Conector de entrada de upload de arquivos ad hoc
Suite
Customer Experience
Produto
Qualtrics
O que há nesta página
Sobre o conector de entrada Ad-Hoc File Upload
Você pode usar o conector de entrada de upload de arquivo ad-hoc para carregar os dados do cliente por meio de um upload de arquivo. Os trabalhos de upload de arquivos ad-hoc ocorrem uma única vez e cada trabalho deve ser agendado separadamente.
As tarefas de arquivo ad-hoc permitem que você carregue dados nos seguintes formatos:
- Arquivos de texto plano delimitado (CSV, TSV, etc.)
- XLS ou XLSX
- JSON
- WebVTT
Configuração de uma tarefa de upload de arquivo ad hoc
Qdica: a permissão “Manage Jobs” (Gerenciar trabalhos) é necessária para usar esse característica.
Na guia Jobs, clique em New Job.
Selecione Ad-Hoc File Upload.


Dê um nome ao seu trabalho para que você possa identificá-lo.

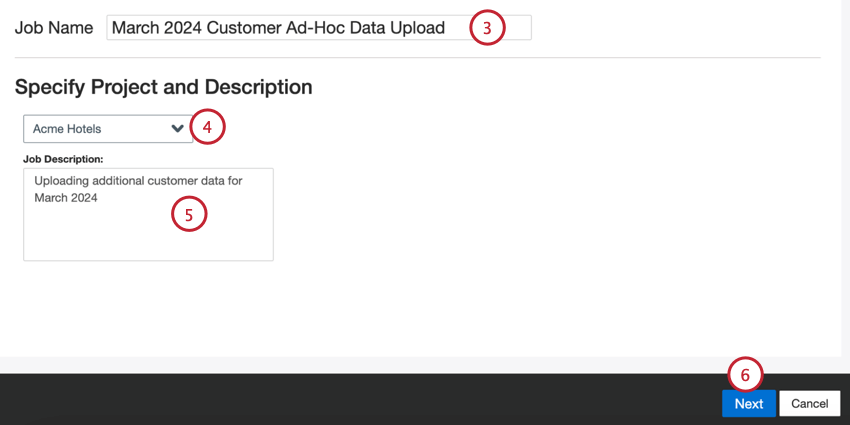
Escolha o projeto para carregar os dados.
Faça uma descrição do seu trabalho para que você saiba o propósito dele.
Clique em Seguinte.
Escolha o tipo de arquivo que deseja carregar:

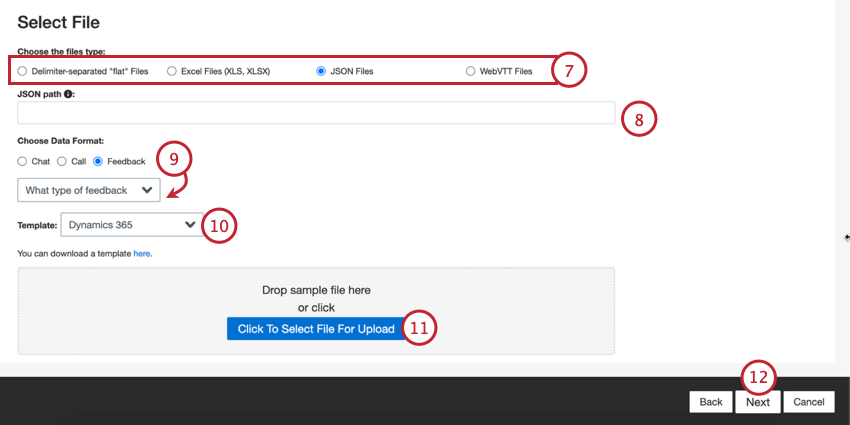
- Arquivos “planos” separados por delimitadores
- Arquivos do Excel (XLS, XLSX)
- Arquivos JSON
- Arquivos WebVTT
Dependendo do tipo de arquivo selecionado, preencha as configurações adicionais do arquivo:
- Arquivos simples separados por delimitadores: Para arquivos separados por delimitadores, escolha o seguinte:
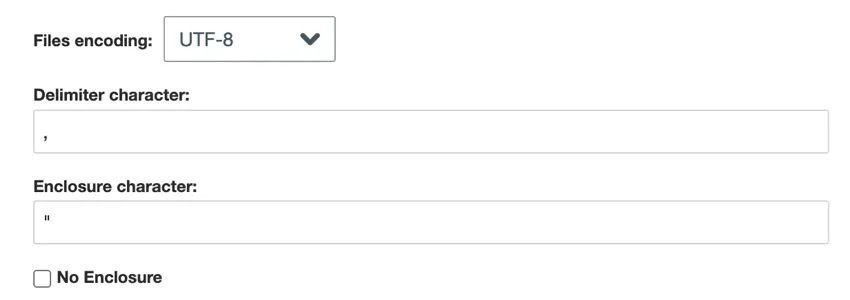
- Codificação do arquivo: Escolha o sistema de codificação do arquivo (UTF-8, ASCII, etc.).
- Caractere delimitador: Digite o caractere usado para delimitar as entradas de dados. Por padrão, é uma vírgula para arquivos CSV.
- Caractere de fechamento: Digite o caractere que envolve a entrada de dados. Deixe esse campo em branco se a opção Nenhum compartimento for selecionada.
- No enclosure: ative essa opção se o seu arquivo não contiver caracteres de delimitação.
- JSON: insira o caminho JSON que contém os dados do documento que você deseja carregar no XM Discover. Deixe esse campo em branco se seus documentos estiverem no nível raiz.

