-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Analisi delle corrispondenze (BX)
Informazioni sull’analisi delle corrispondenze
L’analisi delle corrispondenze rivela le relazioni relative tra e all’interno di due gruppi di variabili, sulla base dei dati forniti in una tabella di contingenza. Per le percezioni del brand, questi due gruppi sono:
- Brand
- Attributi che si applicano a questi brand
Per esempio, supponiamo che un’azienda voglia scoprire quali attributi i consumatori associano ai diversi brand di bevande. L’analisi delle corrispondenze aiuta a misurare le somiglianze tra i brand e la forza dei marchi in termini di relazioni con diversi attributi. La comprensione delle relazioni relative consente ai proprietari dei marchi di individuare gli effetti delle azioni precedenti sui diversi attributi legati al marchio e di decidere i passi avanti da compiere.
L’analisi delle corrispondenze è preziosa per la percezione del brand per un paio di motivi. Quando si cerca di esaminare le relazioni relative tra brand e attributi, le dimensioni del marchio possono avere un effetto fuorviante; l’analisi delle corrispondenze elimina questo effetto. L’analisi delle corrispondenze offre anche una rapida visione intuitiva delle relazioni tra gli attributi del brand (in base alla prossimità e alla distanza dall’origine) che non è fornita da molti altri grafici.
In questa pagina, vedremo un esempio di come applicare l’analisi delle corrispondenze a un caso d’uso per diversi brand (fittizi) di bibite.
Cominciamo con il formato dei dati di input: una tabella di contingenza.
Tabelle di contingenza
Una tabella di contingenza è una tabella bidimensionale con gruppi di variabili sulle righe e sulle colonne. Se i nostri gruppi, come descritto sopra, fossero dei brand e gli attributi ad essi associati, faremmo dei sondaggi e otterremmo diversi conteggi di risposte che associano brand diversi a determinati attributi. Ogni cella della tabella rappresenta il numero di risposte o conteggi che associano quell’attributo a quel brand. Questa “associazione” verrebbe visualizzata attraverso una domanda del sondaggio del tipo “Scegli da una lista qui sotto i brand che secondo te presentano ___ attributi”
Qui i due gruppi sono “Brand” (righe) e “Attributi” (colonne). La cella in basso a destra rappresenta il conteggio delle risposte per il brand “BRAND” e l’attributo “Economico”.
| Gustoso | Estetica | Economico | |
| Burrobirra | 5 | 7 | 2 |
| Squishee | 18 | 46 | 20 |
| Slurm | 19 | 29 | 39 |
| Bevanda frizzante per il sollevamento | 12 | 40 | 49 |
| Brawndo | 3 | 7 | 16 |
Residui (R)
Nell’analisi della corrispondenza, si vogliono esaminare i residui di ciascuna cella. Il residuo quantifica la differenza tra i dati osservati e i dati che ci aspetteremmo, supponendo che non vi sia alcuna relazione tra le categorie di riga e colonna (in questo caso, si tratta di brand e attributo). Un residuo positivo indica che il conteggio per quell’accoppiamento di attributi del brand è molto più alto del previsto, suggerendo una relazione forte; corrispondentemente, un residuo negativo mostra un valore più basso del previsto, suggerendo una relazione più debole. Vediamo come calcolare questi residui.
Un residuo (R) è uguale a: R = P – E, dove P è la proporzione osservata ed E è la proporzione attesa per ogni cella. Analizziamo queste proporzioni osservate e previste!
Proporzioni osservate (P)
Una proporzione osservata (P) è pari al valore di una cella divisore per la somma totale di tutti i valori della tabella. Quindi, per la nostra tabella di contingenza di cui sopra, la somma totale sarebbe: 5 + 7 + 2 + 18 … + 16 = 312. Divisore il valore di ogni cella per il totale risulta nella tabella seguente per le proporzioni osservate (P).
