分析設定
このページの内容
分析設定について
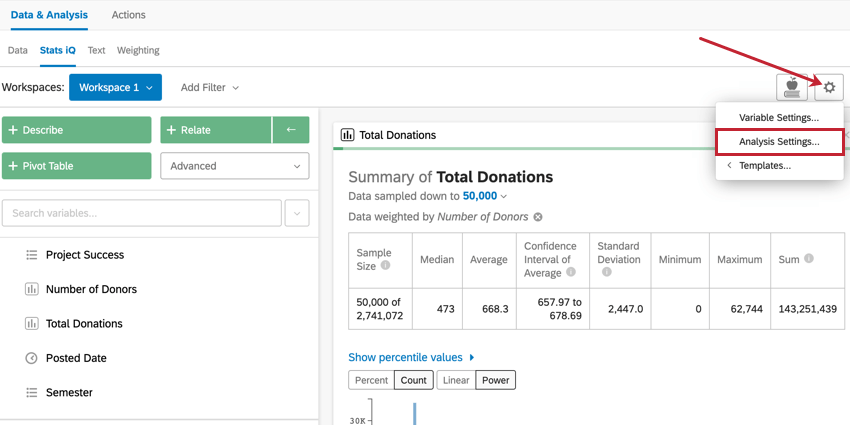
Stats iQの分析設定では、Stats iQ内の分析の詳細を変更することができます。分析設定にアクセスするには、ワークスペースの右上隅にある歯車のアイコンをクリックします。変数設定の詳細を知りたい場合は、変数設定のページをご覧ください。
{kind=link}

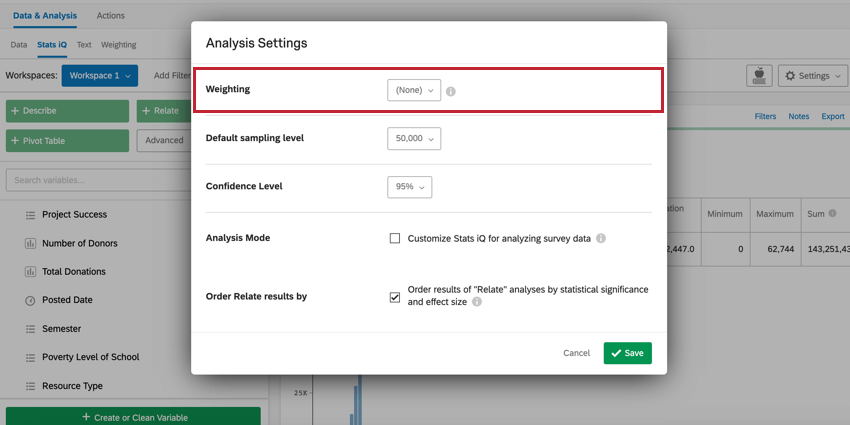
重み設定
{kind=link}

分析設定の重み設定オプションを使用すると、ワークスペース全体に重みを適用できます。重みを選択するには、重み設定オプションの次へドロップダウンメニューをクリックし、分析に適用する重みを選択します。
Qtip: 「クアルトリクス定義の重み設定」とは、「データと分析」タブの「重み設定」で設定した重み設定のことです。
Qtip:Stats iQでの重み設定変数の作成の詳細については、Creating & Applying Weightsのページをお読みください。
