Clustering de la différence maximum
Contenus de cette page
À propos de la Différence maximum Cluster
Au sein des populations de répondants aux enquêtes se trouvent des groupes de personnes partageant les mêmes idées. Ces groupes, ou “clusters”, peuvent être déterminés en fonction de la similitude des fonctions préférées de chaque personne interrogée. En regroupant chaque répondant sur la base de son utilité individuelle pour chaque attribut, nous pouvons déterminer les sous-populations et les données démographiques qui les composent.
Astuce : Cette fonction est extrêmement utile pour définir des segments.
Préparation d’une enquête pour le clustering
Avant de pouvoir utiliser le clustering de MaxDiff, vous devez vous assurer que l’Enquête de votre Projets MaxDiff pose les bonnes questions. Cela signifie que vous devez configurer certaines fonctions avant de collecter des données.
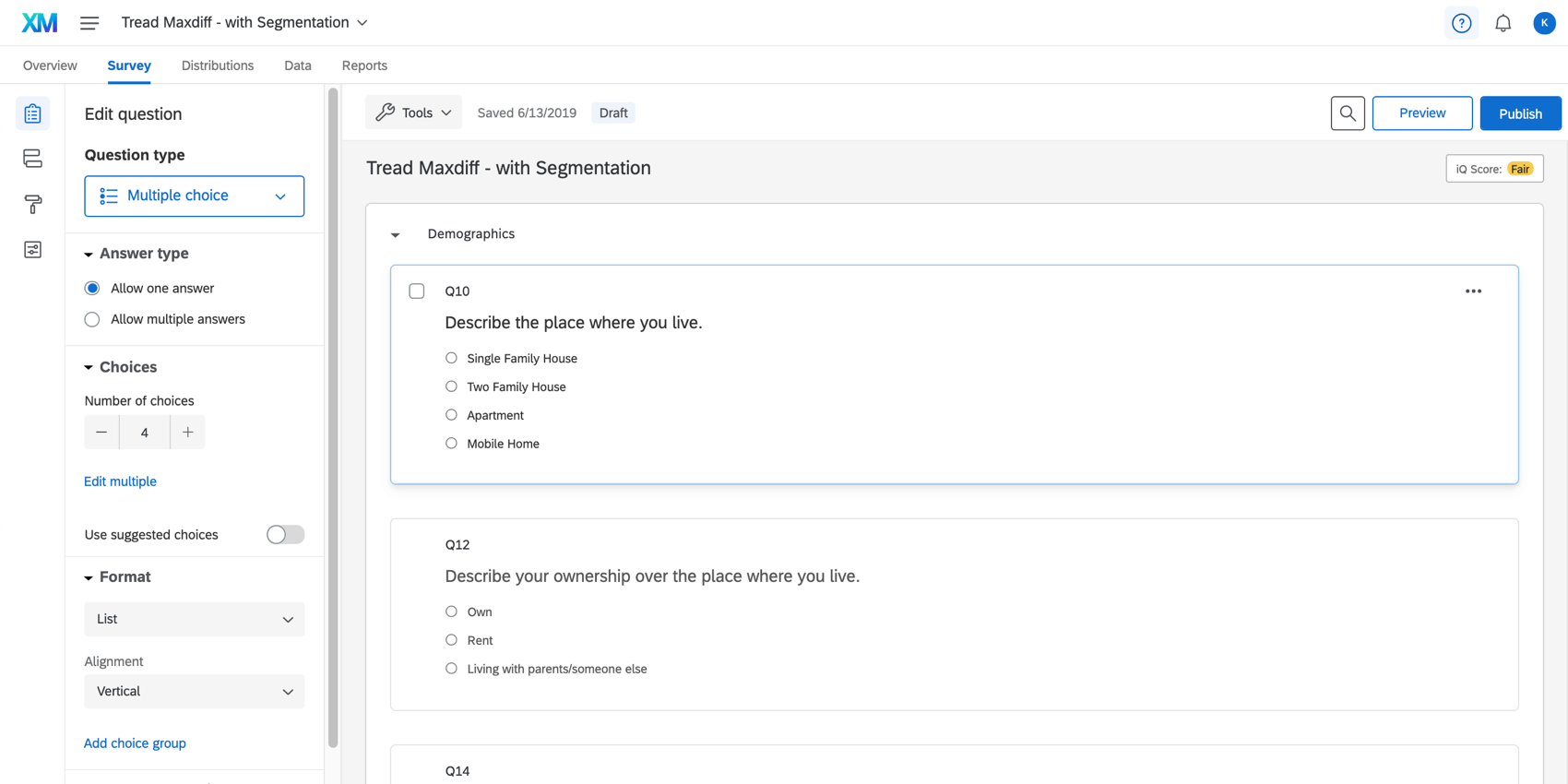
Dans l’onglet Enquête, assurez-vous que vous avez ajouté des questions à un bloc qui n’est pas de type Différence maximum. Dans l’exemple ci-dessous, le bloc Démographie comporte une question sur l’âge, le nombre de personnes dans le ménage du répondant, etc.