Ad esempio, nella cella in basso a destra abbiamo preso il valore iniziale della cella di 16/312 = 0,051. Questo ci dice la percentuale del nostro intero grafico che l’accoppiata Brawndo ed Economico rappresenta in base ai dati raccolti.
| Gustoso | Estetica | Economico | |
| Burrobirra | 0.016 | 0.022 | 0.006 |
| Squishee | 0.058 | 0.147 | 0.064 |
| Slurm | 0.061 | 0.093 | 0.125 |
| Bevanda frizzante per il sollevamento | 0.038 | 0.128 | 0.157 |
| Brawndo | 0.01 | 0.022 | 0.051 |
Masse delle righe e delle colonne
Una cosa che possiamo calcolare facilmente dalle proporzioni osservate, e che ci servirà molto in seguito, sono le somme delle righe e delle colonne della nostra tabella di proporzioni, note come masse di riga e di colonna. La massa di una riga o di una colonna è la proporzione di valori per quella riga/colonna. La massa della riga per la “Burrobirra”, guardando il nostro grafico precedente, sarebbe 0,016 + 0,022 + 0,006, per un totale di 0,044.
Facendo calcoli simili, si ottiene il risultato:
| Gustoso | Estetica | Economico | Masse di fila | |
| Burrobirra | 0.016 | 0.022 | 0.006 | 0.044 |
| Squishee | 0.058 | 0.147 | 0.064 | 0.269 |
| Slurm | 0.061 | 0.093 | 0.125 | 0.279 |
| Bevanda frizzante per il sollevamento | 0.038 | 0.128 | 0.157 | 0.324 |
| Brawndo | 0.01 | 0.022 | 0.051 | 0.083 |
| Masse della colonna | 0.182 | 0.413 | 0.404 |
Proporzioni previste (E)
Le proporzioni attese (E) sono quelle che ci aspettiamo di vedere nelle proporzioni di ogni cella, supponendo che non ci siano relazioni tra righe e colonne. Il nostro valore atteso per una cella sarebbe la massa della riga di quella cella moltiplicata per la massa della colonna di quella cella.
Nella cella in alto a sinistra, la massa della riga della Burrobirra moltiplicata per la massa della colonna del Gustoso, 0,044 * 0,182 = 0,008.
| Gustoso | Estetica | Economico | |
| Burrobirra | 0.008 | 0.019 | 0.018 |
| Squishee | 0.049 | 0.111 | 0.109 |
| Slurm | 0.051 | 0.115 | 0.113 |
| Bevanda frizzante per il sollevamento | 0.059 | 0.134 | 0.131 |
| Brawndo | 0.015 | 0.034 | 0.034 |
Ora possiamo calcolare la tabella dei residui (R), dove R = P – E. I residui quantificano la differenza tra le proporzioni dei dati osservati e le proporzioni dei dati attesi, se si ipotizza che non vi sia alcuna relazione tra le righe e le colonne.
Prendendo il valore più negativo, pari a -0,045, per Squishee ed Economic, l’interpretazione è che esiste un’associazione negativa tra Squishee ed Economic; Squishee ha molte meno probabilità di essere considerata “economica” rispetto agli altri brand di bevande.
| Gustoso | Estetica | Economico | |
| Burrobirra | 0.008 | 0.004 | -0.012 |
| Squishee | 0.009 | 0.036 | -0.045 |
| Slurm | 0.01 | -0.022 | 0.012 |
| Bevanda frizzante per il sollevamento | -0.021 | -0.006 | 0.026 |
| Brawndo | -0.006 | -0.012 | 0.018 |
Residui indicizzati (I)
Tuttavia, la lettura dei soli residui presenta alcuni problemi.
Osservando la riga superiore della nostra tabella di calcolo dei residui, vediamo che tutti questi numeri sono molto vicini allo zero. Non dobbiamo trarre l’ovvia conclusione che la Burrobirra non è correlata ai nostri attributi, perché questa supposizione è errata. La spiegazione reale sarebbe che le proporzioni osservate (P) e le proporzioni attese (E) sono piccole perché, come ci dice la nostra massa di righe, solo il 4,4% del campione è Burrobirra.
