クラスタ分析
このページの内容
クラスタ分析について
データを分析する際、私たちはさまざまな属性グループに関心を持つことが多く、回答者を収入、地域、年齢などで細分化します。結局のところ、男性回答者が多いことを知っても、彼らがどんな広告キャンペーンを見たいかはわからない。視聴者の中心はミレニアル世代ですか?サッカーのお父さん?両方?個人的な特徴を、マーケティングの目的で分解できる言葉に置き換えるにはどうすればいいのか?
クラスタ分析は、アンケート調査のデータセットに自然に存在するグループを検出する手段です。これは、どの人口統計学的資質、行動学的資質、信念に基づく資質が最も相関性が高いかを分析することによって行われる。
{kind=link}

Qtip:ワークスペースには750枚までカードを置くことができます。この制限に達した場合、新しいカードを作成しようとするとエラーが表示され、最も古いカードが削除されることを警告します。
クラスタ分析のためのアンケート調査の準備
クラスタ分析を行うには、アンケート調査で正しいデータを収集する必要があります。
- 正しい質問をする
- 人口統計:年齢、所得層、人種、性別など、基本的な記述情報を尋ねる。
- 行動:顧客のブランドや製品への接し方、あるいは購買実態に関連する行動を尋ねる。例えば、顧客が買い物に行く頻度を尋ねることができる。
- 運用 データ:これは、ウェブサイトでの滞在時間や従業員の勤続年数などの情報です。 Qtip:ページ滞在時間のトラッキングに興味がありますか?ウェブサイトフィードバック機能をご利用ください。詳細をご覧になりたい方は、営業担当までご連絡ください。

- 態度と信念:回答者の核となる価値観、態度、信念についてアンケート調査しましょう。これには宗教的、政治的信条も含まれますが、あなたの会社の働き方に直接関係する信条を尋ねることもできます。例えば、サポートが対面であることの重要性を評価してもらうこともできる。
- 質問の形式: 質問の動作や信念を尺度として書式化する。Yes/Noや単一選択の質問は、クラスタ分析にはあまり役に立ちません。 例: あなたはどのような買い物をしますか?”と質問し、”ショッピングモールで買い物をするのが好き”、”オンラインで買い物をするのが好き”、”ブティックで買い物をするのが好き “という選択肢を与えた場合、クラスタリングアルゴリズムは回答者を3つのグループに分け、それぞれの回答に対して1つのグループとします。例えば、”ショッピングモールで買い物をするのが好きですか?”といったように、1~7までの回答で質問すれば、クラスタリング・アルゴリズムは、買い物客同士を区別するポイントをより的確に見極めることができるだろう。
 Qtip: 多肢選択式の質問はスカラーデータを集めるのに最適です。
Qtip: 多肢選択式の質問はスカラーデータを集めるのに最適です。 - 変数タイプ: Stats iQで分析する準備ができたら、変数をカテゴリーまたは数値としてフォーマットしてください。日付はクラスタ分析とは相容れない。
Qtip:変数を作成するときは、相関が高いことがすでに分かっているものを検討しましょう。これにより、クラスタ分析における10変数の制限を守ることができます。
注意: クラスタ分析の最大サンプルサイズは20,000回答です。
クラスタ分析のパフォーマンス
Qtip:1度に10個の変数のクラスタ分析しか実行できません。もっと入れたい場合は、お互いに相関の高い変数を見つけて、Create or Clean Variableボタンを使ってそれらの平均を作成してみてください。
クラスタ分析結果
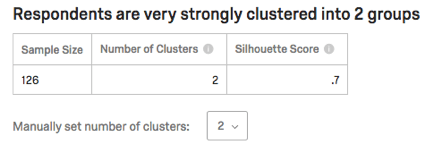
強度と静力学の表
テーブルには、サンプルサイズ(この分析にデータを提供した回答者の数)、クラスタ数、およびシルエットスコアがリストされます。シルエットスコアは、冒頭の文章にある “very strongly “のようなフレーズに解釈される。
{kind=link}
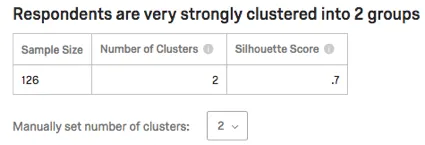
Qtip:この表に表示されているシルエットスコアについては、クラスタ分析の解釈のセクションを参照のこと。
クラスタ分析では、さまざまなクラスタ数でクラスタリングの緊密さをアセスメントすることによって、適切なクラスタ数を自動的に選択しようとしますが、クラスタ数が多くなると作業が難しくなるため、ペナルティを課します。適切な数字を選ぶのは科学というより芸術であり、さまざまな数字を試してみて、何が最も効果的かを見極めるべきである。
場合によっては、アルゴリズムはある数のクラスタを生成できず、より少ない数に後退する。
クラスタの概要
クラスタはクラスタサマリーセクションにリストされます。クラスタのメンバーが最も似た回答をした質問に基づいて説明する。
{kind=link}

