派生属性(デザイナー)
このページの内容
派生属性について
派生属性は、既存の属性や分類結果に基づいて作成される属性です。これらの派生属性は、標準属性と同じように、ダッシュボード、フィルター、およびカテゴリー・ルールで使用することができます。
通常の属性は、任意の数の派生属性にマッピングすることができます。派生属性を使用して別の派生属性を作成することはできません。
派生属性の種類
作成できる派生属性は4種類あります。既存の属性のフィールドタイプによって、使用できる派生属性の種類が決まります。
- 次元ルックアップ:テキスト属性と数値属性で利用可能。標準属性を、標準属性に基づく別の関連属性にマッピングできるようにします。例えば、通常の “city “属性は、派生した “region “属性にロールアップされるかもしれない。詳細は、次元ルックアップ属性を参照してください。
- 範囲のロールアップ:数値属性と日付属性で利用可能。標準属性の範囲を別の関連属性範囲にマッピングできるようにする。例えば、通常の “age “属性は、派生した “age group “属性にロールアップすることができる。詳しくはレンジ・ロールアップ属性を参照。
- 満足度スコア:数値属性でのみ利用可能。満足度関連の質問に対する回答に基づいて、企業の製品やサービスに忠実な顧客の割合を表示できます。詳しくは満足スコアリング属性をご覧ください。
- カテゴリー派生属性(CDA):この属性はカテゴリーモデルから作成されます。構造化されていないテキストから属性(話題になっている製品や著者の性別など)を導き出すことで、分類結果を構造化データに変換できます。詳細はカテゴリー派生属性を参照。