{kind=link}
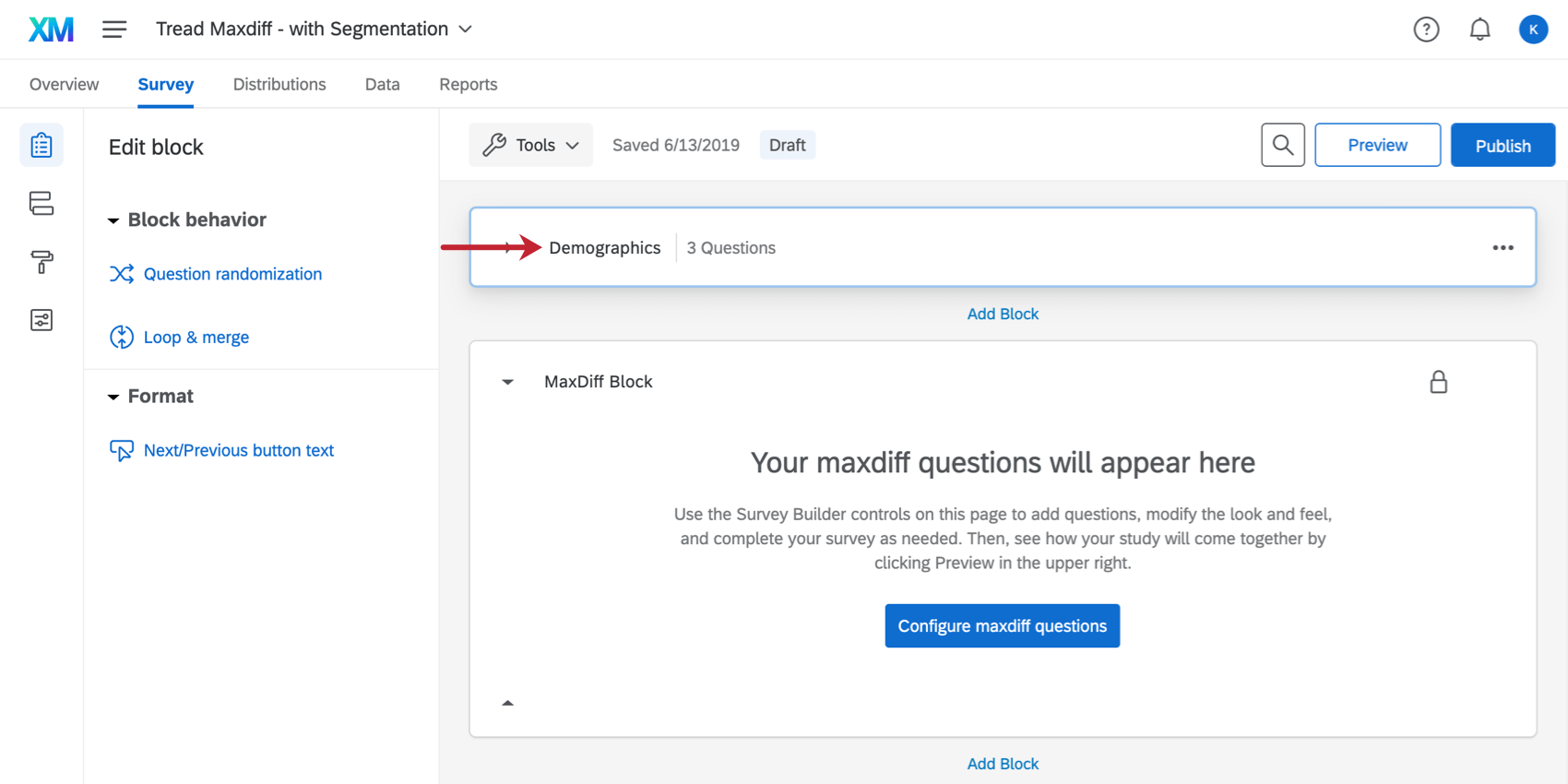
Le bloc Démographie est situé juste au-dessus du bloc Différence maximum, mais vous pouvez le déplacer à votre guise.
{kind=link}
Formatage des questions
Vous ne pouvez effectuer un clustering en Différence maximum qu’à l’aide de questions à choix multiple à sélection unique. En effet, ils offrent une sélection finie de choix qui peuvent être facilement analysés.
- Données démographiques : Demandez des informations descriptives de base, telles que l’âge, la tranche de revenus, la race ou le sexe.
- Comportement : Demandez comment les clients interagissent avec votre organisation et vos produits, ou quels sont les comportements qui peuvent être liés à leur comportement d’achat. Par exemple, vous pouvez demander à quel rythme le client fait ses courses.
- Donnéesopérationnelles : Il s’agit d’informations telles que le temps passé sur votre site web ou l’ancienneté d’un employé dans votre entreprise.
- Formats des questions : Formulez les questions sur les comportements et les croyances sous forme d’échelles. L’étendue d’une échelle peut nous aider à comprendre quels points de l’échelle sont corrélés et donc à peu près dans le même cluster ; les questions de type Oui/Non et à choix unique ne sont pas aussi utiles pour l’analyse des clusters. Exemple : Si vous posez la question “Quel type d’acheteur êtes-vous ?” et que vous donnez les options “Préfère faire du shopping dans les centres commerciaux”, “Préfère faire du shopping en ligne” et “Préfère faire du shopping dans les boutiques”, l’algorithme de clustering voudra séparer les personnes interrogées en trois groupes, un pour chaque réponse. Si vous posez plutôt une série de questions (par exemple, “Aimez-vous faire du shopping dans les centres commerciaux ?”) avec des réponses de 1 à 7, l’algorithme de clustering sera plus à même de discerner réellement ce qui distingue les différents acheteurs les uns des autres.

