Connettore in entrata per il caricamento di file ad hoc
Suite
Customer Experience
Prodotto
Qualtrics
Cosa puoi trovare in questa pagina
Informazioni sul connettore in entrata per il caricamento di file ad hoc
È possibile utilizzare il connettore in entrata per il caricamento di file ad hoc per caricare i dati dei clienti tramite un upload di file. I lavori di caricamento di file ad hoc sono una tantum e ogni lavoro deve essere pianificato separatamente.
I lavori su file ad hoc consentono di caricare dati nei seguenti formati:
- File di testo delimitati piatti (CSV, TSV, ecc.)
- XLS o XLSX
- JSON
- WebVTT
Impostazione di un lavoro di caricamento di file ad hoc
Consiglio Q: per utilizzare questa funzione è necessaria l’autorizzazione “Manage Jobs”.
Nella scheda Lavori, fare clic su Nuovo lavoro.

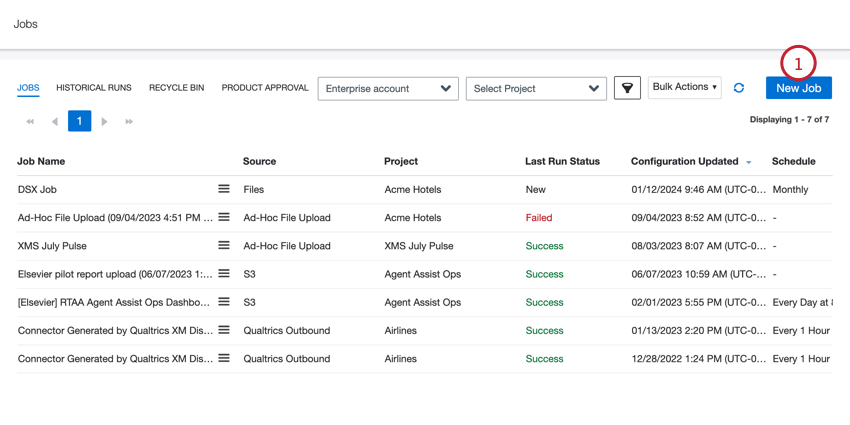
Selezionate Caricamento file ad hoc.


Date un nome al vostro lavoro per poterlo identificare.

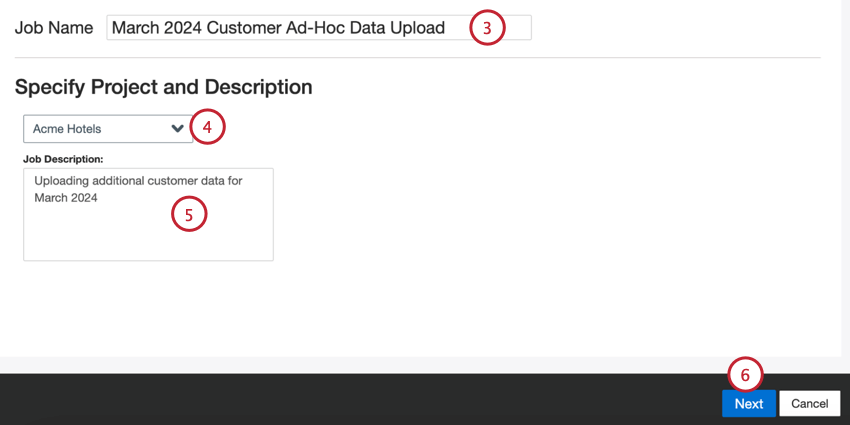
Scegliere il progetto in cui caricare i dati.
Date al vostro lavoro una descrizione, in modo da conoscerne lo scopo.
Fare clic su Successivo.
