カスタム・トピックのインポート
このページの内容
カスタムトピックのインポートについて
機密データポリシー機能では、ブランドのユーザーがアンケートを作成するとき、ユーザーがデータを収集するとき、および回答者がアンケートに回答を提供するときに、フラグを立てたいカスタムトピックをインポートすることができます。このページでは、これらのトピックを正常にインポートするための JSON ファイルのフォーマット方法について説明します。
JSON ファイルを使用する場合、インポートするトピックは常に新しいトピックとして追加され、既存の類似トピックに追加されることはありません。たとえば、トピックとして社会保障を手動で選択し、さらにキーワードを追加した社会保障というトピックを持つ JSON ファイルをインポートした場合、機密データポリシーには 2 つの社会保障トピックが存在することになります。これは、あなたのブランドがプライバシーに違反していないかチェックするツールの能力を損なうものではありません。
Qtip: インポートするには、JSONファイルが400KB以下でなければなりません。
ヒント: この機能はText iQ Topicsとは関係ありません。 ブランド管理者のみがこの機能にアクセスできます。
注意: 機密データポリシーは、すべてのブランドで利用できるわけではありません。アクセシビリティにご興味のある方は、担当営業エグゼクティブまたはアカウントサービスまでご連絡ください。
JSONファイルの編集

Qtip:キーワードは問題のある質問にフラグを立てるために使用され、正規表現は問題のある回答にフラグを立てるために使用されます。両方の場所でフラグを立てたい場合は、キーワードと正規表現を追加する必要がある。
Qtip:括弧の始まりと終わりに注意してください!行をインデントすることで、括弧の開閉位置を揃えることができます。
インポート用JSONファイルのフォーマット
このセクションでは、カスタムトピックを PII チェッカーにインポートできるように、JSON ファイルをフォーマットする方法について説明します。
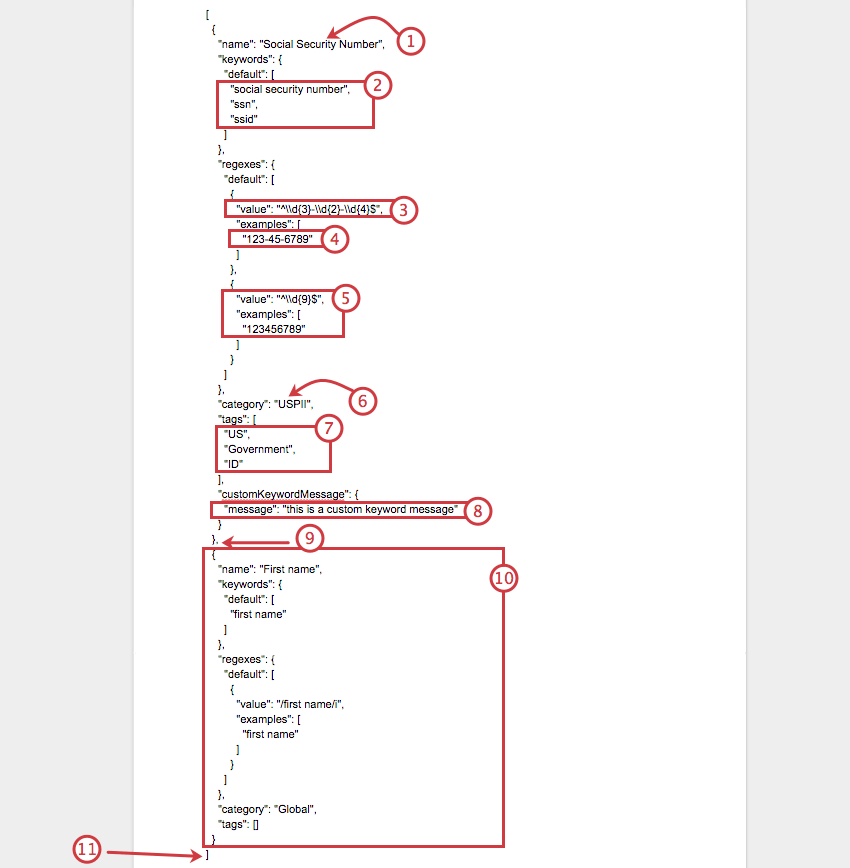
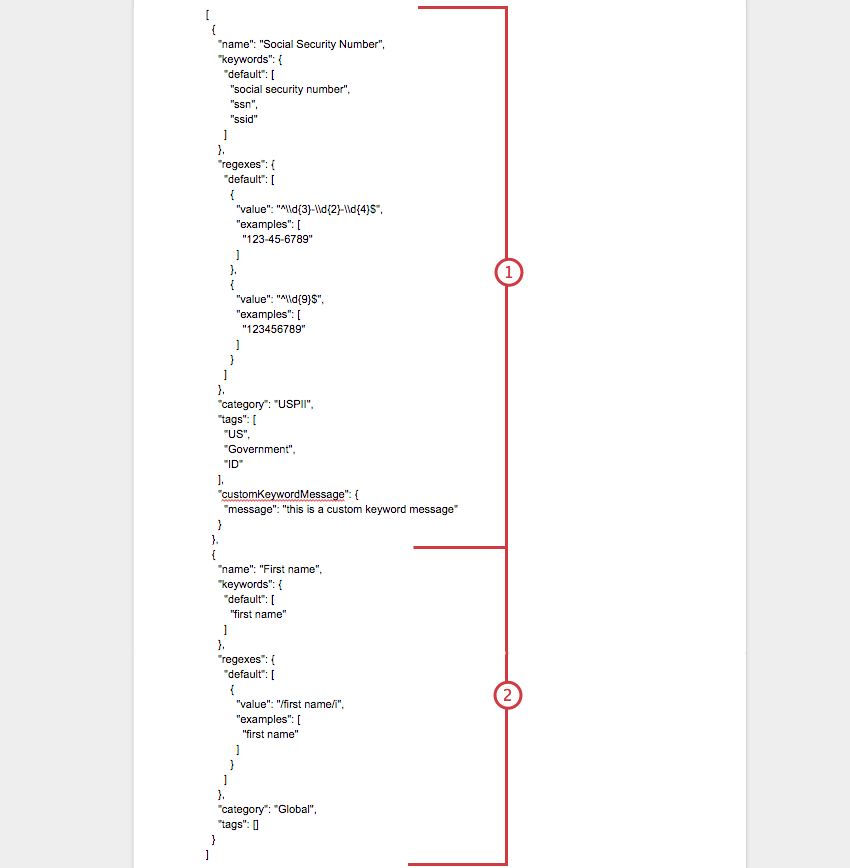
以下は完成したJSONファイルの例で、1つのカスタムトピック(社会保障番号)がどこで終わり、もう1つのカスタムトピック(名前)がどこで始まるかを示しています。

ファイルの種類とプログラム
