XM Discover Link Inbound Connector (connecteur entrant)
Contenus de cette page
À propos du connecteur entrant XM Discover Link
Vous pouvez utiliser le connecteur entrant XM Discover Link pour pousser des données XM dans XM Discover via un point d’extrémité d’API REST tout en tirant parti de toutes les capacités offertes par le cadre des connecteurs, telles que le mappage des champs, les transformations, les filtres, l’observation des tâches, etc.
Astuce : nous recommandons d’utiliser le connecteur XM Discover Link Inbound Connector plutôt que l’API d’importation générale.
Formats de données pris en charge
Les types de données suivants ne sont pris en charge qu’au format JSON:
Avant de configurer le connecteur, créez un fichier échantillon représentant les champs que vous souhaitez importer dans XM Discover. Voir les pages liées ci-dessus pour plus d’informations sur les champs obligatoires et les formats de fichiers.
Des fichiers modèles sont également téléchargeables dans le connecteur pour des formats de données spécifiques :
- Discussion
- Chat (par défaut): Utiliser pour les données d’interactions numériques standard.
- Amazon Connect: À utiliser pour les interactions numériques spécifiques à Amazon Connect Chat.
- Appel
- Appel (par défaut): A utiliser pour les données de transcription d’appel standard.
- Verint: A utiliser pour les transcriptions d’appels spécifiques à Verint.
- Commentaires
- Dynamics 365: Utilisation pour les données de Microsoft Dynamics.
Création d’une tâche de connecteur entrant XM Discover Link
Astuce : L’autorisation “Manage Jobs” est requise pour utiliser cette fonction.

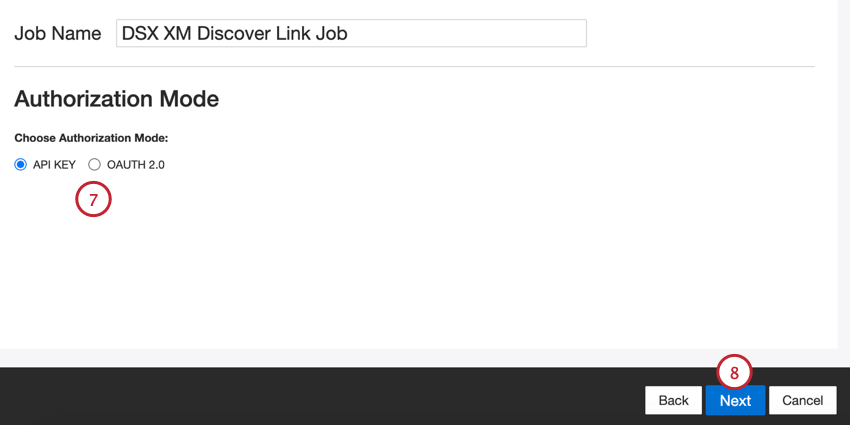
- Clé API: Connectez-vous à l’aide d’une clé API XM Discover.
- OAuth 2.0: Se connecter à l’aide d’un identifiant et d’un secret client fournis par le service d’authentification XM Discover. Contactez votre représentant Discover pour demander cette méthode. Astuce: Vous pouvez contacter votre représentant Discover directement par e-mail. Si vous ne disposez pas de leurs coordonnées, vous pouvez contacter l’équipe d’assistance Discover.

