カテゴリー規定(デザイナー)
このページの内容
カテゴリー規則について
カテゴリー・ルールは、どの文章を各カテゴリーに割り当てるべきかを決定する。カテゴリー・ルールとは、通常、カテゴリーに含めたい、あるいは除外したい単語の例である。
基本ルール
基本ルールは、文中に含まれるべき、あるいは含まれないべき単語を指定することで、文を分類する。
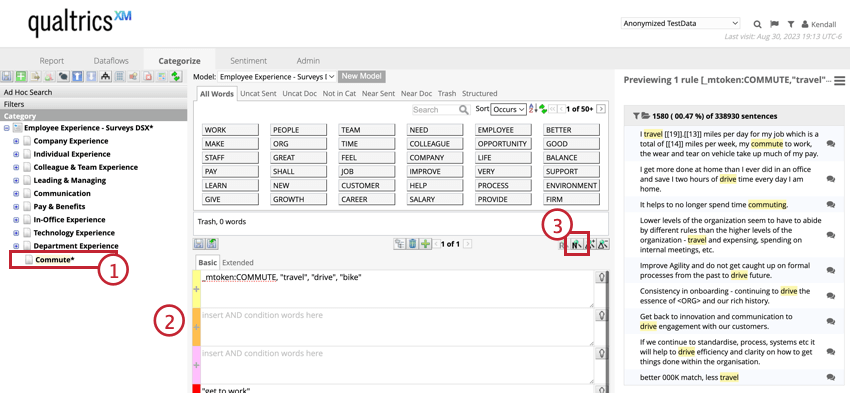
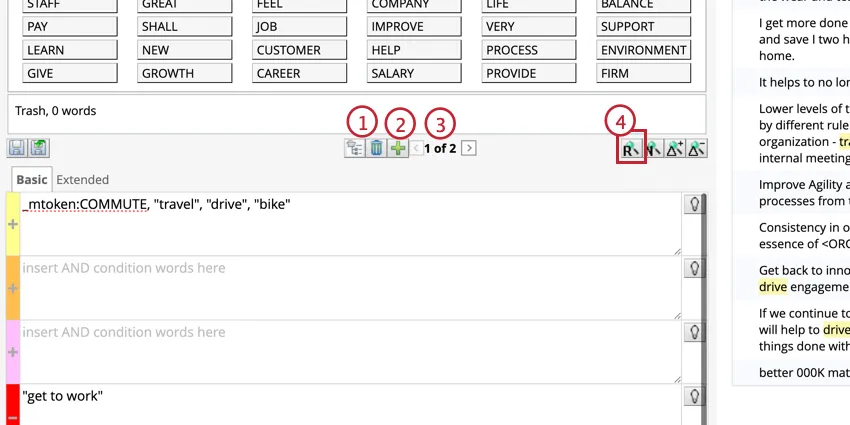
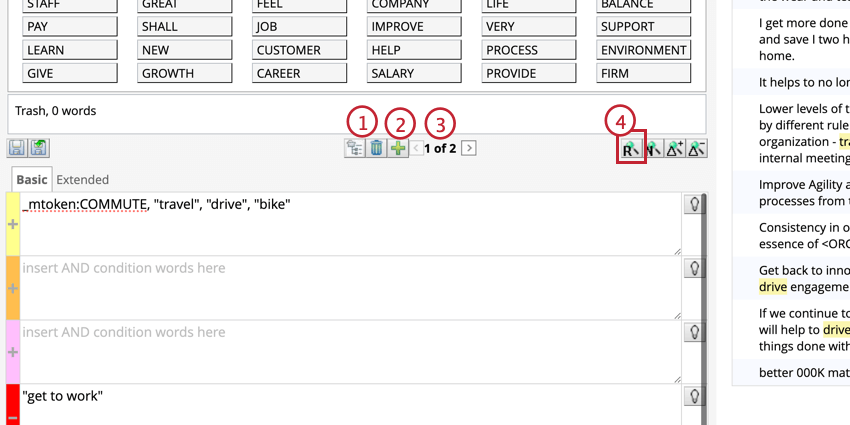
例: 通勤」のカテゴリーを作りたいとします。ルールは、通勤に関連する単語(「commute」や「travel」など)を含み、通勤とは無関係だが検索に表示される可能性のある単語(「drive」や「get to work」など)は除外する。
一部の文字は、高度な検索演算子を作成するために使用されるため、ルールを構築するために使用すると結果に影響します。以下の文字は、基本的なルール作成に使用できる:
- 文字
- 数値
- パーセント記号 ( % )
- 絵文字
- 顔文字
- 通貨記号 ( $, €, £ )
Qtip: ルールを作成する際に短縮形を含む単語やフレーズ(例:”couldn’t find “や “didn’t fit”)を含める場合は、完全な形で引用符の中に記述してください(例:”could not “や “did not”)。
