Predict iQ
Cosa puoi trovare in questa pagina
Attenzione: State leggendo una funzione a cui non tutti gli utenti hanno accesso. Se siete interessati a questa funzione, contattate il vostro Account Executive per verificare se avete i requisiti necessari.
Informazioni su Predict iq
Quando i clienti abbandonano un’azienda, spesso siamo colti di sorpresa. Se solo avessimo saputo che questo cliente era a rischio, forse avremmo potuto contattarlo prima che perdesse completamente la fiducia in noi. Se solo ci fosse un modo per prevedere la probabilità che un cliente abbandoni l’azienda (churn).
Predict iQ apprende dalle risposte dei sondaggi e dai dati integrati per prevedere se l’intervistato finirà per cambiare azienda. Poi, quando arrivano nuove risposte al sondaggio, Predict iQ è in grado di prevedere la probabilità che i partecipanti al sondaggio cambino in futuro. Per prevedere se un cliente si trasformerà, Predict iq utilizza le reti neurali (un sottoinsieme delle quali è chiamato Deep Learning) e la regressione per costruire modelli candidati. Per ogni serie di dati, tenta variazioni di questi modelli e poi sceglie il modello che meglio si adatta ai dati.
Preparazione dei dati
Prima di creare un modello di previsione di abbandono, è necessario assicurarsi che i dati siano pronti.
Predict iQ dà il meglio di sé quando si dispone di almeno 500 intervistati che hanno effettuato un cambio di programma. Tuttavia, i risultati migliori si ottengono con 5.000 o più intervistati.
Impostazione di una variabile Churn
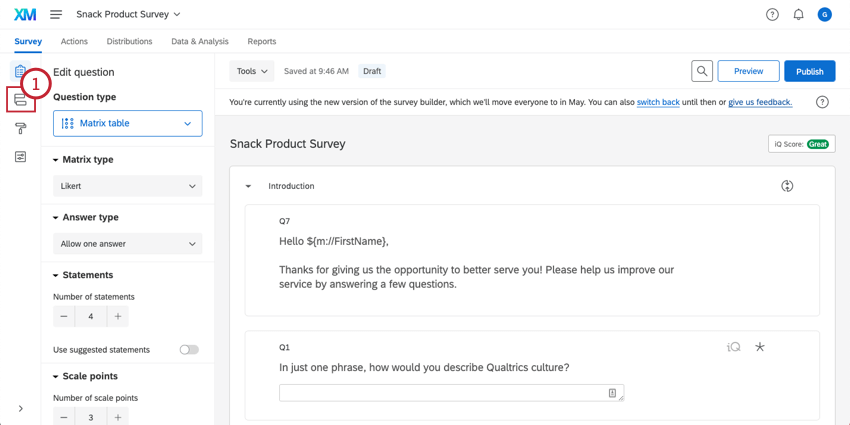
Registrazione dei dati
Una volta che si dispone di una variabile di abbandono, è possibile importare i dati storici nel sondaggio, compresa una colonna per l’abbandono in cui si indica con Sì o No se il cliente ha abbandonato.
Creazione di un modello di previsione di abbandono
Una volta impostata la variabile churn e una volta che si dispone di dati sufficienti, si è pronti ad aprire Predict iq.
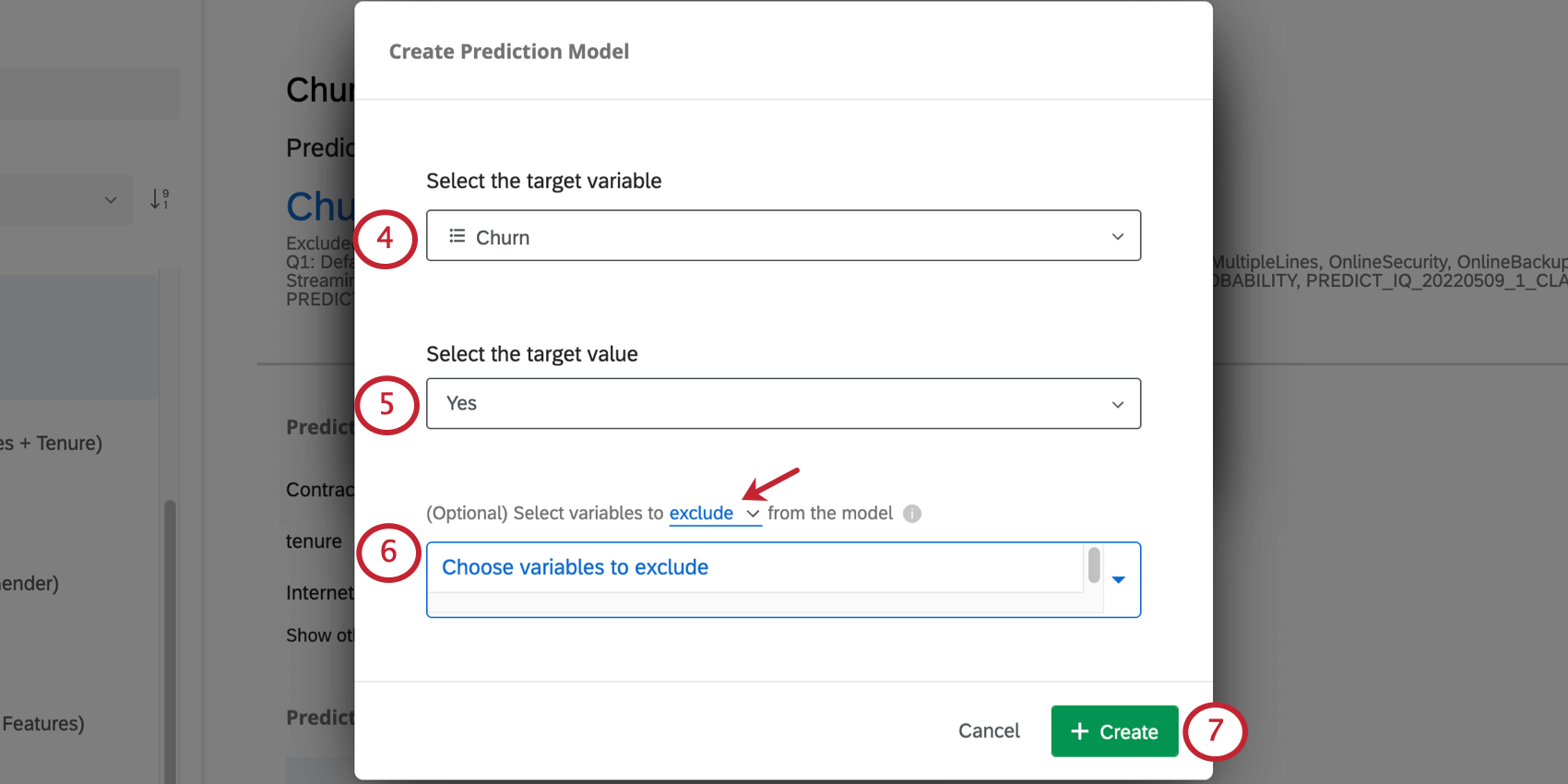
Consiglio Q: Predict iQ prevede solo risultati che hanno 2 scelte possibili, come Sì/No o Vero/Falso. Non prevede risultati numerici (ad esempio, una scala da 1 a 7) o categorici con più di due valori (ad esempio, Sì/Mai/No).
