ブランドトラッカーデータソースの使用と編集
このページの内容
ブランドトラッカーデータソースの使用と編集について
BXプログラムでは、競合ブランドや市場全体に加えて、あなたのブランドに関するデータも収集するため、データセットは標準的なプロジェクトよりも複雑になります。BXプログラムでは、スタックデータセット(ブランドトラッカーデータソース、BTDS)を使用して、データのインサイトをより簡単に特定します。
BX データソースを理解する
注意: ブランド トラッカー データ ソースは、BX プログラムのインポートされたデータ プロジェクトとして作成されます。
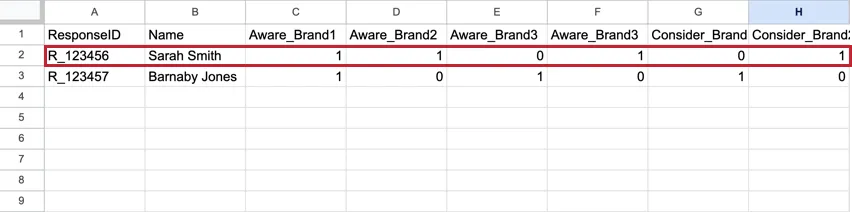
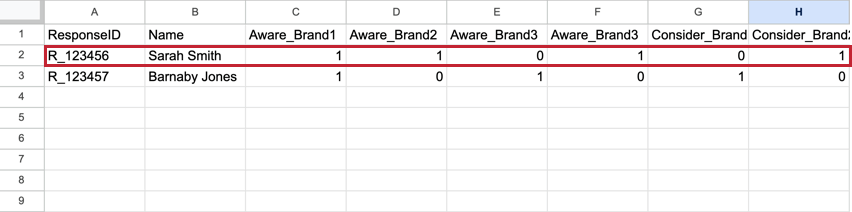
BTDSは標準的なデータセットとは異なる。標準的なデータセットでは、各回答者は、各ブランドの指標をそれぞれの列として、回答に対するすべての回答を含む1行を持ちます。これらのデータセットは、数百の列を持つ非常に広いデータセットになる傾向がある。
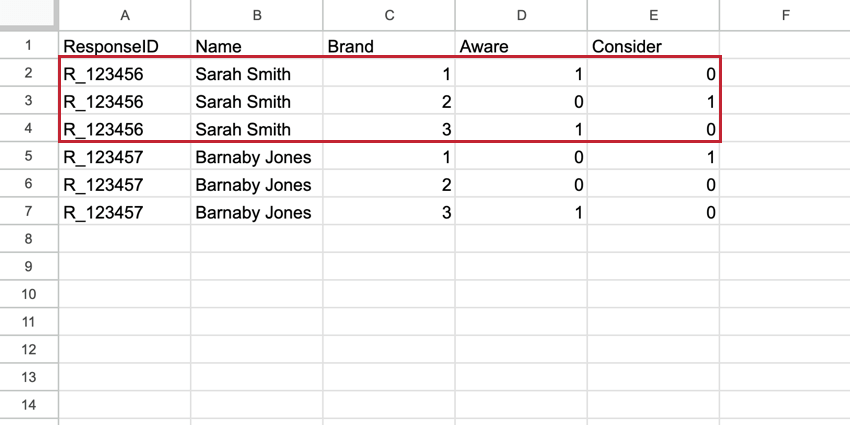
例: このフラットなデータセットには、サラ・スミスのデータが1行、バーナビー・ジョーンズのデータが1行ある。各ブランドの指標は、別々の列で表示される。
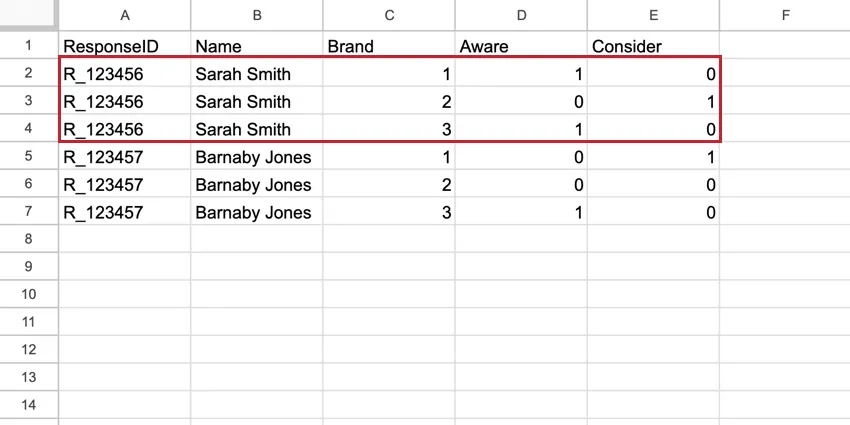
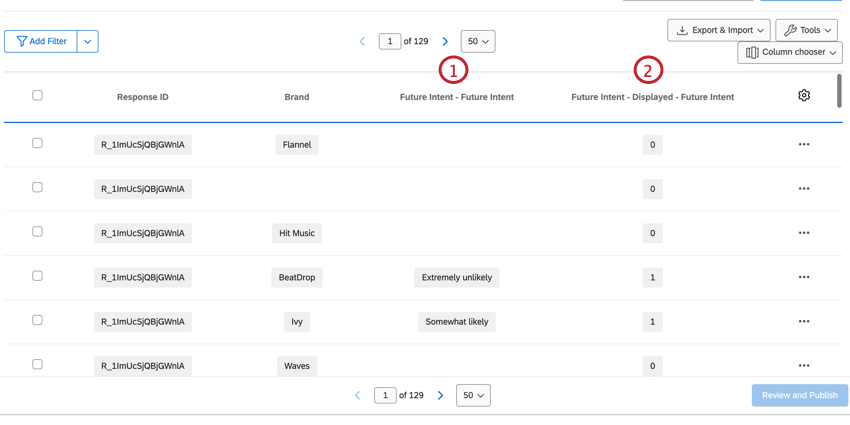
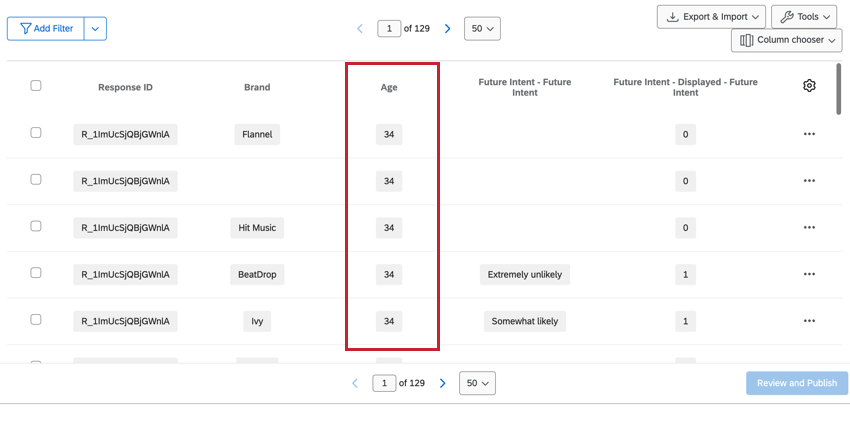
