Filtern nach strukturierten Daten (Designer)
Was finden Sie hier?
Informationen zum Filtern nach strukturierten Daten
Verwenden Sie strukturierte Datenattribute, um Feedback in Modelle zu filtern, die die relevantesten Informationen aus Ihrem Datenset kategorisieren und anzeigen. Informationen zum Anlegen und Bearbeiten von Filtern finden Sie unter. Filtern von Daten (Designer).
Tipp: Die meisten strukturierten Filter werden mithilfe von Attributen angelegt. Weitere Informationen zum Anlegen und Bearbeiten von Attributen in XM Discover finden Sie unter. Attribute.
Nach Stimmung filtern
XM Discover verwendet Stimmungsanalyse, um die Stimmung des Feedback zu ermitteln. Stimmung ist als Attribut mit vordefinierten Bändern verfügbar:
- Negative Stimmung: Feedback mit einem Stimmung von -5.0 bis -1.0
- Neutrale Stimmung: Feedback mit einem Stimmung von -0,99 bis 0,99
- Positive Stimmung: Feedback mit einem Stimmung von 1 bis 5.0
TIPP: Mit dem Attribut STIMMUNG-System können Sie benutzerdefinierte Stimmungsbereiche erstellen. Beispiel: _fetesentimentindex:[2.51 TO 5].
Nach Sprache filtern
Verwenden Sie die folgenden Systemattribute, um nach Datentyp zu filtern:
- CB Auto-detected Language ( _languagedetected ): Das Feedback zur Sprache wurde übermittelt, wenn Ihr Projekt die automatische Spracherkennung verwendet.
- CB Processed Language ( _language ): Das sprachliche Feedback wurde in eingereicht. Wenn die Sprache von XM Discover nicht unterstützt wird, wird sie als „OTHER“ gekennzeichnet.
XM Discover ist in der Lage, Daten mit über 150 Sprachen mithilfe der Funktion Automatische Spracherkennung zu erkennen und zu taggen. Ohne automatische Spracherkennung sind die folgenden Sprachen verfügbar:
- Arabisch
- Bengali
- Chinesisch (vereinfacht und traditionell)
- Niederländisch
- Englisch
- Französisch
- Deutsch
- Hindi
- Indonesisch
- Italienisch
- Japanisch
- Koreanisch
- Polnisch
- Portugiesisch
- Rumänisch
- Russisch
- Spanisch
- Schwedisch
- Tagalog
- Thailändisch
- Türkisch
- Vietnamesisch
Achtung: Versionen mit weniger als 10 Zeichen werden als Englisch getaggt.
Nach Datentyp filtern
Um Feedback nach dem Typ der übermittelten Daten zu filtern, verwenden Sie die folgenden Systemattribute:
- Quellen-ID ( _id_source ): Die Datenquelle der Sätze.
- Verbatim-Typ ( _verbatimtype ): Der Name des Verbatim-Feldes, nach dem Sie filtern möchten. Dies ist nützlich, wenn Sie mehrere ausführliche Spalten haben.
Beispiel: Angenommen, Sie haben zwei ausführliche Spalten: Prüfung und Antwort. Legen Sie eine Regel für an. _verbatimtype:Review, um ein Modell zurückzugeben, das nur Daten aus der Spalte Ausführliche Informationen überprüfen anzeigt.
Nach Inhaltstyp filtern
Verwenden Sie für Projekte mit aktivierter Inhaltstyperkennung die folgenden Systemattribute, um Feedback aus Anzeigen, Spam und anderen nicht umsetzbaren Daten zu filtern:
- CB Inhaltstyp ( cb_content_type ): Angabe, ob Dokumente als inhaltsreich, d.h. mit einem Mittelwert, oder als nicht inhaltsreich gekennzeichnet sind.
- CB Content Subtype ( cb_content_subtype ): Gruppiert Dokumente, die als nicht inhaltsreich gekennzeichnet sind, in Anzeigen, Gutscheine, Artikellinks oder “undefiniert”.
