Règles relatives aux catégories (Designer)
Contenus de cette page
À propos des règles relatives aux catégories
Les règles de catégorie déterminent quelles phrases doivent être affectées à chaque catégorie. Les règles de catégorie sont généralement des exemples de mots que vous souhaitez inclure ou exclure de la catégorie.
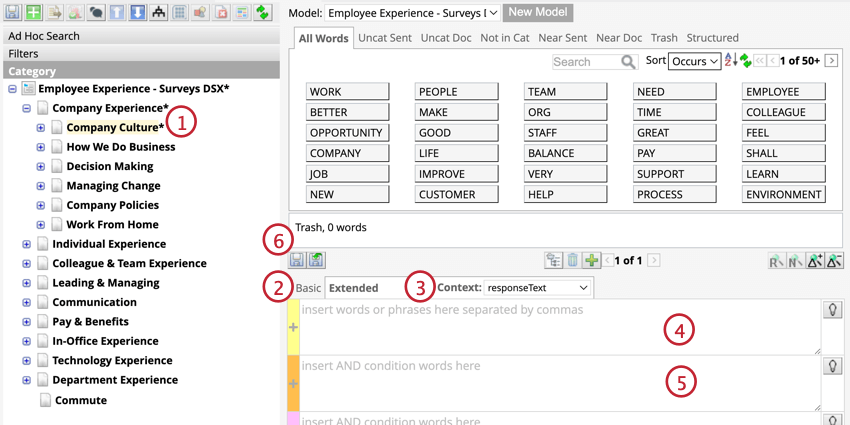
Règles de base
Les règles de base classent les phrases en spécifiant les mots qui doivent être inclus ou exclus dans une phrase.
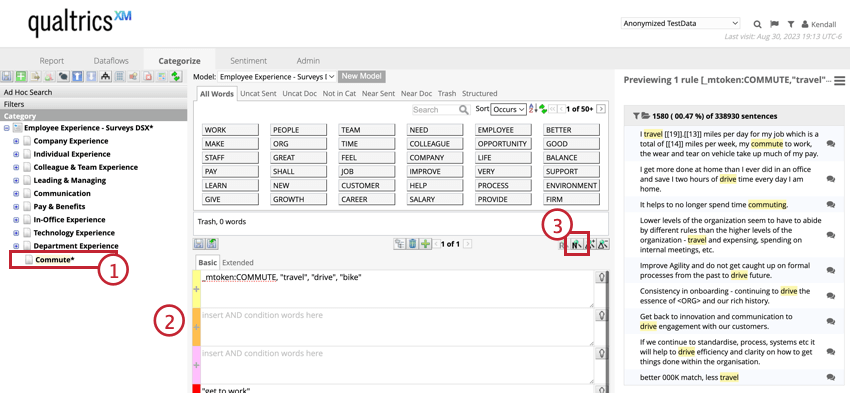
Exemple: Imaginons que vous souhaitiez créer une catégorie “Trajet domicile-travail”. Les règles doivent contenir des mots liés au trajet domicile-travail (comme “commute” ou “travel”) et exclure les mots qui ne sont pas liés au trajet domicile-travail mais qui pourraient apparaître dans la recherche (“drive” ou “get to work”).
Certains caractères sont utilisés pour créer des opérateurs de recherche avancée et affecteront donc les résultats s’ils sont utilisés pour construire une règle. Les caractères suivants peuvent être utilisés pour la création de règles de base :
- Lettres
- Nombres
- Signe de pourcentage ( % )
- Emojis
- Emoticônes
- Symboles monétaires ( $, €, £ )
Astuce: Si vous incluez des mots ou des phrases contenant des contractions lors de l’élaboration d’une règle (par exemple, “couldn’t find” ou “did not fit”), ils doivent être écrits dans la règle sous leur forme complète et entre guillemets (par exemple, “could not” ou “did not”).
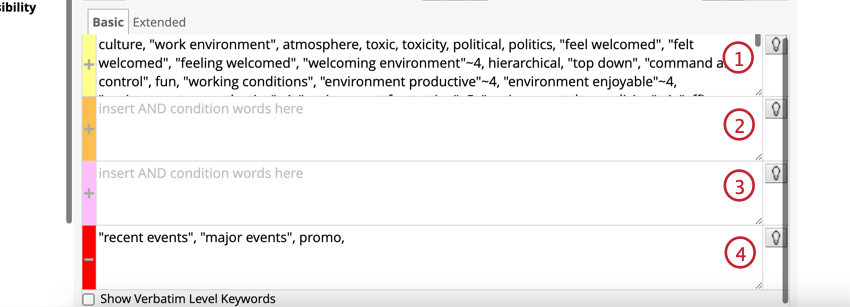
Utilisation des 4 voies de circulation
Il existe 4 voies de règle qui déterminent le lien entre les mots de la règle : OU, ET, ET, PAS.
{kind=link}

Suggestions de voies de circulation
Les suggestions de pistes de règles permettent de créer des catégories plus rapidement en analysant les mots saisis dans une piste de règles et en suggérant des synonymes, des concepts apparentés et des fautes d’orthographe courantes.