Scegliere il tipo di file da caricare:
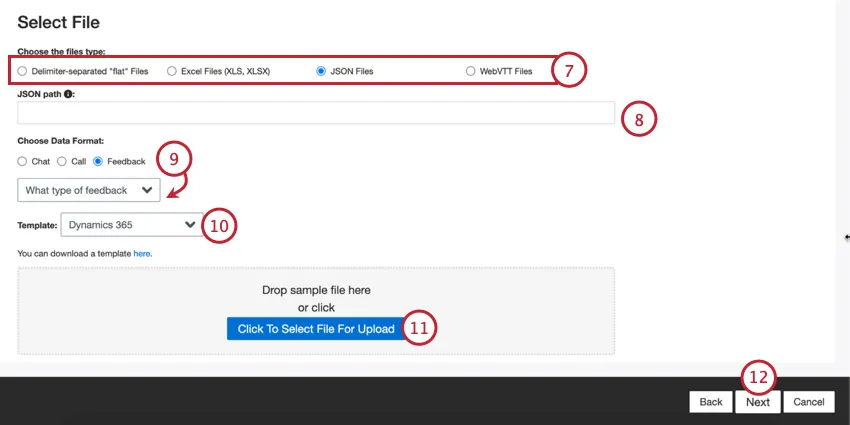
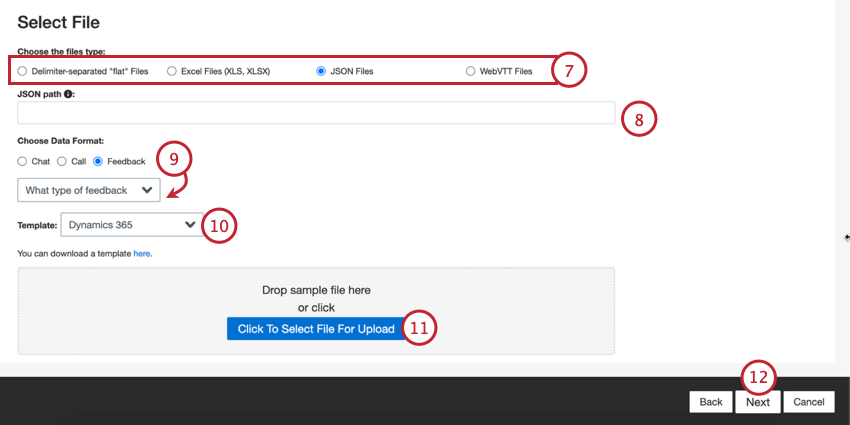
- File “piatti” separati da un delimitatore
- File Excel (XLS, XLSX)
- File JSON
- File WebVTT
A seconda del tipo di file selezionato, compilare le impostazioni aggiuntive del file:
- File piatti separati da delimitatori: Per i file separati da delimitatori, scegliere quanto segue:
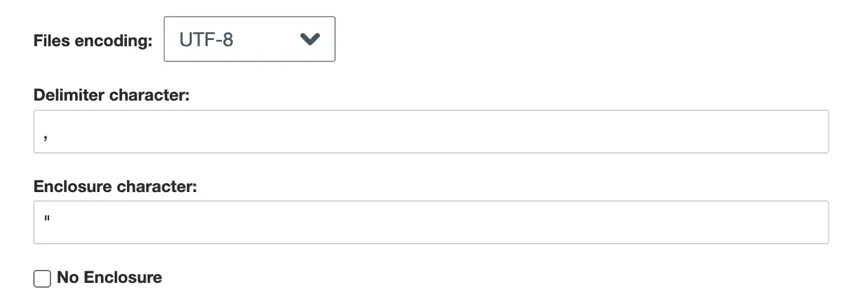
- Codifica del file: Scegliere il sistema di codifica del file (UTF-8, ASCII, ecc.).
- Carattere delimitatore: Inserire il carattere utilizzato per delimitare le voci dei dati. Per impostazione predefinita, si tratta di una virgola per i file CSV.
- Carattere di chiusura: Inserire il carattere che racchiude l’inserimento dei dati. Lasciare questo campo vuoto se è stato selezionato Nessun involucro.
- Nessun allegato: Attivare questa opzione se il file non contiene caratteri di allegato.
- JSON: inserire il percorso JSON che contiene i dati del documento che si desidera caricare su XM Discover. Lasciare questo campo vuoto se i documenti sono a livello di radice.

- Passare al punto avanti per i file Excel e WebVTT.

Scegliere il tipo di dati da importare:
- Chat: Interazioni digitali con più linee di dialogo tra 2 o più partecipanti.
- Chiamata: Trascrizioni di chiamate con più linee di dialogo tra 2 o più partecipanti.
- Feedback: Documenti presentati come file singole o oggetti “piatti”. Consiglio Q: se si è selezionato “Feedback”, apparirà un secondo menu per scegliere il tipo di dati di interazione inclusi nel feedback. Le opzioni sono: chiamata, chat, e-mail, recensione, social e sondaggio.

Consiglio Q: a seconda del tipo di file, alcuni tipi di dati non sono compatibili. Ad esempio, i file WebVTT possono essere utilizzati solo per caricare le trascrizioni delle chiamate.