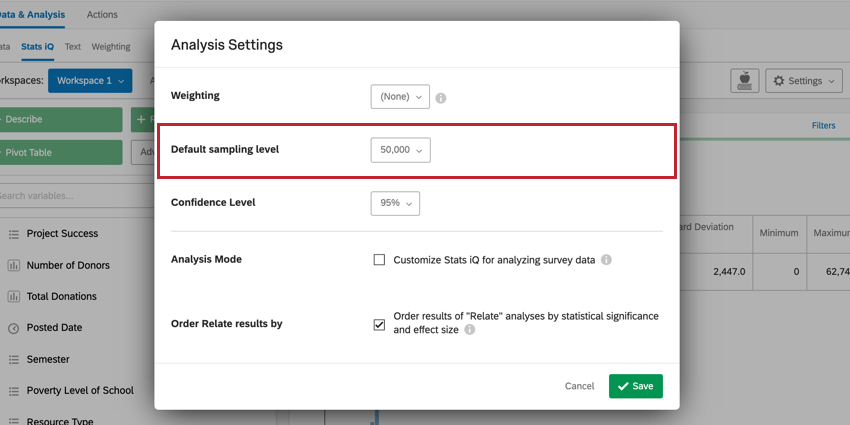
デフォルトサンプリングレベル
{kind=link}
注意: このオプションが表示されるのは、データセットに 10,000 件以上の回答が含まれている場合のみです。データセットに 200,000 件以上の回答が含まれる場合は、自動的にサンプリングが適用されます。
分析設定」では、Stats iQ分析全体のデフォルトサンプリングを変更することができます。デフォルトでは、サンプリングレベルは10,000回答に設定されています。その理由は以下の通りである:
ドロップダウンメニューをクリックして、デフォルトサンプリングレベルを 調整することができます。最低回答数は10,000件。最大値はデータセット全体である。
サンプルリングは、重み設定を適用する前に行われる。しかし、フィルタを適用することを選択した場合、サンプリングはフィルタが追加された後に行われる(または再評価される)。
カード設定