- Pule para a avançar etapa para arquivos Excel e WebVTT.

Escolha o tipo de dados que você deseja importar:
- Bate-papo: Interações digitais com várias linhas de diálogo entre dois ou mais participantes.
- Chamada: Transcrições de chamadas com várias linhas de diálogo entre dois ou mais participantes.
- Comentários: Documentos apresentados como objetos de uma única linha ou “planos”. Qdica: se você selecionou “feedback”, será exibido um segundo menu para que você escolha o tipo de dados de interação incluídos no feedback. Suas opções incluem chamada, bate-papo, e-mail, avaliação, social e pesquisa.

Qdica: dependendo do tipo de arquivo, alguns tipos de dados não são compatíveis. Por exemplo, os arquivos WebVTT só podem ser usados para carregar transcrições de chamadas.
Se necessário, você pode selecionar um arquivo de modelo para download. Clique no link aqui para fazer o download do modelo selecionado. Use esse arquivo para adicionar os dados que você deseja importar para o XM Discover. Consulte a página de suporte XM Discover Data Formats para obter informações específicas sobre a formatação de cada arquivo e tipo de dados.
Clique no botão Click Here to Select File For Upload e escolha o arquivo em seu computador. Seus dados serão exibidos como uma visualização na parte inferior da página.
Qdica: consulte Erros de arquivos Amostra se precisar de ajuda para solucionar problemas com o arquivo de upload.
Clique em Seguinte.
Se necessário, ajuste seus mapeamentos de dados. Consulte a página de suporte do Mapeamento de dados para obter informações detalhadas sobre o mapeamento de campos no XM Discover. A seção Default Data Mapping (Mapeamento de dados padrão ) contém informações sobre os campos específicos desse conector e a seção Conversational Fields (Campos de conversação ) aborda como mapear dados para dados de conversação.

