Predict iQ
Was finden Sie hier?
Achtung: Sie lesen eine Funktion, auf die nicht alle Benutzer Zugriff haben. Wenn Sie an dieser Funktion interessiert sind, Kontakt Ihren Benutzerkonto um zu sehen, ob Sie sich qualifizieren.
Informationen zu Predict iQ
Wenn Kunden ein Unternehmen verlassen, werden wir oft außer Acht gelassen. Wenn wir nur gewusst hätten, dass dieser Kunde gefährdet war, dann hätten wir ihn vielleicht erreichen können, bevor er sein Vertrauen in uns völlig verloren hat. Wenn es nur eine Möglichkeit gab, die Wahrscheinlichkeit vorherzusagen, dass ein Kunde abwandern wird (das Unternehmen zu verlassen).
Predict iQ lernt aus den Antworten der Befragten auf Umfragen und aus eingebetteten Daten, um vorherzusagen, ob der Befragte letztendlich abwandern wird. Wenn dann neue Antworten auf Umfragen eingehen, kann Predict iQ vorhersagen, wie hoch die Wahrscheinlichkeit ist, dass diese Befragten in Zukunft das Unternehmen wechseln werden. Um vorherzusagen, ob ein Kunde abwandern wird, verwendet Predict iQ Neuronale Netzwerke (eine Teilmenge davon werden Deep Learning genannt) und Regression, um Kandidatenmodelle zu erstellen. Er probiert Variationen dieser verschiedenen Modelle für jedes Datenset aus und wählt dann das Modell aus, das am besten zu den Daten passt.
Vorbereiten Ihrer Daten
Bevor Sie ein Abwanderungsvorhersagemodell anlegen, sollten Sie sicherstellen, dass Ihre Daten bereit sind.
Predict iQ funktioniert am besten, wenn mindestens 500 Teilnehmer abwandern. Allerdings erhalten Sie mit 5.000 abwanderten Befragten oder mehr die besten Ergebnisse.
Einrichten einer Abwanderungsvariable
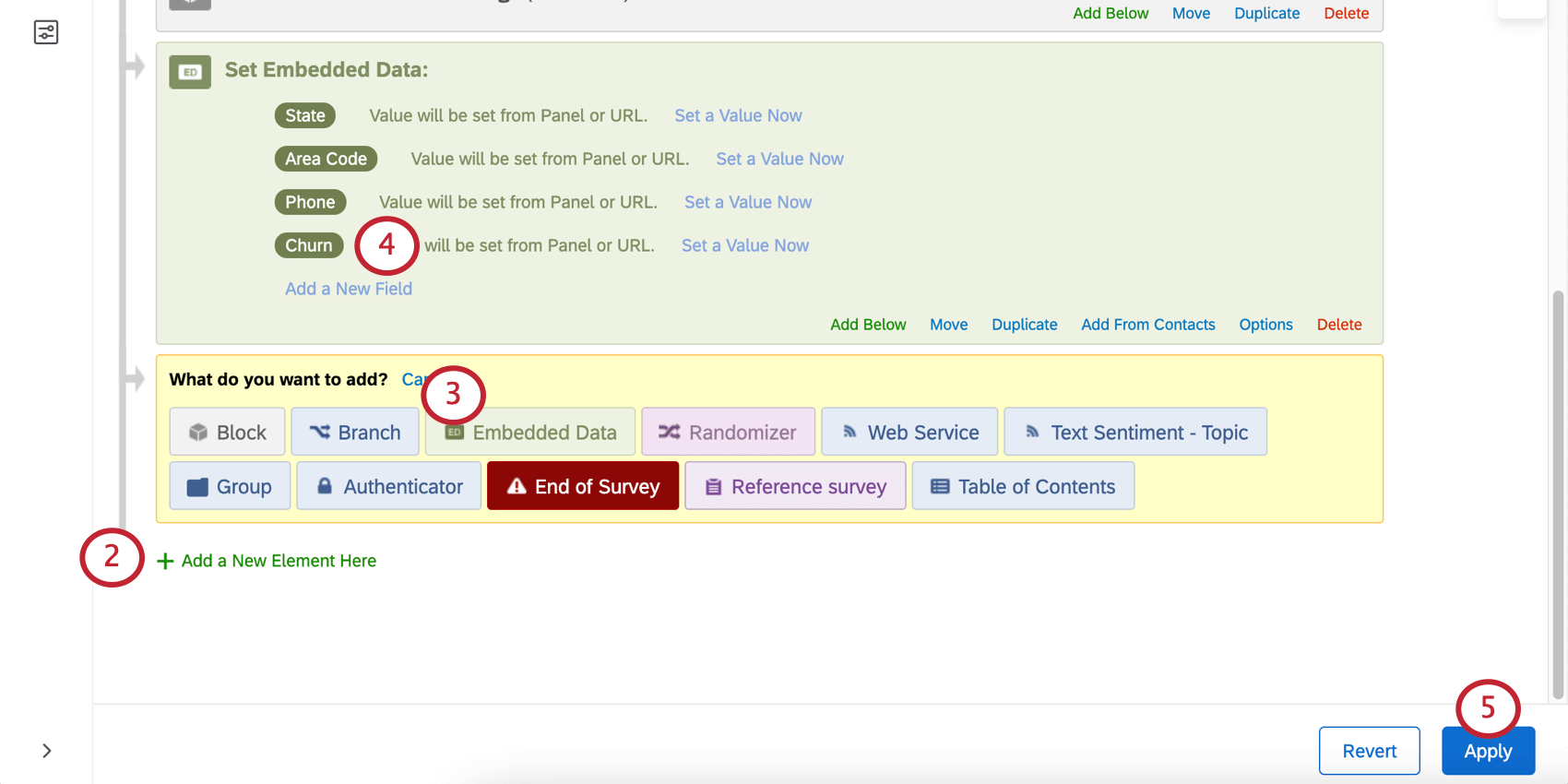
Aufzeichnungsdaten
Sobald Sie eine Abwanderungsvariable haben, können Sie historische Daten in Ihre Umfrage importieren , einschließlich einer Spalte für Abwanderung, in der Sie mit Ja oder Nein angeben, ob der Kunde abwanderte.
Anlegen eines Abwanderungsvorhersagemodells
Sobald Ihre Abwanderungsvariable eingerichtet ist und Sie über genügend Daten verfügen, können Sie Predict iQ öffnen.
