Scripts R pré-compostos
O que há nesta página
Atenção: Você está lendo sobre um característica ao qual nem todos os usuários Stats iQ têm acesso. Se estiver interessado nesse característica, contato o Executivo Conta para verificar se está qualificado.
Sobre scripts R pré-compostos
O R é uma linguagem de programação estatística amplamente usada para análises flexíveis e avançadas. Ao usar o R Coding no Stats iQ, você pode selecionar vários scripts de análise para tornar o uso do R mais fácil e eficiente.
Seleção de um script para o código R
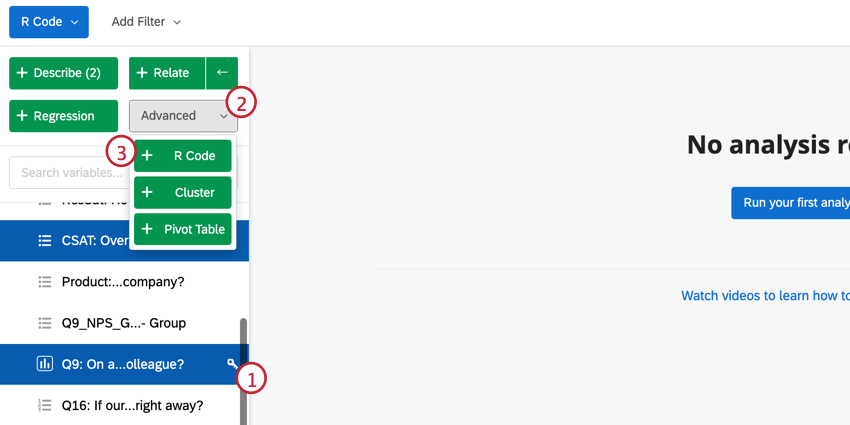
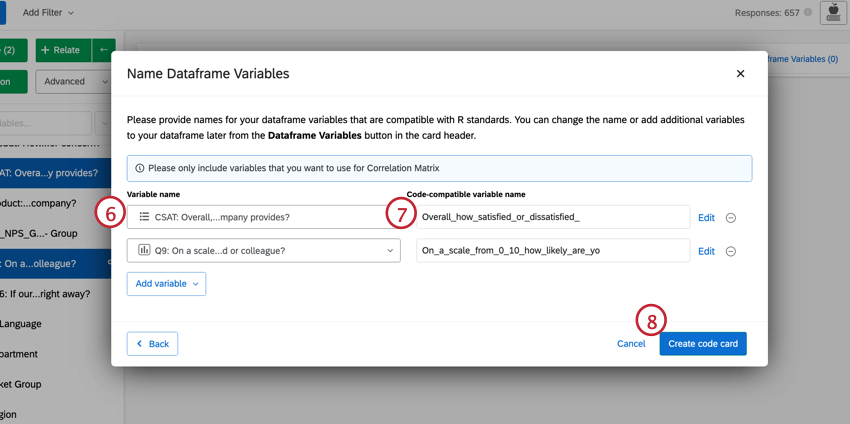
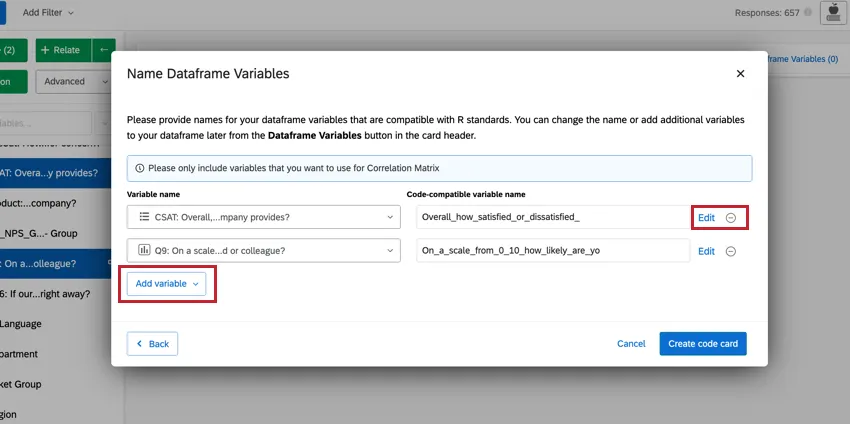
Qdica: Você pode fazer alterações nas variáveis que selecionou diretamente nessa janela. Para editar os valores de recodificação, clique em Edit (Editar). Se você quiser excluir a variável, clique no ícone ( – ). Se você quiser adicionar uma nova variável, clique em Add variable (Adicionar variável ) no canto inferior esquerdo.