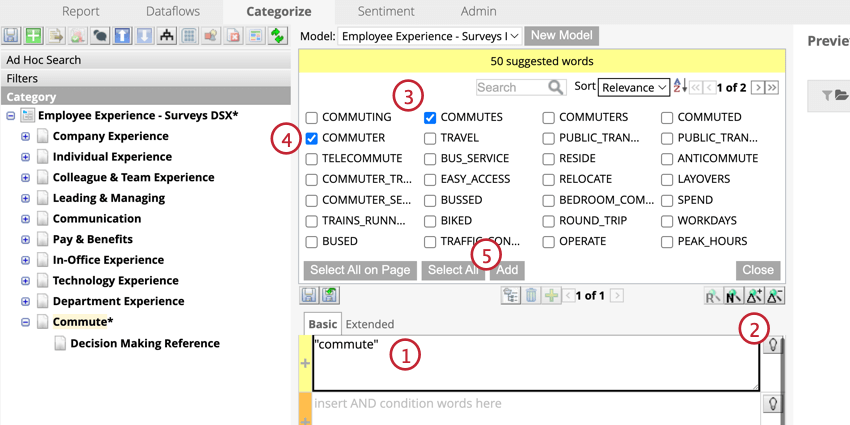
Astuce: Trier les mots suggérés par pertinence ou par nom.
Les suggestions sont compatibles avec les entrées suivantes :
- Termes simples : par exemple “voiture”
- Phrases exactes : par exemple “voiture de sport”
- Caractères génériques à un seul caractère : par exemple, “c?r”
- Caractères génériques à plusieurs caractères : par exemple, “technol*”
- Mots clés: par exemple _mtoken:CAR
Astuce: Les suggestions sont basées sur un vaste ensemble de données externes et ne sont pas spécifiques aux données du projet.
Attention: Les suggestions ne tiennent pas compte des mots et des phrases contenant des opérateurs booléens. Pour plus d’informations, voir Opérateurs de règles avancés.
Règles de contexte
Les règles contextuelles classent les tweets et les commentaires en fonction du contenu de l’article original ou du document parent. Ces règles sont utiles pour catégoriser les données issues de conversations sur les médias sociaux.
{kind=link}

Exemple: Une entreprise publie une annonce pour son nouveau produit et reçoit de nombreux commentaires, mais elle ne souhaite classer que les commentaires de cet article spécifique. Ils créent donc une règle contextuelle (“Nouveau produit”) pour leur nouveau produit. Si une règle de base est ajoutée, Designer extraira les phrases qui mentionnent cette règle (“Fonction du produit”) dans les commentaires de la règle étendue (“Nouveau produit”).
Une règle de contexte est vraie si elle se rapporte à n’importe quelle phrase du document parent et si elle est vraie, toutes les phrases de tous les documents enfants sont classées. Si une règle de contexte est appliquée à un groupe de catégories, elle sera également appliquée à toutes les catégories de ce groupe en tant que requête étendue à chaque règle de base.
Astuce: les requêtes de base et étendues ont un lien ET, de sorte que le texte n’est classé que si les deux conditions sont remplies.
Attention: Des règles étendues peuvent augmenter le temps nécessaire à la catégorisation de votre modèle.
Lors de la création de règles étendues, la fenêtre de prévisualisation ne reflète pas les règles étendues. Au lieu de cela, pour voir les règles étendues appliquées aux phrases ou au sujet, vous devez publier le nœud, le classer et afficher les résultats dans Studio.
RÈGLES CONTEXTUELLES À PARTIR DES DONNÉES DE FACEBOOK
Les données provenant de Facebook sont téléchargées sous la forme d’un message ou d’un commentaire. Seuls les commentaires peuvent contenir un lien vers un article parent, qui peut être utilisé dans les règles contextuelles.
Astuce: les utilisateurs peuvent répondre aux commentaires sur facebook. Dans ce cas, un commentaire peut également servir de parent à un autre commentaire.
RÈGLES CONTEXTUELLES À PARTIR DE DONNÉES TWITTER
Les données provenant de Twitter peuvent être téléchargées sous la forme d’un tweet, d’un retweet ou d’une réponse. Seules les réponses contiennent un lien vers un tweet parent, qui peut être utilisé dans les règles contextuelles. Les réponses à un retweet auront pour parents le tweet original.
Astuce: les utilisateurs peuvent répondre aux commentaires sur Twitter. Dans ce cas, un commentaire peut également servir de parent à un autre commentaire.
RÈGLES CONTEXTUELLES À PARTIR DE DONNÉES DE FICHIERS
Les fichiers téléchargés peuvent avoir une hiérarchie parent-enfant à condition qu’une colonne soit associée à l’attribut systèmeParent Natural ID. Il doit correspondre à l’identifiant naturel d’un document parent.
