-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Connecteur de téléchargement ad hoc de fichiers entrants
À propos du connecteur de téléchargement ad hoc de fichiers entrants
Vous pouvez utiliser le connecteur de téléchargement de fichiers ad hoc pour charger les données des clients via un téléchargement de fichiers. Les tâches de téléchargement de fichiers ad hoc sont ponctuelles et chaque tâche doit être programmée séparément.
Les travaux de fichiers ad hoc vous permettent de télécharger des données dans les formats suivants :
- Fichiers texte délimités à plat (CSV, TSV, etc.)
- XLS ou XLSX
- JSON
- WebVTT
Configuration d’une tâche de téléchargement de fichiers ad hoc
Astuce : L’autorisation “Manage Jobs” est requise pour utiliser cette fonction.
- Dans l’onglet Travaux, cliquez sur Nouveau travail.
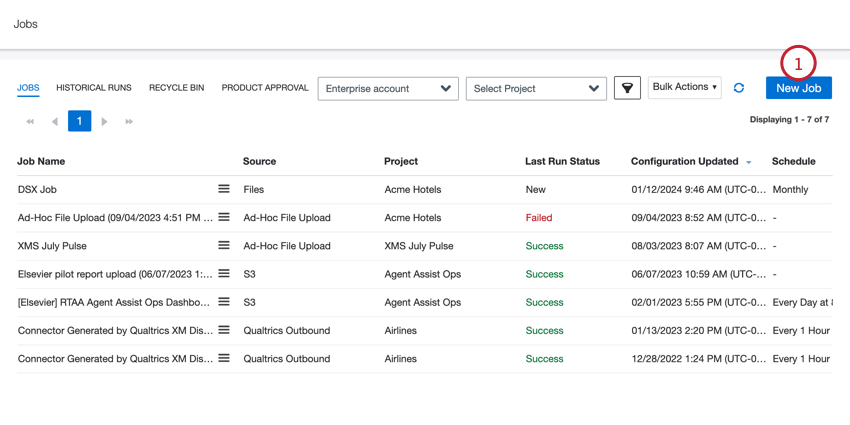
- Sélectionnez Ad-Hoc File Upload.

- Donnez un nom à votre travail afin de pouvoir l’identifier.
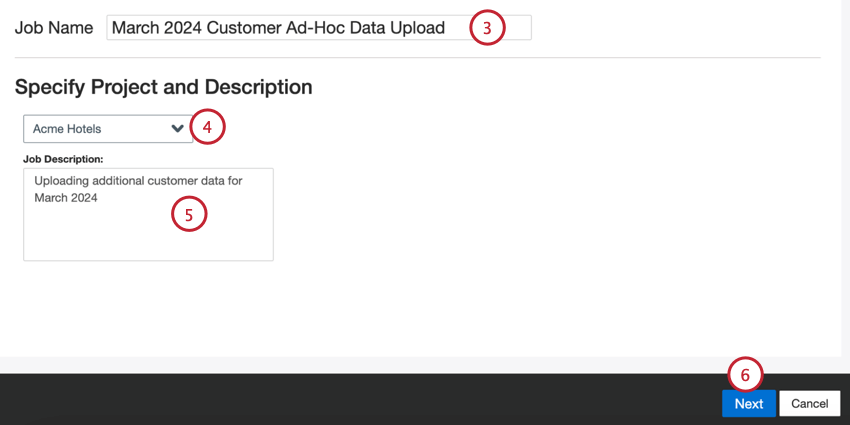
- Choisissez le projet dans lequel vous souhaitez charger les données.
- Donnez une description de votre poste afin d’en connaître l’objectif.
- Cliquez sur Suivant.