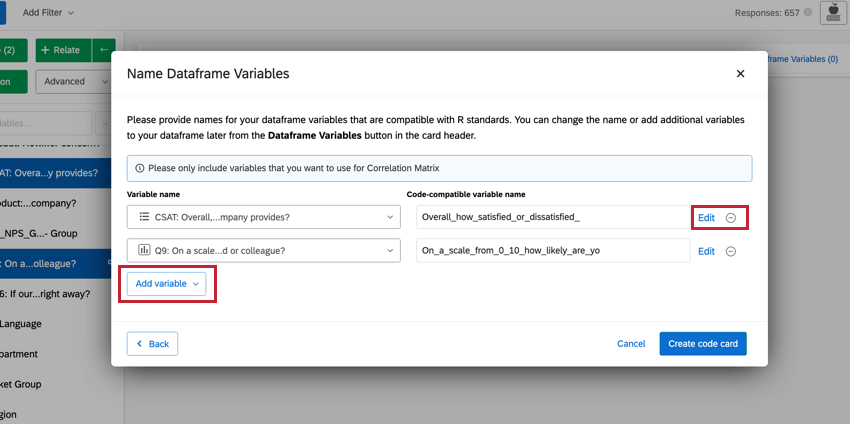
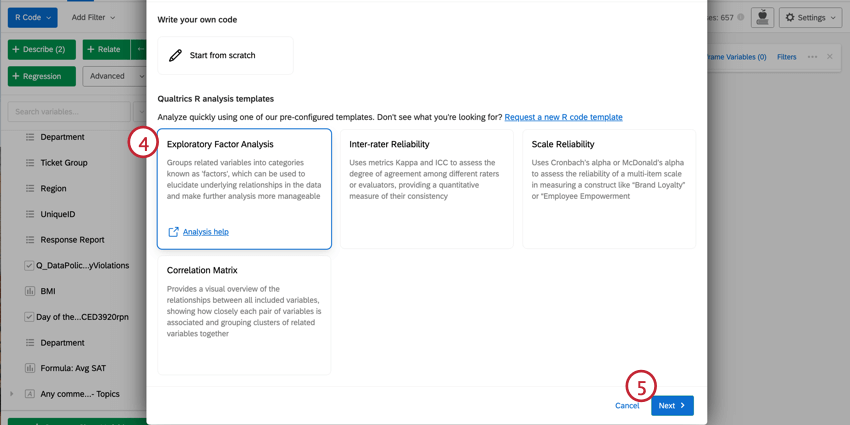
Navegação em scripts de código R pré-compostos
Seu script será colado na seção de código do cartão R Code. Esse código conterá conselhos junto com os comandos para gerar a análise que você selecionou. Para executar sua análise, clique em Run All (Executar tudo). Os resultados serão exibidos na caixa de saída à direita.