Se necessario, è possibile selezionare un file modello da scaricare. Fare clic sul link qui per scaricare il modello selezionato. Utilizzare questo file per aggiungere i dati che si desidera importare in XM Discover. Per informazioni specifiche sulla formattazione di ciascun file e tipo di dati, consultare la pagina di supporto XM Discover Data Formats.
Fare clic sul pulsante Clicca qui per selezionare il file da caricare e scegliere il file sul computer. I dati vengono visualizzati in anteprima nella parte inferiore della pagina.
Consiglio Q: vedere Errori del file di Campione se si ha bisogno di aiuto per la risoluzione dei problemi del file di caricamento.
Fare clic su Successivo.
Se necessario, modificare le mappature dei dati. Per informazioni dettagliate sulla mappatura dei campi in XM Discover, consultare la pagina di supporto Data Mapping. La sezione Mappatura dei dati predefiniti contiene informazioni sui campi specifici di questo connettore, mentre la sezione Campi conversazionali spiega come mappare i dati per i dati conversazionali.

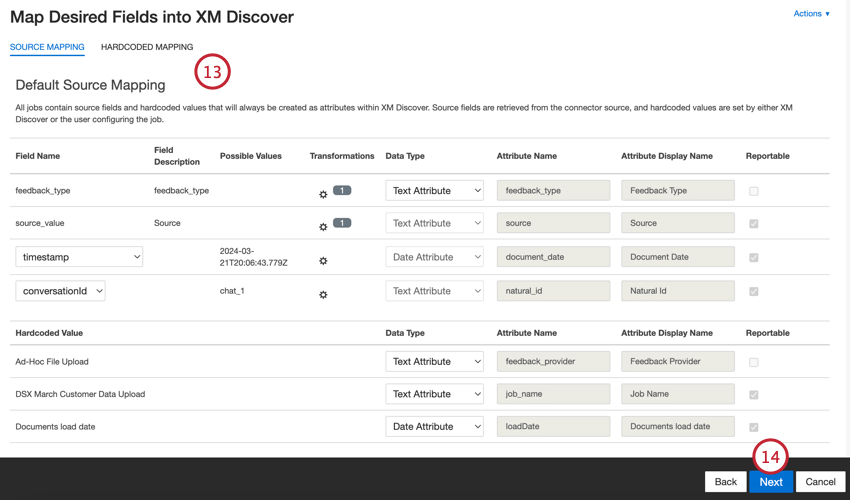
Fare clic su Successivo.
Se lo si desidera, è possibile aggiungere regole di sostituzione e di eliminazione dei dati per nascondere i dati sensibili o sostituire automaticamente determinate parole e frasi nei feedback e nelle interazioni dei clienti. Per ulteriori informazioni, consultare la pagina di supporto Data Substitution and Redaction.

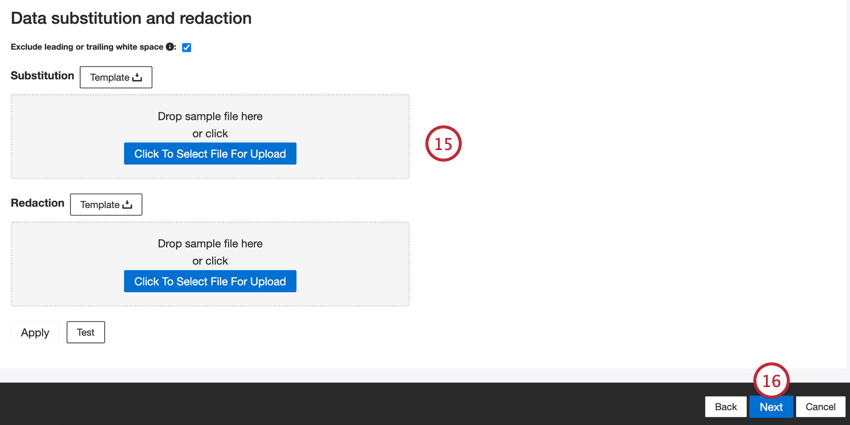
Fare clic su Successivo.
Se si desidera, è possibile aggiungere un filtro al connettore per filtrare i dati in entrata e limitare i dati importati.