Astuce : une fois que vous avez fini d’ajouter des questions, n’oubliez pas de publier.
Activation des clusters
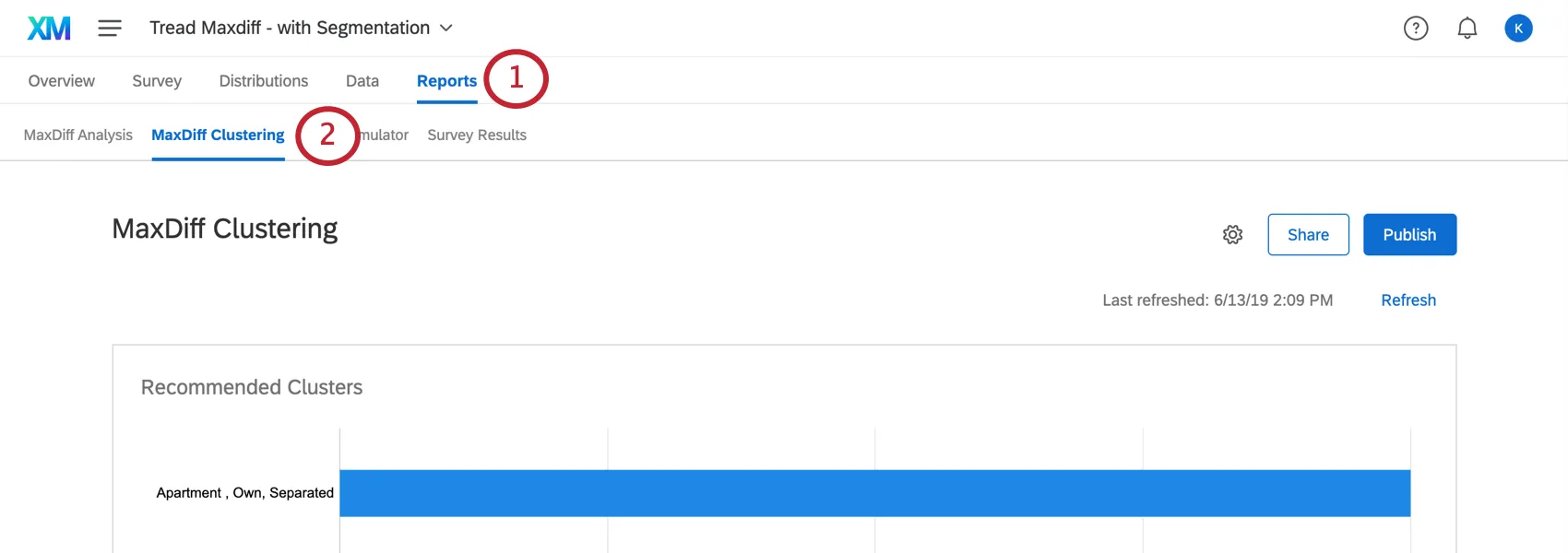
Le clustering se trouve dans la section Clustering de la Différence maximum de l’onglet Rapports.
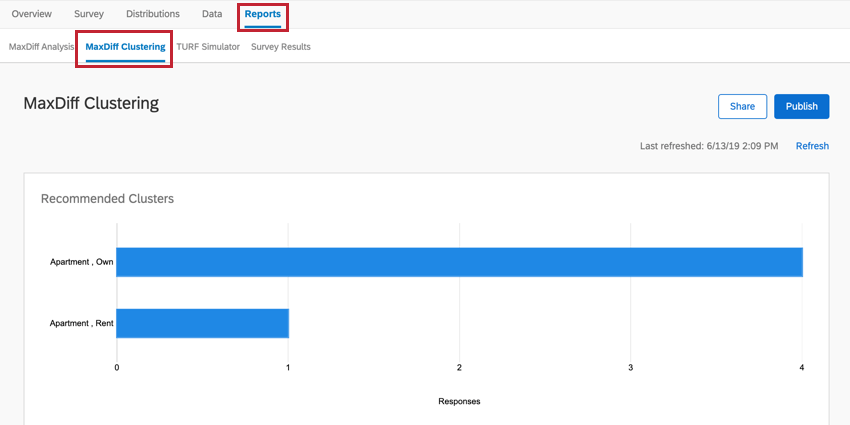{kind=link}

Pour que les données apparaissent la première fois, il se peut que vous deviez plutôt cliquer sur Chronomètre dans la section Analyse de la Différence maximum .