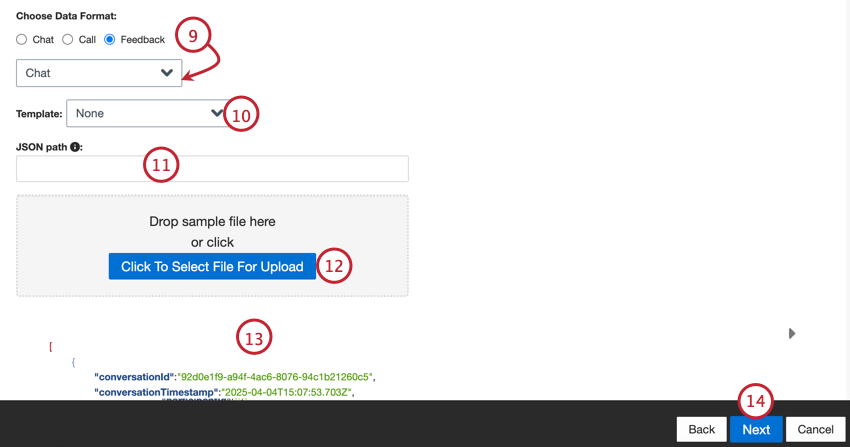
Astuce : Si vous avez sélectionné “retour d’information”, un deuxième menu apparaît pour vous permettre de choisir le type de données d’interaction incluses dans le retour d’information. Les options comprennent l’appel, le chat, l’e-mail, l’évaluateur, le réseau social et l’enquête en revue.
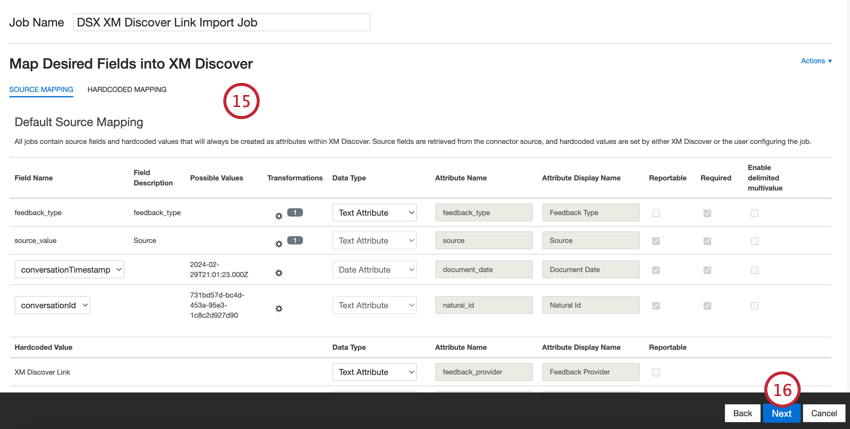
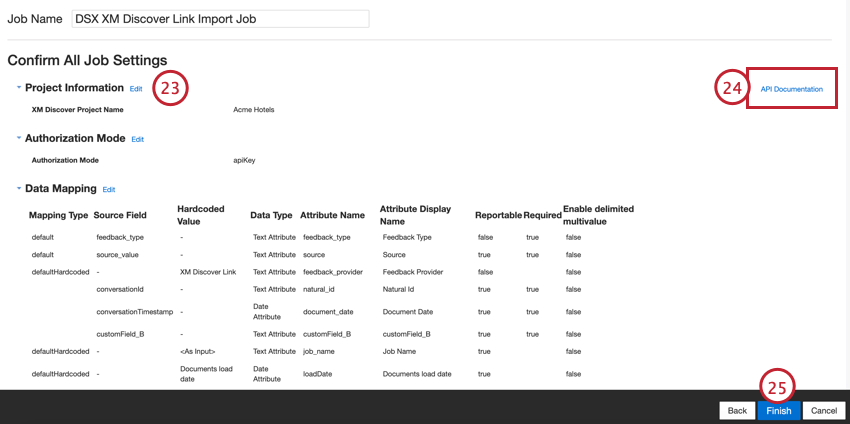
Mappage des données par défaut
Cette section contient des informations sur les champs par défaut des tâches de lien entrant XM Discover.