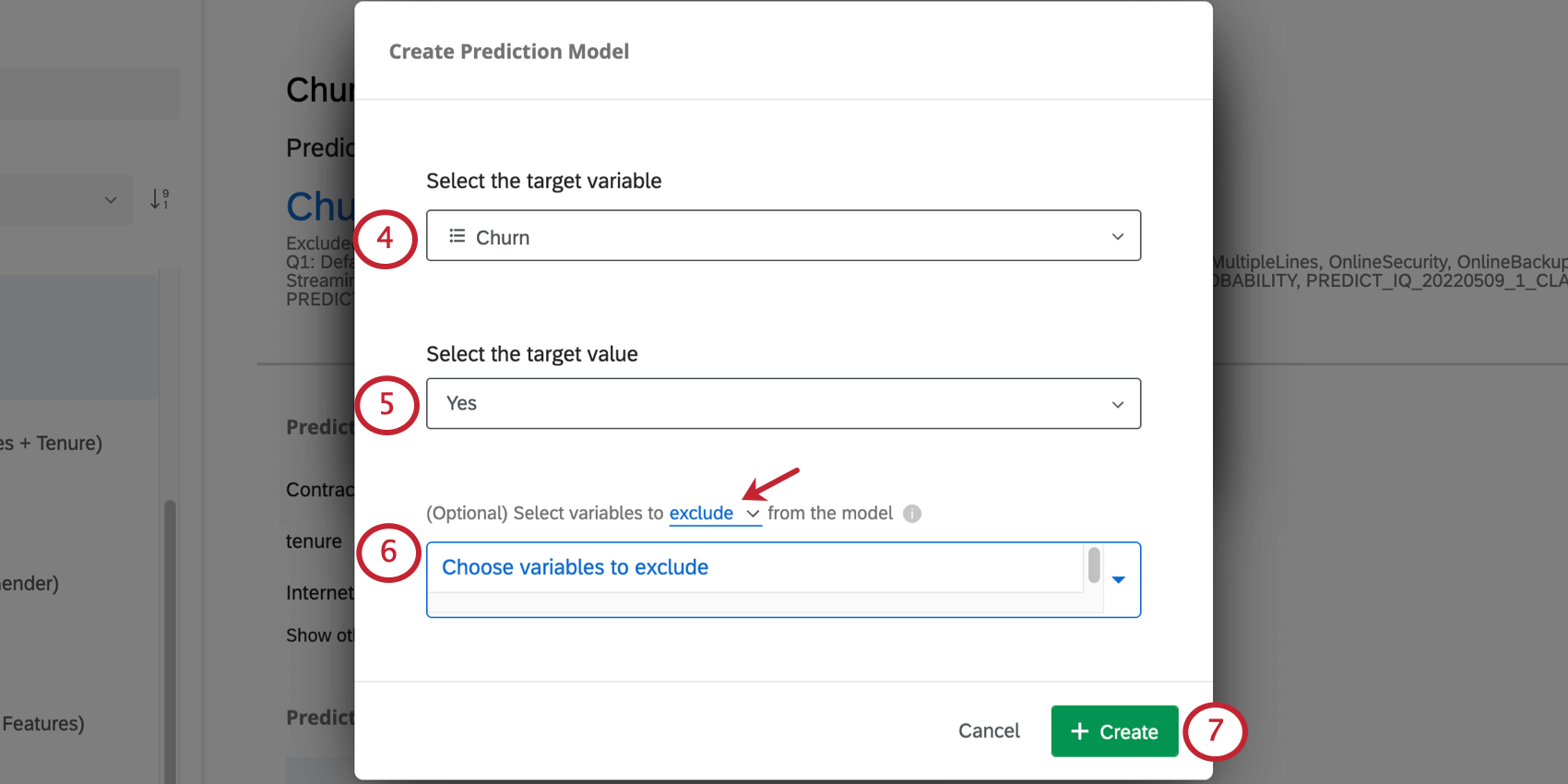
Tipp: Predict iQ prognostiziert nur Ergebnisse mit zwei möglichen Auswahlmöglichkeiten, z.B. Ja/Nein oder Wahr/Falsch. Numerische Ergebnisse (z. B. eine Skala von 1 bis 7) oder kategorische Ergebnisse mit mehr als 2 Werten (z. B. Ja/Vielleicht/Nein) werden nicht vorhergesagt.
Beispiel: Denn in diesem Beispiel heißt unsere Variable Churn, jemand mit Abwanderung gleich Ja ist abwandert. Angenommen, Sie haben Ihre Variable Bleiben Sie bei unserem Unternehmen statt dessen. Dann Nein würde darauf hinweisen, dass sich die Person nicht im Unternehmen aufhielt und abwanderte.
- Ausschließen: Wenn Sie beispielsweise eine Variable mit der Messung „Grund für Abwanderung“ in Ihren historischen Daten haben, können Sie diese aus der Analyse ausschließen, da sie für neue Umfrageteilnehmer nicht verfügbar ist, wenn die Prognose erstellt wird. Tipp: Sie können mehrere Variablen ausschließen. Klicken Sie auf das Symbol X weiter einer Variablen, um sie aus der Liste der ausgeschlossenen Variablen zu entfernen.


- Include: Wählen Sie Variablen aus, die in das Modell aufgenommen werden sollen. Alle anderen werden ignoriert.

Tipp: Die Berechnung Ihres Vorhersageabwanderungsmodells kann einige Zeit in Anspruch nehmen. Sie können von der Seite weg navigieren, um an anderen Projekte oder Websites zu arbeiten, ohne Ihren Fortschritt zu verlieren.
Sobald Ihr Prognosemodell abgeschlossen ist, wird die Predict iQ -Seite durch Informationen zum gerade angelegten Abwanderungsmodell ersetzt.
{kind=link}
Wie erfolgt die Aufteilung Ihres Datensets für das schulung?
Beim schulung Ihres Modells wird Ihr Datenset in schulung, Validierung und Testdaten aufgeteilt. 80 % Ihrer Daten werden für das schulung verwendet. 10 % Ihrer Daten werden für die Validierung verwendet, und 10 % Ihrer Daten werden zum Testen verwendet.
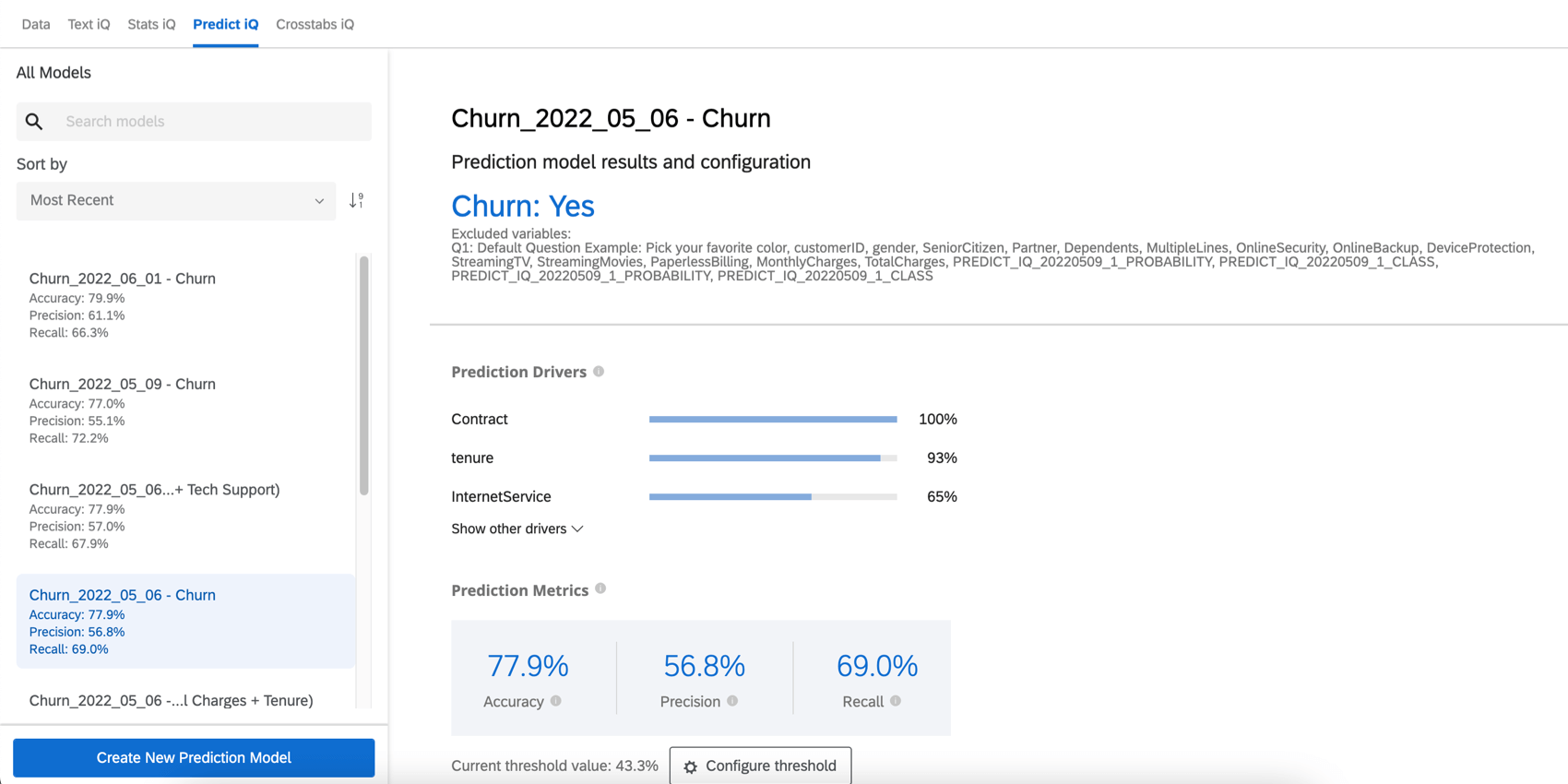
Variableninformationen
Die Ergebnisse und -konfiguration enthält den Namen Ihrer eingebettete Daten für die Abwanderung und den Wert, der angibt, dass ein Kunde wahrscheinlich abwandert. In diesem Abschnitt werden auch Ihre ausgeschlossenen Variablen aufgeführt.