BTDSでは、ブランドはデータセットの第一列となり、すべての回答者が各ブランドの行を持つ。ブランドの行には、その単一ブランドのすべてのデータが含まれる。これらのデータセットは、標準的なデータセットよりも行数は多いが、列数はかなり少ないので、読みやすくなっている。
例: このスタックデータセットでは、Sarah Smithのデータが5行あり、1つの回答しか表していない。各行には、測定された各ブランドについてのサラのデータが含まれている。
Qtip: 積み重ねられたデータセットにはブランドごとに異なる行があるため、BTDS データ & 分析 タブの 記録された回答 数は、ユニーク回答者の総回答数よりも多くなります。固有の回答者の総数を調べるには、Singular = 1 のフィルタを作成します。
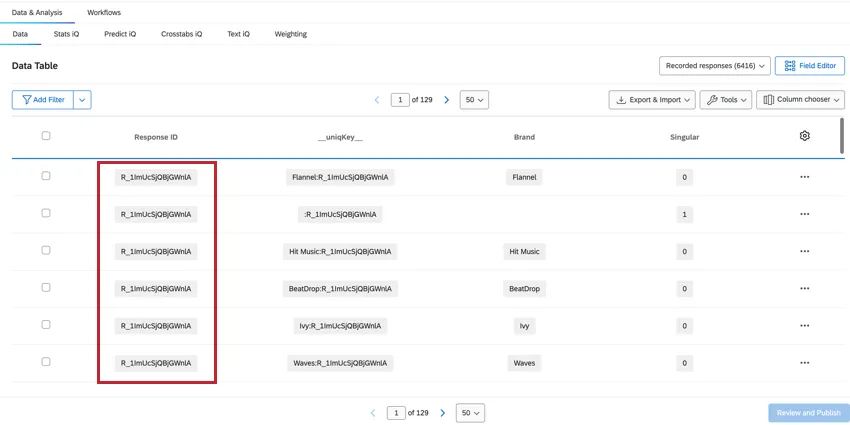
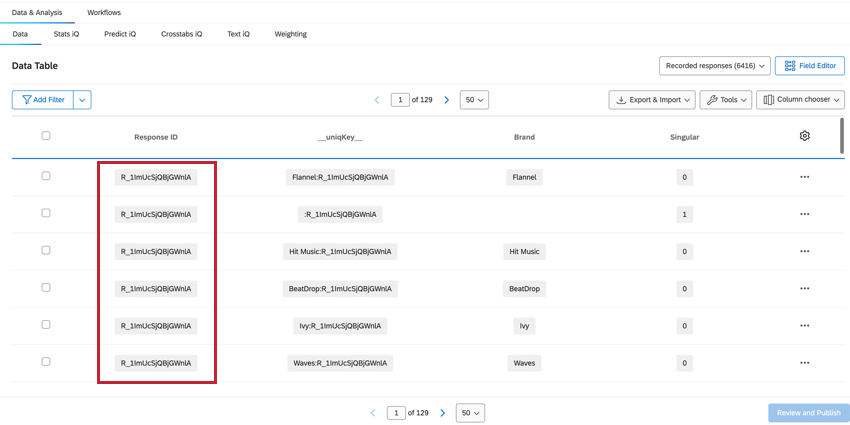
RESPONSEID
ResponseIDフィールドは、どの行が同じ回答者に帰属するかを識別するのに役立ちます。この値は最初のアンケート調査のもので、その回答者に帰属するすべての行で繰り返されます。
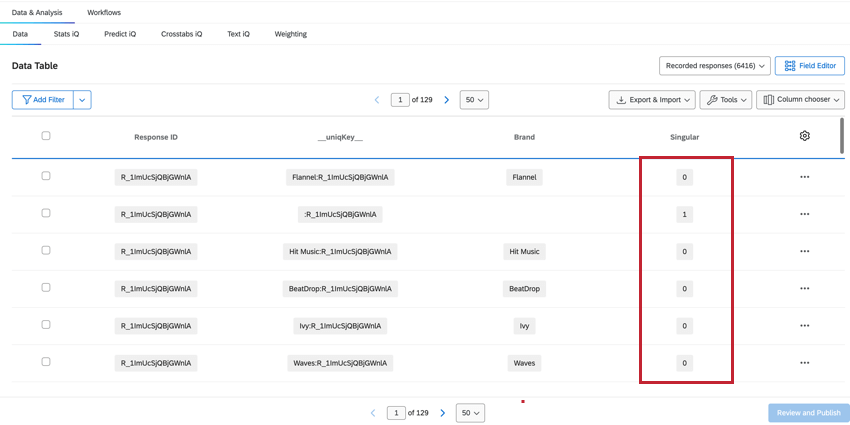
シングル
データと分析] タブの記録された回答の数には、すべての行の総回答数が表示され、固有の回答者の総数よりも多くなります。固有の回答者を決定するには、Singular フィールドをフィルタします。
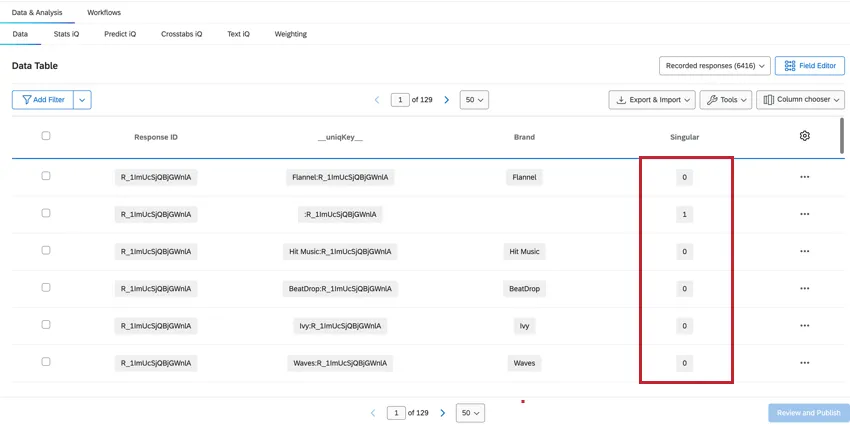