- Choisissez le type de fichier que vous souhaitez télécharger :
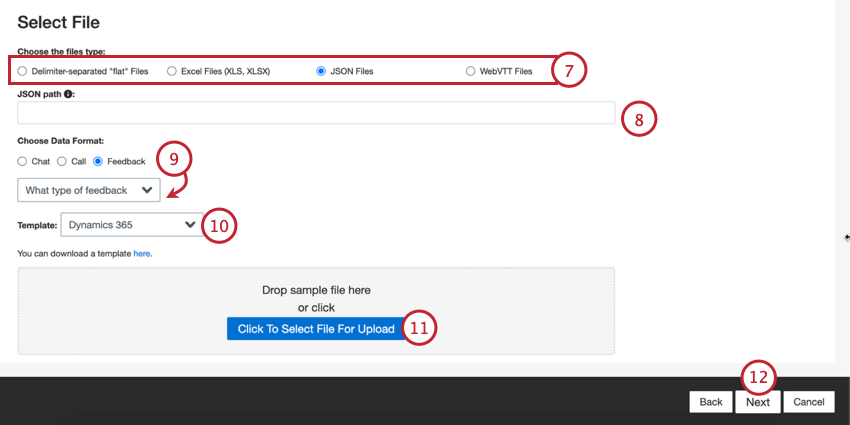
- Fichiers “plats” séparés par des délimiteurs
- Fichiers Excel (XLS, XLSX)
- Fichiers JSON
- Fichiers WebVTT
- En fonction du type de fichier sélectionné, remplissez les paramètres supplémentaires du fichier :
- Fichiers plats séparés par des délimiteurs: Pour les fichiers séparés par des délimiteurs, choisissez l’option suivante :
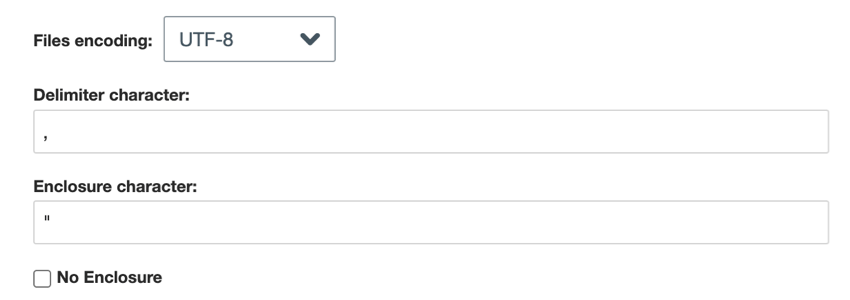
- Encodage du fichier: Choisissez le système d’encodage du fichier (UTF-8, ASCII, etc.).
- Caractère de délimitation: Saisissez le caractère utilisé pour délimiter les entrées de données. Par défaut, il s’agit d’une virgule pour les fichiers CSV.
- Caractère de clôture: Saisissez le caractère qui entoure la saisie des données. Laissez ce champ vide si l’option Pas d’enceinte est sélectionnée.
- Pas de clôture: activez cette option si votre fichier ne contient pas de caractères de clôture.
- JSON: Saisissez le chemin JSON qui contient les données du document que vous souhaitez télécharger vers XM Discover. Laissez ce champ vide si vos documents se trouvent au niveau racine.

- Passez à l’étape suivante pour les fichiers Excel et WebVTT.
- Fichiers plats séparés par des délimiteurs: Pour les fichiers séparés par des délimiteurs, choisissez l’option suivante :
- Choisissez le type de données que vous souhaitez importer :
- Chat: Interactions numériques avec plusieurs lignes de dialogue entre 2 participants ou plus.
- Appel: Transcriptions d’appels comportant plusieurs lignes de dialogue entre 2 participants ou plus.
- Retour d’information: Les documents sont présentés sous forme d’objets à une seule rangée ou “plats”.
Astuce : Si vous avez sélectionné “retour d’information”, un deuxième menu apparaît pour vous permettre de choisir le type de données d’interaction incluses dans le retour d’information. Vos options sont les suivantes : appel, chat, e-mail, évaluateur, réseau social et enquête en revue.
Astuce : Selon le type de fichier, certains types de données ne sont pas compatibles. Par exemple, les fichiers WebVTT ne peuvent être utilisés que pour télécharger des transcriptions d’appels. - Si nécessaire, vous pouvez sélectionner un fichier modèle à télécharger. Cliquez sur le lien suivant pour télécharger le modèle choisi. Utilisez ce fichier pour ajouter les données que vous souhaitez importer dans XM Discover. Consultez la page d’assistance sur les formats de données XM Discover pour obtenir des informations spécifiques sur le formatage de chaque fichier et type de données.
- Cliquez sur le bouton Cliquez ici pour sélectionner le fichier à télécharger et choisissez votre fichier sur votre ordinateur. Vos données apparaîtront sous forme d’aperçu au bas de la page.
Astuce : consultez la rubrique Erreurs dans les échantillons de fichiers si vous avez besoin d’aide pour résoudre les problèmes liés à votre fichier de téléchargement.
- Cliquez sur Suivant.