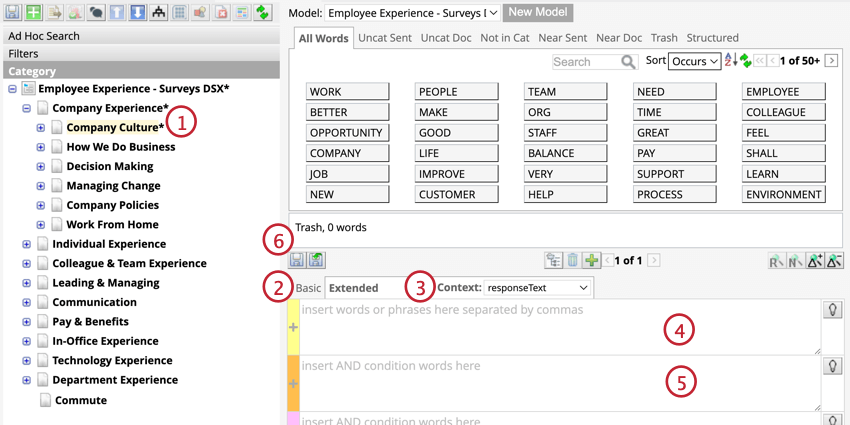
4つのルールレーンの使用
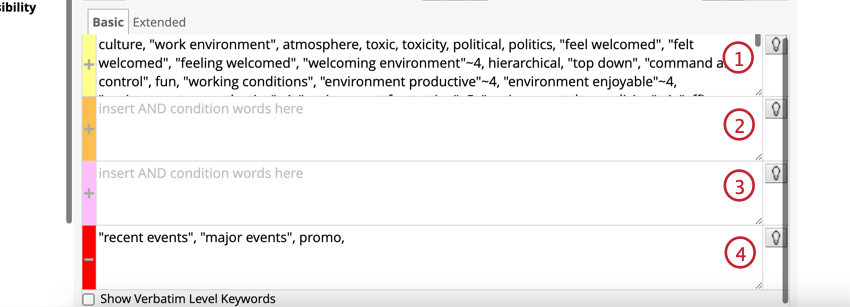
ルールレーンには、ルール内の単語の関係を決定する4つのレーンがある:or、and、and、not。
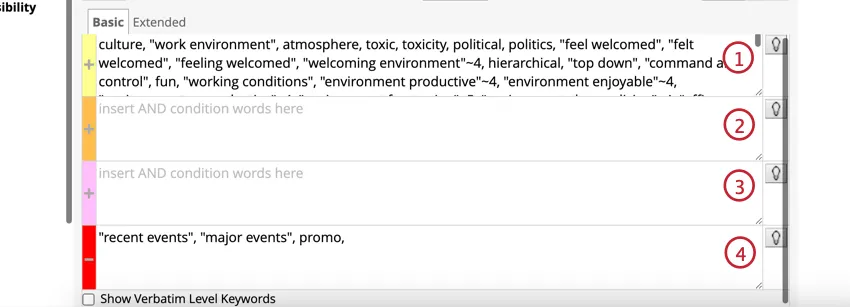
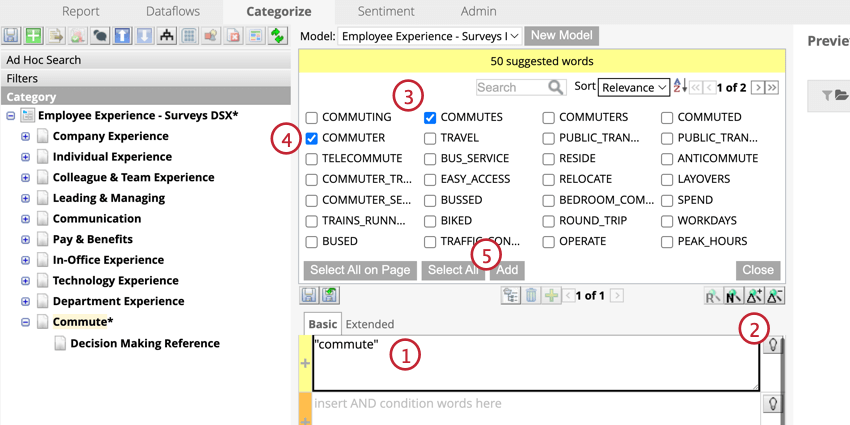
ルールレーンの提案
ルールレーン候補は、ルールレーンに入力された単語を分析し、類義語、関連する概念、よくあるスペルミスを提案することで、カテゴリーをより速く構築するのに役立ちます。
Qtip: 提案された単語を関連性または名前で並べ替えます。
以下の入力に対応しています:
- 簡単な用語:例えば “車”
- 正確なフレーズ:例 “スポーツカー”
- 一文字のワイルドカード:例えば “c?r”
- 複数文字のワイルドカード:例えば “technol*”
- キーワード:例えば_mtoken:CAR
Qtip: プロジェクトデータは、大規模な外部データセットに基づくものであり、プロジェクトデータに特化したものではありません。
注意: サジェストでは、ブーリアン演算子を含む語句は無視されます。詳しくは「高度なルール演算子」を参照。
コンテキスト・ルール
