-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Benutzerfreundlicher Leitfaden zur logistischen Regression
Was ist logistische Regression?
Die logistische Regression schätzt eine mathematische Formel, die eine oder mehrere Eingabevariablen mit einer Ausgabevariablen verknüpft.
Nehmen wir zum Beispiel an, Sie führen einen Limonadenständer und interessieren sich dafür, welche Kundentypen tendenziell zurückkommen. Ihre Daten umfassen einen Eintrag für jeden Kunden, seinen ersten Kauf und ob er innerhalb des weiter Monats für mehr Limonade zurückgekommen ist. Ihre Daten könnten wie folgt aussehen:
| Zurück | Alter des Kunden | Geschlecht | Temp. beim ersten Kauf | Limonadenfarbe | Hosenlänge |
|---|---|---|---|---|---|
| War nicht | 21 | Männlich | 24 | Rosa | Shorts |
| Zurückgegeben | 34 | Weiblich | 20 | Gelb | Shorts |
| Zurückgegeben | 13 | Weiblich | 25 | Rosa | Hose |
| War nicht | 25 | Weiblich | 27 | Gelb | Kleid |
| usw. | usw. | usw. | usw. | usw. | usw. |
Sie denken, dass “Kundenalter” (ein Input oder erklärende Variable) kann sich auf “Return” (eine Ausgabe oder Antwortvariable). Die logistische Regression kann zu folgendem Ergebnis führen:
Im Alter von 12 Jahren (dem niedrigsten Alter) beträgt die Wahrscheinlichkeit, dass die Rückkehr zurückgegeben wird, 10 %.
Für jedes zusätzliche Jahr des Alters ist “Rückkehr” 1,1-mal mehr zu “Zurückgegeben”.
Dieses Wissen ist aus zwei Gründen nützlich.
Erstens können Sie damit eine Beziehung verstehen: Ältere Kunden kehren wahrscheinlicher zurück. Diese Erkenntnis könnten dazu führen, dass Sie Ihre Werbung auf ältere Kunden ausrichten, da sie mit größerer Wahrscheinlichkeit zu Wiederholungskunden werden.
Zweitens, und damit verbunden, kann es Ihnen auch helfen, bestimmte Prognosen zu erstellen. Wenn ein 24-jähriger Kunde vorbeikommt, könnten Sie schätzen, dass es eine Wahrscheinlichkeit von 26 % gibt, dass er später ein Retourenkunde wird, wenn er etwas Limonade gekauft hat.
Verstehen der Multiplikation von Quoten
Beachten Sie, dass wir Folgendes tun, wenn wir sagten, dass „Zurückgegeben“ in einer Situation „1,5-mal wahrscheinlicher“ war als in einer anderen Situation:
Quoten waren 1:9, auch geschrieben 1/(1+9) = 10%.
Die „Chancen für“ (die 1) werden mit 1,5 multipliziert.
Jetzt 1,5:9, auch geschrieben 1,5/(1,5+9) = 14%.
Ein weiteres Beispiel, dieses Mal von 50 % Wahrscheinlichkeit zu etwas dreimal so wahrscheinlich zu gehen:
Chancen waren 1:1, auch geschrieben 1/(1+1) = 50%.
Die „Chancen für“ (linke Seite 1) wird mit 3 multipliziert.
Nun 3:1, auch geschrieben 3/(3+1) = 75%.
Nun führen wir den Prozess zum Anlegen dieses Regressionsmodells durch.
Anlegen eines Regressionsmodells vorbereiten
1. Denken Sie an die Theorie Ihrer Regression.
Nachdem Sie eine Antwortvariable ausgewählt haben,,” Hypothese, wie verschiedene Eingaben damit verbunden sein können. Sie könnten beispielsweise denken, dass eine höhere “Temperatur beim ersten Kauf” zu einer höheren Wahrscheinlichkeit von “Zurückgegeben” führt. Sie sind sich möglicherweise nicht sicher, wie sich “Alter” auf “Rückgabe” auswirkt.,” Und vielleicht glauben Sie, dass “Pants” (vs. Shorts) ist von “Temperatur” betroffen, hat aber keine Auswirkungen auf Ihren Limonadenständer.
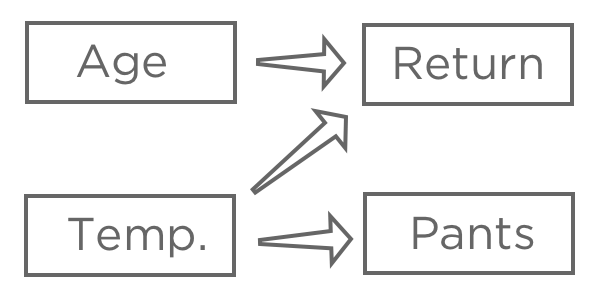
Das Ziel der Regression besteht in der Regel darin, die Beziehung zwischen mehreren Eingaben und einer Ausgabe zu verstehen. Daher würden Sie in diesem Fall wahrscheinlich ein Modell anlegen, das “Return” mit “Temperatur” erklärt. und “Alter” (auch als „Vorhersage Rückgabe von Temperatur und Alter,“ selbst wenn Sie mehr an einer Erklärung als an einer tatsächlichen Vorhersage interessiert sind).
