Análise de Cluster
O que há nesta página
Sobre a análise Cluster
Quando analisamos nossos dados, geralmente nos preocupamos com diferentes grupos demográficos e segmentamos os entrevistados por renda, região, idade e muito mais. Mas, às vezes, esses rótulos podem ser reducionistas – afinal, saber que você tem muitos entrevistados do sexo masculino não lhe diz que tipo de campanha publicitária eles gostariam de ver. Seu público-alvo é formado principalmente por millenials? Pais do futebol? Ambos? Como você coloca as características pessoais em termos que podem ser divididos para fins de marketing?
A análise Cluster é um meio de detectar os grupos que ocorrem naturalmente no conjunto de dados de sua pesquisa. Isso é feito por meio da análise de quais qualidades demográficas, comportamentais e/ou baseadas em crenças são as mais altamente correlacionadas.
{kind=link}

Qdica: Você pode ter até 750 cartões em seu área de trabalho. Se você atingir esse limite, será exibido um erro quando você tentar criar um novo cartão, avisando que os cartões mais antigos serão excluídos.
Preparação de uma Pesquisa para análise Cluster
Para realizar uma análise cluster, é necessário coletar os dados corretos em sua pesquisa.
- Faça as perguntas certas:
- Dados demográficos: Pergunte sobre informações descritivas básicas, como idade, faixa de renda, raça ou gênero.
- Comportamento: Pergunte como os clientes interagem com sua marca e seus produtos, ou sobre comportamentos que possam estar relacionados ao comportamento de compra deles. Por exemplo, você pode perguntar com que frequência o cliente vai às compras.
- Dadosoperacionais : São informações como o tempo gasto em seu site ou o tempo de permanência de um colaborador em sua empresa. Qdica: você tem interesse em monitorar o tempo gasto em uma página? Então, talvez seja interessante usar o característica Feedback do site. Contato seu executivo Conta se estiver interessado em saber mais.

- Atitudes e crenças: Pesquisa seus entrevistados sobre seus valores fundamentais, suas atitudes e crenças. Isso pode incluir crenças religiosas ou políticas, mas você também pode perguntar sobre crenças diretamente relevantes para a forma como sua empresa trabalha. Por exemplo, você pode pedir que eles avaliem a importância de as interações de suporte serem presenciais.
- Formatos de perguntas: Formate as perguntas sobre comportamentos e crenças como escalas. O intervalo em uma escala pode nos ajudar a entender quais pontos da escala estão correlacionados e, portanto, mais ou menos no mesmo cluster; perguntas do tipo Sim/Não e de seleção única não são tão úteis para a análise cluster. Exemplo: Se você perguntar “Que tipo de comprador você é?” e der as opções “Prefere fazer compras em shoppings”, “Prefere fazer compras on-line” e “Prefere fazer compras em butiques”, o algoritmo de agrupamento desejará dividir os entrevistados em três grupos, um para cada resposta. Se, em vez disso, você fizer uma série de perguntas (por exemplo, “Você gosta de fazer compras em shoppings?”) com respostas de 1 a 7, o algoritmo de agrupamento fará um trabalho melhor para realmente discernir o que separa os diferentes compradores uns dos outros.
 Qdica: as perguntas de múltipla Opção de resposta são as melhores para coletar dados escalares.
Qdica: as perguntas de múltipla Opção de resposta são as melhores para coletar dados escalares. - Tipos de variáveis: Quando estiver pronto para analisar no Stats iQ, certifique-se de formatar suas variáveis como categorias ou números. As datas são incompatíveis com a análise cluster.
Qdica: ao criar suas variáveis, considere aquelas que você já sabe que são altamente correlacionadas. Isso o ajudará a permanecer no limite de 10 variáveis na análise cluster.
Atenção: A análise Cluster tem um tamanho máximo de amostra de 20.000 respostas.