JSONファイルは、デスクトップ上のテキストエディタで作成・編集できる。例えば、TextEdit、Sublime Editor、Notepad++などだ。
JSON ファイルの例をダウンロードするには、[複数のカスタム・トピックのインポート] セクションの手順 1 ~ 6 に従います。提供されたフォーマットから逸脱しないようにしてください。
トピックスの名称とキーワード
これらはカスタムトピックで、好きな名前をつけることができます!例えば、あなたのブランドのユーザーが社会保障番号を収集しようとしないことを確認したいかもしれません。この話題を “社会保障番号 “と呼ぶこともできる。
キーワードは、ソーシャル・セキュリティー・ナンバーを収集しようとしている人物を特定する方法である。質問にフラグを立てるには、”ssid”、”ssn”、”social security number “というキーワードを探すとよい。これらのキーワードは大文字と小文字を区別しない。
{
"name":"Social Security Number",
"keywords":{
"default":[
"social security number",
"ssn",
"ssid"
]
}.トピックのカテゴリーとタグ
カテゴリは、クアルトリクスにフラグを立てさせたいさまざまなトピックを整理するための組織です。名前と同じように、カテゴリーも好きなように呼ぶことができる。例えば、「ファーストネーム」というトピックの場合、カテゴリーを「グローバル」とすることができる。これは、全世界の個人情報を明らかにするものであり、どの地域のデータを収集するユーザーにも適用されるからである。対比として、「社会保障番号」は「USPII」に分類されるかもしれない。U.S.は米国の分類システムであることを意味し、PIIは非常にプライベートで保護された情報であることを意味するからだ。
タグは、指定されたカテゴリーを検索し、定義するのに役立ちます。USPIIの場合、タグは “US”、”government”、”ID “となる。
"category":"USPII",
"tags":[
"US",
"Government",
"ID"
].カスタムメッセージ
ユーザーがアンケート調査でフラグ付きのキーワードを使用しようとしたときに表示されるカスタムメッセージを定義することができます。
カスタムメッセージを入れたくない場合は、このフィールドをファイルから削除すればよい。
"customKeywordMessage":{
"message":"this is a custom keyword message"
}.