Ciò solleva un grosso problema nell’analisi dei residui: poiché non teniamo conto del numero effettivo di record nelle righe e nelle colonne, i nostri risultati sono sbilanciati verso le righe/colonne con masse maggiori. Possiamo risolvere questo problema dividendo i nostri residui per le proporzioni attese (E), ottenendo una tabella di residui indicizzati (I, I = R / E):
| Gustoso | Estetica | Economico | |
| Burrobirra | 0.95 | 0.21 | -0.65 |
| Squishee | 0.17 | 0.32 | -0.41 |
| Slurm | 0.2 | -0.19 | 0.11 |
| Bevanda frizzante per il sollevamento | -0.35 | -0.04 | 0.2 |
| Brawndo | -0.37 | -0.35 | 0.52 |
I residui indicizzati sono facili da interpretare: più il valore è lontano dalla tabella, più grande è la proporzione osservata rispetto a quella attesa.
Ad esempio, prendendo il valore in alto a sinistra, la Burrobirra ha il 95% di probabilità in più di essere vista come “Gustosa” rispetto a quanto ci aspetteremmo se non ci fosse alcuna relazione tra questi brand e attributi. Mentre nel valore in alto a destra, la Burrobirra ha il 65% in meno di probabilità di essere considerata “Economica” rispetto a quanto ci aspetteremmo, non essendoci alcuna relazione tra i brand e gli attributi.
| Gustoso | Estetica | Economico | |
| Burrobirra | 0.95 | 0.21 | -0.65 |
| Squishee | 0.17 | 0.32 | -0.41 |
| Slurm | 0.2 | -0.19 | 0.11 |
| Bevanda frizzante per il sollevamento | -0.35 | -0.04 | 0.2 |
| Brawndo | -0.37 | -0.35 | 0.52 |
Dati i residui indicizzati (I), le proporzioni attese (E), le proporzioni osservate (P) e le masse di riga e colonna, passiamo al calcolo dei valori dell’analisi delle corrispondenze per il nostro grafico!
Calcolo delle coordinate per l’analisi delle corrispondenze
Decomposizione del valore singolare (SVD)
Il primo passo consiste nel calcolare la Singular Value Decomposition (SVD). L’SVD ci fornisce i valori per calcolare la varianza e tracciare le righe e le colonne (brand e attributi).
Calcoliamo la SVD sul residuo standardizzato (Z), dove Z = I * sqrt(E), dove I è il nostro residuo indicizzato ed E è la nostra proporzione attesa. Moltiplicando per E si ottiene una ponderazione della SVD, in modo tale che alle celle con un valore atteso più elevato venga attribuito un peso maggiore e viceversa; ciò significa che, poiché i valori attesi sono spesso correlati alla dimensione del campione, le celle più “piccole” della tabella, in cui l’errore di campionamento sarebbe stato maggiore, vengono ponderate meno. Pertanto, l’analisi delle corrispondenze mediante una tabella di contingenza è relativamente resistente agli outlier causati dall’errore di campionamento.
Tornando alla nostra SVD, abbiamo: SVD = svd(Z). Una decomposizione dei valori singolari genera 3 output:
Un vettore, d, contenente i valori singolari.
| 1a dimensione | 2a dimensione | 3a dimensione |
| 2.65E-01 | 1.14E-01 | 4.21E-17 |
Una matrice, u, contenente i vettori singolari di sinistra (brand).
| 1a dimensione | 2a dimensione | 3a dimensione | |
| Burrobirra | -0.439 | -0.424 | -0.084 |
| Squishee | -0.652 | 0.355 | -0.626 |
| Slurm | 0.16 | -0.0672 | -0.424 |
| Bevanda frizzante per il sollevamento | 0.371 | 0.488 | -0.274 |
| Brawndo | 0.469 | -0.06 | -0.588 |
Una matrice, v, contenente i vettori singolari destri (attributi).
| 1a dimensione | 2a dimensione | 3a dimensione | |
| Gustoso | -0.41 | -0.81 | -0.427 |
| Estetica | -0.489 | >0.59 | -0.643 |
| Economico | 0.77 | -0.055 | -0.635 |
I vettori singolari di sinistra corrispondono alle categorie nelle righe della tabella, mentre i vettori singolari di destra corrispondono alle colonne. Ciascuno dei valori singolari, per il calcolo della varianza, e i vettori corrispondenti (cioè le colonne di u e v), per il tracciamento delle posizioni, corrispondono a una dimensione. Le coordinate utilizzate per tracciare le categorie di righe e colonne del nostro grafico di analisi delle corrispondenze sono derivate dalle prime due dimensioni.
