
What is sentiment analysis?
Sentiment analysis is a powerful tool for monitoring and understanding contextual sentiment for any customer, employee, product, or brand experience. It uses natural language processing, text analysis, linguistics to systematically identify, extract, quantify and study subjective information.
Sentiment analysis is particularly useful for opinion mining and analyzing the voice of the customer materials such as reviews, survey responses, social media, customer feedback, and more. For example, it can understand the polarity of a document to see whether an expressed opinion, sentence, or response to a feature/aspect is positive, negative, or neutral. As opposed to basic sentiment analysis, more advanced sentiment analysis tools can identify positive and negative words and uncover emotional states, such as anger, enjoyment, disgust, sadness, fear, and so on.
Why is sentiment analysis important?
Today, customers engage with brands through modalities such as text and voice, and across multiple channels like surveys, call centers, social media, and websites. Listening to what customers have to say and more importantly understanding how they feel about a product or a service, is paramount to deepening relationships with them, ensuring engagement, and increasing retention.
In other words, understanding your customers’ feelings is critical to the future success of your business. And this is where sentiment analysis algorithms come into play. Through it, you can uncover deeper insights.
Initially, we built a sentiment analysis system that followed these guidelines:
- Simplicity - The sentiment analysis model should provide a simple yet nuanced analysis of the data that is actionable and not too complex to understand.
- Multilingual support - It should have the ability to support multiple languages by understanding cultural and linguistic nuances and provide consistent sentiment prediction accuracy.
- Question text dependency - With different questions, the same customer responses can have completely different meanings and therefore different sentiment predictions. Consider the examples below:
Example 1
Question: What did we do well?
Customer response: Service
Sentiment: Positive
Example 2 Question: What can we improve?
Customer response: Service
Sentiment: Negative
Since then, we've made significant improvements to the sentiment analysis system by building a state-of-the-art sentiment model, leveraging recent groundbreaking advancements in deep learning, cross-lingual language modeling, and in-domain data. In this article, we will talk about our new response-level sentiment system (5-Label Sentiment System) and core prediction model (Sentiment-X).
The 5-Label Sentiment System
In our legacy sentiment system, we had 3 main classification categories: Positive, Negative, and Neutral (Mixed is assigned if the response contains both positive and negative sentiment) and 21 point scoring (from -10 to +10). For example, given a customer response “I really like your service”, our legacy system would predict the sentiment to be Positive with a sentiment score of 18. The legacy system is difficult to understand since the range for sentiment scores was too wide (-10 to +10), making it hard to differentiate between close scores.
In our new 5-Label sentiment system, we removed the 21 point scores and expanded the main sentiment classification categories from 3 to 5: Very Positive, Positive, Negative, Very Negative, Neutral. This significantly simplified our system and reduced the confusion introduced by the 21 point-scoring. It also enhances the sentiment analysis to a fine-grained level without introducing too much complexity.
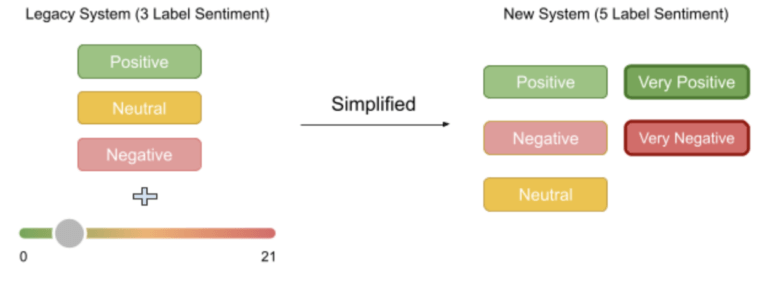
Figure: Categorization and scoring comparison between legacy sentiment system vs 5-Label sentiment system.
Overview of approach
Lexicon-based models and traditional machine learning models, such as support vector machines (SVM) or decision trees, are popular in building sentiment analysis models. In a lexicon-based approach, sentiment classification is performed by using a dictionary of sentiment terms. Traditional machine learning approaches, on the other hand, leverage handcrafted features such as tf-idf, parts of speech, or adjectives to train the model. These approaches require significant human effort for feature engineering and it is hard to scale such models to different domains and languages.
