Text mining – the context
Our world has been transformed by the ability of computers to process vast quantities of data. Machines can quantify, itemize and analyze text data in sophisticated ways and at lightning speed – a range of processes that are covered by the term text analytics.
At the same time, advances in technology have made it possible for machines to go even further, extracting complex, semantically meaningful conclusions from text. This is text mining, a sister technology to text analytics that augments and complements its capabilities.
Free eBook: This Year’s Global Market Research Trends Report
Text mining definition
So what is text mining?
Text mining is the process of turning natural language into something that can be manipulated, stored, and analysed by machines. It’s all about giving computers, which have historically worked with numerical data, the ability to work with linguistic data – by turning it into something with a structured format.
Quantitative and qualitative data
To really understand text mining, we need to establish some key concepts, such as the difference between quantitative and qualitative data.
Qualitative data
Most of the human language we find in everyday life is qualitative data. It describes the characteristics of things – their qualities – and expresses a person’s reasoning, emotion, preferences and opinions. Qualitative data can be very rich and complex. It’s also often highly subjective, since it comes from a single person, or in the case of conversation or collaborative writing, a small group of people.
Quantitative data
The opposite of qualitative data is quantitative data. Quantitative data is numerical – it tells you about quantity. And it’s excellent at telling you precisely about measurements and quantities, in the past or present, which makes it invaluable for analysis and predictions. However it can’t provide the ‘why’ information that textual data gives a human reader or speaker.
Text analysis takes qualitative textual data and turns it into quantitative, numerical data. It does things like counting the number of times a theme, topic or phrase is included in a large corpus of textual data, in order to determine the importance or prevalence of a topic. It can also do tasks like assessing the difference between multiple data sources in terms of the words or topics mentioned per quantity of text.
Structured and unstructured data
In addition to quantitative and qualitative data, there is another concept that’s key to understanding text mining: structured, semi-structured, and unstructured data.
- Unstructured data is language in its natural form, as created for and by human beings. Most of the text we consume day to day is in the form of unstructured documents, and even this article is an example of unstructured data. As well as text documents, unstructured data can take the form of video or audio files.
- Structured data is information presented in a consistent format so that it’s easy for computers to analyse and store. A list of phone numbers is an example of structured data. So is a spreadsheet showing a business’ annual accounts.