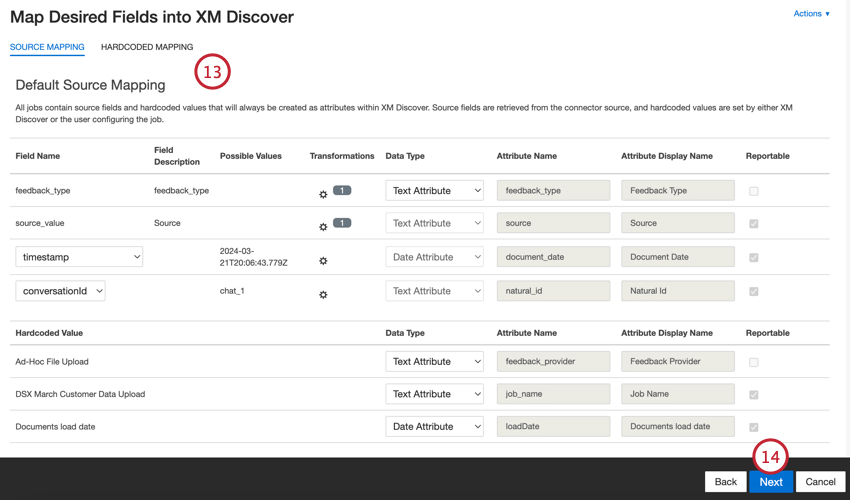
Clique em Seguinte.
Se desejar, você pode adicionar regras de substituição e redação de dados para ocultar dados confidenciais ou substituir automaticamente determinadas palavras e frases no feedback e nas interações do cliente. Consulte a página de suporte de Substituição e Redação de Dados para obter mais informações.
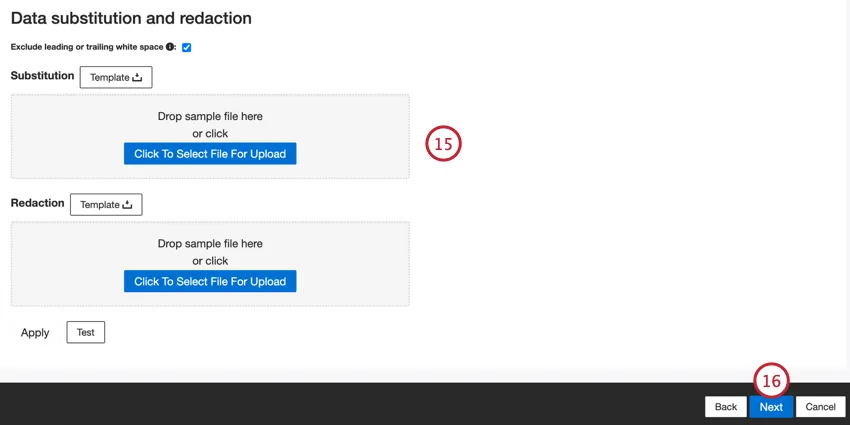
Clique em Seguinte.
Se desejar, você pode adicionar um filtro de conector para filtro os dados de entrada e limitar os dados importados.

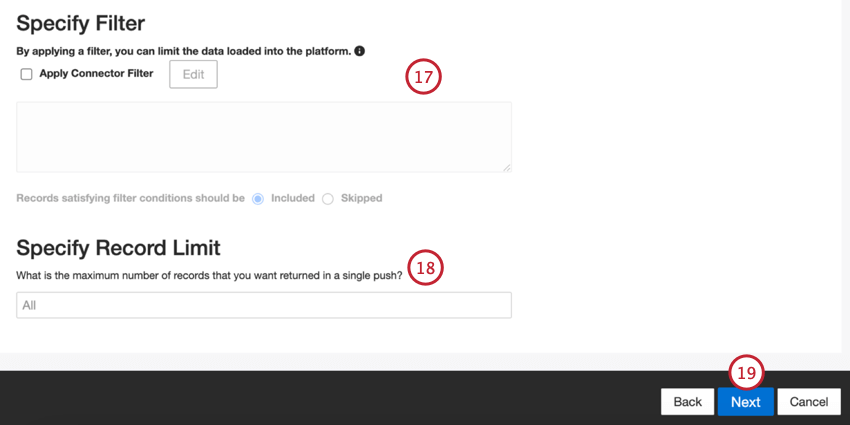
Também é possível limitar o número de registros importados em um único trabalho inserindo um número na caixa Specify Record Limit (Especificar limite de registros ). Digite “All” se quiser importar todos os registros.
Qdica: para dados de conversação, o limite é aplicado com base em conversações e não em linhas.
Clique em Seguinte.
Escolha quando você gostaria de ser notificado. Consulte Notificações de trabalho para obter mais informações.

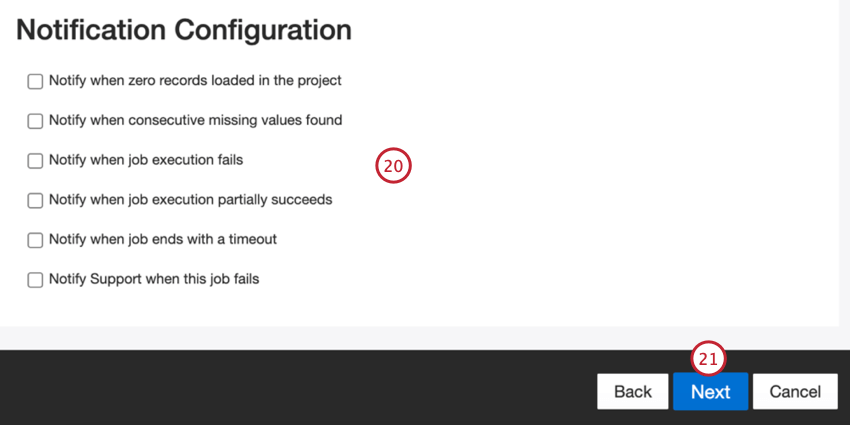
Clique em Seguinte.
Escolha como os documentos duplicar são tratados. Consulte Tratamento de Duplicar para obter mais informações.

