
Attributes Basic Overview
What's on this page
About Attributes Basic Overview
An attribute is a property of a document that characterizes it in some way. Common examples of attributes include the author name and creation date.
You can create custom attributes for your projects. There are also a variety of system attributes for you to use. You can also set up intelligent entities which automatically detect attributes based on the document’s text (for example, when a brand or a product is mentioned in a customer’s feedback).
After you add attributes, it’s possible to create additional derived attributes to further understand your data. You can also organize your attributes into attribute sets, making it easier to report on these attributes.
Attribute Field Types
The following field types are supported for attributes:
- Text
- Number
- Date
Accessing Attributes
Attributes are managed on a project level. To access the attributes for a project:
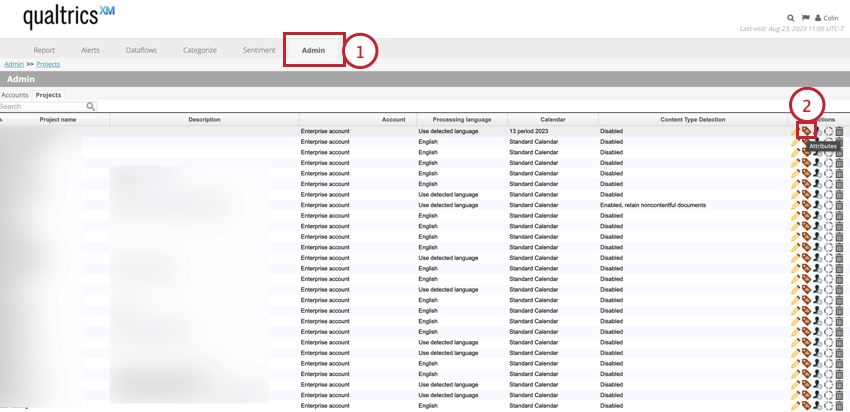
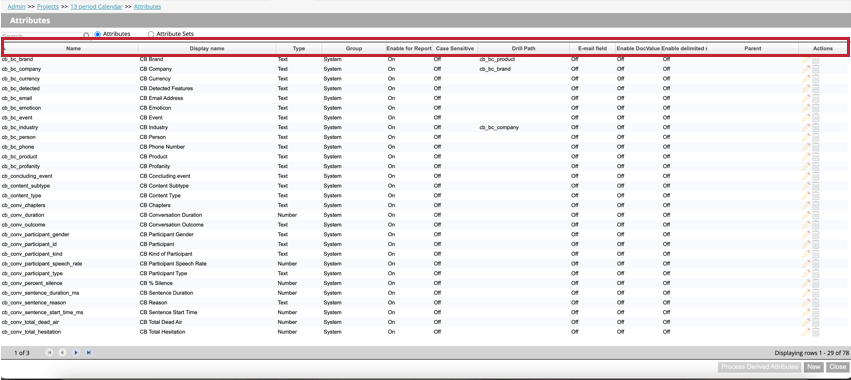
This opens the attributes table containing the following information about each attribute in the project:
{kind=link}
- Name: The attribute’s system name. See Attribute Naming for naming requirements.
- Display name: The attribute’s display name, which appears in reports, filters, etc. See Attribute Naming for naming requirements.
- Type: The attribute’s type. For standard attributes, values can be Text, Number, or Date. For derived attributes, values can be Dimensional Lookup, Range Rollup, Satisfaction Score, or Derived From Category.
- Group: The attribute’s group that represents its origin and intended use. Values be one of the following:
- Category derived: attributes derived from models or categories.
- System: system attributes.
- Customer-defined: all custom attributes available from the data source of your choice (including dimensional lookups, range roll-ups, and satisfaction scores).
- Scorecard: attributes used in intelligent scoring.
- Enable for Reporting: Shows if an attribute is enabled for reporting (On) or not (Off).
- Case Sensitive: Shows if an attribute is marked as case-sensitive when displaying values in Document Explorer, Source Highlighter, Custom Export, and sentences preview export.
- Drill Path: Shows custom drill path if it was defined. If there is no custom drill path, then this field will be blank.
- E-mail field: Shows if an attribute contains an email address.
- Enable DocValue: Shows if ElasticSearch doc values are used for this attribute.
- Enable delimited multivalue: Shows if multiple values are enabled for this attribute.
- Parent: If the attribute is a derived attribute, then this field will display “parent.” This field will be blank for custom and standard attributes.