次元ルックアップ属性
このセクションでは、ディメンジョン・ルックアップ属性の作成方法について説明します。
ルックアップデータファイルの準備
XM Discoverでディメンジョン・ルックアップ属性を作成する前に、まずルックアップ・データを含むデータ・ファイルを準備する必要があります。これは、以下の書式に従ったデータでスプレッドシートを作成することで可能です:
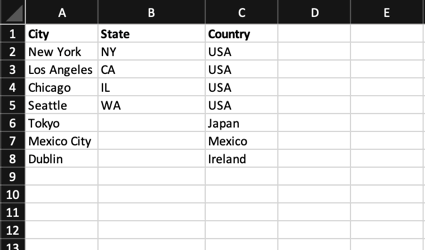
- A列には、あなたの標準的な属性値を入れてください。これは、派生属性を作成するために使用する属性でなければなりません。
- B列、C列などには、対応する派生属性値を入れます。同じソース属性に基づいている限り、ファイルに複数の派生属性を含めることができます。
- ファイルをXLSまたはXLSX形式で保存します。
また、ファイルを作成する際には、以下の点にご注意ください:
- ファイルに空の値が含まれている場合、XM Discoverでは “undefined “として表示されます。
- データセットにはまだ存在しないが、後で現れると予想される属性値を含めることができる。これらの値がプロジェクトにアップロードされると、ルックアップデータファイルに従って自動的にマッピングされます。
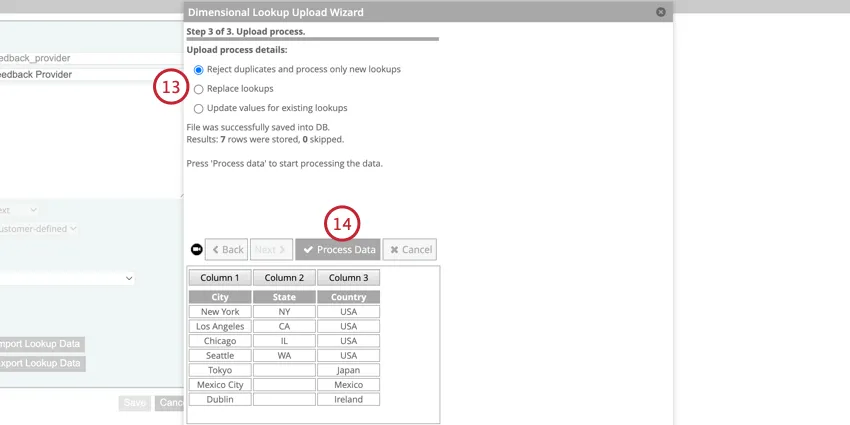
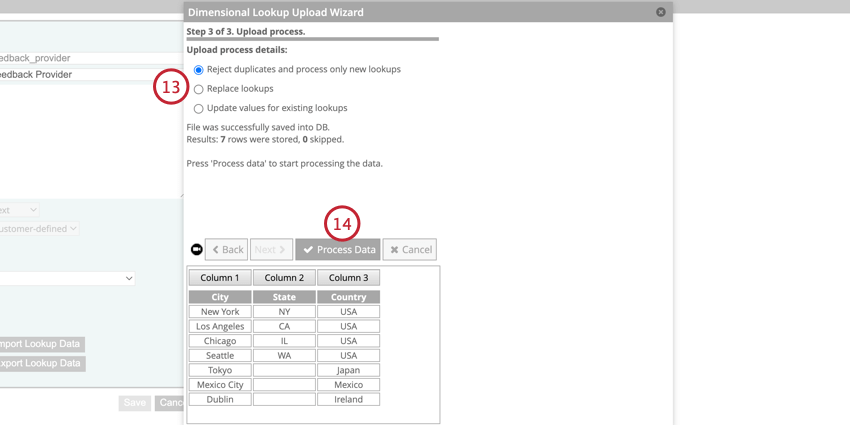