分析ごとにサンプリングを調整したい場合もあるだろう。1枚のカードのサンプリングを変更するには、左上にあるsampled down to Xと書かれたドロップダウンをクリックします。
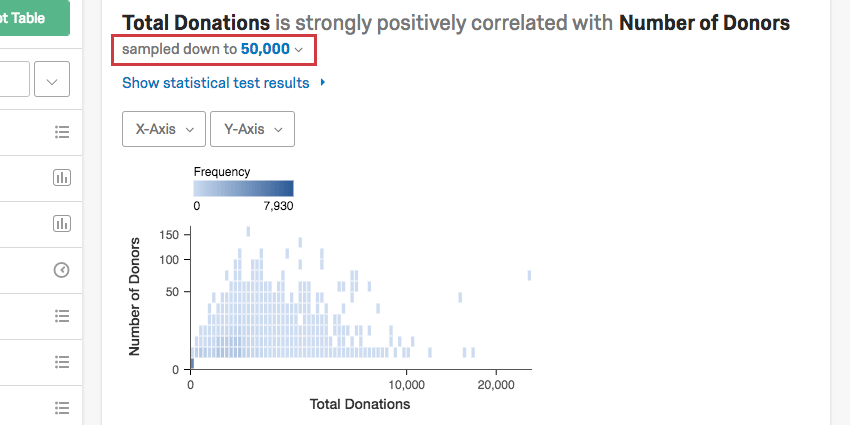{kind=link}

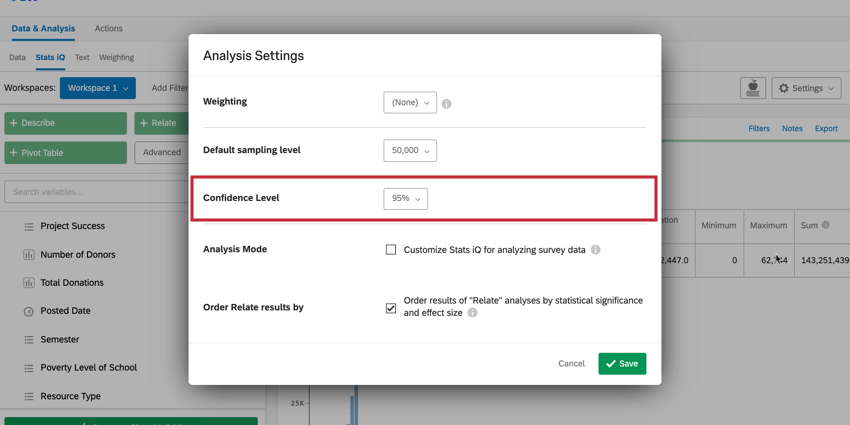
信頼レベル
{kind=link}

Stats iQで信頼水準を設定することは、分析によって生成された結果が一般集団と一致することをどの程度確信したいかを示します。信頼水準を変更するには、分析設定の信頼水準オプションの次へドロップダウンメニューを使用します。
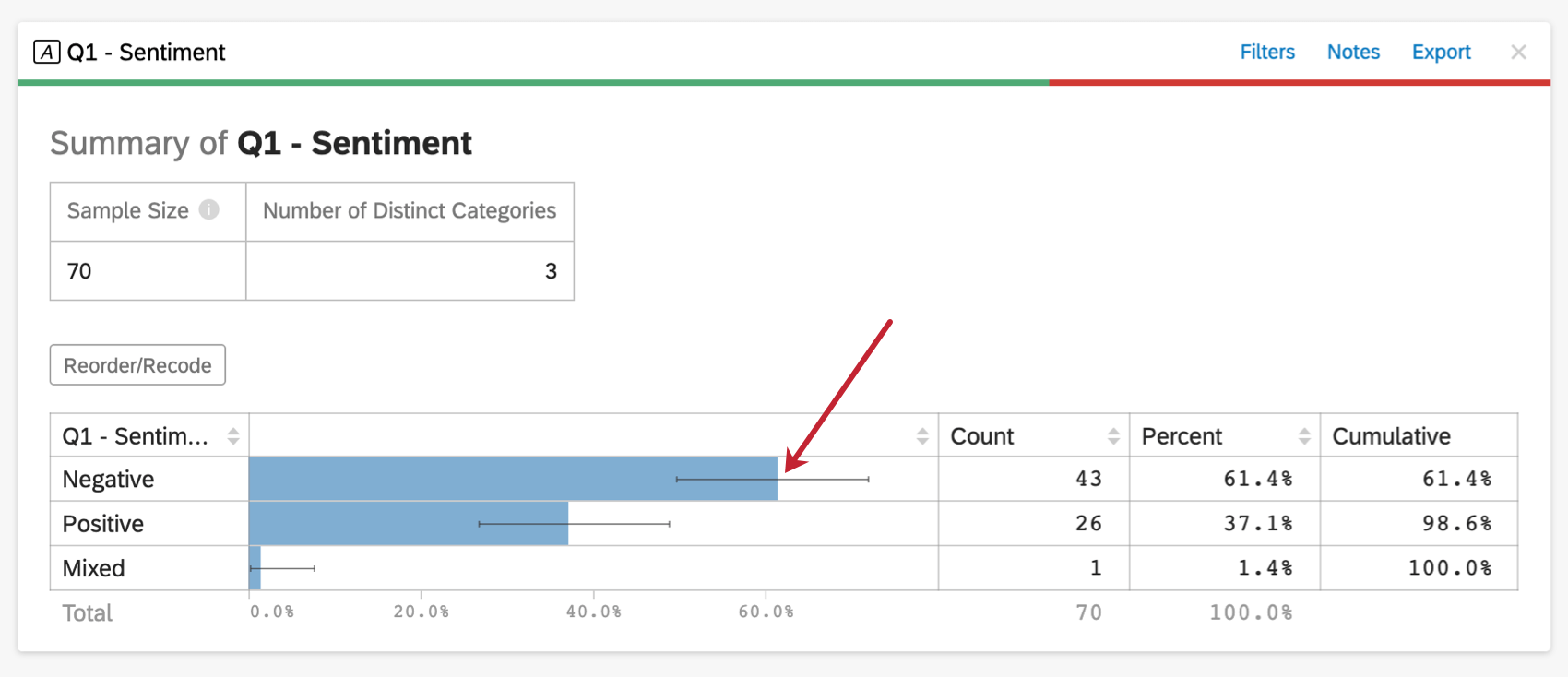
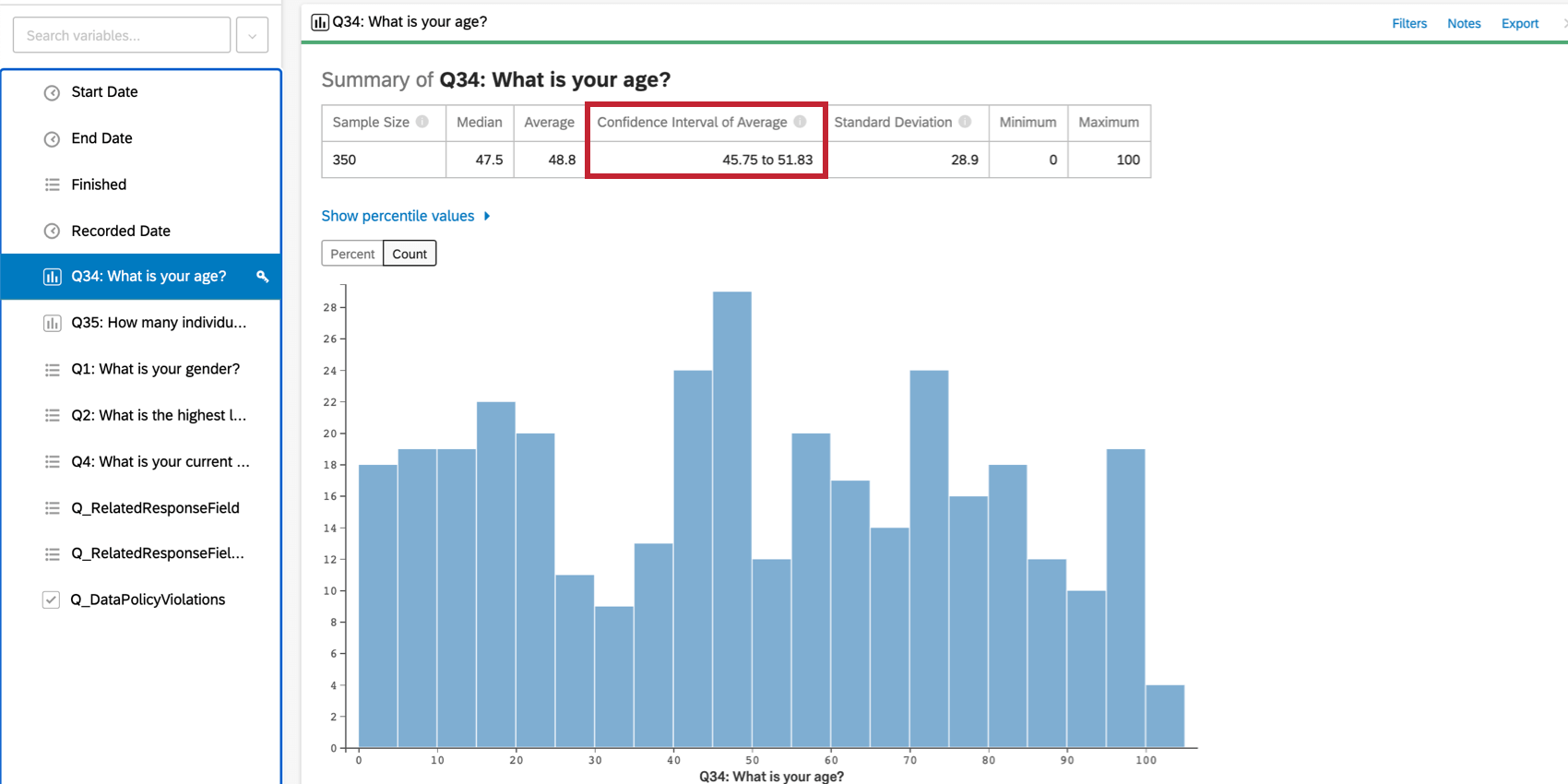
位置に関するデータを含む変数に対してDescribe分析オプションを選択すると、Stats iQはグラフ出力に信頼区間(エラーバーの形)を表示します。信頼水準が95%に設定されている場合、このエラー・バーの幅は、母集団を複数回サンプリングした場合、結果がバーの95%以内に収まると予想されることを示している。