- Singular = 1 の場合、ブランド情報のないユニークな回答者の行が表示されます。回答ごとに一意の回答者行があります。 Qtip: Singular = 1 のフィルタを作成すると、個々の回答者の数が表示されます。

- Singular = 0の場合、その行はブランドデータを含む。各回答者のブランドデータは複数行あります。
注意: ダッシュボードのデータ目標に応じて、Singular = 1とSingular = 0のどちらをフィルターにかけるかをよく検討する必要があります。ほとんどの場合、Singular = 0でフィルタリングし、ブランド以外の余分な行を基本サイズから除外し、データの不正確さを防ぎます。または、回答者レベルのデータの真のカウントを表示する必要がある場合は、Singular = 1 でフィルタします。
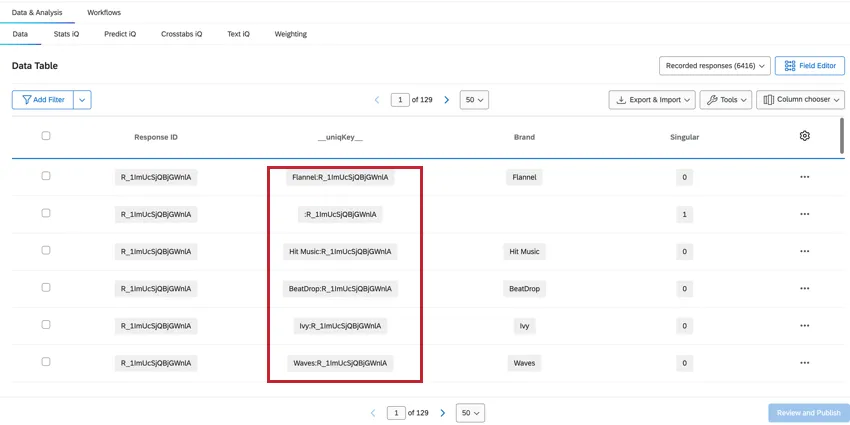
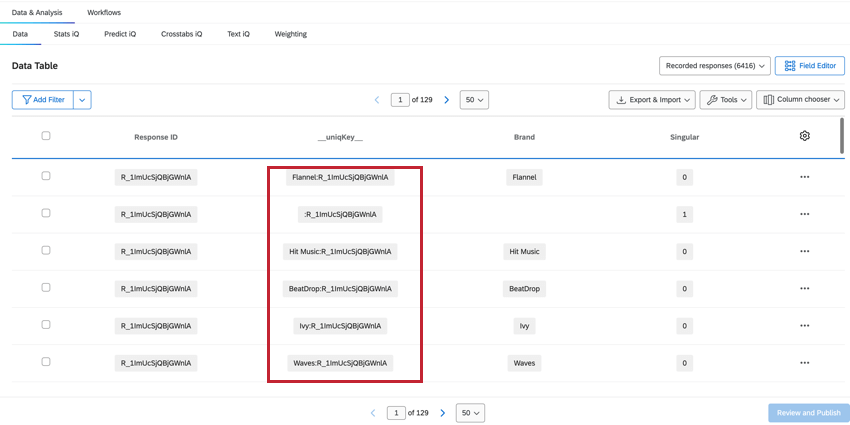
ユニックキー
uniqKey__ フィールドは、ResponseID とブランド名を組み合わせたもので、BrandName:ResponseID と表示されます。ブランド情報のないユニークな回答者の行 (Singular = 1 の行) では、__uniqKey__ は:Responseid となります。これは、このデータが正確な回答であるか、また具体的にフィードバックしたブランドを絞り込むのに便利です。
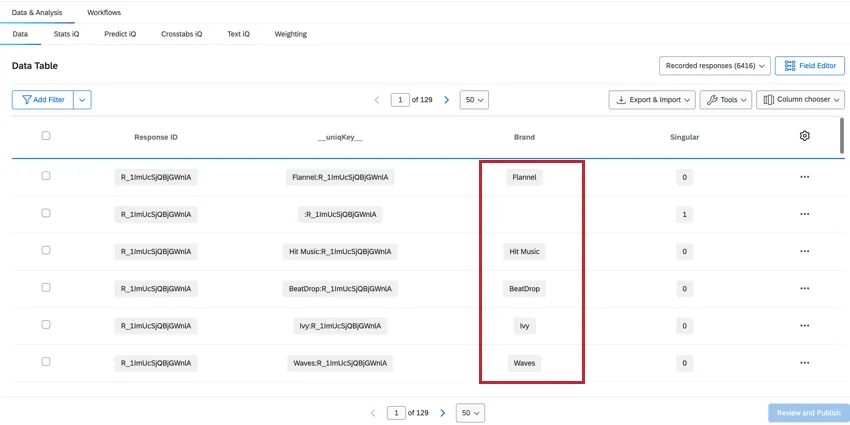
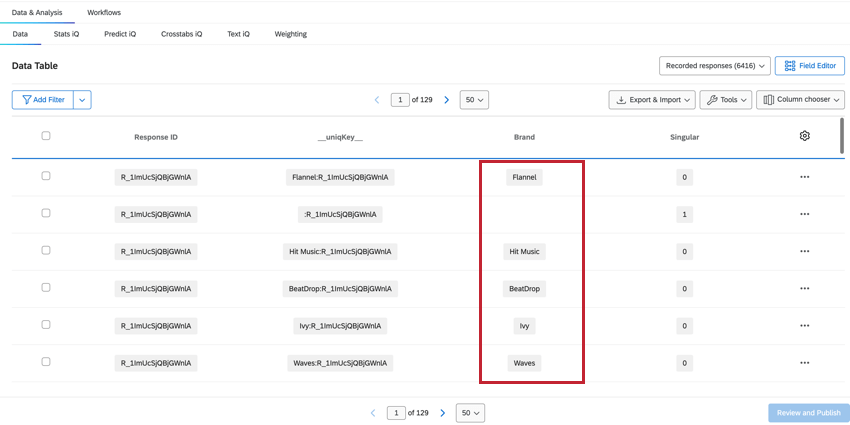
ブランド