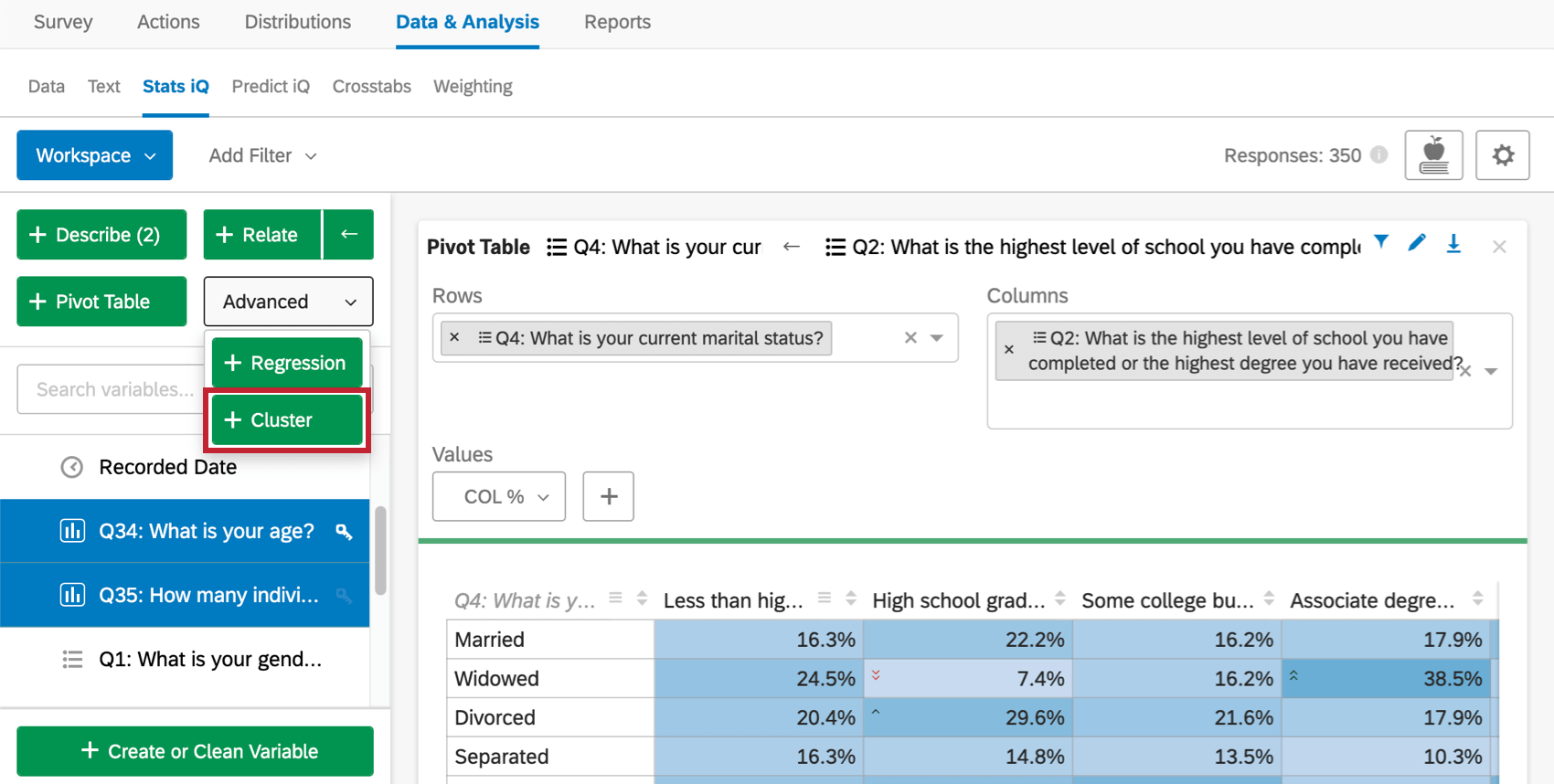
Execução da análise Cluster
Qdica: você só pode executar uma análise cluster em 10 variáveis de cada vez. Se quiser incluir mais, tente encontrar variáveis que estejam altamente correlacionadas entre si e crie uma média delas usando o botão Criar ou Limpar variável.
