-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Aperçu général des données et analyses
Données et analyse
L’onglet Données et analyse vous permet de filtrer, de classer, de fusionner, de nettoyer et d’analyser statistiquement vos données de réponses :
- Cliquez sur Données et analyse pour faire apparaître jusqu’à 6 sections clés.

- Choisissez parmi les sections présentées ci-dessous :
- Données
- Texte
- Stats iQ
- Predict iQ
- Tableaux croisés
- Pondération
- Audio et vidéo
Sur cette page d’assistance, nous présenterons les fonctions de base incluses dans Données et Analyse, en particulier dans les projets d’enquête.
Section « Data » (Données)
La plupart des activités de filtrage, de classification, de fusion, d’importation et de nettoyage des données se déroulent dans la section Données. Par exemple :
- Affichez et examinez les résultats dans la fenêtre des réponses en basculant entre vos :
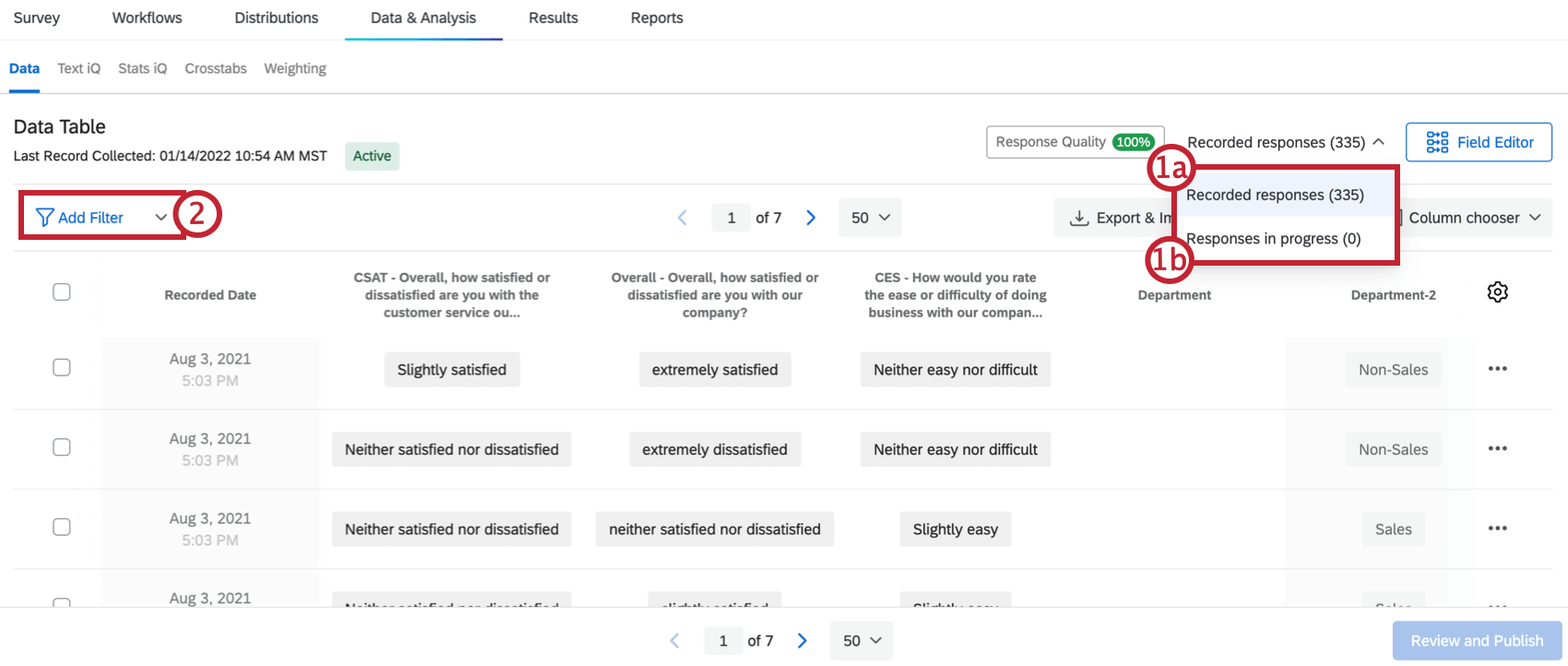
- ” Réponses complètes ou enregistrées
- ” Réponses incomplètes ou Réponses en cours
- Filtrez par questions spécifiques ou par vos filtres enregistrés, métadonnées d’enquête, champs de contact ou champs de données intégrés.