Beispiel: Wenn Sie ein Modell erstellen möchten, das nur inhaltliche Daten kategorisiert, legen Sie eine Regel mit dem Attribut CB-Inhaltstyp an: cb_content_type:contentful.
Nach Satzart filtern
XM Discover verwendet semantische Analysen, um Absichten zu identifizieren, die für Ihre Analysen relevant sind. Diese Kategorien werden im Attribut auf Satzebene verwendet: Satzart VB ( cb_sentence_type ). Die Analyse der Art der Absicht, die in Ihren Daten verwendet wird, kann dabei helfen, zu verstehen, wie die Kundenerfahrung verbessert werden kann.
Klicken Sie auf die folgenden Satzarten, um zu sehen, was mit dem Attribut identifiziert wird:
Tipp: Sätze, die keiner der Satzarten entsprechen, werden als UNDEFINED gekennzeichnet.
Nach Wortanzahl filtern
Verwenden Sie die Satzwortanzahl oder die Dokumentwortanzahlattribute, um Ihre Daten nach der Anzahl der Wörter in Ihrem Satz oder Datensatz zu filtern. Der in diesen Attributen festgelegte Bereich umfasst Werte. Wenn die Wortanzahl null ist, hat der Satz/Datensatz entweder keinen Text oder wurde geladen, bevor die Funktion aktiviert wurde.
- CB Sentence Word Count ( cb_sentence_word_count ): Mit dem Attribut auf Ebene des Satzes können Sie Daten nach der Anzahl der Wörter in einem Satz filtern. Tipp: Um Sätze mit 10 oder weniger Wörtern anzuzeigen, verwenden Sie den Bereich cb_sentence_word_count: [1 TO 10].

- CB Document Word Count ( cb_document_word_count ): Mit dem Attribut auf Ebene des Datensatzes können Sie Daten nach der Anzahl der Wörter in einem Datensatz filtern. Dies ist auch die Summe aller Satzwortzähler. Tipp: Um Datensätze mit 50 oder mehr Wörtern anzuzeigen, verwenden Sie cb_document_word_count: [50 TO 200].
Nach Satzquartil filtern
Das Attribut CB Sentence Quartile ( cb_sentence_quartile ) kennzeichnet den Teil des Wortlauts, in den ein Satz mündet. Die Werte sind 1-4, wobei jeder Abschnitt 25 % der ausführlichen Länge darstellt. Wenn ein Datensatz mehrere ausführliche Angaben enthält, gibt es Quartile für jedes ausführliche Datum im Datensatz.
Tipp: Dieses Attribut kann hilfreich sein, wenn Sie sich darauf konzentrieren möchten, warum Kunden anrufen. Dies wird in der Regel im ersten Quartil ( 1) der ausführlichen Beschreibung erläutert. Wenn Sie daran interessiert sind, wie Vertreter ihre Anrufe beenden, können Sie Ihre Berichte alternativ auf das letzte Quartil ( 4 ) beschränken.
Anwenden des Satzquartils
Wenn in Ihren historischen Daten Satzquartildaten fehlen, können Sie diese Ihren Daten hinzufügen.
