ユニオン(CX)
このページの内容
ユニオンについて
データモデルでは、ユニオンを利用すると複数のデータソースを1つのデータセットに結合することができます。ユニオンは、ジョインのようにデータの各行を結合するのではなく、同じデータセットに別の行を追加します。
ヒント:ユニオンはデータマッパーでデータを結合する唯一の方法です。
ユニオンの詳細
ユニオンを理解するために、例をいくつか見てみましょう。
例1
2019年と2020年に同一のNPSアンケートを実施しました。これら2つのアンケートのユニオンを作成すれば、ダッシュボードで両方のデータに基づいたレポートを作成できます。
平均NPSパフォーマンスを表示するウィジェットを作成したい場合、両アンケートのNPSデータを使用することでそれが実現可能になります。
2019年アンケートデータ
| NPSスコア | 部門 |
|---|---|
| 10 | 衣料品 |
| 9 | 電子機器 |
| 7 | 家庭用品 |
2020年アンケートデータ
| NPSスコア | 店舗 |
|---|---|
| 5 | トロント |
| 6 | ローリー |
| 9 | シアトル |
結果のデータセット
| NPSスコア | 部門 | 店舗 |
|---|---|---|
| 10 | 衣料品 | Null |
| 9 | 電子機器 | Null |
| 7 | 家庭用品 | Null |
| 5 | Null | トロント |
| 6 | Null | ローリー |
| 9 | Null | シアトル |
例2
2019年と2020年にNPSアンケートを実施しました。ただし、各年に追加および削除した質問がいくつかあります。2つのアンケートをユニオン結合すれば、ダッシュボードで両方のデータに基づいたレポートが可能です。
平均NPSのウィジェットを作成したい場合、両アンケートのNPSデータを使用することでそれが実現可能になります。NPSのデータは両アンケートに共通しているためです。
部門についてのレポートも作成したい場合は、ダッシュボードにもう1つのウィジェットを追加できます。ただし、2020年のアンケートには部門のデータがないため、このウィジェットに含まれるのは2019年のデータのみとなります。
2019年アンケートデータ
| NPSスコア | 部門 |
|---|---|
| 10 | 衣料品 |
| 9 | 電子機器 |
| 7 | 家庭用品 |
2020年アンケートデータ
| NPSスコア | 店舗 |
|---|---|
| 5 | トロント |
| 6 | ローリー |
| 9 | シアトル |
結果のデータセット
| NPSスコア | 部門 | 店舗 |
|---|---|---|
| 10 | 衣料品 | Null |
| 9 | 電子機器 | Null |