{kind=link}

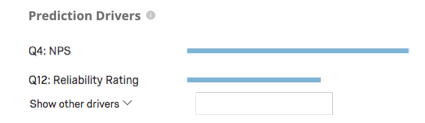
Vorhersagetreiber
Die Prognosetreiber sind die Variablen, die analysiert wurden, um Ihr Prognosemodell anzulegen, sortiert nach ihrer Wichtigkeit bei der Vorhersage der Abwanderung. Dazu gehören alle Variablen, die nicht von der Analyse ausgeschlossen wurden. Im Beispiel unten steuern NPS und Zuverlässigkeitsbewertungen die Abwanderungsvorhersage.
{kind=link}

Klicken Sie auf Andere Treiber anzeigen um die Liste zu expandieren.
Tipp: Um dieses Diagramm zu erstellen, wird jede Variable in einer einfachen logistischen Regression gegen die Abwanderungsvariable ausgeführt. Der höchste R-Quadrat-Wert wird auf 1 gesetzt, und die Werte der anderen Variablen werden entsprechend skaliert. Wenn beispielsweise das höchste R-Quadrat 0,5 beträgt, ist die Balkenlänge jeder Variable R-Quadrat * 2, wobei die Balkenlänge 1 ist.
Das Diagramm ist daher ein Indikator für die relative Stärke der Variablen bei der Vorhersage der Abwanderung und ist in der Natur nicht multivariat. Eine Bewertung der Auswirkungen jeder Variablen auf das Ergebnis eines Deep-Learning-Algorithmus ist ein Bereich aktiver akademischer Forschung, für den an dieser Stelle keine Best Practices akzeptiert wurden.
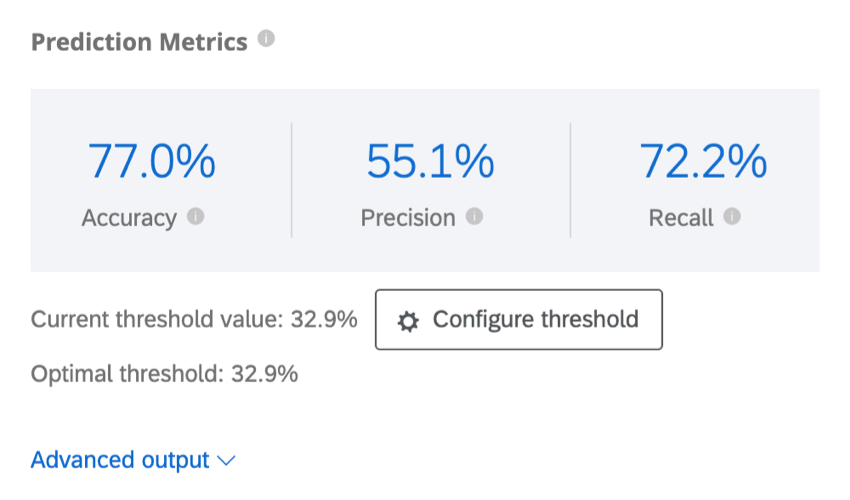
Vorhersagemetriken
Predict iQ 10 % der Daten „hält“ (stillgelegt), bevor Sie das Modell erstellen. Nachdem das Modell angelegt wurde, legt es Prognosen für diese 10 % an. Anschließend vergleicht sie ihre Vorhersagen mit dem, was tatsächlich passiert ist, ob diese Kunden tatsächlich abwandern. Diese Ergebnisse werden verwendet, um die folgenden Genauigkeitskennzahlen zu optimieren. Beachten Sie, dass dies zwar eine effektive Best-Practice-Methode zur Schätzung der Genauigkeit des Modells ist, aber keine Garantie für die zukünftige Genauigkeit des Modells ist.
{kind=link}
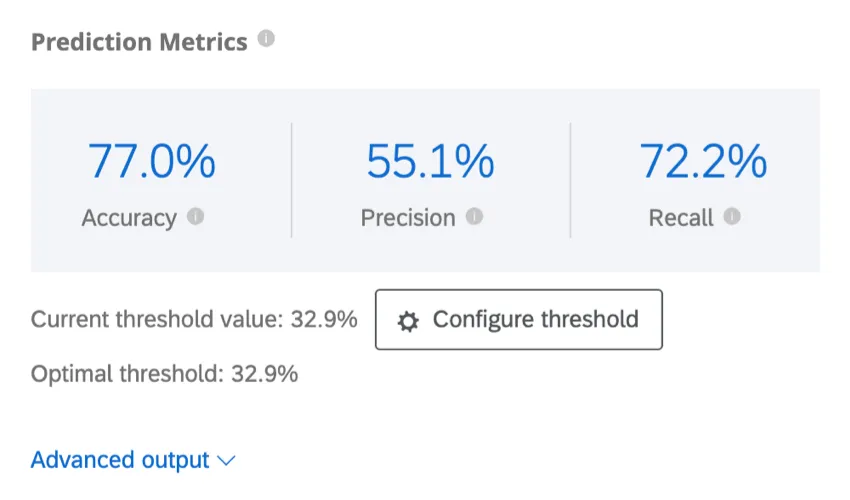
- Genauigkeit: Der Anteil der genauen Vorhersagen des Modells.
- Genauigkeit: Der Anteil der Kunden, deren Abwanderung vorhergesagt wird.
- Rückruf: Der Anteil derjenigen, die tatsächlich abwanderten, dass das im Voraus vorhergesagte Modell dies tun würde.
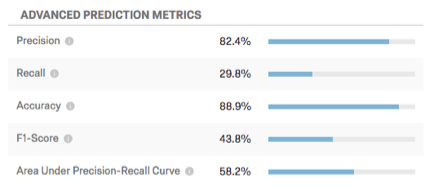
Beispiel: In diesem Screenshot werden die Vorhersagen des Modells 88,9 % der Zeit genau sein. Es ist genau genug, dass 82,4 % der Kunden, für die eine Abwanderung vorhergesagt wurde, abwandern werden. Die Rückrufkennzahl gibt an, dass das Modell eine geschätzte Abwanderung von 29,8 % der Kunden korrekt identifiziert.