例: このスクリーンショットのクラスタ1には、次のような人々が含まれています:
- 既婚
- 修士号取得者
- 家に住んでいる人(肉親、子供)が少ない。
- ヤング
クラスタ名をクリックしてクラスタ名を変更します。
Qtip:クラスタの名前を変更することは、結果を実世界やマーケティングの文脈でより意味のあるものにするために重要です。

{kind=link}
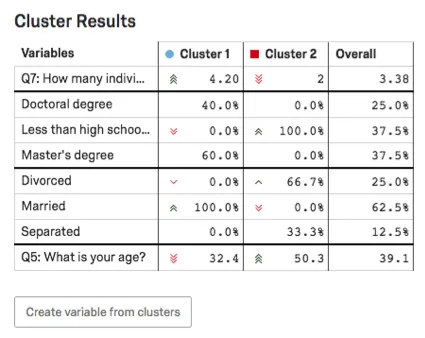
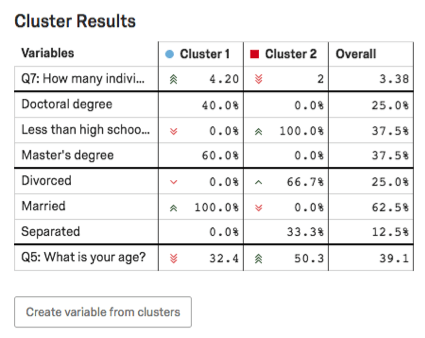
クラスタ結果テーブル
クラスタ結果テーブルでは、クラスタの主要変数が強調表示されます。カテゴリー変数については、最も一般的な選択肢と、この回答をしたクラスタ内の回答者の割合が示される。数の変数については、平均回答が表示されます。
例: このスクリーンショットでは、教育レベルはカテゴリー分けされているため、博士号取得者の回答者の割合と、博士号取得者の回答者の割合の詳細区分が表示されています。高卒未満と高卒未満の比較。修士号
ここでは年齢を数字で表しているため、各クラスタの平均年齢がわかる(クラスタ1は32.4歳、クラスタ2は50.3歳)。
{kind=link}
クラスタから変数を作成する詳細を見るには、クラスタから変数を作成するセクションを参照してください。
変数の重要度
変数重要度表は、各変数とクラスタとの関係の強さを示す。関係が強ければ強いほど、その変数がクラスタの形成により重要であったことを示す。
これを計算するために、各変数について回帰分析を行う。例えば、年齢をクラスタの結果と照らし合わせたり、労働時間をクラスタの結果と照らし合わせたり、といった具合である。
これらの回帰から得られたr二乗の結果は、最も高いr二乗が1となるようにスケールアップされる。
例: Q7のr2乗が0.5で、グループ中最高だったとしよう。つまり、もしQ13のr二乗が0.4であれば、下のグラフでは0.8と表示される。

