
Predictive analytics definition
Predictive analytics is the art of using historical and current data to make projections about what might happen in the future. By looking at what’s happening in the present and what has happened historically, and then applying statistical analysis techniques to the data, researchers can make predictions about what the future might hold.
Predictive analytics is used in a wide variety of business contexts, including experience management programs, to model the impact of possible future actions on a business. Using predictive analytics can transform the way organizations make decisions, since they’re able to ‘foresee’ the results of possible courses of action before choosing which path to take.
Of course, predictive analytics isn’t foolproof. Sometimes the predictions will be wrong, although it still presents a powerful alternative to blind guesses.
Effortlessly integrate feedback collection, research techniques and analytics
Predictive analytics vs other types of business analytics
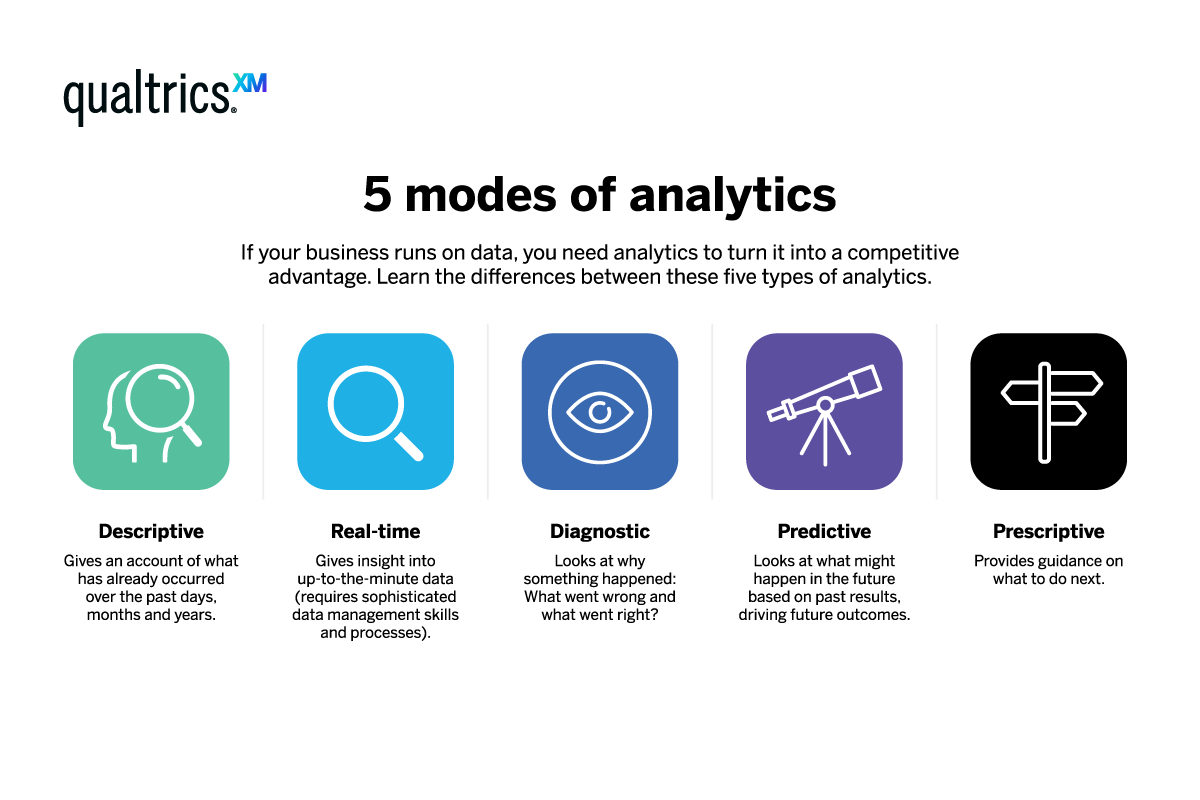
Predictive analysis sits alongside a few other types of data analysis which are increasingly becoming mainstream in the world of business. It can be easy to get them confused, especially when the names are used interchangeably. Here’s a quick glossary of the main types.
- Descriptive analytics tells you what has been happening leading up to the present
- Real-time analytics gives you moment-by-moment data on what is happening
- Diagnostic analytics helps you assess the causal factors relating to an event or situation
- Predictive analytics uses past and current events to forecast what might happen next
- Prescriptive analytics makes recommendations on the best course of action in the future. Prescriptive analytics can be considered one of the most advanced forms of predictive analytics.