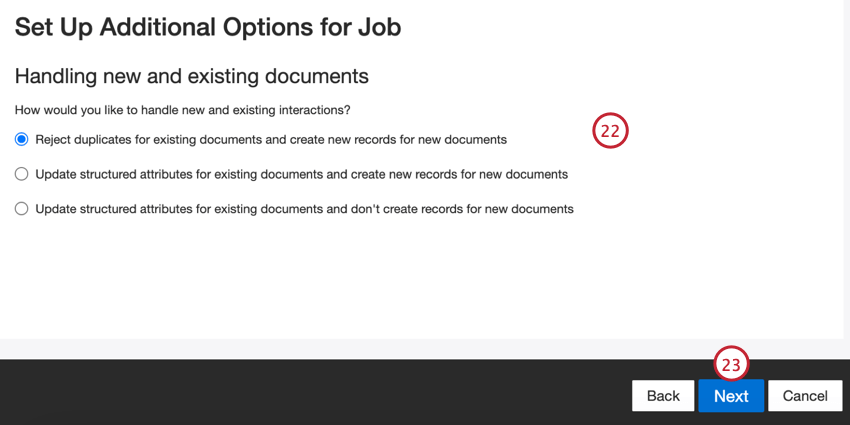
Clique em Seguinte.
Revise sua configuração. Se você precisar alterar uma configuração específica, clique no botão Edit (Editar ) para ser levado a essa etapa na configuração do conector.