ブランドフィールドには、その列のデータがどのブランドを参照しているかが表示され、ブランドデータの確認やフィルターが簡単にできます。
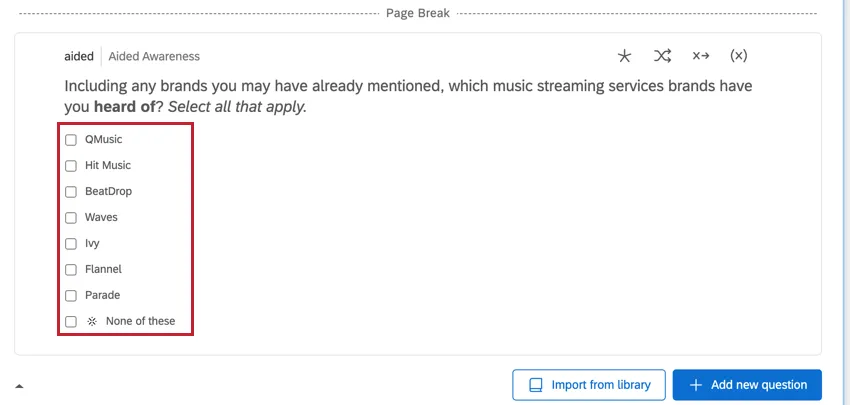
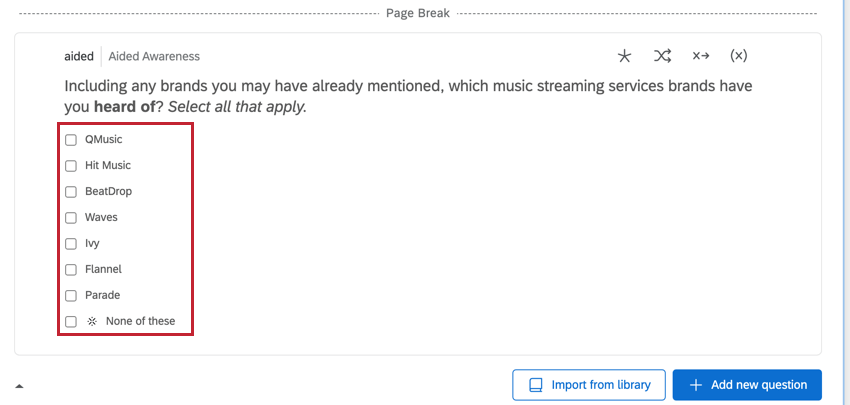
属性選択データ
属性主導の質問には、回答の選択肢としてブランドが含まれます。これらは通常、複数選択可能な質問タイプで、その質問に対応するデータを持つ複数の列があります。
例: これらの問題タイプの一般的な例は、「助成想起」問題です。
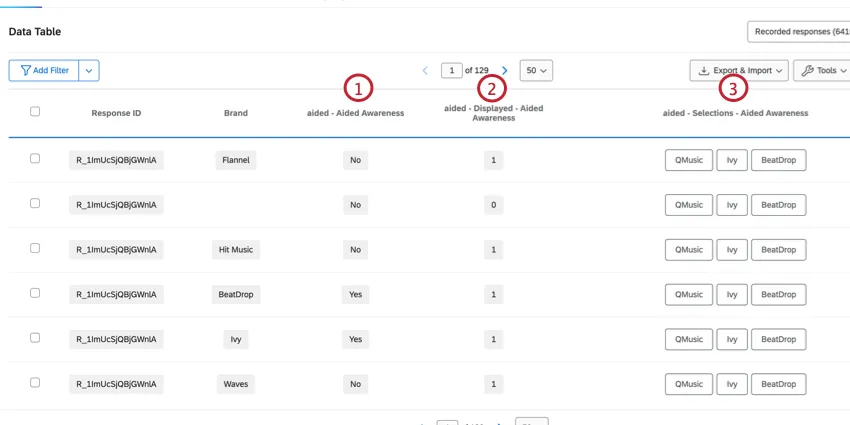
質問データのループと結合
また、ループと結合を使ってブランド名をパイプで入力する質問には複数の列がある。
例: この質問タイプの例として、「将来の意図」の質問があります。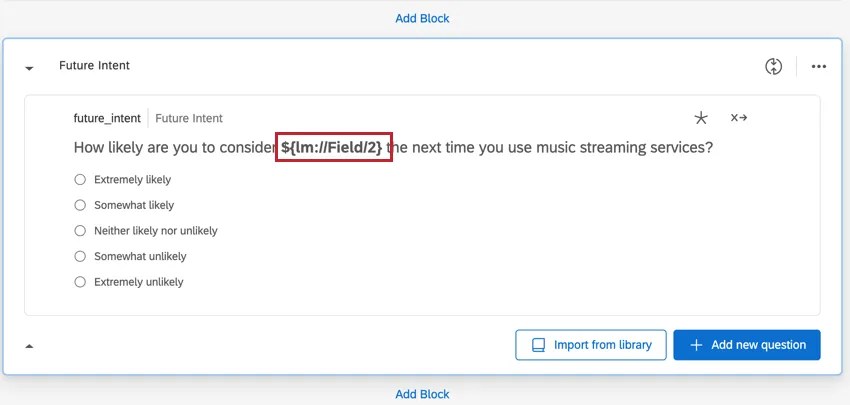
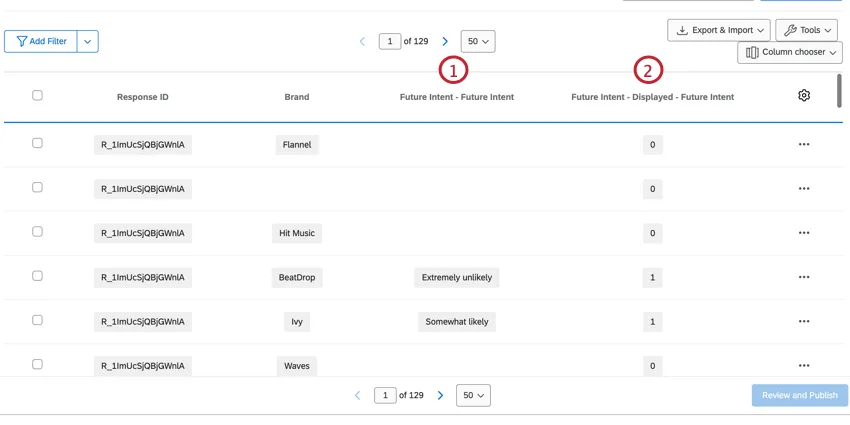
非スタックデータ
非積層データは、標準的な質問(人口統計など)や非積層埋め込みデータフィールドなど、ブランドに関連しないデータである。これらのフィールドはブランドごとに繰り返されるため、特定のブランドを見ている場合でも、すべてのブランドを見ている場合でも、データを利用することができます。
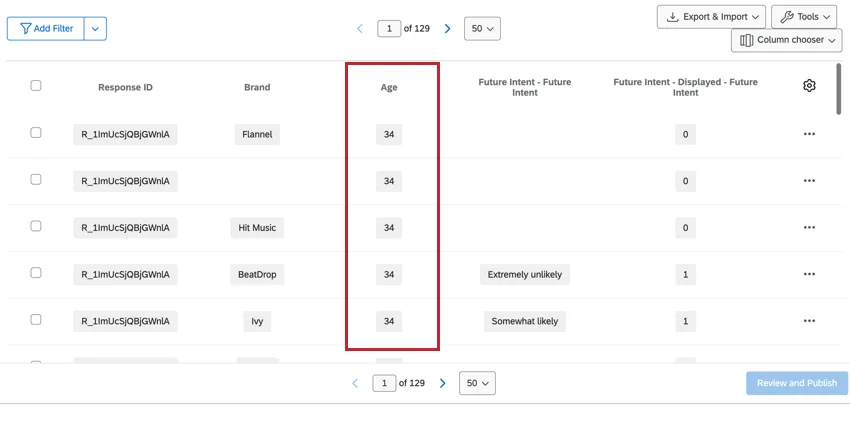
Qtip: ブランド以外のデータを使用した複数選択の質問には、同じ列で選択された選択肢のリストが含まれます。回答者が選択肢を見たかどうかの情報は保存されません。
BTDSの生成
