スタジオでのフィルター
スイート
Customer Experience
製品
Qualtrics
このページの内容
フィルターについて
フィルタを使用すると、レポートでデータのサブセットを表示できます。Studioは2種類のフィルターをサポートしています:
- Designer フィルタ:Designerで作成した共有フィルタを、対応するStudioウィジェットに適用できます。デザイナー・フィルターはそのまま使用され、Studioで変更することはできません。
- スタジオフィルター:Studio 内で、日付、レポート属性、コンテンツプロバイダーのトピックに基づいてカスタムフィルタを定義できます。スタジオ・フィルターは、スタジオではウィジェットへの適用、共有、変更、削除ができますが、デザイナーではできません。
フィルタの編集、共有、複製などの詳細については、スタジオでのフィルタのマネージャーを参照してください。
フィルターページへのアクセシビリティ
上部ナビゲーションエリアの「スペース」メニューをクリックします。
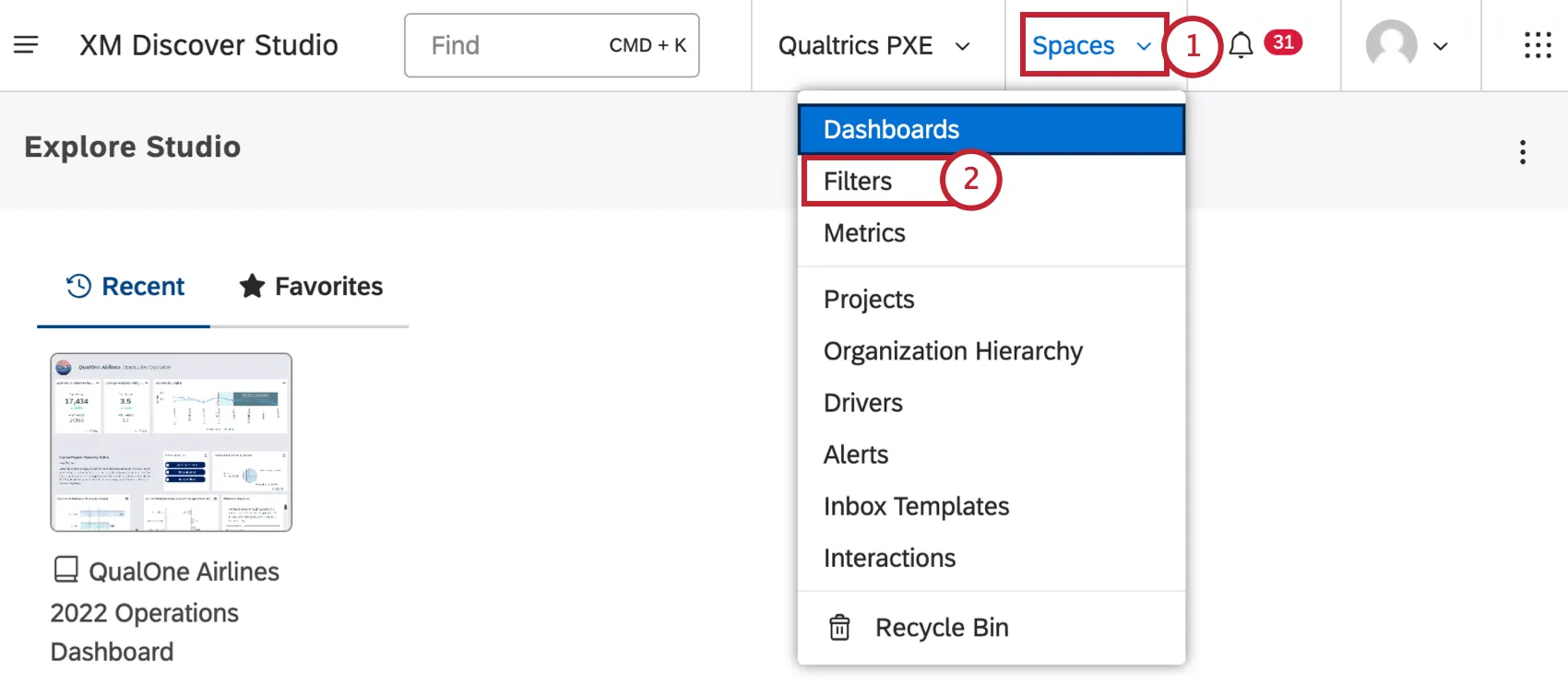
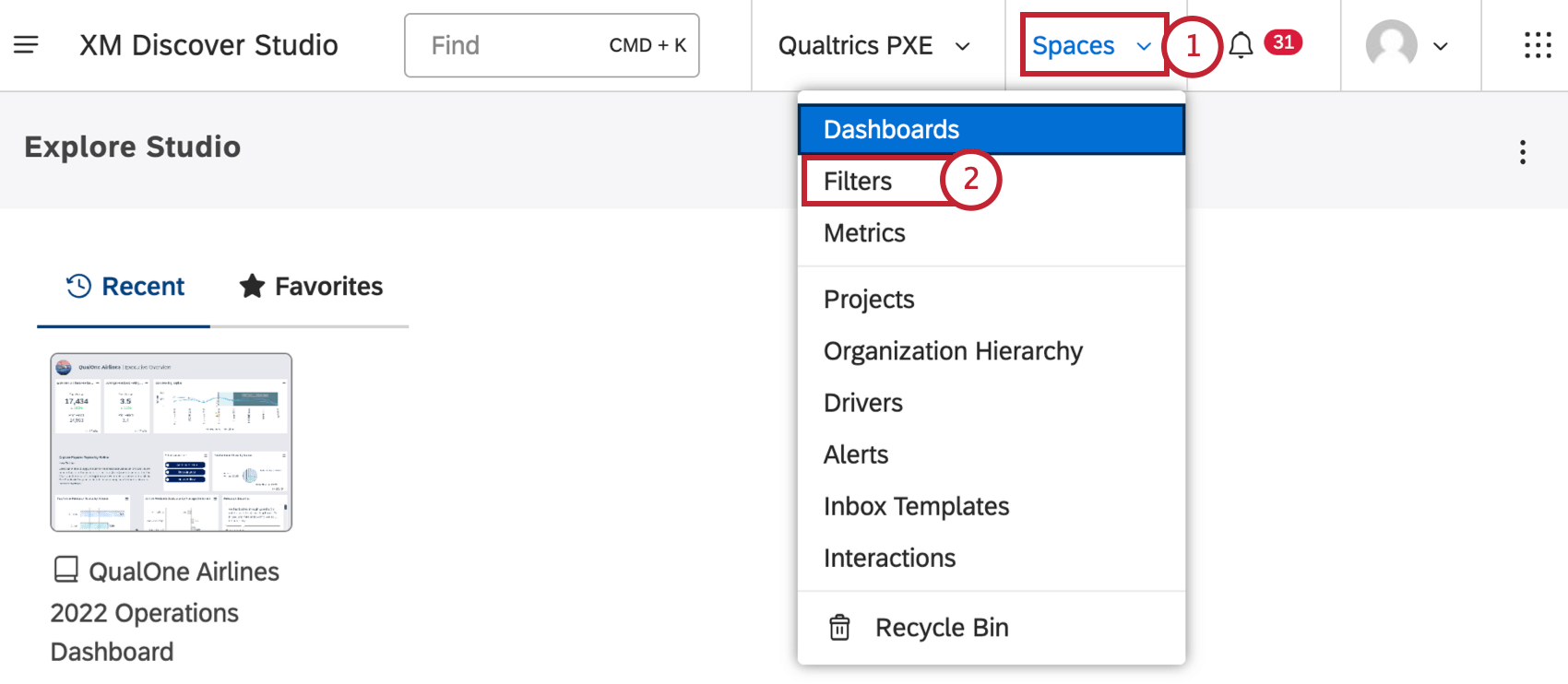
フィルターを選択する。
フィルター ページの概要
Qtip: コンテンツ・プロバイダにリンクされているユーザーだけが、スタジオとデザイナーで作成したフィルタをフィルタ・ページで管理できます。
フィルター・ ページでは以下のことができる:
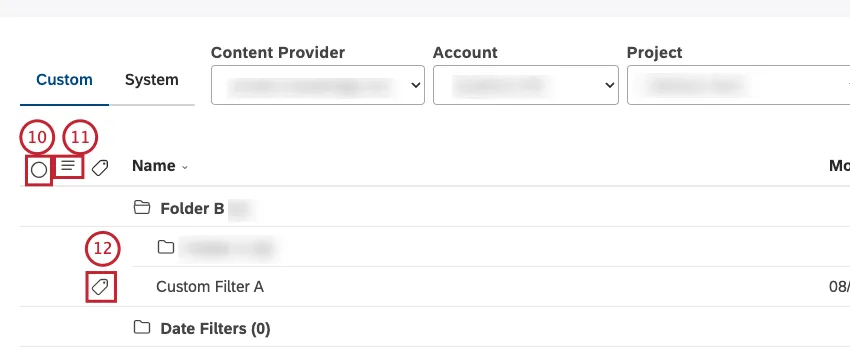
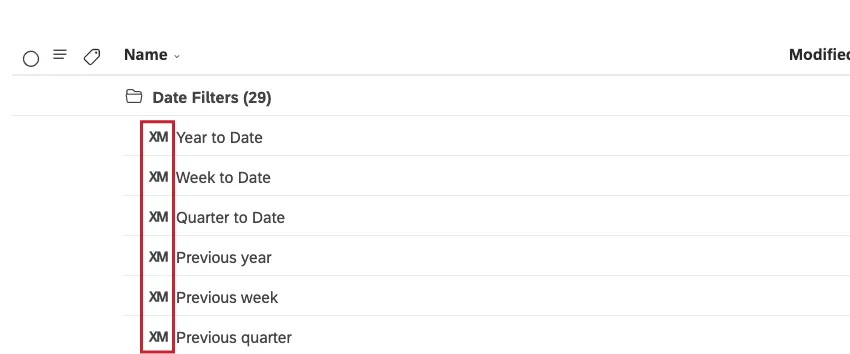
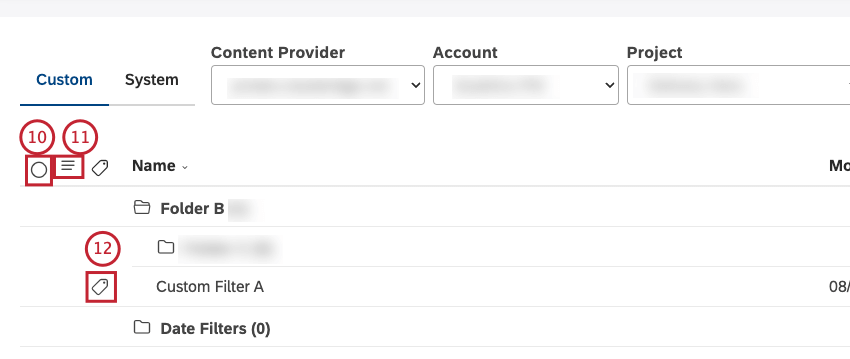
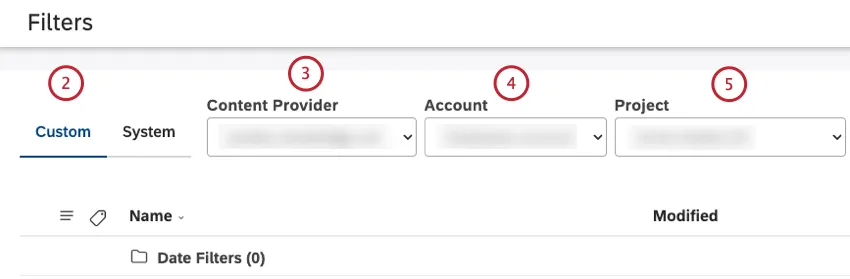
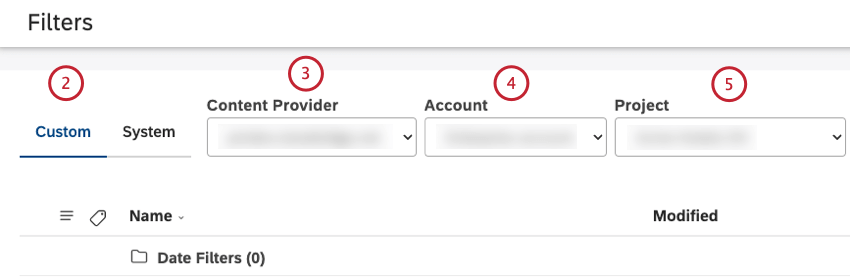
カスタムタブでユーザー定義のフィルターにアクセ スします。すべてのカスタム日付フィルターは、Date Filters フォルダ内に保存されます。
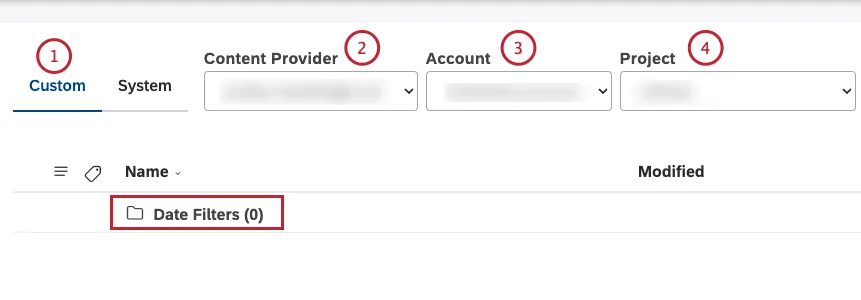
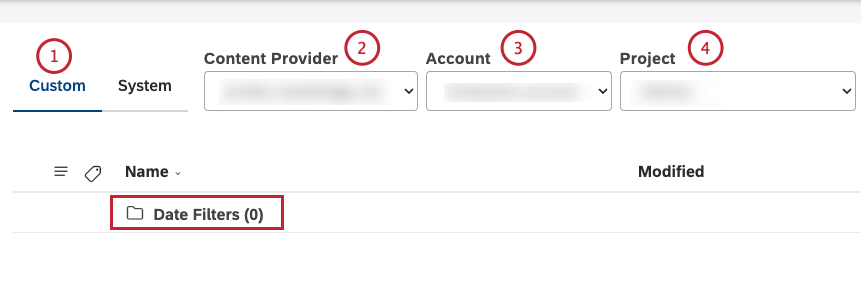
コンテンツプロバイダーを選択します。
複数のアカウントにアクセシビリティがある場合は、アカウントを選択してください。
複数のプロジェクトにアクセシビリティがある場合は、プロジェクトを選択してください。
フィルタとラベルの検索 ボックスを使用して、名前またはラベルでフィルタを検索します。
