
What is sampling?
In survey research, sampling is the process of using a subset of a population to represent the whole population. To help illustrate this further, let’s look at data sampling methods with examples below.
Let’s say you wanted to do some research on everyone in North America. To ask every person would be almost impossible. Even if everyone said “yes”, carrying out a survey across different states, in different languages and timezones, and then collecting and processing all the results, would take a long time and be very costly.
Sampling allows large-scale research to be carried out with a more realistic cost and time-frame because it uses a smaller number of individuals in the population with representative characteristics to stand in for the whole.
However, when you decide to sample, you take on a new task. You have to decide who is part of your sample list and how to choose the people who will best represent the whole population. How you go about that is what the practice of sampling is all about.
Free eBook: This Year’s Global Market Research Trends Report
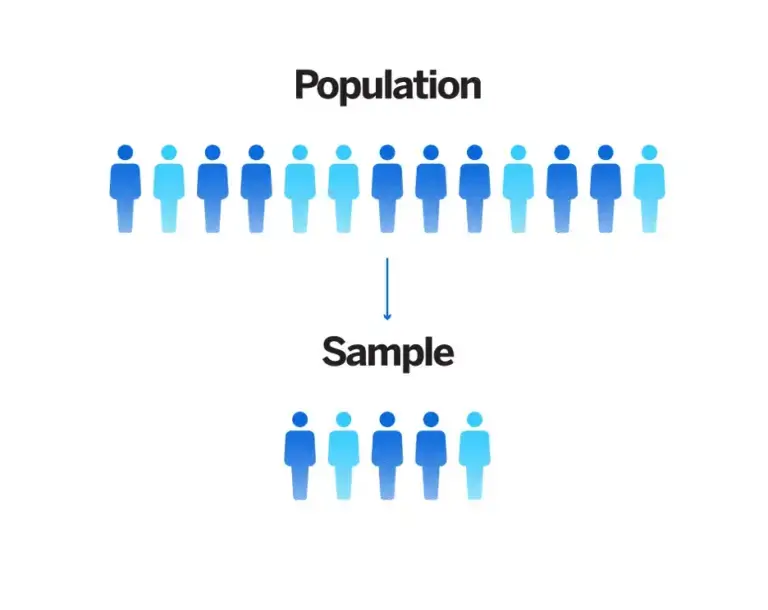
Sampling definitions
- Population: The total number of people or things you are interested in
- Sample: A smaller number within your population that will represent the whole
- Sampling: The process and method of selecting your sample
Why is sampling important?
Although the idea of sampling is easiest to understand when you think about a very large population, it makes sense to use sampling methods in research studies of all types and sizes. After all, if you can reduce the effort and cost of doing a study, why wouldn’t you? And because sampling allows you to research larger target populations using the same resources as you would smaller ones, it dramatically opens up the possibilities for research.
Sampling is a little like having gears on a car or bicycle. Instead of always turning a set of wheels of a specific size and being constrained by their physical properties, it allows you to translate your effort to the wheels via the different gears, so you’re effectively choosing bigger or smaller wheels depending on the terrain you’re on and how much work you’re able to do.
Sampling allows you to “gear” your research so you’re less limited by the constraints of cost, time, and complexity that come with different population sizes.
It allows us to do things like carrying out exit polls during elections, map the spread and effects rates of epidemics across geographical areas, and carry out nationwide census research that provides a snapshot of society and culture.
Types of sampling
Sampling strategies in research vary widely across different disciplines and research areas, and from study to study.
There are two major types of sampling methods: probability and non-probability sampling.
- Probability sampling, also known as random sampling, is a kind of sample selection where randomisation is used instead of deliberate choice. Each member of the population has a known, non-zero chance of being selected.
- Non-probability sampling techniques are where the researcher deliberately picks items or individuals for the sample based on non-random factors such as convenience, geographic availability, or costs.
As we delve into these categories, it’s essential to understand the nuances and applications of each method to ensure that the chosen sampling strategy aligns with the research goals.
Probability sampling methods
There’s a wide range of probability sampling methods to explore and consider. Here are some of the best-known options.