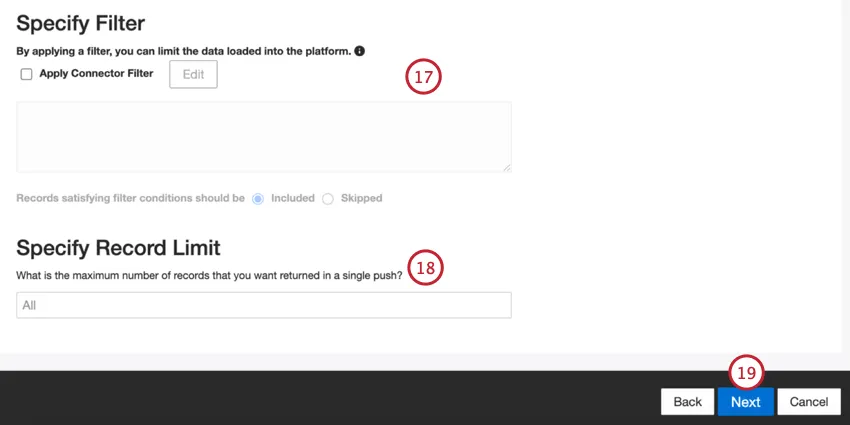
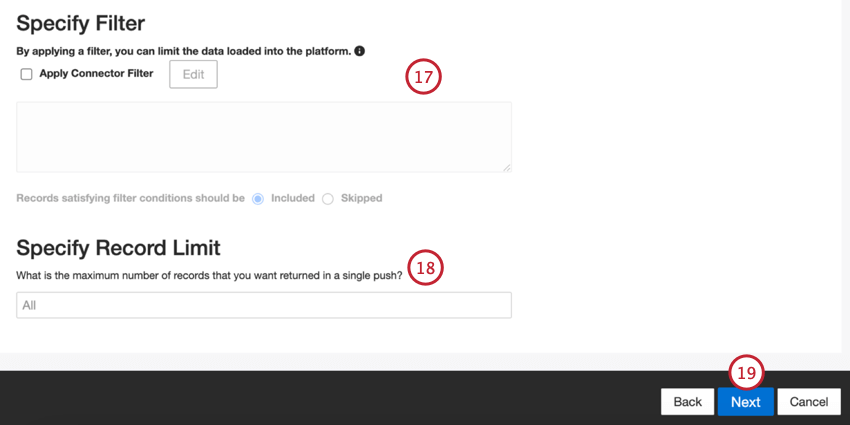
È anche possibile limitare il numero di record importati in un singolo lavoro inserendo un numero nella casella Specifica limite record. Inserire “Tutti” se si desidera importare tutti i record.
Consiglio Q: Per i dati delle conversazioni, il limite si applica in base alle conversazioni anziché alle righe.
Fare clic su Successivo.
Scegliete quando volete essere avvisati. Per ulteriori informazioni, vedere Notifiche di lavoro.

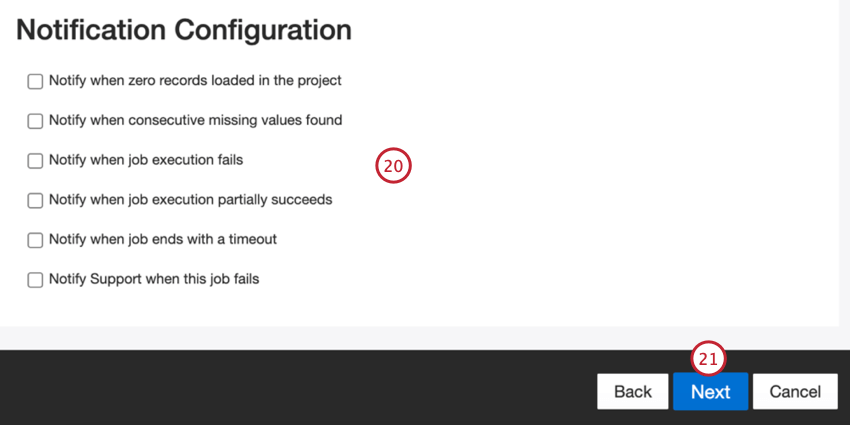
Fare clic su Successivo.
Scegliere come gestire i documenti duplicati. Per ulteriori informazioni, vedere Gestione dei duplicati.