Esempio: Poiché in questo esempio la nostra variabile è denominata Churn, chi ha Churn uguale a Yes ha effettuato un churn. Ma supponiamo che la vostra variabile si chiami invece Rimanere con la nostra azienda. Allora il No indicherebbe che la persona non è rimasta in azienda e ha cambiato lavoro.
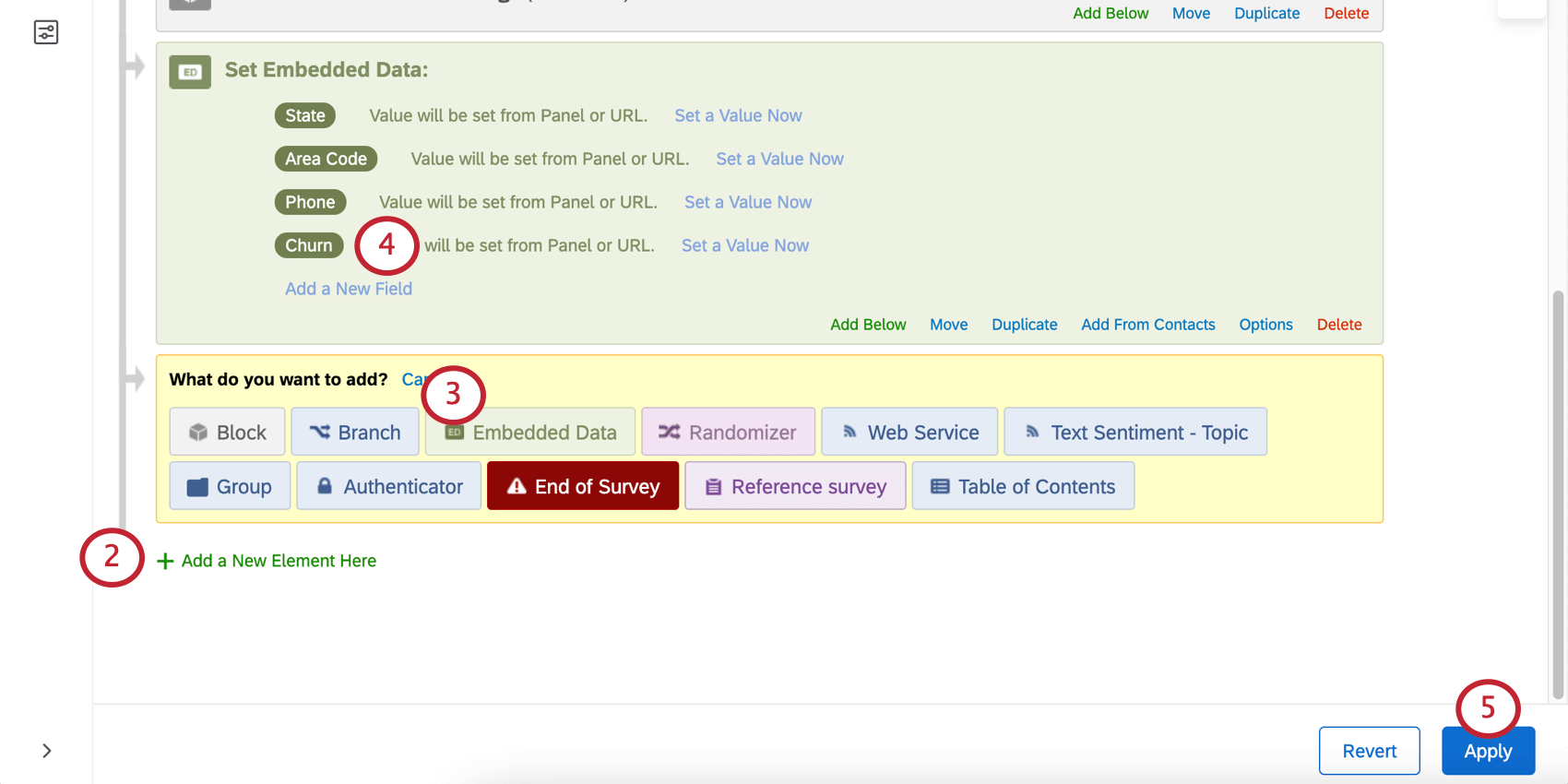
- Escludere: Ad esempio, se nei dati storici è presente una variabile che misura il “Motivo dell’abbandono”, è possibile escluderla dall’analisi, poiché non sarà disponibile per i nuovi intervistati al momento della previsione. Consiglio Q: è possibile escludere più variabili. Fare clic sulla X avanti a una variabile per rimuoverla dalla lista delle variabili escluse.