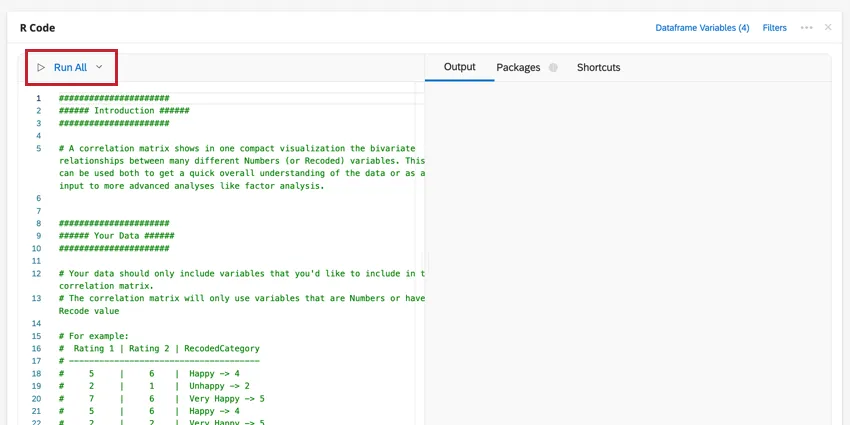
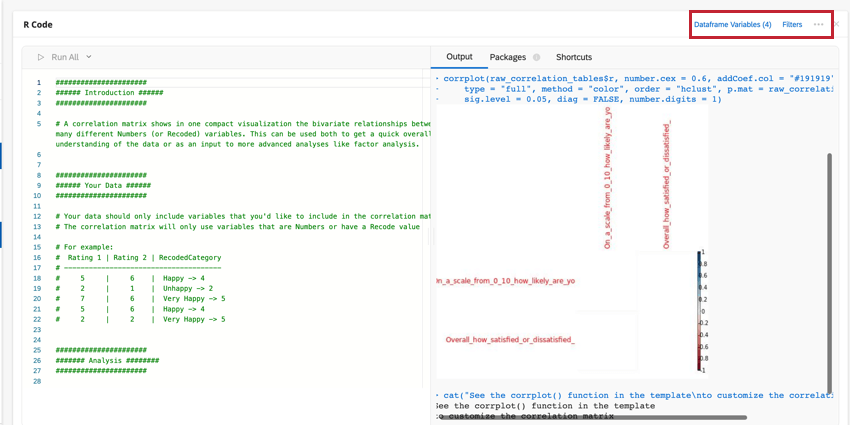
Você pode editar suas variáveis de dataframe ou adicionar um filtro à análise clicando nas opções no canto superior direito. Clique no menu de três pontos para adicionar notas ao seu cartão de código, copiar a análise ou abrir o cartão em tela cheia.
RETROCESSOS
Os atalhos de teclado podem ser usados para navegar com mais eficiência no cartão do Código R. Clique em Atalhos para obter uma lista de ações possíveis.
PACOTES
A codificação R no Stats iQ vem pré-instalada com centenas dos pacotes R mais populares usados para análise. Clique na guia Packages (Pacotes) na metade direita do cartão para ver a lista de pacotes disponíveis. Para obter mais informações sobre o uso de pacotes, consulte Codificação R no Stats iQ.
Índice de confiabilidade
A confiabilidade da escala avalia a extensão em que os itens de uma escala de vários itens podem medir um construto de forma confiável. Em outras palavras, se a mesma coisa for medida usando o mesmo conjunto de perguntas, haverá resultados semelhantes de forma confiável? Se for esse o caso, há confiança de que quaisquer mudanças que veremos no futuro se devem a mudanças na população pesquisada ou a intervenções que foram feitas para melhorar a pontuação.
INTERPRETAÇÃO DE MEDIDAS DE CONFIABILIDADE
As medidas de confiabilidade da escala variam entre 0 e 1 e são essencialmente uma correlação agregada entre todos os itens da escala.
O alfa de Cronbach, uma medida de confiabilidade amplamente usada, frequentemente subestima a confiabilidade devido a determinadas suposições. O ômega do McDonald’s, uma alternativa recomendada, evita essas falhas. Por padrão, usamos o ômega do McDonald’s, mas o alfa de Cronbach ainda é amplamente aceito.