Varianza espressa dalle nostre dimensioni
I valori singolari al quadrato sono noti come autovalori (d^2). Gli autovalori nel nostro esempio sono 0,0704, 0,0129 e 0,0000. Esprimendo ciascun autovalore in proporzione alla somma totale, si ottiene la quantità di varianza catturata in ciascuna dimensione dell’analisi delle corrispondenze, in base al valore singolare di ciascuna dimensione; l’84,5% della varianza è espressa dalla prima dimensione e il 15,5% dalla seconda dimensione (la terza dimensione spiega lo 0% della varianza).
Analisi della corrispondenza standard
Ora disponiamo delle risorse per calcolare la forma di base dell’analisi delle corrispondenze, utilizzando le cosiddette coordinate standard, calcolate dai vettori singolari destro e sinistro. In precedenza, abbiamo ponderato i residui indicizzati prima di eseguire la SVD. Per ottenere le coordinate che rappresentano i nostri residui indicizzati, dobbiamo ora decomprimere i risultati della SVD, dividendo ogni riga dei vettori singolari di sinistra per la radice quadrata delle masse di riga e dividendo ogni colonna dei vettori singolari di destra per la radice quadrata delle masse di colonna, ottenendo le coordinate standard delle righe e delle colonne per il grafico.
Coordinate standard del brand:
| 1a dimensione | 2a dimensione | 3a dimensione | |
| Burrobirra | -2.07 | -2 | -0.4 |
| Squishee | -1.27 | 0.68 | -1.21 |
| Slurm | 0.3 | -1.27 | -0.8 |
| Bevanda frizzante per il sollevamento | 0.65 | 0.86 | -0.48 |
| Brawndo | 1.62 | -0.21 | -2.04 |
Coordinate standard dell’attributo:
| 1a dimensione | 2a dimensione | 3a dimensione | |
| Gustoso | -0.96 | -1.89 | -1 |
| Estetica | -0.76 | 0.92 | >-1 |
| Economico | 1.21 | -0.09 | -1 |
Utilizziamo le due dimensioni con la maggiore varianza catturata per il grafico, la prima dimensione sull’asse X e la seconda sull’asse Y, generando il nostro grafico standard dell’analisi delle corrispondenze.
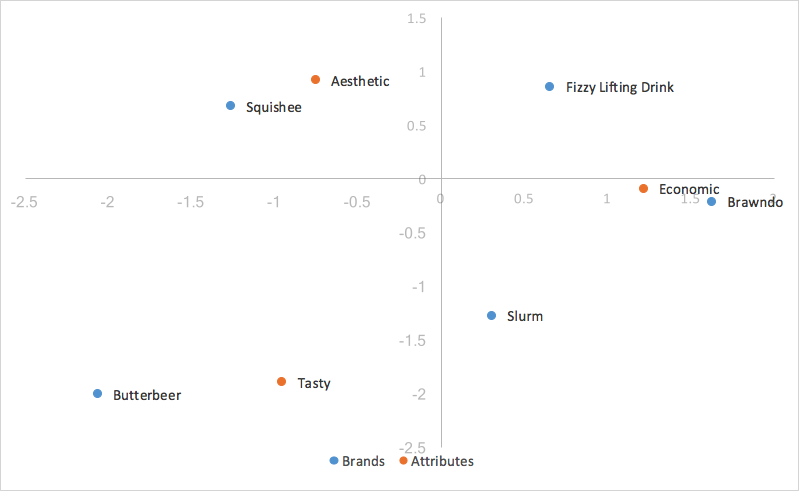
Abbiamo gettato le basi dei calcoli necessari per l’analisi delle corrispondenze standard, ma nella prossima sezione esploreremo i pro e i contro dei diversi stili di analisi delle corrispondenze e quale si adatta meglio ai nostri scopi di analisi delle percezioni dei brand.