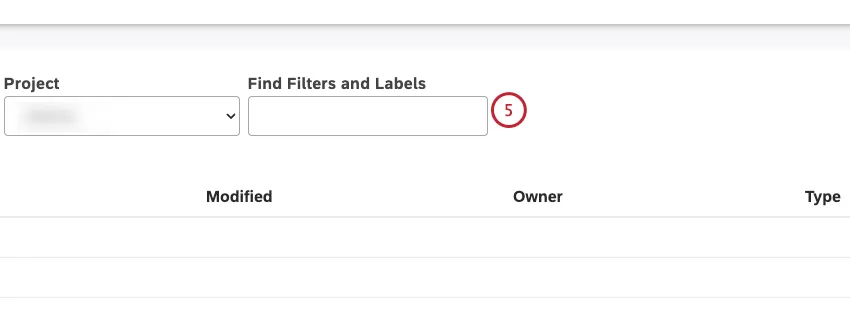
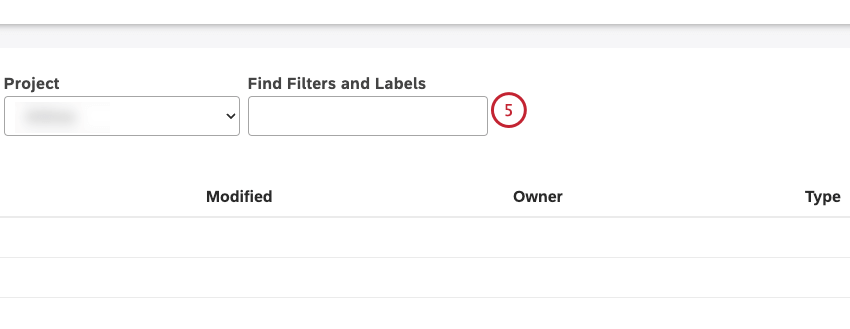
Qtip: 「フィルターとラベルの検索」ボックスに「labels」と入力すると、ラベルのあるフィルターだけが表示されます。
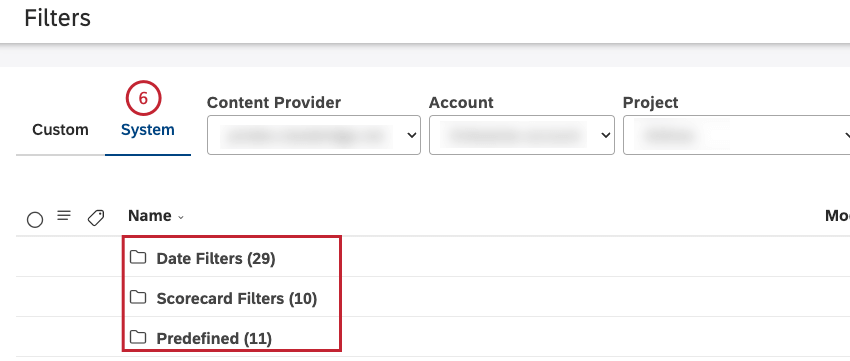
システム」タブで以下のフィルターにアクセシビリティを設定します:
- 日付フィルター
- 定義済み(例:Effort Detected(定義済み)
- スコアカードフィルター
- デザイナーフィルター
![システム]タブのアクセシビリティフィルタ](https://www.qualtrics.com/sites/default/files/styles/standard_xl_retina/public/migrations/dsx/content/filters_system_6_4.png.webp?itok=IZf1Zi-s)
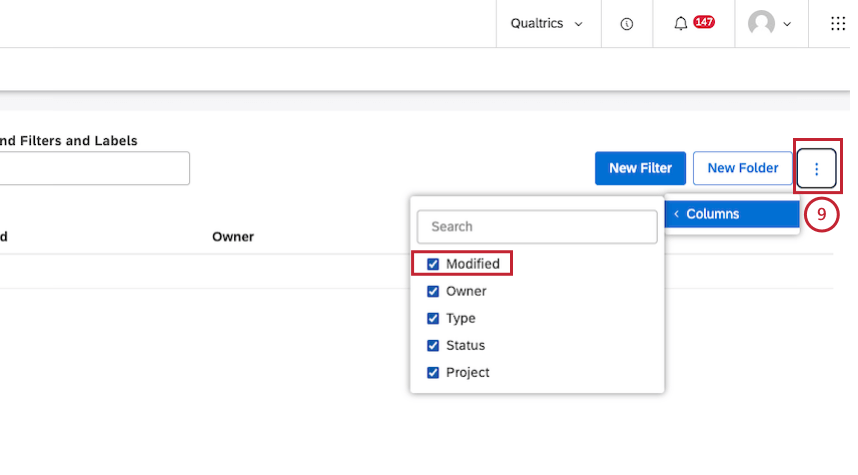
新しいフィルタを作成するには、「新しいフィルタ」をクリックします。
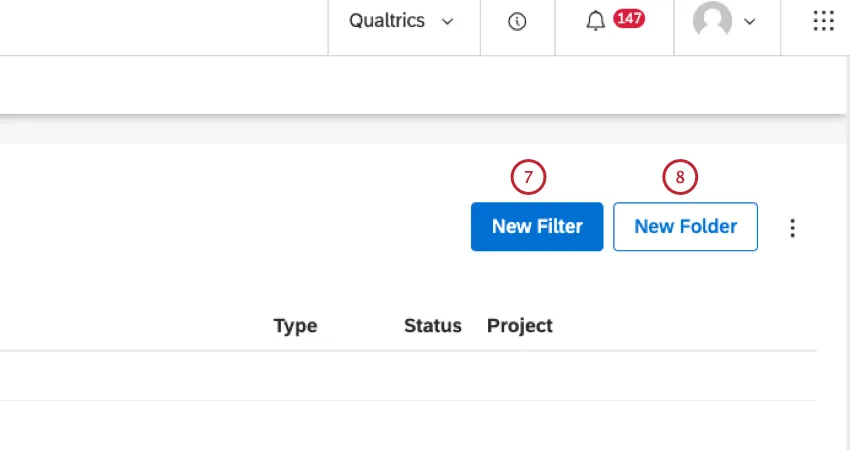
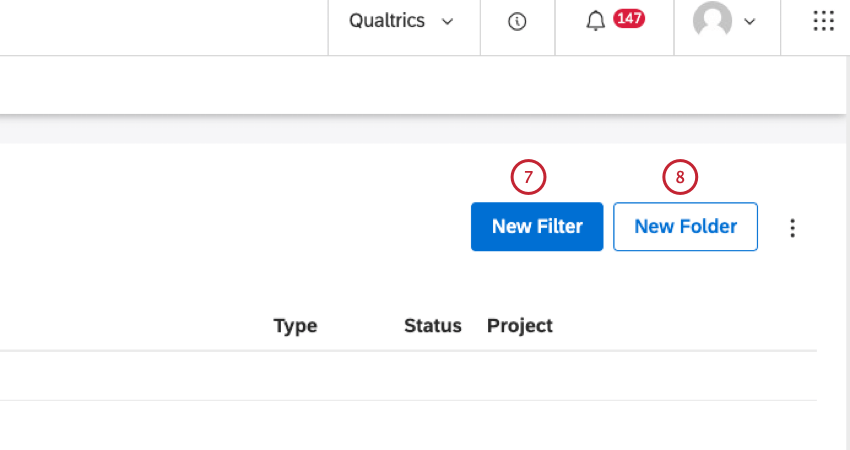
フィルタを整理するフォルダを作成するには、「新規フォルダ」をクリックします。
このページの表に表示するオプションの列を選択します。これを行うには、オプションアイコンをクリックし、表示したい列の次へチェックボックスが選択されていることを確認します。この設定はユーザーによって異なります。

現在の選択項目に応じて、一番上のチェックボックスを使用して、すべての項目を選択または選択解除することができます。
選択項目は、非表示で見えない項目や、検索クエリによってフィルタリングされた項目には適用されません。
選択項目は、非表示で見えない項目や、検索クエリによってフィルタリングされた項目には適用されません。
フィルター情報の表示
フィルター」ページの表には、以下の情報が記載されています:
Name 列のフィルター名。
Qtip: XMアイコンはスタジオページ全体のすべてのシステムオブジェクトを表します。
Modified 列の現在のユーザーのタイムゾーンに従って、このフィルターが作成された、または最後に修正されたタイミング。
フィルタの現在の所有者をOwner列に表示します。
- 私:現在のユーザーが所有するフィルターについて。
- XM Discover:システムフィルター用。


- Studioユーザーが作成したフィルター用のStudio。