{kind=link}

Stats iQは、カテゴリーデータではグラフの上に、数値データではカードの上部に、信頼区間の範囲を明示的に表示します。
{kind=link}

同じロジックが、relateを使用して作成された統計検定、回帰で生成された係数、およびStats iqの他のいくつかの統計計算にも適用されます。
大差で、最もよく使われる信頼水準は95%である。また、ビジネスの場では90%、科学的な場では利用可能なデータが多い場合は99%以上ということも比較的よく見られる。
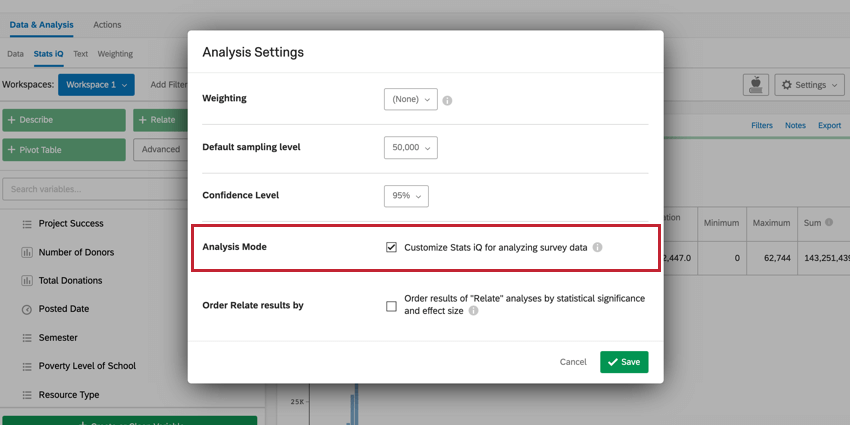
分析モード
{kind=link}

注意: このオプションはインポートされたデータプロジェクトにのみ表示されます。
分析モードオプションは、アンケートデータを分析するためにStats iQワークプレイスをカスタマイズするために使用します。この設定を有効にすると、通常この指標はアンケートのコンテキストには関係ないため、「合計」の計算はアンケート調査から非表示になります。