- Includi: Selezionare le variabili da includere nel modello; tutte le altre saranno ignorate.

Consiglio Q: il modello predittivo del churn potrebbe richiedere del tempo per terminare i calcoli. È possibile allontanarsi dalla pagina per lavorare su altri progetti o siti web senza perdere i progressi.
Una volta completato il modello di previsione, la pagina Predict iQ sarà sostituita da informazioni sul modello di previsione degli abbandoni appena creato.
{kind=link}

Come viene suddiviso il dataset per la formazione del modello?
Nel processo di formazione del modello, il dataset viene suddiviso in dati di formazione, convalida e test. l ‘80% dei dati viene utilizzato per la formazione. il 10% dei dati viene utilizzato per la convalida e il 10% per il test.
Informazioni variabili
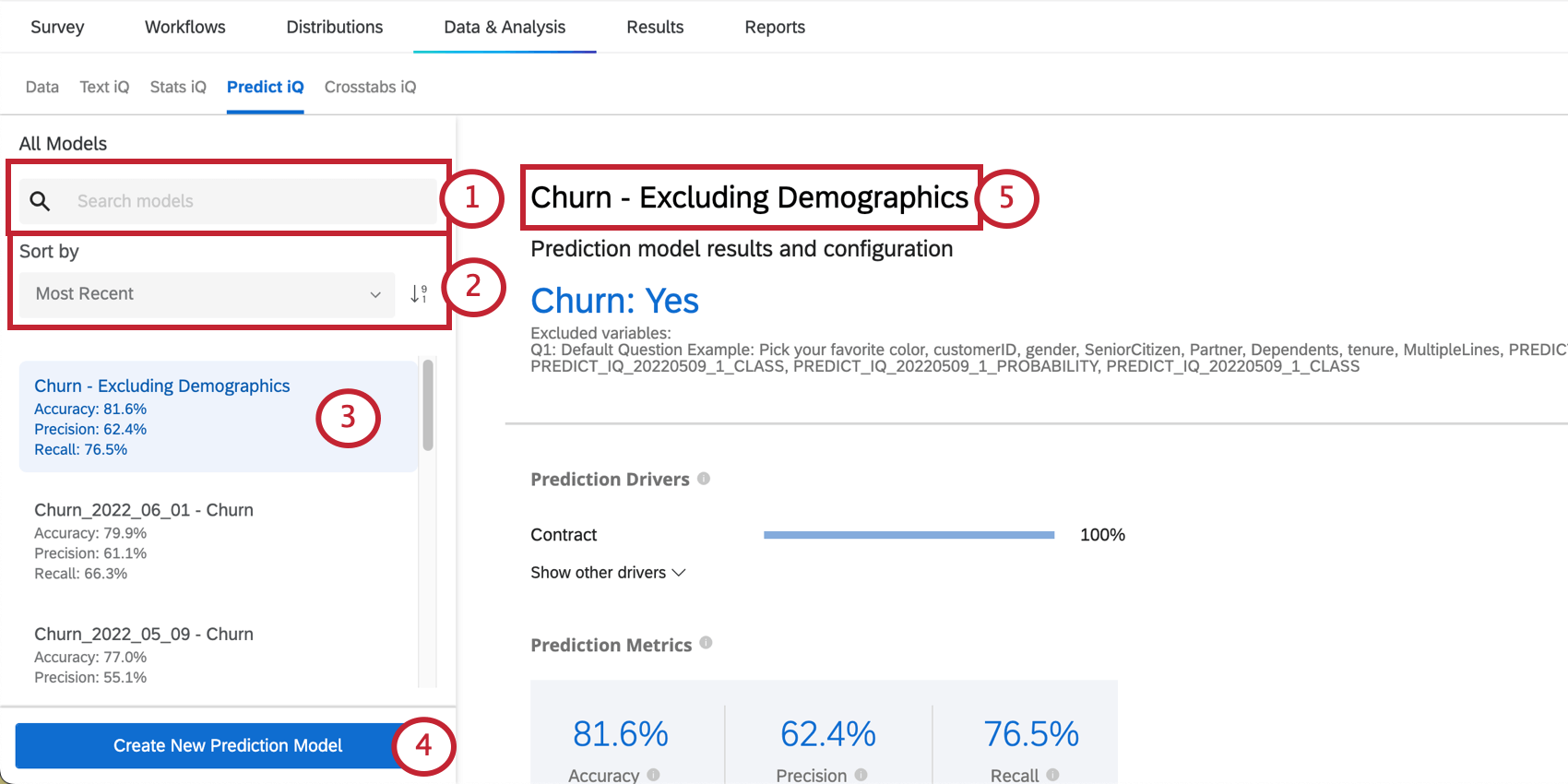
La sezione Risultati e configurazione del modello di previsione fornisce il nome della variabile dati INTEGRATI e il valore che indica la probabilità di abbandono di un cliente. In questa sezione sono elencate anche le variabili escluse.
