Filtrer les interactions (Studio)
Suite
Customer Experience
Produit
Qualtrics
Contenus de cette page
À propos du filtrage des interactions
Vous pouvez filtrer les documents en fonction de la date et d’autres paramètres. Cela peut s’avérer utile pour retrouver des réponses particulières ou pour décider de ce qu’il convient de supprimer ou d’exporter.
Astuce : Les filtres appliqués à l’âge des interactions seront répercutés dans les exportations.
Astuce : Filtrer les commentaires par texte fait toujours apparaître toutes les phrases dans le volet Résultats.
Filtrer les interactions
Astuce : Vous devez disposer de l’autorisation Voir l’explorateur d’interactions pour visiter cette page.
Cliquez sur le menu Espaces.
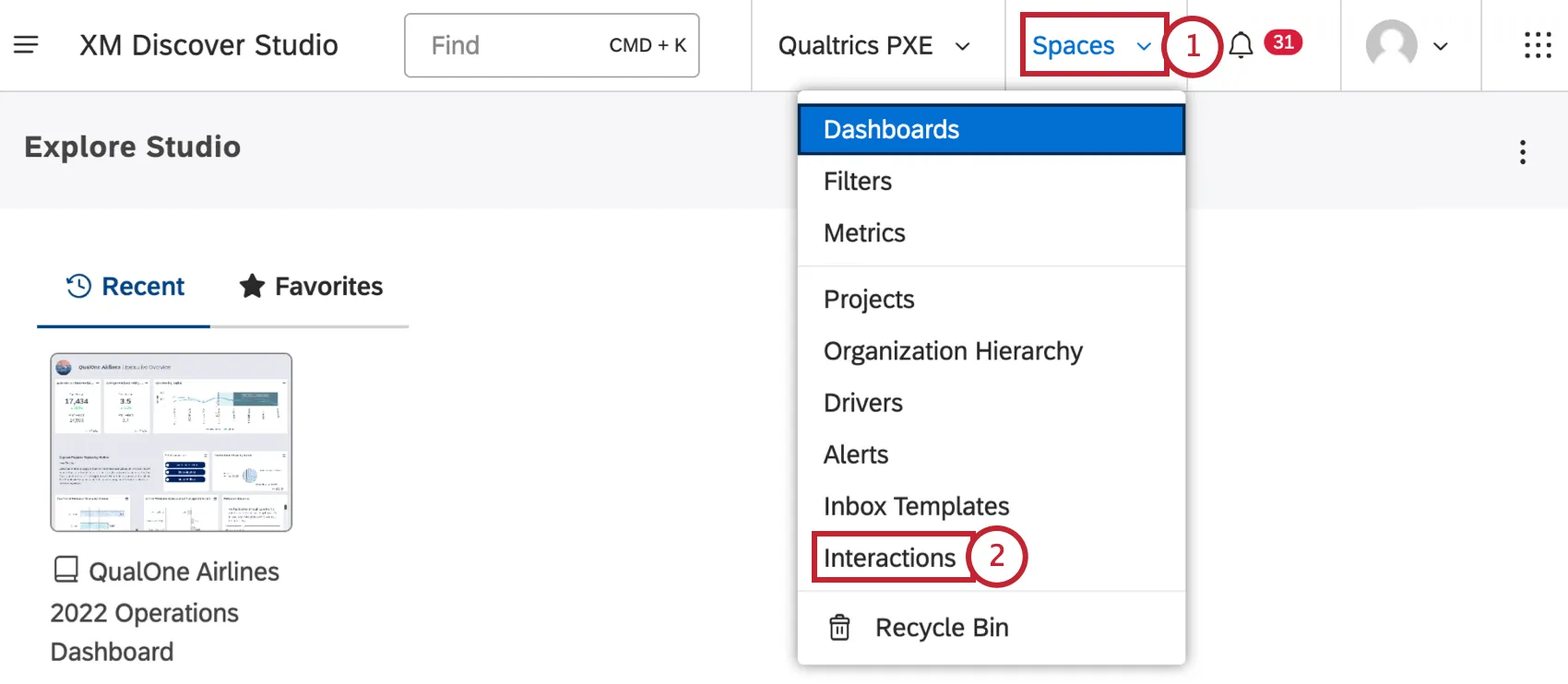
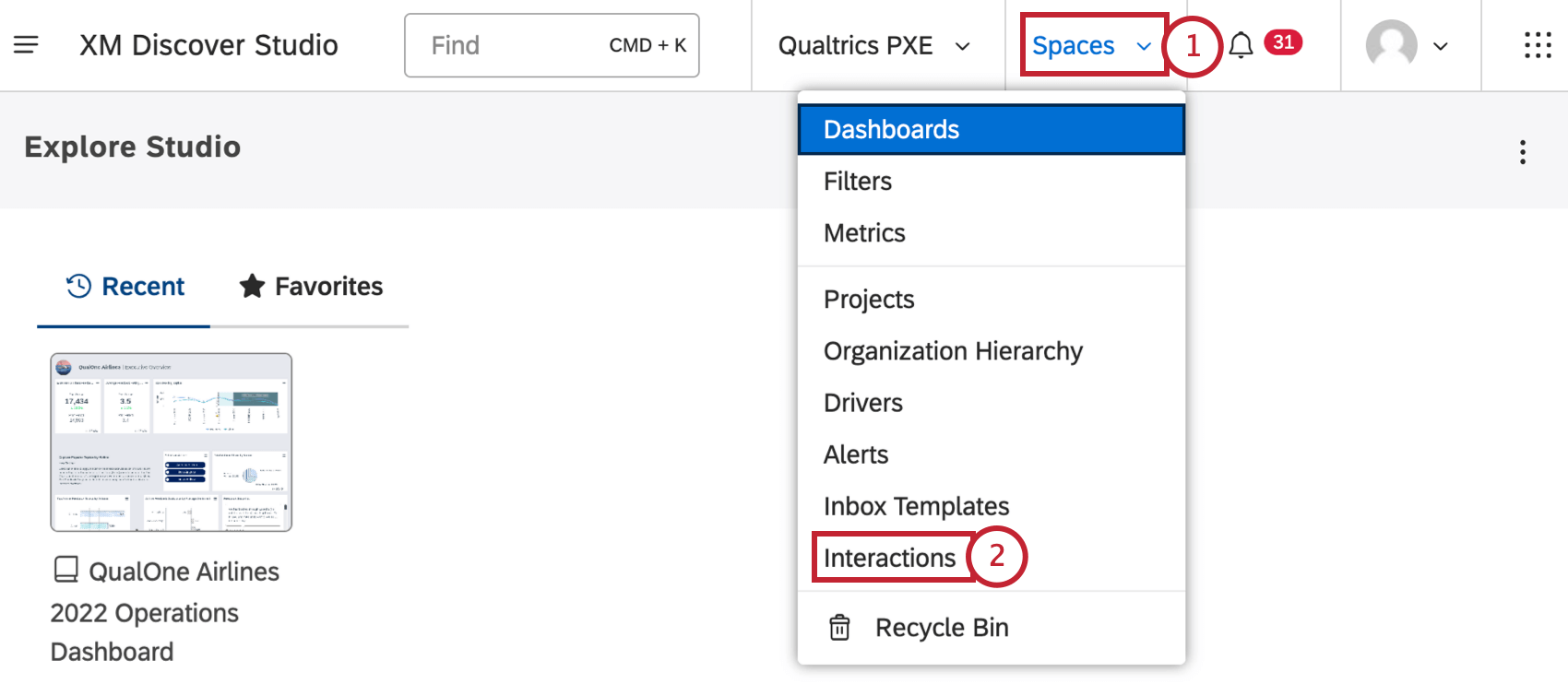
Sélectionnez Interactions.
Utilisez le menu déroulant Projet pour afficher les interactions associées à différents projets.