- Semi-structured data is somewhere between the two — essentially, semi-structured data is in an organised form but it lacks the format computers need in order to analyse it. An example would be an email inbox. Data is somewhat organised into received, sent, spam, junk and so on, but the data within each email is not organised in any consistent way by the email software.
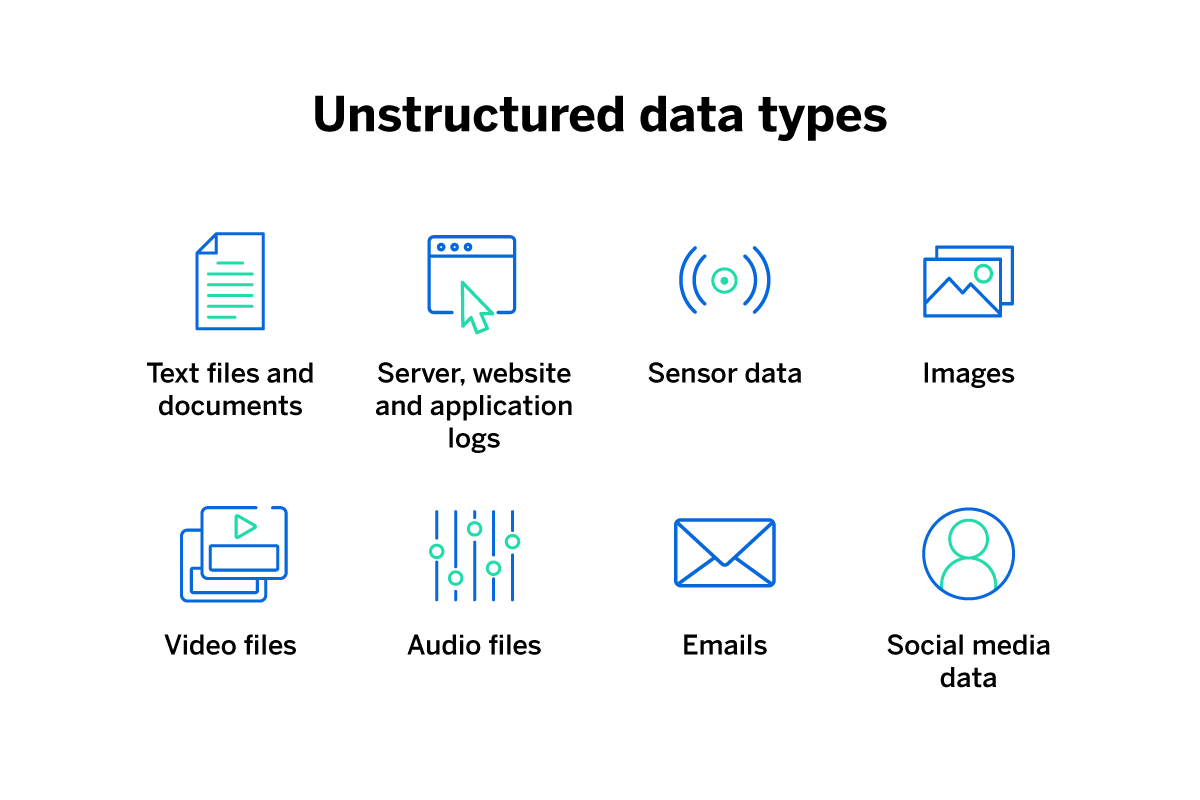
The text mining process turns unstructured data or semi-structured data into structured data. Although you can apply text mining technology to video and audio, it’s most commonly used on text. Text mining is sometimes described as text data mining.
Text mining vs. text analysis
What’s the difference between text mining and text analytics or text analysis? Well, the two terms are often used interchangeably, but they do have subtly different meanings.
Both text mining and text analysis describe several methods for extracting information from large quantities of human language. The two concepts are closely related and in practice, text data mining tools and text analysis tools often work together, resulting in a significant overlap in how people use the terms.
- Text analytics focuses on turning human language data into a structured format suitable for computers. It’s the art of finding numerical data in text documents, such as frequency of word repetition or the presence or absence of themes in different documents. The first text analysis is said to have been carried out in the Middle Ages by French cardinal Hugh of Saint-Cher, who created an early version of a ‘concordance’ – a cross referencing of terms and concepts in the Bible.
- Text mining looks at patterns and trends in textual data, and produces insights that aren’t apparent from just looking at the language itself. It works both by analysing what information is already there in the text, and by looking at metadata such as when documents were written and relationships between textual entities such as different web pages or online reviews.
It can be used to identify semantic themes and even emotions around topics. For example, it might recognise frustration with customer experience or happiness about value for money. Text mining can be valuable in predicting what might happen in the future based on the trends in large volumes of written text over a period of time.
How is text mining different from using a search engine?
Search engines are powerful tools that make huge quantities of information available to us. However, the level of text analysis a search engine uses when crawling the web is basic compared to the way text analytics tools and text mining techniques work.
Rather than looking for keywords and other signals of quality and relevance as search engines do, a text mining algorithm can parse and assess every word of a piece of content, often working in multiple languages. Text mining algorithms may also take into account semantic and syntactic features of language to draw conclusions about the topic, the author’s emotions, and their intent in writing or speaking.