コンテキスト・ルールは、元の投稿や親文書の内容に基づいてツイートやコメントを分類する。これらのルールは、ソーシャルメディア上のスレッド化された会話からデータを分類する際に役立つ。
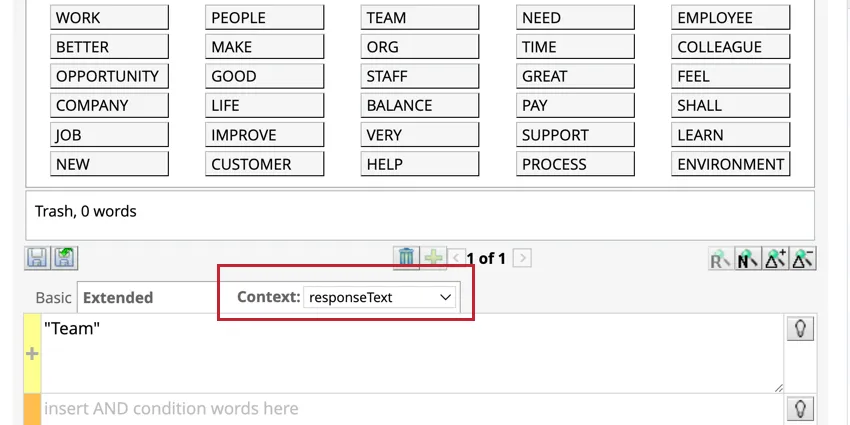
例: 例えば、ある企業が新商品の告知を投稿し、たくさんのコメントが寄せられたが、この特定の投稿のコメントだけを分類したいとする。そこで、新製品のコンテキスト・ルール(「新製品」)を作成する。基本ルールが追加されると、Designerは拡張ルール(「新製品」)からコメントでそのルール(「製品機能」)に言及する文章を引き出します。
コンテキスト・ルールは、親文書のいずれかの文に関連していれば真となり、真であればすべての子文書のすべての文が分類される。コンテキストルールがカテゴリーグループに適用された場合、すべての基本ルールに対する拡張クエリーとして、そのグループ内のすべてのカテゴリーにも適用される。
Qtip: 基本クエリと拡張クエリはAND関係なので、両方の条件が満たされた場合のみテキストが分類されます。
注意: ルールを拡張すると、モデルの分類にかかる時間が長くなる場合があります。
拡張ルールを作成する場合、プレビューウィンドウには拡張ルールが反映されません。代わりに、文またはトピックに適用された拡張ルールを確認するには、ノードをパブリッシュして分類し、スタジオで結果を表示する必要があります。
facebookデータからのコンテキスト・ルール