例: この例は、”city “標準属性に基づいて “country “と “state “の派生属性を作成するためのデータ・ファイルを示している。

次元ルックアップ属性の作成
ルックアップ・データ・ファイルを準備したら、XM Discoverで次元ルックアップ属性を作成できます。
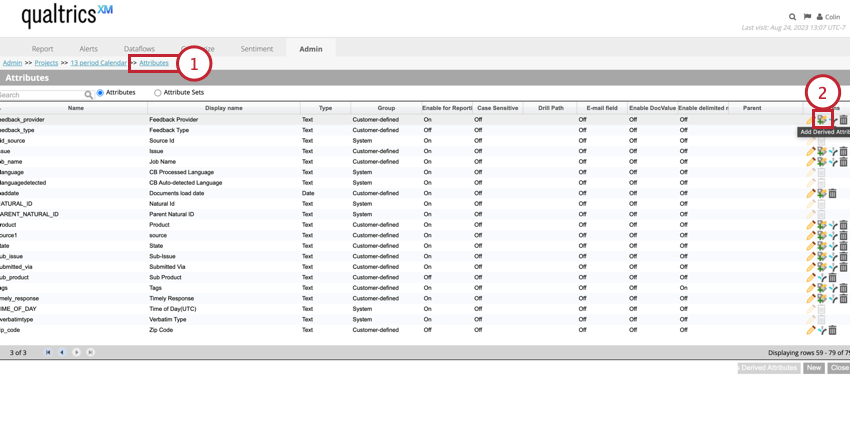
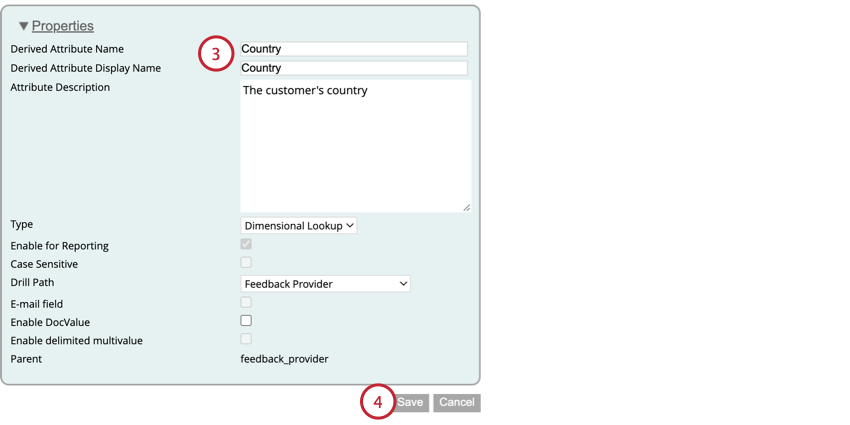
- これらのオプションのほとんどは、好きなように設定できる。ただし、TypeがDimensional Lookupに設定されていることを確認してください。
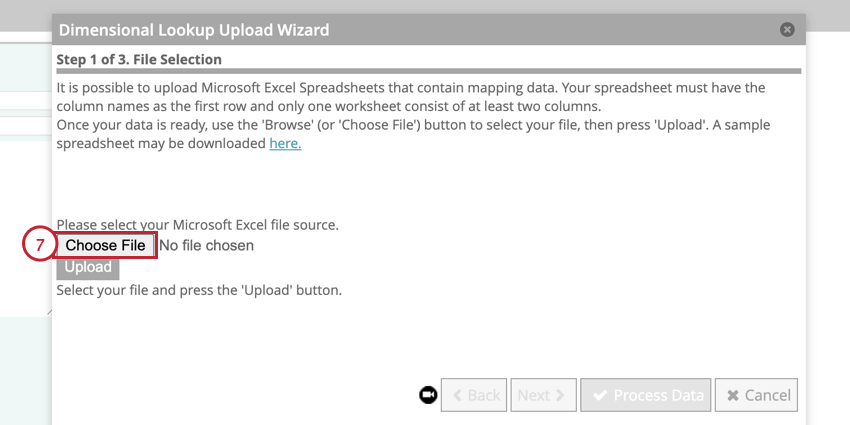
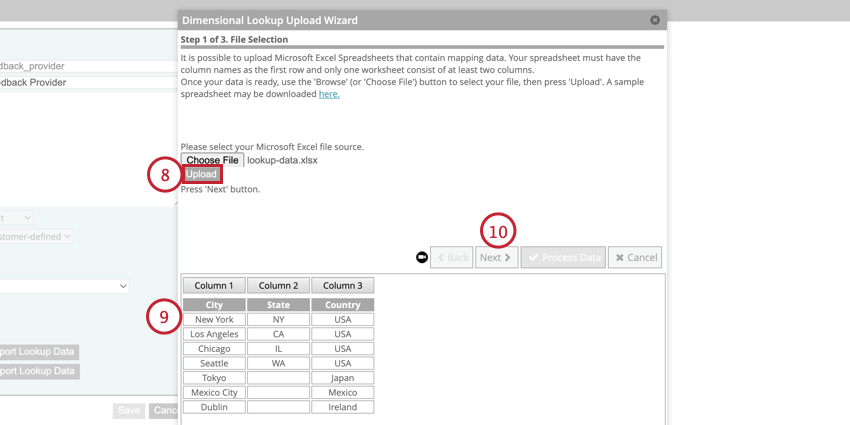
Qtip:変更が必要な場合は、データ・ルックアップ・ファイルを編集し、「Choose File(ファイルを選択)」→「Upload(アップロード)」をクリックして再アップロードしてください。
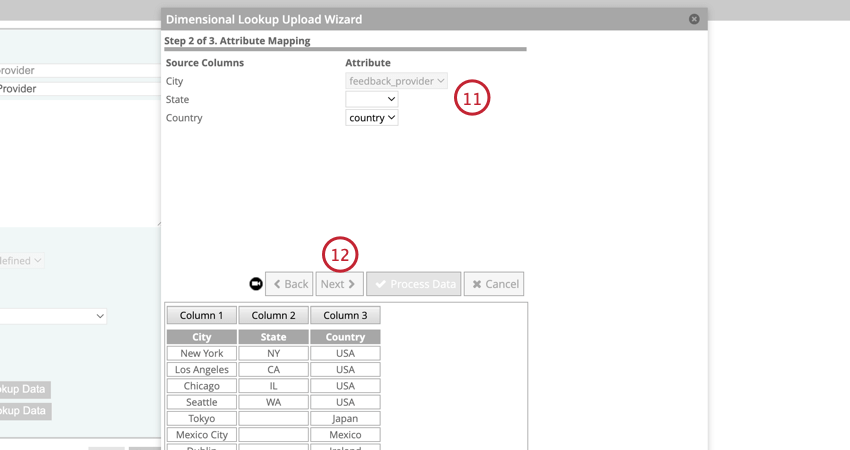
Qtip:複数の派生属性のルックアップデータを一度にインポートする場合、マッピングを空白のままにしておくと、派生属性のマッピングがクリアされます。これは、ルックアップ・データ・ファイルの行の値が空白であるかのように、値を「未定義」として記録する。インポート処理の後半で「ルックアップを置き換える」オプションを選択しない限り、これは既存のルックアップを置き換えることはない。