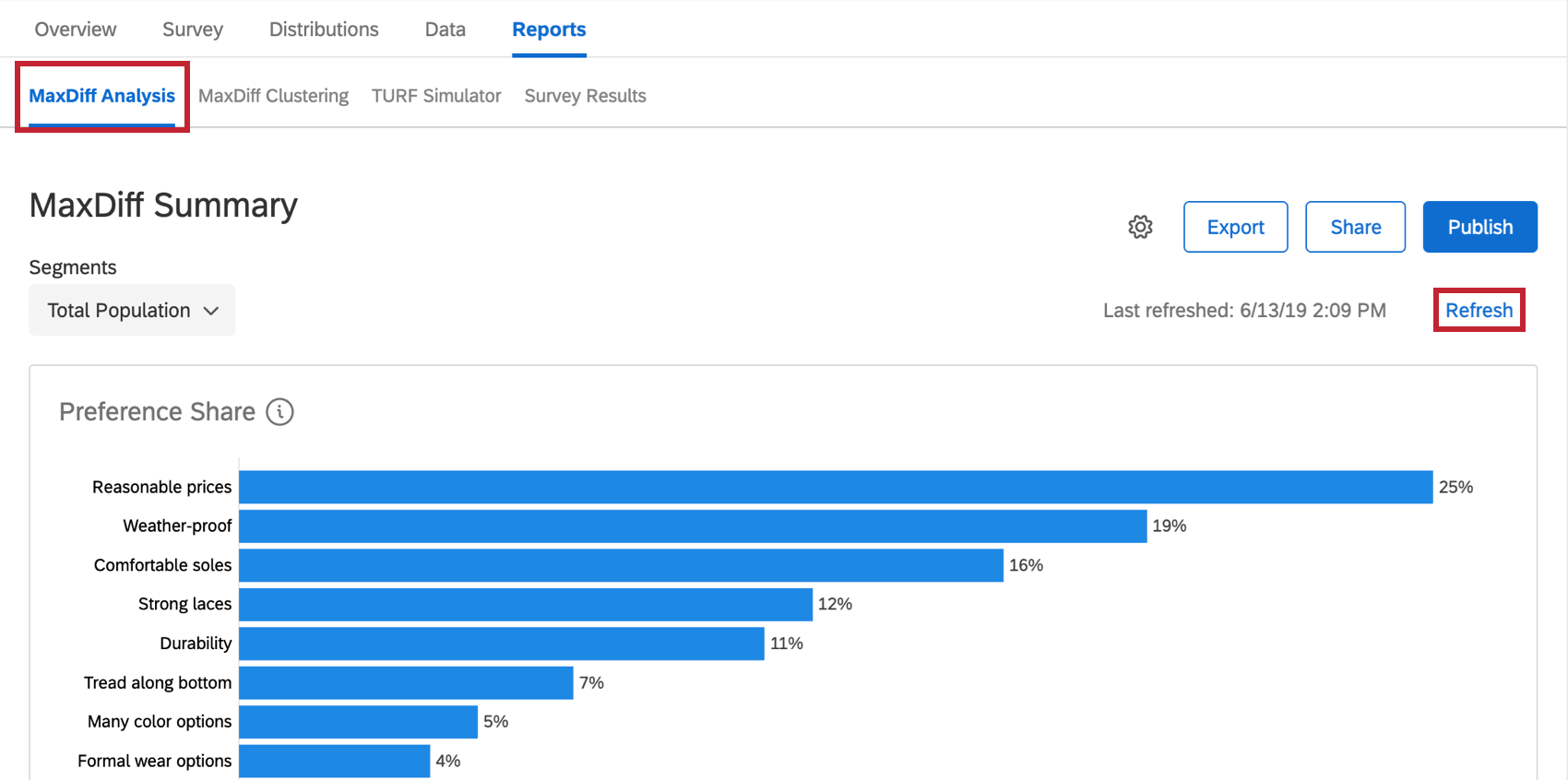{kind=link}
Astuce : Comme les rapports d’analyse de Différence maximum, le rapport de clustering de Différence maximum est actualisé toutes les heures.
Ajustement des données démographiques utilisées dans les clusters
Par défaut, la méthode de clustering de Différence maximum utilisera toutes les questions d’enquête à choix multiple que vous avez posées. Cependant, vous n’êtes pas obligé d’utiliser chaque question si vous ne le souhaitez pas, et vous pouvez ajouter et supprimer du contenu pour voir quels sont les différents clusters que cette fonction vous recommande.
Suppression des données démographiques
Dans la boîte située à droite de l’en-tête Détails du cluster, cliquez sur le X d’une question pour la supprimer de l’analyse du cluster. La suppression d’une question n’entraîne pas un nouveau calcul des clusters.
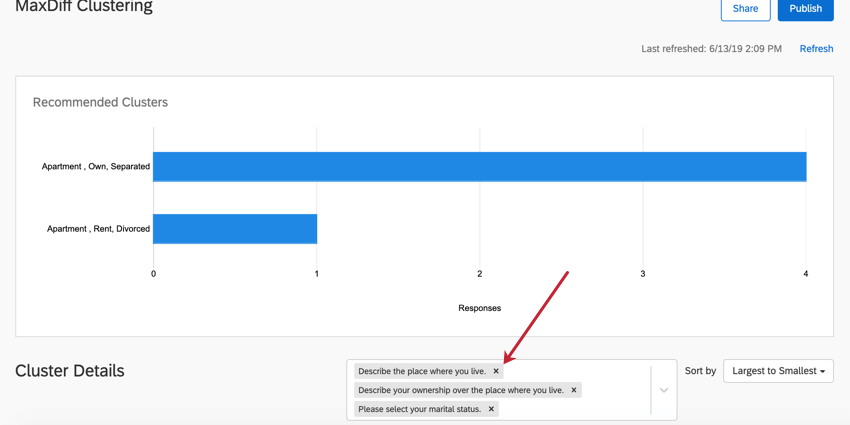{kind=link}
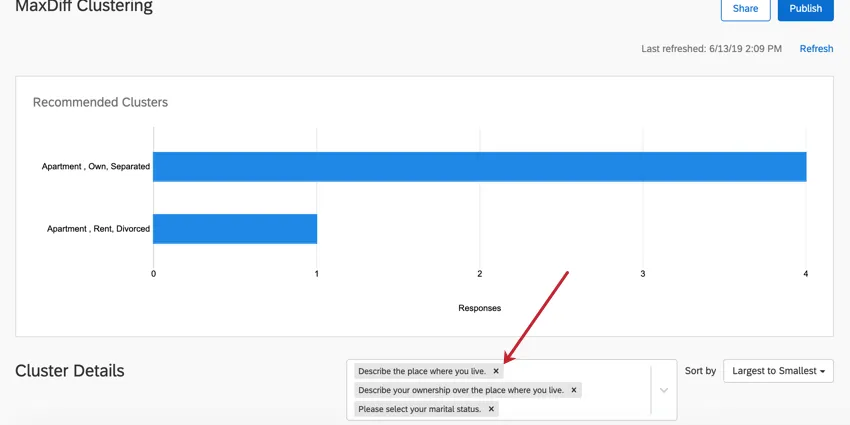
Ajout de données démographiques
Dans la zone située à droite de l’en-tête Détails du cluster, cliquez sur la flèche déroulante. Sélectionnez ensuite les questions que vous souhaitez ajouter aux clusters.
