
Nobody likes losing customers. Customer churn is a real problem across many industries, and the average churn rate can be surprisingly high. For some global markets, churn rates can be as high as 30%.
Customer churn can be expensive. Customer acquisition costs (CAC) for new customers are often significantly greater than the cost of retaining an existing customer base. Particularly in times of economic uncertainty, customers turn to trusted brands as they grow more cautious of spending. Your brand will need to work harder to retain customers and spend less on new acquisitions.
So how do you know if you’re about to lose customers? And how do you take action before it’s too late?
The good news is that there’s a lot you can do to keep them, even when they’re less engaged than they once were. In this post, we’ll discuss how to measure indicators of customer churn, how to use that data to predict the likelihood of churned customers happening, and how to prevent at-risk customers from churning before it’s too late.
Free eBook: 2026 Consumer Experience Trends Report
What is customer churn?
Customer churn, also known as customer attrition, is when someone chooses to stop using your products or services. In effect, it’s when a customer ceases to be a customer.
Customer churn is measured using customer churn rate. That’s the number of people who stopped being customers during a set period of time, such as a year, a month, or a financial quarter.
Calculating customer churn
Here’s an example of how to calculate customer churn rate:
Business X has lost 200 B2C customers over a monthly period. It had 4,000 customers at the beginning of the month and ended with 3,800.
Using the churn rate formula (Lost Customers ÷ Total Customers at Start of Chosen Time Period) x 100 = Churn Rate, we can calculate churn at 5% monthly for Business X.
By using a churn rate formula like this, you can turn it into like-for-like data that help you measure progress over time. You can also express your churn rate in terms of dollar value if it makes sense to do so, helping you to calculate the average revenue cost of losing customers.
Choosing a monthly, quarterly or annual churn rate calculation
When you calculate churn rate, it’s important to be clear about when you consider somebody to have churned. Some sales cycles are longer than others. For example, in some industries, such as optical eyewear or home furnishings, it’s typical for customers to go for long periods without purchasing because of the nature of the product, not because they’re under-engaged or at risk of churn. Other businesses might have monthly recurring revenue due to a shorter sales cycle.
For each product and service you provide, fit your churn definition to your typical sales cycle time period, whether that’s monthly, quarterly, annual or otherwise. Without this cycle in mind, you may end up making reactivation efforts with customers prematurely or calculate churn ineffectively.
Why does customer churn matter?
Some customer churn is inevitable. It’s not realistic to think that 100% of the customers who bought from you on day 1 of your business will still be with you several years down the line. But when your customer churn rate is very high, or if it’s showing a trend of getting higher over time, you’ll want to take action.
Generally speaking, a high customer churn rate is bad news for a couple of reasons:
Your competitors can snap up your market share
Especially during periods when customers are feeling the squeeze, your competitiveness in the market becomes make-or-break when it comes to customer retention. With less money to go around and higher expectations of brand quality and value, there is higher competition between your business and others in your market. An elevated churn rate can hand-deliver your revenue into your competitor’s pockets as customers go to brands they trust.
Dissatisfied customers negatively impact your brand
A churned customer may well be an unhappy customer. It’s not just your churn rate you need to be worried about; beyond the loss of their spending, you could be on the receiving end of negative word-of-mouth, bad reviews, and a detriment to your overall brand value. For these reasons alone, it makes sense to reach out to customers in danger of churning to try and repair these relationships.
Customer churn costs you more
It’s often said that keeping an existing customer costs less and delivers more value than acquiring a new one. Stats and figures on this vary, and some take the view that customer lifetime value matters more than a single cost dimension like acquisition or retention.
But whichever perspective you look from, it generally makes more sense to maintain an existing relationship rather than writing it off and starting again from scratch. Large numbers of existing customers leaving affect your bottom line – meaning addressing your customer churn rate is vital.
Customer churn can impact future growth
Your churn rate can be a strong indicator of future potential growth – or the lack of it. If you’re considering bringing new products and services to the market, the best audience is likely to be your existing customers who already know your brand. If your customer lifetime value is poor, however, your new venture might suffer. A high customer churn rate works against future growth – meaning you need to take steps to reduce customer churn for your future success.
Causes of customer churn
There are many reasons why your customer churn rate is high, and narrowing them down will involve customer churn analysis and measurement.
However, there are a few common drivers of a high churn rate, listed below:
1. Your service isn’t up to scratch
A rising customer churn rate can be an indicator of poor service, meaning you need to do some evaluation of your frontline teams. Good customer service shouldn’t be reserved for new customers – your existing customers deserve great service too.
2. Your product fit or market fit might be lacking
A high customer churn rate might be an indication of a bad product fit. Your existing customers could be finding better solutions elsewhere, or perhaps you’re targeting the wrong audience.