Não há uma única maneira correta de interpretar o número resultante, mas nossa regra prática preferida para ambos os ômegas está descrita abaixo:
| Menos de 0,65 | Inaceitável |
| 0.65 | Aceitável |
| 0.8 | Muito bom |
Se sua escala confiável for inaceitável, há algumas opções para corrigir seu conjunto de dados:
- Remova todos os itens que estejam diminuindo o ômega ou o alfa.
- É possível que haja dois construtos distintos sendo medidos. Se esse for o caso, separar as variáveis em dois grupos e executar essa análise em cada um deles levaria a pontuações de confiabilidade mais altas do que as da análise inicial. Você pode explorar isso revisando a matriz de correlação no resultado ou usando o script Exploratory Factor Analysis para ver quais agrupamentos surgem naturalmente dos dados.
- Por fim, pode ser necessário modificar e executar a pesquisa novamente. Os itens que têm baixa correlação com os demais podem precisar ser esclarecidos ou reelaborados, ou outros itens podem precisar ser adicionados.
resultados muito altos (por exemplo, 0,95) também podem indicar um problema com a escala, geralmente porque você ainda pode ter uma escala muito confiável sem ter tantos itens. Nesse caso, recomendamos remover os itens menos úteis da escala e executar novamente a análise.
INTERPRETAÇÃO DE ESTATÍSTICAS EM NÍVEL DE ITEM
O script primeiro executa uma medida de confiabilidade geral e, em seguida, executa uma iteração para cada variável. O objetivo da análise de confiabilidade por item é entender quais itens são mais úteis para a construção da escala. Stats iQ produzirá uma tabela semelhante a esta:
Ômega geral do McDonald’s: 0,71
| N | Média | Correlação item-total | McDonald’s Omega se removido | |
| A1 | 2784 | 4.59 | 0.31 | 0.72 |
| A2 | 2773 | 4.80 | 0.56 | 0.69 |
| A3 | 2774 | 4.60 | 0.59 | 0.61 |
| … | … | … | … | … |
- O objetivo geral é ter um McDonald’s Ômega maior com um número menor de itens. Portanto, se um pesquisador estivesse criando uma nova escala, provavelmente desejaria remover A1, já que o ômega é realmente mais alto sem ele.
- O restante dos itens que reduziriam a confiabilidade se fossem removidos fica a cargo do pesquisador determinar. Por exemplo, se um pesquisador estiver preocupado com o cansaço pesquisa, ele poderá permitir uma redução maior na confiabilidade ao decidir remover uma variável.
- A Correlação Item-Total é a correlação entre esse item e a média de todos os outros. A baixa correlação item-total sugere que a variável não é suficientemente representativa do construto subjacente. A regra geral mais comum é desconfiar de qualquer coisa com uma correlação item-total de 0,3 ou menos, especialmente se você tiver muitos itens, o que aumenta artificialmente a métrica de confiabilidade.
Se você optar por remover um item, deverá executar novamente todas as outras estatísticas antes de decidir se removerá outro item. No Stats iQ, isso significa apenas remover a variável de todo o cartão – o resto acontecerá automaticamente.
MATRIZ CORRELAÇÃO ENTRE ITENS
A Matriz de correlação entre itens mostra a correlação entre cada variável na análise e cada uma das outras variáveis. Por exemplo, se uma variável estiver altamente correlacionada com outra (por exemplo, 0,9), essas perguntas podem ser redundantes e removê-las terá apenas um pequeno impacto em sua confiabilidade.
A correlação média entre itens é a média dos números na matriz. Números mais altos sugerem que alguns itens podem ser redundantes e podem ser removidos. Em geral, as variáveis devem se situar no intervalo de 0,2 a 0,4.
Qdica: A correlação média entre itens pode fornecer informações úteis sobre as pontuações gerais de confiabilidade. Por exemplo, se você estiver trabalhando com um número menor de itens (por exemplo, 3) e tiver uma pontuação de confiabilidade baixa e uma correlação média alta entre itens, isso pode sugerir que isso se deve à falta de itens e não à falta de correlação entre eles.