- 日付フィルタをプリセット。
- 感情、努力、感情強度の各バンドに定義済み。
- ルーブリック基準に基づく自動フィルタ用のスコアカード。
- Designerで作成されたフィルター用。
- プライベート:プライベートフィルターは、作成したユーザーのみが使用できます。Studioでフィルタを作成すると、デフォルトで非公開になります。
- 共有:共有フィルターは、共有されたユーザーが使用することができます。
- 公開:パブリックフィルターは、マスターアカウントのすべてのユーザーが使用できます。すべての Designer 共有フィルタは公開ステータスを持ち、対応するコンテンツ プロバイダにアクセシビリティを持つすべての Studio ユーザーが使用できます。
フィルターの作成
このアクションを実行するには、フィルタの作成権限が必要です。後でレポートウィジェットに適用できるフィルタを作成できます。
Qtip: ウィジェットのプロパティで直接フィルタを定義したり、デザイナーで作成したフィルタを使用することもできます。
カスタム」タブを選択する。
フィルタを作成したいコンテンツプロバイダーを選択します。
Qtip: コンテンツプロバイダーとアカウントは、ユーザー設定でお気に入りとして事前に選択することができます。
アカウントを選択します。
プロジェクトを選択します。
ルート・フォルダー内にフィルターを作成するには、「新規フィルター」ボタンをクリックします。
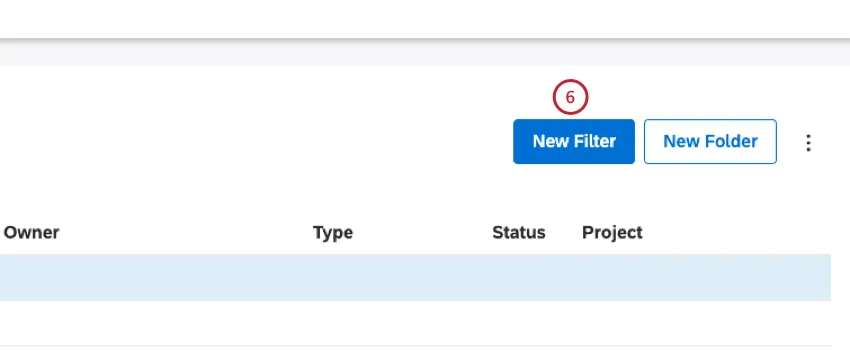
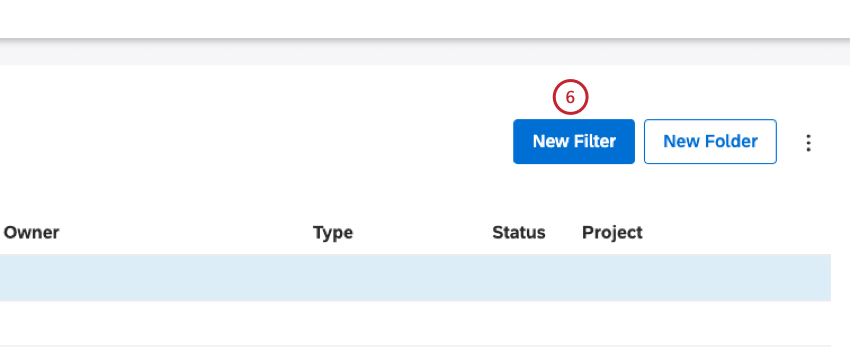
Qtip: 別の方法として、特定のフォルダ内にフィルタを作成するには、そのフォルダの次へアクションメニューを展開し、新規フィルタの作成を選択します。
名前ボックスにフィルターの名前を入力します。
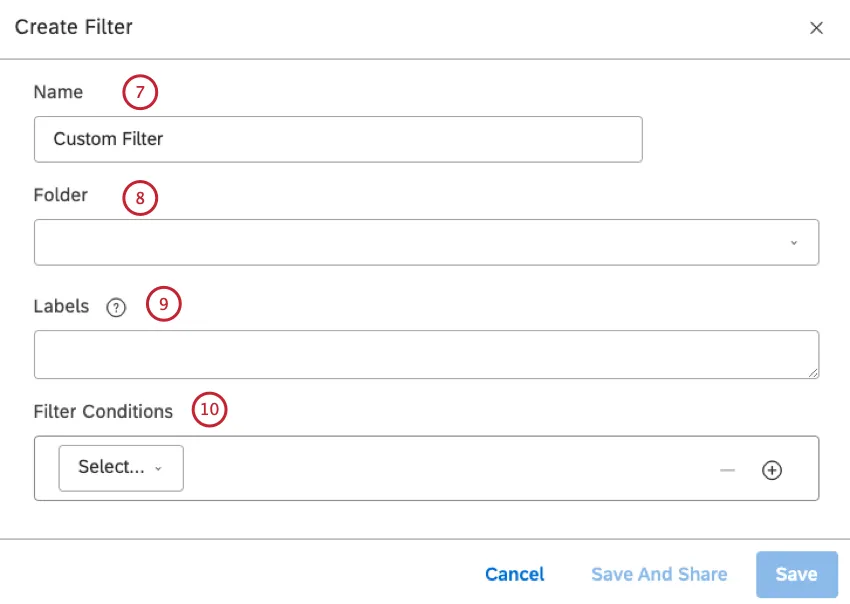
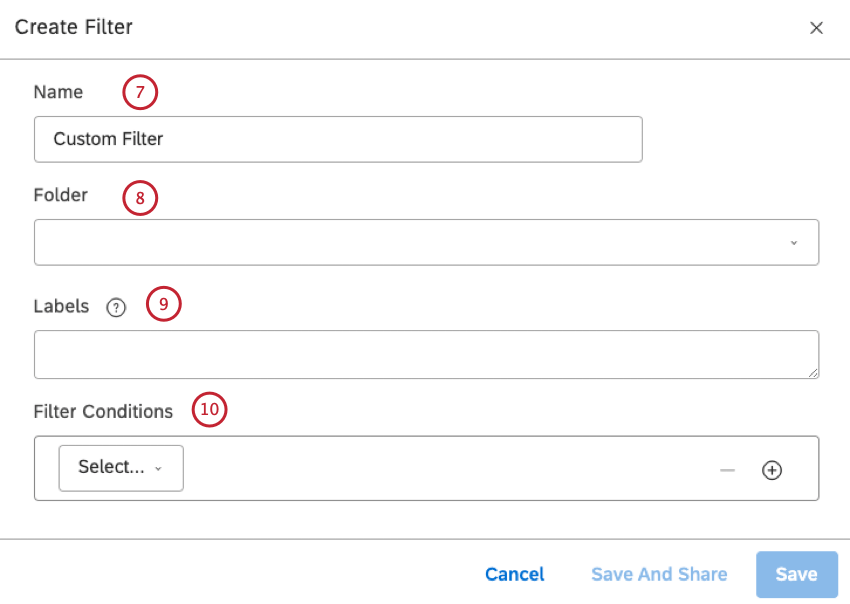
必要であれば、フィルタ用のフォルダをフォルダメニューから選択できます(オプション)。
Qtip: フィルタをルートフォルダに保持するには、フォルダメニューからフォルダを選択しないでください。
Qtip: 日付フィルターは自動的に日付フィルターフォルダーに入ります。
ご希望であれば、フィルターにラベルを追加できます(オプション)。ラベルボックスにラベルを入力し Enter をクリックしてラベルを保存し、別のラベルを追加します。詳しくは、フィルタのラベリングを参照してください。
フィルターには最大5つの条件を追加できます。Select メニューで条件を選ぶ。