Text mining and text analysis in action
So what are the applications of these technologies and what are some typical text mining tasks? Here are a few examples:
● Customer experience
Text mining allows a business to monitor how and when its products and brand are being talked about. Using sentiment analysis, the company can detect positive or negative emotion, intent and strength of feeling as expressed in different kinds of voice and text data. Then if certain criteria are met, automatically take action to benefit the customer relationship, e.g. by sending a promotion to help prevent customer churn.
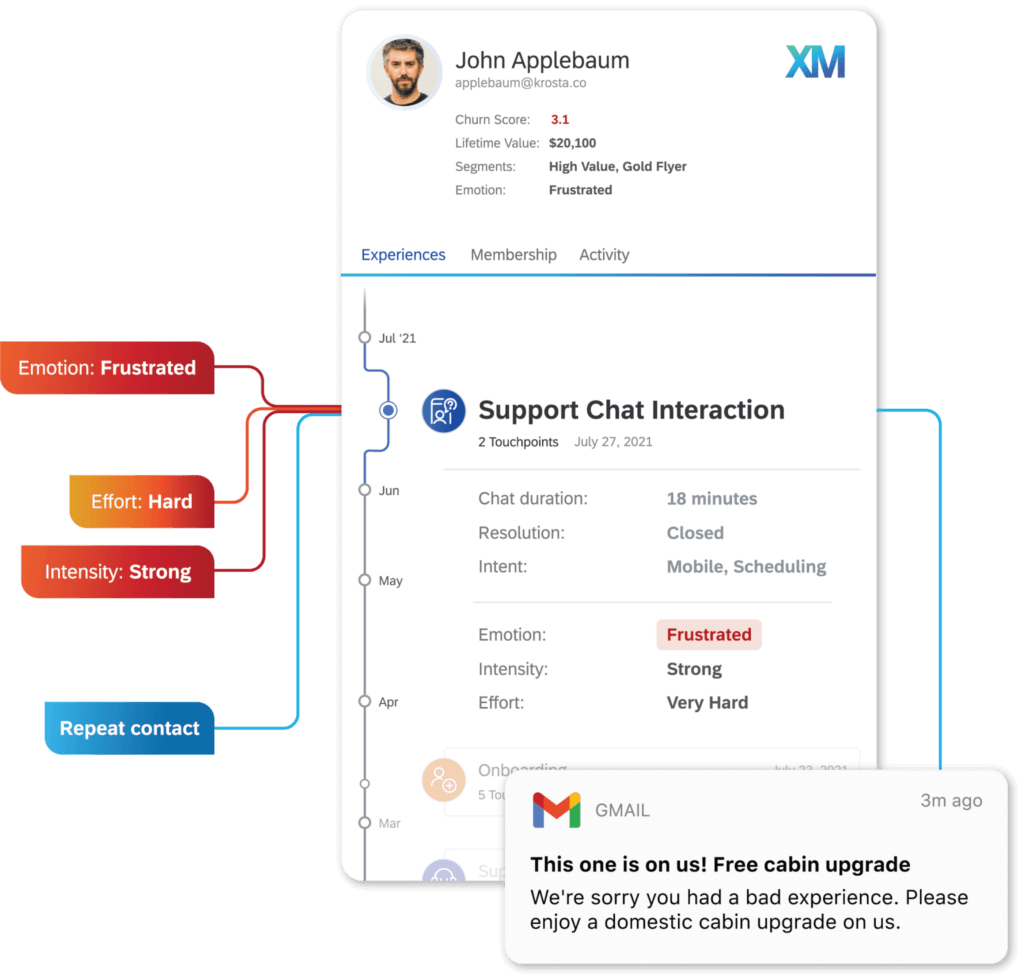
● Customer service
Text mining plays a central role in building customer service tools like chatbots. Using training data from previous customer conversations, text mining software can help generate an algorithm capable of natural language understanding and natural language generation.
● Market research
By analysing social media, chat messages, customer surveys and customer reviews, text mining can help paint a picture of how a brand is perceived in relation to its competitors, the level of brand familiarity among the target audience, and what its perceived strengths and weaknesses are.