正規表現
Regex(「正規表現」の略)は、トピック値のパラメータを定義する。
注意: 正規表現は大文字小文字を区別せずに評価されます。
例えば、”あなたの電話番号を教えてください “というような質問を考えてみてください。米国の電話番号の場合、数字を含む答えだけが必要で、10桁以上の長さは必要ない。
"regexes":{
"default":[
{
"value":"^d{3}-\d{3}-\d{4}$",
"examples":[
"123-456-7890"
]
},
{
"value":"^d{10}$",
"examples":[
"1234567890"
]
}.
クアルトリクスサポートでは、正規表現については技術的にカスタムコーディングとなるため、アドバイスすることができません。しかし、これらのリソースをチェックすることで、より多くの助けを得ることができる:
完全なJSONファイルの例
[
{
"name":"Social Security Number",
"keywords":{
"default":[
"social security number",
"ssn",
"ssid"
]
},
"regexes":{
"default":[
{
"value":"^d{3}-\d{2}-\d{4}$",
"examples":[
"123-45-6789"
]
},
{
"value":"^d{9}$",
"examples":[
"123456789"
]
}
]
},
"category":"USPII",
"tags":[
"US",
"Government",
"ID"
],
"customKeywordMessage":{
"message":"this is a custom keyword message"
}
},
{
"name":"First name",
"keywords":{
"default":[
"first name"
]
},
"regexes":{
"default":[
{
"value":"/first name/i",
"examples":[
"first name"
]
}
]
},
"category":"Global",
"tags":[]
}
]. 複数のカスタム・トピックのインポート