| 7 | 家庭用品 | Null |
| 5 | Null | トロント |
| 6 | Null | ローリー |
| 9 | Null | シアトル |
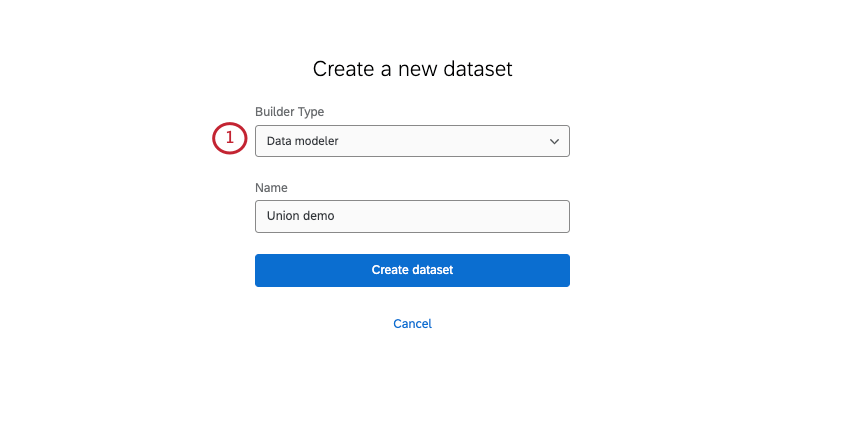
ユニオンの作成
ヒント:1つのデータセットにつき作成できるユニオンは3つです。
ヒント:ジョインの作成を予定している場合は、ユニオンを作成した後にジョインを作成することをお勧めします。こうすることでダッシュボードで最速のパフォーマンスを得られます。
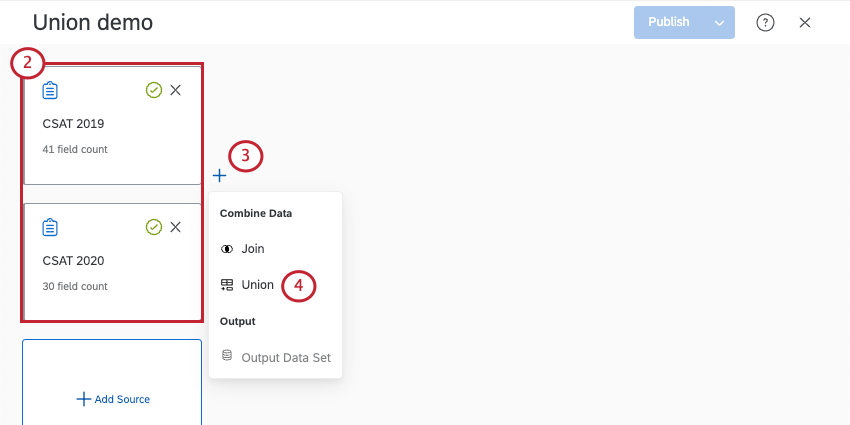
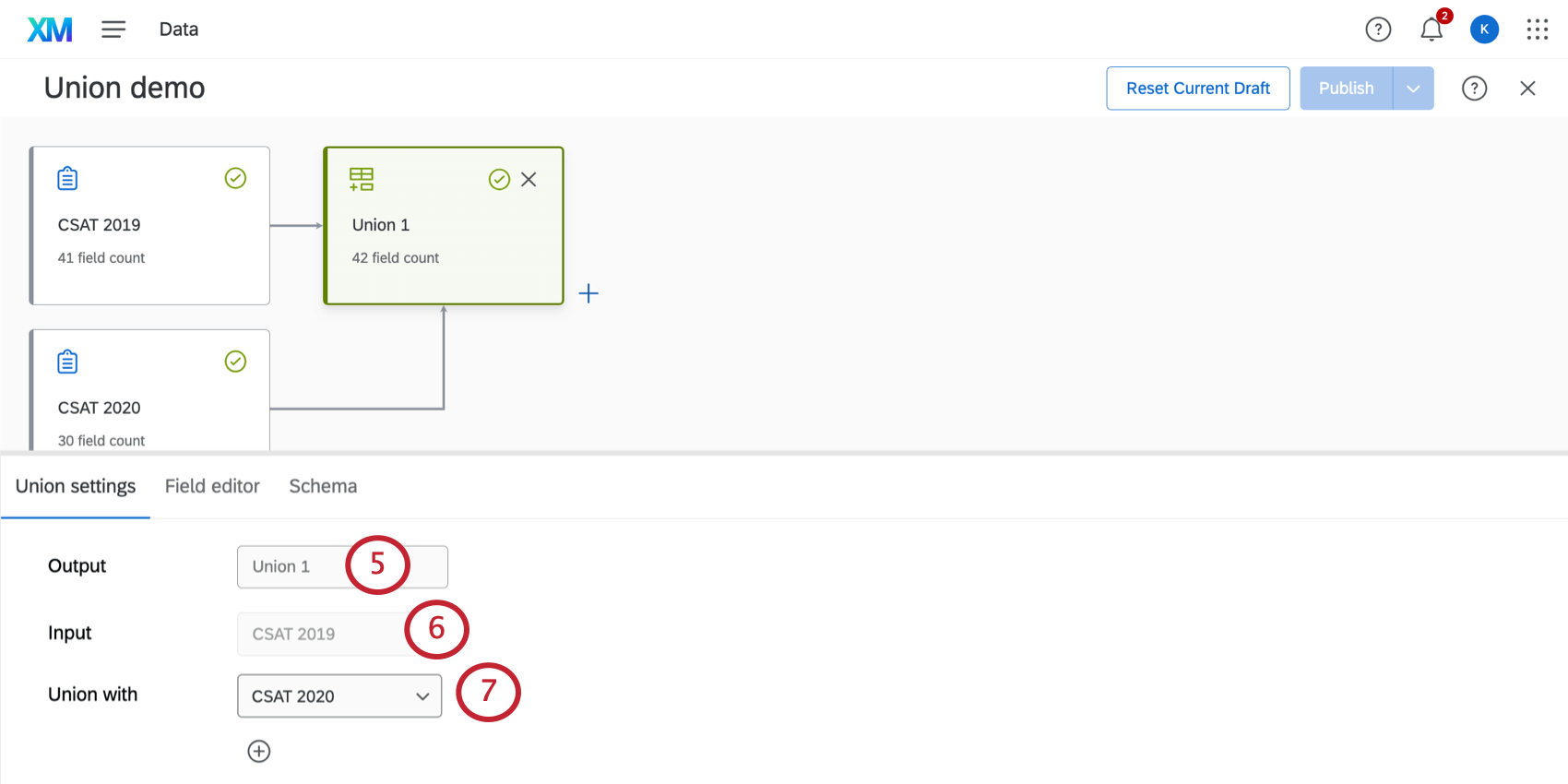
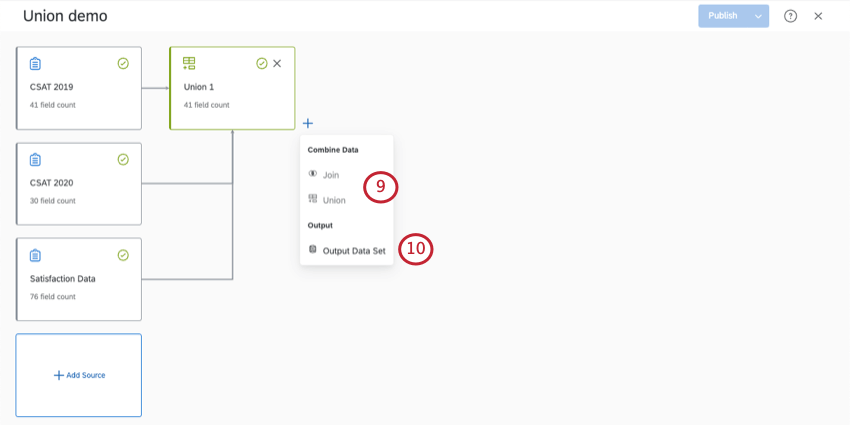
ヒント:プラス記号(+)をクリックすると、ほかのソースをユニオンに追加できます。
![下部メニューの[フィールドエディター]タブ](https://www.qualtrics.com/m/assets/support/wp-content/uploads//2023/11/union-cx-4.png)
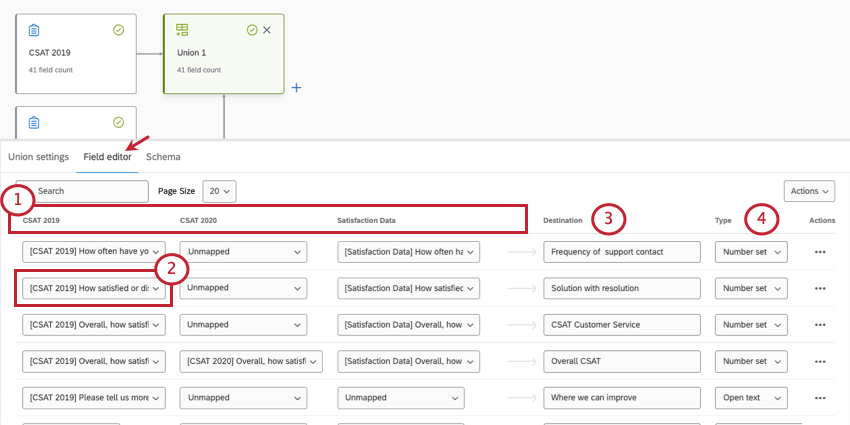
フィールドのマッピング、結合、分離
データをマッピングすることで、ダッシュボードのデータに相応する、アンケートの質問とメタデータを指定できます。ユニオンを作成する際には、異なるアンケートの類似した質問が同じダッシュボードフィールドにマッピングされます。
例:3つの異なるアンケートに含まれている、全体的な顧客満足度に関する同一の質問は、全体的なCSATという名前のダッシュボードフィールドにマッピングされます。


検出された類似性に基づいて、多くのフィールドが自動的にマッピングされます。ただし、必ずデータを再確認して正確さを図ることが重要です。
ヒント:フィールドが自動的にマッピングされるのは、各ソースのフィールド名が完全に一致する場合のみです。例えば、あるソースに「Age」というフィールド名があり、2つ目のソースに「Q3 – Age」というフィールド名がある場合、それらは自動的にはマッピングされません。しかし、両方のソースでフィールド名が単に「Age」となっている場合、両者は一緒にマッピングされます。
すべてのデータマッピングはフィールドエディタータブで行います。
![ユニオンのブロックがクリックされた状態。ページ下部に沿って開くメニューに表示される[フィールドエディター]](https://www.qualtrics.com/sites/default/files/styles/standard_xl_retina/public/migrations/dsx/content/union-cx-7_3.png.webp?itok=9ZILG_R6)