Predict iQ berechnet den optimalen Schwellenwert durch Maximierung des F1-Scores. Ihr Modell wird standardmäßig auf den optimalen Schwellenwert gesetzt, Sie können diesen Wert jedoch anpassen; siehe unten Schwellenwert konfigurieren.
Klicken Sie auf Erweiterte Ausgabe unterhalb der Tabelle Prognosekennzahlen, um die Tabellen Matrix und Erweiterte Vorhersagemetriken anzuzeigen.
Präzision und Rückruf
Genauigkeit und Rückruf sind die wichtigsten Vorhersagemetriken. Sie haben eine umgekehrte Beziehung. Daher müssen Sie oft über den Kompromiss nachdenken, ob Sie genau wissen, welche Kunden abwandern werden, und dass Sie wissen, dass Sie alle oder die meisten Kunden identifiziert haben, die wahrscheinlich abwandern.
Beispiel: Stellen Sie sich vor, Sie haben mit jedem einzelnen Kunden Kontakt aufgenommen. Sie würden sich auf jeden Fall an alle wenden, die abwandern (100 % Rückruf), aber Sie würden viele ressourcen und Zeit für Kunden verschwenden, die nie über das Verlassen nachdenken (geringe Genauigkeit). Auf der anderen Seite, wenn Sie nur die einzelne Person Follow-up, die am ehesten abwandern wird, haben Sie wahrscheinlich 100 % Präzision, aber Sie werden viele Kunden vermissen, die letztendlich abwandern (sehr geringer Rückruf).
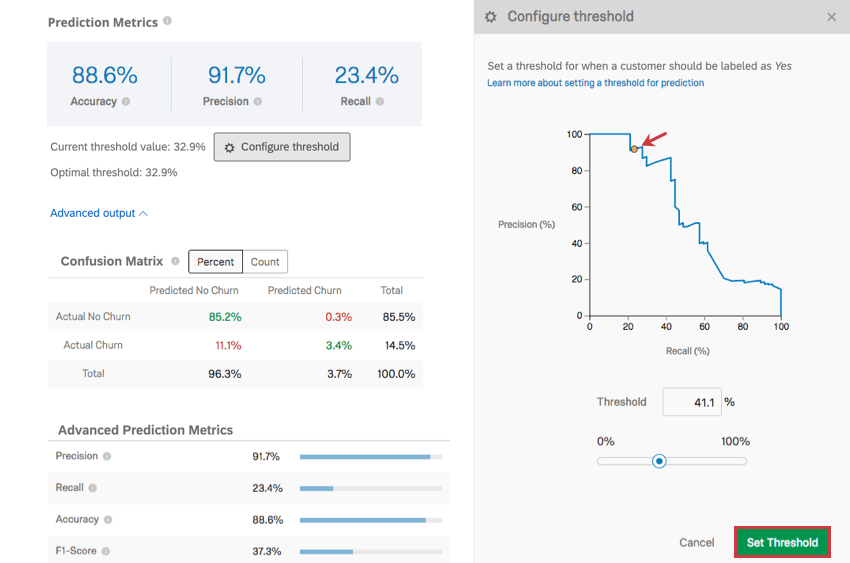
Schwellenwert konfigurieren
Klicken Sie auf Schwellenwert konfigurieren um einen Schwellenwert festzulegen, ab dem ein Kunde als wahrscheinlich für eine Abwanderung gekennzeichnet werden soll. Dieser Schwellenwertprozentsatz ist die individuelle Abwanderungswahrscheinlichkeit.
Beispiel: Das Modell liefert eine Schätzung der Abwanderungswahrscheinlichkeit eines beliebigen Kunden. Angenommen, es gibt drei Kunden mit einer Abwanderungswahrscheinlichkeit von 10 %, 40 % und 75 %. Wenn der Schwellenwert auf 30 % gesetzt ist, werden sowohl die 40 % als auch die 75 % der Kunden als wahrscheinlich für eine Abwanderung gekennzeichnet und erhalten daher eine E-Mail oder einen Anruf. Wenn der Schwellenwert jedoch auf 50 % gesetzt ist, wird nur der 75 %-Kunde als wahrscheinlich für die Abwanderung gekennzeichnet.
{kind=link}
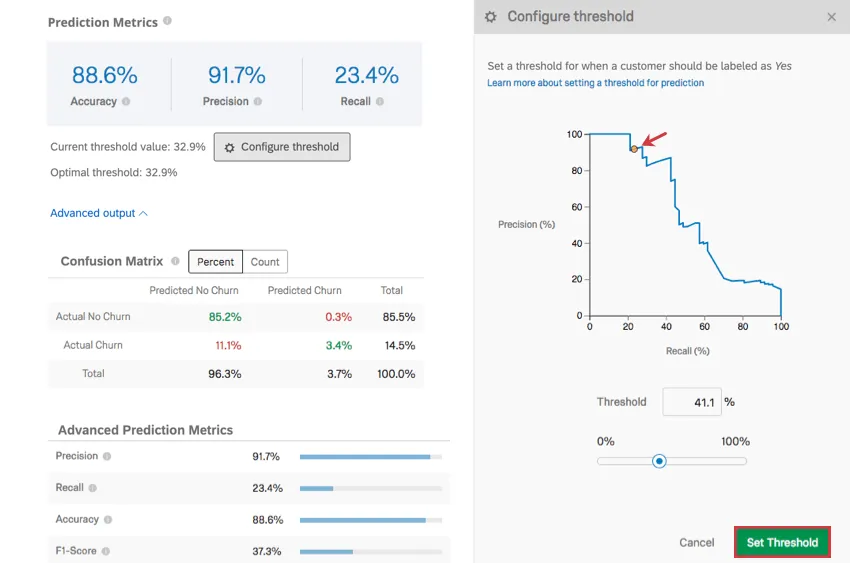
Klicken und ziehen Sie den Punkt im Diagramm, um den Schwellenwert anzupassen, oder geben Sie einen Schwellenwert in % ein, und beobachten Sie, wie sich das Diagramm ändert. Wenn Sie fertig sind, klicken Sie auf Schwellenwert festlegen um Ihre Änderungen zu sichern. Sie können Änderungen auch abbrechen, indem Sie auf klicken. Abbrechen unten rechts oder auf der Registerkarte X oben rechts.
Durch das Anpassen des Schwellenwerts wird die Genauigkeit entlang der Y-Achse und die Wiederholung entlang der X-Achse angepasst. Diese Metriken haben eine umgekehrte Beziehung. Je genauer Ihre Messungen sind, desto niedriger ist der Rückruf und umgekehrt.
Tipp: Das Anpassen des Schwellenwerts ändert die Art und Weise, wie zukünftige Daten gesammelt werden, wenn Sie Erstellen Sie eine Vorhersage, wenn ein neuer Befragte:r diese Umfrage abschließt ausgewählt in der Vorhersagen streamen unten auf der Predict iQ. Um die Abwanderungsdaten Ihres vorherigen Modells zu überschreiben, müssen Sie die Abwanderungsvariable löschen und eine neue Variable hinzufügen. Schwellenwerte wirken sich nicht auf die Variable Abwanderungswahrscheinlichkeit aus, sondern nur auf die binäre Option Ja/Nein.