Lors du mappage de vos champs, les champs par défaut suivants sont disponibles :
{kind=link}
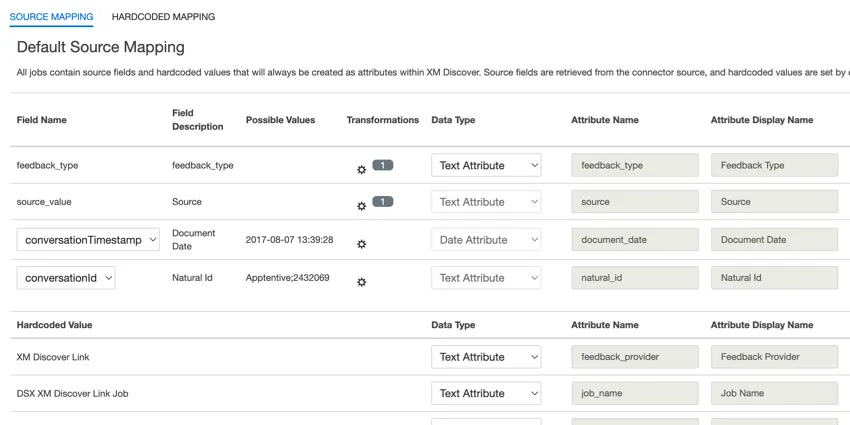
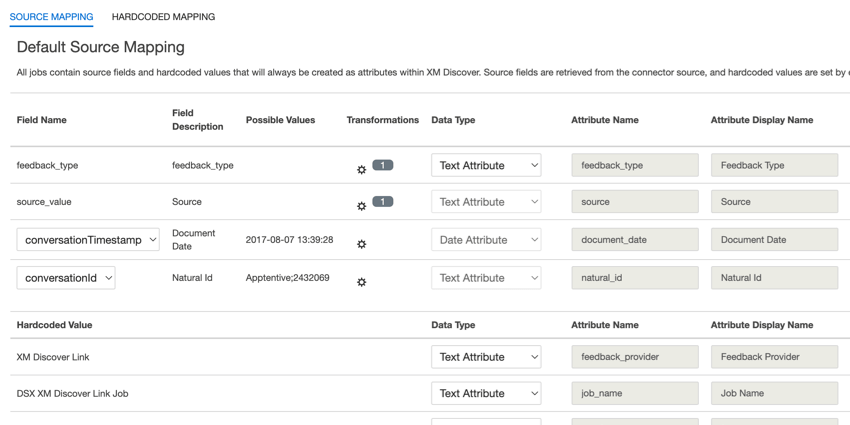
- feedback_type : Le type de retour d’information permet d’identifier les données en fonction de leur type. Cela est utile pour les rapports lorsque votre projet contient différents types de données (par exemple, des enquêtes et des commentaires sur les médias sociaux). Ce champ est modifiable. Par défaut, la valeur de cet attribut est fixée à :
- “call” pour les transcriptions d’appels
- “chat” pour les interactions numériques
- “feedback” pour un retour d’information individuel
- Vous pouvez utiliser des transformations personnalisées pour définir une valeur personnalisée.
- source: La source permet d’identifier les données obtenues à partir d’une source spécifique. Il peut s’agir de tout ce qui décrit l’origine des données, comme le nom d’une enquête ou d’une campagne de marketing mobile. Ce champ est modifiable. Par défaut, la valeur de cet attribut est fixée à “XM Discover Link” Vous pouvez utiliser la transformation personnalisée pour définir une valeur personnalisée.
- richVerbatim: Ce champ est utilisé pour les données conversationnelles (telles que les transcriptions d’appels et de chats) et n’est pas modifiable. XM Discover utilise un format de verbatim conversationnel pour le champ richVerbatim. Ce format prend en charge l’ingestion des métadonnées spécifiques au dialogue nécessaires au déverrouillage de la visualisation de la conversation (tours de parole, silence, évènements conversationnels, etc.) et des enrichissements (heure de début, durée, etc.). Ce champ de verbatim comprend des champs “enfants” pour suivre la côte à côte du client et du représentant dans la conversation :
- clientVerbatim suit la côte à côte du client dans la conversation.
- agentVerbatim suit la côte à côte du représentant (agent) de la conversation.
- inconnu suit la côte à côte de la conversation.
- Astuce : Les transformations ne sont pas prises en charge pour les champs verbatim conversationnels. Le même verbatim ne peut pas être utilisé pour différents types de données conversationnelles. Si vous souhaitez que votre projet accueille plusieurs types de conversation, utilisez des paires distinctes de verbatims conversationnels par type de conversation.