{kind=link}

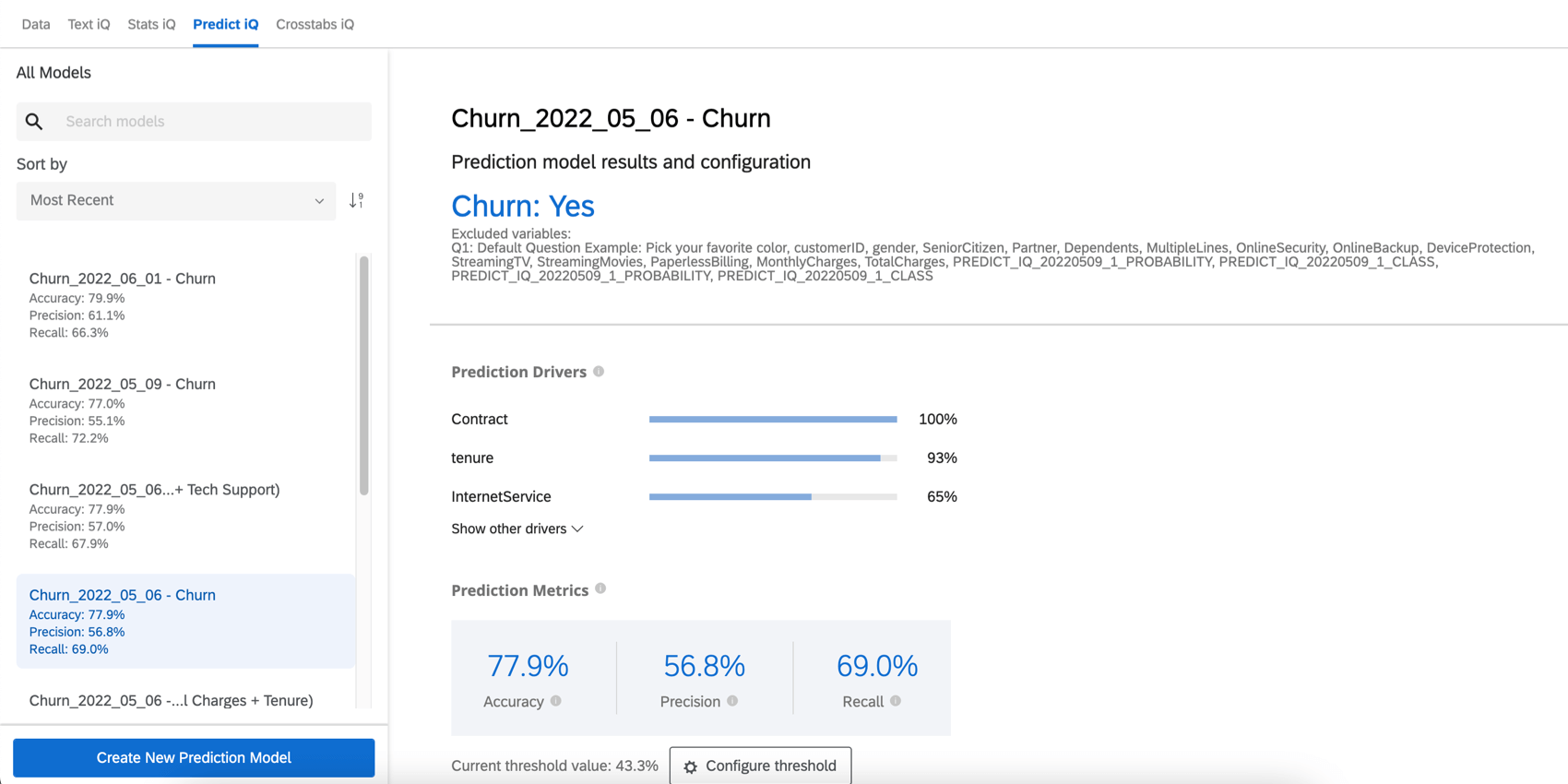
Fattori di previsione
I driver di previsione sono le variabili che sono state analizzate per creare il modello di previsione, ordinate in base alla loro importanza nel predire gli abbandoni. Questo include qualsiasi variabile che non sia stata esclusa dall’analisi. Nell’esempio seguente, i punteggi NPS e le valutazioni di affidabilità guidano la previsione di abbandono.
{kind=link}

Fare clic su Mostra altri driver per espandere la lista.
Consiglio Q: per creare questo grafico, ogni variabile viene eseguita in una regressione logistica semplice rispetto alla variabile churn. Il valore r-squared più alto viene impostato a 1 e i valori delle altre variabili vengono scalati di conseguenza. Ad esempio, se l’r-quadro più alto è 0,5, la lunghezza della barra di ciascuna variabile sarà r-quadro * 2, dove la lunghezza della barra è 1.
Il grafico è quindi un indicatore della forza relativa delle variabili nel predire il churn e non è di natura multivariata. La valutazione dell’impatto di ciascuna variabile sui risultati di un modello basato su un algoritmo di deep learning è un’area di ricerca accademica attiva, che non prevede al momento alcuna pratica migliore accettata.