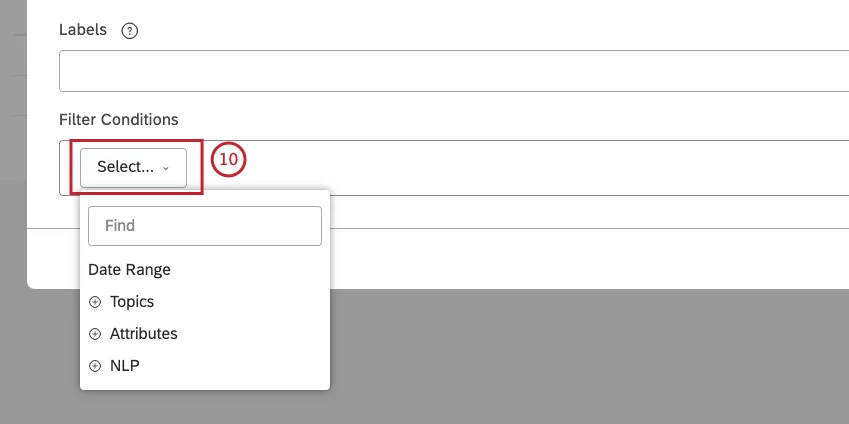
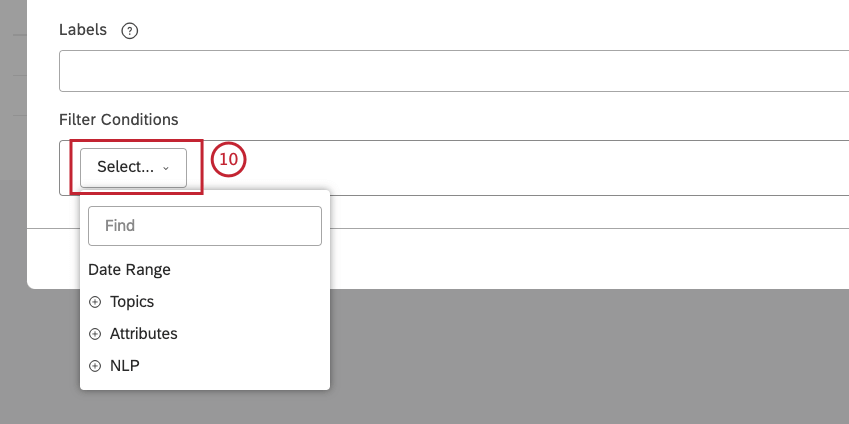
Date Range を選択して、カスタム日付範囲を定義し、日付でフィードバックをフィルタリングします。カスタム日付範囲については、カスタム日付範囲の定義を参照してください。定義済みの日付範囲については、日付範囲フィルタを参照してください。
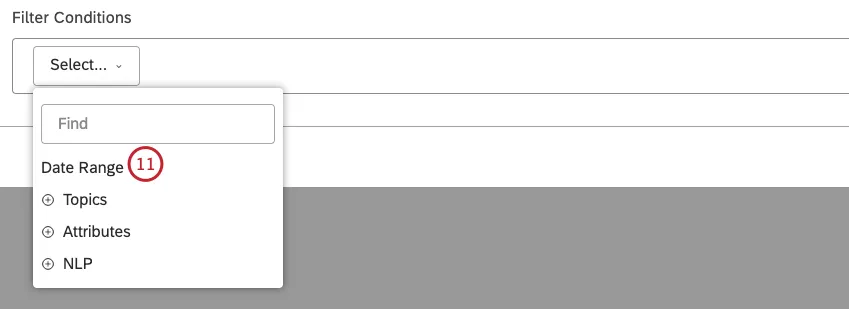

Qtip: この条件は、レポート、トレンド、アラートなどで使用される主要な日付フィールドであるDocument Dateを使用します。
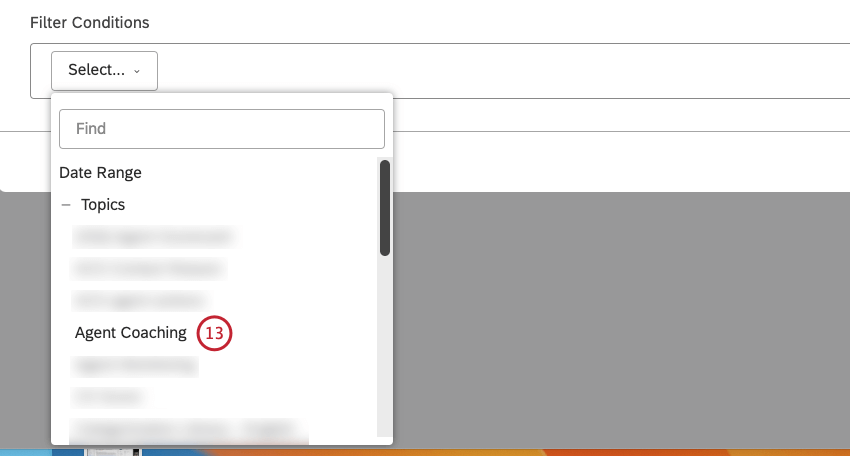
トピック] を選択してカテゴリ モデルを選択し、そのトピック (またはモデル全体) によってデータを フィルタリングします。
![トピック] を選択してカテゴリ モデルを選択し、そのトピック (またはモデル全体) によってデータを フィルタリングします。](https://www.qualtrics.com/sites/default/files/styles/standard_xl_retina/public/migrations/dsx/content/topics_12_4.png.webp?itok=7iGHXSVx)
![トピック] を選択してカテゴリ モデルを選択し、そのトピック (またはモデル全体) によってデータを フィルタリングします。](https://www.qualtrics.com/m/assets/support/wp-content/uploads//2023/09/topics_12.png)
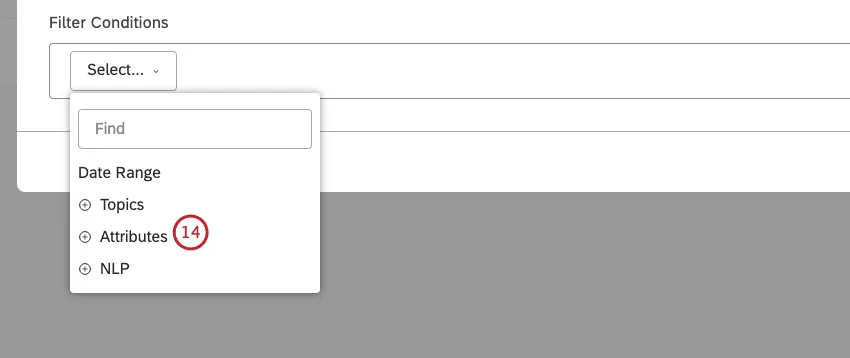
レポート可能な構造化属性を選択し、その値でデータをフィルタリングするか、またはドキュメント日付以外の日付フィールドを選択するには、属性を選択します。
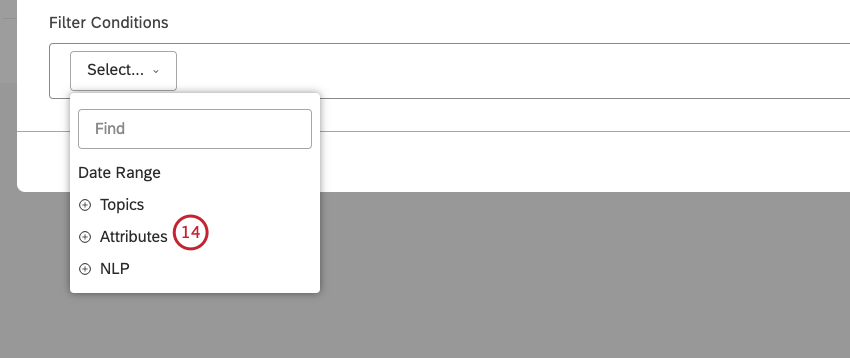
属性を選択します。
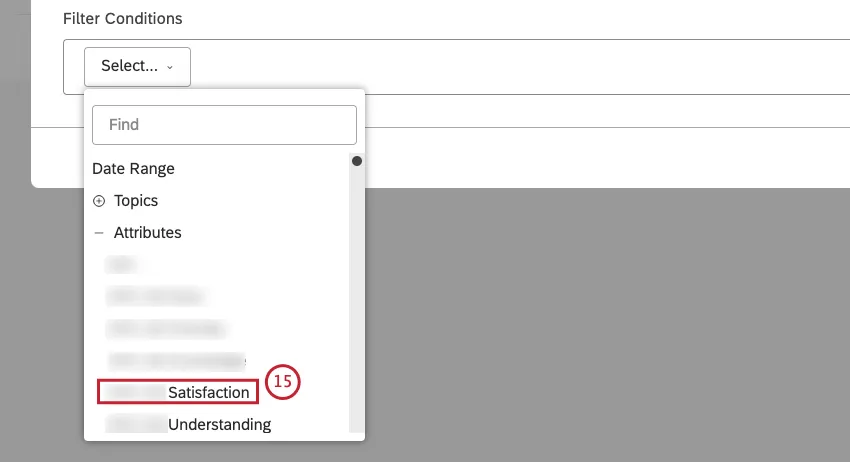

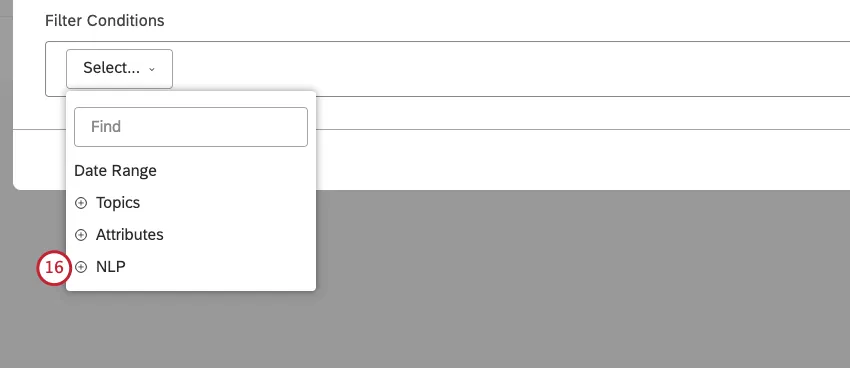
NLP を選択すると、XM Discover 自然言語処理(NLP)エンジンが検出した単語やその他の言語エンティティでデータをフィルターします。詳細については、以下の「NLP条件 」のセクションを参照してください。
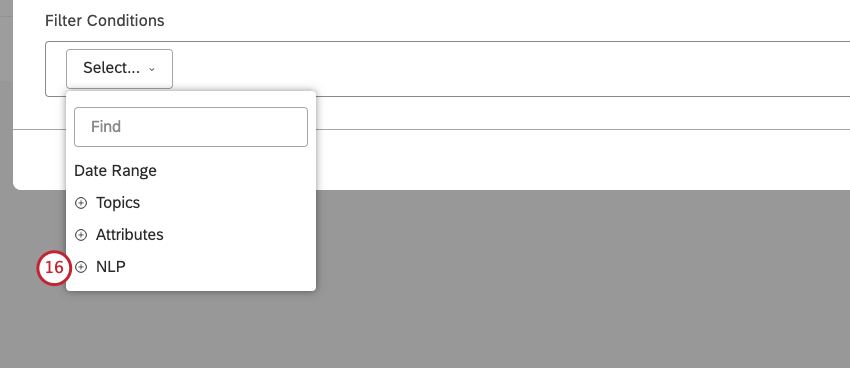
単語や言語エンティティを選択する。
