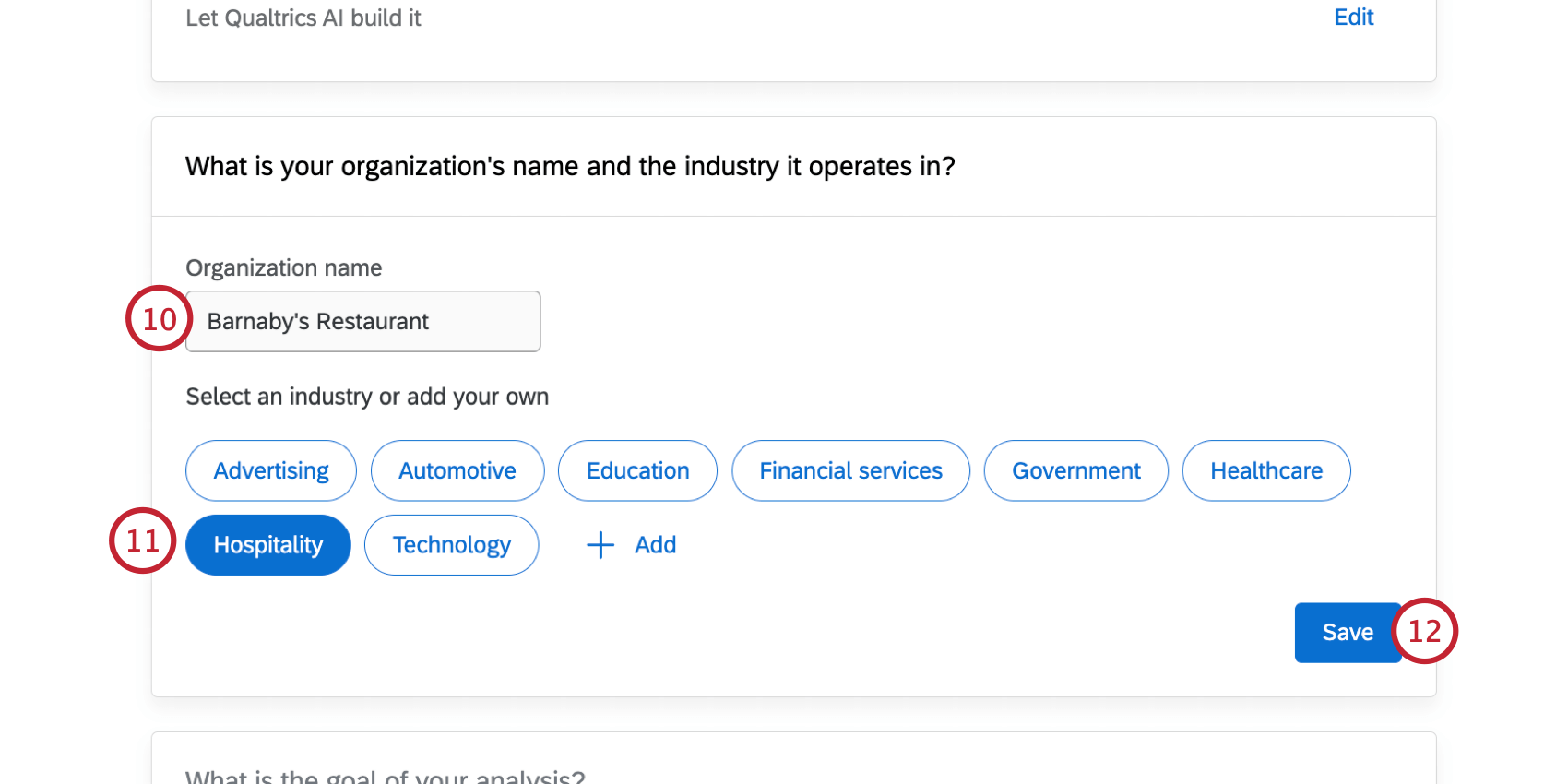
ヒント:ここに業種が表示されていない場合は、「追加」をクリックし、テキストボックスで業種を指定してください。
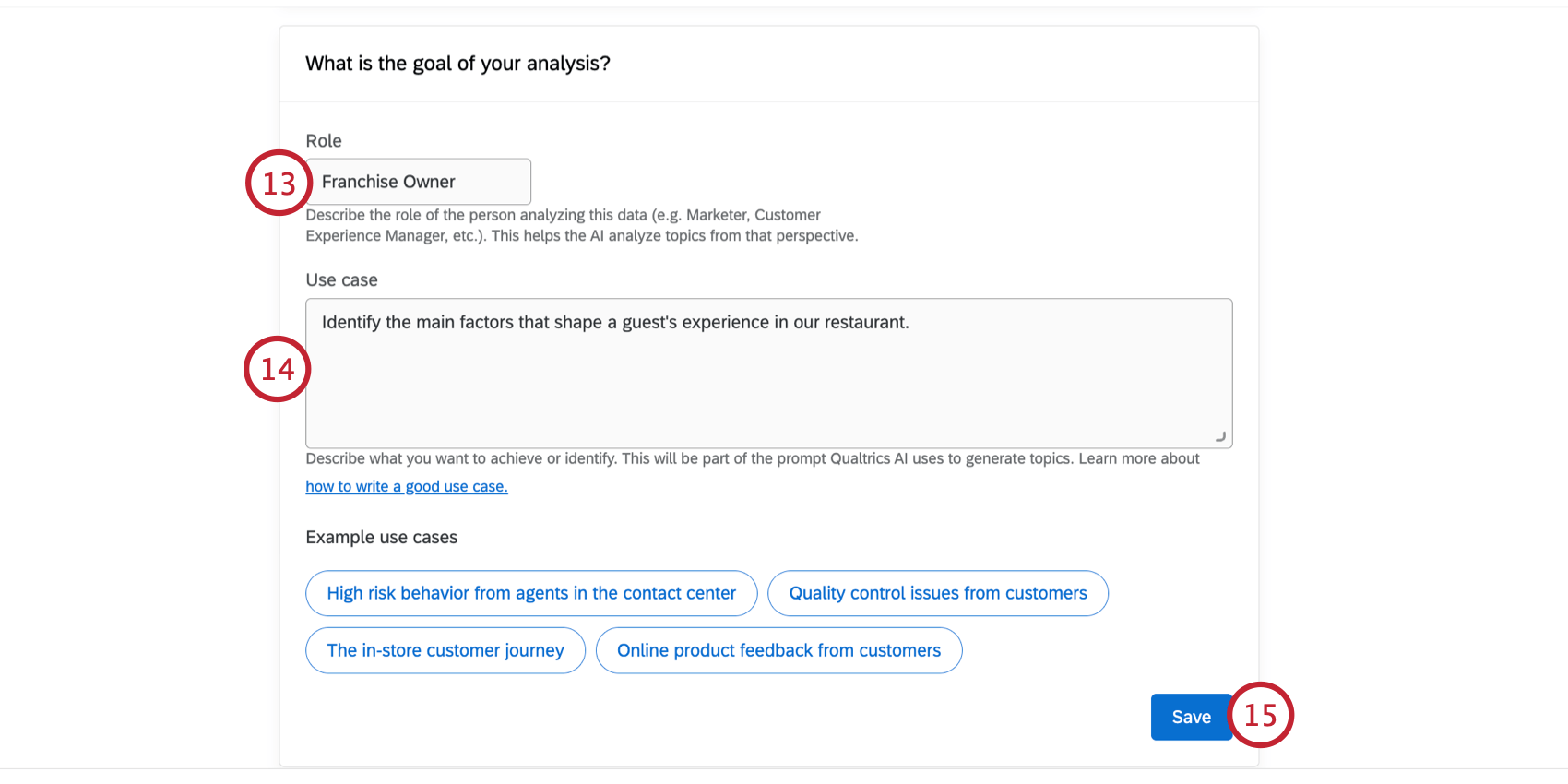
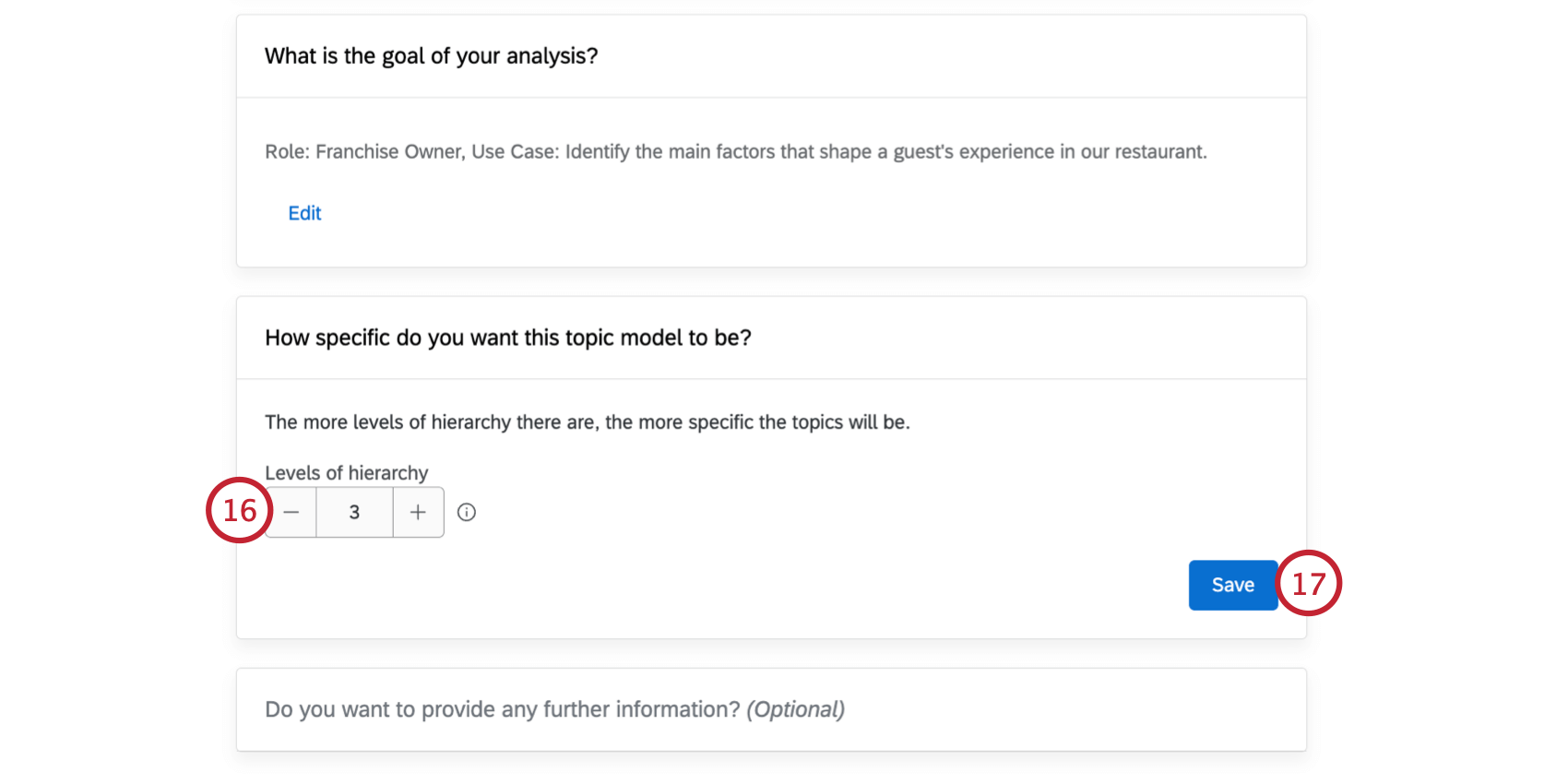
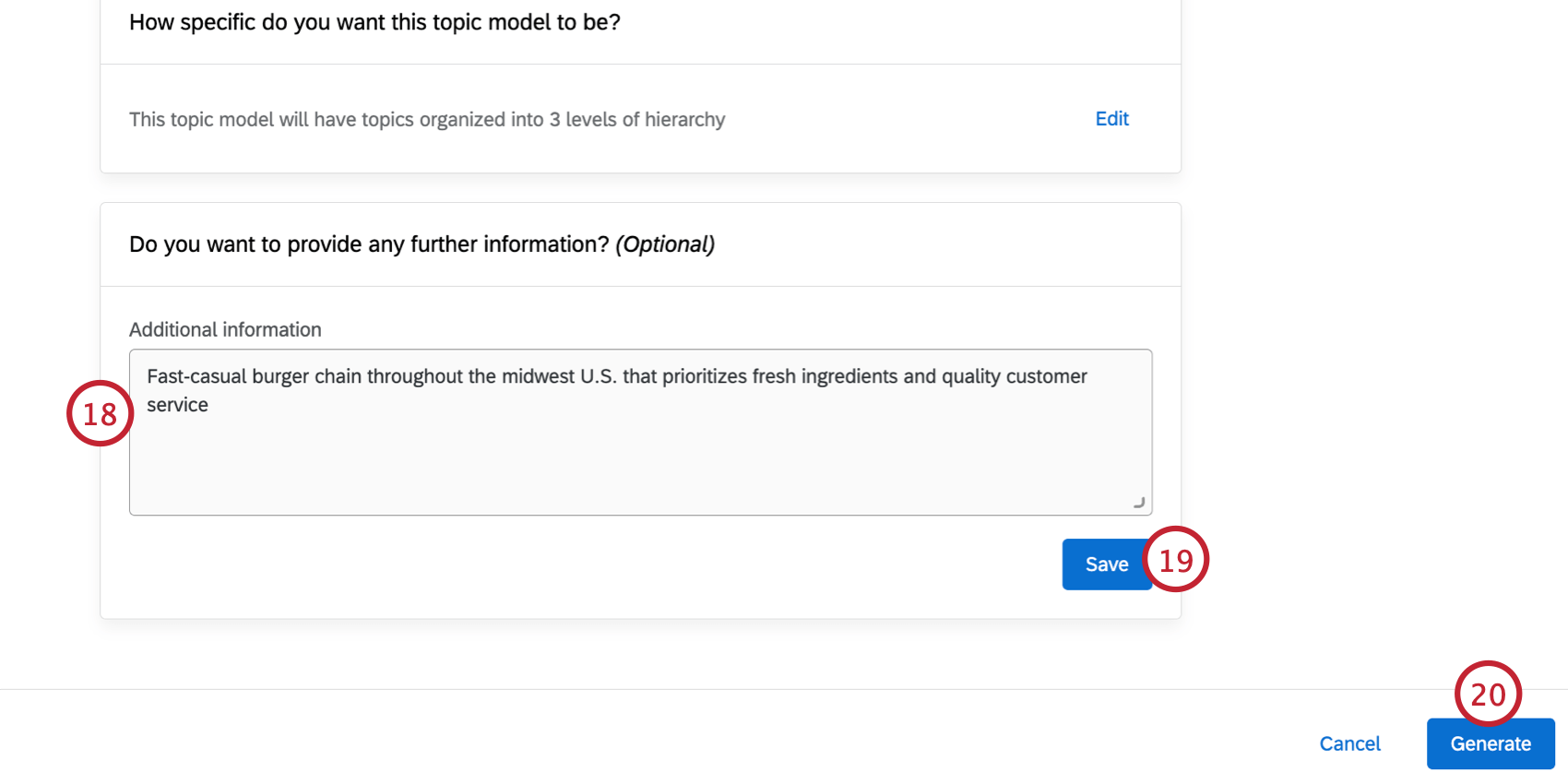