Tipi di analisi delle corrispondenze
Analisi delle corrispondenze principali riga/colonna
L’analisi delle corrispondenze standard è facile da calcolare e permette di trarre ottimi risultati. Tuttavia, la corrispondenza standard è una scelta inadeguata per le nostre esigenze; le distanze tra le coordinate di riga e colonna sono esagerate e non c’è un’interpretazione diretta delle relazioni tra le categorie di riga e colonna. Per interpretare le relazioni tra le coordinate delle righe (brand) e le relazioni tra le categorie delle righe e delle colonne, è necessaria la normalizzazione principale delle righe (o, se i brand fossero sulle colonne, la normalizzazione principale delle colonne).
Per la normalizzazione principale delle righe, si vogliono utilizzare le coordinate standard calcolate in precedenza per i valori delle colonne (attributi), ma si vogliono calcolare le coordinate principali per i valori delle righe (brand). Per calcolare le coordinate principali è sufficiente prendere le coordinate standard e moltiplicarle per i corrispondenti valori singolari (d). Quindi, per le nostre righe, dobbiamo semplicemente moltiplicare le nostre coordinate di riga standard per i nostri valori singolari (d), come mostrato nella tabella seguente. Per la normalizzazione del capitale delle colonne basterà moltiplicare le colonne, anziché le righe, per i valori singolari (d).
| 1a dimensione | 2a dimensione | 3a dimensione | |
| Burrobirra | -0.55 | -0.23 | 0 |
| Squishee | -0.33 | 0.08 | 0 |
| Slurm | 0.08 | -0.14 | 0 |
| Bevanda frizzante per il sollevamento | 0.17 | 0.1 | 0 |
| Brawndo | 0.43 | -0.02 | 0 |
Sostituendo le coordinate principali per le righe (brand), si ottiene:
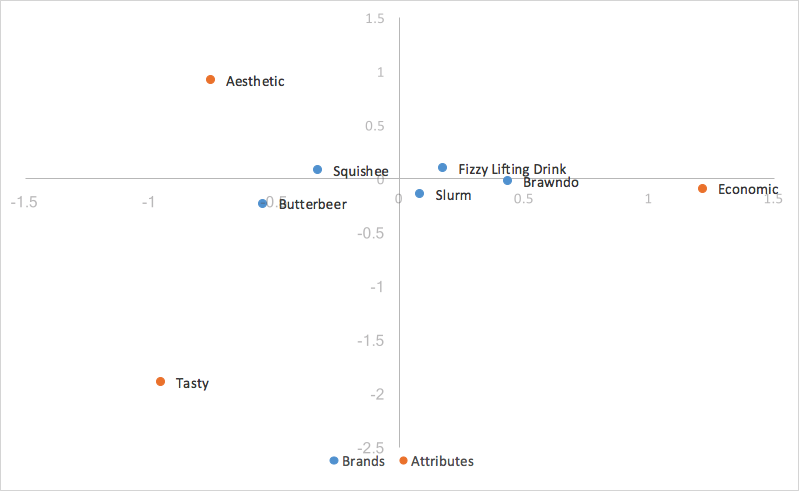
Poiché abbiamo scalato per i valori singolari, le coordinate principali per le righe rappresentano la distanza tra i profili delle righe della tabella originale; è possibile interpretare le relazioni tra le coordinate delle righe nel grafico dell’analisi delle corrispondenze in base alla loro vicinanza reciproca.
Le distanze tra le nostre coordinate di colonna, essendo basate su coordinate standard, sono ancora esagerate. Inoltre, la scalatura in base ai valori singolari in una sola delle due categorie (righe/colonne) ci ha fornito un modo per interpretare le relazioni tra le categorie di righe e colonne. Dato un valore di riga e uno di colonna, ad esempio Burrobirra (riga) e Gustoso (colonna), maggiore è la loro distanza dall’origine, più forte è la loro associazione con altri punti della mappa. Inoltre, più piccolo è l’angolo tra i due punti (Burrobirra e Gustoso), più alta è la correlazione tra i due.