- Si nécessaire, ajustez vos correspondances de données. Consultez la page d’assistance sur le mappage des données pour obtenir des informations détaillées sur le mappage des champs dans XM Discover. La section Mappage des données par défaut contient des informations sur les champs spécifiques à ce connecteur et la section Champs conversationnels couvre la manière de mapper les données pour les données conversationnelles.
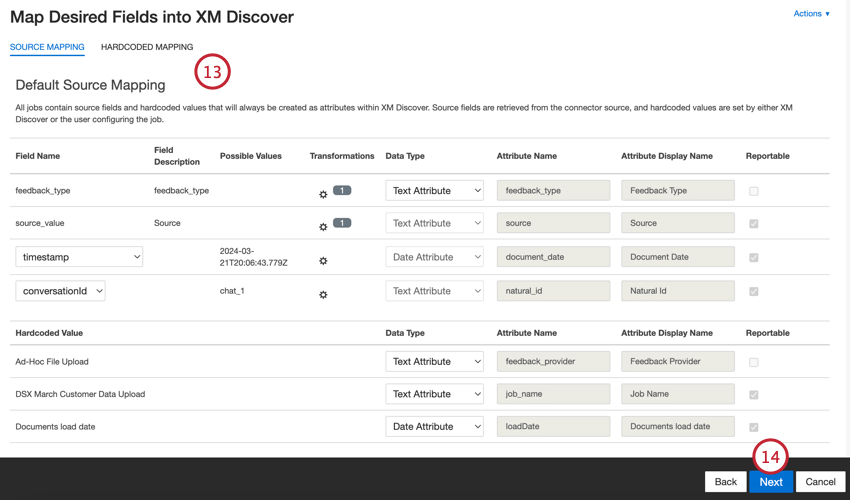
- Cliquez sur Suivant.
- Si vous le souhaitez, vous pouvez ajouter des règles de substitution de données et de rédaction pour masquer les données sensibles ou remplacer automatiquement certains mots et phrases dans les commentaires et interactions des clients. Pour plus d’informations, voir la page d’aide sur la substitution et la rédaction des données.
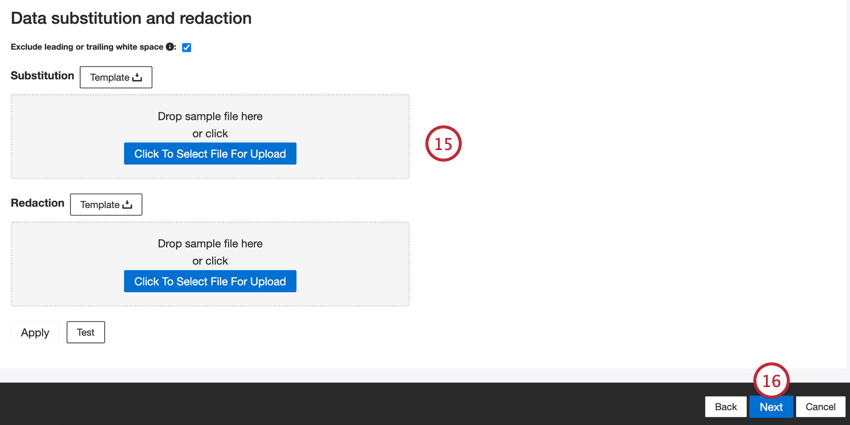
- Cliquez sur Suivant.
- Si vous le souhaitez, vous pouvez ajouter un filtre de connecteur pour filtrer les données entrantes afin de limiter les données importées.
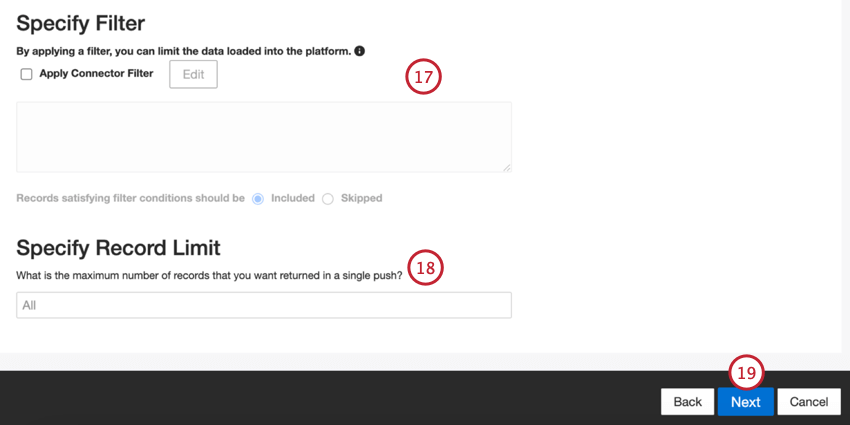
- Vous pouvez également limiter le nombre d’enregistrements importés dans une seule tâche en entrant un nombre dans la case Spécifier la limite d’enregistrements. Saisissez “Tous” si vous souhaitez importer tous les enregistrements.