- 複製を拒否し、新しい検索のみを処理する:新しい検索が追加され、既存の検索は無視されます。新しい値が既存の値を置き換えることはなく、空の値が既存の値を削除することもない。
- ルックアップを置き換える:新しいマッピングが処理される前に、以前にアップロードされたマッピングはすべて削除される。ルックアップをアップロードしたファイルとまったく同じにしたい場合は、このオプションを使用します。以前は利用可能だったルックアップがファイルにない場合、これらのルックアップは削除されます。
- 既存のルックアップの値を更新する:新規ルックアップと既存ルックアップの両方が処理される。既存のルックアップの場合、アップロードされた新しい値は既存の値を置き換えるが、空の値は既存の値を置き換えない。
Qtip:このジョブの進行状況は、DataflowsタブのImport Lookup Dataデータフローで確認できます。
範囲ロールアップ属性
このセクションでは、レンジ・ロールアップ属性の作成方法について説明します。範囲ロールアップ属性には、ソース属性のタイプに応じて2つの異なるタイプがあります:
- カスタム範囲:ソース属性が数値フィールドの場合、異なる範囲バケットカテゴリを作成することができます。
- カスタム期間:ソース属性が日付フィールドの場合、異なる日付範囲カテゴリを作成できます。
レンジのロールアップ属性を作成する:
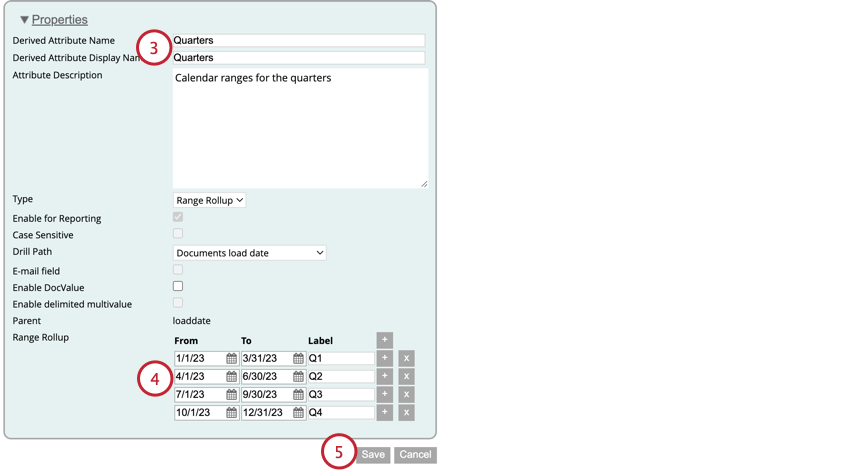