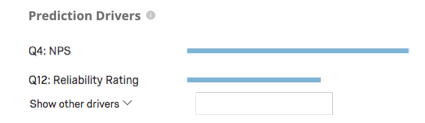
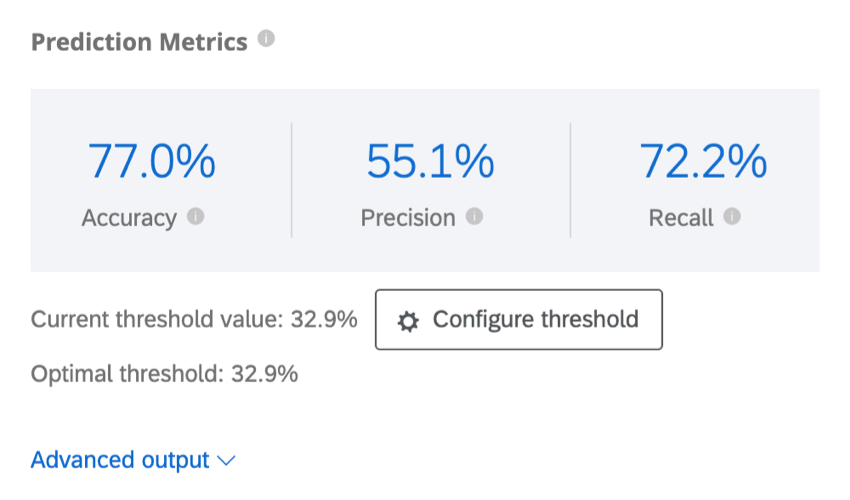
Metriche di previsione
Predict iQ “trattiene” (mette da parte) il 10% dei dati prima di creare il modello. Una volta creato il modello, esso crea previsioni per quel 10%. Quindi confronta le sue previsioni con ciò che è effettivamente accaduto, ovvero se quei clienti hanno effettivamente abbandonato. Questi risultati vengono utilizzati per elaborare le metriche di precisione riportate di seguito. Si noti che, pur essendo un metodo efficace di best practice per stimare l’accuratezza del modello, non è una garanzia dell’accuratezza futura del modello.
{kind=link}
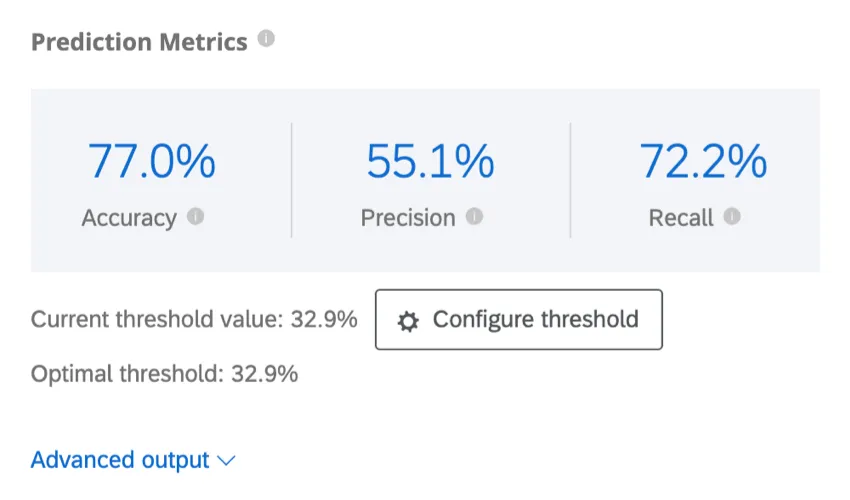
- Accuratezza: La percentuale delle previsioni del modello che saranno accurate.
- Precisione: La percentuale di clienti di cui si prevede l’abbandono che effettivamente lo faranno.
- Richiamo: La percentuale di coloro che hanno effettivamente effettuato il churning che il modello aveva previsto in anticipo.
Esempio: In questa schermata, le previsioni del modello saranno accurate nell’88,9% dei casi. È abbastanza preciso che l’82,4% dei clienti di cui si prevede l’abbandono lo farà. La metrica di richiamo indica che il modello identificherà correttamente circa il 29,8% dei clienti che effettivamente effettueranno il churning.
Predict iQ calcolerà il valore di soglia ottimale massimizzando il punteggio F1. Per impostazione predefinita, il modello sarà impostato sulla soglia ottimale, ma è possibile modificarla; vedere Configurazione della soglia di seguito.
Fare clic su Output avanzato sotto la tabella Metriche predittive per visualizzare le tabelle Matrice di confusione e Metriche predittive avanzate.
Precisione e richiamo
Precisione e richiamo sono le metriche di previsione più importanti. Le due relazioni sono inverse e quindi spesso si deve pensare a un compromesso tra il sapere esattamente quali clienti si cancelleranno e il sapere di aver identificato tutti o la maggior parte dei clienti che probabilmente si cancelleranno.
Esempio: Immaginate di seguire ogni singolo cliente. Raggiungereste sicuramente tutti coloro che si ritirano (100% di richiamo), ma sprechereste molte risorse e tempo con clienti che non hanno mai pensato di abbandonare (bassa precisione). D’altra parte, se si effettua il follow-up solo con il singolo individuo che ha la maggiore probabilità di cambiare, si avrà probabilmente una precisione del 100%, ma si perderanno molti clienti che alla fine cambieranno (richiamo molto basso).
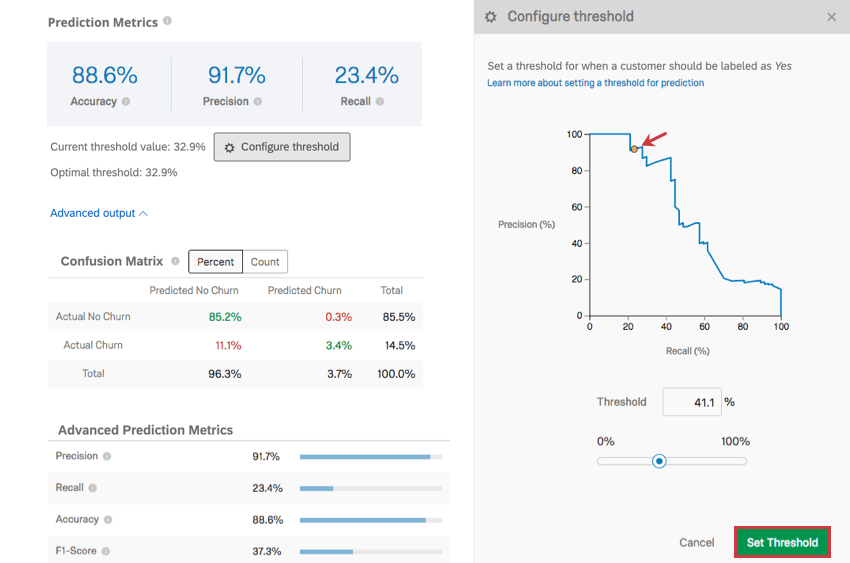
Configurare la soglia
Fare clic su Configura soglia per impostare una soglia per il momento in cui un cliente deve essere etichettato come suscettibile di abbandono. Questa percentuale di soglia rappresenta la probabilità individuale di abbandono.
