オムニチャネル・リスニング・マネージャー
このページの内容
オムニチャネル・リスニングについて
オムニチャネル・リスニングとは、顧客が組織との会話で何を話しているかを追跡・分析することである。チャット、Eメール、ボイスのデータをクアルトリクスにインポートすることで、顧客の感情やオペレーターのパフォーマンスに関するインサイトを得ることができます。
ワークフローでは、テキスト分析やダッシュボード作成のために、クアルトリクスにコンタクトセンターのデータを取り込むことができます。コンタクトセンターベンダーからクアルトリクスにデータをインポートするのに役立つワークフロータスクがいくつかあります:
コンタクトセンターのデータは、チャット、Eメール、または音声データを受信するように構成されたプロジェクトにインポートされる必要があります。データの種類に応じて、以下のプロジェクトタイプを使用できます:
このサポートページでは、ワークフロー作成から最適なダッシュボード表示まで、オムニチャネル・リスニングのセットアップをエンド・ツー・エンドで実現する方法をご紹介します。
ご注意: オムニチャネルリスニングプログラムの設定は、クアルトリクス導入チームが行います。導入に関するご質問や、お使いのライセンスでこの機能が利用可能かどうかご不明な場合は、クアルトリクスアカウントチームまでお問い合わせください。
注意: 音声プロジェクトは、チャットデータやメールデータのプロジェクトとは異なる設定があります。チャットデータプロジェクトとメールデータプロジェクトは同じ手順で設定できますが、音声プロジェクトは異なる手順があります。
ヒント:音声データの自動化とインポートは英語データでのみ機能します。
必要なパーミッション
この機能を使用するには、ブランド管理者があなたまたはあなたが帰属意識するユーザータイプに対して、以下のユーザー権限を有効にする必要があります:
- 一般的な許可:
- メールプロジェクトの作成(メールデータをインポートされた場合のみ必要です。)
- チャットプロジェクトの作成(チャットデータをインポートされた場合のみ必要です。)
- ボイスパイプラインのマネージャー(ボイスデータをインポートする場合のみ必要) ヒント:音声プロジェクトには、音声プロバイダーの特定の権限も必要です。詳細については、「パーミッションと音声プロバイダの 要件」を参照してください。

- AIアシスト・テキスト分析(XM Discoverデータ分析用)
- 自動テキスト分析(クアルトリクス・プラットフォームのデータ分析用)
- エクステンションの許可:
- Genesysからデータを抽出
- NICE CXoneからデータを抽出
- Salesforceからデータを抽出
ステップ1:プロジェクトの作成
コンタクトセンターのデータをクアルトリクスに定期的に取り込む前に、データを保存するプロジェクトを作成する必要があります。すべてのコンタクトセンターのデータは最終的に同じダッシュボードに表示することができるので、インポートするデータが複数ある場合は、複数のプロジェクトを作成することになります。
チャットとEメールのデータ
クアルトリクスにインポートするチャットやメールのデータがある場合は、以下のリンク先のリソースで、各タイプのプロジェクトの作成手順をご覧ください:
ヒント:複数のコンタクトセンターソースからのデータを、同じチャットデータまたはメールデータプロジェクトに追加できます。
音声データ
クアルトリクスにインポートする音声データがある場合は、以下のリンク先のリソースでステップバイステップの手順をご覧ください:
ステップ2:コンタクトセンタータスクの作成
チャットとEメールのデータ