Astuce: Voir la page Filtrer les réponses pour plus de détails.
- Naviguez dans vos réponses page par page.
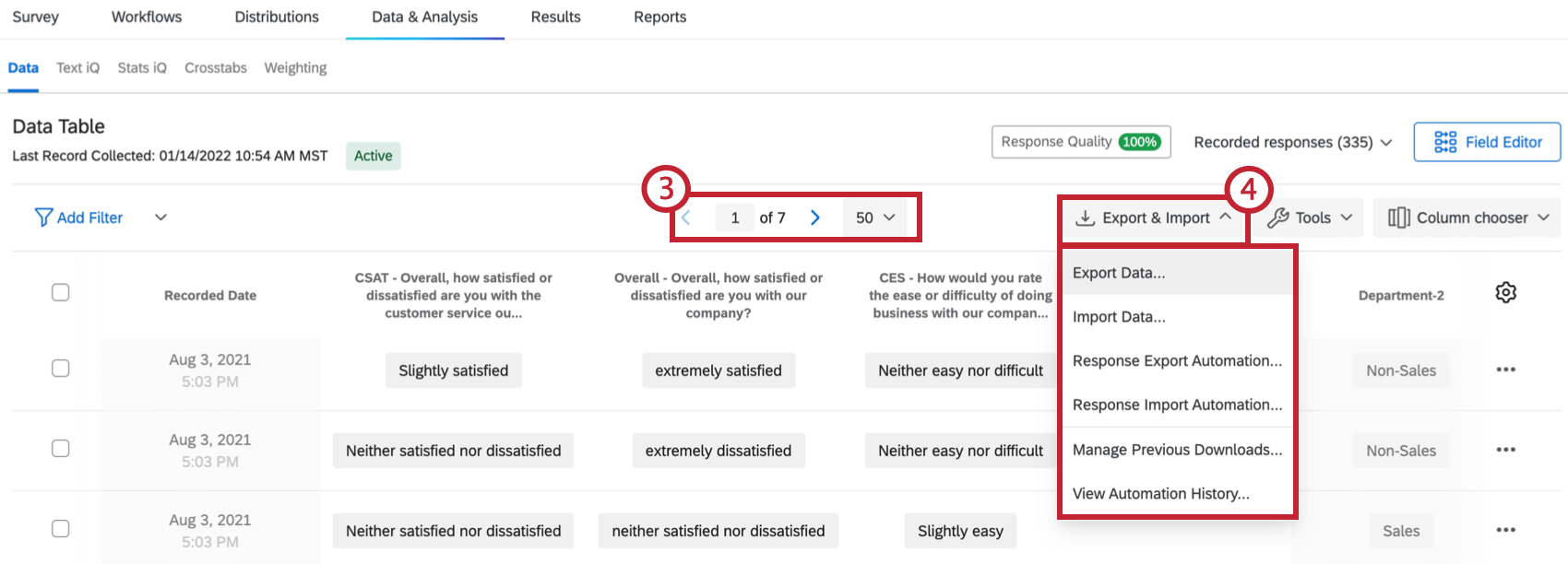
- Cliquez sur le menu déroulant Exporter et Importer pour importer des réponses, combiner les réponses de plusieurs enquêtes, gérer vos téléchargements précédents ou exporter vos données dans différents formats.
- Cliquez sur les réponses individuelles pour modifier les réponses. Vous pouvez ajouter des réponses à des réponses individuelles ou procéder à des modifications essentielles, telles que la suppression de termes grossiers.