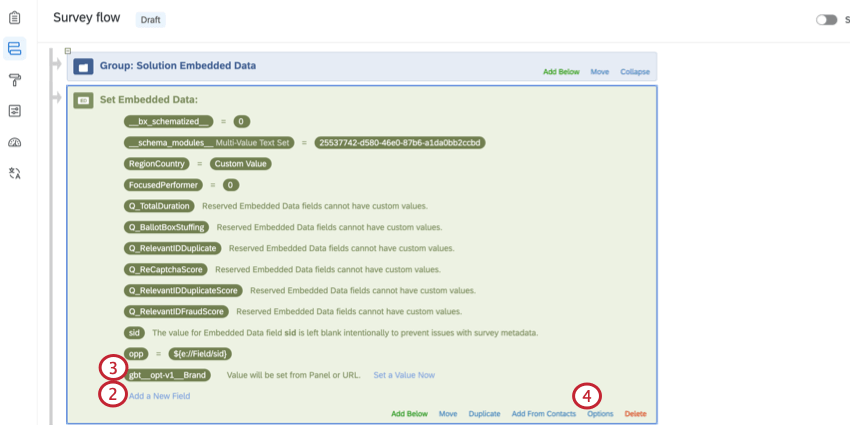
BX プログラムをゼロから作成する場合、ブランド トラッカー データソースは自動生成されないため、データ収集の前に生成する必要があります。BTDSが生成される前に収集されたデータはスタックされない。
Qtip: アンケートが完全にプログラムされ、テストされた後にBTDS を作成することをお勧めします。Itを早く生成すると、余分な材料や列でデータセットが複雑になってしまう可能性がある。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
スタックデータセット互換性
積み重ねられたデータセットには、データ処理に最適なフィールドタイプや質問タイプに制限がある。BX プログラムを作成する際には、アンケート調査が生成される BTDS と互換性があることを確認することが重要です。
BTDSは以下の質問タイプに対応しています:
- 多肢選択式(単一および多肢選択式)
- 自由回答、マトリックス
- 説明テキスト
- コンスタントサム
- スライダー
- ランキング
- メタ情報
注意: 互換性のない質問タイプを使用すると、データが予期しない方法でスタックされたり、まったくスタックされなかったりする可能性があります。
フィルタリングとBTDSのエクスポート
BTDSのフィルタリングとエクスポートは、「データと分析」タブからのフィルタリングとエクスポートと同じように機能します。これらの操作は、ダッシュボードのインサイトをよりよく理解したり、データセットのサイズを狭めたり、スタックされたデータセットの特定のサブセクションを表示したりするのに役立ちます。