MAIS RECURSOS
- A análise de confiabilidade no Stats iQ é executada pela função compRelSem() do pacote semTools R. Diversas configurações avançadas estão descritas na documentação. Não é necessário usar ou entender essas configurações para executar uma análise de confiabilidade.
- A matriz de correlação é executada pela função corrplot() do pacote R corrplot. Uma variedade de configurações e personalizações avançadas está descrita na documentação e neste passo a passo.
Confiabilidade entre avaliadores
A confiabilidade entre avaliadores (IRR) é usada para avaliar até que ponto dois ou mais avaliadores concordam em sua avaliação. Por exemplo, três codificadores diferentes podem avaliar um comentário de texto como tendo sentimento positivo, neutro ou negativo; a IRR descreve o quanto eles concordam uns com os outros.
MEDIDAS DE CONFIABILIDADE ENTRE AVALIADORES
A TIR é avaliada usando métricas ligeiramente diferentes com base na estrutura dos dados. Por exemplo, uma análise da interconfiabilidade de dois avaliadores usará uma métrica ligeiramente diferente daquela da interconfiabilidade de três avaliadores.
Stats iQ selecionará automaticamente a métrica apropriada para seus dados.
INTERPRETAÇÃO DE RESULTADOS
A métrica Kappa ou ICC é o principal resultado, entre 0 e 1, e indica o grau de correlação entre os avaliadores. Sugerimos os intervalos abaixo para interpretar o Kappa:
| 0.75 para 1 | Excelente |
| 0.6 a 0,75 | Bom |
| 0.4 a 0,6 | Razoável |
| 0.4 ou inferior | Fraco |
MAIS RECURSOS
- Essa análise de confiabilidade é executada pelas funções do pacote IRR R. Diversas configurações avançadas estão descritas na documentação. Não é necessário usar ou entender essas configurações para executar essa análise.
Análise de fator exploratório
A análise fatorial exploratória (EFA) é uma técnica estatística que ajuda a reduzir um grande número de variáveis em um conjunto menor e mais gerenciável de “fatores” resumidos. Isso facilita muito a interpretação, a comunicação e a execução de análises adicionais (por exemplo, análise de regressão). Em geral, a AFE segue esse conjunto de etapas:
O resultado é um conjunto de fatores nomeados e seus itens pesquisa componentes. Esses fatores podem servir como uma estrutura conceitual para análises posteriores ou podem ser aplicados novamente aos dados.
Exemplo: Se os itens “Meu quarto estava limpo”, “O resto do hotel estava limpo” e “Meu quarto tinha tudo o que eu precisava” estiverem no mesmo fator, você poderá calcular a média desses itens e informar a medida resumida de “Qualidade do quarto”.
DIAGNÓSTICO
O script primeiro executa uma série de diagnósticos para garantir que os dados sejam adequados para a AFE:
- Tamanho Amostra: Em geral, sugere-se uma proporção de 10:1 entre respostas e os itens. Por exemplo, se você tiver 10 perguntas, deverá ter pelo menos 100 respondentes.
- Teste de esfericidade de Bartlett: Esse teste avalia se os itens estão correlacionados o suficiente para serem agrupados de forma útil em fatores. Se isso não funcionar, é provável que haja vários itens que não se correlacionam suficientemente com os outros. Você pode considerar a possibilidade de eliminar itens da sua análise que não se correlacionam com outros ou adicionar mais itens relacionados ao pesquisa.
- Determinante: O determinante avalia se os itens estão altamente correlacionados para serem agrupados de forma útil em fatores. Se esse diagnóstico falhar, é provável que haja itens muito semelhantes entre si para serem separados em fatores. Considere editar os itens pesquisa para que sejam mais distintos.