Our legacy sentiment model is a hybrid model combined with a lexicon-based model and a shallow neural network model. This approach is hard to scale and inaccurate. Our new sentiment model is an all-in-one model that supports more than 16 languages and performs better than the legacy model in English.
Transformer-based cross-lingual sentiment analysis
We leverage the latest deep learning technologies and build a transformer-based cross-lingual sentiment model. The model is fine-tuned using Qualtrics multilingual human-labeled sentiment data to make sentiment predictions. There are 6 categories in total: Very Positive, Positive, Neutral, Negative, Very Negative, and Mixed. Compared to our legacy sentiment model, the transformer-based model learns the text contextually and can be refined to support several languages with better sentiment predictions.
Question text awareness
For sentiment, question text is a very important part of the analysis. Different question texts can lead to different sentiment predictions. Our sentiment analysis model leverages both the question text and response text when analyzing the sentiment. When a question text is available, our model uses it as additional input to decide what the sentiment should be. For example, “price” can be interpreted in different ways depending on the question text.
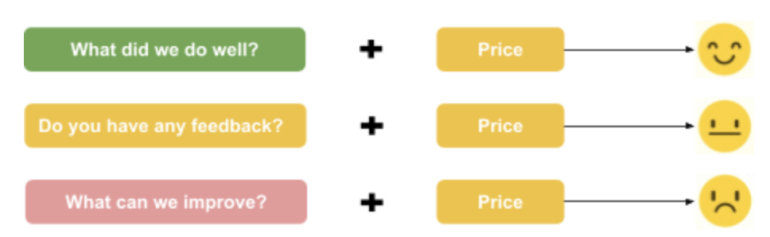
Figure: Examples of how question text can change the sentiment of response text.
Context-awareness is a key differentiating factor between the legacy sentiment model vs the new model. By including question text in the model training, the new sentiment analysis model can resolve ambiguity and generate sentiment labels and scores with high accuracy.
Building a multilingual model
The new model leverages a cross-lingual pre-trained language model trained on diverse web data. We enhanced the base model with anonymized and aggregated customer data points across multiple languages and industries for sentiment analysis. It primarily uses English training data and varying amounts of training data in other languages.
Leveraging pre-trained language models enabled us to obtain superior performance on limited training data. This approach eliminated the need to develop individual language-specific models while providing consistent scoring and sentiment label prediction across multiple languages. We currently support 16 languages, including English, French, Spanish, German, Korean, Italian, Dutch, Japanese, Portuguese, Traditional Chinese, Simplified Chinese, Polish, Swedish, Thai, Indonesian and Russian.
How was the model built?
We followed a 3 phased approach to develop and train our new sentiment analysis system:
Step 1: Prepare the training data - We started by sampling anonymized Qualtrics customer data and aggregated it across different domains/industries and languages to create a training dataset. This training dataset was then manually vetted and labeled for sentiment annotation at the sentence level. For example, the following customer responses were manually labeled by our linguistics team:
Question text: Feedback? Response Text: I really like your service → Positive sentiment
Question text: Feedback? Response Text: I don’t like your service but I like your food → Mixed sentiment
Step 2: Define model architecture - We used a pre-trained transformer-based language model with additional enhancements to achieve superior performance for sentiment analysis across different languages.
Step 3: Train the model - We refined the baseline model with high-quality training samples. We also set up a feedback loop in our model pipeline to listen and learn by incorporating changes our users made to model predictions.
Enhance your data set with sentiment analysis
The 5-Label Sentiment System (and the underlying state-of-the-art sentiment analysis backend) offers superior prediction accuracy compared to the 3-label legacy system. The 5-Label sentiment feature is generally available to all customers with an advanced text license to opt-in. To get an advanced text license for your brand, please reach out to your account representative.
You can opt-in either by visiting your dashboard or your project’s Text iQ tab (Data & Analysis > Text iQ).
The 5-label sentiment feature opt-in is on an individual project/survey basis and is not reversible (you cannot go back to the old 3 label sentiment rubric). If you want to enable 5-label sentiment features for all of your projects/surveys, please reach out to your account representative.