Sie würden wahrscheinlich “Hosen” nicht in Ihre Regression einbeziehen. Es kann mit “Rückgabe” korreliert sein, da beide mit “Temperatur” zusammenhängen, aber nicht vor “Rückgabe” in der Kausalkette stehen, sodass das Einschließen Ihres Modells verwirrend wäre.
2. „Beschreiben“ Sie alle Variablen, die für Ihr Modell nützlich sein könnten.
Beginnt von beschreibende die Antwortvariable, in diesem Fall „Umsatz“, und ein gutes Gefühl dafür zu bekommen. Gehen Sie für Ihre erklärenden Variablen genauso vor.
Hinweis, die eine Form wie diese haben…
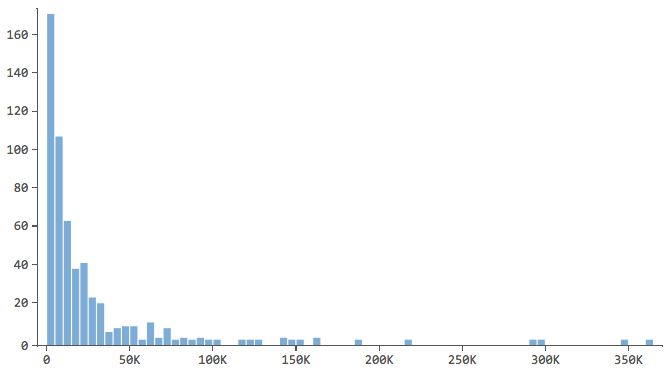
… wo sich der Großteil der Daten in den ersten Bins des Histogramms befindet. Diese Variablen erfordern später besondere Aufmerksamkeit.
3. „Verknüpfen“ Sie alle möglichen erklärenden Variablen mit der Antwortvariablen.
Stats iQ wird die Ergebnisse nach der Stärke der statistischen Beziehung. Sehen Sie sich die Ergebnisse an, und notieren Sie, welche Variablen sich auf „Umsatz“ beziehen und wie.
4. Beginnen Sie mit dem Aufbau der Regression.
Erstellen einer Regression -Modell ist ein iterativer Prozess. Sie durchlaufen die folgenden drei Phasen so oft wie nötig.
Die drei Phasen des Aufbaus eines Regressionsmodells
Stufe 1: Variable addieren oder subtrahieren.
Fügen Sie nacheinander Variablen hinzu, die in Ihren vorherigen Analysen mit “Umsatz” zusammenhängen. (oder fügen Sie Variablen hinzu, für die Sie einen theoretischen Grund haben). Eins nach dem anderen zu gehen ist nicht unbedingt notwendig, aber es macht es einfacher, Probleme zu erkennen und zu beheben, während Sie weitergehen, und hilft Ihnen, ein Gefühl für das Modell zu bekommen.
Angenommen, Sie beginnen mit der Prognose von „Umsatz“ mit „Temperatur“. Sie finden eine starke Beziehung, bewerten das Modell und finden es zufriedenstellend (weitere Details in einer Minute).
<– Temperatur zurückgeben
Anschließend fügen Sie “Lemonade-Farbe” hinzu, und nun hat Ihr Regressionsmodell zwei Begriffe, von denen beide statistisch signifikante Prädiktoren sind. So:
Umsatz <– Temperatur & Lemonadenfarbe
Dann fügen Sie “Sex” hinzu, und die Ergebnisse zeigen nun, dass “Sex” statistisch signifikant im Modell ist, aber “Lemonade color” ist nicht mehr. In der Regel würden Sie “Limonadenfarbe” aus dem Modell entfernen. Jetzt haben wir:
Umsatz <– Temperatur & Geschlecht
Das heißt, wenn Sie das Geschlecht des Kunden kennen, wenn Sie wissen, welche Farbe von Limonade er bestellt hat, erhalten Sie keine weiteren Informationen darüber, ob er ein Retourenkunde sein wird.
Sie könnten untersuchen und entdecken, dass Frauen dazu neigen, gelbe Limonade mehr zu pflücken als Männer und dass Frauen eher zurückkehren. Anfangs schien es also, dass die Auswahl von Gelb dazu führte, dass ein Kunde eher zurückkehrt, aber tatsächlich ist “Lemonade color” nur mit “Return” durch “Sex.” Wenn Sie also “Sex” in die Regression aufnehmen, fällt “Lemonade color” aus der Regression.
Die Interpretation von Ergebnisse erfordert viel Einschätzung, und nur weil eine Variable statistisch signifikant ist, bedeutet dies nicht, dass sie tatsächlich kausal ist. Aber indem Sie Variablen sorgfältig addieren und subtrahieren, notieren, wie sich das Modell ändert, und immer über die Theorie hinter Ihrem Modell nachdenken, können Sie interessante Beziehungen in Ihren Daten auseinanderreißen.