- Actions: Perform the following actions on the attribute:
- Edit the attribute
- Create a derived attribute
- Delete the attribute
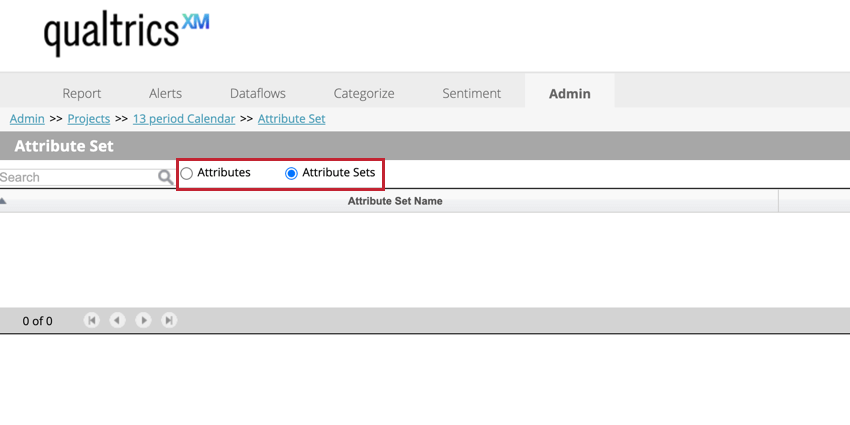
Managing Attribute Sets
Use the Attribute Sets toggle at the top of the page to view your attribute sets. This allows you to create new attribute sets and delete existing ones. Select Attributes to view your individual attributes.
{kind=link}
System Attributes
There are a number of system attributes, such as Document Date and Source ID, that are automatically applied to each document uploaded to XM Discover. These attributes help you manage feedback within XM Discover, as well as enrich it with XM data derived by the NLP engine.
Below is a table of the different system attributes, grouped by the different categories of attributes. This table contains the following information about each attribute:
- Name: The attribute name that appears in reports, filters, etc.
- System Name: The attribute’s system name which you use to query or filter your data.
- Type: The attribute type.
- Description: A brief description of the attribute’s meaning and purpose.
- Granularity: The level of data granularity associated with an attribute. For example, Sentence Word Count is only relevant on a sentence level, while Document Date is available both for a document and for each sentence in that document.
IDs and References
| Name | System Name | Type | Description | Granularity |
|---|---|---|---|---|
| Document ID | _id_document | number | The unique system ID of the document. Unlike Natural ID, Document ID is generated automatically by XM Discover. | document and sentence |
| Natural ID | natural_id | text | The unique Natural ID of the document. Unlike Document ID, Natural ID is generated from the fields specified when you upload a document. Natural ID is used by duplicate detection and can also be useful when tracing the document to its source outside of XM Discover. | document and sentence |
| Sentence ID | _id_sentence | number | The unique ID of the sentence. This ID is generated automatically. | sentence |
| Session ID | _id_batch | number | The unique ID of the upload session during which the document was loaded into XM Discover. This ID is generated automatically. | document and sentence |
| Source ID | _id_source | text | The name of the data source. Depending on the data source, it can be either generated automatically or from the fields specified when you upload the document. | document and sentence |
| Verbatim ID | _id_verbatim | number | The unique ID of the verbatim. This ID is generated automatically. | verbatim and sentence |
| Verbatim Type | _verbatimtype | text | The name of the verbatim field. This attribute lets you distinguish sentences by different verbatim fields in your data. | verbatim and sentence |
Date and Time
| Name | System Name | Type | Description | Granularity |
|---|---|---|---|---|
| CB Date of Creation | cb_date_created_utc | date, Epoch time in milliseconds | The date the document was added to XM Discover. This date is generated automatically. | document and sentence |
| CB Update Date | cb_date_updated | date, Epoch time in milliseconds | The date the document was last updated. Updates do not include categorization changes. This date is generated automatically. | document |
| Document Date | _doc_time | date, ISO 8601 in seconds | The primary date of the document. Document Date is used in reports, trend reports, alerts, etc. This date is generated from the fields specified when you upload the document. | document and sentence |
| Document Date Without Time | _doc_date | date, yyyy-mm-dd format | The date of the document without the timestamp. This date is generated from the fields specified when you upload the document. | document and sentence |
| Time of Day | time_of_day | text, hh:mm format | The time of the document, rolled down to the hour. For example, comments posted at 9:09 and 9:59 will both roll up to 9:00. This attribute is generated automatically. | document and sentence |
Word Counts and Position
| Name | System Name | Type | Description | Granularity |
|---|---|---|---|---|
| CB Document Word Count | cb_document_word_count | number | The number of words in a document. Document word count is a sum of all sentence word counts. | document and sentence |
| CB Sentence Quartile | cb_sentence_quartile | number | The part of the verbatim a sentence falls into. This attribute can have 1 of the following values: 1, 2, 3, or 4. Each section represents 25% of the entire verbatim length. | sentence |
| CB Sentence Word Count | cb_sentence_word_count | number | The number of words in a sentence. | sentence |
That's great! Thank you for your feedback!
Thank you for your feedback!