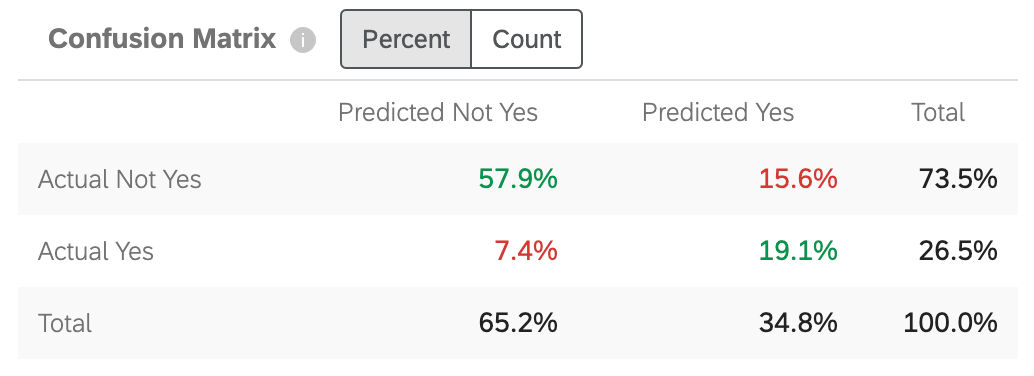
Konfusionsmatrix
Wenn Predict iQ ein Prognosemodell erstellt, hält es 10 % der Daten „zurück“ (oder legt es zurück). Um die Genauigkeit des generierten Modells zu prüfen, werden die Daten aus dem neuen Modell mit dem 10%-Holdout abgeglichen. Dies dient als Vergleich dessen, was vorhergesagt wird und was „tatsächlich passiert ist“.
{kind=link}
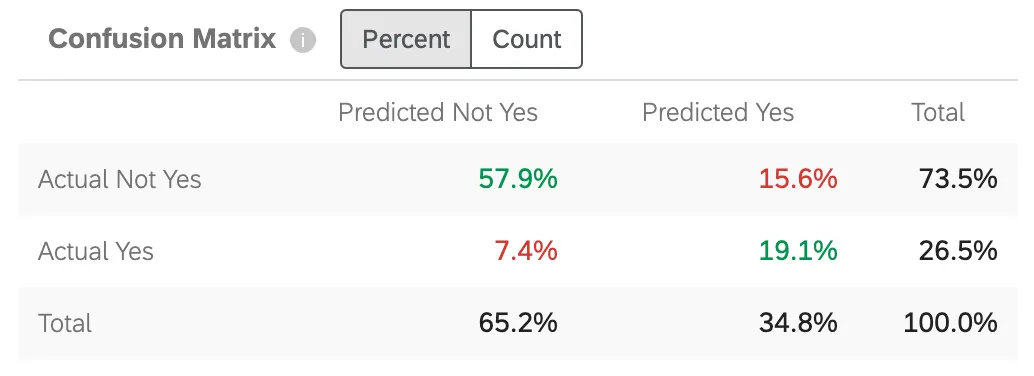
“Ja” in diesem Diagramm wird durch den Ziel ersetzt, den Sie in angegeben haben. Schritt 5 der Einrichtung.
- Ist nicht Ja / Prognostiziert nicht Ja: Der Prozentsatz der Kunden, die das Modell prognostiziert hat, nicht abwandern würden, die tatsächlich nicht abwandern.
- Ist Ja / Prognostiziert nicht Ja: Der Prozentsatz der Kunden, die das Modell prognostiziert hat, nicht abwandern würden, die umgekehrt abwandern.
- Ist nicht Ja / Prognostiziert Ja: Der Prozentsatz der Kunden, die das Modell vorhergesagt hat, würden abwandern, die umgekehrt nicht abwandern.
- Ist Ja/Prognostiziert Ja: Der Prozentsatz der Kunden, die das Modell vorhergesagt hat, würden abwandern, die tatsächlich abwandern.
Zahlen sind grün, um anzugeben, dass diese Zahlen so hoch wie möglich sein sollen, da sie korrekte Vermutungen widerspiegeln. Zahlen sind rot, um darauf hinzuweisen, dass diese Zahlen niedrig sein sollen, da sie falsche Vermutungen widerspiegeln.
Sie können die Matrix so anpassen, dass sie angezeigt wird: Prozent oder Anzahl. Diese Anzahl umfasst die 10 % Ihrer zurückgehaltenen Daten, nicht den vollständigen Datensatz.
Erweiterte Vorhersagemetriken
Diese Tabelle zeigt zusätzliche Vorhersagemetriken an.
{kind=link}
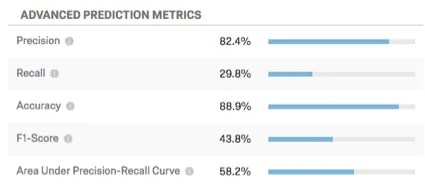
- Genauigkeit: Der Anteil der Kunden, deren Abwanderung vorhergesagt wird.
- Rückruf: Der Anteil derjenigen, die tatsächlich abwanderten, dass das im Voraus vorhergesagte Modell dies tun würde.
- Genauigkeit: Der Anteil der genauen Vorhersagen des Modells.
- F1-Score: Der F1-Score wird verwendet, um einen Schwellenwert auszuwählen, der die Genauigkeit mit dem Rückruf ausgleicht. Ein höherer F1-Score ist in der Regel besser, obwohl der richtige Ort zum Festlegen des Schwellenwerts durch Ihre Geschäftsziele bestimmt werden sollte.
- Bereich unter Precision-Recall-Kurve: Die Precision-Recall-Kurve ist die Kurve, die Sie im Diagramm beobachten, wenn Sie auf Schwellenwert konfigurieren. Die Gesamtfläche unter der Kurve ist ein Maß für die Gesamtgenauigkeit des Modells (unabhängig davon, wo Sie den Schwellenwert festlegen). Ein Bereich unter der Kurve von 50% ist gleich Zufallschance; 100% ist perfekt genau.
Vorhersagen machen
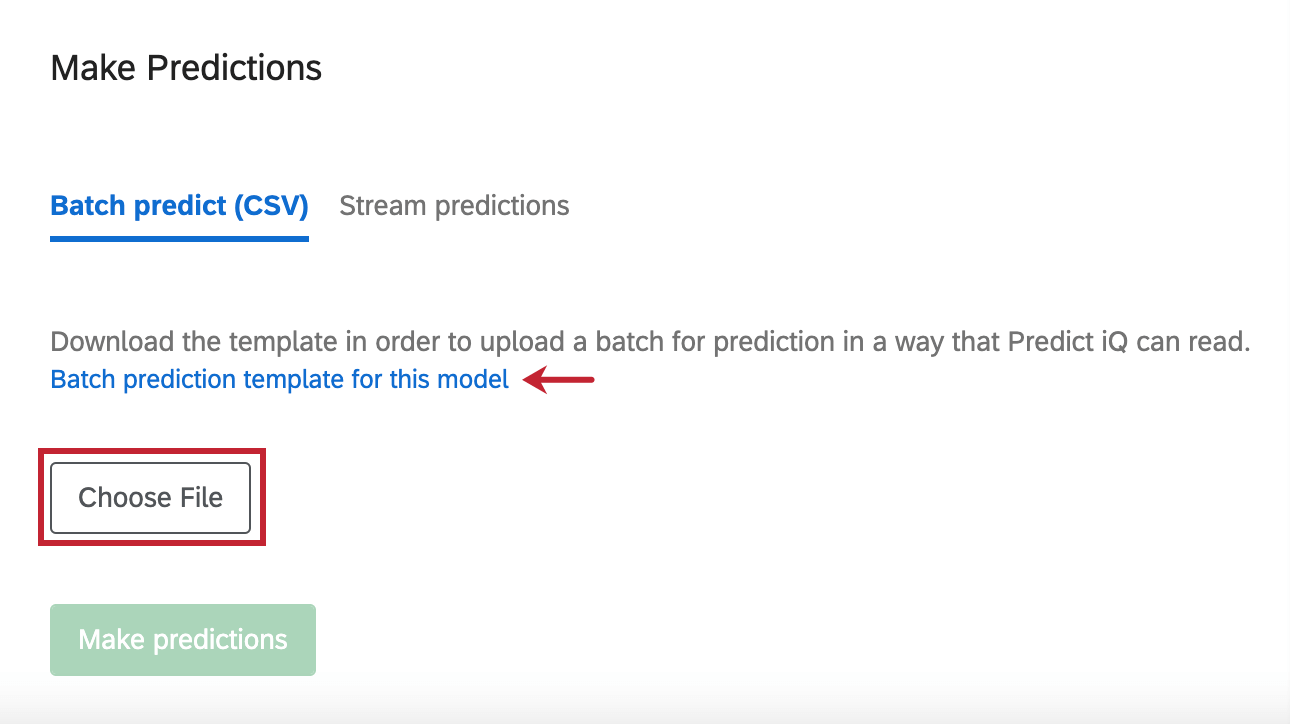
Batch Predict (CSV)
Neben der Analyse der Antworten, die Sie in Ihrer Umfrage erfasst haben, können Sie auch eine bestimmte Datendatei hochladen, die Predict iQ bewerten soll.