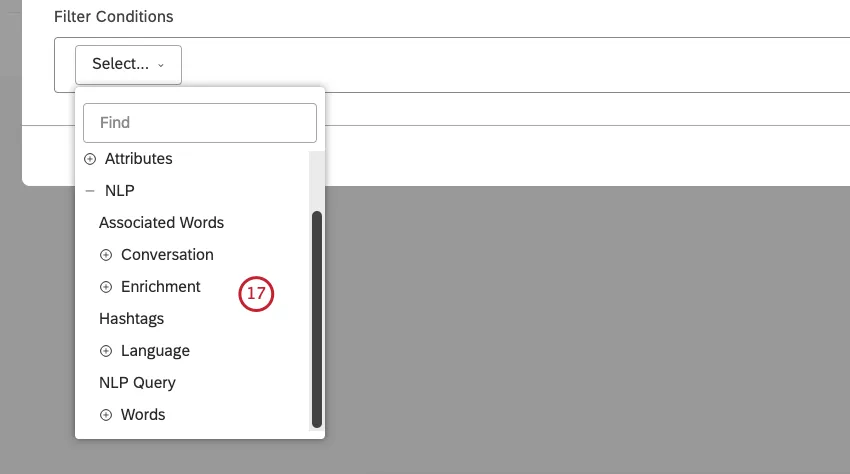
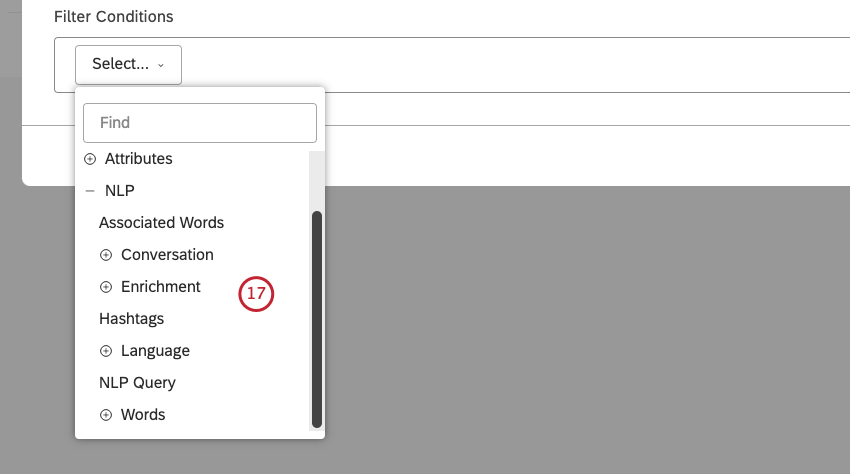
トピック、属性、および NLP エンティティについては、中央のメニューからフィルタ条件の演算子を選択 します。
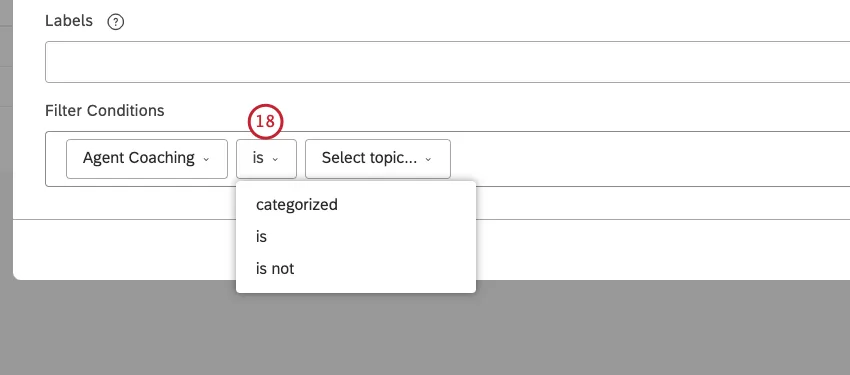
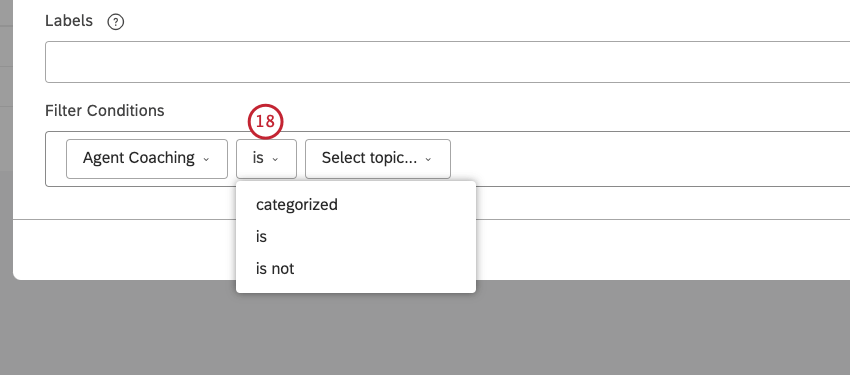
Qtip: 演算子は条件のタイプ(テキスト、数値、日付)に依存します。オペレーターについては、以下の「オペレーター」のセクションを参照のこと。
値の次へチェックボックスを選択して、(選択した条件に応じて)1つ以上の値を選択します。
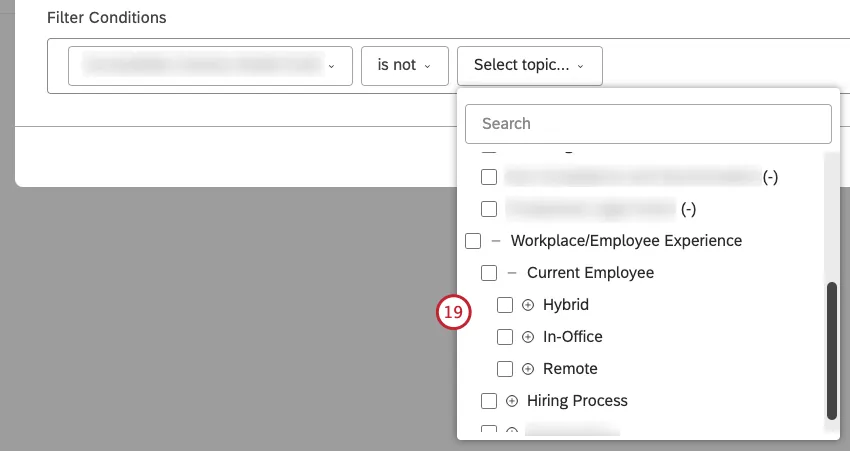
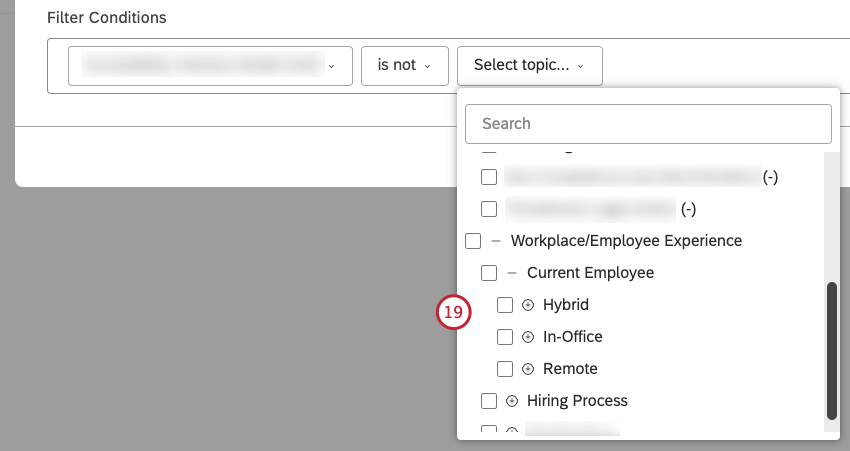
Qtip: 長いリストの場合、検索したい項目の最初の文字を入力すると、一致する値が表示されます。属性とNLPエンティティはかなりの数の値を持つことができるため、結果の洗練されたリストを得るには十分な数の文字を入力する必要があるかもしれません。
探している値が最初の20個の値にない場合は、Load Moreをクリックすると次へ20個の値が表示されます。
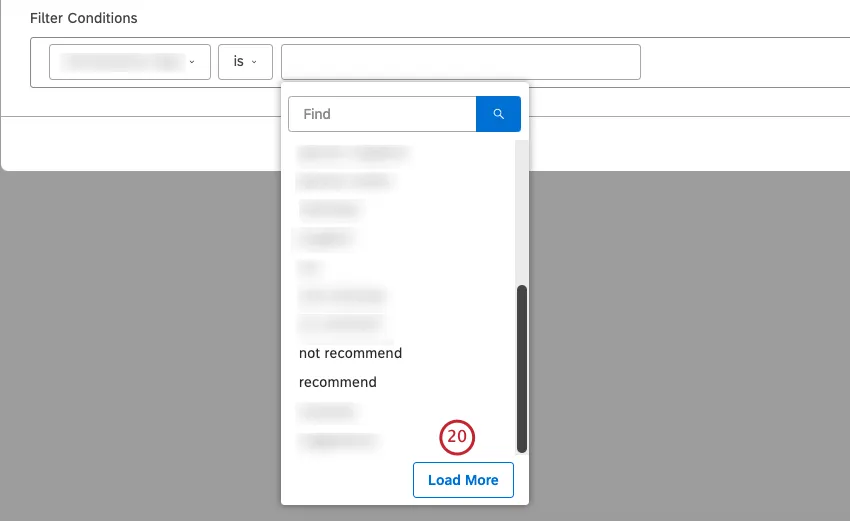
Qtip: キャッシュされた結果をバイパスし、コンテンツプロバイダーから最新の値を取得するには、Load Moreボタンを使用します。
Qtip: 入力した結果に一致するものがない場合、No Updatesというメッセージが表示されます。
条件を追加または削除するには、プラス (+)とマイナス (-)の アイコンをクリックします。
![条件を追加または削除するには、プラス(+)とマイナス(-)のアイコンをクリックします。保存]をクリックするか、[保存して共有]をクリックします。](https://www.qualtrics.com/sites/default/files/styles/standard_xl_retina/public/migrations/dsx/content/save-and-share_21-to-23_4.png.webp?itok=iNaVIXJW)
![条件を追加または削除するには、プラス(+)とマイナス(-)のアイコンをクリックします。保存]をクリックするか、[保存して共有]をクリックします。](https://www.qualtrics.com/m/assets/support/wp-content/uploads//2023/09/save-and-share_21-to-23.png)