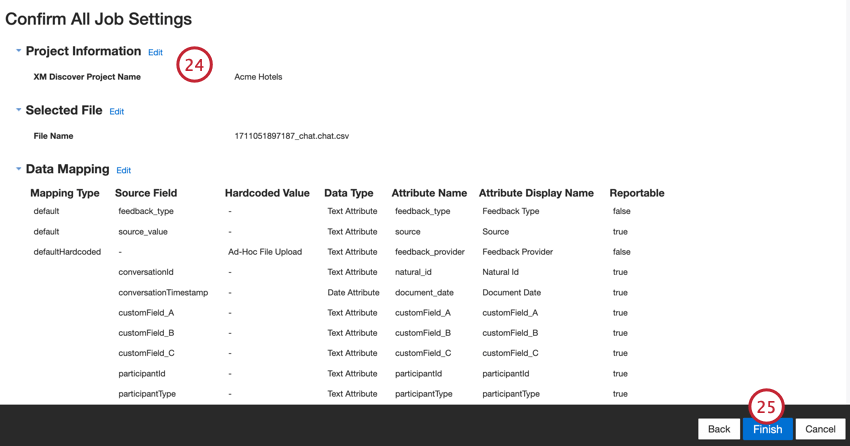
Clique em Finish (Concluir ) para salvar o trabalho.
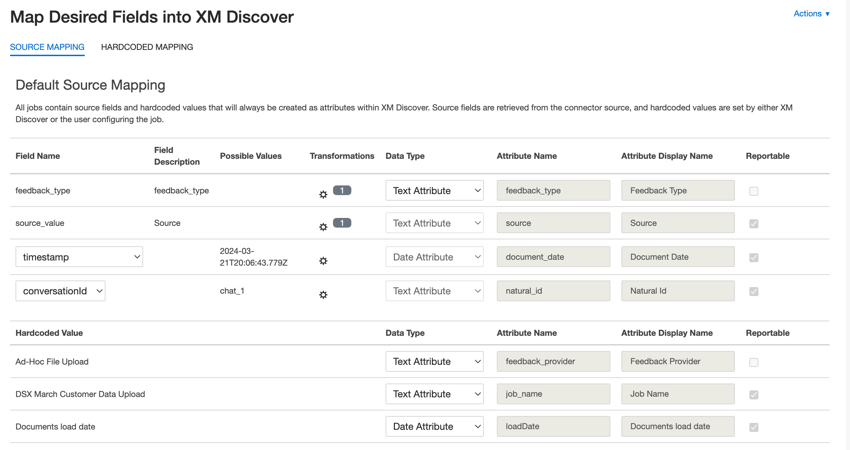
Mapeamento de dados padrão
Esta seção contém informações sobre os campos padrão para trabalhos de entrada de upload de arquivos ad hoc.
{kind=link}
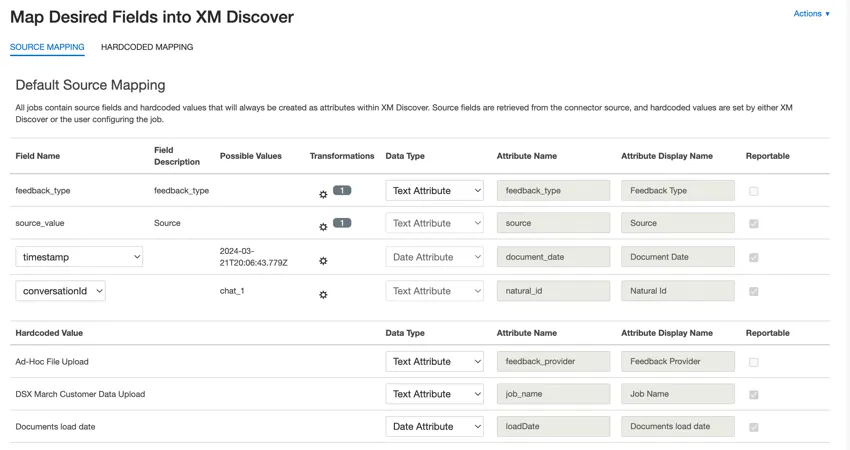
- feedback_type: Identifica os dados com base em seu tipo. Isso é útil para a geração de relatórios quando o seu projeto contém diferentes tipos de dados (por exemplo, pesquisas e feedback de mídia social). Por padrão, o valor desse atributo é definido como “call” para transcrições de chamadas, “chat” para interações digitais ou “feedback” para feedback individual. Use transformações personalizadas para definir um valor personalizado, definir uma expressão ou mapeá-lo para outro campo.
- source_value: Identifica os dados obtidos de uma fonte específica. Isso pode ser qualquer coisa que descreva a origem dos dados, como o nome de uma pesquisa ou de uma campanha de marketing móvel. Por padrão, o valor desse atributo é definido como “Ad-Hoc File Upload” Use transformações personalizadas para definir um valor personalizado, definir uma expressão ou mapeá-lo para outro campo.
- document_date: o campo de data primária associado a um documento. Essa data é usada nos relatórios, tendências e alertas XM Discover, entre outros. Você pode usar qualquer campo de data em seu conjunto de dados para a data do documento. Você também pode definir uma data específica para o documento.
- natural_id: Um identificador exclusivo de um documento. É altamente recomendável ter um ID exclusivo para cada documento para processar as duplicatas corretamente. Para Natural ID, você pode selecionar qualquer campo de texto ou numérico de seus dados. Como alternativa, você pode gerar IDs automaticamente adicionando um campo personalizado.
- feedback_provider: Identifica os dados obtidos de um provedor específico. Para uploads de arquivos, o valor desse atributo é definido como “Ad-Hoc File Upload” e não pode ser alterado.
- job_name: Identifica os dados com base no nome do trabalho usado para carregá-los. Você pode modificar o valor desse atributo durante a configuração por meio do campo Job Name (Nome do trabalho ), exibido na parte superior de cada página durante a configuração.
- loadDate: indica quando um documento foi carregado no XM Discover. Esse campo é definido automaticamente e não pode ser alterado.
Qdica: consulte Mapeamento de campos de conversação para obter informações sobre como mapear dados de conversação.
Muitas das páginas neste site foram traduzidas do inglês original usando tradução automática. Embora na Qualtrics tenhamos feito nossa diligência prévia para obter as melhores traduções automáticas possíveis, a tradução automática nunca é perfeita. O texto original em inglês é considerado a versão oficial, e quaisquer discrepâncias entre o inglês original e as traduções automáticas não são juridicamente vinculativas.
Isso é ótimo! Obrigado pelo seu feedback!
Obrigado pelo seu feedback!