Qtip: Singular = 0 のフィルタをかけると、BX プログラムのユニークな回答のみが含まれるようにデータセットが絞り込まれます。この回答数は、番組のアンケート調査プロジェクトのデータと一致しなければならない。
最適化
大規模なブランドリストを持つBXプログラムでは、必要以上に大きなデータセットが作成される可能性があります。ブランドの最適化により、重要なブランドだけにデータを限定することができる。
例: アメリカとカナダのブランドについてリサーチしているとします。アメリカで注目されているブランドは10あるが、カナダで注目されているブランドは4つしかない。カナダの調査チームは、最適化を用いて4つのブランドを分離し、不必要なデータを扱う必要がなくなる。
gbt__opt-v1__ブランド。 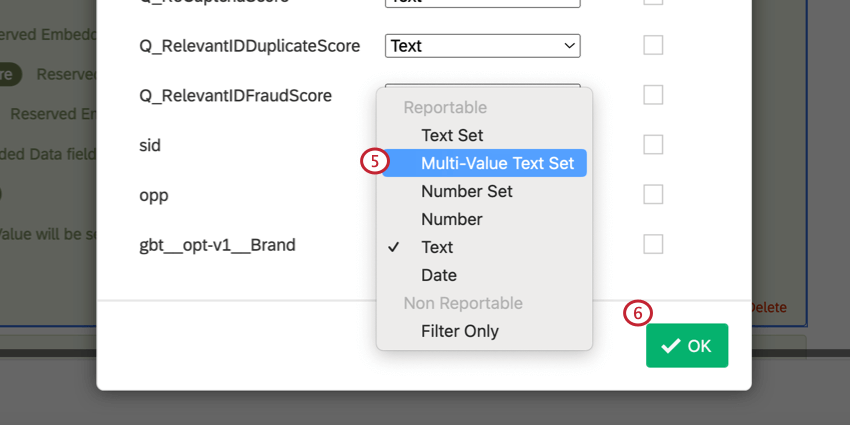
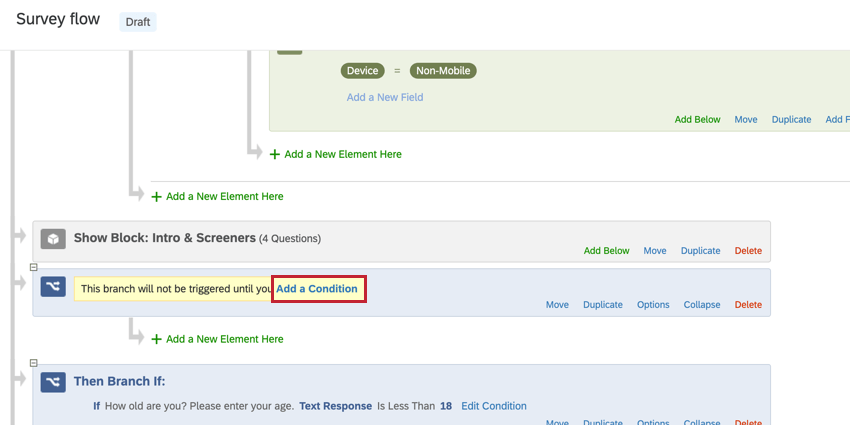
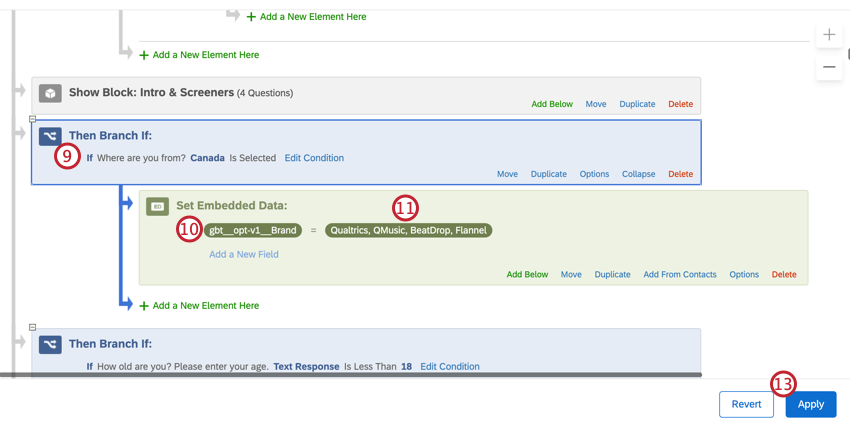
最適化変数が定義されている場合、処理されたBTDSは、その変数のリストに含まれていない行を削除する。
BTDSのトラブルシューティング
注意: 回答が収集された後にアンケートに変更が加えられた場合、その変更を既存の回答に適用するには、BTDS を再処理する必要があります。
BTDSによくある問題は以下の通り:
- BTDSとアンケート調査のData &分析では回答数が異なる。
- ブランドの質問またはフィールドがスタックされないか、BTDS生成後に不適切にスタックされる。
回答数