Qtip: フィルター条件にはANDがある 同じ条件のフィルター値にはOR関係がある。フィルター作成時に、日付範囲を他の条件と組み合わせることはできません。
保存をクリックしてフィルターを保存し、ウィンドウを閉じます。
または、「保存して共有」をクリックしてフィルターを保存し、「フィルターの共有 」を開きます。フィルターの共有については、「フィルターの共有」をご覧ください。
NLP条件
フィルタを作成する際、NLP条件には以下のオプションがあります:
- ワード
- 関連語
- ハッシュタグ
- エンリッチメント
- 言語
- NLPクエリー
ワード
単語でデータをフィルターする:
- すべての単語:規則的な単語でデータをフィルターします。
- CBブランド:ブランド名でフィルタ。
- CBカンパニー会社名でフィルターをかける。
- CB通貨:通貨名、記号、略語を変えるなど、通貨量でデータをフィルタ。
- CBメールアドレス:フィードバックに記載されたメールアドレスでデータをフィルタ。
- CB Emoticon:ITで使用されている絵文字や顔文字でデータをフィルタします。
- CBイベント:フィードバックで言及された休日やイベントでデータをフィルタ。
- CB業界:業界の関連性でデータをフィルタします。
- CB Person:フィードバックで言及された人の名前でデータをフィルタ。
- CB電話番号:フィードバックに記載された電話番号でデータをフィルタ。
- CB製品:製品の言及によってデータをフィルタリングします。
- CB冒涜:冒涜的な言葉でデータをフィルタリングします。
関連語
連想語のペアでデータをフィルタ。
ハッシュタグ
ハッシュタグ-ハッシュタグ記号(# ) を先頭に持つ単語または空白のないフレーズでデータをフィルタリングします。
エンリッチメント
以下のエンリッチメントオプションの1つでフィルターをかける:
- CBチャプター:会話の意味的に関連する細分化(オープニング、ニーズ、検証、解決ステップ、クロージングなど)でデータをフィルタリングします。
- CB検出機能:検出されたNLP機能の種類によってデータをフィルタリングします。例えば、業界やブランドの言及を含むデータ。
- CBエモーション:NLPエンジンによって検出された感情の種類(怒り、混乱、失望、恥ずかしさ、恐怖、欲求不満、嫉妬、喜び、愛、悲しみ、驚き、感謝、信頼、その他など)によってデータをフィルタリングします。
- CB センテンスタイプ:文の種類によってデータをフィルタリングする。
- コンテンツタイプ:コンテンツがあるか ないかでデータをフィルタする。