- これらのオプションのほとんどは、好きなように設定できる。ただし、TypeがRange Rollupになっていることを確認してください。

範囲ロールアップ属性を作成したら、レポートに適用することができます。
カスタム・レンジ
以下の手順に従って、数値フィールドに基づく派生属性のカスタム範囲を作成してください。
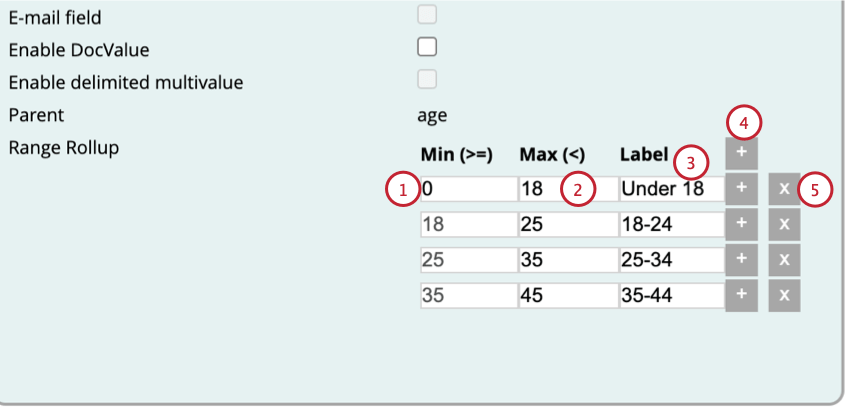
Qtip:あなたの最大値は、自動的にあなたの属性の次へ範囲の最小値になります。
Qtip:複数の範囲を追加する場合、範囲が重なったり隙間ができたりしないようにしてください。ある範囲の最大値は、自動的にそれに続く範囲の最小値となる。
カスタム期間
以下の手順に従って、日付フィールドに基づく派生属性のカスタム期間を作成してください。
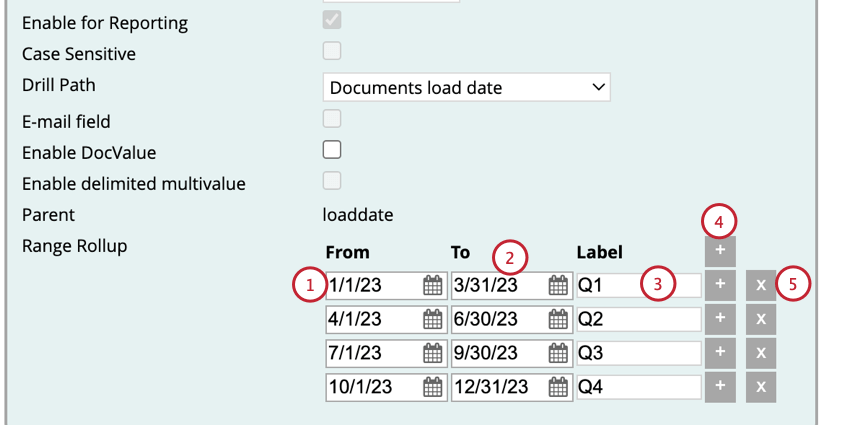
Qtip:複数のピリオドを追加する場合、ピリオドが重なることはありません。しかし、期間と期間の間にギャップが生じることもある。
満足スコア 属性
満足度スコア属性を作成し、ロイヤルティの高い顧客の割合を調べることができます。満足度スコアは、任意の数値属性に基づいて作成することができる。
満足度スコアは、アンケート調査に対する顧客の回答に基づいて算出される。例えば、顧客に企業のサービスを1~5の5段階で評価してもらい、この評価基準に基づいて満足度スコアを算出することができます。また、複数の評価指標を組み合わせて、1つの満足度スコアとして計算することもできます。
満足度スコアは以下の式で算出される。