- clientVerbatim: Ce champ est utilisé pour les données conversationnelles et est modifiable. Ce champ permet de suivre la côte à côte du client dans les interactions par appel et par chat. Par défaut, ce champ est associé à :
- clientVerbatimChat pour les interactions numériques.
- clientVerbatimCall pour les interactions d’appel.
- agentVerbatim: Ce champ est utilisé pour les données conversationnelles et est modifiable. Ce champ permet de suivre la côte à côte du représentant dans les interactions d’appel et de chat. Par défaut, ce champ est associé à :
- agentVerbatimChat pour les interactions numériques.
- agentVerbatimCall pour les interactions d’appel.
- inconnu: ce champ est utilisé pour les données conversationnelles et est modifiable. Ce champ permet de suivre la côte à côte inconnue de la conversation dans les interactions d’appel et de chat.Par défaut, ce champ est mappé à :
- unknownVerbatimChat pour les interactions numériques.
- unknownVerbatimCall pour les interactions d’appel.
- document_date: la date du document est le champ de date primaire associé à un document. Cette date est utilisée dans les rapports XM Discover, les tendances, les alertes, etc. Pour la date du document, choisissez l’une des options suivantes :
- conversationTimestamp (pour les données conversationnelles) : Date et heure de l’ensemble de la conversation.
- Si les données sources contiennent d’autres champs de date, vous pouvez définir l’un d’entre eux comme date du document en le sélectionnant dans le menu déroulant du champ Nom de champ.
- Vous pouvez également fixer une date spécifique en ajoutant un champ personnalisé.
- natural_id: L’identifiant naturel sert d’identifiant unique à un document et permet de traiter correctement les dupliqués. Pour l’identification naturelle, choisissez l’une des options suivantes :
- conversationId (pour les données conversationnelles) : Un identifiant unique pour l’ensemble de la conversation.
- Sélectionnez un champ textuel ou numérique de vos données dans le champ Nom de champ.
- Générer automatiquement des identifiants en ajoutant un champ personnalisé.
- feedback_provider: Le fournisseur de retour d’information vous permet d’identifier les données obtenues auprès d’un fournisseur spécifique. Pour les téléchargements de liens XM Discover, la valeur de cet attribut est fixée à “XM Discover Link” et ne peut pas être modifiée.
- job_name: le nom du job permet d’identifier les informations en fonction du nom du job utilisé pour les télécharger. Vous pouvez modifier la valeur de cet attribut dans le champ Nom du travail en haut de la page ou en utilisant le menu des options du travail.
- loadDate: La date de chargement indique quand un document a été téléchargé dans XM Discover. Ce champ est défini automatiquement et ne peut pas être modifié.
Outre les champs susmentionnés, vous pouvez également mettre en correspondance les champs personnalisés que vous souhaitez importer. Pour plus d’informations sur les champs personnalisés, consultez la page d’aide sur le mappage des données.
Accessibilité du point final de l’API
Attention : Le point de terminaison de l’API ne prend en charge qu’une seule couverture par appel API et ne doit inclure que les champs de l’exemple de charge utile.
Le point de terminaison API est utilisé pour télécharger des données vers XM Discover en envoyant les données par le biais d’une requête API REST au format JSON.