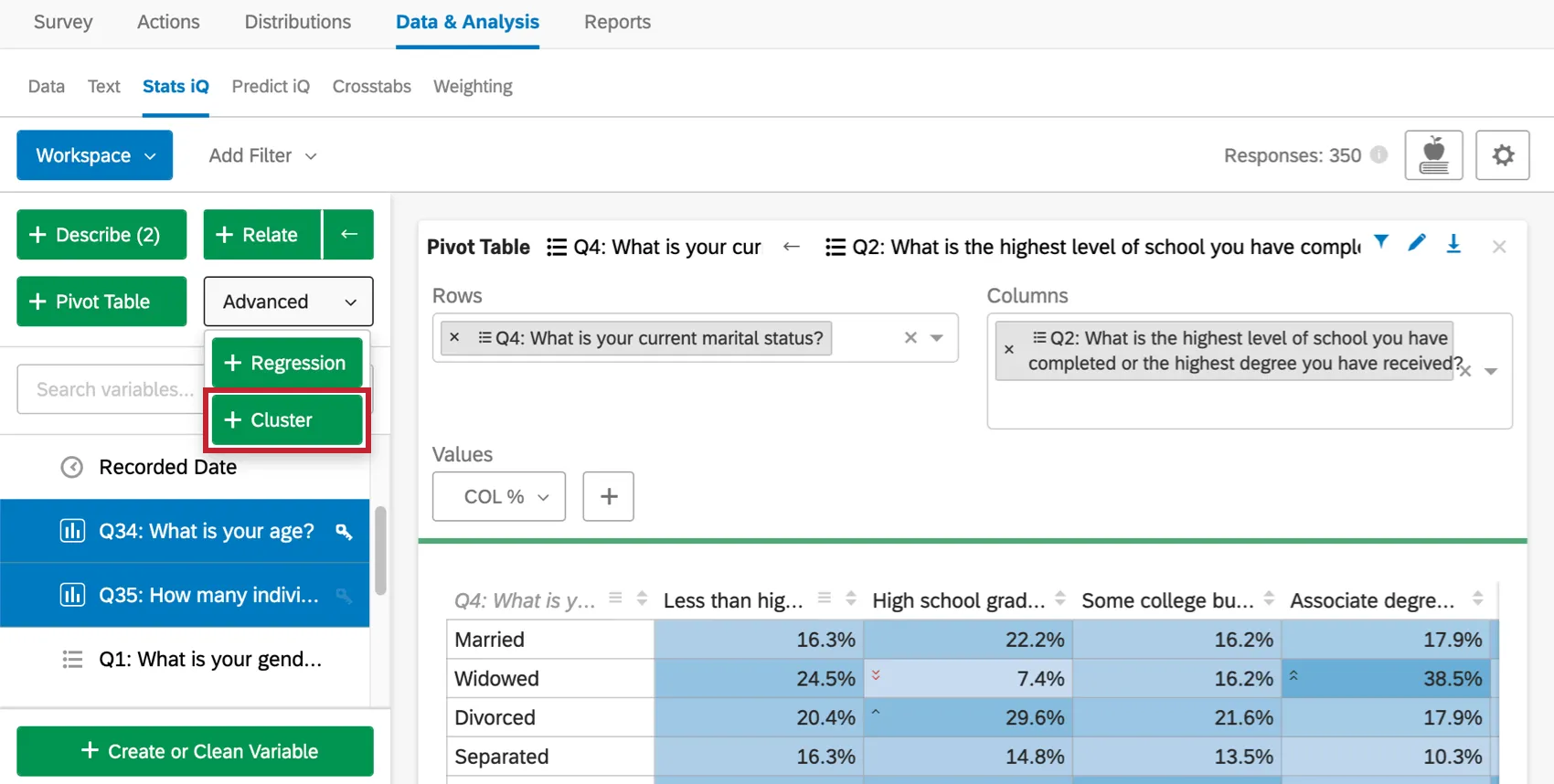
Resultados da análise de Cluster
Tabela de resistência e estática
A tabela lista o tamanho amostra (quantos respondentes contribuíram com dados para essa análise), o número de clusters e a pontuação de silhueta. A pontuação da silhueta é interpretada em frases como “muito forte” na frase na parte superior.
{kind=link}

Qdica: para saber mais sobre a pontuação da silhueta exibida nessa tabela, consulte a seção Interpretação da análise Cluster.
A análise Cluster tenta escolher o número apropriado de clusters automaticamente, avaliando a rigidez do clustering em vários números, mas penalizando números mais altos de clusters por serem mais difíceis de trabalhar. Escolher o número certo é mais arte do que ciência, e você deve experimentar diferentes números para ver o que funciona melhor.
Em alguns casos, o algoritmo não conseguirá produzir um determinado número de clusters e voltará a um número menor.
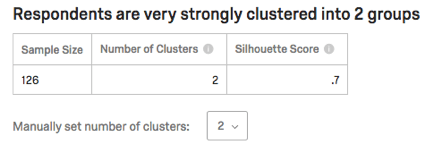
Resumo de Cluster
Seus clusters serão listados na seção Resumo do Cluster. Eles serão descritos com base nas perguntas que os membros do cluster responderam de forma mais semelhante.
