Regroupement des données (Studio)
Contenus de cette page
À propos du regroupement des données dans Studio
Lorsque vous créez un tableau de bord dans Studio, vous pouvez spécifier les données que vous souhaitez inclure dans le tableau de bord. Vous pouvez limiter les données d’un rapport en les regroupant, en les triant ou en les filtrant.
Vous pouvez utiliser différents types de regroupements pour vos données. Cette page explique comment regrouper vos données en fonction de ces différents groupes.
Regrouper des données dans un widget
Astuce : Vous ne pouvez pas regrouper des données dans les widgets de mesure ou de retour d’information.
Vous pouvez regrouper des données dans les types de widgets pris en charge. Pour regrouper les données dans votre widget :
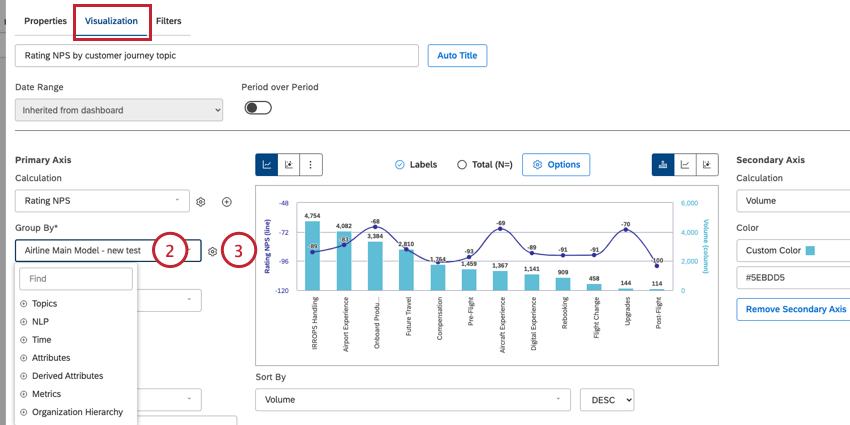
Astuce : Si vous utilisez un widget de tableau, cette option s’appelle plutôt “Groupements”. Si vous utilisez un widget de carte thermique, cette option s’appelle plutôt “Boîtes”. Si vous utilisez un widget réseau, cette option s’appelle plutôt “Nœuds”.
Sujets
La sélection de Sujets vous permet de regrouper les données selon les catégories dérivées du retour d’information des clients. Cela vous permet d’avoir une vue d’ensemble de ce dont parlent vos clients.
Après avoir choisi votre modèle de catégorie, ouvrez les paramètres de regroupement pour sélectionner les sujets inclus dans le widget. Pour plus d’informations, voir Personnaliser les groupes de modèles de catégories.
Lorsque vous regroupez des données par thèmes, vous pouvez choisir d’établir des rapports à différents niveaux dans votre modèle de catégorie. Pour obtenir un aperçu de haut niveau de ce dont parlent vos clients, regroupez les données par thèmes de Niveau 1. Pour suivre des thèmes plus spécifiques dans les commentaires des clients, regroupez les données par thèmes de Niveau 2 ou inférieur (selon votre modèle). Pour obtenir le rapport le plus granulaire à tous les niveaux, regroupez les données à l’aide de l’option Feuille, qui vous permet de vous concentrer sur les feuilles de sujet, ou sur les catégories qui n’ont pas de sous-catégories.
PNL
La sélection de NLP vous permet de regrouper les données en fonction de critères créés automatiquement par le moteur de traitement du langage naturel de XM Discover. Ces critères sont créés à partir d’un retour d’information non structuré qui est traité par XM Discover. Vous avez le choix entre plusieurs sous-groupes :
Mots
Les groupes NLP de mots vous permettent de regrouper les données par mots ou types de mots spécifiques mentionnés dans les commentaires des clients. Les groupes suivants sont disponibles :
- Tous les mots: Regrouper les données par mots réguliers. Cela vous donnera une idée des termes les plus courants que les clients utilisent lorsqu’ils parlent de votre produit ou service.
- CB Organisation: Regrouper les données par mentions d’organisation.
- CB Company: Données du groupe par mentions de l’entreprise.
- CB Email Address: Regrouper les données en fonction des adresses électroniques mentionnées dans le retour d’information.