Esempio: Il modello produce una stima della probabilità di abbandono di 1 cliente qualsiasi. Immaginiamo che ci siano 3 clienti, con probabilità di abbandono del 10%, 40% e 75%. Se la soglia è fissata al 30%, sia i clienti del 40% che quelli del 75% sono contrassegnati come probabili acquirenti e riceveranno quindi un’e-mail o una telefonata. Se la soglia è fissata al 50%, però, solo il cliente al 75% viene contrassegnato come probabile cliente che si ritira.
{kind=link}

Fare clic e trascinare il punto sul grafico per regolare la soglia, oppure digitare una soglia % e osservare come cambia il grafico. Al termine, fare clic su Imposta soglia per salvare le modifiche. È inoltre possibile annullare le modifiche facendo clic su Annulla in basso a destra o sulla X in alto a destra.
La regolazione della soglia regola la precisione lungo l’asse delle ordinate e il richiamo lungo l’asse delle ascisse. Queste metriche hanno una relazione inversa. Quanto più precise sono le misure, tanto più basso è il richiamo, e viceversa.
CONSIGLIO Q: La regolazione della soglia modifica il modo in cui vengono raccolti i dati futuri quando si è selezionato Crea una previsione ogni volta che un nuovo rispondente completa questo sondaggio nella sezione Previsioni del flusso in fondo alla pagina Predict iq. Per sovrascrivere i dati relativi alla curva di crescita del modello precedente, è necessario eliminare la variabile della curva e aggiungerne una nuova. Le soglie non influiscono sulla variabile Probabilità di abbandono, ma solo sulla variabile binaria Sì/No.
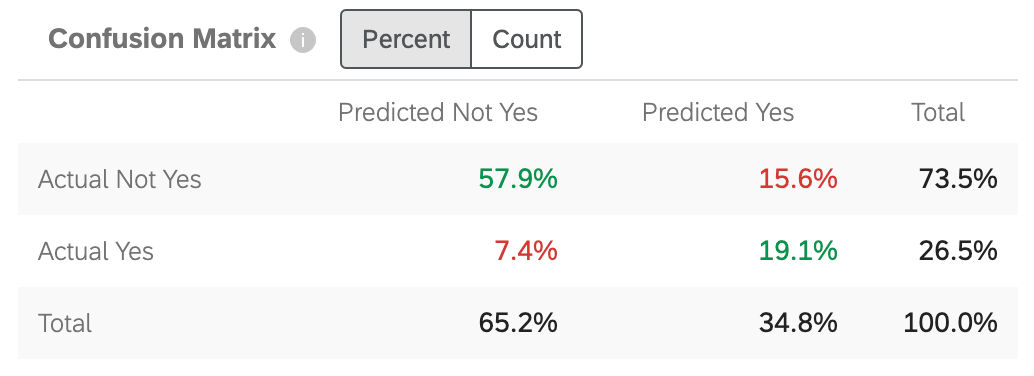
Matrice di confusione
Quando Predict iQ costruisce un modello di previsione, “trattiene” (o mette da parte) il 10% dei dati. Per verificare l’accuratezza del modello generato, i dati del nuovo modello vengono confrontati con il 10% di holdout. Questo serve come confronto tra ciò che è stato previsto e ciò che è “realmente accaduto”
{kind=link}

“Sì” in questo grafico sarà sostituito dal valore di destinazione indicato al punto 5 dell’impostazione.
- Non Sì effettivo / Non Sì previsto: la percentuale di clienti che il modello prevedeva non avrebbero abbandonato e che in realtà non hanno abbandonato.
- Sì effettivo / Non sì previsto: la percentuale di clienti che il modello prevedeva non avrebbero abbandonato e che invece hanno abbandonato.
- Non Sì / Previsto Sì: la percentuale di clienti che il modello prevedeva di abbandonare e che invece non l’hanno fatto.
- Sì effettivo / Sì previsto: la percentuale di clienti che il modello prevedeva di abbandonare e che invece hanno effettivamente abbandonato.
I numeri sono verdi per indicare che si desidera che questi numeri siano il più alti possibile, in quanto riflettono le ipotesi corrette. I numeri sono rossi per indicare che si desidera che questi numeri siano bassi, in quanto riflettono le ipotesi errate.
È possibile regolare la matrice in modo da visualizzare la percentuale o il conteggio. Questo conteggio include il 10% dei dati che avete conservato, non l’intero set di dati.
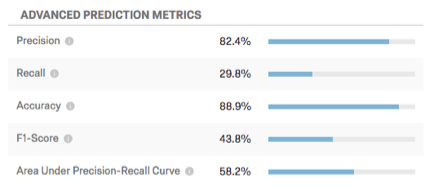
Metriche di previsione avanzate
Questa tabella mostra ulteriori metriche di previsione.
{kind=link}

- Precisione: La percentuale di clienti di cui si prevede l’abbandono che effettivamente lo faranno.
- Richiamo: La percentuale di coloro che hanno effettivamente effettuato il churning che il modello aveva previsto in anticipo.