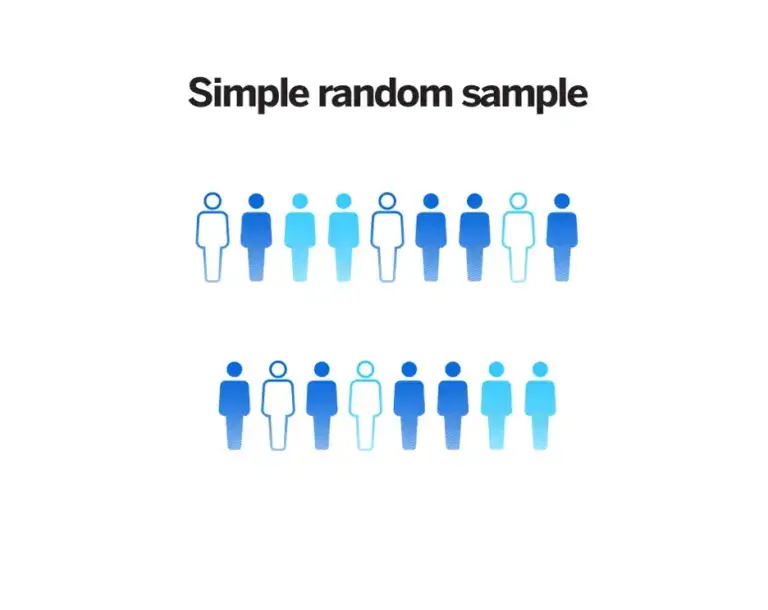
1. Simple random sampling
With simple random sampling, every element in the population has an equal chance of being selected as part of the sample. It’s something like picking a name out of a hat. Simple random sampling can be done by anonymising the population – e.g. by assigning each item or person in the population a number and then picking numbers at random.
Pros: Simple random sampling is easy to do and cheap. Designed to ensure that every member of the population has an equal chance of being selected, it reduces the risk of bias compared to non-random sampling.
Cons: It offers no control for the researcher and may lead to unrepresentative groupings being picked by chance.
2. Systematic sampling
With systematic sampling the random selection only applies to the first item chosen. A rule then applies so that every nth item or person after that is picked.
Best practice is to sort your list in a random way to ensure that selections won’t be accidentally clustered together. This is commonly achieved using a random number generator. If that’s not available you might order your list alphabetically by first name and then pick every fifth name to eliminate bias, for example.
Next, you need to decide your sampling interval – for example, if your sample will be 10% of your full list, your sampling interval is one in 10 – and pick a random start between one and 10 – for example three. This means you would start with person number three on your list and pick every tenth person.
Pros: Systematic sampling is efficient and straightforward, especially when dealing with populations that have a clear order. It ensures a uniform selection across the population.
Cons: There’s a potential risk of introducing bias if there’s an unrecognised pattern in the population that aligns with the sampling interval.
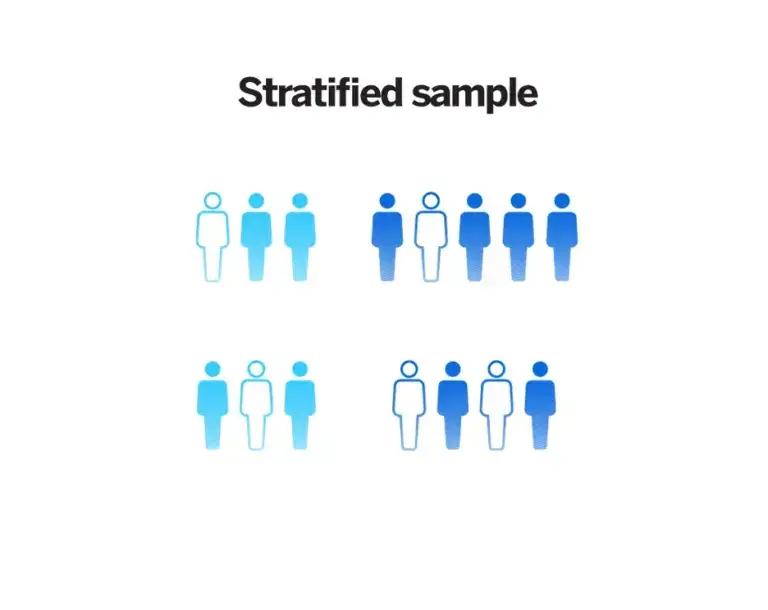
3. Stratified sampling
Stratified sampling involves random selection within predefined groups. It’s a useful method for researchers wanting to determine what aspects of a sample are highly correlated with what’s being measured. They can then decide how to subdivide (stratify) it in a way that makes sense for the research.