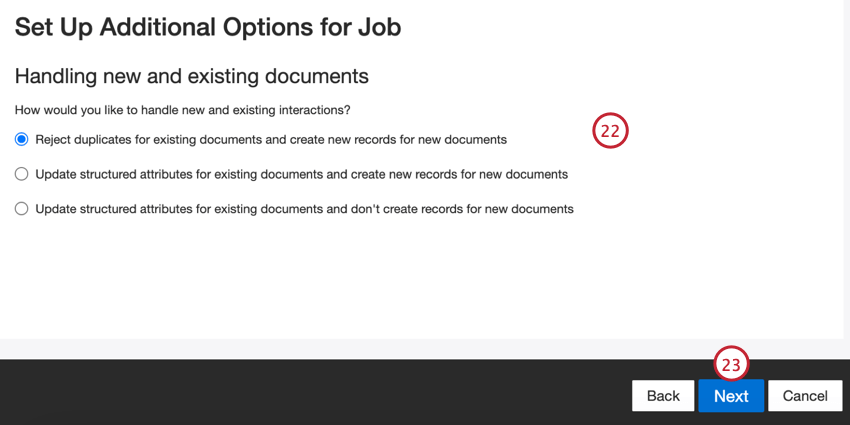
Fare clic su Successivo.
Valutate la vostra configurazione. Se è necessario modificare un’impostazione specifica, fare clic sul pulsante Modifica per accedere alla fase di impostazione del connettore.
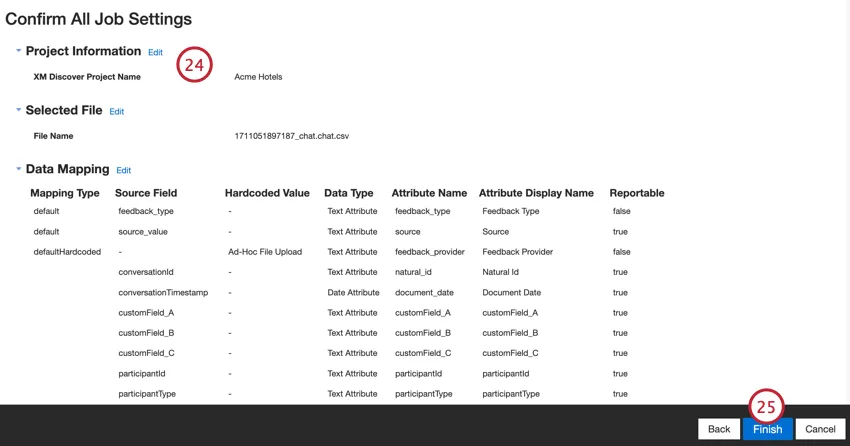
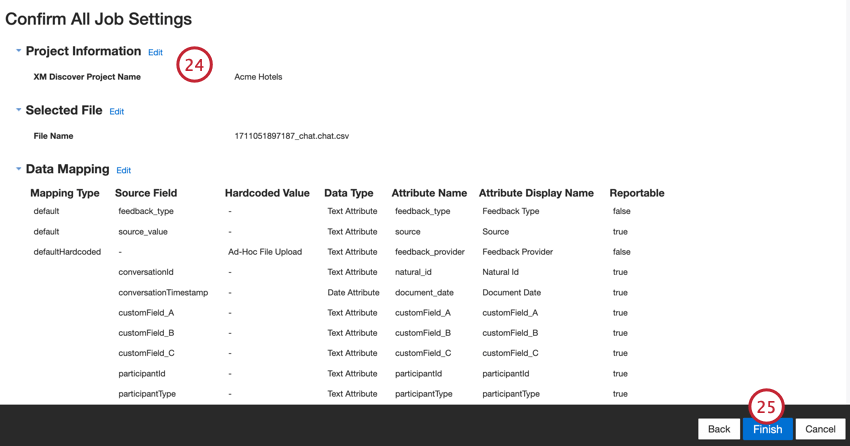
Fare clic su Fine per salvare il lavoro.
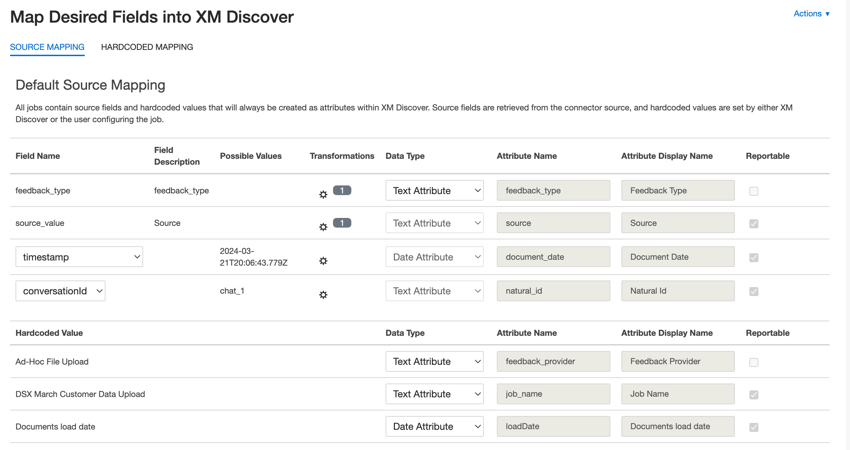
Mappatura dei dati predefinita
Questa sezione contiene informazioni sui campi predefiniti per i lavori in entrata di caricamento file ad hoc.