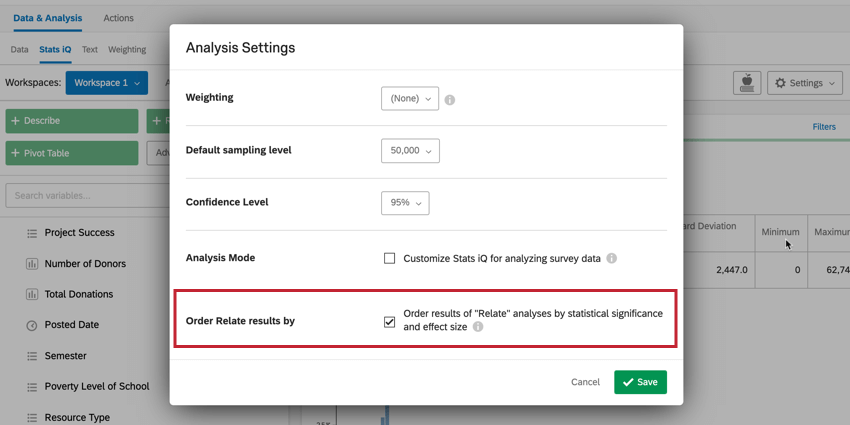
関連する結果を注文する
{kind=link}

Order Relate results by]オプションは、ワークスペースでのリレーションカードの並び順を決定します。このオプションを有効にすると、関係分析は統計的有意性と効果の大きさの順に表示され、最も強い関係が最初に表示されます。このオプションを無効にすると、関連分析は変数ペインに表示される変数と同じ順序で表示されます。
Qtip: 関連分析ボタンが選択される前に、キー変数に加えて複数の変数が選択されると、複数の関連カードが作成されます。詳しくは、関連データのページをご覧ください。
FAQs
Stats iQの変数を新規に作成する方法を教えてください。
Stats iQの変数を新規に作成する方法を教えてください。
Stats iQで値を「再コード化」するにはどうすればよいですか?