Predictive analytics – a human trait?
As human beings, we’re hard-wired to find ways to predict future events. We take our past experiences, quickly assess how they’re similar to the current situation, and use that information to make an educated guess about what’s likely to happen next. In that sense, the human brain is already primed for predictive analytics, although it’s only relatively recently that predictive models and the data analysis tools to create them for business purposes have been developed.
See what’s in store, and take action
Until recently, that kind of data required for high quality predictive analytics was in limited supply. However, with the emergence of data mining, data analytics, and intelligent software suites, predictive analytics has become not only more accessible but more powerful than ever before.
We can now collect huge volumes of data – a phenomenon often called ‘big data’ – and we have the processing power to analyze it rapidly and easily. We also have an array of technologies, including machine learning and multiple kinds of predictive model.
What are predictive models?
Making predictions from data involves constructing a mathematical model (AKA predictive model). This is a tool for finding out what you want to know based on historical data, the target outcome, and the known facts about the scenario.
You can think of a predictive model as a mathematical representation of reality. Like a scale model or architectural model, it replicates a real-world scenario or idea and scales it down so that only the parts you’re interested in are included.
Predictive models are objective, repeatable, based on real information, and use statistics to identify and organize what matters most, to make the prediction accurate. Predictive models are what we use in predictive analytics because they’re much better than human “gut” predictions, which are subject to personal bias and human error.
The importance of current data
Predictive models need to be kept up to date in order to stay effective. Predictive analytics software requires a steady stream of up-to-date information in order to be able to make predictions, since it relies on past data and present data to make accurate forecasts.
That’s part of the reason ‘big data’ capabilities are so important. The more data collected, the more accurate your predictive analytics process will be. Naturally, then, organizations are increasingly looking to collect more data on their employees, customers, products, and brands so they can continue to make predictions about future events.
How does predictive analytics work?
One of the most straightforward examples of predictive analytics – and one that is highly popular and effective – is regression analysis.
Regression analysis, which is divided into linear and nonlinear regression dependeing on the method used, looks at causal relationships between variables. It charts how an independent variable affects dependent variables over time. If there is a consistent pattern, the regression analysis will identify that pattern. It can then make predictions that the same kind of effect will occur in the future, according to the pattern observed in the past.
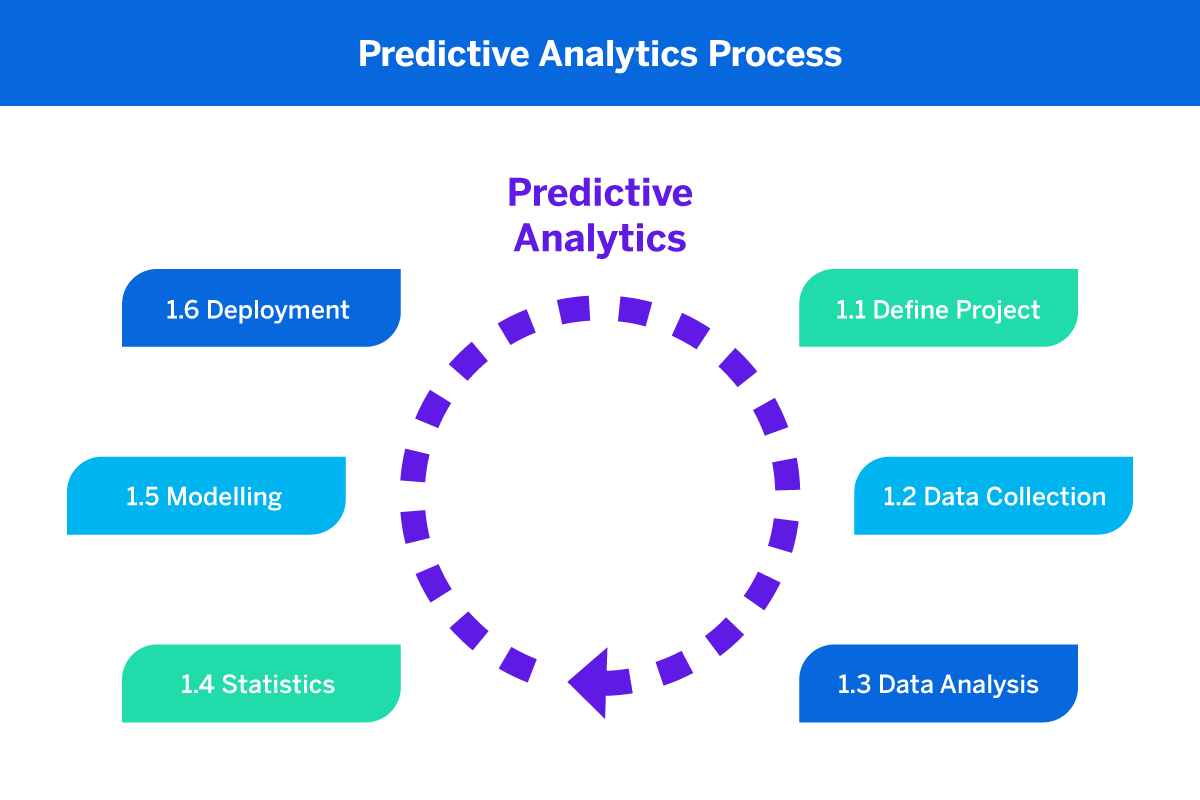
In short, there are a few key steps to any predictive modeling process:
- Decide what you’d like to predict
Whether it’s customer churn or future trends, you need to pick an outcome that you’d like your predictive analytics software to monitor.