- Accuratezza: La percentuale delle previsioni del modello che saranno accurate.
- Punteggio F1: Il punteggio F1 viene utilizzato per selezionare una soglia che bilanci la precisione e il richiamo. Un punteggio F1 più alto è generalmente migliore, anche se il punto giusto in cui fissare la soglia deve essere determinato dagli obiettivi aziendali.
- Area sotto la curva di precisione-richiamo: La curva precisione-richiamo è la curva che si osserva sul grafico quando si fa clic su Configura soglia. L’area totale sotto la curva è una misura dell’accuratezza complessiva del modello (indipendentemente dall’impostazione della soglia). Un’area sotto la curva del 50% è pari alla casualità; il 100% è perfettamente accurato.
Effettua previsioni
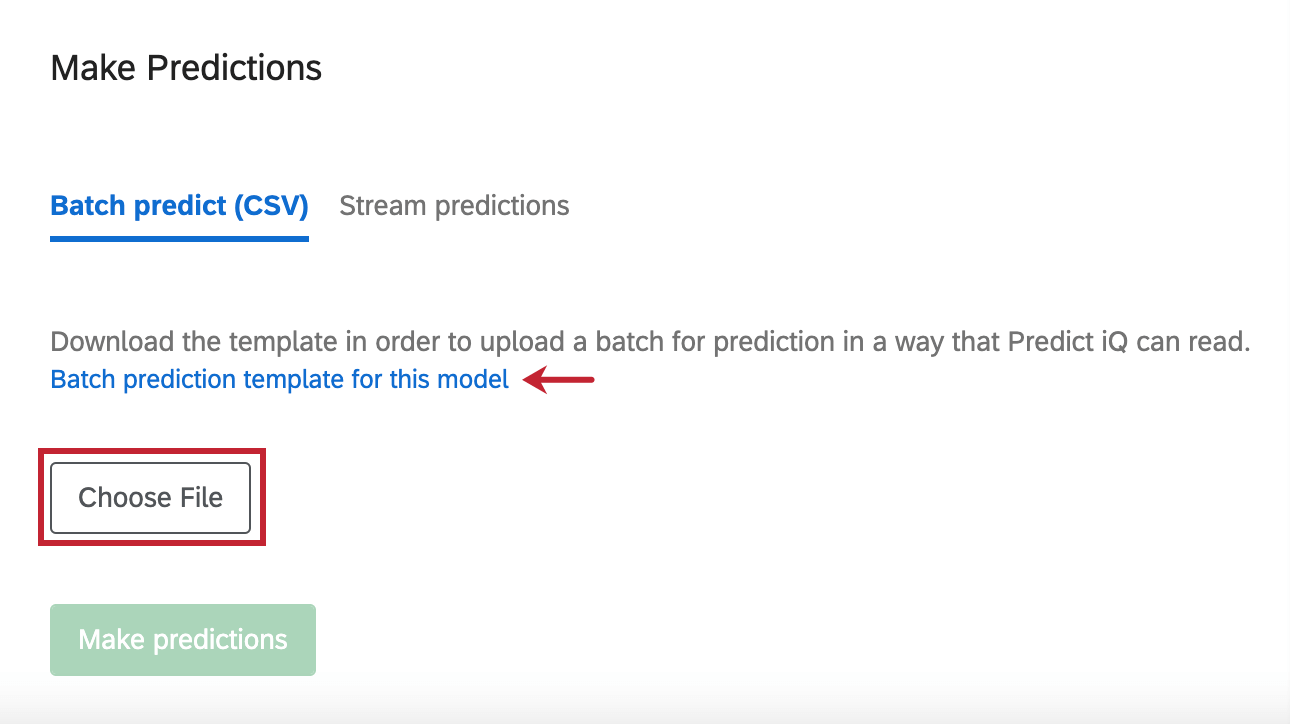
Previsione batch (CSV)
Oltre ad analizzare le risposte raccolte nel sondaggio, è possibile caricare un file di dati specifico che Predict iQ deve valutare.
{kind=link}

Per ottenere un modello del file, fare clic su Modello di predizione batch per questo modello.
Quando si è terminato di modificare il file in Excel e si è pronti a ricaricarlo, fare clic su Scegli file per selezionare il file. Quindi fare clic su Effettua previsioni per avviare l’analisi.
Consiglio Q: Avete problemi con il file del modello? Vedere la pagina Problemi di caricamento CSV/TSV.
Previsioni sul flusso
Le previsioni delle correnti si aggiornano man mano che i dati arrivano al sondaggio. In questa sezione, è possibile decidere quando effettuare gli aggiornamenti delle previsioni.
{kind=link}
Crea una previsione ogni volta che un nuovo rispondente completa il sondaggio: Questa impostazione abilita le previsioni in tempo reale. Nei dati sono presenti altre due colonne: Churn Probability, la probabilità di abbandono in formato decimale; e Churn Prediction, una variabile Sì/No. La previsione di abbandono si basa sulla soglia configurata.
Consiglio Q: se i dati includono dati integrati estratti da un’origine del sondaggio diversa, i dati potrebbero non arrivare in Qualtrics subito dopo il completamento del sondaggio. Se i dati sono importanti per le previsioni, si consiglia di aspettare che vengano caricati per poterli includere.
Manager dei modelli
Sulla sinistra della pagina è presente un menu in cui è possibile scorrere e selezionare i modelli di previsione creati in passato.