● Product development and design
Product teams can get an at-a-glance summary of how customers feel about an existing product by running text mining algorithms on customer feedback. This can help them find the unmet needs they can address to make something better. They can also use text mining tools to find out where there are promising gaps in the market for new product development.
● Fraud prevention
Text mining is useful in finance and insurance as a form of risk management. It can analyse data on potential borrowers or insurance customers and flag inconsistencies. This kind of risk management can help prevent potential fraud situations — for example, by combing the unstructured text data entered in loan application documents.
-
Content selection
Content publishing and social media platforms can also use text mining to analyse user-generated information such as profile details and status updates. The service can then automatically serve relevant content such as news articles and targeted ads to its users.
-
Medical research
Because of its ability to analyse large volumes of data and extract information, text mining can be very helpful in scanning scientific literature as part of medical research. It can help unlock valuable knowledge from papers and books, and even electronic health records, to help medics care for their patients.
The business benefits of text mining
Typical businesses now deal with vast amounts of data from all kinds of sources. The amount of data produced, collected, and processed has increased by approximately 5000% since 2010.
As well as the traditional information, like accounting and record-keeping, customer details, HR records, and marketing lists, brands must now contend with a whole new layer of data.
That includes external data like social media, emails and instant messages, online reviews, news media and IoT data, and internal data, such as meta-data and analytic information, customer profiles used for personalisation, compliance check data, and many more sources, all producing streams of information 24 hours a day. Some of it is structured, but much of it is unstructured text data.
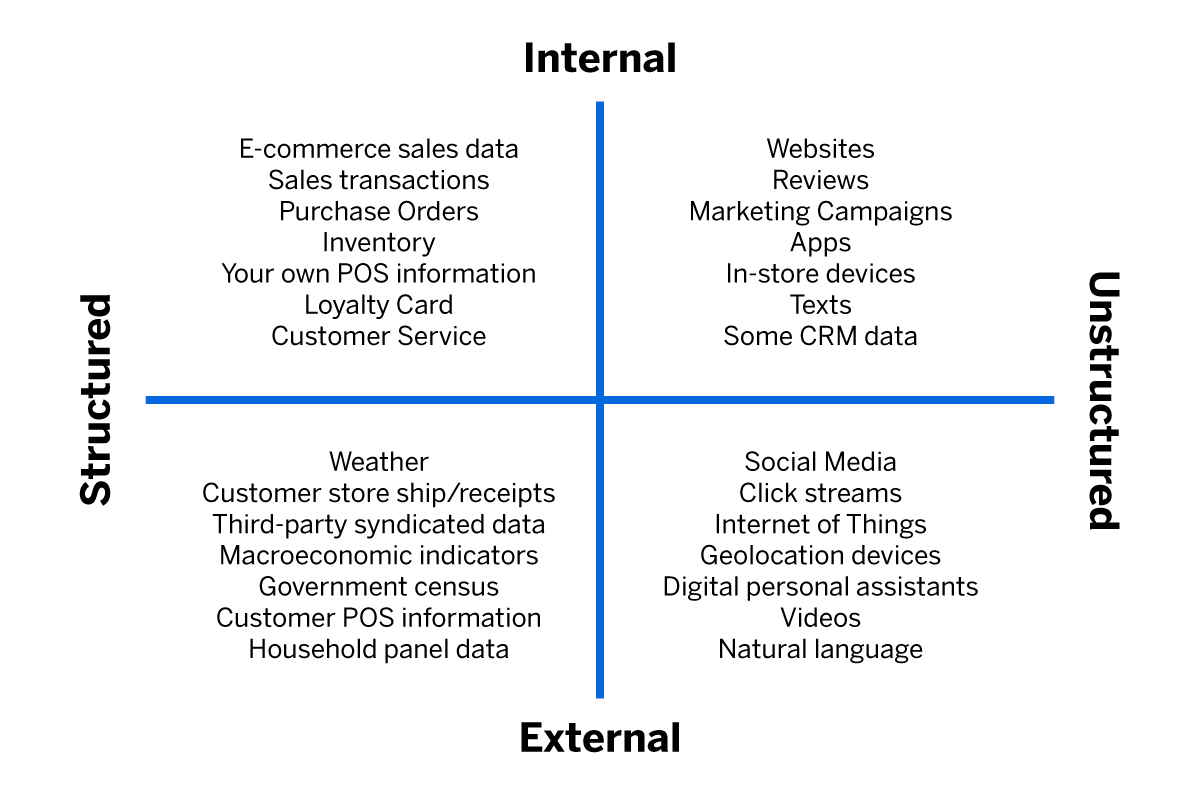
Dealing with this much information manually has become impossible, even for the largest and most successful businesses. It’s no longer a human task.