フェイスブックからのデータは、投稿やコメントとしてアップロードされる。親記事へのリンクを含むことができるのはコメントだけです。
Qtip: ユーザーはfacebookのコメントに返信することができます。この場合、コメントは別のコメントの親になることもできる。
twitterデータからのコンテキストルール
ツイッターのデータは、ツイート、リツイート、リプライとしてアップロードできる。返信のみ親ツイートへのリンクを含み、コンテキストルールで使用できる。リツイートへの返信は、元のツイートを親として持つ。
Qtip: ユーザーはTwitterのコメントに返信することができます。この場合、コメントは別のコメントの親になることもできる。
ファイルデータからのコンテキストルール
アップロードされたファイルは、Parent Natural ID システム属性にマップされた列がある限り、親子階層を持つことができます。これは親文書のNatural IDと一致しなければならない。
バーベイタム固有の規則
逐語固有ルールは、文ではなく逐語に現れる用語によって文を分類する。これらのルールは、文の境界やスタイルが異なる可能性のあるソーシャルメディアデータを扱うときに便利です。詳細については、Verbatim-Specific Rulesを参照のこと。
高度なルール演算子
特殊文字は、より高度なルールを構築するために使用することができる。
例: décor “という用語を検索することができます。アクセント記号を使用している回答もあれば、省略している回答もある。両方のオプションを含めるには、1文字のワイルドカード検索を使用します:”d?cor”
| キャラクター | 使用 |
|---|---|
| ? | 1文字のワイルドカード検索。
|
| * | 複数文字のワイルドカード検索。
|
| ブール演算子:AND、OR、NOT | 複数文字のワイルドカード検索。
|
注意: ワイルドカードで始まるクエリは、分類のロード時間が長くなる可能性があります。
カテゴリーごとに複数のルールを適用する
カテゴリーごとに複数のルールを適用することができます。複数のルールが指定された場合、それらのクエリは常にOR関係を持ち、少なくとも1つのルールにマッチすれば、センテンスが分類されることを意味する。
ルールでカテゴリーを参照する
カテゴリーを参照すると、あるカテゴリーのルールを別のカテゴリーで再利用できる。参照はすべてのカテゴリーモデルで機能するため、プロジェクト内の異なるモデル間でルールを共有することができます。参照されるカテゴリーに変更を加えた場合、その変更を適用するために、それを参照するすべてのカテゴリーで分類を再実行する必要があります。
注意: 1つのルールは最大30個のカテゴリー参照を含むことができる。例えば、カテゴリーAがカテゴリーBを参照し、そのカテゴリーBがカテゴリーCを参照する。
Qtip: カテゴリはそれ自身やその親カテゴリ、子カテゴリを参照することはできません。