Règles spécifiques au Verbatim
Une règle spécifique au verbatim classe les phrases en fonction des termes qui apparaissent dans le verbatim plutôt que dans la phrase. Ces règles sont utiles lorsque l’on travaille avec des données de médias sociaux, où les limites des phrases et le style peuvent varier. Pour plus d’informations, voir Règles spécifiques au Verbatim.
Opérateurs de règles avancés
Des caractères spéciaux peuvent être utilisés pour élaborer des règles plus avancées.
Exemple : Vous pouvez rechercher le terme “décor”. Si certaines réponses utilisent la marque d’accentuation, d’autres l’omettent. Pour inclure les deux options, utilisez un caractère de remplacement unique : “d?cor”
| Caractère | Utiliser |
|---|---|
| ? | Recherche de caractères génériques à un seul caractère.
|
| * | Recherche de caractères génériques multiples.
|
| Opérateurs booléens : AND, OR, NOT | Recherche de caractères génériques multiples.
|
Attention: Les requêtes commençant par des caractères génériques peuvent allonger le temps de chargement de la classification.
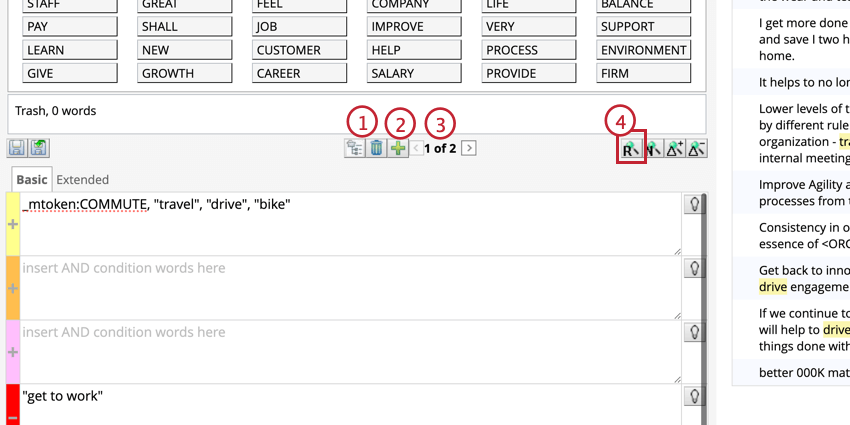
Appliquer plusieurs règles par catégorie
Vous pouvez appliquer plusieurs règles par catégorie. Lorsque plusieurs règles sont spécifiées, leurs requêtes ont toujours un lien OR, ce qui signifie que les phrases sont classées si elles correspondent à au moins une des règles.
{kind=link}

Référencement des catégories dans les règles
Lorsque vous faites référence à une catégorie, vous pouvez réutiliser les règles d’une catégorie dans une autre catégorie. Le référencement s’applique à tous les modèles de catégories, ce qui permet de partager des règles entre les différents modèles d’un projet. Si vous apportez des modifications à la catégorie référencée, vous devez réexécuter la classification de toutes les catégories qui la référencent pour appliquer ces informations.
Attention: Une règle peut contenir jusqu’à 30 références à des catégories. Une chaîne de références de catégories peut avoir jusqu’à deux liens, par exemple si la catégorie A renvoie à la catégorie B qui renvoie à la catégorie C.
Astuce: une catégorie ne peut pas faire référence à elle-même ou à ses catégories parents ou enfants.
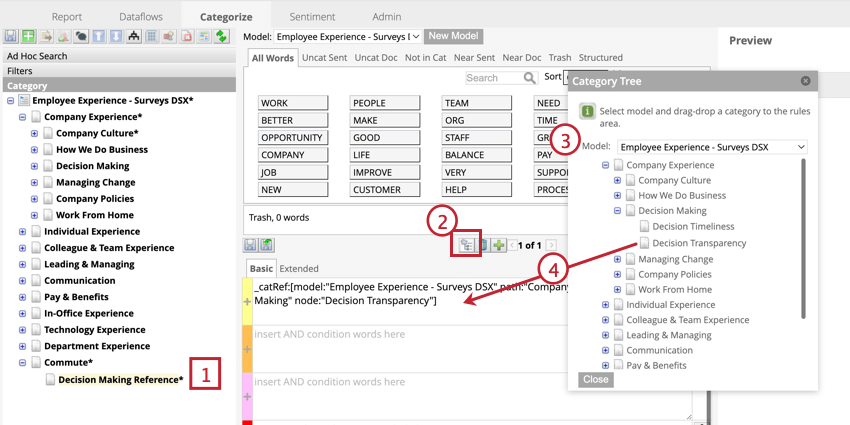
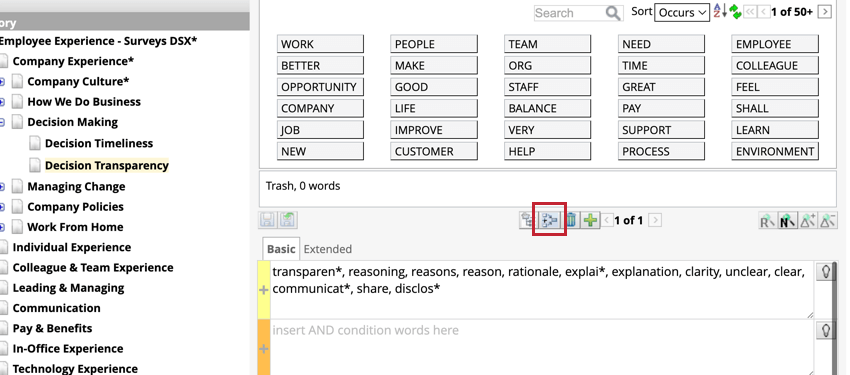
Les références aux catégories ont la syntaxe “catRef” et comprennent le modèle de catégorie et le chemin d’accès à la catégorie.