満足度スコア = ([最もロイヤルティが高い人数] – [最もロイヤルティが低い人数]) / 合計 * 100
QTip:満足度スコア計算に Null 値を含めるオプションを有効にしている場合、この計算の合計が異なることがあります。
満足スコア属性の作成
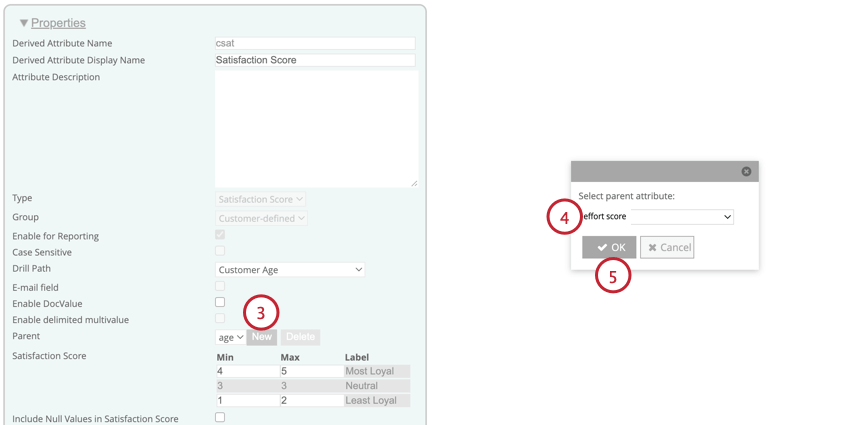
満足度スコア属性を作成するには、以下の手順に従ってください:
- これらの設定のほとんどは好きなようにできる。ただし、属性タイプとして「満足スコア」を選択してください。
- 有効にすると、満足度スコア計算に Null 値を含めるには 、質問に回答しなかった回答も総回答数に含めます。このオプションを有効または無効にすると、満足度スコアの計算方法に影響します。
- これは計算に使用されるソース属性であるため、Parentフィールドを調整しないでください。それは、ステップ2で選択した属性と同じ名前でなければなりません。
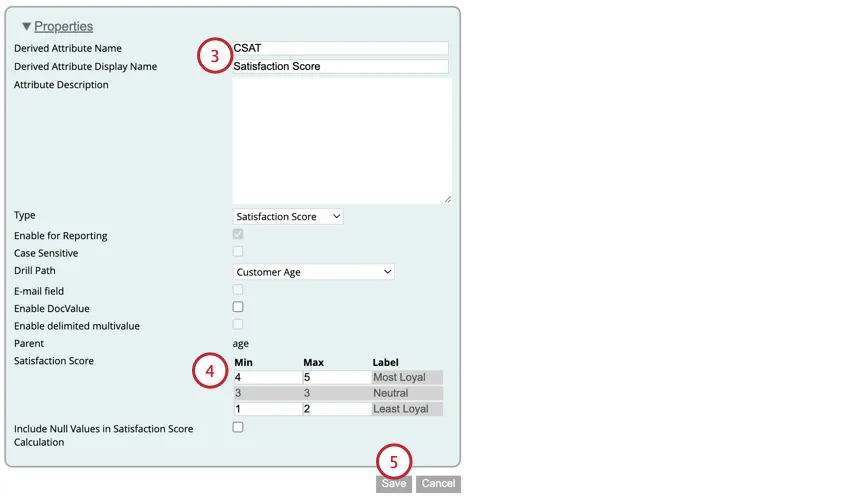
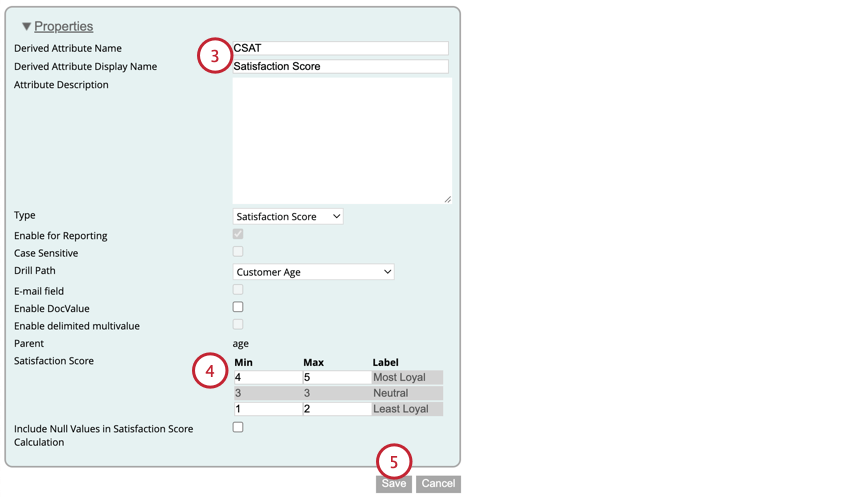
- 最も忠実な顧客:忠実な顧客とみなされるための最小スコアと最大スコアを入力します。5尺度では、これは通常4と5である。
- 最も忠実でない:忠実でないと見なされる顧客の最小スコアと最大スコアを入力します。5尺度では、これは通常1と2である。
- 中立:中立(ロイヤルティがない、またはロイヤルティがない)と見なされる顧客の最小スコアと最大スコア。中立スコアの範囲は、Most LoyalとLeast Loyalの範囲に基づいて自動的に生成される。