{kind=link}
結果から新しい変数を作る
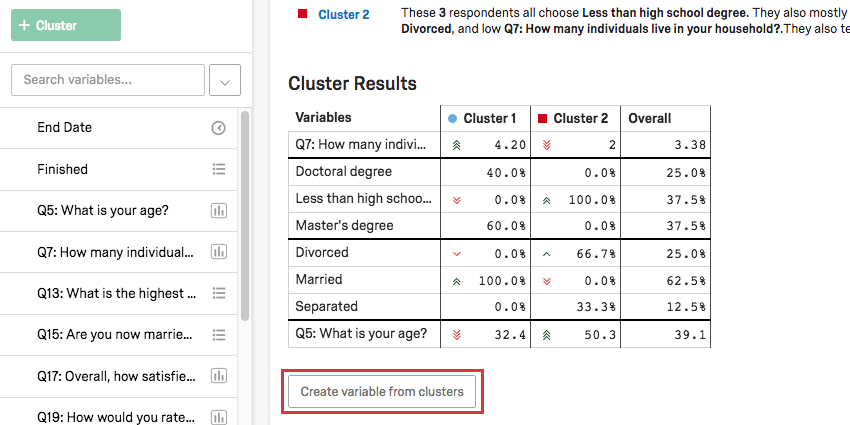
回答者のクラスタを決定したら、これらのカテゴリをStats iQで分析できる新しい変数にすることができます!
まず、クラスタの名前をクリックして変更してください。

Qtip:リネーミングのステップは必須ではありませんが、そうすることでデータがすっきりし、あなたや同僚がより理解しやすくなります。
クラスタに納得のいく名前を付けたら、クラスタ結果テーブルの下のクラスタから変数を作成するをクリックします。これにより、左側の変数リストにカテゴリ変数が自動的に追加されます。
{kind=link}

Qtip:この変数はStats iQでのみ利用可能です。クアルトリクスのデータのどこにも表示されません。
テクニカルノート
Stats iQのクラスタ分析では、潜在クラス分析(LCA)を使用して、ユーザーが提供したデータを基本的なクラスタに分割します。他のクラスタリング・アルゴリズムと異なり、Stats iQ LCAアルゴリズムでは、混合データ型(数値、カテゴリー、バイナリー)をクラスタ化することができます。
混合型潜在クラス分析
潜在クラスタ分析(LCA)は、確率ベースのクラスタリング・モデルである。各クラスタは、データポイントの変数の値に基づいて、特定のデータポイントがそのクラスタに帰属する可能性を返す確率密度関数のコレクションによって定義されます。
例: あなたの家族は、現在の子供、両親、祖父母など、いくつかの世代に分けることができます。LCAモデルはこれら3つのクラスタを表現し、各クラスタは年齢に基づく1つの確率関数で定義される:
クラスタ 確率関数 平均 確率関数 標準偏差 現在 25 7 親 48 5 祖父母 75 3 30歳の人をクラスタに割り当てるには、これらの確率密度関数を使用して、彼らが「現在」である可能性が44%、「両親」である可能性が1%、「祖父母」である可能性が1%であることを計算する。この選手は、最も可能性の高いクラスタであるカレントに割り当てられる。
LCAモデルは、データポイントがクラスタに帰属する尤度を各変数に基づいて乗算することにより、複数の変数に適用することができる。このモデルは、異なる確率密度関数を使用することにより、異なる変数タイプに適用することができる:
| タイプ | 変換 | 確率密度関数 |
|---|---|---|
| 分類別 | ダミー符号化 (N-1) | ベルヌーイ |
| バイナリ | ベルヌーイ | |
| 数字 | 標準 |
クラス数の決定
最適なクラス数を決定するために、Stats iQはBICスコアを使用します。
モデルフィットの評価者
モデルの客観的な「良さ」を評価するために、Stats iQは確率ベースのシルエットスコアを使用します。シルエットスコアとは、各データポイントがそのクラスタ内にどの程度位置するかを示す尺度である。シルエットスコアは、そのクラスタ内の他のすべての点に対する特定の点の類似性を測定し、最も近いクラスタ内のすべての点とどれだけ似ているかを比較する。Stats iqは、2つのデータポイント間の類似性を測定するために、ポイント間のガワー距離(バイナリ、カテゴリー、数値データに有効な距離メトリック)を計算します。
FAQs
Stats iQに新しい回答を表示させるにはどうしたらよいですか?
Stats iQに新しい回答を表示させるにはどうしたらよいですか?
What do I do if my data isn't loading properly?
What do I do if my data isn't loading properly?
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!