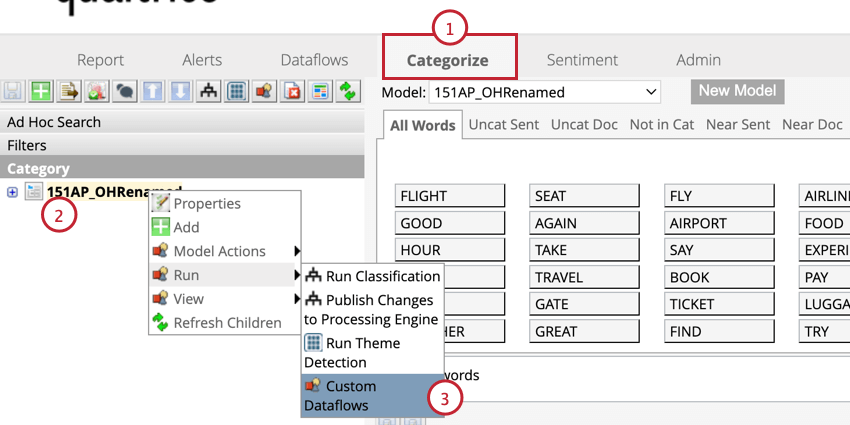
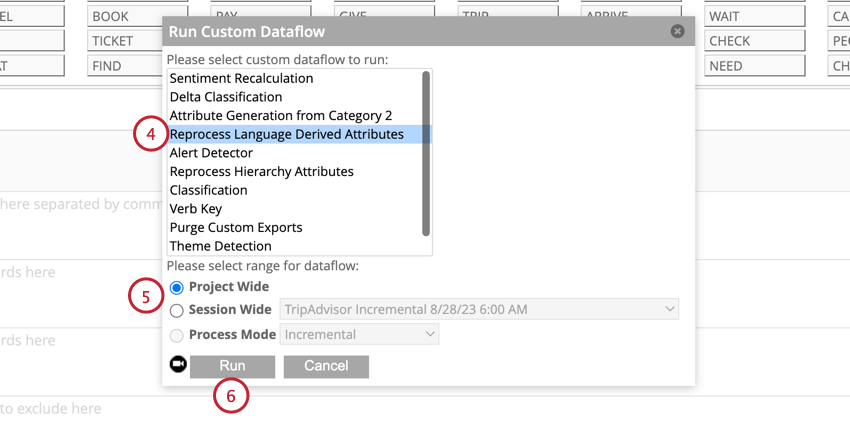
Nach Aufwand filtern
CB-Aufwand misst den Ebene, der von den Kunden während ihrer Erfahrung ausgedrückt wird. Dieses Attribut ist auf Satzebene auf einer Skala von -5 bis 5 verfügbar, wobei -5 die härteste Erfahrung und 5 die einfachste Erfahrung angibt. Der Bereich umfasst Werte.
TIPP: Um Sätze anzuzeigen, in denen die Ebene des Aufwands sehr hoch ist, können Sie den Bereich: cb_sentence_ease_score:[-5 to -3] verwenden.
Tipp: CB-Aufwand ist nur mit ganzen Zahlen kompatibel.
Nach Loyalty-Beschäftigungsdauer filtern
CB-Loyalty-Beschäftigungsdauer Mit können Sie Daten nach der Zeit in Jahren filtern, die ein Kunde eine Serviceleistung in Anspruch genommen hat oder der ein Produkt gehört hat. Dieses Attribut ist auf Satzebene in Sätzen mit der Satzart Beschäftigungsdauer verfügbar. Der Bereich umfasst Werte.
Beispiel: Der Satz „Ich bin seit 10 Jahren Kunde“ wird einen Loyalty-Tenure-Wert von 10 zurückgeben. Um Sätze mit einer Dauer von bis zu 10 Jahren anzuzeigen, verwenden Sie den folgenden Bereich: cb_loyalty_tenure:[1 TO 10].
Nach Interaktionsart filtern
CB-Interaktionsart ( cb_interaction_type ) definiert Daten nach der Art der XM, mit der Sie reguläres Feedback von dialogorientierten Daten unterscheiden können. Dieses Attribut ist auf Dokument-, ausführlicher und Satzebene verfügbar.
Die Interaktionsart kann folgende Werte haben:
- Chat: Konversationsdaten aus digitalen Kanälen.
- Feedback: Regelmäßige Feedback-Daten (wie Online-Erwähnungen, Beurteilungen usw.).
- UMFRAGEN: Antwortdaten aus einer Umfrage.
- Sprachdienste: Konversationsdaten aus transkribierten Unterhaltungen im Audio.
Großartig! Vielen Dank für die Rückmeldung!
Vielen Dank für die Rückmeldung!