属性を作成したら、レポートに適用してください。
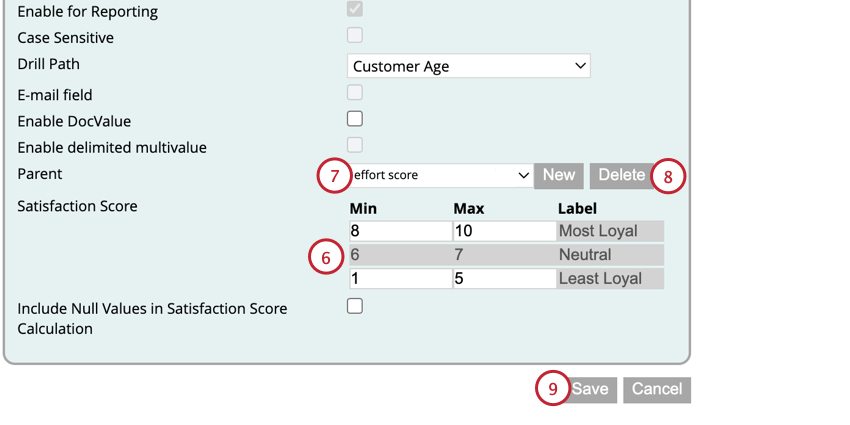
複数の属性に基づく満足スコアリング
必要に応じて、いくつかの数値属性に基づいて満足度スコアを計算することができます。
カテゴリー派生属性
カテゴリー・モデルを使用して属性を作成することができます。これにより、顧客フィードバックアンケートで議論されている製品など、構造化されていないテキストから属性を導き出すことができます。
Qtip:カテゴリー派生属性は文書全体に適用されます。インサイトを文レベルで表示したい場合は、カテゴリーモデルを文書に適用してください。
Qtip:モデル内の個々のカテゴリーがすでにそこから派生した属性を持っている場合、モデル全体に基づいて属性を派生させることはできず、このオプションはなくなります。
- モデル全体に基づいて属性を導出する場合は、代わりにモデル内の各レベルの名前を追加する必要があります。以下の例では、3つのレベルがある。最初のレベルはサービスの種類をカバーするもので、この場合は航空会社である。第二レベルは、サービス提供国をカバーする。第3レベルは、各国の航空会社をカバーする。

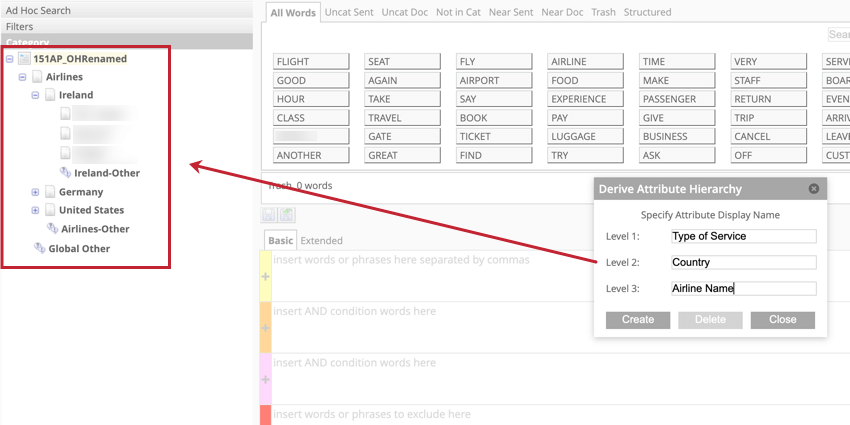
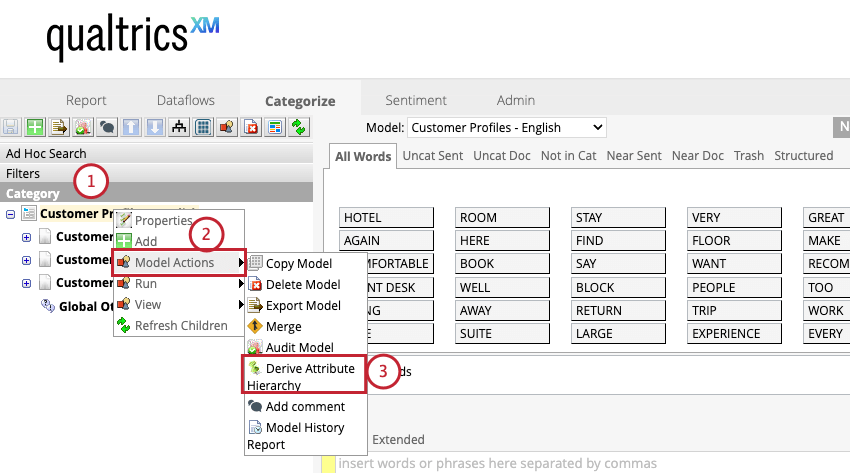
Qtip:カテゴリーモデルに基づいて属性を削除するには、そのモデルを右クリックして、「モデルアクション」メニューから「属性の導出」を選択します。表示されたウィンドウで、Deleteをクリックする。