- CB Emoticon: Regroupe les données par emojis et émoticônes utilisés dans le retour d’information.
- Évènement: Regrouper les données autour des fêtes habituelles (comme le Nouvel An ou Halloween), des évènements de la vie (comme un mariage ou un diplôme) et des évènements culturels courants (comme le Super Bowl) mentionnés dans les commentaires.
- Industrie CB: Regrouper les données par secteur d’activité.
- CB Person: Regrouper les données en fonction des noms des personnes mentionnées dans le retour d’information.
- Numéro de téléphone CB: Regrouper les données par numéros de téléphone mentionnés dans les commentaires.
- CB Product: Regrouper les données par mentions de produits.
- CB Profanity: Regrouper les données par mots profanes à partir d’un ensemble prédéterminé.
Mots associés
Le regroupement des mots associés vous permet de regrouper les données par paires de mots qui sont mentionnés en relation l’un avec l’autre dans les commentaires des clients. Cela vous permet de voir les sujets et les thèmes les plus courants dans les commentaires des clients, indépendamment de la catégorisation des sujets.
Les mots associés sont présentés sous la forme suivante : mot 1 → mot 2.
Exemple : Si les commentaires d’un client étaient “Le magasin était sale” et que vous regroupez par mots associés, vous verrez alors “magasin → sale” dans votre widget.
Hashtags
Le regroupement Hashtags vous permet de regrouper les données par phrases hashtags (mots ou phrases précédés du symbole #) . Les hashtags sont généralement utilisés dans les publications sur les médias sociaux pour aider à identifier et à catégoriser la personne évaluée.
Enrichissement
Les groupes d’enrichissement vous permettent de regrouper les données en fonction des types de contenu inclus dans les commentaires des clients. Les groupes suivants sont disponibles :
- Chapitres CB: Regrouper les données par chapitres conversationnels qui représentent des segments sémantiquement liés de la conversation (tels que l’ouverture, le besoin, la vérification, l’étape de la solution et la clôture).
- Sous-type de contenu CB: Regrouper davantage les données non-contenues en fonction de leurs sous-types (tels que les publicités, les coupons, les liens d’articles ou le type “non défini”). Notez que pour les enregistrements à contenu, le sous-type est toujours à contenu également.
- Type de contenu CB: Regrouper les informations en fonction de leur contenu ou de leur absence de contenu, tel qu’il est automatiquement identifié par XM Discover.
- CB Detected Features (fonctions détectées) : Regrouper les données en fonction des types de fonctions NLP détectées (par exemple, les données contenant des mentions d’industrie ou d’organisation).
- CB Emotion: Regrouper les données par type d’émotion détectée par le moteur NLP (colère, confusion, déception, embarras, peur, frustration, jalousie, joie, amour, tristesse, surprise, remerciement, confiance ou autre).
- CB Medical Condition: Regrouper les données en fonction des conditions médicales mentionnées dans le texte (par exemple, “covid” ou “méningite”).
- CB Procédure médicale: Regrouper les données en fonction des procédures médicales mentionnées dans le texte (par exemple, “mammographie” ou “chirurgie du dos”).
- Notation de l’empathie des participants au CB: Regrouper les données conversationnelles selon que les représentants ont fait preuve d’empathie dans leurs interactions avec les clients ou non. 0 signifie que le représentant n’a pas fait preuve d’empathie, tandis que 1 signifie qu’il a fait preuve d’empathie.
- CB Reason: Regrouper les données en fonction des raisons d’un évènement de conversation particulier (par exemple, raison du contact ou raison de l’empathie).
- CB Rx: regrouper les données en fonction des noms de médicaments mentionnés dans le texte (par exemple, “acetaminophen” ou “tylenol”).
- CB Type de phrase: Regrouper les données en fonction du type de phrase ou de l’intention (par exemple, “appel à l’aide” ou “suggestion”).
Langue
Les groupes de langues vous permettent de regrouper les données en fonction de la langue dans laquelle le retour d’information a été laissé. Les groupes suivants sont disponibles :
- CB Langue détectée automatiquement: Regroupe les données en fonction des langues détectées automatiquement (si la détection automatique des langues est activée pour un projet).