{kind=link}
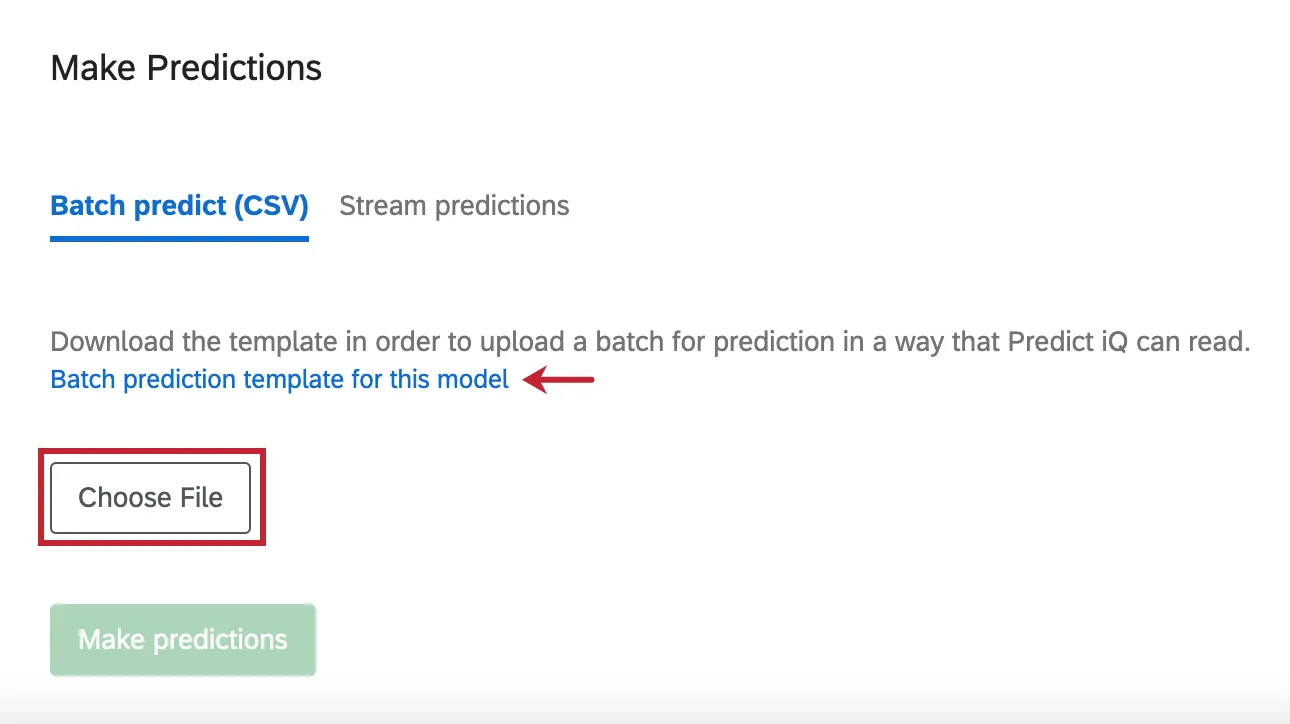
Um eine Vorlage für die Datei zu erhalten, wählen Sie Batch-Vorhersagevorlage für dieses Modell.
Wenn Sie die Bearbeitung Ihrer Datei in Excel abgeschlossen haben und bereit sind, sie erneut hochzuladen, klicken Sie auf Datei auswählen um die Datei auszuwählen. Wählen Sie dann Prognosen erstellen um die Analyse zu starten.
Tipp: Haben Sie Probleme mit Ihrer Vorlagendatei? Siehe Probleme beim Hochladen CSV/TSV Seite.
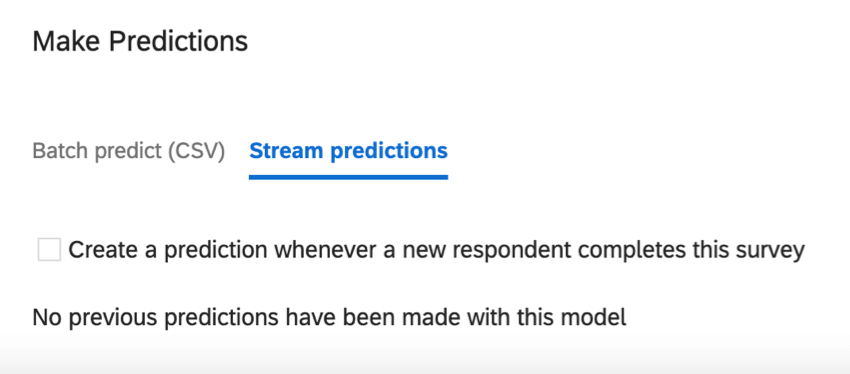
Vorhersagen streamen
Stream-Prognosen werden aktualisiert, wenn Daten in die Umfrage einfließen. In diesem Abschnitt können Sie entscheiden, wann diese Prognoseaktualisierungen stattfinden.
{kind=link}
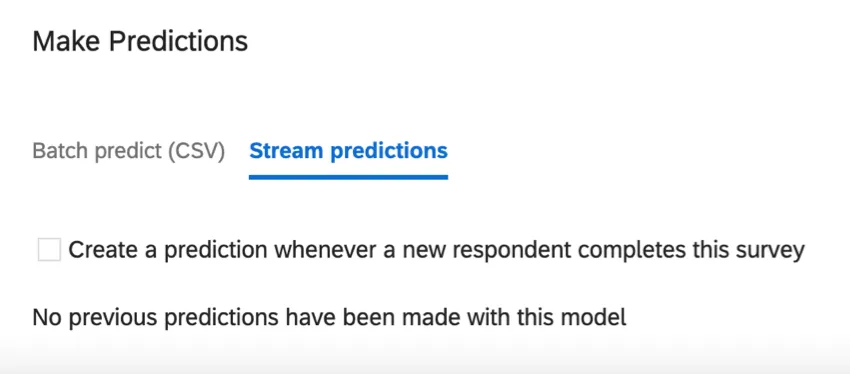
Erstellen Sie eine Prognose, wenn ein neuer Befragte:r diese Umfrage abschließt: Diese Einstellung ermöglicht Echtzeitvorhersagen. Sie haben zwei weitere Spalten in Ihren Daten: Abwanderungswahrscheinlichkeit, Abwanderungswahrscheinlichkeit in einem Dezimalformat und Abwanderungsvorhersage, eine Ja/Nein-Variable. Die Abwanderungsvorhersage basiert auf dem Schwellenwert konfiguriert.