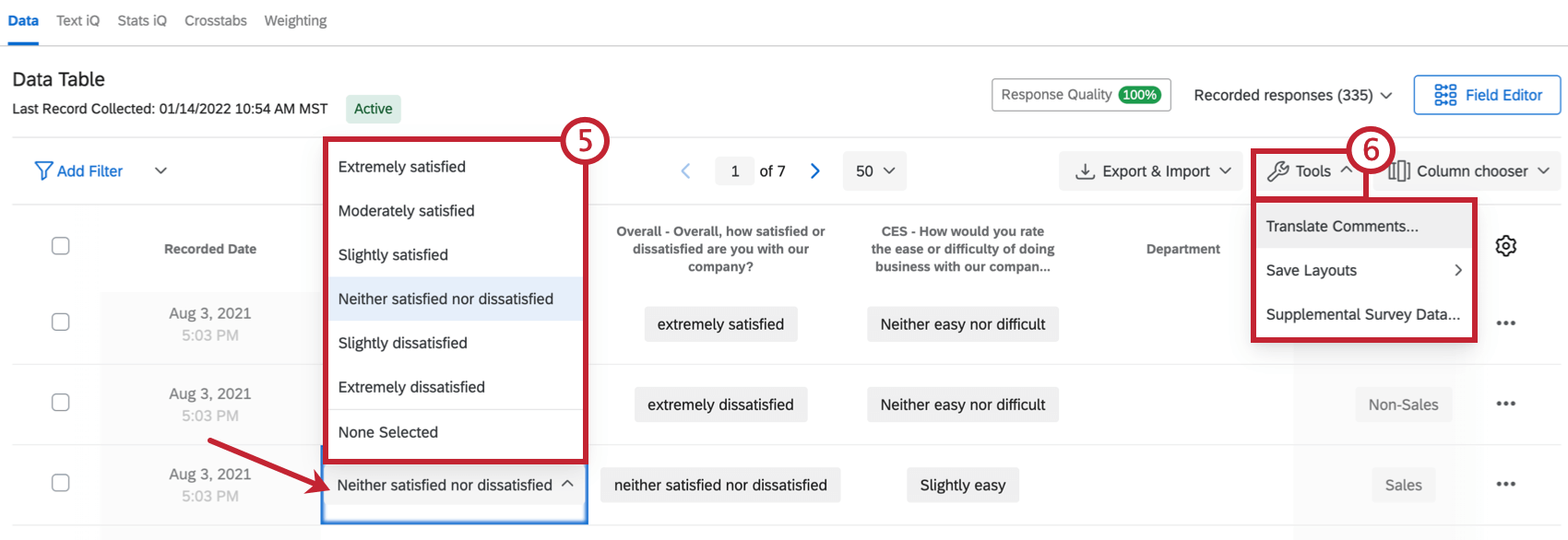 Astuce: Voir la page Modification des réponses pour plus de détails.
Astuce: Voir la page Modification des réponses pour plus de détails. - Traduisez les réponses, enregistrez les mises en page des colonnes ou configurez les projets en tant que source de données supplémentaire dans le menu déroulant Outils.
- Sélectionnez les colonnes de votre tableau de données en cliquant sur Sélecteur de colonnes.
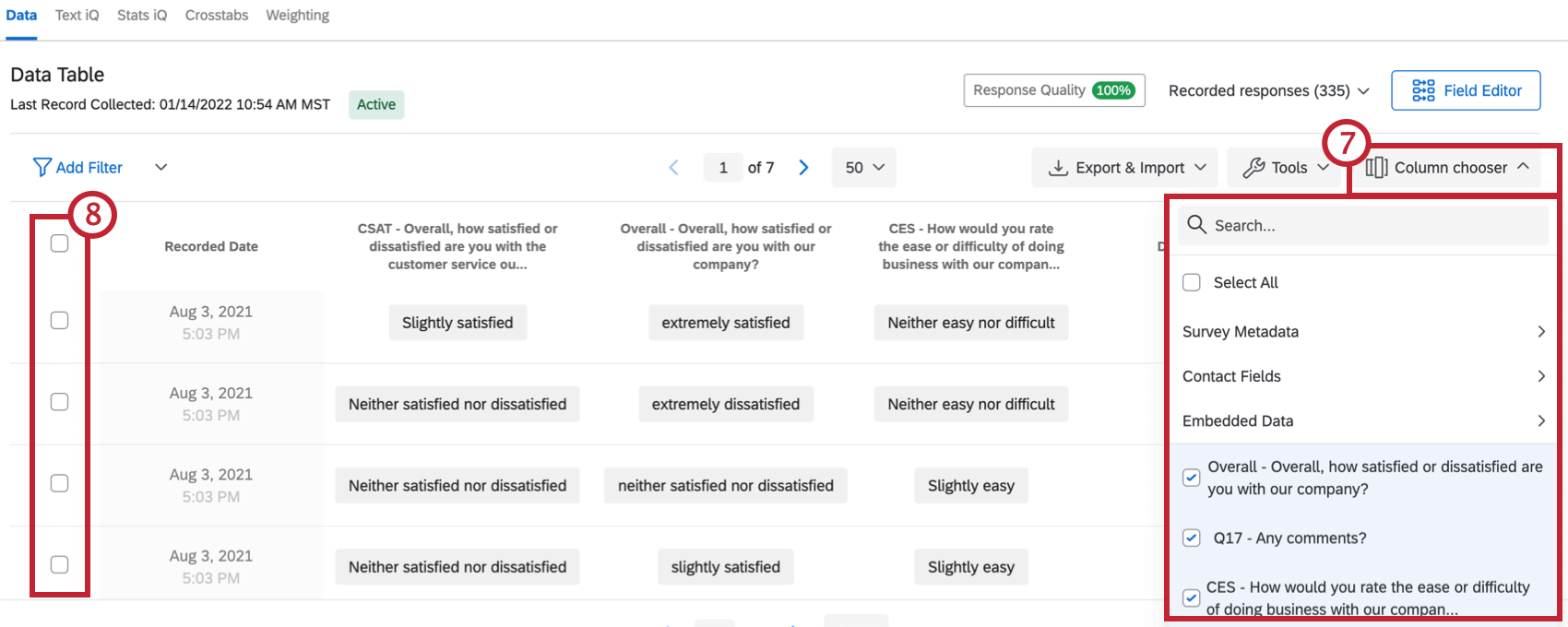
- Supprimez, modifiez ou rétablissez les modifications apportées à plusieurs réponses en utilisant les cases à cocher du tableau de données.