- Collect data
As with any kind of data analysis, the more data mining you can do, the more accurate your predictive modeling will be, as per the principle of ‘big data’. We recommend using experience management software to automate this process as much as possible.
- Train and test
Put your model to the test, and use the results to train it to be more accurate in the future – on an ongoing basis. Predictive analytics applications that use artificial intelligence and machine learning should be able to self-improve over time.
Building predictive models
Begin the predictive analytics process by gathering all the data you have on the variables that you think might predict some outcome of interest.
If you are training your predictive modeling using machine learning, you’ll need to have some source of ‘ground truth’ to train it against. This is basically a dataset for a desired outcome, so that the model can learn from what happened in the past.
‘Ground truth’ definition:
Ground truth is any information that is known to be true, provided by direct measurement (i.e. empirical evidence) – that’s as opposed to information provided anecdotally.
For example, let’s say you’re developing predictive modeling techniques for finding out whether it will be sunny on a certain day. To train it, you’d provide data that covered things like:
- How often it was sunny on the same date in past years
- What the weather was like leading up to sunny days in the past
- Any known weather systems such as storms or areas of low pressure
Testing and training the model
When you then introduce new data or the ‘test data set,’ you’ll provide the model with your desired outcome and see how well it predicts it based on the ‘ground truth.’
It’s important to split the dataset into ‘training’ and ‘test’ sets, so that when you give it your training data set – all the predictors without the knowledge of whether it was sunny that day or not – you can assess how well it predicted a sunny day.
The model would also need clear parameters to define the outcome you’re interested in. For example, you might specify the hours of sunshine and the temperature range that would qualify a day as sunny.
At the end of the training period, your model would hopefully be able to predict that, for example, sunny days are most likely after a thunderstorm, and happen more often now than they did 50 years ago.
Using predictive ‘drivers’
A key benefit of predictive modeling is scale. A human can look at a small dataset and identify key indicators that something will happen, but it’s impossible for us to extract predictors out of millions of data points – we just don’t have the processing capacity.
That’s why, as well as using your model to predict if an outcome occurs, you can also use it to extract the most predictive elements in the model and surface them as ‘drivers.’
XM Discover Drivers, for instance, can return the key predictors of your chosen outcome. In that sense, you can think of predictive drivers as a ‘hypothesis generation tool’. In a business environment, it means that instead of spending days slicing and dicing data looking for correlations with a key outcome (like churn, for example), you can use drivers to sniff out leads proactively.
Predictive analytics benefits in commercial business
With so many possible applications of predictive technology, the benefits are theoretically endless. Here’s how predictive analytics can help in commercial settings…
Predicting customer churn
Predictive models can use historical and transactional data to learn the behavioral patterns that precede customer churn, and flag up when they’re happening. By acting promptly, a company may then be able to retain the customer by taking action.
Boosting the customer experience
Predictive technology can help businesses provide a personalized experience to customers by learning what they like and anticipating what they may want next. It can also boost the customer experience more generally by building an understanding of typical consumer behaviors and preferences that businesses can use to help them plan and design experiences.