All of this means companies have become much more selective and sophisticated when it comes to navigating data related to their activities. They must choose what sorts of information they capture from textual materials and plan strategically to filter out the noise and arrive at the insights that will have the most impact.
Text mining, with its advanced ability to assimilate, summarise and extract insights from high-volume unstructured data, is an ideal tool for the task.
Text mining technologies
To get from a heap of unstructured text data to a condensed, accurate set of insights and actions takes multiple text mining techniques working together, some in sequence and some simultaneously. The text data has to be selected, sorted, organised, parsed and processed, and then analysed in the way that’s most useful to the end-user. Finally, the information can be presented and shared using tools like dashboards and data visualisation.
Here are a few of the text mining techniques currently in use.
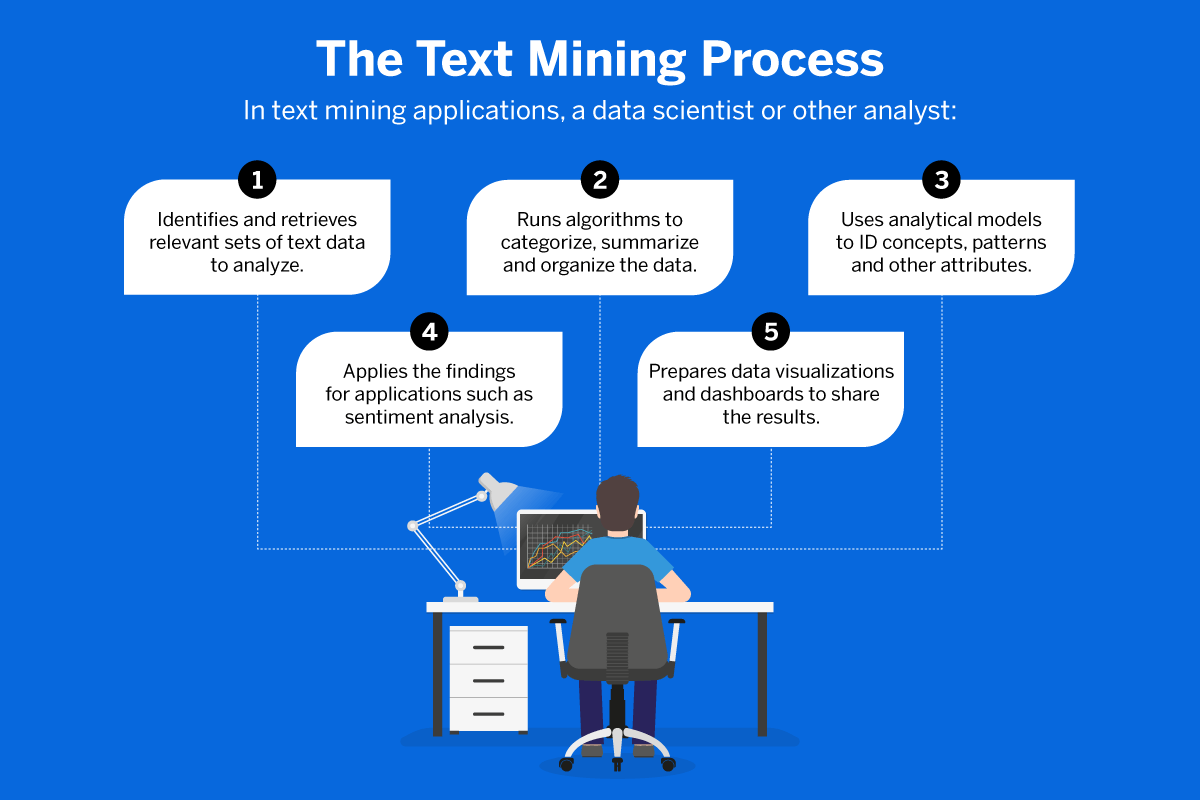
1. Information retrieval
Information retrieval means identifying and collecting the relevant information from a large quantity of unstructured data. That means identifying and selecting what is useful and leaving behind what’s not relevant to a given query, then presenting the results in order according to their relevance. In this sense, using a search engine is a form of information retrieval, although the tools used for linguistic analysis are more powerful and flexible than a standard search engine.
Information retrieval is an older technology than text mining, and one that has been brought up to date in order to act as a part of the text mining process. In information retrieval for text mining, relevant information has to be identified and organised into a textual form that retains its meaning, while at the same time being compatible with linguistic processing by a computer.
That may involve the removal of ‘stop words’ – non-semantic words such as ‘a’ ‘the’ and ‘of’, and even the replacement of synonyms with a single term from a thesaurus which standardises them all together.
2. Language identification
Before information extraction and text analytics can be done effectively, it’s necessary for the text mining tools to identify what language the text is written or spoken in. Even in the case of multilingual data mining, language detection is essential so that the right meaning and role can be ascribed to words and phrases.
Identifying words in different languages is important, especially in cases where a word has the same form but different meanings in different languages. For example the word camera means photographic equipment in English, but in Italian means a room or chamber.