ヒント:必要であれば、テキスト階層を生成する前に、Editをクリックしてモデル・パラメータの一部を変更することができます。階層が生成された後に、これらのパラメータを編集することはできない。
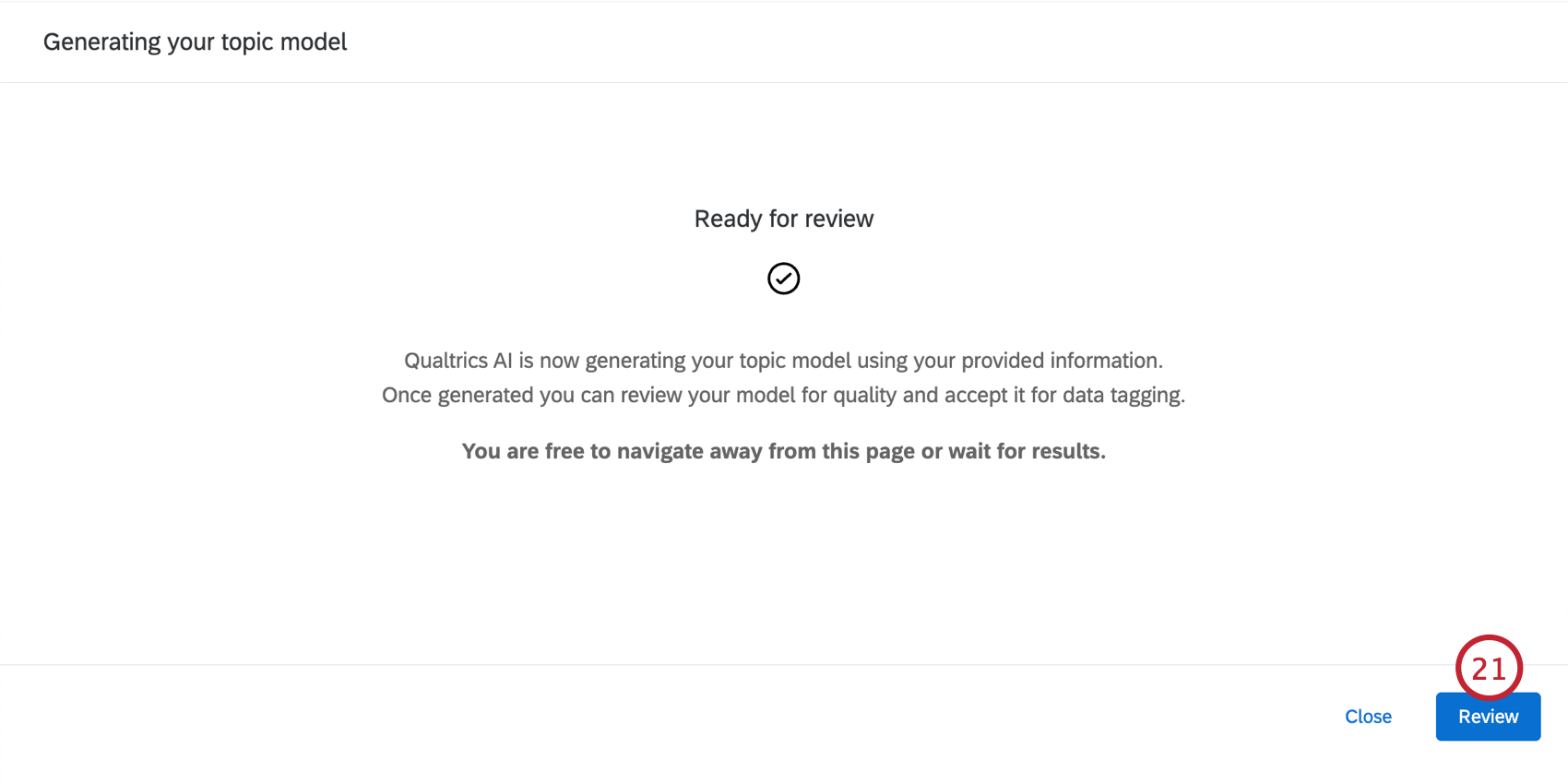
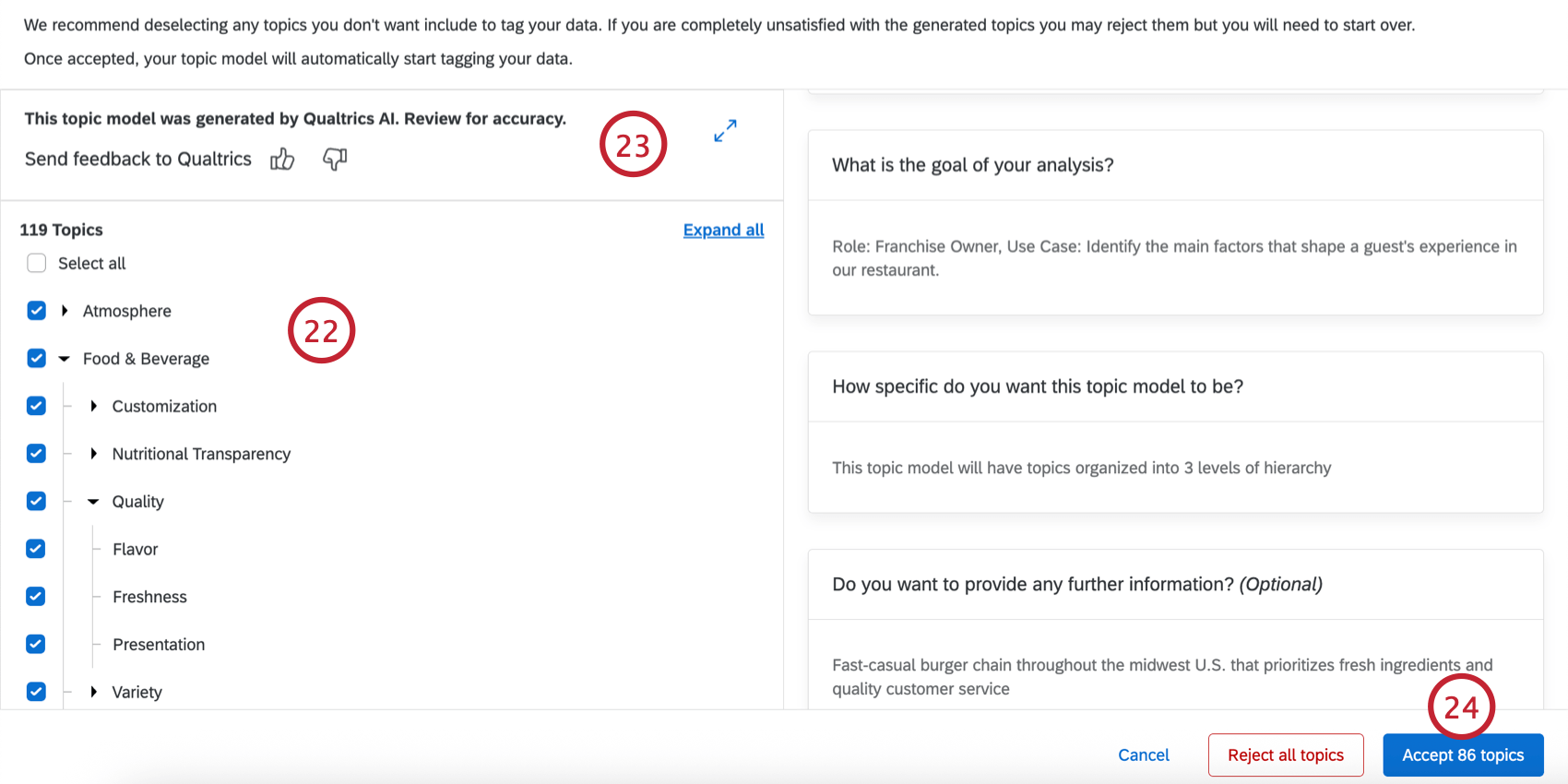
ヒント:新しいモデルを生成するために(例えば、組織内の特定の役割に合