- コンテンツのサブタイプ:サブタイプ(広告、クーポン、記事リンク、”undefined “タイプなど)により、非コンテントフルデータをさらにフィルターする。 コンテントフルレコードの場合、サブタイプも常にコンテントフルである。 Qtip: データに何が含まれているかによって、さらにエンリッチメントが可能です。

言語
言語によってデータをフィルターします:
- 自動検出言語:プロジェクトの言語自動検出が有効な場合)自動的に検出された言語でデータをフィルタ。
- 処理言語:フィードバックが処理された言語によってデータをフィルタする。XM Discoverでサポートされていない言語はOTHERと表示されます。サポートされている言語のリストについては、サポートされている言語を参照してください。
NLPクエリー
上から順に4つのルールレーンを使って複雑な検索クエリを定義する:or、and、and、not。
- OR: 顧客のフィードバックから検索するキーワードを1つ以上指定する。ORレーンのみを使用した場合、クエリはここで指定したキーワードのいずれかを含むフィードバックを返します。
- AND 1: 必要に応じて、ORレーン(オプション)のキーワードとともに、顧客のフィードバックから検索するキーワードを1つ以上追加することができます。クエリは、ORレーンのキーワードとANDレーンのキーワードのいずれかを含むフィードバックを返します。
- AND 2: 必要であれば、ORレーンのキーワードとAND 1レーンのキーワード(オプション)とともに、顧客のフィードバックから検索するキーワードを1つ以上追加することができます。
- NOT:必要に応じて、クエリ結果から除外するキーワードを1つ以上指定できます(オプション)。クエリは、ここで指定したキーワードを含まないフィードバックのみを返します。 Qtip: 各ルールレーンには最大1,000文字までのクエリーを含めることができます。
オペレーター
フィルタ条件では、以下の演算子が使用できる:
- です:完全一致を指定する。例えば、CITY is bostonはボストンのすべてのデータを返す。完全一致を複数指定することもでき、その場合、フィルターは(OR関係を使って)いずれかの値を満たすデータを返します。例えば、CITYがboston, new york cityの場合、ボストンまたはニューヨークのすべてのデータが返される。
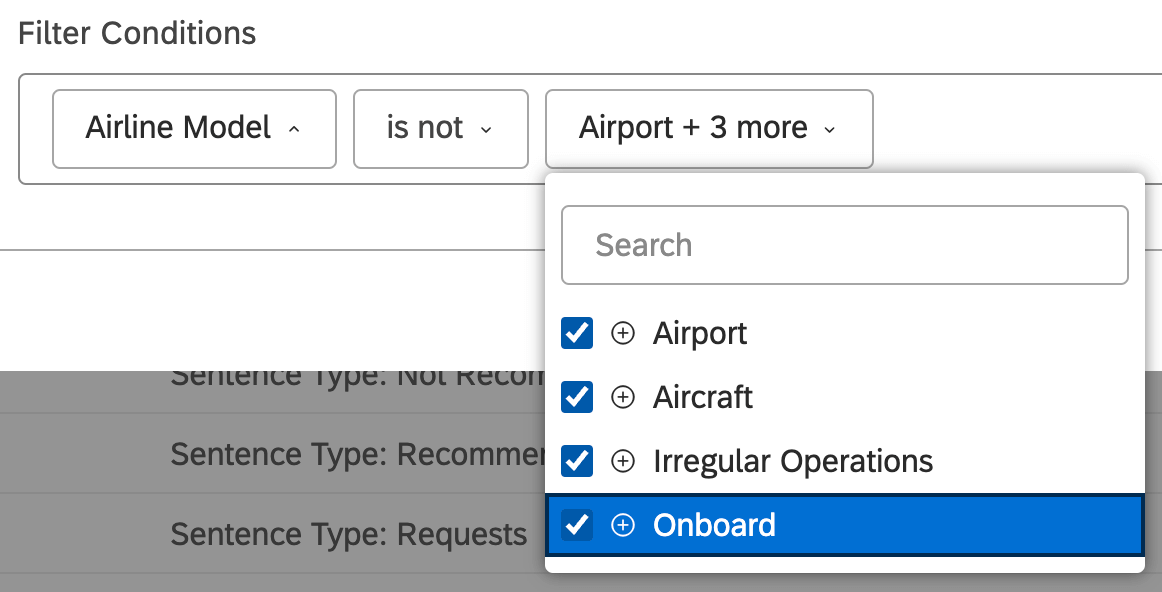