{kind=link}

Dati di abbandono
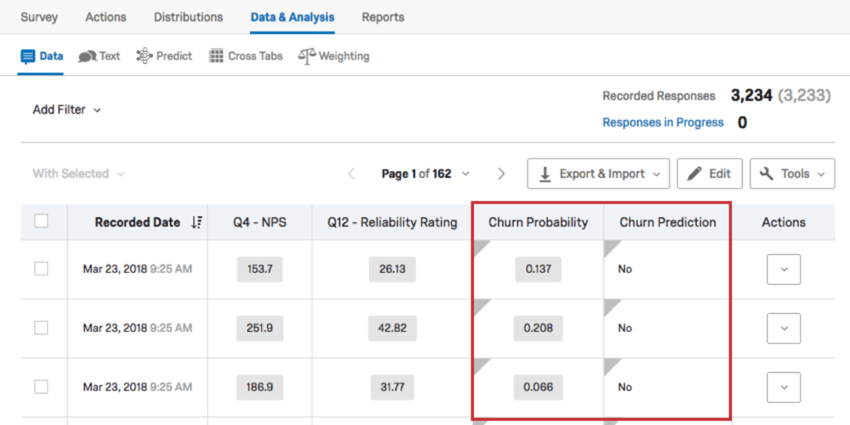
Nella sezione Dati della scheda Dati e analisi è possibile esportare i dati in un comodo foglio di calcolo. Dopo che il modello di previsione è stato caricato, in questa pagina sono presenti altre colonne per i dati relativi al churn.
{kind=link}
- Probabilità di abbandono: Probabilità di abbandono in formato decimale. Appare quando è stata attivata la predizione del flusso e si basa sulla soglia impostata. Se non si vede la colonna Churn Probability, si può anche cercare una colonna dati denominata “[campo churn selezionato]_PROBABILITY_PREDICT_IQ”.
- Previsione di abbandono: Una variabile Sì/No che conferma o nega l’abbandono in base alla soglia impostata. Appare quando è stata attivata la predizione del flusso. Se non si vede la colonna Churn Prediction, si può anche cercare una colonna dati denominata “[campo churn selezionato]_CLASS_PREDICT_IQ”.
Esempio: Se il campo churn selezionato durante la creazione del modello di previsione churn si chiama “CustomerChurnFlag”, le colonne dei dati churn possono avere l’aspetto di CustomerChurnFlag_CLASS_PREDICT_IQ e CustomerChurnFlag_PROBABILITY_PREDICT_IQ.
I nomi delle colonne includeranno anche la data di formazione del modello nel formato MMDDYYY. Ad esempio, il 14 gennaio 2022 sarà rappresentato nel nome della colonna come 01142022.
Si noti che le probabilità di abbandono e le previsioni si applicano solo ai risultati dei nuovi sondaggi. Alle risposte esistenti in precedenza non verranno aggiunte le probabilità di abbandono e le predizioni.
Consiglio Q: Una volta create queste variabili, possono essere analizzate con Rapporti sui risultati o Rapporti avanzati, come qualsiasi altra variabile.
Pulizia automatica dei dati
Durante la formazione del modello, Predict iQ ignorerà automaticamente alcuni tipi di variabili che non saranno utili per le previsioni, mentre trasformerà automaticamente altre variabili.
Variabili ad alta cardinalità
Se una variabile ha più di 50 valori unici o più del 20% dei valori registrati sono unici, verrà ignorata durante la formazione del modello. Le variabili con un numero eccessivo di valori unici non sono buone funzioni per le previsioni.
Esempio: Ad esempio, se si dispone di una variabile Contea – USA, questa variabile verrebbe ignorata durante la formazione del modello perché negli Stati Uniti ci sono più di 3000 contee in tutti i 50 stati.
Esempio: Come altro esempio, si consideri una variabile come Gusto di gelato preferito e si supponga di avere 100 righe di dati per questa variabile. Tra queste 100 righe, si scopre che ci sono 21 valori unici per il gusto del gelato. Questa variabile viene ignorata durante la formazione del modello perché più del 20% dei suoi valori registrati sono unici.
Valori mancanti per colonne numeriche
Per le variabili numeriche incluse nel modello, i valori mancanti sono sempre imputati a 0 (zero).
Codifica one-hot delle categorie
Le variabili categoriali saranno codificate a un punto se la variabile non è ricodificata o se la variabile non ha una relazione ordinale per le sue categorie.
Consiglio Q: Predict iQ riporta le stesse impostazioni delle variabili utilizzate in Stats iQ.
Variabili invarianti
Le variabili che non presentano varianza nei valori registrati saranno ignorate per la formazione del modello. Ciò significa che se una variabile ha un solo valore univoco, non farà parte del modello. Le variabili utili per la previsione troveranno un buon equilibrio tra avere pochi valori unici e troppi valori unici. Vedere “Variabili ad alta cardinalità” sopra.
Se durante la pulizia dei dati vengono escluse delle variabili invarianti, queste vengono elencate nella sezione Risultati e configurazione del modello di previsione.
Progetti in cui è possibile utilizzare Predict iQ
Predict iQ non è incluso in ogni licenza. Tuttavia, se si dispone di questa funzione, è possibile accedervi in diversi tipi di progetti:
Predict iQ può comparire anche nei progetti Engage e Lifecycle, ma in base alla natura dei dati solitamente raccolti da questi tipi di progetti, il set di dati non sarebbe necessariamente il migliore per Predict iQ.
Predict iQ è presente in Conjoint e MaxDiff, ma non è consigliabile utilizzarli insieme. I contenuti specifici di Conjoint e MaxDiff non sono compatibili con Predict iq, pertanto è possibile analizzare solo i dati demografici.
Non sono supportati altri tipi di progetti.
Consiglio Q: I progetti elencati in questa sezione non sono disponibili in tutte le licenze.
FAQs
Non ho la scheda descritta in questa pagina! Che faccio?
Non ho la scheda descritta in questa pagina! Che faccio?
È fantastico! Grazie per il tuo feedback!
Grazie per il tuo feedback!