わせたモデルを作成するために)入力を修正しながら、これらの手順を繰り返すことができます。
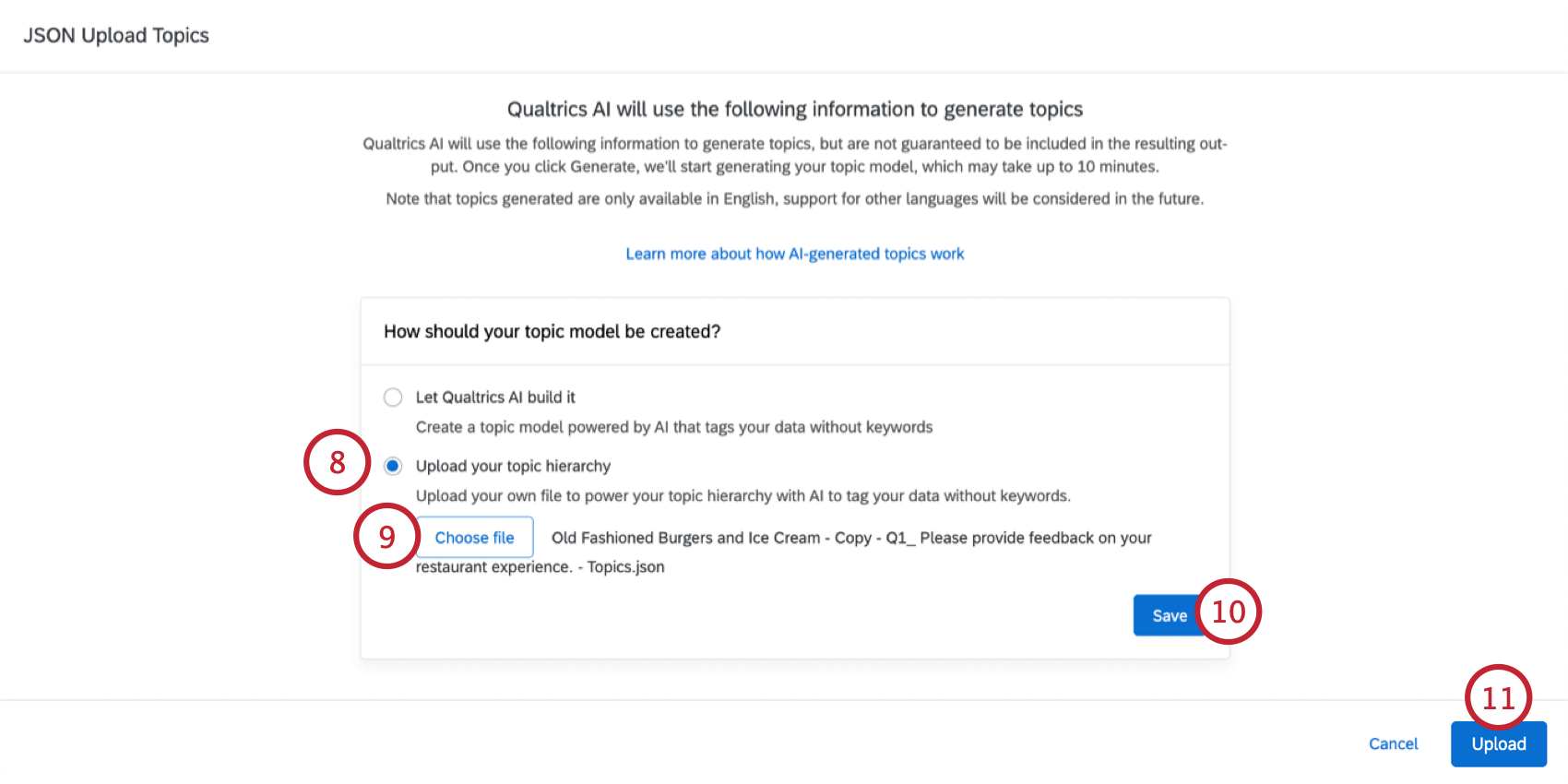
トピック・モデルのインポート
このセクションの手順に従って、JSON ファイルからトピック モデルをインポートします。通常、このファイルは既存のText iqデータセットからエクスポートされます。
ヒント:このオプションは、クアルトリクス・プラットフォームのデータソースでのみ使用できます。