Stats iQで値を「再コード化」するにはどうすればよいですか?
直接再コード化できない変数については、作成 またはクリーン変数 メニューで値を再コード化することができます。Create Variable ウィンドウで、Logic メソッドを使用して、変数の既存の各値に数値を割り当てます。新しい変数を作成するか、左下の「既存の変数を置換」を選択して、新しい数値で変数を更新することができます。
変数作成の Logic 方式については、サポートページ Variable Creation をご覧ください。
Stats iQでデータを分析する際のオプションは何ですか?
Stats iQでデータを分析する際のオプションは何ですか?
- Describe:リストから変数を選択し、Describe をクリックすると、その変数に含まれるデータを視覚化することができます。ある変数のデータがどのように分布しているかを確認したい場合に使用します。
- Relate:2つの変数を選択し、Relateをクリックすると、2つの変数間の関係の統計分析が実行されます。2つの変数がどの程度強く相関しているかを知りたいときに使用します。
- ピボットテーブル:2 つ以上の変数を選択してピボットテーブルをクリックすると、変数の値を行と列で表示する表が作成されます。セルには、列や行のパーセンテージ、Sum、Varianceなど、さまざまな情報を表示するように設定することができます。変数の特定の値間の重なりを比較したい場合に使用します。
- Regression:2つの変数を選択し、回帰をクリックすると、変数間の数学的関係が表示されます。ある変数の値から別の変数の値を予測したい場合に使用します。
- クラスター:2~10個の人口統計変数を選択し、「クラスタ」をクリックすると、一緒に発生する可能性が最も高い形質のグループ分けが表示され、データに含まれる人口層が明らかにされます。
Stats iQの変数の種類にはどのような意味があるのでしょうか?
Stats iQの変数の種類にはどのような意味があるのでしょうか?
この統計用語の意味がわからない。教えてもらえますか?
この統計用語の意味がわからない。教えてもらえますか?
- 統計テスト:ANOVA、T-test、カイ二乗はすべてStats iQが2つの変数間の関係が有意であるかどうかを検定するために行う統計検定です。これらの検定はP-Valueを生成するために使用されます。
- P-Value:この値は、変数間に相関が存在しない場合に、観測された結果が見られる確率を表しています。P-Valueが低いほど、相関のあるデータであることを意味する。
- 効果量:効果量とは、2つの変数間の相関がどの程度大きいかを示す指標である。これは、実施した統計検定の種類によって異なる方法で測定されます。例えば、Cohenのd、Pearsonのr、Cramerのvなどがあり、効果量の数値が大きいほど、変数の相関が高いことを意味する。
Stats iQに表示されるデータをフィルタリングする方法を教えてください。
Stats iQに表示されるデータをフィルタリングする方法を教えてください。
Stats iQに新しい回答を表示させるにはどうしたらよいですか?
Stats iQに新しい回答を表示させるにはどうしたらよいですか?
Stats iQって何?/ スタットウィングはどこ?
Stats iQって何?/ スタットウィングはどこ?
What do I do if my data isn't loading properly?
What do I do if my data isn't loading properly?
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!