- は除外する:選択した値を除外する。 Qtip:ダッシュボードフィルターは文レベルで最も効果的です。ドキュメントレベルデータを見ている場合(例えば、ドキュメントビューフィードバックウィジェットで)、除外しているモデルにタグ付けされたセンテンスが表示されるかもしれません。したがって、除外フィルタは、バー、ライン、パイのような集約ウィジェットで最もよく機能する。例: ある航空会社のカテゴリーモデルがあるとします。このモデルには、ルートのすぐ下に4つのレベル1ノードがある:空港,航空機,イレギュラー・オペレーション,オンボーディング.以下の例では、これらの4つのノードをフィルターに含めないということは、ルート・ノード(Airline、および適用されたクエリー)の条件に一致する文章だけを探し、それ以外は探さないということです。これは特に文レベルの分析に役立つ。例えば、共通のテーマを探し、それを使ってレベル1のノードを増やすことができる。

 Qtip:“is not “フィルターは便利ですが、カテゴリーモデル全体を除外したい場合は、代わりに “Global Other “バケットを使用することをお勧めします。上記の例で説明したように、”is not “フィルターはダッシュボードでは必ずしも期待通りに動作しないので、このサポートページの手順を使用して未分類のデータを見る方が良いでしょう。
Qtip:“is not “フィルターは便利ですが、カテゴリーモデル全体を除外したい場合は、代わりに “Global Other “バケットを使用することをお勧めします。上記の例で説明したように、”is not “フィルターはダッシュボードでは必ずしも期待通りに動作しないので、このサポートページの手順を使用して未分類のデータを見る方が良いでしょう。
{kind=link}
- の間です:フィルタする属性値の範囲を数値で定義します。
- の間にない:結果から除外する数値属性値の範囲を定義する。
- 以上であることを示す:選択された数値属性の値が、選択されたしきい値以上であるすべてのデータを返します。
- 以下であることを示す:選択された数値属性の値が、選択されたしきい値以下であるすべてのデータを返します。
- categorized:選択されたカテゴリモデルのトピックのいずれかに分類されたすべてのデータを返します。
- に何らかの値がある場合選択した属性に値があるすべてのデータを返します。
- には値がありません:選択した属性に値がないすべてのデータを返します。
当サポートサイトの日本語のコンテンツは英語原文より機械翻訳されており、補助的な参照を目的としています。機械翻訳の精度は十分な注意を払っていますが、もし、英語・日本語翻訳が異なる場合は英語版が正となります。英語原文と機械翻訳の間に矛盾があっても、法的拘束力はありません。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!