{kind=link}

Exemplo: Cluster 1 nesta captura de tela contém pessoas que são:
- Casado
- Ter mestrado
- Ter poucas pessoas (familiares diretos, crianças) morando em sua casa
- Jovem
Clique no nome de um cluster para renomeá-lo.
Qdica: renomear seus clusters é importante para que resultados façam mais sentido em um contexto do mundo real ou de marketing.

{kind=link}
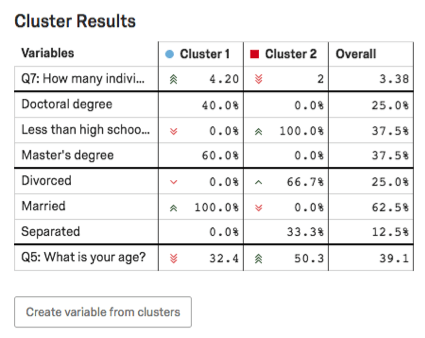
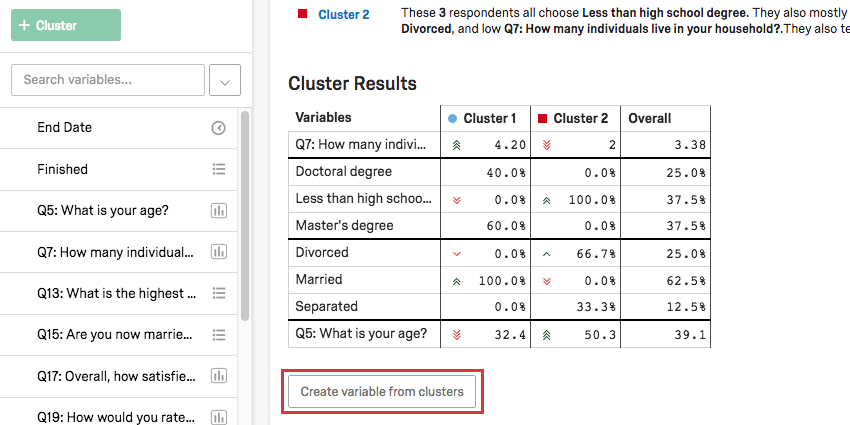
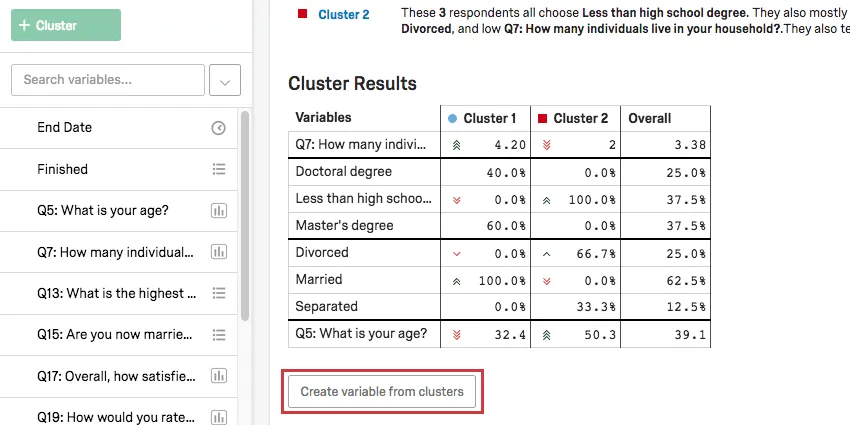
Tabela de Resultados Cluster
Na Tabela de resultados Cluster, as principais variáveis do cluster serão destacadas. Para variáveis categóricas, serão fornecidas a opção mais comum e a porcentagem de entrevistados no cluster que forneceram essa resposta. Para variáveis numéricas, você verá uma resposta média.
Exemplo: Nesta captura de tela, nível de escolaridade é categórico, portanto, vemos um quebra das porcentagens de entrevistados com doutorado em comparação com os entrevistados com doutorado. Menos do que o ensino médio vs. Mestrado.
A idade é numérica aqui, portanto, vemos a idade média de cada cluster (32,4 para o Cluster 1, 50,3 para o Cluster 2).

{kind=link}
Para saber mais sobre como criar variáveis a partir de clusters, consulte a seção Criar variável a partir de clusters.
Importância da Variável
A tabela Importância da variável mostra a força da relação entre cada variável e os clusters. Uma relação mais forte indica que a variável foi mais importante na criação dos clusters.