_catRef :[model : "Model Name" path : "Parent Category" node : "CHILD CATEGORY"] Une fois que vous avez ajouté une référence à une catégorie, vous pouvez cliquer sur le bouton “Nœuds de catégorie référents” au-dessus des pistes de règles de la catégorie référencée pour afficher toutes les références à ce nœud.
{kind=link}
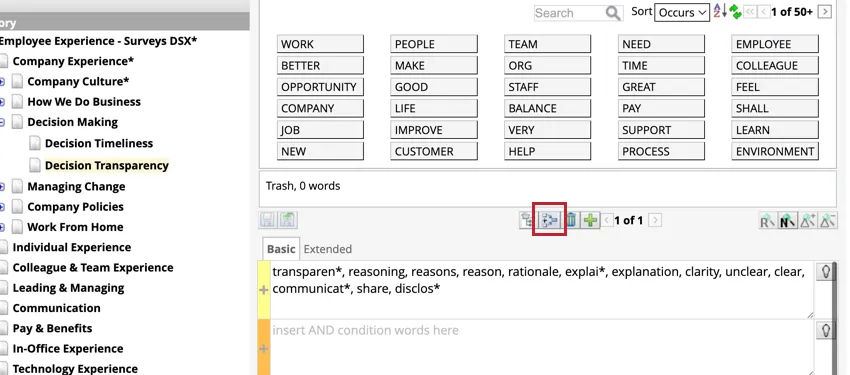
Attention: Vous ne pouvez pas supprimer une catégorie qui a été référencée. Toutes les références doivent être supprimées avant qu’une catégorie puisse être supprimée.
Création et modification de règles avec Smart Query
Smart Query utilise l’intelligence artificielle (IA) pour générer des règles basées sur votre cas d’utilisation. Cela peut être utile pour construire et développer des modèles de catégories plus complexes.