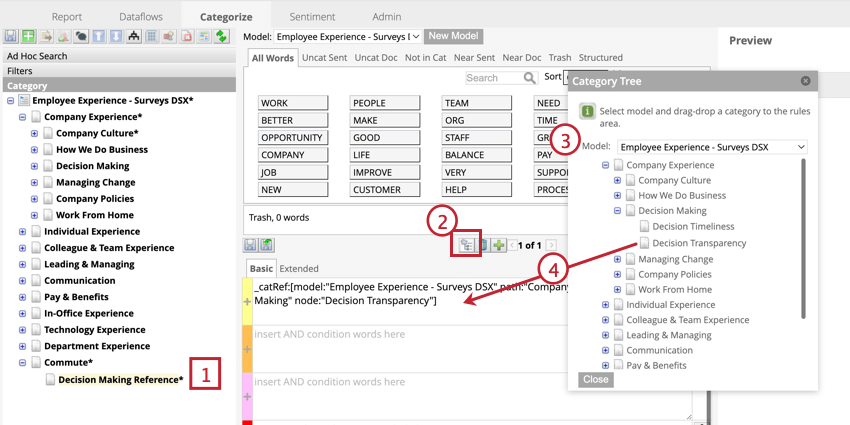
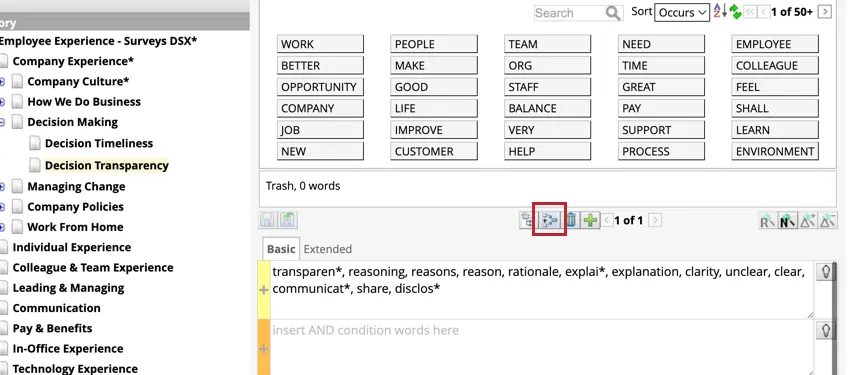
カテゴリー参照は “catRef “という構文を持ち、カテゴリーモデルとカテゴリーパスを含む。
_catRef:[model: "モデル名" path: "Parent Category" node: "CHILD CATEGORY"]] 。 カテゴリー参照を追加すると、参照されたカテゴリーのルールレーンの上にある「参照カテゴリーノード」ボタンをクリックして、そのノードへのすべての参照を見ることができます。
注意: 参照されたカテゴリを削除することはできません。カテゴリーを削除する前に、すべての参照を削除する必要があります。
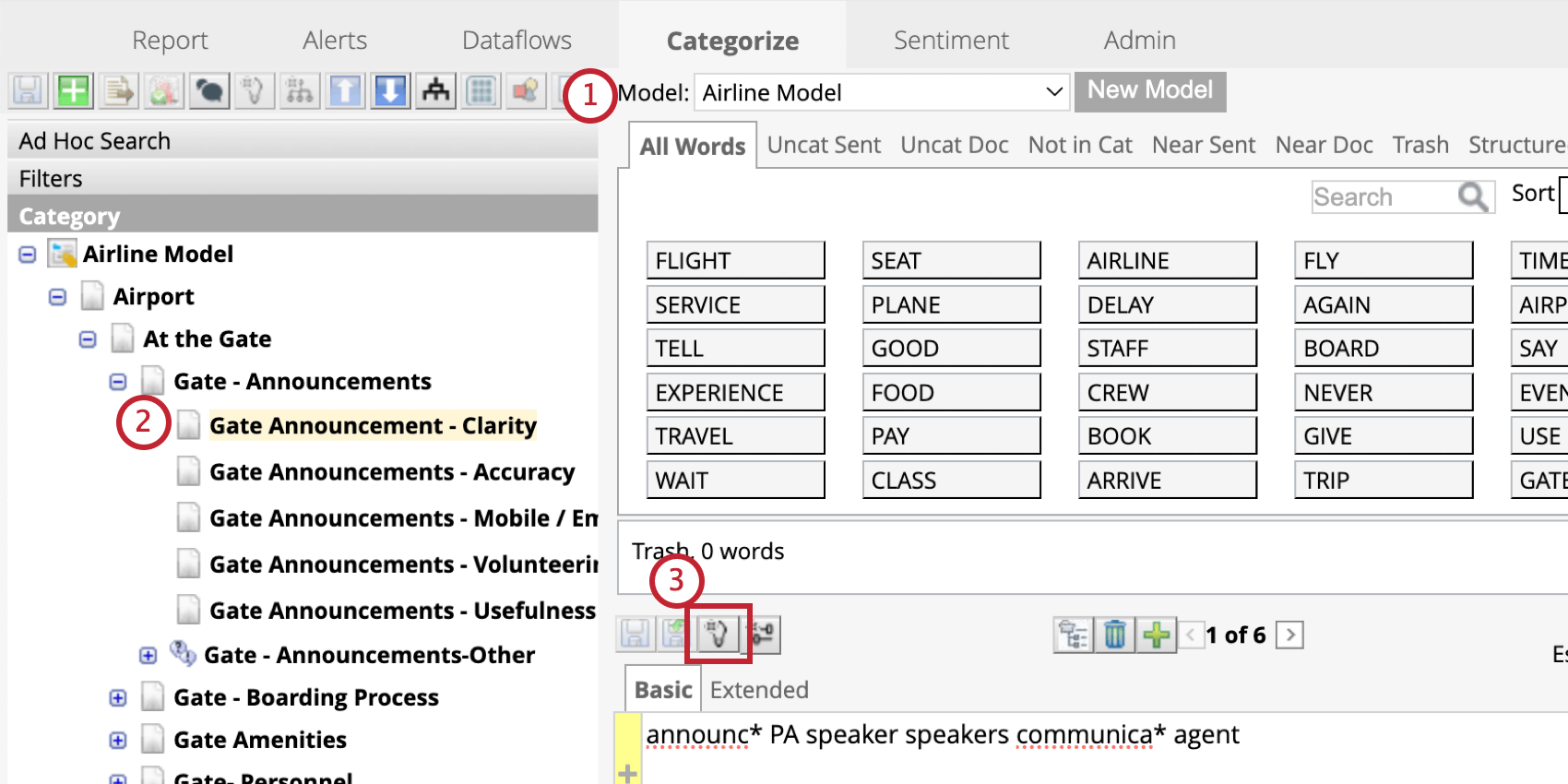
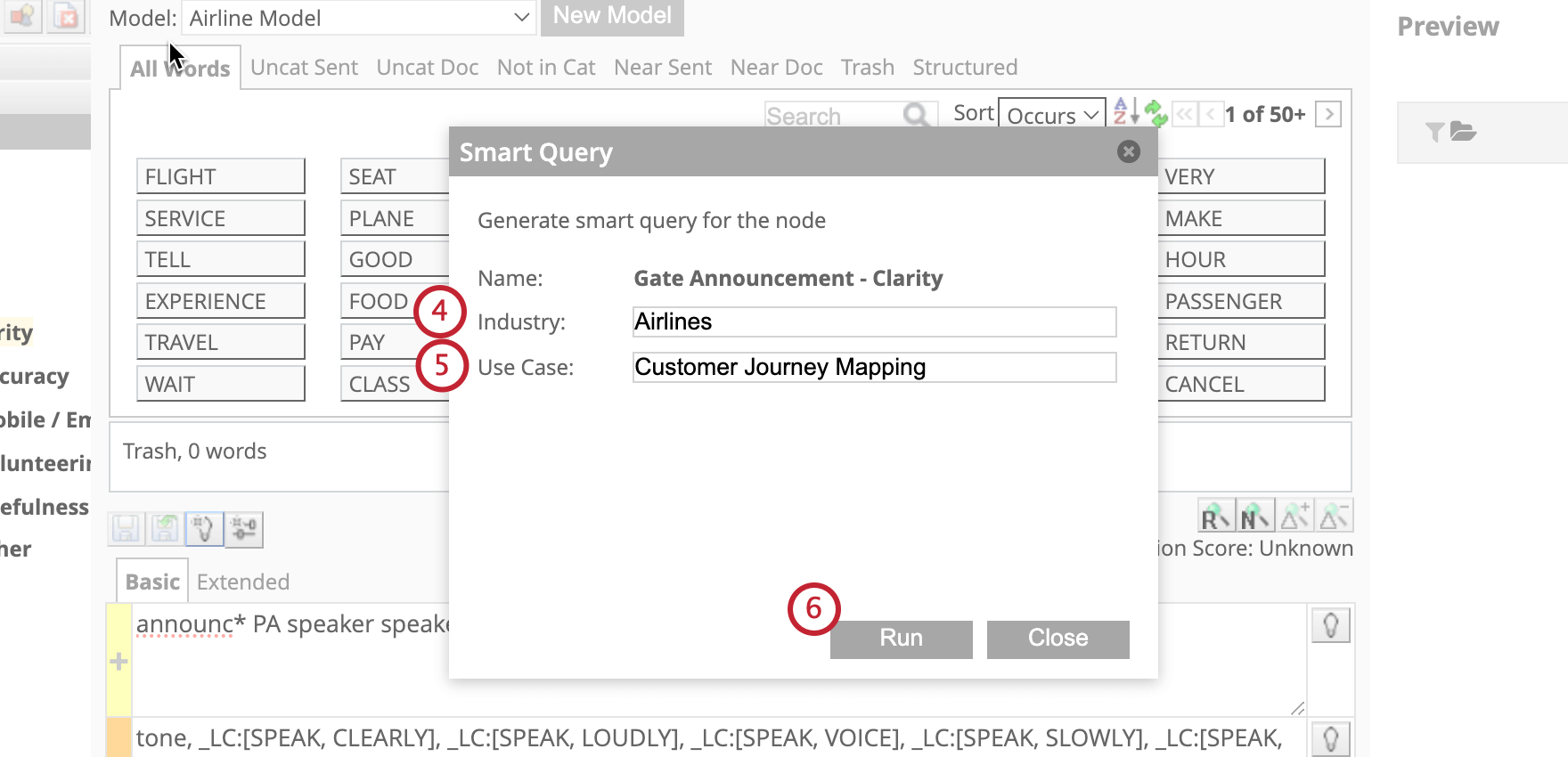
スマートクエリを使ったルールの作成と編集
スマート・クエリは、人工知能(AI)を使用して、ユースケースに基づいたルールを生成します。これは、より複雑なカテゴリーモデルの育成に役立つ。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
ユースケースを入力するためのベストプラクティス
ユースケースはオープンテキストのフィールドで、スマートクエリがどのようにルールを構築するかを指示することができます。ユースケースを作成するためのベストプラクティスを紹介します:
- 重要な役割と視点を明確にする:依頼者としての自分自身と、自分の役割について説明する。
- モデルのフォーカスエリアを明確にする:ITの枠を超えて、モデルが何をするのかを説明する。
- 望ましい結果を含める:このユースケースで達成したいことを記述します。
- データを明確にし 一字一句 ソース 分析に使用するデータと、そのデータの性質および/または提供者を明記する。
- 重要なタッチポイントを明記する:タッチポイントが発生する可能性のある重要なエリアを示す。また、網羅的なリストでない場合は、他のタッチポイントも考慮する必要があることに注意することもできる。
- 詳細とカバー範囲のバランスをとる: 十分に詳細でありながら、様々なシナリオをカバーするのに十分な広さのルールを入力できるようにする。また、使用したいルールレーンの詳細レベルや数を明確にすることもできる。
例:
“I am a [role] querying [data/verbatim source] for [company name]. 私は[role]で、[company name]の[data/verbatim source]を照会しています。このモデルは[モデルのフォーカスエリア]に焦点を当てている。私は[望む結果]を目指している。重要なタッチポイント]に関連するクエリのインクルージョンを検討する-これはすべてを網羅するリストではなく、他の関連するクエリを含める必要がある。過度に制限することなく、[データソース]言語とは異なる表現をアカウントとするルールを作成する。” すべてのインクルージョン・レーンを使用すべきではない。