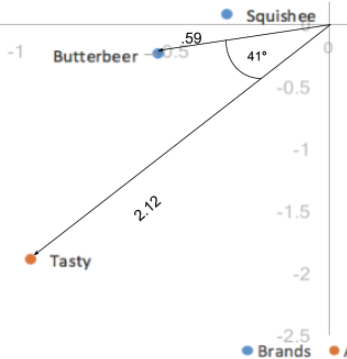
La distanza dall’origine combinata con l’angolo tra i due punti è l’equivalente del prodotto dei punti; il prodotto dei punti tra un valore di riga e uno di colonna misura la forza dell’associazione tra i due. Infatti, quando la prima e la seconda dimensione spiegano tutta la varianza dei dati (sommate al 100%), il prodotto dei punti è direttamente uguale al residuo indicizzato delle due categorie. In questo caso, il prodotto dei punti sarebbe la distanza dall’origine dei due punti moltiplicata per il coseno dell’angolo che li separa; .59*2,12*cos(41) = .94. Tenendo conto degli errori di arrotondamento, è uguale al nostro valore residuo indicizzato di .95. Pertanto, gli angoli inferiori a 90 gradi rappresentano un residuo indicizzato positivo e quindi un’associazione positiva, mentre gli angoli superiori a 90 gradi rappresentano un residuo indicizzato negativo o un’associazione negativa.
Analisi di corrispondenza principale a righe scalari
Osservando il grafico precedente per la normalizzazione del capitale di riga, è facile notare che i punti delle colonne (tratti) sono molto più distribuiti, mentre i punti delle righe (brand) si raggruppano intorno all’origine. Questo può rendere l’analisi del nostro grafico a occhio piuttosto difficile e poco intuitiva, e a volte impossibile leggere le categorie delle righe se sono tutte sovrapposte. Fortunatamente, esiste un modo semplice per scalare il nostro grafico per inserire le colonne, mantenendo la possibilità di utilizzare il prodotto dei punti (distanza dall’origine e angolo tra i punti) per analizzare le relazioni tra i punti delle righe e delle colonne, noto come normalizzazione principale delle righe in scala.
La normalizzazione principale scalare della riga prende la normalizzazione principale della riga e scala le coordinate della colonna nello stesso modo in cui abbiamo scalato l’asse x delle coordinate della riga – in altre parole, le coordinate della colonna vengono scalate dal primo valore dei valori singolari (d). I valori delle righe rimangono invariati rispetto alla normalizzazione del capitale di riga, ma ora le coordinate delle colonne vengono ridotte di un fattore costante.
| 1a dimensione | 2a dimensione | 3a dimensione | |
| Gustoso | -0.2544 | -0.501 | -0.265 |
| Estetica | -0.201 | 0.2438 | -0.265 |
| Economico | 0.321 | -0.02 | -0.265 |
Ciò significa che le coordinate delle colonne vengono scalate per adattarsi molto meglio alle coordinate delle righe, rendendo più facile l’analisi delle tendenze. Poiché abbiamo scalato tutte le coordinate delle colonne con lo stesso fattore costante, abbiamo contratto la dispersione delle coordinate delle colonne sulla mappa, ma non abbiamo apportato alcuna modifica alle loro relatività; continuiamo a utilizzare il prodotto dei punti per misurare la forza delle associazioni. L’unico cambiamento è che quando la prima e la seconda dimensione coprono tutta la varianza dei dati, il residuo indicizzato, invece di essere uguale al prodotto dei punti delle due categorie, è ora uguale al prodotto dei punti scalato delle due categorie, che è il prodotto dei punti scalato da un valore costante del nostro primo valore singolare (d). L’interpretazione del grafico rimane invariata rispetto alla normalizzazione del principio di riga.