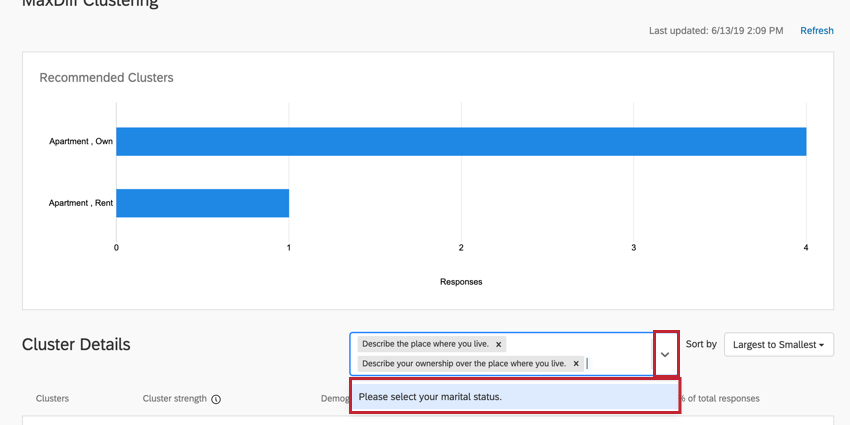{kind=link}

Clusters recommandés
Une fois que vous avez collecté suffisamment de données et actualisé votre page de clustering MaxDiff, cette fonction vous recommandera des clusters. Ces clusters sont déterminés en fonction de la similitude des fonctions préférées des personnes interrogées. Leur utilité individuelle pour chaque attribut est calculée, puis les caractéristiques démographiques communes à ces clusters sont surlignées afin que vous puissiez mieux comprendre comment les différentes populations préfèrent vos produits.
Surlignez un cluster dans le graphique du haut pour en savoir plus sur ce cluster. Cliquez dessus pour ouvrir les informations sur le cluster ci-dessous.
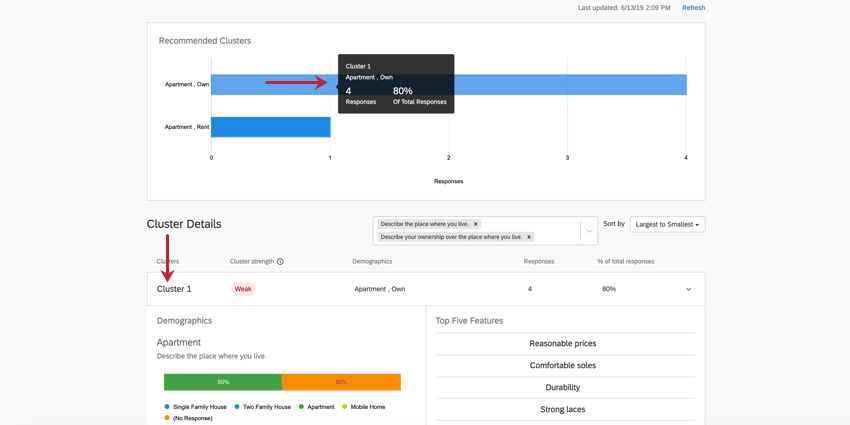{kind=link}
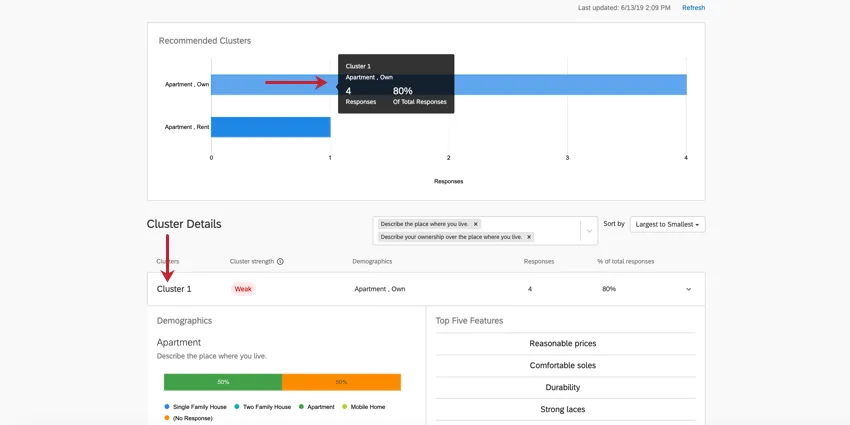
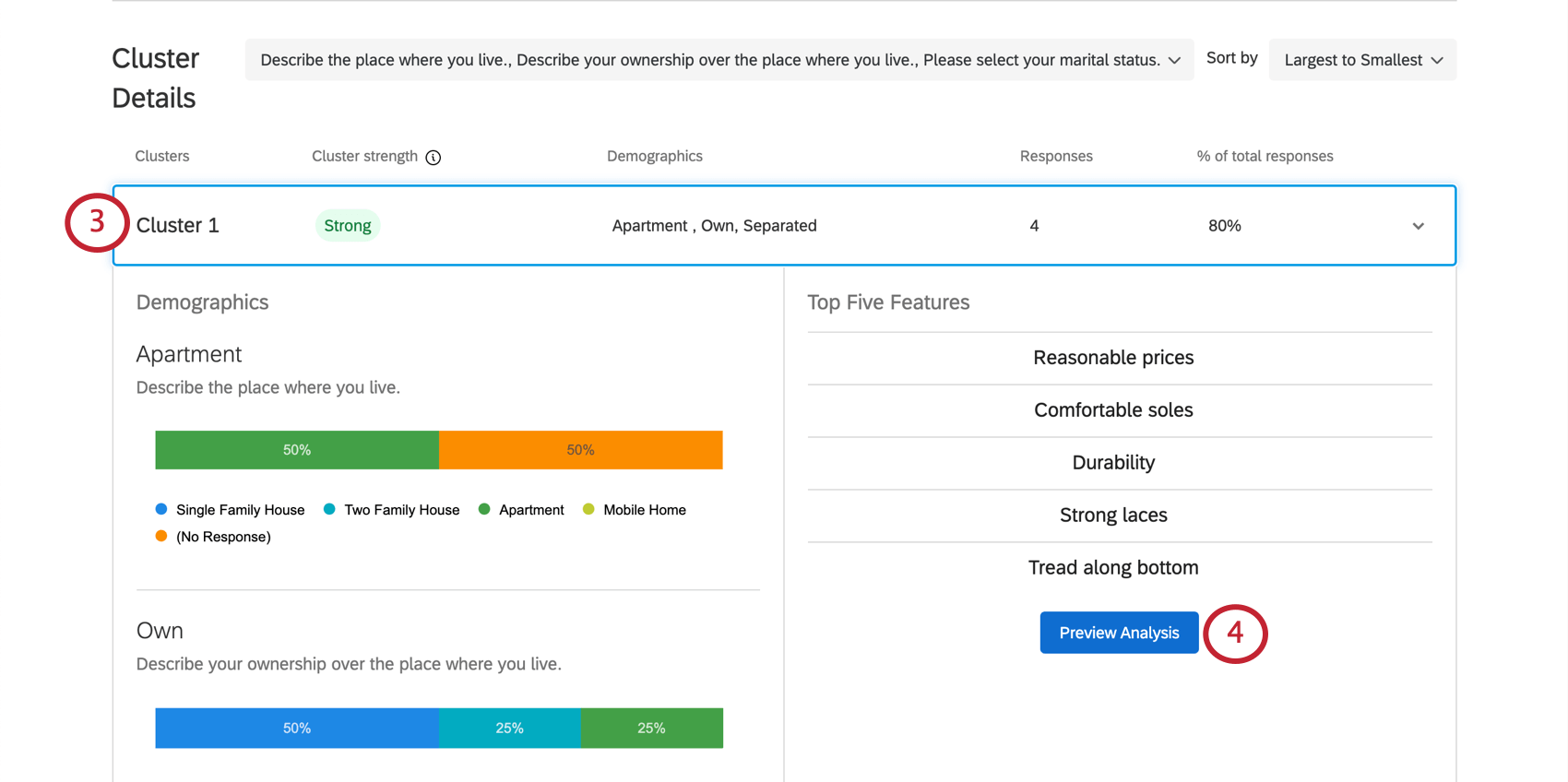