- CB Langue traitée: Regrouper les données en fonction des langues dans lesquelles le retour d’information a été traité. Les langues non prises en charge par la détection linguistique de XM Discover sont marquées comme “autres”
Conversation
Les groupes de conversation vous permettent de regrouper les données en fonction de divers enrichissements conversationnels. Notez que ces regroupements ne sont disponibles que pour les données conversationnelles (appels et chats traités à l’aide du format conversationnel de Qualtrics). Les groupes suivants sont disponibles :
- CB % Silence: Regroupe les données en fonction du pourcentage de silence dans un appel.
- CB Durée de la conversation: Regroupe les données en fonction de la durée de la conversation en millisecondes. Pour les chronomètres, il s’agit du temps écoulé entre le début de la première phrase et la fin de la dernière. Les silences de tête et de queue ne sont pas pris en compte. Pour les chronomètres, il s’agit du temps écoulé entre la première et la dernière phrase.
- CB Type de participant: Regrouper les données en fonction du type de participant. Les valeurs possibles sont les suivantes :
- Chat_bot est un chatbot.
- IVR est un bot de réponse vocale interactive.
- L’homme est une personne.
- CB Participant Type: Regrouper les données en fonction du type de participant. Les valeurs possibles sont les suivantes :
- l’agent est un représentant de l’entreprise ou un chatbot.
- est un client.
- type_inconnu est un participant qui n’est pas identifié comme un agent ou un client.
- CB Sentence Duration (Durée de la phrase): Regroupe les données en fonction de la durée d’une phrase dans un appel en millisecondes.
- CB Sentence Start Time: regrouper les données en fonction de l’horodatage du début de la phrase. Pour les appels, il s’agit du temps en millisecondes écoulé depuis le début audible du premier mot de la première phrase. Pour les chronomètres, il s’agit du temps en millisecondes écoulé depuis l’envoi du premier message. Astuce : L’heure de début du premier message de chat sera toujours de 0 ms pour cet attribut.

- CB Total Dead Air: Regroupe les données en fonction de l’air mort total d’un appel en millisecondes. Dans les appels, l’air mort est une longue pause entre les orateurs.
- CB Total Hésitation: Regroupe les données en fonction de l’hésitation totale (de l’agent et du client) lors d’un appel, en millisecondes. Dans les appels, l’hésitation est une longue pause d’un locuteur.
- CB Total Overtalk: Regroupe les données en fonction de la durée cumulée des phrases qui se chevauchent lors d’un appel, en millisecondes. Lors d’un appel, on parle d’overtalk à chaque fois que deux ou plusieurs locuteurs parlent simultanément et que les timestamps de leurs phrases se chevauchent.
- CB Silence total: Regrouper les données en fonction de la durée cumulée de tous les silences supérieurs ou égaux à 2 secondes entre les phrases pour tous les participants à un appel, en millisecondes.
Heure
La sélection de Chronomètre permet de regrouper les données par périodes de temps. Vous pouvez utiliser les regroupements d’attributs temporels pour créer un rapport de tendance, ce qui vous permet de voir comment vos calculs et vos métriques évoluent dans le temps.
Attributs
La sélection d’attributs permet de regrouper les données en fonction des valeurs d’un attribut structuré sélectionné. Un attribut structuré est un champ numérique ou une chaîne de caractères présent dans un enregistrement qui n’est pas le retour d’information textuel proprement dit. Les attributs structurés contiennent généralement des données discrètes avec un haut degré d’organisation (comme l’âge d’une personne ou le nom du produit qu’elle utilise). Les attributs disponibles pour le regroupement dépendent de la source du retour d’information et varient généralement d’un ensemble de données à l’autre.
Exemple : Je peux faire des regroupements par l’Attribut “Agent” pour voir les regroupements d’interactions par les différents agents qui ont traité l’interaction.
Mesures
La sélection de Métriques vous permet de regrouper les données par valeurs discrètes ou par bandes de certains calculs standard et métriques dérivées. En d’autres termes, vous pouvez organiser les données en fonction d’une mesure et les mesurer à l’aide d’une autre mesure. Les groupes suivants sont disponibles :
- Sentiment (3 bandes): Regrouper les données par 3 bandes de sentiment (Négatif, Neutre, Positif). Pour plus d’informations, voir Regroupement par Sentiment.