Vous pouvez accéder au point de terminaison à partir de la page Emplois :
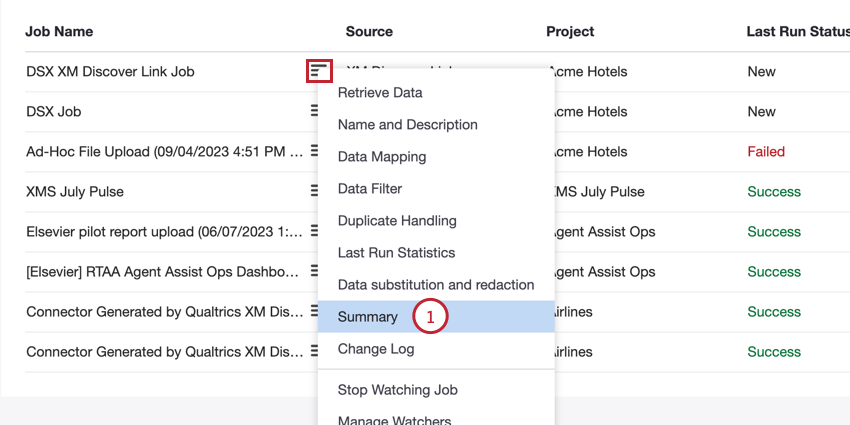

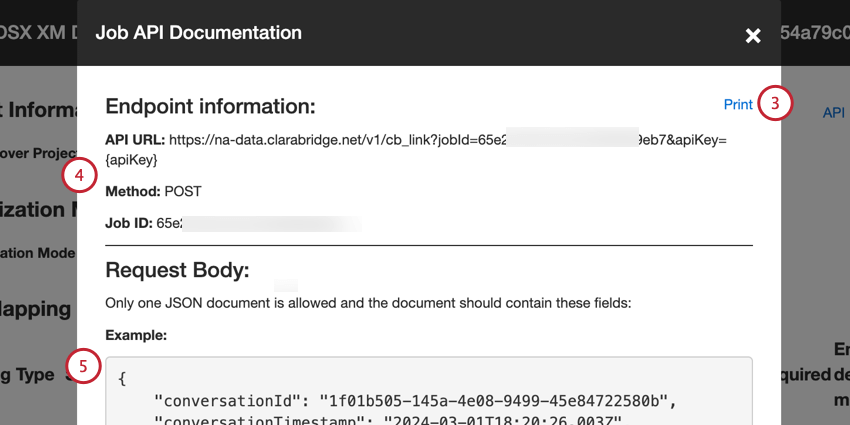
- API URL: L’URL utilisée pour la demande d’API.
- Méthode: Utilisez la méthode POST pour charger des données dans XM Discover.
- Job ID: L’ID du travail actuellement sélectionné.
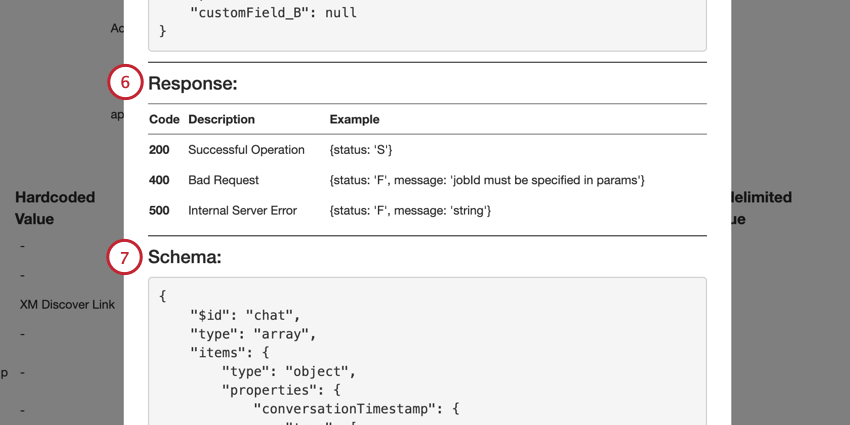
Surveillance d’une tâche de lien XM Discover via l’API
Vous pouvez surveiller l’état des travaux de liaison XM DISCOVER sans vous connecter à XM Discover en appelant le point de terminaison API d’état. Cela vous permet d’obtenir le dernier état d’exécution d’un travail, les chronomètres d’un travail spécifique ou les chronomètres cumulés pour une période donnée.
Informations sur le point d’arrivée de l’état
Pour appeler le point de terminaison de l’état, vous aurez besoin des éléments suivants :
- URL de l’API: https://na-data.clarabridge.net/v1/public/job/status/<jobID>?apiKey=<apiKey>
- <jobId> est l’ID de la tâche XM Discover Link que vous souhaitez surveiller.