属性を作成すると、以下のロジックを使用してデータに適用されます:
- 既存のデータには、このカテゴリー・モデルの分類を実行しない限り、属性は適用されません。
- 新しいデータには、必要に応じて属性が付けられる。
- カテゴリーモデルを編集する場合は、派生属性名も編集してください。
- 複数のカテゴリー派生属性がある場合、文書には複数の属性が付けられる可能性があります。もし文書がどの値とも一致しない場合、”undefined “というタグが付けられる。
派生属性の適用
ディメンジョン・ルックアップ、レンジ・ロールアップ、または満足度スコア属性を作成した後、レポートで使用できるようにするには、それらを処理する必要があります。
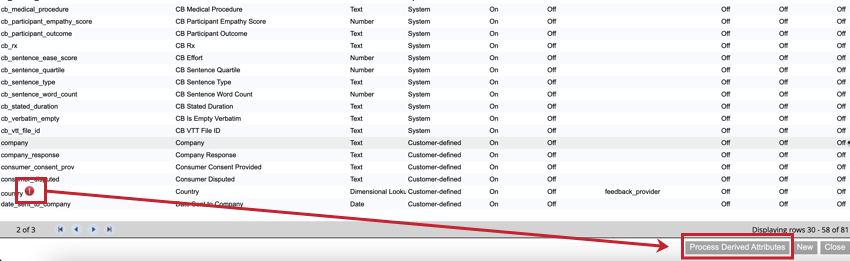
未適用のマッピングがある場合、属性名の次へ赤い感嘆符(!)が表示されます。派生属性を適用するには、Process Derived Attributesをクリックします。XM Discoverはすべての文書を処理し、関連する属性を適用します。
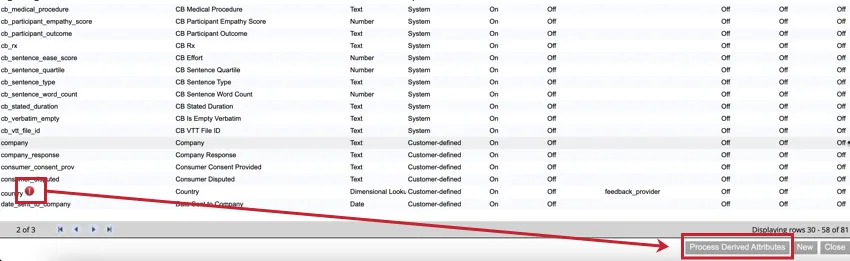
Qtip:新しいデータがプロジェクトにロードされると、派生属性が自動的に適用されます。派生属性を処理する必要があるのは、既存のデータでその属性を利用したい場合だけです。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!