Détails du cluster
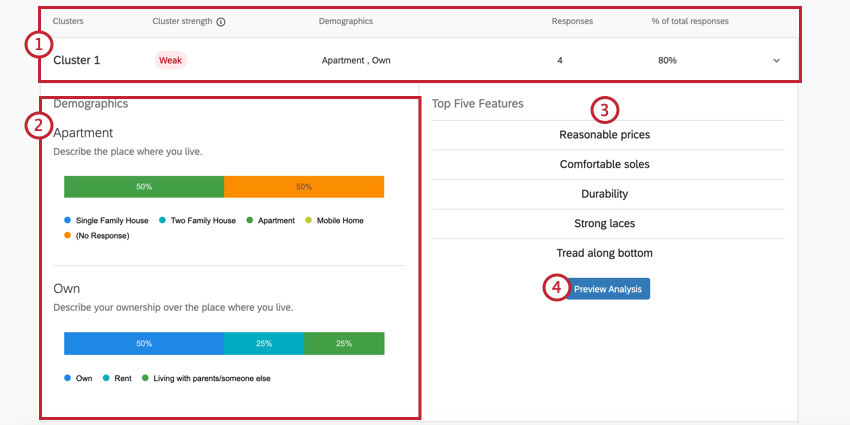{kind=link}
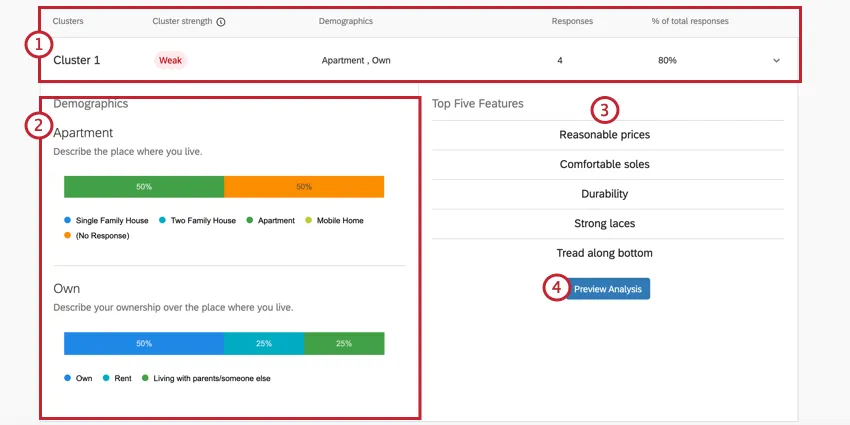
Exemple : Dans le Cluster 1 illustré ici, les réponses tendent à provenir de personnes qui possèdent leur propre appartement. 4 répondants correspondent généralement à ce schéma, soit 80 % de l’ensemble des données. Il s’agit d’un très petit ensemble de données, et il est donc peu probable que des décisions soient prises sur la base de ces résultats. C’est également ce qu’indique la faible force du cluster.
Exemple : Le revenu annuel du Cluster 1 est listé comme “20 000 – 29 000 $” Toutefois, il ne s’agit pas du revenu annuel le plus courant pour ce Cluster, comme le montre la barre des “70 000 – 79 000 $” à la fin, qui est beaucoup plus longue. En effet, les personnes disposant d’un revenu inférieur sont tout simplement plus susceptibles