Phase 2: Bewerten Sie das Modell.
Jedes Mal, wenn Sie eine Variable addieren oder subtrahieren, sollten Sie die Genauigkeit des Modells bewerten, indem Sie das R-Quadrat (R2), AICc und alle Warnungen von Stats iQ. Jedes Mal, wenn Sie das Modell ändern, vergleichen Sie die neuen R-Quadrat-, AICC- und Diagnosediagramme mit den alten, um zu ermitteln, ob sich das Modell verbessert hat oder nicht.
R-Quadrat (R)2)
Die numerische Metrik zur Quantifizierung der Prognosegenauigkeit des Modells wird als R-Quadrat bezeichnet, das zwischen null und eins liegt. Eine Null bedeutet, dass das Modell keinen Prognosewert hat, und eine davon bedeutet, dass das Modell alles perfekt vorhersagt.
Beispielsweise führen die auf der linken Seite dargestellten Daten zu einem viel weniger genauen Modell als die Daten auf der rechten Seite. Stellen Sie sich vor, Sie versuchen, eine Linie durch das Streudiagramm zu ziehen; Sie könnten fast vollständig blau (“Zurückgegeben”) von rot (“Didn’t”) auf der rechten Seite trennen, aber auf der linken Seite wäre es schwierig, dies zu tun.
Das heißt, die rechte Seite hat ein hohes R-Quadrat; wenn Sie “Temperatur” und “Alter” kennen, können Sie “Zurückgegeben” vs. “Hab’s nicht” ganz leicht. Die linke Seite hat ein niedrig- bis mittleres R-Quadrat; wenn Sie “Temperatur” und “Alter” kennen, Sie haben eine ziemlich gute Vermutung, ob es “zurückgegeben” vs. “Hat nicht getan”, aber es wird viele Fehler geben.
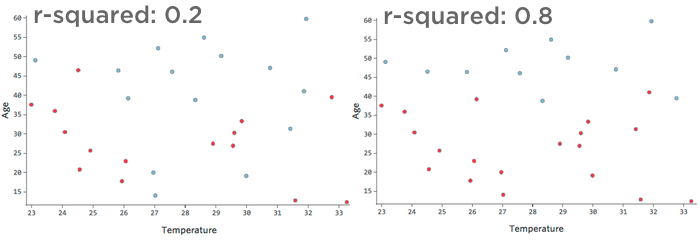
Es gibt keine feste Definition eines „guten“ R-Quadrats. In einigen Einstellungen kann es interessant sein, irgendeinen Effekt zu sehen, während Ihr Modell in anderen unbrauchbar sein könnte, es sei denn, es ist sehr genau.
Jedes Mal, wenn Sie eine Variable hinzufügen, geht das R-Quadrat hoch, sodass das Erreichen des höchstmöglichen R-Quadrats nicht das Ziel ist. Stattdessen möchten Sie die Genauigkeit (R-Quadrat) des Modells mit seiner Komplexität (in der Regel die Anzahl der Variablen darin) ausgleichen.
AICc
AICc ist eine Metrik, die Genauigkeit mit Komplexität ausgleicht. Eine höhere Genauigkeit führt zu besseren Scores, und eine zusätzliche Komplexität (mehr Variablen) führt zu schlechteren Bewertungen. Das Modell mit dem unteren AICc ist besser.
Beachten Sie, dass die AICc-Metrik nur für den Vergleich von AICcs aus Modellen mit derselben Anzahl von Datenzeilen nützlich ist. und dieselbe Ausgabevariable.
Warnungen
Von Zeit zu Zeit wird Stats iQ Möglichkeiten zur Verbesserung Ihres Modells vorschlagen. Stats iQ kann beispielsweise vorschlagen, dass Sie den Logarithmus einer Variablen (Details dazu, was das bedeutet).
Matrix und Precision-Recall-Kurve
Die Matrix und die Präzisions-Rückruf-Kurve sind auch nützliche Werkzeuge, um zu verstehen, wie genau Ihr Modell ist. Und wenn Sie Vorhersagen basierend auf Ihrem Modell erstellen möchten, helfen Ihnen diese Werkzeuge dabei. Sie sind nicht unbedingt erforderlich, um ein gutes Verständnis davon zu erhalten, was Ihr Modell Ihnen sagt. Daher stellen wir sie in einen anderen Abschnitt über die Matrix und die Präzision-Recall-Kurve
Phase 3: Ändern Sie das Modell entsprechend.
Wenn die Bewertung des Modells zufriedenstellend ist, sind Sie entweder fertig, oder Sie kehren zu Phase 1 zurück und geben weitere Variablen ein.
Wenn Ihre Bewertung feststellt, dass das Modell fehlt, verwenden Sie Stats iQ, um die Probleme zu beheben.
Wenn Sie das Modell ändern, notieren Sie sich kontinuierlich die sich ändernden R-Quadrate, AICR und Residualdiagnosen und entscheiden Sie, ob die Änderungen, die Sie vornehmen, Ihr Modell unterstützen oder verletzen.