- Sentiment (5 bandes): Regrouper les données par 5 bandes de sentiment (Fortement négatif, Négatif, Neutre, Positif, Fortement positif). Pour plus d’informations, voir Regroupement par Sentiment.
- Effort (3 bandes): Regrouper les données par 3 bandes d’effort (dur, neutre, facile). Lors du regroupement par Effort, les valeurs nulles sont incluses par défaut.
- Effort (5 bandes): Regrouper les données par 5 bandes d’effort (Très dur, Dur, Neutre, Facile, Très facile). Lors du regroupement par Effort, les valeurs nulles sont incluses par défaut.
- Intensité émotionnelle: Regrouper les données selon trois catégories d’intensité émotionnelle (faible, moyenne, élevée).
- CB Document Word Count: Regroupe les données en fonction du nombre de mots dans un document.
- CB Loyalty Tenure (ancienneté de la fidélité): Regrouper les données en fonction de la durée de la fidélité du client (en années).
- CB Sentence Quartile: regrouper les données en fonction du quart du verbatim dans lequel se situe une phrase (1, 2, 3 ou 4). Cela peut vous aider à comprendre quels sont les sujets abordés et à quel moment de la conversation.
- CB Sentence Word Count: Regrouper les données en fonction du nombre de mots dans une phrase.
En outre, vous pouvez définir vos propres indicateurs de satisfaction et de satisfaction maximale, ainsi que vos propres indicateurs de satisfaction minimale, en fonction desquels vous pouvez regrouper les données. Vous pouvez ainsi déterminer si le retour d’information provient d’un promoteur, d’un détracteur ou d’un client neutre. Les groupes suivants sont disponibles :
- Top Box: Regrouper les données par groupes top box (promoteurs et autres).
- Boîte inférieure: Regrouper les données en fonction des bandes de la boîte inférieure (détracteurs et autres).
- Satisfaction: Regrouper les données par tranches de satisfaction (détracteurs, neutres, promoteurs).
Facteurs
Astuce : Vous ne pouvez utiliser les pilotes que dans les widgets de nuage de points.
La sélection de Pilotes vous permet de regrouper les données en fonction des pilotes que vous créez dans votre compte. Vous pouvez utiliser ces moteurs pour trouver les attributs et les sujets qui mènent à un certain résultat.
Hiérarchie d’organisation
La sélection de Hiérarchie de l’organisation permet de regrouper les données selon les différents niveaux de la hiérarchie de l’organisation sélectionnée.
Coût du regroupement
Lorsque vous exécutez des rapports avec des regroupements multiples, vous pouvez recevoir le message d’erreur suivant :
“Oops ! Nous appliquons un coût estimé à chaque regroupement, et la somme des coûts ne peut pas dépasser le budget de garde-corps de [10.5]. (Supprimez ou choisissez d’autres groupements en fonction des coûts listés ci-dessous afin de vous assurer que le coût total du widget ne dépasse pas le budget : [liste des regroupements et de leurs coûts] Coût total actuel : [total de tous les coûts]”
Le coût de chaque regroupement dépend du nombre de valeurs uniques dans le groupe (cette mesure est appelée cardinalité). Par défaut, la plupart des widgets affichent les 10 premiers éléments en volume. S’il y a 100 éléments au total, ce calcul est généralement très rapide. S’il y a 1 000 000 d’informations, le calcul des 10 premières prend plus de temps. En général, le fait d’avoir plus d’éléments uniques résulte en un calcul plus coûteux en termes de performance. Ce coût peut se multiplier rapidement pour les widgets qui renvoient plusieurs niveaux de données, et peut entraîner l’apparition du message d’erreur ci-dessus.
Si vous recevez l’erreur ci-dessus lors de l’utilisation de regroupements dans un rapport, vous devez supprimer un ou plusieurs des regroupements listés afin que leur coût total ne dépasse pas le budget. Le message d’erreur affiche les coûts estimés pour chaque groupe afin de vous aider à décider quel groupe supprimer.
C'est génial! Merci pour votre avis!
Merci pour votre avis!