For example, you want to measure the height of students at a college where 80% of students are female and 20% are male. We know that gender is highly correlated with height, and if we took a simple random sample of 200 students (out of the 2,000 who attend the college), we could by chance get 200 females and not one male. This would bias our results and we would underestimate the height of students overall. Instead, we could stratify by gender and make sure that 20% of our sample (40 students) are male and 80% (160 students) are female.
Pros: Stratified sampling enhances the representation of all identified subgroups within a population, leading to more accurate results in heterogeneous populations.
Cons: This method requires accurate knowledge about the population’s stratification, and its design and execution can be more intricate than other methods.
4. Cluster sampling
With cluster sampling, groups rather than individual units of the target population are selected at random for the sample. These might be pre-existing groups, such as people in certain postcodes or students belonging to an academic year.
Cluster sampling can be done by selecting the entire cluster, or in the case of two-stage cluster sampling, by randomly selecting the cluster itself, then selecting at random again within the cluster.
Pros: Cluster sampling is economically beneficial and logistically easier when dealing with vast and geographically dispersed populations.
Cons: Due to potential similarities within clusters, this method can introduce a greater sampling error compared to other methods.
Non-probability sampling methods
The non-probability sampling methodology doesn’t offer the same bias-removal benefits as probability sampling, but there are times when these types of sampling are chosen for expediency or simplicity. Here are some forms of non-probability sampling and how they work.
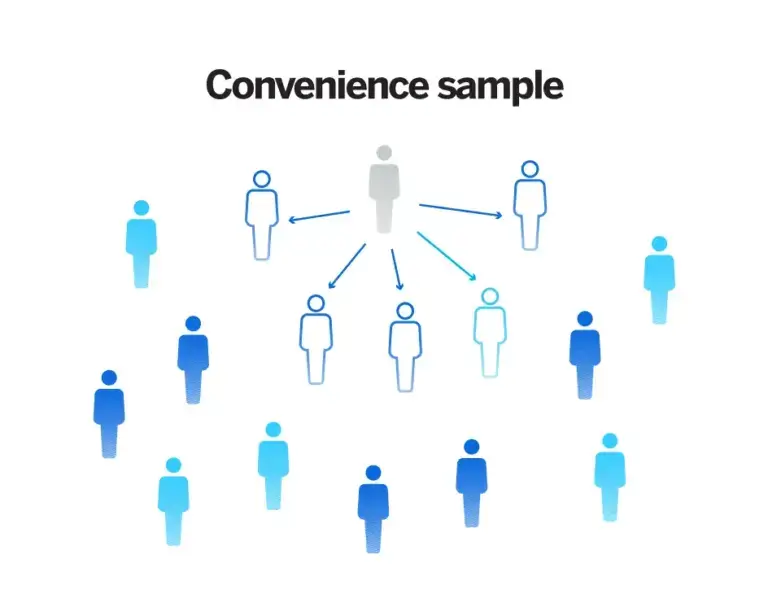
1. Convenience sampling
People or elements in a sample are selected on the basis of their accessibility and availability. If you are doing a research survey and you work at a university, for example, a convenience sample might consist of students or co-workers who happen to be on campus with open schedules who are willing to take your questionnaire.
This kind of sample can have value, especially if it’s done as an early or preliminary step, but significant bias will be introduced.
Pros: Convenience sampling is the most straightforward method, requiring minimal planning, making it quick to implement.
Cons: Due to its non-random nature, the method is highly susceptible to biases, and the results are often lacking in their application to the real world.
2. Quota sampling
Like the probability-based stratified sampling method, this approach aims to achieve a spread across the target population by specifying who should be recruited for a survey according to certain groups or criteria.
For example, your quota might include a certain number of males and a certain number of females. Alternatively, you might want your samples to be at a specific income level or in certain age brackets or ethnic groups.
Pros: Quota sampling ensures certain subgroups are adequately represented, making it great for when random sampling isn’t feasible but representation is necessary.
Cons: The selection within each quota is non-random and researchers’ discretion can influence the representation, which both strongly increase the risk of bias.
3. Purposive sampling
Participants for the sample are chosen consciously by researchers based on their knowledge and understanding of the research question at hand or their goals.
Also known as judgement sampling, this technique is unlikely to result in a representative sample, but it is a quick and fairly easy way to get a range of results or responses.
Pros: Purposive sampling targets specific criteria or characteristics, making it ideal for studies that require specialised participants or specific conditions.