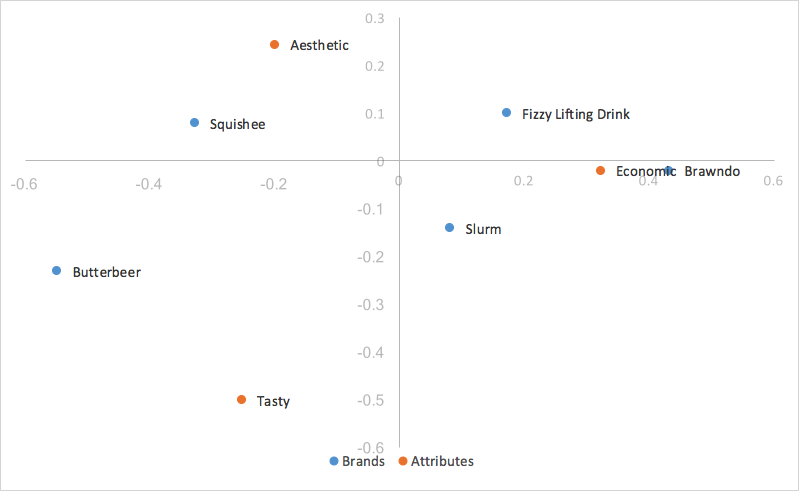
Analisi della corrispondenza principale
Un’ultima forma di analisi delle corrispondenze che citeremo è l’analisi delle corrispondenze principali, nota anche come mappa simmetrica, scala francese o analisi delle corrispondenze canoniche. Invece di moltiplicare solo le righe o le colonne standard per i valori singolari (d) come nell’analisi delle corrispondenze principali riga/colonna, moltiplichiamo entrambe per i valori singolari. Quindi i valori standard delle colonne, moltiplicati per i valori singolari, diventano:
| 1a dimensione | 2a dimensione | 3a dimensione | |
| Gustoso | -0.2544 | -0.215 | 0 |
| Estetica | -0.201 | 0.105 | 0 |
| Economico | 0.321 | -0.01 | 0 |
Mettendo insieme questi valori con quelli delle righe calcolati nell’analisi principale delle righe, otteniamo:
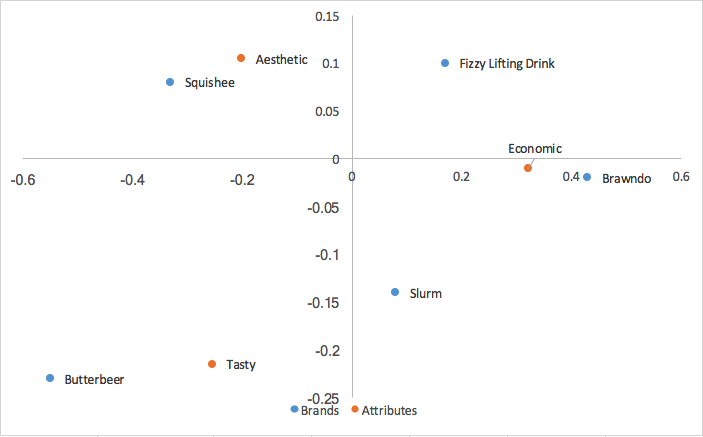
L’analisi delle corrispondenze canoniche calcola le coordinate delle righe e delle colonne in base ai valori singolari. Ciò significa che possiamo interpretare le relazioni tra le nostre coordinate di riga come nell’analisi delle corrispondenze principali di riga (in base alla prossimità), e possiamo interpretare le relazioni tra le nostre coordinate di colonna come nell’analisi delle corrispondenze principali di colonna; possiamo analizzare le relazioni tra i brand e le relazioni tra gli attributi. Si perde anche il cluster riga/colonna al centro della mappa, ottenuto con l’analisi principale riga/colonna. Tuttavia, ciò che perdiamo dall’analisi delle corrispondenze canoniche è un modo di interpretare le relazioni tra i nostri brand e gli attributi, cosa molto utile nella percezione dei marchi.
Confronto AFFIANCATO
Analisi delle corrispondenze standard
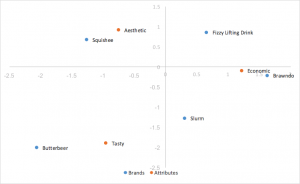
Lo stile di analisi delle corrispondenze più semplice da calcolare, che utilizza i vettori singolari sinistro e destro della SVD divisi per le masse di riga e colonna. Le distanze tra le coordinate di riga e colonna sono esagerate e non c’è un’interpretazione diretta delle relazioni tra le categorie di riga e colonna.