アンケート調査データセットと BTDS の回答数を比較するには、BTDS を Singular = 1 でフィルターする。このカウントをアンケート調査データセットの合計カウントと比較する。データが正しく流れていれば、この2つの数字は一致するはずだ。
これらの数字が一致しない場合は、アンケートの構成要素に互換性がない可能性がある。BXプログラムのベストプラクティスを評価する。すべてのコンポーネントが正しく表示される場合は、影響を受けるレスポンスIDのリストを添えてクアルトリクスサポートまでご連絡ください。
積み重ねない、または不適切に積み重ねる
Qtip: 積層データセット・プログラミングの詳細については,BX Program Best Practicesを参照してください.
- 再利用可能な選択肢リストとすべてのブランド主導の質問をチェックしてください。ブランド名は再利用可能な選択肢リストと完全に一致していなければならない。
- ブランドリスト内に部分文字列がないことを確認してください(たとえば、あるブランド「クアルトリクス」と別のブランド「クアルトリクス従業員エクスペリエンス」)。
- 質問文は、積み重ねられる各質問に完全に一致するようにしてください。各質問で異なるテキストの差し込み (例: ブランドごとに異なるロゴのテキストの差し込み) を行うことで、特にマトリックスの質問でよく見られる、質問の重ね合わせを防ぐことができます。
- Expert Review > Data Stackingの結果を確認し、フラグが立っている問題があるかどうかを確認する。
FAQs
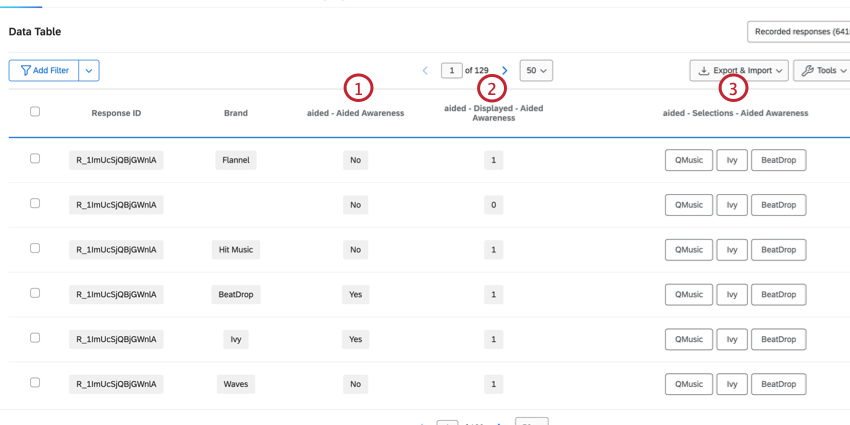
When does the BTDS assign a zero or a “Null”?
When does the BTDS assign a zero or a “Null”?
- If a question is not displayed to a respondent, the BTDS assigns a “Null”.
- If an attribute-led brand question is shown to a respondent, the BTDS assigns a zero if the brand is not selected, even if the brand is not displayed.
- If a brand-led question is not displayed to a respondent, the BTDS assigns a “Null”.
- If a brand-led question is displayed and not answered, the BTDS assigns a “Null”.
- If an attribute-led question is not displayed to a respondent, the BTDS assigns a “Null”.
- If an attribute-led question is displayed but the brand answer option is not, the BTDS assigns a 0.
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!