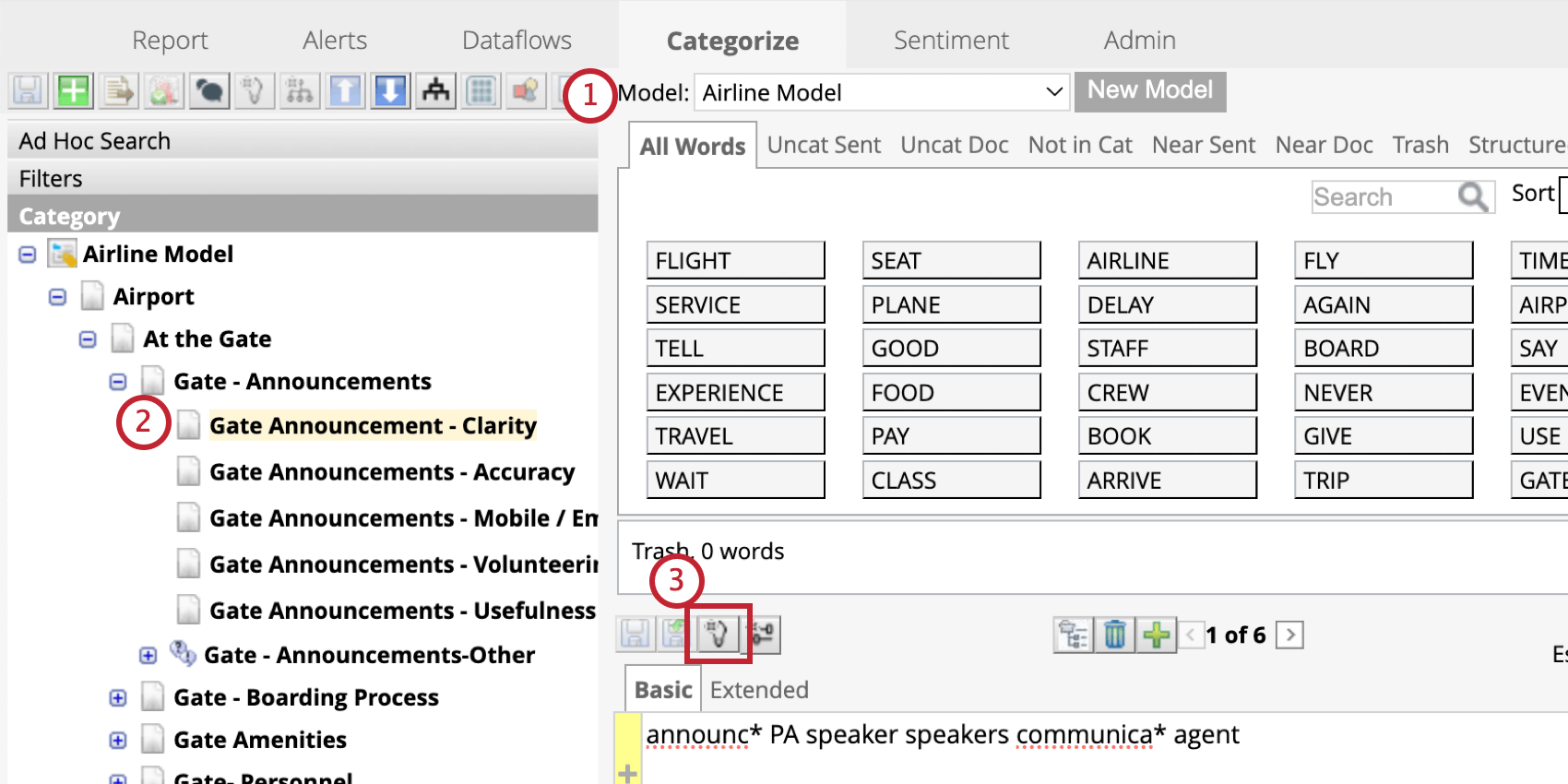
Astuce: Vous pouvez utiliser des requêtes intelligentes pour créer des règles pour les catégories vierges également. Pour plus d’informations sur la création de nouvelles catégories, voir Ajouter des catégories.
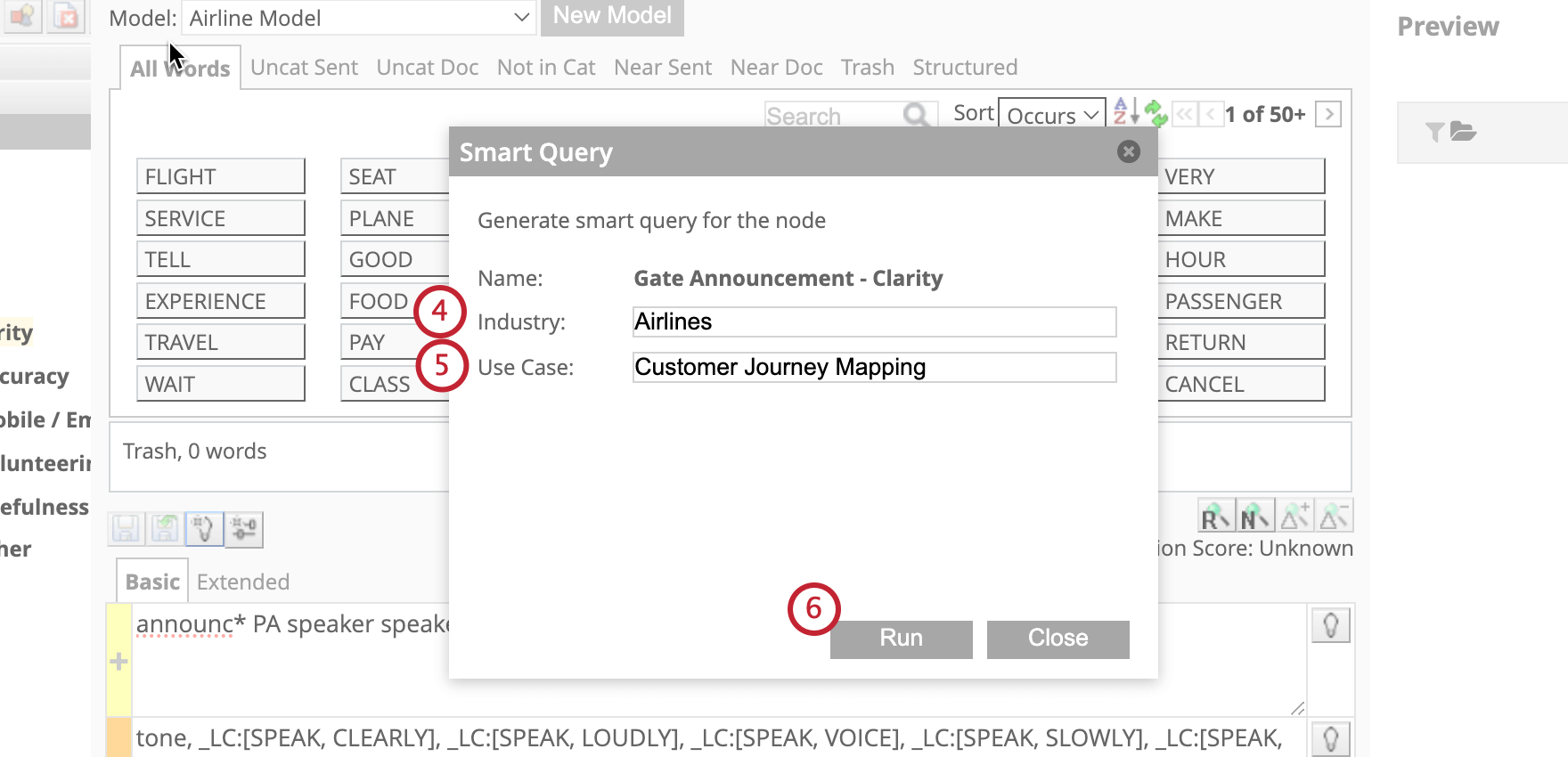
Bonnes pratiques pour la saisie des cas d’utilisation
Le cas d’utilisation est un champ de texte ouvert dans lequel vous pouvez fournir des instructions sur la manière dont Smart Query construit votre règle. Voici quelques bonnes pratiques pour créer votre cas d’utilisation :
- Identifier les rôles et les perspectives clés: Fournir un contexte sur vous-même en tant que demandeur et sur votre rôle.