Ensuring your products are aimed at the right audience and developed correctly can help. You should also consider if you’re missing key features that your existing customers have grown to need – it’s not just about drawing in new subscribers, but keeping an eye on how current customers’ tastes have changed.
3. You don’t understand your target audience well enough
Though you might have had your current customers for a long time, that doesn’t mean you always know what they want. As mentioned, more customers might be looking for new features that you’re simply not providing – and that might be a new need that you’re not aware of. The only way to understand your target audience well enough is to track customer feedback and engage with your customer base to know what they’re looking for over time. Keeping an eye on their needs will help you to lower your churn rate.
4. Your pricing isn’t right
Your customers might have been willing to pay a certain amount when they first started using your products or services, but that might not be the case now. As the market changes and competitors challenge your offering, your customers might decide that your price isn’t right – and they might leave as a result. Improving your customer retention might call for a review of your pricing in line with current market values.
5. Your competition offers better services or products
Even if your pricing is competitive, your competition might simply be more in touch with your target customer base. Trying to retain customers might mean evaluating what you’re offering them in the context of your competition – not just at the beginning, but throughout their customer journey and your business trajectory.
A focus on product iteration and new concepts is, therefore, crucial, as you can begin to provide features and functions that your customers want — and your competitors lack.
6. Your market is seasonal
Seasonal markets can have a significant effect on whether your customer churn rate is high. For example, a Halloween store is likely to see a huge influx of new customers in the months coming up to the holiday, with a high churn rate after. If this is the case, evaluating your churn rate in the context of a more sensible time period – such as yearly, rather than monthly – might make more sense.
You can then start to counteract churn by expanding your product/service line or adding to your existing offering to make it more applicable out of season.
7. Your renewal offers aren’t tempting
A large part of reducing customer churn can be giving customers the right offer at the right time. When the time comes to renew a product or service, your customers might simply be deciding that your renewal offers aren’t tempting enough when faced with other offers elsewhere. Customers pay for value, so make sure you’re offering something that feels like a good deal.
Customer churn analysis and measurement
With each customer who churns, there are usually early indicators that could have been uncovered with churn analysis. There are several avenues to consider when it comes to data, and various methods of analysis to choose from when you evaluate what is contributing to the number of customers churning.
Operational and experience insights
Looking at both operational insights (e.g. declining repeat purchases, reduced purchase amounts, and customer service ticket answer rate), as well as experience insights along the customer journey, is foundational to predicting churn. For example, a customer who has declined in recent visits and gives a Net Promoter Score of 7 after their latest shopping experience could have an increased probability of churning.
Conversation analytics
Improving customer retention means listening to your customers, no matter which channel they choose. Using conversation analytics, you can often discover the emotion, intent, and effort behind customer behavior, with customers often telling you their reasons for churning before they depart in indirect ways.
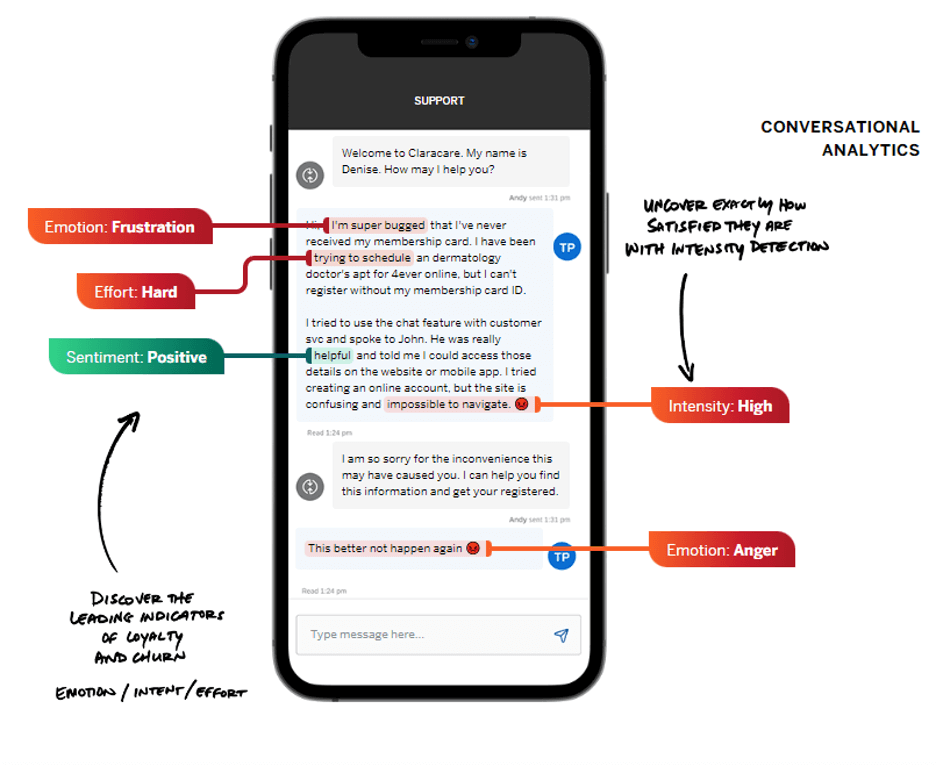
Relational feedback
To start understanding the customer’s journey and the experiences they have set up relational feedback requests that help you assess and diagnose key drivers of customer satisfaction.