- <apiKey> est la clé API.
- Type: Utiliser la méthode REST HTTP
- Méthode HTTP: Utilisez la méthode GET pour récupérer des données.
Éléments d’entrée
Les éléments d’entrée optionnels suivants peuvent être utilisés pour récupérer des données supplémentaires sur votre travail :
- historicalRunId: L’identifiant de la session de téléchargement spécifique. Si cet élément est omis et qu’aucune plage de dates n’est fournie, l’appel à l’API renvoie le dernier état d’exécution du travail. Si cet élément est omis et qu’une plage de dates est fournie, l’appel API renvoie les métriques cumulées pour la période spécifiée.
- startDate: Définir la date de début à partir de laquelle les données doivent être renvoyées.
- endDate: Définir la date de fin pour renvoyer les données sur la base du dernier téléchargement. Si cet élément est omis et que la date de début est fournie, la date de fin est automatiquement fixée à la date du jour.
Astuce : si historicalRunId est fourni, les données seront accumulées pour l’historicalRunId spécifié. Si startDate et endDate sont fournis, les données seront accumulées pour une plage de dates spécifiée, sinon les métriques seront accumulées pour le dernier historicalRunId.
Éléments de sortie
Les éléments de sortie suivants seront renvoyés, à condition que vous ayez saisi les éléments d’entrée requis :
- job_status: Le statut du travail.
- job_failure_reason: Si le travail a échoué, la raison de l’échec.
- run_metrics: Informations sur les documents traités par le travail. Les mesures suivantes sont incluses :
- SUCCESSFULLY_CREATED: Nombre de documents créés avec succès.
- SUCCESSFULLY_UPDATED: Nombre de documents mis à jour avec succès.
- SKIPPED_AS_DUPLICATES: Le nombre de documents ignorés en tant que dupliqués.
- FILTERED_OUT: Le nombre de documents filtrés par un filtre spécifique à la source ou par un filtre de connecteur.
- BAD_RECORD: Nombre d’interactions numériques soumises au traitement qui ne correspondaient pas au format conversationnel de Qualtrics.
- SKIPPED_NO_ACTION: Nombre de documents ignorés parce qu’ils ne sont pas dupliqués.
- FAILED_TO_LOAD: Nombre de documents dont le chargement a échoué.
- TOTAL: Le nombre total de documents traités pendant l’exécution de ce travail.
Messages d’erreur
Les messages d’erreur suivants sont possibles pour la demande d’API d’état :
- 401 Non autorisé: L’authentificateur a échoué. Utilisez une autre clé API.
- 404 Not Found: Un travail avec l’ID spécifié n’existe pas. Utiliser un autre identifiant de travail.
Demande d’échantillon
Voici un exemple de requête pour obtenir le statut d’un travail
:curl --location --request GET 'https://na-data.clarabridge.net/v1/public/job/status/62da736987c9788b830918e0?apiKey=02e7a0e26b592632dd50f623e974fff6'
Échantillon de réponses
Vous trouverez ci-dessous un échantillon de réponses d’un travail ayant échoué
:{
"job_status" : "Failed",
"job_failure_reason" : "{\"problem\" :[{\"requestId" : "RQ-MOB-f339aa58-71b6-4a1d-a67c-12b8d3439321", "severity" : "ERROR", "description" : "La limite de longueur de 900 caractères pour l'attribut supportexperienceresp a été dépassée, la longueur est de 1043\"}],\"status":\"ERROR\"}",
"run_metrics" : {
"successfully_created" : 10,
"failed_to_load" : 1,
"total" : 11
}
}
Exemples de charge utile
Cette section contient un exemple de charge utile JSON pour chaque type de données structurées pris en charge (retour d’information, chat, appel).
Attention : Les charges utiles présentées dans cette section sont uniquement destinées à des fins de démonstration. Les champs de votre charge utile dépendront de votre configuration spécifique.
  ;
C'est génial! Merci pour votre avis!
Merci pour votre avis!