![ウェブサイトの各ページの左上にある最上位のナビゲーションから[管理者]を選ぶ](https://www.qualtrics.com/m/assets/support/wp-content/uploads//2018/03/admin-global-navigation.png)
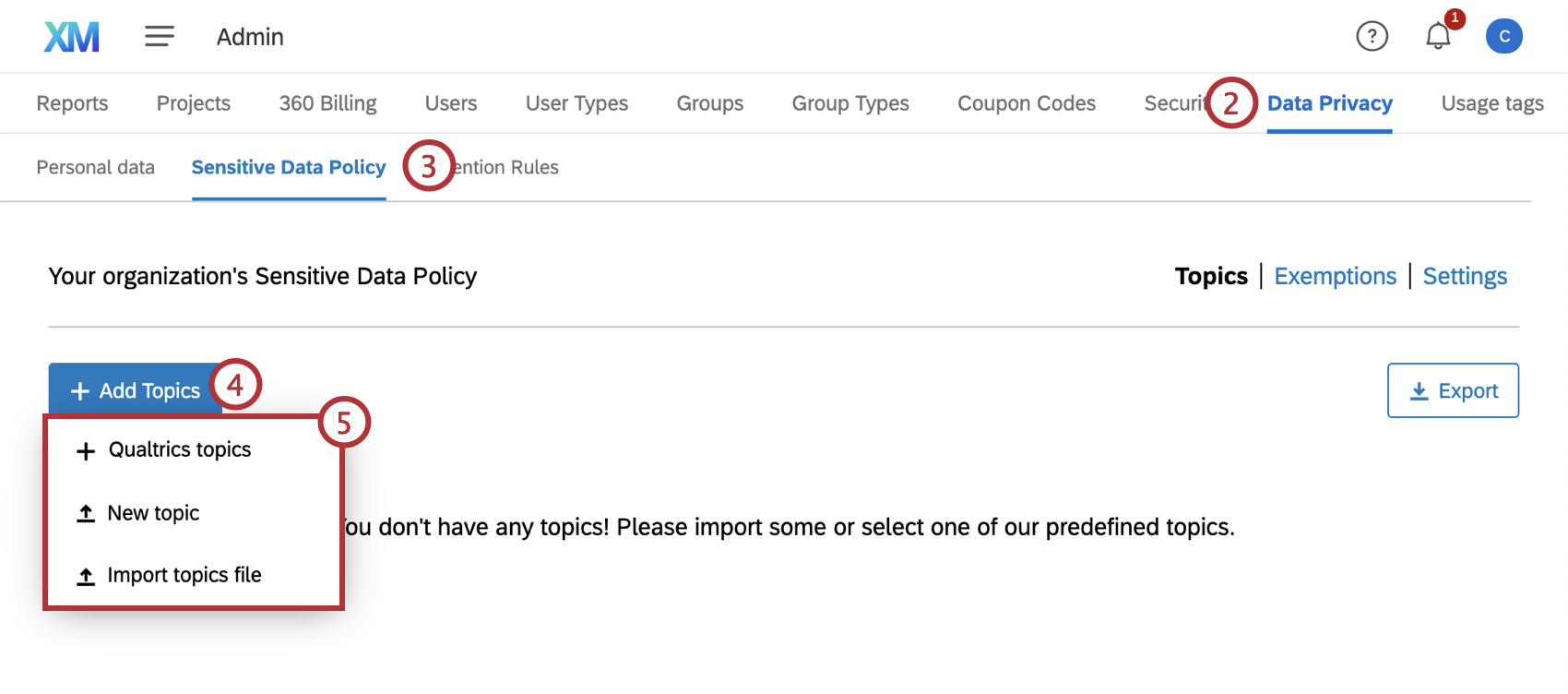
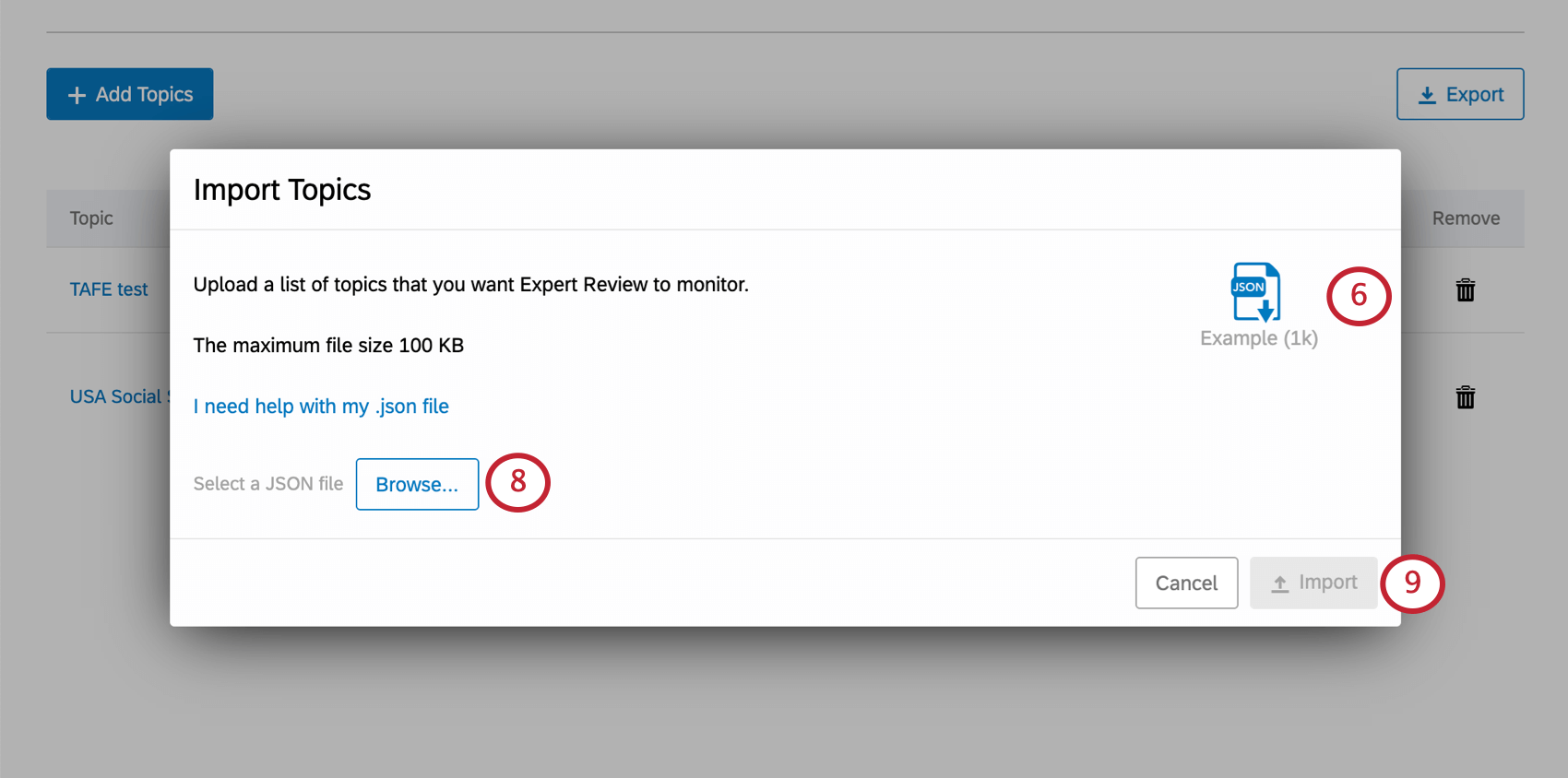
単一のカスタムトピックの追加
![カスタムトピックの編集] ウィンドウ上部のフィールド](https://www.qualtrics.com/m/assets/support/wp-content/uploads//2021/03/sensitive-data-4.png)