ヒント:ここで選択する対象となるデータについては、「要件」を参照してください。
自動化されたトピックモデルの使用
ヒント:自動化トピックには、インプリメンテーションコンサルタントやテクニカルサクセスマネージャーなど、クアルトリクス担当者によるサポートが付いています。この担当者は、ダッシュボードのデータ設定にテキスト分析を実装するためのケアを行います。
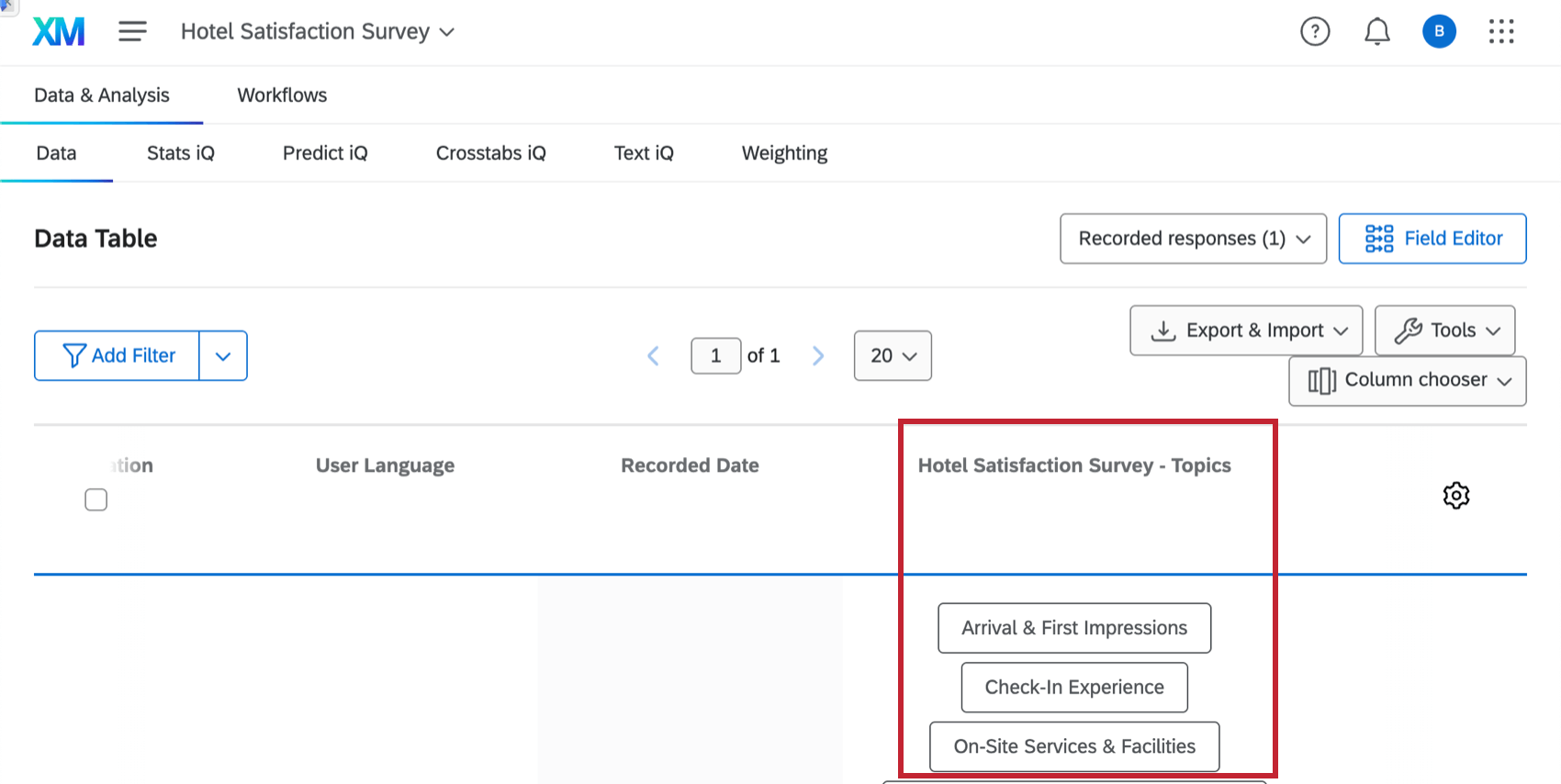