- Medida Kaiser-Meyer-Olkin (KMO): essa medida verifica se os itens do seu pesquisa têm o suficiente em comum para agrupá-los em fatores significativos. A aprovação nesse diagnóstico significa que as respostas do seu pesquisa têm muito em comum e podem ser agrupadas de forma adequada. Caso contrário, os itens não se cluster em categorias. Se esse diagnóstico falhar, talvez seja necessário revisar os itens pesquisa para capturar temas mais semelhantes e considerar a remoção de itens que não estejam mostrando uma relação clara com outros.
ESCOLHA DE FATORES
O objetivo da AFE é reduzir muitas variáveis a um número relativamente pequeno que seja útil para a análise, portanto, talvez seja necessário executar a análise fatorial várias vezes com diferentes números de fatores para encontrar um agrupamento que funcione para você. O script EFA sugerirá o número de fatores usando seus valores próprios.
Qdica: os valores próprios medem o grau de correlação de um fator com as variáveis originais a partir das quais ele foi criado, somando os valores de r-quadrado entre o fator e as variáveis. Por exemplo, se o r-quadrado entre o fator e Q1 for 0,8 e o do fator e Q2 for 0,5, o valor próprio será 1,3. Em geral, devem ser usados fatores com um valor próprio acima de 1. O script EFA usa essa referência para sugerir o número de fatores.
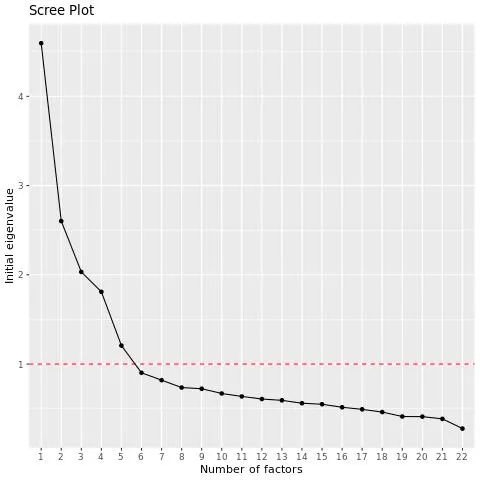
O script EFA produzirá um gráfico scree, que mostra os valores próprios das variáveis em ordem decrescente. Você pode examinar o gráfico para ver quantos fatores ocorrem antes do “cotovelo” no gráfico, após o qual adicionar mais fatores é menos útil.
Exemplo: Neste exemplo, há uma grande queda após a 4ª variável e, em seguida, outra queda significativa após a 5ª variável. Por padrão, o script usará 5 fatores aqui, mas talvez você queira executá-lo também com 4 fatores e comparar resultados.
{kind=link}
{kind=link}
{kind=link}
NOMEANDO SEUS FATORES
Depois de executar a AFE, cada variável é atribuída a um fator. É útil dar a cada fator um nome que lhe dê uma forma abreviada de falar sobre eles, o que torna suas descobertas mais acessíveis. O objetivo aqui é simplificar seus dados complexos em alguns temas compreensíveis.
Aqui estão algumas diretrizes para nomear seus fatores:
- Seja descritivo: Tente captar o tema comum que resume as variáveis do grupo.
- Mantenha a simplicidade: Os nomes de seus fatores devem ser fáceis de entender e comunicar. Evite jargões técnicos ou frases muito complexas.
- Considere seu público: Os nomes dos fatores devem fazer sentido para as pessoas que usarão sua análise. Por exemplo, “Limpeza” seria significativo tanto para os gerentes quanto para os hóspedes do hotel.
- Consistência: Se a sua pesquisa ou conjunto de dados abranger diferentes domínios ou assuntos, verifique se os nomes dos fatores são consistentes.
MEDIDAS ASSOCIADAS & MÉTRICAS
A tabela de cargas de fatores é um dos principais resultados da AFE. A carga do fator para um determinado par variável-fator é a correlação entre essa variável e o fator. Se uma variável tiver uma carga fatorial alta para um determinado fator, isso significa que a pergunta está fortemente conectada a esse fator.