Transactional experience measurement
Once you’ve gathered relational feedback, you can move into measuring transactional experiences, such as a purchase or post-support follow-up, so you can get a better sense of where you have detractors and build out a plan to follow up with them. Capturing your audience who might become lost customers and offering them incentives or solutions can help reduce your churn rate significantly.
Key experience measurement throughout the customer journey
You can map out the full customer journey and measure the key experiences across them, from the moment there is a need (e.g. to purchase an item, to get help, to file a claim) to the moment it is fulfilled.
Touchpoints need to be handled correctly to ensure customers don’t decide to look elsewhere – make sure you can resolve issues at speed and serve customers the way they prefer.
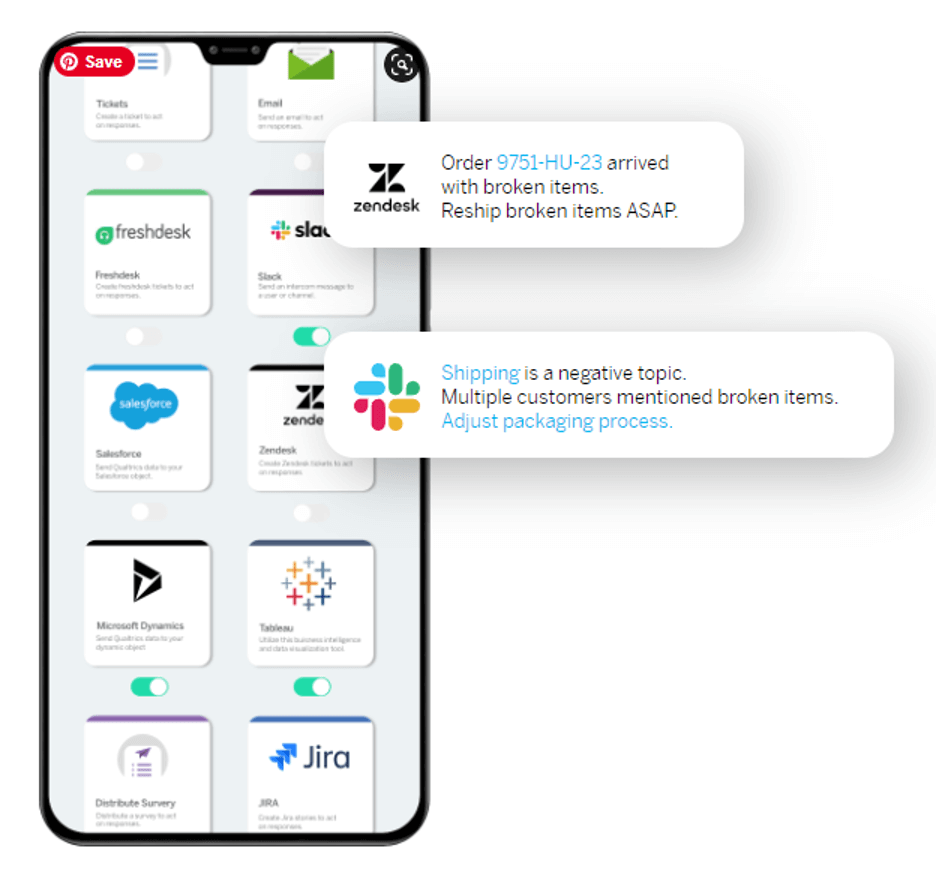
The Qualtrics Customer Experience platform can help you not only measure these critical experience touchpoints but analyze and surface key insights, such as the likelihood to churn, so you can take action and drive outcomes for your business.
Competition analysis
Your plan to reduce customer churn should include examining your position against your competitors. That can include looking at their:
- Pricing
- The current innovation and new product offerings
- Brand exposure
- Share of voice
- Customer engagement
- Product ease of use
- Upgrade and renewal offers
- Sales tactics
- Customer support facilities
By understanding what drives
Customer segment analysis
Understanding your customer segments more deeply can help you to predict behavior and see patterns of customer churn. Here, it’s sensible to do your research on your customer base, not only as they stand now but who they might be in the future. You might want to consider how customer churn changes based on:
- Industries they occupy
- Customer longevity
- Pricing tiers
- Product feature usage
How to predict customer churn
Once you’ve built out a holistic view of your customer’s experience history with your brand, you need to combine it with operational data, such as repeat visits or credit card usage, to identify key drivers of churn and begin making predictions.