自動トピックモデルを作成した後、生成されたトピックは、モデルに使用されたデータソースにタグ付けされます。これらのトピックは、他のテキスト トピック フィールドと同じように、プロジェクトの [データと分析] タブに表示されます。
{kind=link}
![プロジェクトの [データと分析] タブで、ai トピック フィールドを表示する。](https://www.qualtrics.com/sites/default/files/styles/standard_xl_retina/public/migrations/dsx/content/ai-topics-data-analysis_4.png.webp?itok=4JX080nk)
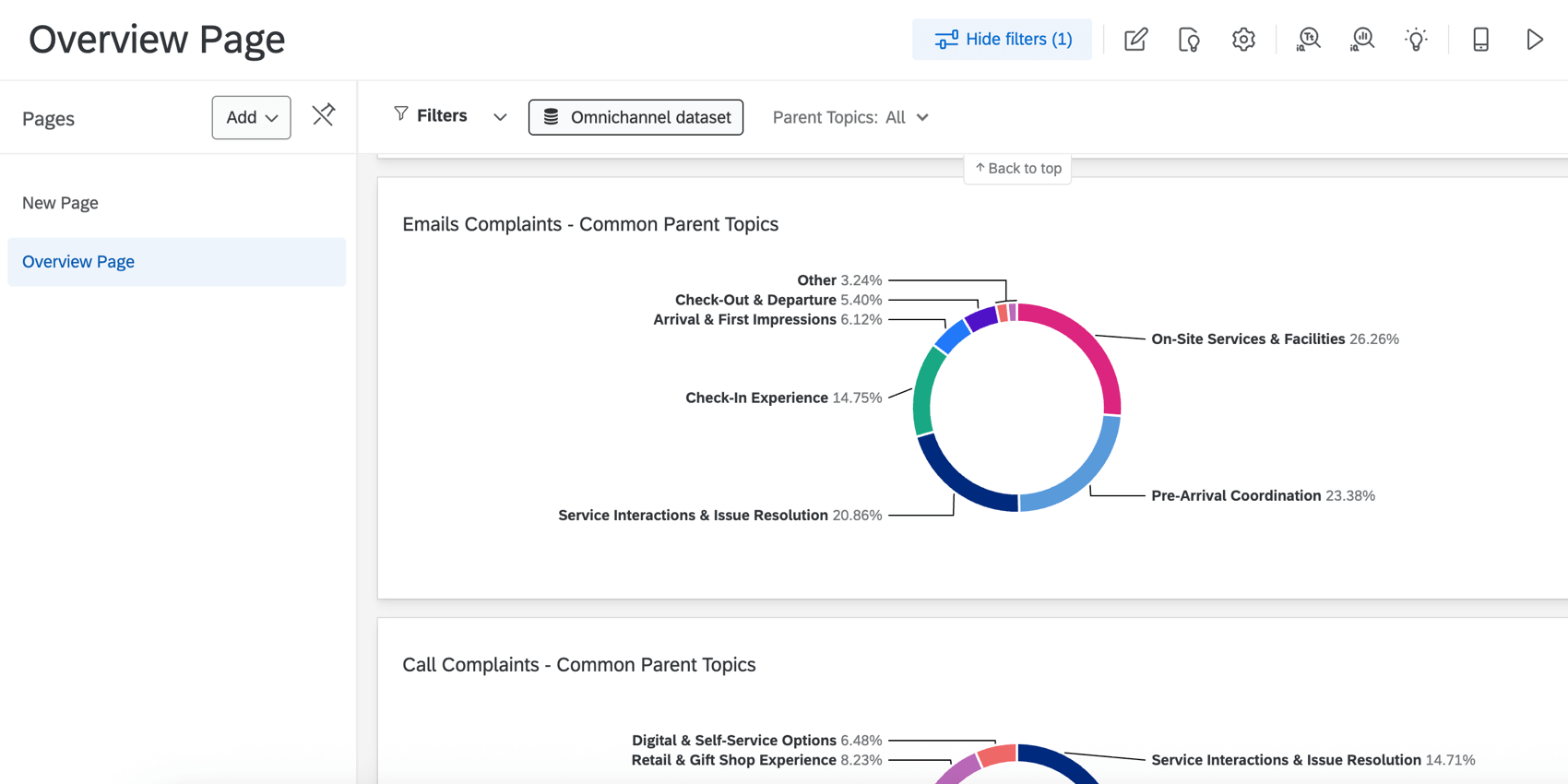
自動化されたトピックモデルは、ソース・インタラクションのすべての文の構造を持つ「Granular Text Analytics」データソースも作成します。各文章には、関連するトピック、感情、努力、感情、感情の強さ、および行動可能性のフィールドがあります。このデータソースは、CXダッシュボードのデータモデラーで使用できます。
テキストエンリッチメントを含む新しいソースを作成したら、Cxダッシュボードに表示することができます。現在、これはクアルトリクスチームによって管理されています。テキストエンリッチメントを含む新しいソースは、元のインタラクションデータと結合され、リンクされたダッシュボードフィールドは、インタラクションデータセットと派生データセット間で同じフィールドをリンクするために使用されます。ダッシュボードのデータが設定されると、ウィジェットやフィルターごとに使用するデータセットを選択することができます。
{kind=link}

素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!