Analisi delle corrispondenze con normalizzazione dei principi di riga
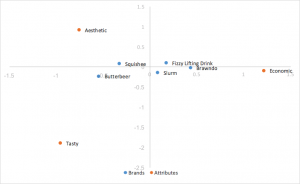
Utilizza le coordinate standard di cui sopra, ma moltiplica le coordinate di riga per i valori singolari per normalizzare. Le relazioni tra le righe (brand) si basano sulla distanza reciproca. Le distanze delle colonne (attributi) sono ancora esagerate. Le relazioni tra righe e colonne possono essere interpretate mediante il prodotto dei punti. I brand tendono a raggrupparsi al centro.
Normalizzazione principale a righe scalari Analisi delle corrispondenze
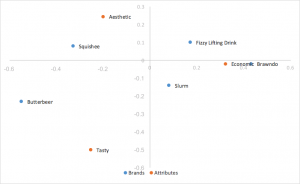
Prende la normalizzazione principale della riga e scala le coordinate della colonna per una costante del primo valore singolare. Stesse interpretazioni della normalizzazione principale delle righe, sostituendo il prodotto dei punti con il prodotto dei punti scalato. Contribuisce a eliminare gli ammassi di file al centro. Questo è lo stile di analisi della corrispondenza che preferiamo.
Analisi delle corrispondenze con normalizzazione principale (simmetrica, mappa francese, canonica)
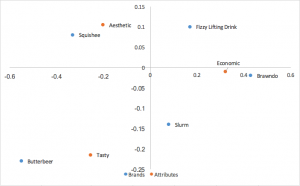
Un’altra forma popolare di analisi delle corrispondenze utilizza le coordinate principali normalizzate sia nelle righe che nelle colonne. Le relazioni tra le righe (brand) possono essere interpretate in base alla distanza reciproca; lo stesso si può dire per le colonne (attributi). Non è possibile trarre alcuna interpretazione per le relazioni tra righe e colonne.
Conclusione
In conclusione, l’analisi delle corrispondenze viene utilizzata per analizzare le relazioni relative tra e all’interno di due gruppi; nel nostro caso, questi gruppi sarebbero i brand e gli attributi.
L’analisi delle corrispondenze elimina l’asimmetria dei risultati derivanti da masse diverse tra i gruppi utilizzando residui indicizzati. Per quanto riguarda le percezioni dei brand per l’analisi delle corrispondenze, utilizziamo la normalizzazione principale di riga (o principale di colonna se i brand sono posizionati sulle colonne), che ci permette di analizzare le relazioni tra i diversi brand in base alla loro vicinanza l’uno all’altro, e ci permette anche di analizzare le relazioni tra brand e attributi in base alla loro distanza dall’origine combinata con l’angolo tra loro e l’origine (il prodotto di punti), con il sacrificio di rappresentare in modo errato la relazione tra gli attributi con distanze esagerate (che non ci interessa, poiché non ci interessano le relazioni tra gli attributi). Utilizziamo la normalizzazione principale scalare riga/colonna per facilitare l’analisi del nostro grafico a costo zero. È bene ricordare che la varianza spiegata dalle etichette degli assi X e Y (la prima e la seconda dimensione) viene sommata per visualizzare la varianza totale catturata nella mappa; quanto più basso è questo numero, tanto maggiore è la varianza non spiegata nei dati e tanto più fuorviante è il grafico.
Un’ultima cosa da ricordare è che l’analisi delle corrispondenze mostra solo le relatività, poiché abbiamo eliminato il fattore massa dei nostri dati; il nostro grafico non ci dirà nulla su quali brand hanno i punteggi più “alti” negli attributi. Una volta compreso come creare e analizzare i grafici, l’analisi delle corrispondenze è uno strumento potente che non tiene conto degli effetti di dimensionamento dei brand per fornire informazioni potenti e facili da interpretare sulle relazioni tra i brand e all’interno di essi e sugli attributi applicabili.