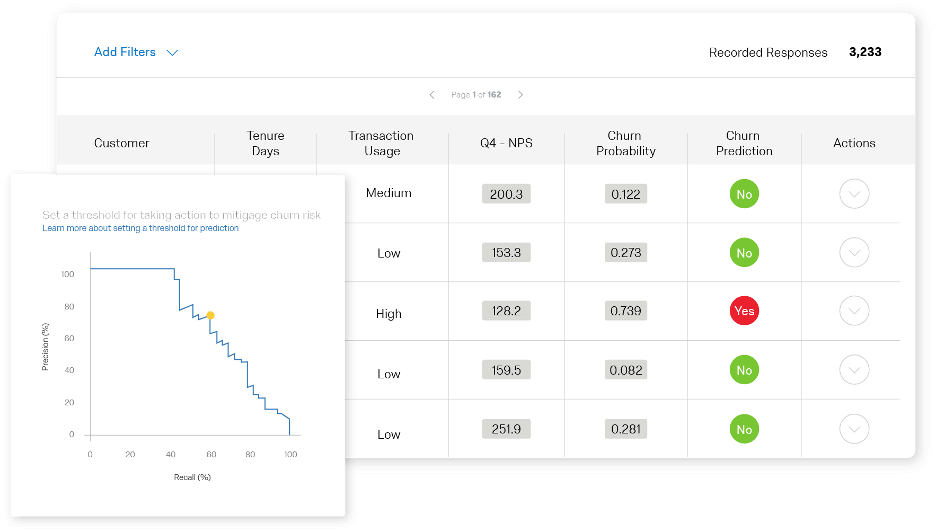
There are four key elements of churn prediction and prevention:
- Understand the drivers of customer churn
- Automatically identify at-risk customers
- Define thresholds for taking action based on the likelihood of churn
- Easily create tickets and take immediate action for closed-loop follow-up
A key way of customer churn prediction is to create a model. This helps you to build patterns by viewing operational data, like return visits and credit card usage, and combine those with experience data, like satisfaction or likelihood to recommend. This model can help you to predict the probability of churn for each customer.
There are tools to make this process simpler. For example, using deep learning and neural networks, Qualtrics iQ combines experience data and operational data to help you predict individual customer behavior, and take action before it is too late.
How to reduce customer churn and retain existing customers
Reducing customer churn isn’t just about saving at-risk customer relationships from the point of no return, although that’s an important part of the picture. Reducing the conditions for churn is something you can do at every stage of the customer lifecycle, through initiatives like:
- Improving CX
A great customer experience is one of the best investments you can make in customer acquisition as well as retention. Great CX makes customers feel good about doing business with you, whether they’re brand new or returning for the 50th time. - Educating your customer
Part of providing good service is giving customers the information and support they need to get the most out of your products and services. That might mean offering how-to guides and explainers on your website, giving prompt answers through a live agent or chatbot feature, or being active on social media when customers share opinions and ask questions. - Rewarding loyalty
Loyalty programs and discounts give your customers an incentive to keep coming back to you again and again. They also help give you an edge over your competitors. Becoming a trusted brand that rewards loyalty helps your business to weather times of reduced consumer spending, as well as tempt customers away from your competitors. - Recognizing your best customers
Dollar for dollar, some customers offer more than others across the lifetime of the business relationship. Recognizing and appreciating your MVPs (most valuable players) will help you make sure that they’re not the ones who end up churning. - Listening to more than just top-level customer comments
Customers won’t necessarily tell you that they’re leaving, but there are many indicators that they’re considering departing. Make sure you take an omnichannel approach to listen, with analysis going deeper than surface-level words. Customer intent, emotion, sentiment, and drivers will help you spot when customers are thinking of leaving.
Closing the loop and reducing customer attrition
Once you’ve predicted whether a customer is at risk of churning, closing the loop with those at-risk customers is the critical next step. Qualtrics XM for Customer Experience can help you create alerts and tickets for customers in various states of unhappiness with your products or services.
For example, you can set a target that requires all tickets for customers with an 80% likelihood to churn to be resolved within 24 hours. If you get a low score on an experience survey and the churn threshold is triggered for a specific customer, Qualtrics automatically generates a ticket requiring specific attention and immediate resolution.
With Qualtrics and the action-planning module, you can go beyond continuously reacting to customer pain, taking insights from the closed-loop process to drive system-wide improvements that avoid customer issues altogether. Employees can collaborate with others, tag owners, set deadlines, and even supply step-by-step guidance.