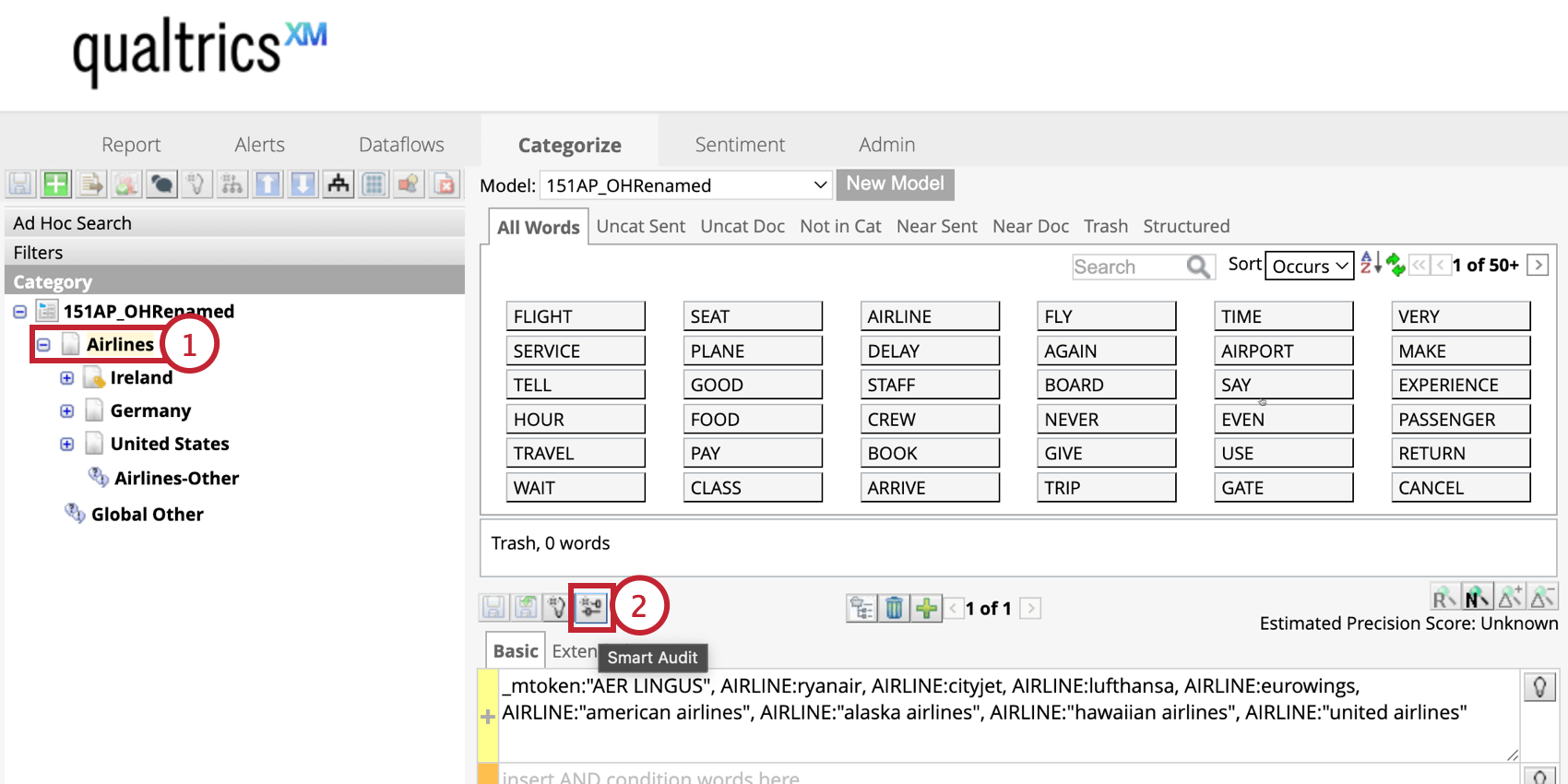
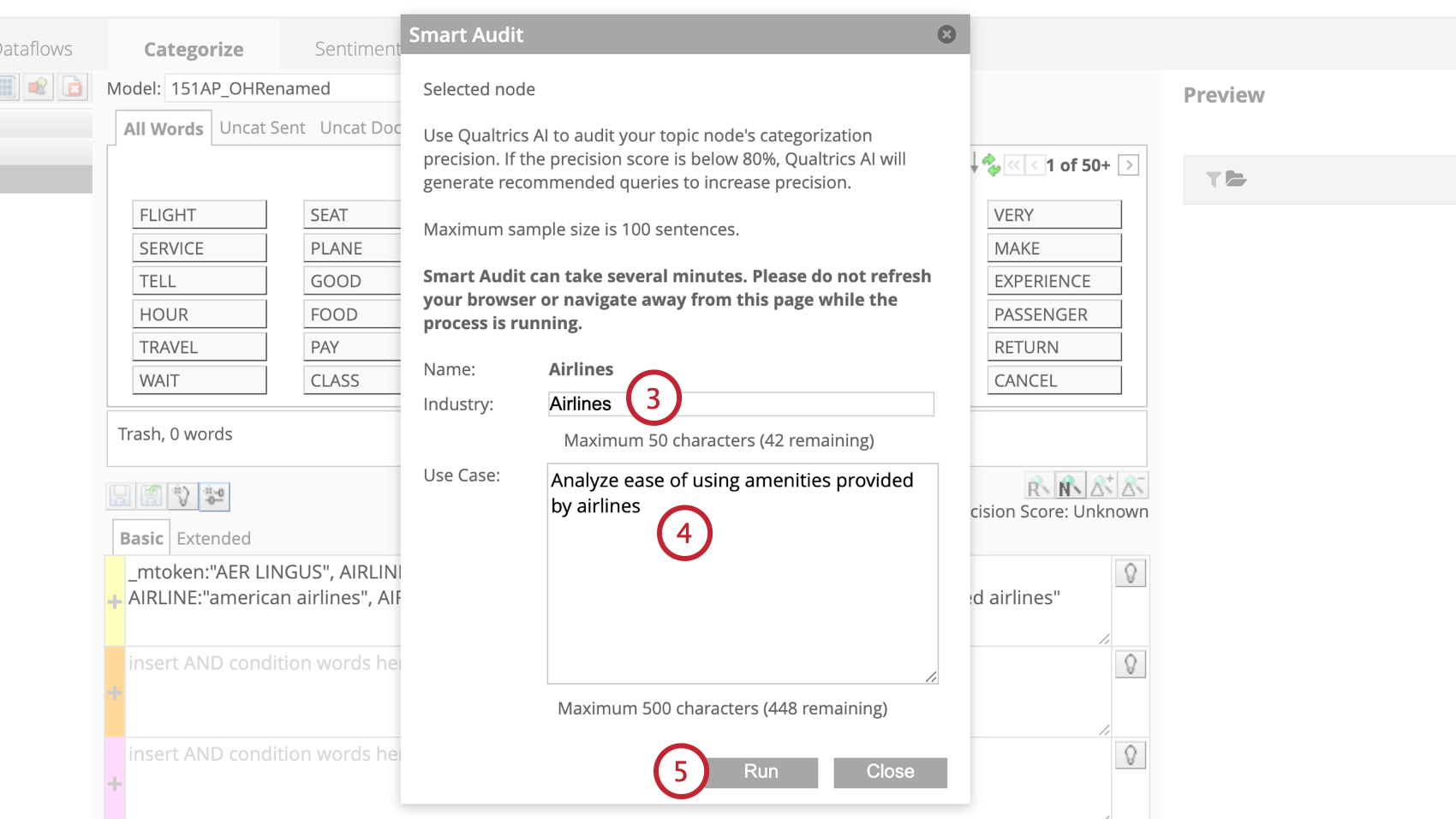
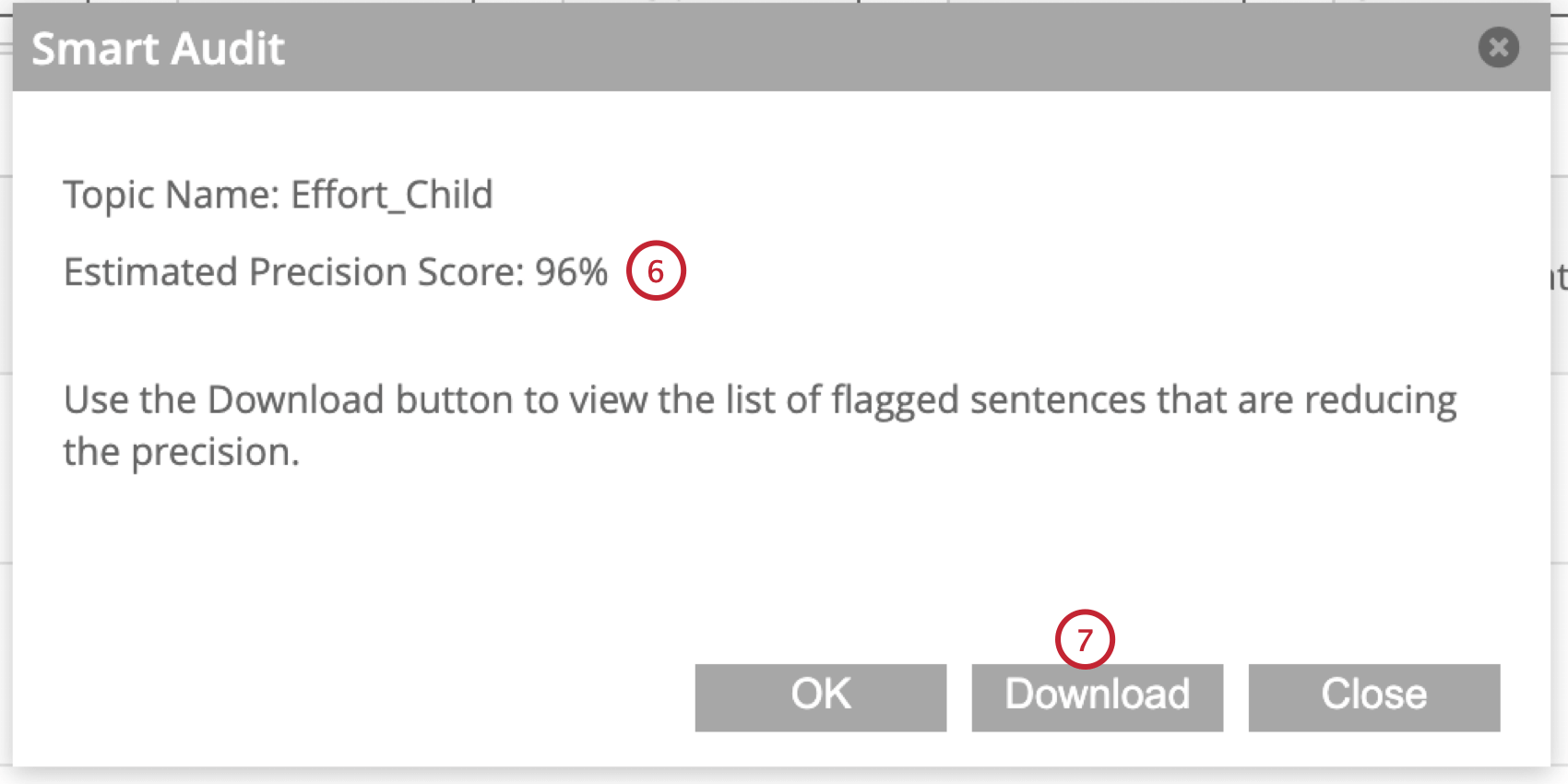
スマート監査
Smart auditは、生成人工知能(AI)を使用して、XM Discoverのトピッククエリを強化します。トピックにタグ付けされた文章を分析し、クエリの精度スコアをリングし、モデルから削除すべき文章を特定します。
Qtip:スマート監査は、アカウント管理者が有効または無効にすることができます。
ベストプラクティス
- アドホック・サーチを使用して、カテゴリー・モデルを変更することなく、データを探索し、ルールを試すことができます。
- 基本的なルールでノードを埋めるか、既存のカテゴリのルールを再利用します。
- テーマ検出を使用して結果を絞り込む。
- 構造化属性とシステム属性に基づいてデータをフィルタリングします。
- ソースの強調表示を使って文章をプレビューし、その文章がどのカテゴリに割り当てられているかを確認できます。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!