例:この行では、「CSAT 2019」および「Satisfaction Data」アンケートの各質問が「Solution with resolution」フィールドにマッピングされています。「CSAT 2020」はこのフィールドにマッピングされていません。
すべてのソースをすべてのフィールドにマッピングする必要はありません。マッピングのない項目が残っていても問題ありません。必要に応じて、複数のデータソースから同じフィールドにデータを結合することも、データを分離しておくことも可能です。
例:この3つのアンケート調査で収集した「場所」データは、同じ情報を表すものではありません。1つは店舗の場所、もう1つは顧客の自宅の場所です。一致するソースだけをマッピングし、ほかのソースはマッピングしないようにすることで、これらのフィールドを別々に処理します。
![マッパーでは各フィールドが分離されており、[マッピングされていない]と表示される列もある](https://www.qualtrics.com/sites/default/files/styles/standard_xl_retina/public/migrations/dsx/content/union-cx-8_4.png.webp?itok=lP0rFlmz)
![マッパーでは各フィールドが分離されており、[マッピングされていない]と表示される列もある](https://www.qualtrics.com/m/assets/support/wp-content/uploads//2023/11/union-cx-8.png)
{kind=link}
新しいフィールドの追加
新しいフィールドは、既存のデータモデルにあるユニオン、元のソース、あらゆるジョインに追加可能です。新しいフィールドを追加する場合は、必ずモデル内のすべてのノードに追加する必要があります。
より詳細な手順については、「新しいフィールドの追加」を参照してください。
FAQs
Are changes to data models reflected immediately in dashboards?
Are changes to data models reflected immediately in dashboards?
If you have multiple sources of the same type in your dataset (such as tickets and surveys), we generally recommend creating unions before you create joins.
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!