Tipp: Wenn Ihre Daten eingebettete Daten enthalten, die aus einer Nicht-Umfragequelle abgerufen wurden, kommen die Daten möglicherweise nicht sofort nach Abschluss der Umfrage in Qualtrics an. Wenn diese Daten für Prognosen wichtig sind, können Sie warten, bis sie geladen wurden, damit sie eingeschlossen werden können.
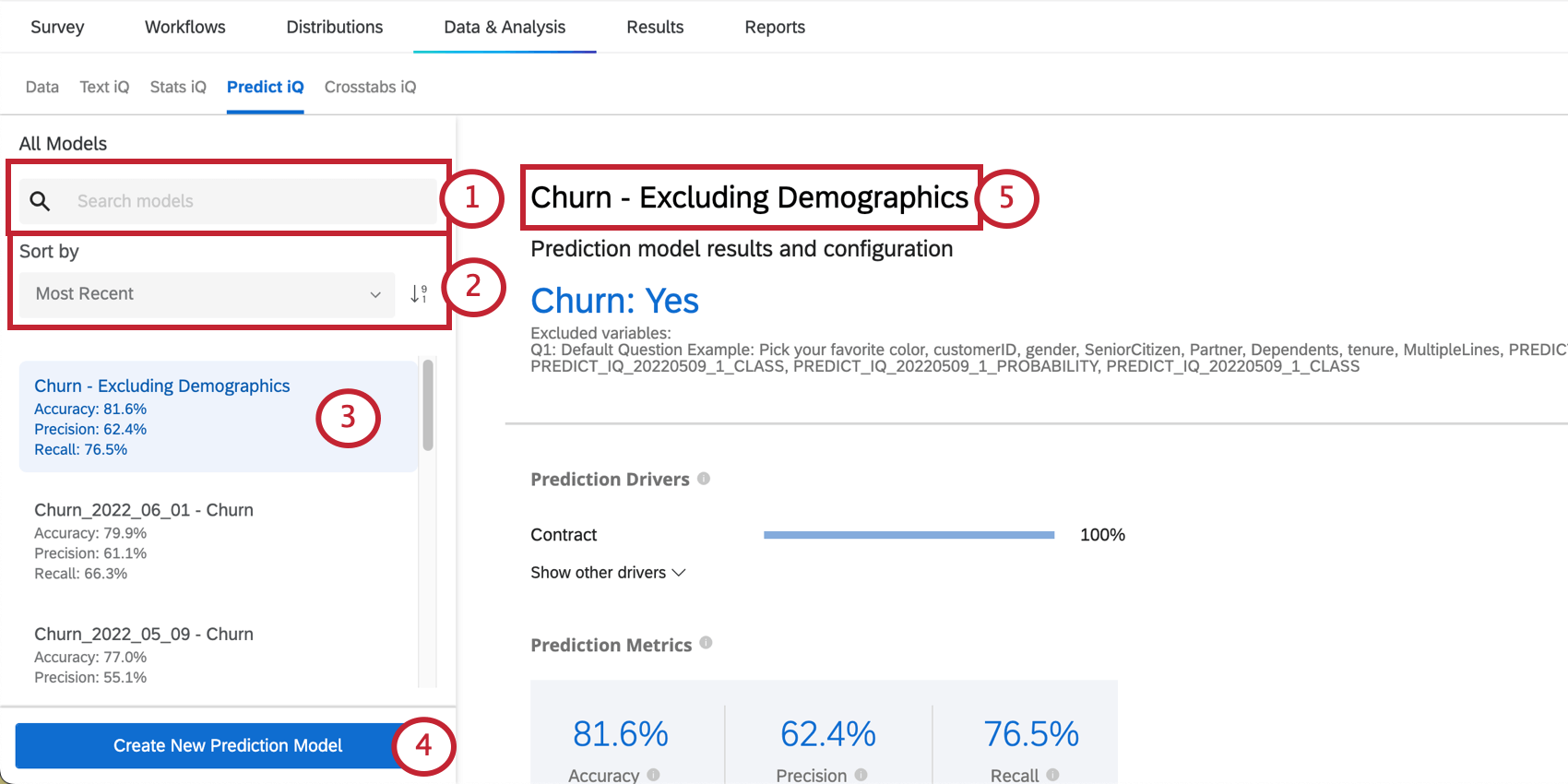
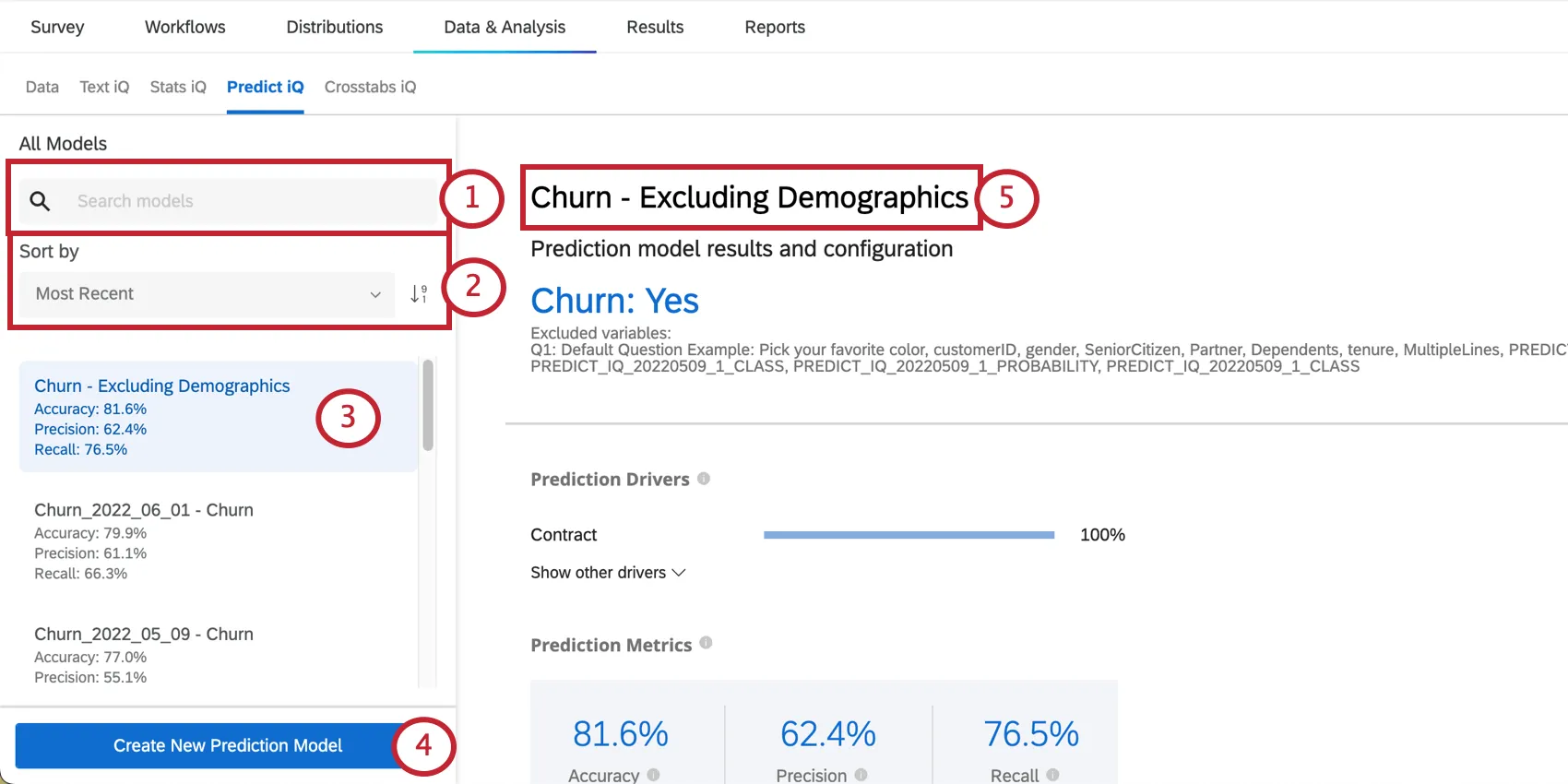
Modelle verwalten
Links auf der Seite sehen Sie ein Menü, in dem Sie durch Prognosemodelle blättern und Prognosemodelle auswählen können, die Sie in der Vergangenheit angelegt haben.