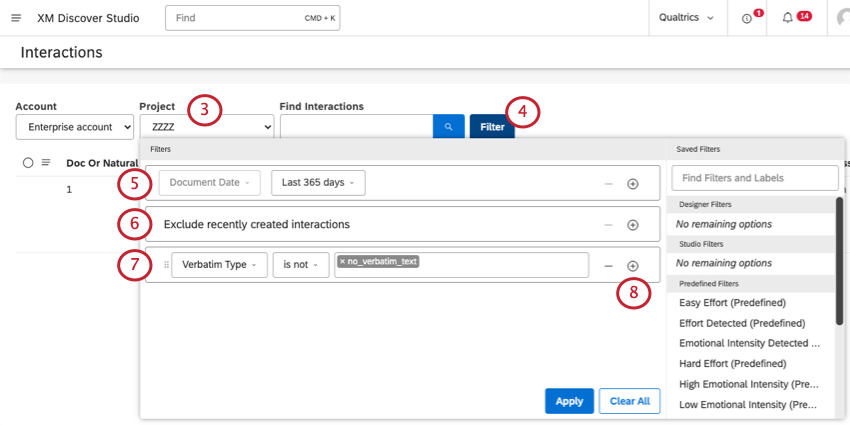
Astuce : Vous devrez peut-être aussi choisir un compte et un fournisseur de contenu, en fonction de ce à quoi vous avez accès.
Cliquez sur Filtre.
Ajustez le filtre de la date du document si nécessaire. Par défaut, seuls les documents enregistrés dans les 30 jours sont pris en compte.
Astuce : Vous ne pouvez pas supprimer le filtre de la date du document.
Les interactions créées au cours des 10 dernières minutes seront exclues afin de garantir que seules les données prêtes à l’emploi sont incluses dans vos résultats.
Astuce : Vous ne pouvez pas supprimer ce filtre.
Par défaut, les verbatims sans texte seront exclus des résultats. Vous pouvez supprimer cette condition en cliquant sur le signe moins ( – ).
Pour ajouter d’autres conditions, cliquez sur le signe plus ( + ).
Sélectionnez le type de condition que vous souhaitez créer :
- Date du document: Filtrez les documents en fonction de leur date de création. Pour plus de détails, voir Filtres de plage de dates.
- Texte: Recherche de documents contenant des mots ou des phrases spécifiques. Voir Filtres de texte pour savoir comment fonctionne la recherche.
- Sujets: Filtrez les informations en fonction d’un modèle de catégorie ou de ses thèmes.
- Attributs: Filtrez les documents en fonction des valeurs d’un attribut structuré.
- NLP: Filtrez les documents en fonction des mots et autres entités linguistiques détectés par le moteur de traitement du langage naturel (NLP) de XM Discover. Voir la section Conditions de la PNL ci-dessous.
Vous pouvez également sélectionner des filtres enregistrés à droite.
Astuce : Apprenez à enregistrer les filtres à la page Utilisation des filtres.
Lorsque vous avez terminé, cliquez sur Appliquer pour filtrer les interactions.
Astuce : pour revenir aux filtres par défaut, sélectionnez Tout effacer.
Conditions de la PNL
Pour les conditions de traitement du langage naturel (NLP), vous disposez des options suivantes :
- Mots: Filtrez les données par mots ou types de mots. Vos options comprennent :
- Tous les mots: Filtrez les données en fonction des mots de votre choix.
- CB Organisation: Filtrez les données en fonction des mentions de l’organisation.
- CB Company: Filtrer les données par mentions d’entreprises.
- CB Currency: Filtrez les données par quantités monétaires, par exemple en faisant varier les noms, symboles et abréviations des devises.
- CB Email Address: Filtrez les données en fonction des adresses électroniques mentionnées dans les commentaires.
- CB Emoticon: Filtre les données en fonction des emojis et des émoticônes utilisés dans les commentaires.
- Évènement CB: Filtrez les données en fonction des jours fériés et des évènements mentionnés dans les commentaires.
- CB Industrie: Filtrez les données par secteur d’activité.
- CB Person: Filtre les données sur les noms des personnes mentionnées dans le retour d’information.
- Numéro de téléphone CB: Filtrez les données en fonction des numéros de téléphone mentionnés dans les commentaires.
- CB Product: Filtrer les données par mentions de produits.