Para calcular isso, executamos regressões para cada variável. Por exemplo, compararíamos a idade com o resultado do cluster, as horas trabalhadas com o resultado cluster e assim por diante.
Os valores de r-quadrado resultantes dessas regressões são então escalonados de forma que o r-quadrado mais alto seja definido como 1.
Exemplo: Digamos que a Q7 tenha um r-quadrado de 0,5, o mais alto do grupo. Precisamos dobrar esse valor para defini-lo como 1. Isso significa que, se a Q13 tivesse um r-quadrado de 0,4, ele seria exibido como 0,8 no gráfico abaixo.

{kind=link}
Criação de novas variáveis a partir de Resultados
Depois de determinar os grupos entre seus respondentes, é possível transformar essas categorias em novas variáveis que podem ser analisadas no Stats iQ!
Primeiro, certifique-se de renomear seus clusters clicando em seus nomes.

Qdica: a etapa de renomeação não é obrigatória, mas tornará seus dados mais limpos e compreensíveis para você e seus colegas.
Quando os clusters tiverem nomes que façam sentido para você, clique em Create variable from clusters (Criar variável de clusters ) na Tabela de resultados Cluster Results (Resultados de clusters ). Isso adicionará automaticamente uma variável categórica à sua lista de variáveis à esquerda.
{kind=link}
Qdica: essa variável só está disponível no Stats iQ. Ele não aparecerá em nenhum outro lugar em seus dados do Qualtrics.
Notas Técnicas
A análise Cluster no Stats iQ usa a análise de classe latente (LCA) para particionar os dados fornecidos pelo usuário em seus clusters subjacentes. Diferentemente de outros algoritmos de agrupamento, o algoritmo Stats iQ LCA permite que tipos de dados mistos sejam agrupados (numéricos, categóricos e binários).
Análise de classe latente de tipo misto
A análise de classe latente (LCA) é um modelo de agrupamento baseado em probabilidade. Cada cluster é definido por uma coleção de funções de densidade de probabilidade que, com base no valor das variáveis de um ponto de dados, retorna a probabilidade de um determinado ponto de dados pertencer a esse cluster.
Exemplo: Sua família pode ser dividida em algumas gerações, como os filhos atuais, os pais e os avós. Um modelo LCA representaria esses três grupos, em que cada cluster é definido por uma única função de probabilidade com base na idade:
Cluster Função de probabilidade Média Função de probabilidade Desvio padrão Atual 25 7 Responsáveis 48 5 Avós 75 3 Para atribuir uma pessoa de 30 anos a um cluster, use essas funções de densidade de probabilidade para calcular que há 44% de probabilidade de ela estar em Current (Atual), <1% de probabilidade de ela estar em Parents (Pais) e <1% de probabilidade de ela estar em Grandparents (Avós). Esse indivíduo seria atribuído ao seu cluster mais provável, o Current.
Um modelo LCA pode ser aplicado a várias variáveis multiplicando a probabilidade de um ponto de dados pertencer a um cluster com base em cada variável. O modelo pode ser aplicado a diferentes tipos de variáveis usando diferentes funções de densidade de probabilidade:
| Digitar | Transformação | Função de densidade de probabilidade |
|---|---|---|
| Categórico | Dummy codificado (N-1) | Bernoulli |
| Binário | Bernoulli | |
| Numérico | Normal |
Determinação do número de classes
Para determinar o número ideal de classes, Stats iQ usa uma pontuação BIC.
Avaliação da adequação do modelo
Para avaliar a “qualidade” objetiva de um modelo, Stats iQ usa uma pontuação de silhueta baseada em probabilidade. Uma pontuação de silhueta é uma medida de quão bem cada ponto de dados está dentro de seu cluster. Uma pontuação de silhueta mede a semelhança de um ponto específico com todos os outros pontos em seu cluster e compara essa semelhança com a de todos os pontos em seu cluster vizinho mais próximo. Para medir a similaridade entre dois pontos de dados, Stats iQ calcula a distância de gower (uma métrica de distância que funciona para dados binários, categóricos e numéricos) entre os pontos.
Perguntas frequentes
Como faço para que minhas novas respostas apareçam no Stats iQ?
Como faço para que minhas novas respostas apareçam no Stats iQ?
O que faço se meus dados não estiverem sendo carregados corretamente?
O que faço se meus dados não estiverem sendo carregados corretamente?
Isso é ótimo! Obrigado pelo seu feedback!
Obrigado pelo seu feedback!