Cons: It’s highly subjective and based on researchers’ judgement, which can introduce biases and limit the study’s real-world application.
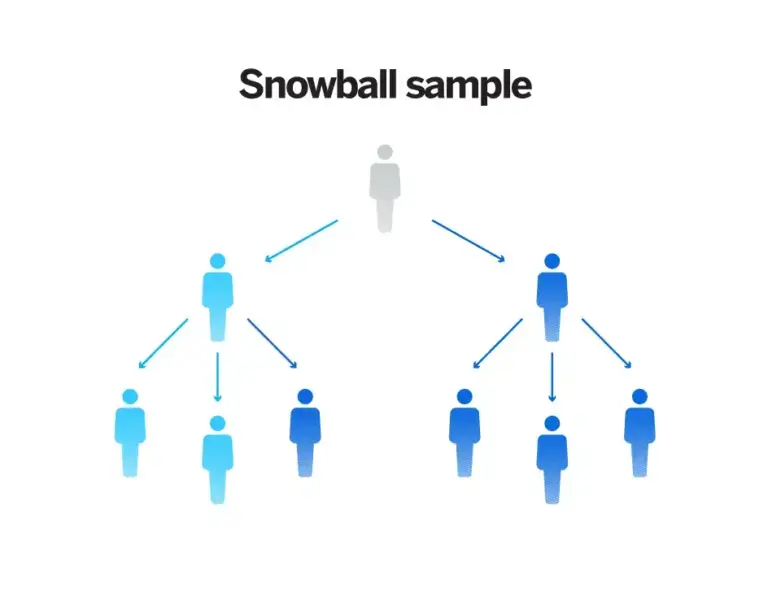
4. Snowball or referral sampling
With this approach, people recruited to be part of a sample are asked to invite those they know to take part, who are then asked to invite their friends and family and so on. The participation radiates through a community of connected individuals like a snowball rolling downhill.
Pros: Especially useful for hard-to-reach or secretive populations, snowball sampling is effective for certain niche studies.
Cons: The method can introduce bias due to the reliance on participant referrals, and the choice of initial seeds can significantly influence the final sample.
What type of sampling should I use?
Choosing the right sampling method is a pivotal aspect of any research process, but it can be a stumbling block for many.
Here’s a structured approach to guide your decision.
1. Define your research goals
If you aim to get a general sense of a larger group, simple random or stratified sampling could be your best bet. For focused insights or studying unique communities, snowball or purposive sampling might be more suitable.
2. Assess the nature of your population
The nature of the group you’re studying can guide your method. For a diverse group with different categories, stratified sampling can ensure all segments are covered. If they’re widely spread geographically, cluster sampling becomes useful. If they’re arranged in a certain sequence or order, systematic sampling might be effective.
3. Consider your constraints
Your available time, budget and ease of accessing participants matter. Convenience or quota sampling can be practical for quicker studies, but they come with some trade-offs. If reaching everyone in your desired group is challenging, snowball or purposive sampling can be more feasible.
4. Determine the reach of your findings
Decide if you want your findings to represent a much broader group. For a wider representation, methods that include everyone fairly (like probability sampling) are a good option. For specialised insights into specific groups, non-probability sampling methods can be more suitable.
5. Get feedback
Before fully committing, discuss your chosen method with others in your field and consider a test run.
Avoid or reduce sampling errors and bias
Using a sample is a kind of short-cut. If you could ask every single person in a population to take part in your study and have each of them reply, you’d have a highly accurate (and very labour-intensive) project on your hands.
But since that’s not realistic, sampling offers a “good-enough” solution that sacrifices some accuracy for the sake of practicality and ease. How much accuracy you lose out on depends on how well you control for sampling error, non-sampling error, and bias in your survey design. Our blog post helps you to steer clear of some of these issues.
How to choose the correct sample size
Finding the best sample size for your target population is something you’ll need to do again and again, as it’s different for every study.
To make life easier, we’ve provided a sample size calculator. To use it, you need to know your:
- Population size
- Confidence level
- Margin of error (confidence interval)
If any of those terms are unfamiliar, have a look at our blog post on determining sample size for details of what they mean and how to find them.
Unlock the insights of yesterday to shape tomorrow
In the ever-evolving business landscape, relying on the most recent market research is paramount. Brands and businesses can harness crucial insights to outmanoeuvre challenges and seize opportunities.
Equip yourself with this knowledge by exploring Qualtrics’ Market Research Global Trends Report below.