Astuce : pour les données conversationnelles, la limite est appliquée en fonction des conversations et non des lignes.
- Cliquez sur Suivant.
- Choisissez le moment où vous souhaitez être informé. Pour plus d’informations, voir Notifications d’emploi.
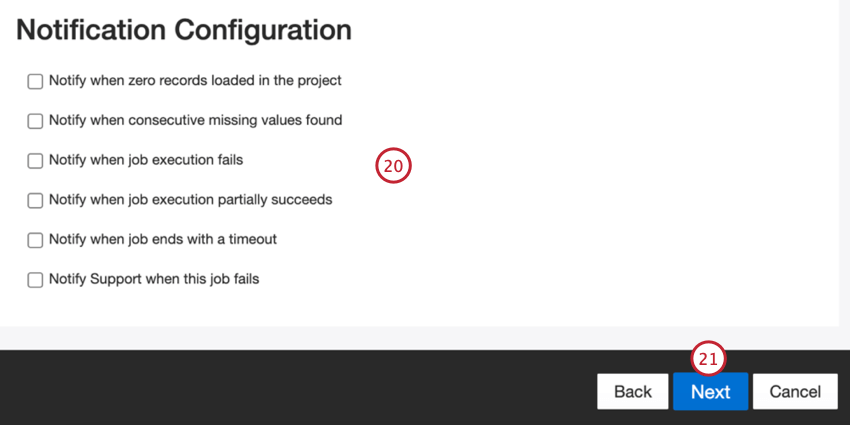
- Cliquez sur Suivant.
- Choisissez le mode de traitement des documents dupliqués. Pour plus d’informations, voir la rubrique Traitement des dupliqués.
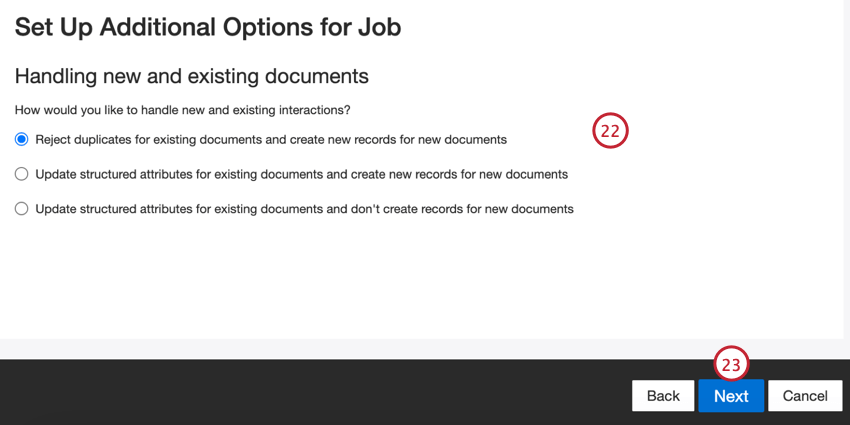
- Cliquez sur Suivant.
- Évaluateur. Si vous devez modifier un paramètre spécifique, cliquez sur le bouton Modifier pour accéder à cette étape de la configuration du connecteur.