As well as this, predictive analysis can also help with acting on customer support. Free text (e.g. responses typed into an open field on a survey or as part of a customer review) is information-rich but harder to process than numbers and rating scales because it varies in form and structure.
Predictive technology is now capable of processing both structured and unstructured data. It can process text data at scale and identify clusters of words and phrases that represent certain sentiments or ideas. It can then generalize them to create a big-picture analysis that can be understood at a glance.
Detecting and preventing fraud
The strength of predictive analytics is its ability to recognize patterns, which means it can also spot when something is out of place. Predictive technology can help businesses detect unusual patterns of behavior that might indicate fraud.
If a banking customer based in the US suddenly seems to be making purchases in many other continents in a short space of time, the company can intervene to ensure the account is secure.
Assessing risk
Whether you want to predict credit risk before offering a loan to a customer, or you are a health care clinician who needs to decide the right treatment pathway for a patient, applying predictive analytics can give you the ability to predict future outcomes in an unbiased and consistent way.
Because these kinds of assessments can materially affect people’s lives, it’s paramount that the data sets provided to clinical decision support systems and business analytics for lending and borrowing money are of the highest quality. The training data sets the behavior of the model, so it must be kept up-to-date and actively reviewed by qualified data scientists to make sure that inherent bias in the model doesn’t lead to poor choices.
Predictive analytics: Operational benefits
Implementing predictive data analytics into your day-to-day operations – and using it to anticipate future events – can have real, tangible benefits to organizations of all shapes and sizes.
Planning ahead
Maybe the most obvious reason to use predictive analytics in business is its ability to help you see into the future and plan accordingly across a wide range of verticals like stock, staffing, and customer behavior. Predictive technologies can tell you what’s likely to be over the horizon so that you can prepare in advance and adjust how you allocate your resources.
Predictive analytics example
Let’s say you’re a fashion retailer, and an advanced analytics model tells you that natural materials are about to rise in popularity. You can start working with designers and manufacturers who make these kinds of clothes and cut back on your synthetic lines.
Time-saving and efficiency
Businesses can turn a lot of the work involved in low-risk, routine decision-making over to predictive technologies, freeing up humans for more valuable or high-risk strategic tasks.
Predictive analytics example
Predictive analytics can do much of the work of generating a credit score or deciding whether a straightforward insurance claim can be paid out. In healthcare, predictive analytics can be used to automatically map the likely success rates for new treatments, identify patients that would benefit, or help predict the outcomes of trials based on what’s gone before.
Predicting and preventing risks
By looking at trends and patterns from your operational past, predictive analytics models can spot potential threats, what causes them, and how likely they are to arise. You can then use that information to build out risk or crisis-management processes ahead of time.
Predictive analytics example
You’re a food retailer who relies on a steady supply of inventory to meet customer needs. Predictive insights making use of Big Data can track factors that affect shipping and distribution – like weather or sea conditions. This can help you adjust your stock orders dynamically, as well as to prepare what you’ll do if shortages arise.
Predictive analytics: Getting started
Right now, we’re living in a sweet spot for predictive analytics. The technology is affordable, the know-how is accessible and there’s enough accessible historical data to make truly valuable predictions for business, governance, and the organization of everything from ecological conservation work to education and healthcare.
But although these capabilities are more accessible than they used to be, they are not yet standard. Now is a time when the mastery of predictive analytics still offers companies a competitive advantage, particularly if they make wise choices when choosing their predictive analytics applications.
Most businesses are aware that predictive technology is of value to themselves and their customers, but not everyone is using it – yet.
So how can you start to use predictive analytics in your business?
Luckily, the solution is simple: bring predictive analytics applications into your tech stack. You’ll usually find predictive analytics capabilities built into experience management software – either as a managed, user-directed tool, or an automatic one that uses machine learning algorithms to do a lot of the heavy lifting for you.
Using machine learning to model future events, these software suites will be able to do the hard work for you, and then – ideally – suggest actions as a result, all while using continuous data collection to self-improve. You can use these action points to get ahead of trouble before it arises.
How expert partners can help
Leading providers have developed predictive analytics tools that put the power of advanced predictive analysis in the hands of just about anyone. Machine learning and ‘big data’ mining techniques to run predictive analysis on a constant, ever-evolving basis in order to make predictions about future events, identify risks and even offer guidance on the right choices via prescriptive analytics.
It’s important to choose a predictive analytics partner with a human-first ethos, which means you can take the often intimidating world of data science and turn it into a powerful, everyday tool.