- Genesysからデータを抽出
- NICE CXoneからデータを抽出
- Salesforce抽出タスク ヒント:OXMのデータをインポートするには、SalesforceからEメールを抽出します。
ヒント:これらのワークフローは、メールデータまたはチャットデータのプロジェクト内に作成することをお勧めしますが、独立したグローバルワークフロー内に作成することもできます。
音声データ
ボイスプロジェクトを作成したら、ボイスタスクを作成してボイスデータをインポートします。ステップバイステップの手順については、音声 タスクの設定を 参照してください。
ステップ3:データの修正
注意: このステップはチャットとEメールのデータにのみ適用されます。音声データには適用されない。
ワークフローを接続してコンタクトセンターからデータを抽出した後、必要に応じて、ワークフローにタスクを追加してデータを変換することができます。以下のタスクは、プロジェクトにロードする前にデータを修正するために使用できます:
- 基本変換タスク:抽出したフィールドに基本的な変更を加える。
- データの再編集と置換タスク:データソースから特定のフィールドを再編集または置換します。 ヒント:ローダータスクの中に、顧客の連絡先や支払い情報など、保護したい機密データがある場合は、データの再編集と置換タスクを使用すると便利です。
ステップ 4: プロジェクトへのデータのロード
注意: このステップはチャットとEメールのデータにのみ適用されます。音声データには適用されない。
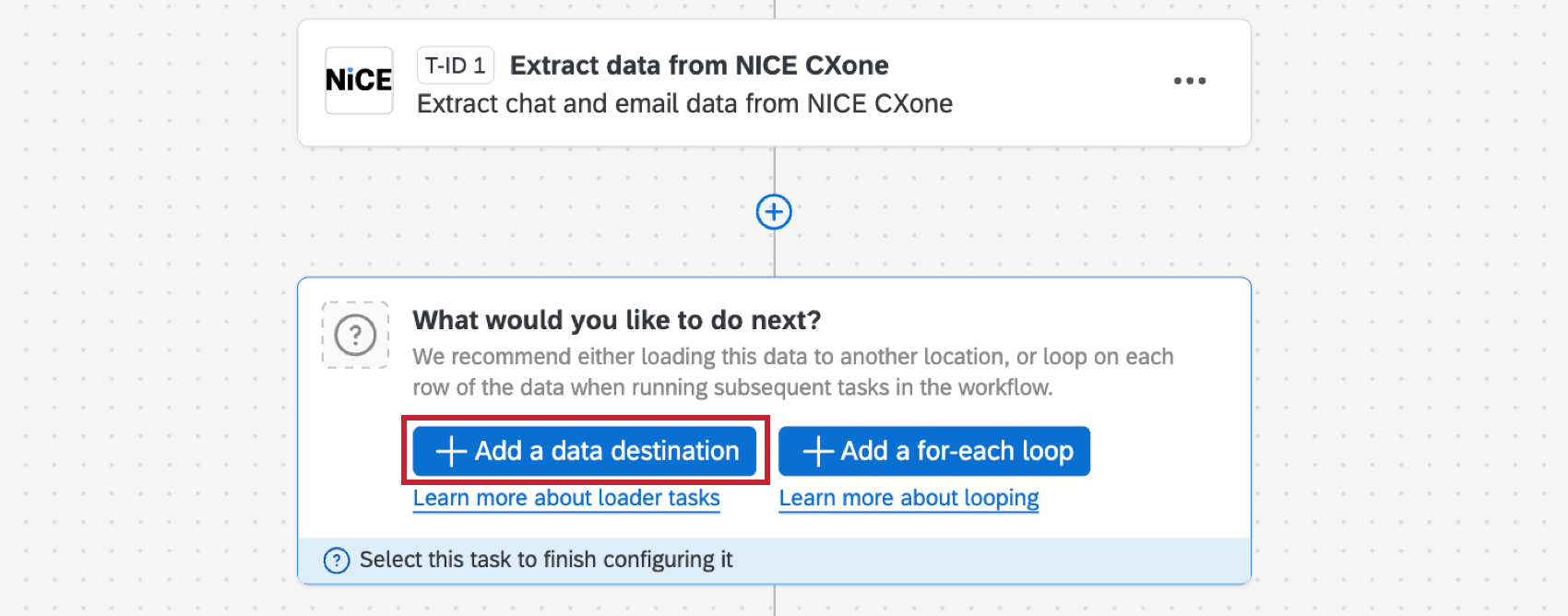
抽出タスクを作成し、データに必要な変換を設定したら、データをプロジェクトに送り返す必要があります。作成したワークフロー内で、「Add a data destination 」をクリックします。
{kind=link}

Conversational Analyticsタスクにデータをロードする]を選択します。このタスクの設定方法については、「Load Data to Conversational Analytics タスクの設定 」を参照してください。ステップ 1で作成したプロジェクトが、すでにデスティネーション・プロジェクトとして選択されています。
ステップ5:データの分析
データがコンタクトセンターからプロジェクトのデータタブに流れ始めたら、次は会話分析を行う番です。これを行うには、まずテキスト分析ツールに向かい、AIの力で主要なテーマとカテゴリーを特定する。
詳しくは、自動化トピックスをご覧ください。
ヒント:自動化トピックには、インプリメンテーションコンサルタントやテクニカルサクセスマネージャーなど、クアルトリクス担当者によるサポートが付いています。この担当者は、ダッシュボードのデータ設定にテキスト分析を実装するためのケアを行います。
ステップ6:ダッシュボードの構築
コンタクトセンターのデータをクアルトリクスに取り込んだ後は、ダッシュボードを使用してレポートすることができます。ダッシュボードを使用すると、多くのソースからデータを取り込み、動的フィルタリングを使用してチャートやテーブルを作成し、関係者にロールベースのアクセスを提供することができます。
以下は、あなたが始めるために使用できるいくつかのリソースです:
- CXダッシュボードを始めよう: ダッシュボードを初めて使用する場合は、この一連のページを使用して、最初のダッシュボード設計から最終製品を関係者と共有するまでの機能をエンドツーエンドで学んでください。
- ダッシュボードで複数のデータセットを使う:全ての会話データが同じダッシュボードに入るようにする最も簡単な方法の一つは、複数のデータセットを使用することです。このオプションを使うと、プロジェクトごとに1つのデータセットを作成し、それぞれを同じダッシュボードに追加して、プロジェクトに共通するフィールドをリンクすることができます。
- データモデルの作成およびJoin:データモデルでは、左外部結合を使用することができます。左外部結合は、フィールドの結合やリンクとは異なるデータレコードの結合手段です。ダッシュボード設計の経験が豊富であったり、複雑なデータを必要とする場合は、結合を試してみるとよいでしょう。
FAQs
What’s the difference between linking, merging, or joining fields?
What’s the difference between linking, merging, or joining fields?
Linking fields ensures different fields from multiple datasets are mapped to each other. You should use this option to create a simple link between datasets. For example, if all you want to do is show data from different sets side by side in the same dashboard, or add a few shared filters for this data, then we recommend linking fields.
Joining fields combines multiple data sources within the same data model, using one field as a “key” to identify records that should be combined. You should use this option to add context to data. For example, if you have multiple stores you manage and collect feedback on, you can have a location directory with important information about all of the stores. Your surveys would then only need the store ID collected with each response. The join can be used to enrich the survey responses with this store data.
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!