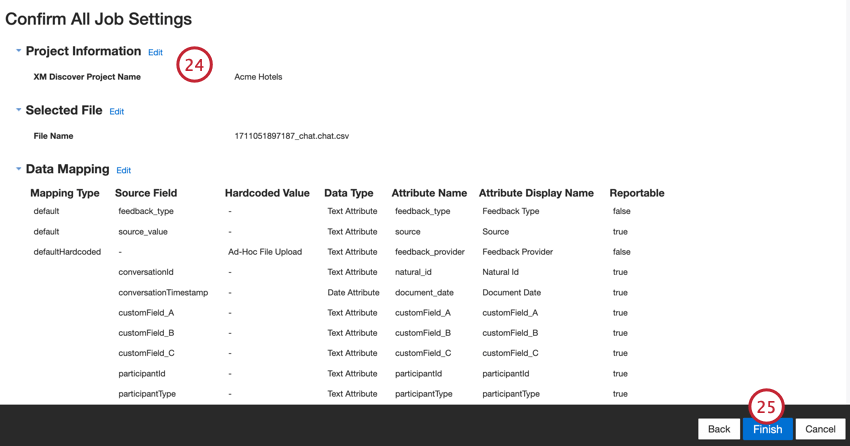
- Cliquez sur Terminer pour enregistrer le travail.
Mappage des données par défaut
Cette section contient des informations sur les champs par défaut des travaux entrants de téléchargement de fichiers ad hoc.
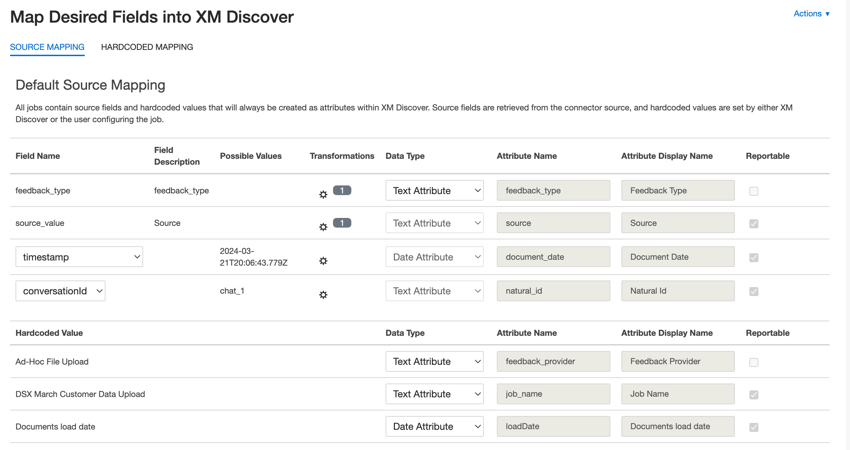
- feedback_type: Identifie les informations en fonction de leur type. Cela est utile pour les rapports lorsque votre projet contient différents types de données (par exemple, des enquêtes et des commentaires sur les médias sociaux). Par défaut, la valeur de cet attribut est définie sur “call” pour les transcriptions d’appels, “chat” pour les interactions numériques ou “feedback” pour les retours d’information individuels. Utilisez les transformations personnalisées pour définir une valeur personnalisée, une expression ou une correspondance avec un autre champ.
- valeur_source: Identifie les données obtenues à partir d’une source spécifique. Il peut s’agir de tout ce qui décrit l’origine des données, comme le nom d’une enquête ou d’une campagne de marketing mobile. Par défaut, la valeur de cet attribut est fixée à “Téléchargement de fichiers ad hoc” Utilisez les transformations personnalisées pour définir une valeur personnalisée, une expression ou une correspondance avec un autre champ.
- document_date: Champ de date primaire associé à un document. Cette date est utilisée dans les rapports XM Discover, les tendances, les alertes, etc. Vous pouvez utiliser n’importe quel champ de date de votre ensemble de données pour la date du document. Vous pouvez également fixer une date spécifique pour le document.
- natural_id: Identifiant unique d’un document. Il est fortement recommandé d’avoir un identifiant unique pour chaque document afin de traiter correctement les dupliqués. Pour Natural ID, vous pouvez sélectionner n’importe quel champ textuel ou numérique de vos données. Vous pouvez également générer automatiquement des identifiants en ajoutant un champ personnalisé.
- feedback_provider: Identifie les données obtenues auprès d’un fournisseur spécifique. Pour les téléchargements de fichiers, la valeur de cet attribut est fixée à “Ad-Hoc File Upload” et ne peut pas être modifiée.
- job_name: identifie les informations en fonction du nom de la tâche utilisée pour les télécharger. Vous pouvez modifier la valeur de cet attribut pendant la configuration via le champ Nom de champ qui s’affiche en haut de chaque page pendant la configuration.
- loadDate: Indique quand un document a été téléchargé dans XM Discover. Ce champ est défini automatiquement et ne peut pas être modifié.
Astuce : Voir Mappage des champs conversationnels pour plus d’informations sur le mappage des données conversationnelles.