{kind=link}
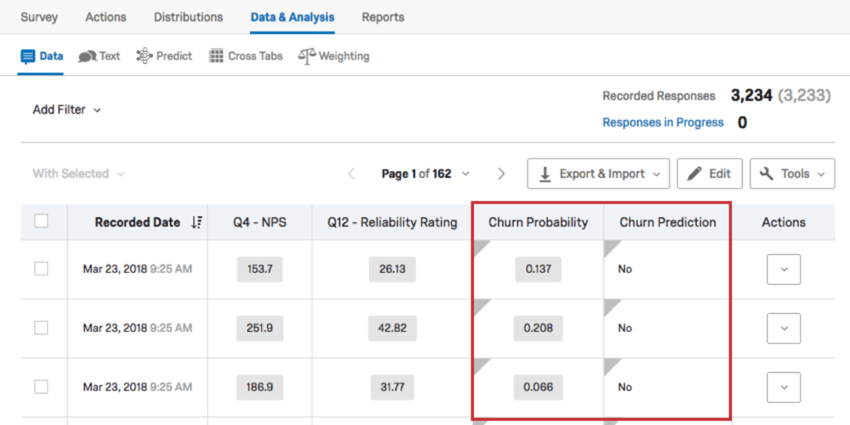
Abwanderungsdaten
Im Abschnitt Daten der Registerkarte Daten & Analyse können Sie Ihre Daten als praktische Tabellenkalkulation exportieren. Nachdem Ihr Prognosemodell geladen wurde, stehen auf dieser Seite zusätzliche Spalten für Abwanderungsdaten zur Verfügung.
{kind=link}
- Abwanderungswahrscheinlichkeit: Die Abwanderungswahrscheinlichkeit in einem Dezimalformat. Wird angezeigt, wenn Stromprognose wurde aktiviert und basiert auf dem festgelegten Schwellenwert. Wenn die Spalte Abwanderungswahrscheinlichkeit nicht angezeigt wird, können Sie auch nach einer Datenspalte mit dem Namen „[ausgewähltes Abwanderungsfeld]_PROBABILITY_PREDICT_IQ“ suchen.
- Abwanderungsvorhersage: Eine Ja/Nein-Variable, die die Abwanderung basierend auf dem festgelegten Schwellenwert bestätigt oder ablehnt. Wird angezeigt, wenn Stromprognose wurde aktiviert. Wenn die Spalte Abwanderungsvorhersage nicht angezeigt wird, können Sie auch nach einer Datenspalte mit dem Namen „[ausgewähltes Abwanderungsfeld]_CLASS_PREDICT_IQ“ suchen.
Beispiel: Wenn das Abwanderungsfeld, das Sie beim Anlegen Ihres Abwanderungsvorhersagemodells ausgewählt haben, den Namen „CustomerChurnFlag“ hat, können die Abwanderungsdatenspalten wie CustomerChurnFlag_CLASS_PREDICT_IQ und CustomerChurnFlag_PROBABILITY_PREDICT_IQ aussehen.
Spaltennamen enthalten auch das Datum, an dem das Modell im Format MMTTJJJJ trainiert wurde. Beispiel: Der 14. Januar 2022 wird im Spaltennamen als 01142022 dargestellt.
Beachten Sie, dass Abwanderungswahrscheinlichkeiten und Vorhersagen nur für neue Ergebnisse von Umfragen übernommen werden. Bisher vorhandene Antworten werden keine Abwanderungswahrscheinlichkeiten und Vorhersagen hinzugefügt.
Tipp: Nachdem Sie diese Variablen angelegt haben, können sie mithilfe von Ergebnisberichte oder Erweiterte Berichte, genau wie jede andere Variable.
Automatische Datenbereinigung
Beim schulung des Modells ignoriert Predict iQ automatisch bestimmte Variablentypen, die für Prognosen nicht nützlich sind, während andere Variablen automatisch transformiert werden.
Variablen mit hoher Kardinalität
Wenn eine Variable mehr als 50 eindeutige Werte hat oder mehr als 20 % der erfassten Werte eindeutig sind, wird sie beim schulung ignoriert. Variablen mit zu vielen eindeutigen Werten sind keine guten Funktion für Prognosen.
Beispiel: Wenn Sie beispielsweise eine Variable haben, die Landkreis – USAwird diese Variable beim schulung ignoriert, da es mehr als 3000 Countys in den USA in allen 50 Bundesstaaten gibt.
Beispiel: Betrachten Sie als weiteres Beispiel eine Variable wie Lieblings-Eiscreme-Aroma Angenommen, Sie haben 100 Datenzeilen für diese Variable. Unter diesen 100 Reihen stellen Sie fest, dass es 21 einzigartige Werte für Eiscreme-Geschmack gibt. Diese Variable wird beim schulung ignoriert, da mehr als 20 % der erfassten Werte eindeutig sind.
Fehlende Werte für numerische Spalten
Für numerische Variablen, die im Modell enthalten sind, werden fehlende Werte immer auf 0 (null) angerechnet.
One-Hot-Kodierung von Kategorien
Kategorische Variablen werden einheiß kodiert wenn die Variable nicht umkodiert oder die Variable hat keine Beziehung für ihre Kategorien.
Tipp: Predict iQ übernimmt dasselbe In Stats iQ verwendete Variableneinstellungen .
Invariantenvariablen
Jede Variable, die keine Abweichung in ihren erfassten Werten aufweist, wird für das schulung ignoriert. Das bedeutet, dass eine Variable, die nur einen einzigen eindeutigen Wert hat, nicht Teil des Modells ist. Variablen, die für die Prognose nützlich sind, bilden ein gutes Gleichgewicht zwischen zu wenigen eindeutigen Werten und zu vielen eindeutigen Werten. Siehe „Variablen mit hoher Kardinalität“ oben.
Wenn invariante Variablen während der Datenbereinigung ausgeschlossen werden, werden sie im Abschnitt Ergebnisse und Konfiguration.
Projekte, in denen Sie Predict iQ verwenden können
Predict iQ ist nicht in jeder Lizenz enthalten. Wenn Sie jedoch über diese Funktion verfügen, kann sie in einigen verschiedenen Projekte:
Predict iQ kann auch in Engagement und Lebenszyklus Projekte, aber basierend auf der Art der Daten, die in der Regel von diesen Projekttypen gesammelt werden, wäre der Datensatz nicht unbedingt am besten für Predict iQ.
Während Predict iQ in Conjoin und MaxDiff, tun wir nicht empfiehlt, sie zusammen zu verwenden. Conjoint- und MaxDiff-spezifische Inhalte sind nicht mit Predict iQ kompatibel, sodass Sie nur demografische Daten analysieren können.
Andere Projektarten werden nicht unterstützt.
Tipp: Die in diesem Abschnitt aufgeführten Projekte sind nicht in jeder Lizenz verfügbar.
Großartig! Vielen Dank für die Rückmeldung!
Vielen Dank für die Rückmeldung!