{kind=link}
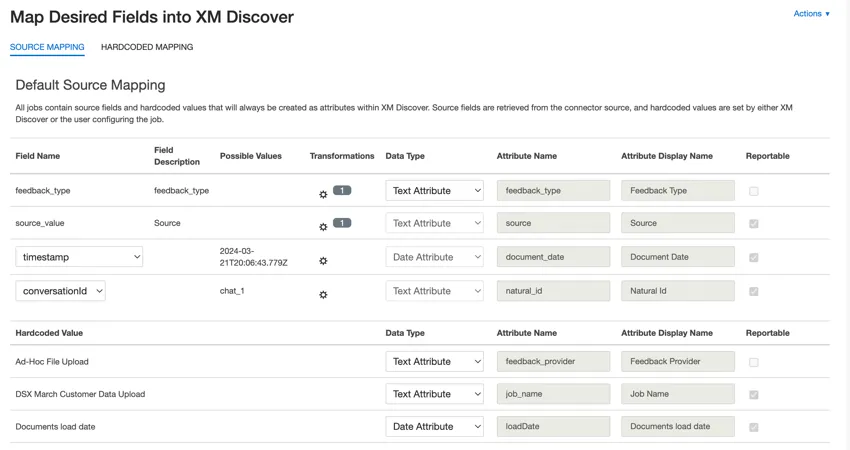
- tipo_di_feedback: Identifica i dati in base al loro tipo. Questo è utile per i rapporti quando il progetto contiene diversi tipi di dati (ad esempio, sondaggi e feedback sui social media). Per impostazione predefinita, il valore di questo attributo è impostato su “call” per le trascrizioni delle chiamate, “chat” per le interazioni digitali o “feedback” per i feedback individuali. Utilizzare le trasformazioni personalizzate per impostare un valore personalizzato, definire un’espressione o mapparlo su un altro campo.
- valore_fonte: Identifica i dati ottenuti da un’origine specifica. Può essere qualsiasi cosa che descriva l’origine dei dati, come il nome di un sondaggio o di una campagna di marketing mobile. Per impostazione predefinita, il valore di questo attributo è impostato su “Caricamento file ad hoc” Utilizzare le trasformazioni personalizzate per impostare un valore personalizzato, definire un’espressione o mapparlo su un altro campo.
- data_documento: il campo data primario associato a un documento. Questa data viene utilizzata nei rapporti di XM Discover, nelle tendenze, negli avvisi e così via. Per la data del documento è possibile utilizzare qualsiasi campo data del dataset. È anche possibile impostare una data specifica per il documento.
- natural_id: Identificatore univoco di un documento. Si raccomanda vivamente di avere un ID unico per ogni documento per elaborare correttamente i duplicati. Per ID naturale, è possibile selezionare qualsiasi campo di testo o numerico dai dati. In alternativa, è possibile generare automaticamente gli ID aggiungendo un campo personalizzato.
- feedback_provider: Identifica i dati ottenuti da un fornitore specifico. Per il caricamento di file, il valore di questo attributo è impostato su “Caricamento file ad hoc” e non può essere modificato.
- job_name: identifica i dati in base al nome del lavoro utilizzato per caricarli. È possibile modificare il valore di questo attributo durante l’impostazione tramite il campo NOME CAMPO, visualizzato nella parte superiore di ogni pagina durante l’impostazione.
- loadDate: indica quando un documento è stato caricato in XM Discover. Questo campo viene impostato automaticamente e non può essere modificato.
Consiglio Q: per informazioni sulla mappatura dei campi dati delle conversazioni, vedere Mappatura dei campi dati delle conversazioni.
Molte delle pagine di questo sito sono state tradotte dall'originale in inglese mediante traduzione automatica. Sebbene in Qualtrics abbiamo profuso il massimo impegno per avere le migliori traduzioni automatiche possibili, queste non sono mai perfette. Il testo originale inglese è considerato la versione ufficiale, e qualsiasi discrepanza tra questo e le traduzioni automatiche non è legalmente vincolante.
È fantastico! Grazie per il tuo feedback!
Grazie per il tuo feedback!