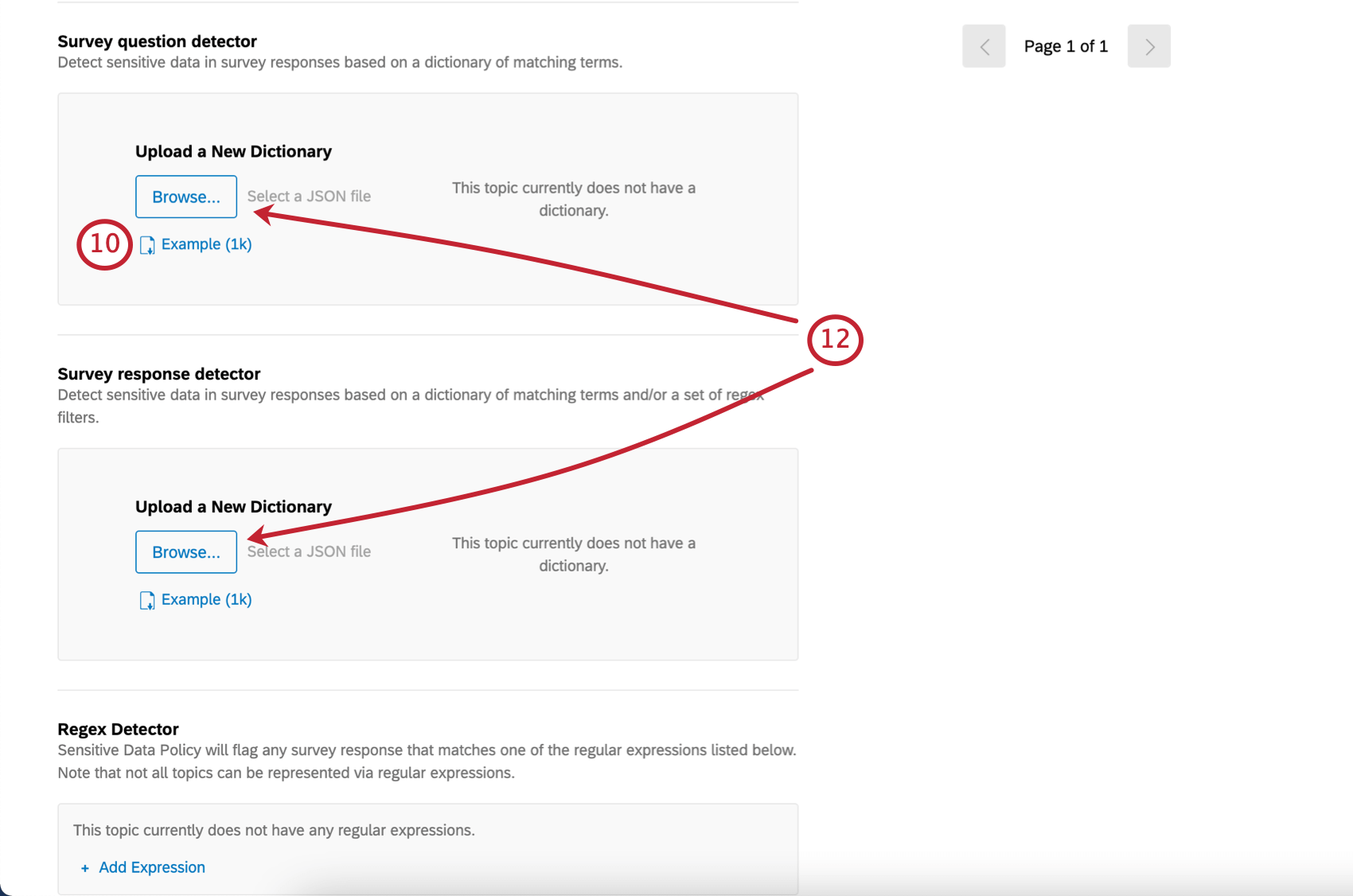
Qtip:このJSONフォーマットは、このページで先に説明したものと似ていますが、複数のトピックではなく、1つのファイルにつき1つのトピックとそれに関連するキーワードにのみ関係します。
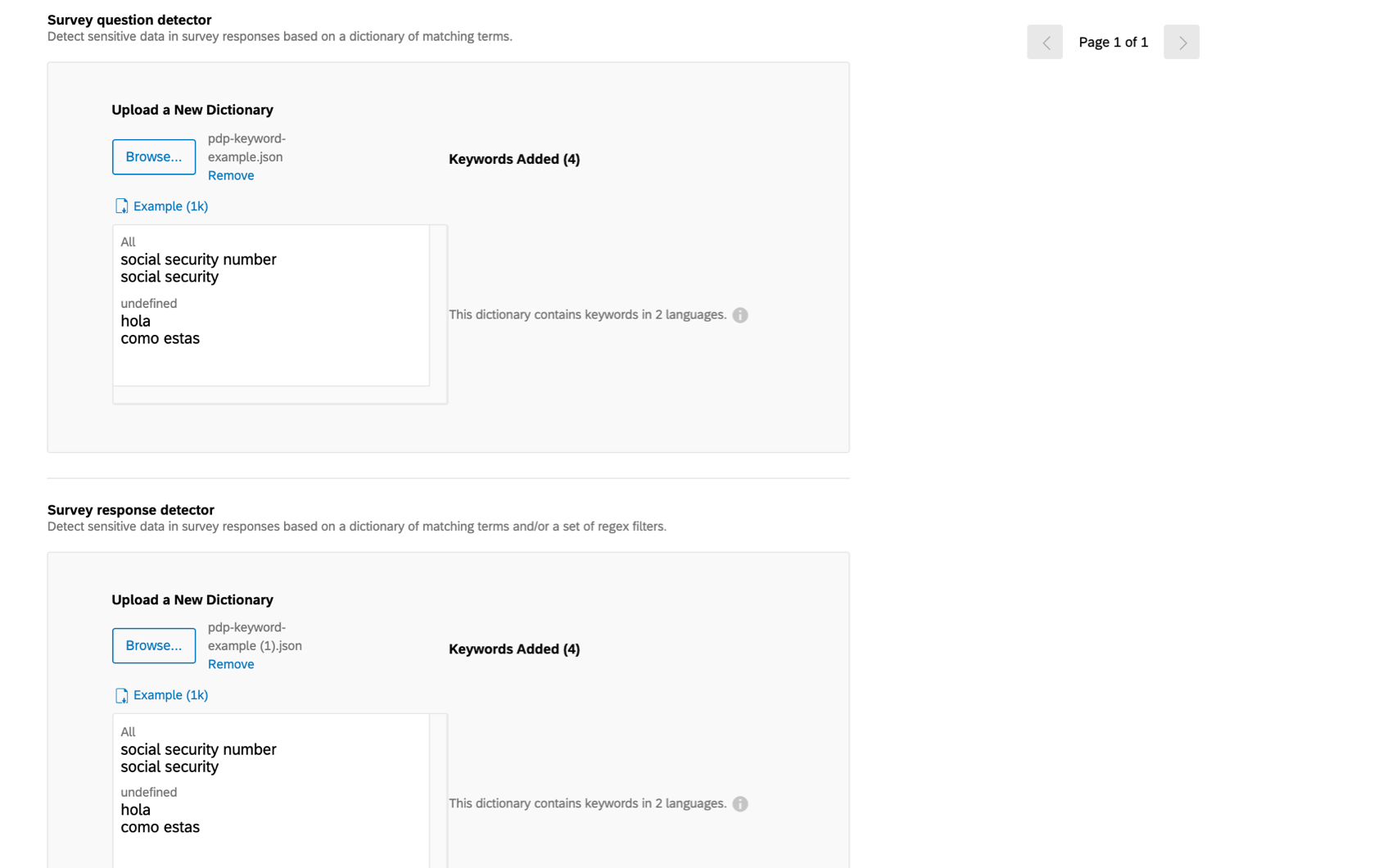
Qtip:キーワードが同じ場合は、アンケートの質問と回答の両方で 1 つのファイルを作成することができますが、必ず両方のフィールドにアップロードしてください!

{kind=link}
{kind=link}
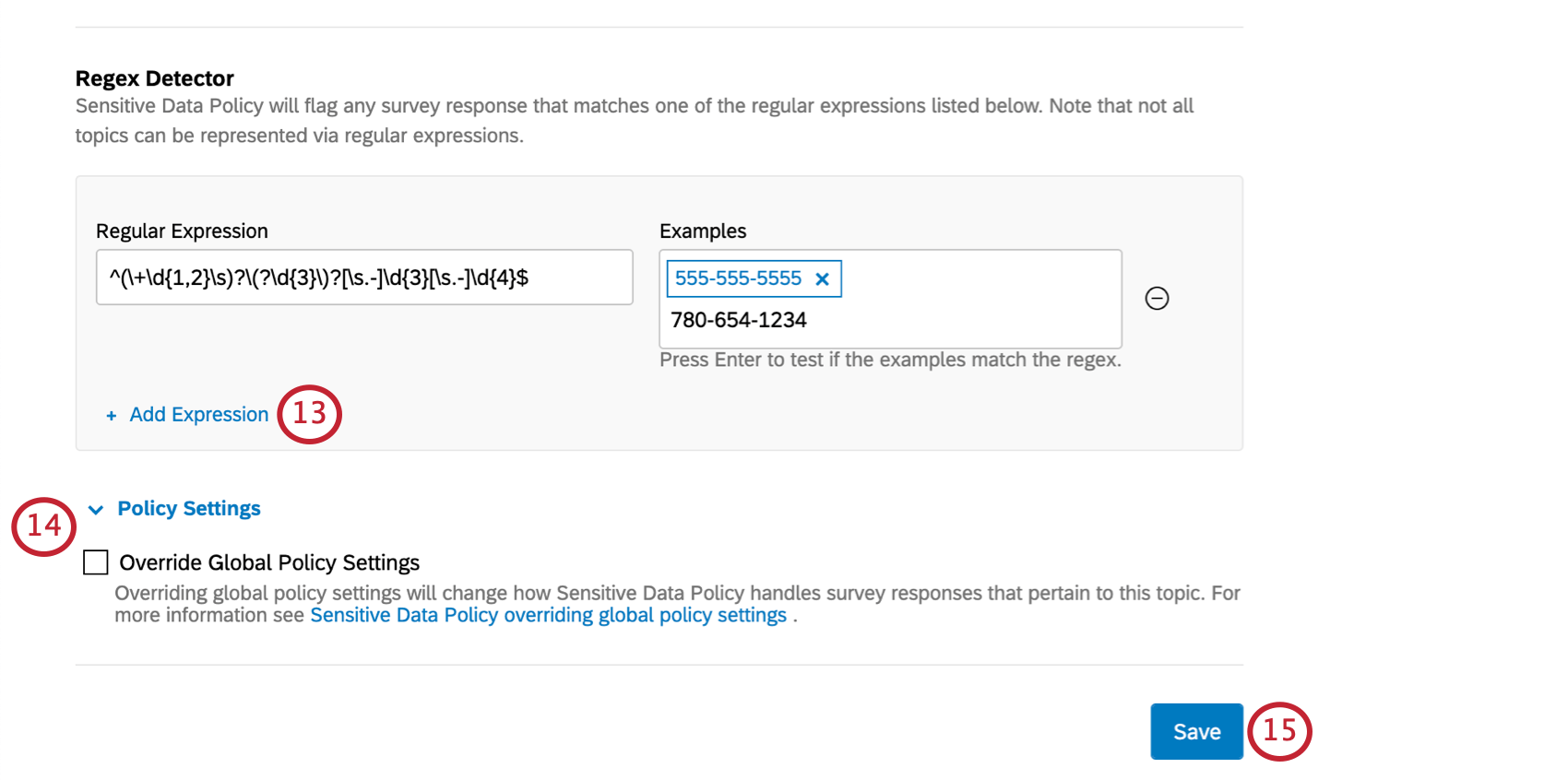