A singularidade é a parte da variação que é exclusiva da variável específica e não é compartilhada com outras variáveis. Os valores de exclusividade variam de 0 a 1, sendo que os valores mais altos indicam que a variável é exclusiva e não se encaixa bem em nenhum dos fatores. .
Em geral, recomenda-se remover variáveis se suas cargas fatoriais estiverem acima de 0,3 ou se sua exclusividade estiver acima de 0,7.
USANDO SEUS RESULTADOS
A análise fatorial é um processo iterativo, portanto, talvez seja necessário executá-la várias vezes com diferentes números de fatores para encontrar um agrupamento que funcione para você. Para a maioria dos pesquisadores, a principal lição é encontrar agrupamentos de fatores que possam fornecer novos insights sobre seus dados, mas você pode usar esses fatores como novas variáveis em análises subsequentes, como regressão ou análise cluster. Por exemplo, você pode criar uma nova variável para cada fator que usa o valor médio de todas as variáveis agrupadas nela.
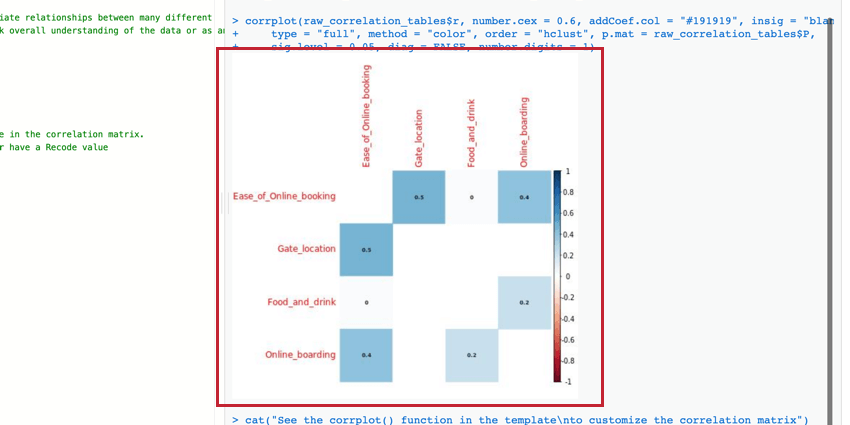
Matriz de correlação
A matriz de correlação é uma tabela que mostra a correlação entre cada par de variáveis fornecidas. Essa tabela usa o r de Pearson por padrão para medir a correlação, mas você pode alterá-lo para o rho de Spearman, se desejar.
{kind=link}
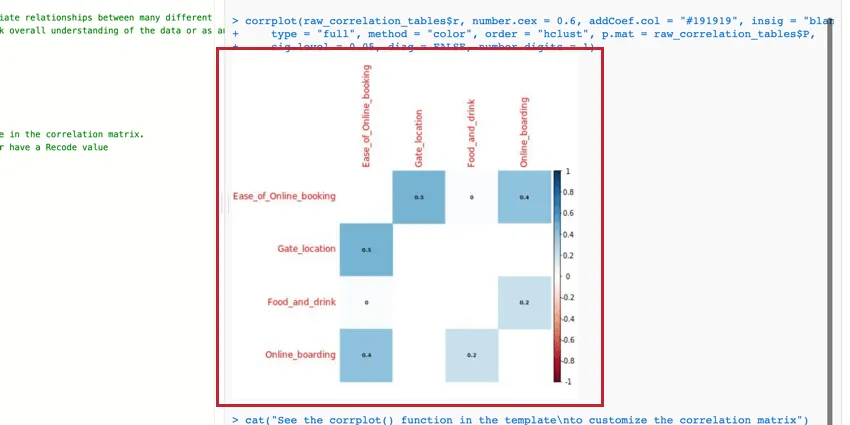
Você pode editar os parâmetros da função corrplot() para modificar a tabela e torná-la mais legível. Para obter mais informações, você pode ver o passo a passo e a documentação oficiais do R.
Isso é ótimo! Obrigado pelo seu feedback!
Obrigado pelo seu feedback!