- Définir les domaines clés du modèle : Décrire ce que le modèle fera, au-delà de son titre.
- Inclure les résultats souhaités: Décrivez ce que vous souhaitez obtenir avec ce cas d’utilisation.
- Clarifier les données et verbatim les sources : Précisez les données utilisées dans votre analyse, ainsi que la nature et/ou le fournisseur de ces données.
- Préciser les points de contact importants: Indiquer les zones critiques où des points de contact peuvent avoir lieu. Vous pouvez également noter, si la liste n’est pas exhaustive, que d’autres points de contact doivent être pris en compte.
- Trouver un équilibre entre le détail et la couverture : Veillez à ce que votre contribution permette d’établir des règles suffisamment détaillées, mais aussi suffisamment larges pour couvrir différents scénarios. Vous pouvez également préciser le niveau de détail et/ou le nombre de voies de règlement que vous souhaitez utiliser.
Exemple: Voici un exemple de cas d’utilisation utilisant les meilleures pratiques listées ci-dessus :
“I am a [role] querying [data/verbatim source] for [company name]. Ce modèle est axé sur [domaines clés du modèle]. Je vise à [résultat souhaité]. Envisager l’inclusion de requêtes liées à [points de contact importants]-cette liste n’est pas exhaustive et d’autres requêtes pertinentes doivent être incluses. Créez des règles qui tiennent compte des différentes expressions du langage [de la source de données] sans être trop restrictives ; toutes les voies d’inclusion ne doivent pas être utilisées.”
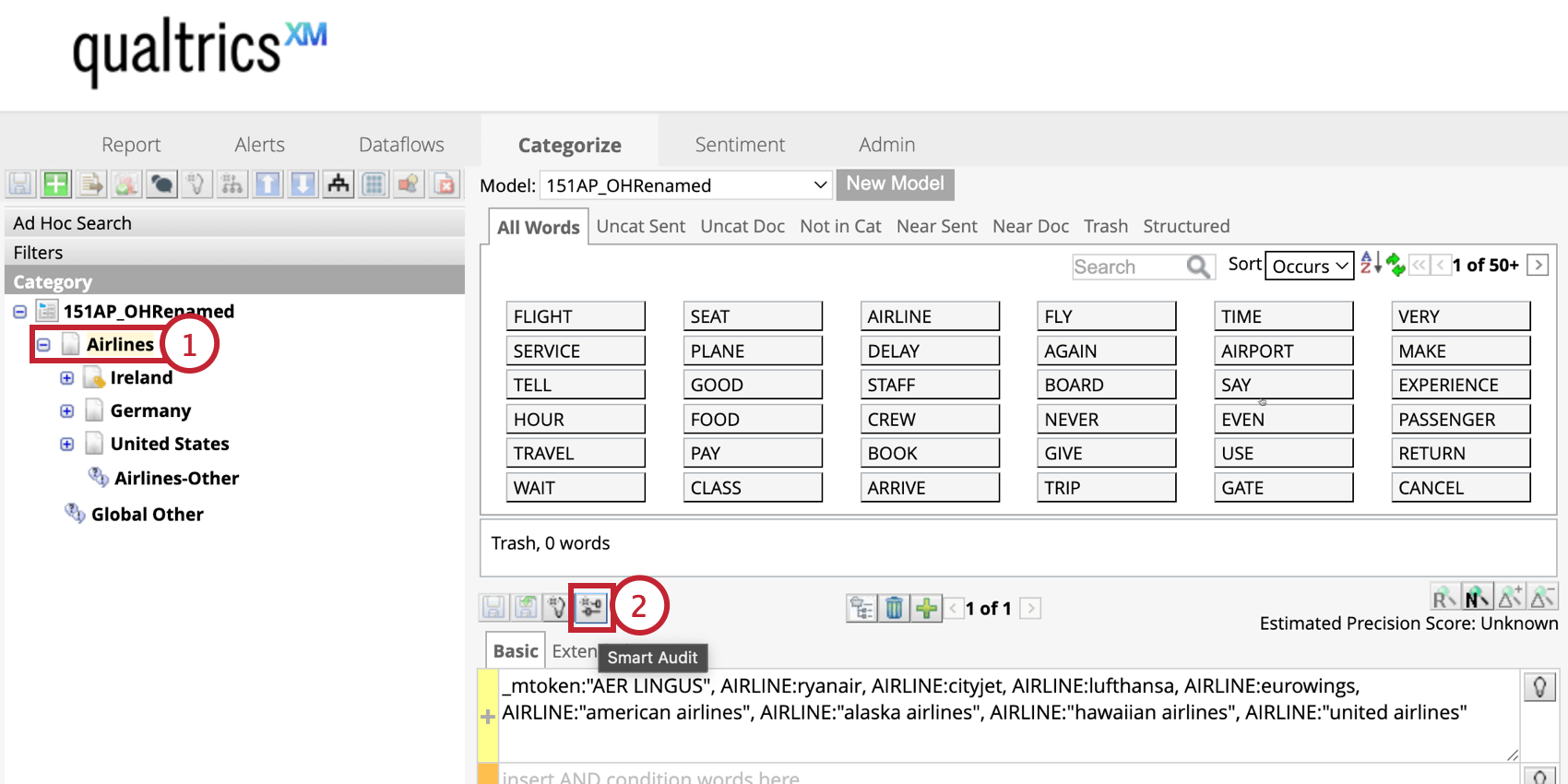
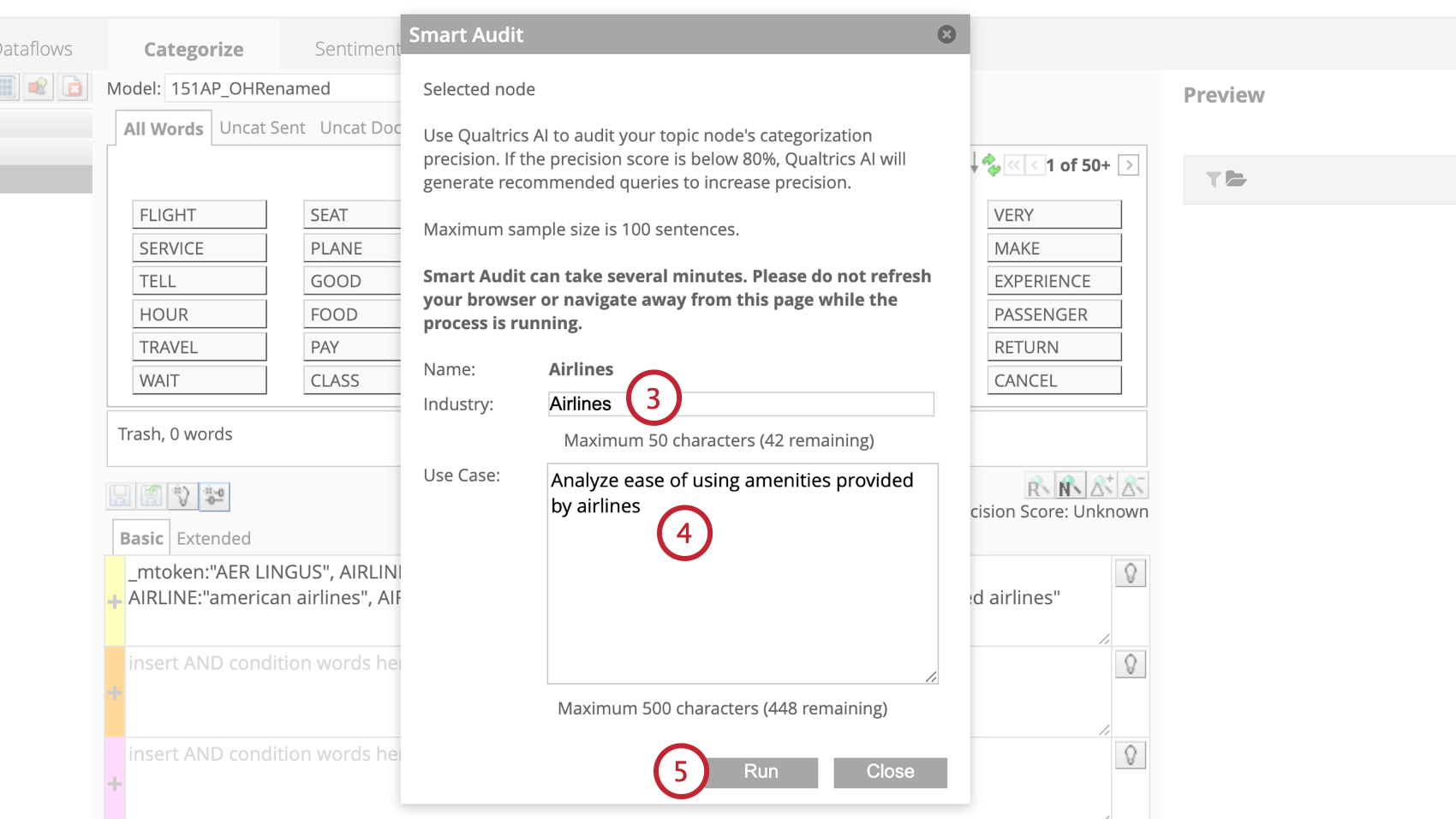
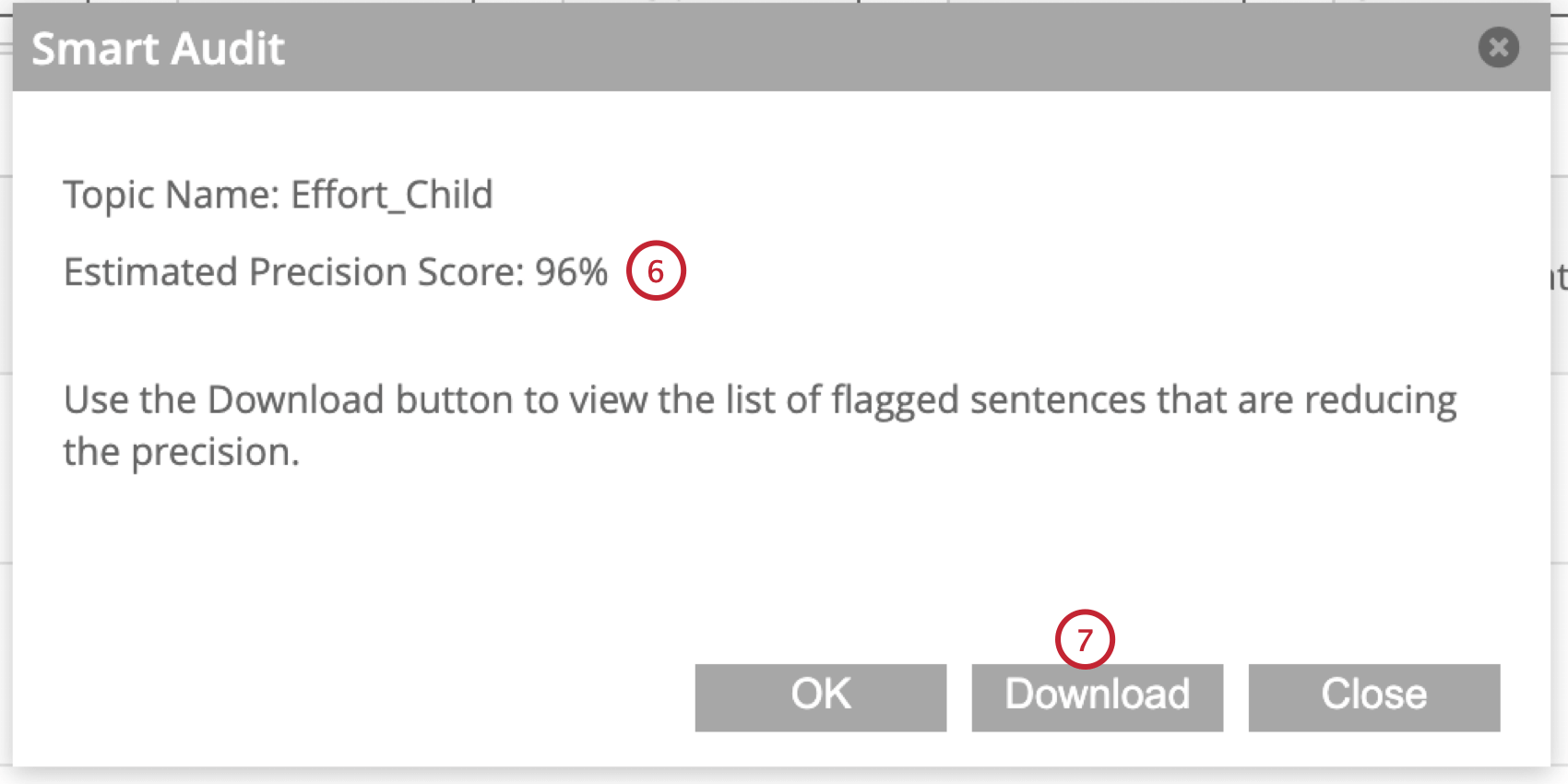
Audit intelligent
Smart audit utilise l’intelligence artificielle générative (IA) pour améliorer vos requêtes thématiques dans XM Discover. Elle analyse vos phrases étiquetées avec un sujet, générant une notation de précision pour la requête, et identifiant les phrases qui devraient être supprimées de votre modèle.
Astuce : l’audit intelligent peut être activé ou désactivé par un administrateur de compte.
Meilleures pratiques
- Utilisez la recherche ad hoc pour explorer les données et expérimenter des règles sans modifier votre modèle de catégorie.
- Remplissez les nœuds avec des règles de base ou réutilisez les règles des catégories existantes.
- Utiliser la détection des thèmes pour affiner les résultats.
- Filtrez vos données sur la base d’attributs structurés et d’attributs du système.
- Utilisez le Surligneur de Source pour prévisualiser une phrase et voir dans quelles catégories elle a été classée.
C'est génial! Merci pour votre avis!
Merci pour votre avis!