d’avoir accordé de l’importance aux prix raisonnables, à la durabilité, etc. que les personnes du cluster disposant d’un revenu annuel plus élevé.
Astuce : Rappelez-vous que les “données démographiques” de ces graphiques sont les questions sans différence maximum que vous avez créées dans l’onglet Enquête.
Détermination de la force des clusters
Qualtrics utilise une métrique appelée notation de la silhouette pour déterminer la force de chaque cluster. Cette notation donne une valeur comprise entre 0 et 1 qui détermine le degré de clusterisation des répondants. Nous utilisons le tableau suivant pour convertir la notation de la silhouette en force du cluster :
| Notation de la corrélation | La force des liens | Label de force du cluster |
|---|---|---|
| 0.71 à 1.0 | Lien très fort | Fort |
| 0.51 à 0,70 | Lien assez fort | Plutôt fort |
| 0.26 à 0,50 | Lien assez faible | Un peu faible |
| 0 à 0,25 | Pas de lien significatif | Faible |
  ;
Appliquer des Clusters aux Rapports
Les clusters peuvent être appliqués au rapport d’analyse de la Différence Maximum afin que vous puissiez voir des détails plus spécifiques sur la façon dont les répondants de ce cluster ont évalué les attributs qui leur ont été présentés.
Dans la section Analyse de la Différence Maximum de l’onglet Rapports, sélectionnez un cluster dans le menu déroulant Segments en haut à gauche.
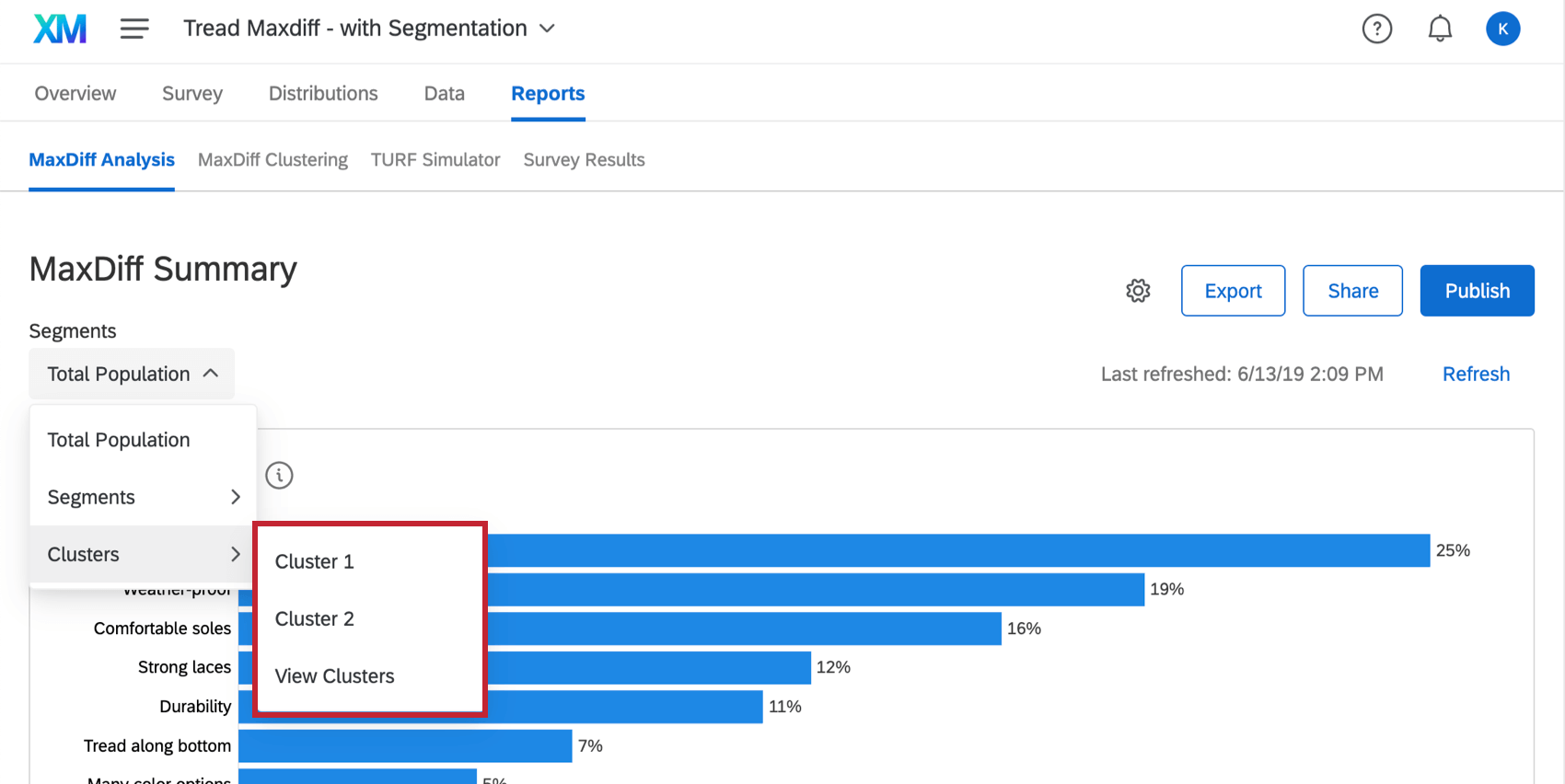{kind=link}

Vous pouvez également sélectionner Prévisualiser l’analyse lorsqu’un cluster est sélectionné dans la section Cluster de la Différence maximum de l’onglet Rapports.
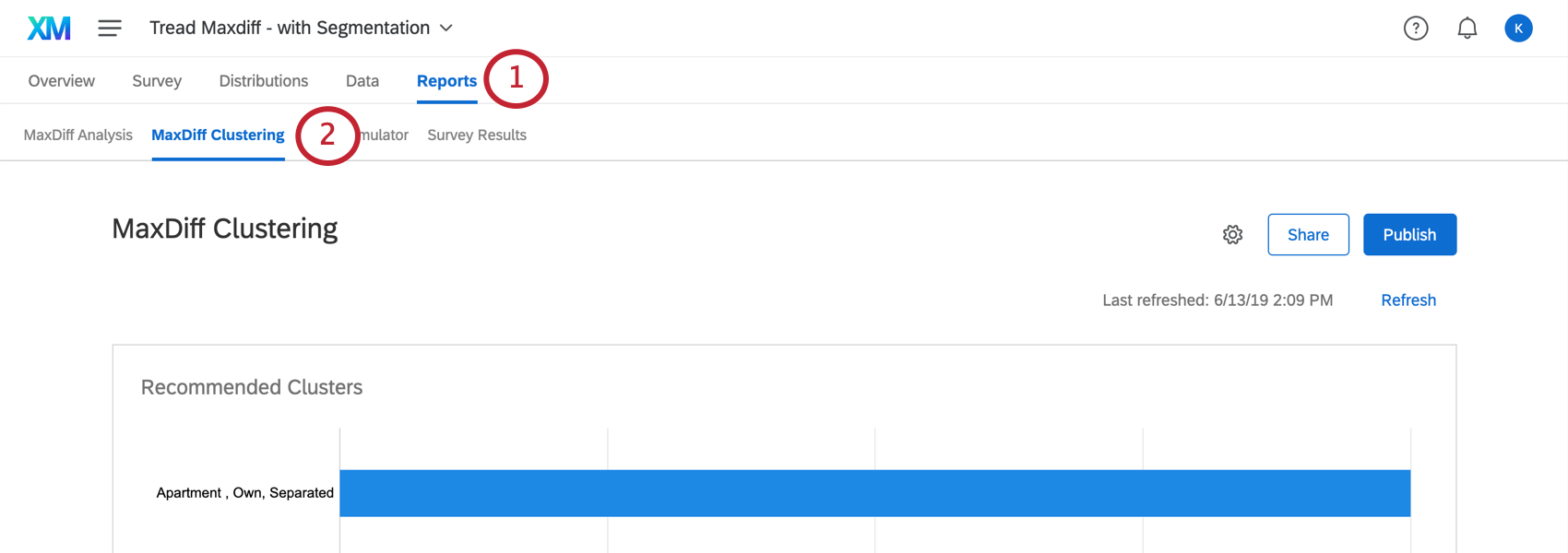{kind=link}
{kind=link}

C'est génial! Merci pour votre avis!
Merci pour votre avis!