- CB Profanity: Filtre les données en fonction des mots blasphématoires.
- Mots associés: Filtrez les données par paires de mots associés.
- Hashtags: Filtrez les données par hashtags (mots ou phrases non espacées qui commencent par un symbole dièse ( # )).
- Enrichissement : Les enrichissements sont des données CX dérivées par le moteur NLU (compréhension du langage naturel) de XM Discover. Les enrichissements comprennent une variété de métadonnées ajoutées par le moteur NLU aux documents pendant le traitement au niveau de la phrase ou du document. Les enrichissements que vous pouvez filtrer sont les suivants :
- Chapitres CB: Filtrez les données par chapitres conversationnels, tels que Ouverture, Besoin, Vérification, Étape de solution et Clôture.
- Fonctions détectées par CB: Filtrez les données en fonction des fonctions NLP détectées. Par exemple, vous pouvez filtrer les données qui contiennent des mentions de l’industrie ou de l’organisation.
- CB Emotion: Filtrez les données en fonction des types d’émotion détectés par le moteur NLP, tels que la colère, la confusion, la déception, l’embarras, la peur, la frustration, la jalousie, la joie, l’amour, la tristesse, la surprise, la reconnaissance, la confiance ou autre.
- CB Type de phrase: Filtre les données en fonction du type de phrase.
- Type de contenu: Filtrez les informations selon qu’elles contiennent ou non du contenu. “Les données “Contentful” signifient qu’il y a une validation du contenu d’un avis, d’un retour client ou d’une conversation client. Les documents qui ne sont pas “contentful” n’ont pas de contenu valide (voir les sous-types ci-dessous).
- Sous-type de contenu: Filtrez davantage les informations vides en fonction de leurs sous-types, tels que les publicités, les coupons, les liens d’articles ou le type “non défini”. Astuce : En fonction des données dont vous disposez, il peut y avoir des enrichissements supplémentaires qui ne sont pas abordés ici.

- Langue : Filtrez les données par langue.
- Langue détectée automatiquement: Filtrer les données en fonction des langues détectées automatiquement. Cette fonction n’est utile que si la détection automatique de la langue est activée pour un projet.
- Langue traitée: Filtrez les données en fonction des langues dans lesquelles le retour d’information a été traité. Les langues non prises en charge par XM Discover sont signalées par la mention OTHER. Pour obtenir la Liste des langues prises en charge, contactez l’équipe d’assistance XM Discover.
Opérateurs
Les opérateurs permettent de définir le lien entre une condition de filtre choisie et la cible. Par exemple, si vous souhaitez n’inclure que les documents dont le sentiment est supérieur ou égal à 5, l’opérateur est “supérieur ou égal à”.
Voir la liste des opérateurs disponibles.
FAQs
Qu'est-ce qu'un modèle de catégorie ? Qu'est-ce qu'un sujet ?
Qu'est-ce qu'un modèle de catégorie ? Qu'est-ce qu'un sujet ?
Un sujet est un thème spécifique mentionné dans les avis ouverts que XM Discover capture à l'aide de modèles de catégorie. Un modèle de catégorie est une taxonomie hiérarchique basée sur des règles utilisée pour organiser les phrases en sujets.
Étant donné que les modèles de catégorie sont la manière dont XM Discover analyse les sujets, vous verrez « modèle de catégorie » et « sujet » utilisés de manière interchangeable sur l'ensemble de la plateforme.
Étant donné que les modèles de catégorie sont la manière dont XM Discover analyse les sujets, vous verrez « modèle de catégorie » et « sujet » utilisés de manière interchangeable sur l'ensemble de la plateforme.
De nombreuses pages de ce site ont été traduites de l'anglais en traduction automatique. Chez Qualtrics, nous avons accompli notre devoir de diligence pour trouver les meilleures traductions automatiques possibles. Toutefois, le résultat ne peut pas être constamment parfait. Le texte original en anglais est considéré comme la version officielle, et toute discordance entre l'original et les traductions automatiques ne pourra être considérée comme juridiquement contraignante.
C'est génial! Merci pour votre avis!
Merci pour votre avis!