Qtip:正規表現は技術的にカスタムコーディングとなるため、クアルトリクスサポートではアドバイスできません。しかし、これらのリソースをチェックすることで、より多くの助けを得ることができる:
注意: 正規表現は常に大文字小文字を区別せずに評価されます。
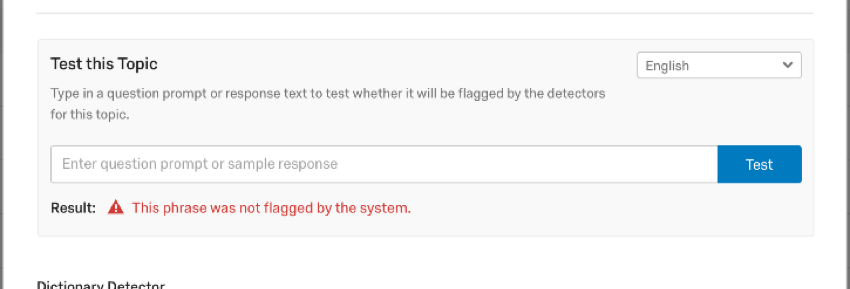
Qtip:「このトピックをテストする」セクションを使用して、ランダム化機能を使ってフレーズや単語がどのようにフラグを立てるかをテストしてください。これは、カスタムトピックを正しく設定したかどうかを確認するのに役立ちます。

{kind=link}
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!