3. Natural language processing (NLP)
Natural language processing is a kind of AI (artificial intelligence). It focuses on giving machines human-like abilities in processing human voices or written communications.
Natural language processing blends techniques from computer science, such as machine learning, and the field of linguistics to create a system that not only understands the semantic meanings of words but can also infer the sentiment and intent of the speaker or writer (an aspect of NLP known as sentiment analysis).
Natural language processing is used in all kinds of contexts, including familiar ones like customer service chatbots, satnavs, and voice assistants. It’s also working in the background of many applications and services, from web pages to automated contact centre menus, to make them easier to interact with.
NLP is something of an umbrella term for a mix of technologies that work together to approximate the way humans do language processing. These include:
- Part-of-speech tagging
Part-of-speech, or POS tagging is a form of text categorisation that identifies the verbs, nouns, adverbs and prepositions in documents written by humans. - Syntactic parsing
This process identifies the grammatical role of words and phrases in clauses and sentences, such as subject, object, noun phrase or prepositional phrase. - Entity recognition
Entity recognition (ER) and named entity recognition (NER) help the text mining algorithm to identify the primary things a piece of natural language text is ‘about’ – for example, in an online review, these entities might include the company, a specific product or service, the customer, and so on. - Entity extraction
Taking things a step further, information extraction, or entity extraction, describes the text mining capabilities that separate and sort unstructured data into structured data that can be processed and edited. It identifies the entities, attributes, and relationships and stores the information in a database where it can easily be accessed.
How is text mining different from data mining?
Data mining is the process of finding trends, patterns, correlations, and other kinds of emergent information in a large body of data. Data mining, unlike text mining overall, extracts information from structured data rather than unstructured data. In a text mining context, Data mining happens once the other elements of text mining have done their work of transforming unstructured text into structured data.

Free eBook: This Year's Global Market Research Trends Report