- Cliquez sur un en-tête de colonne pour déplacer, masquer ou trier les colonnes (par exemple, de A à Z). Vous pouvez également afficher les réponses sous forme de valeurs numériques (également appelées valeurs recodées) dans une colonne.
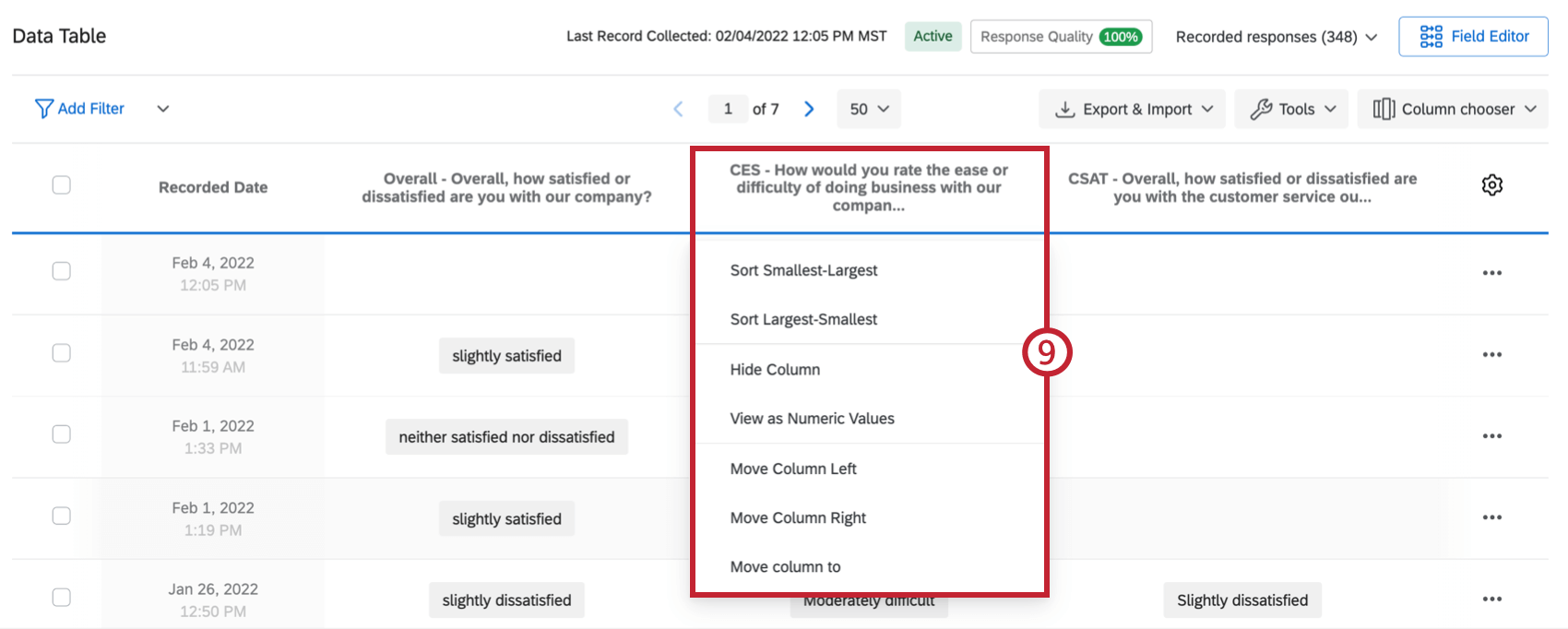
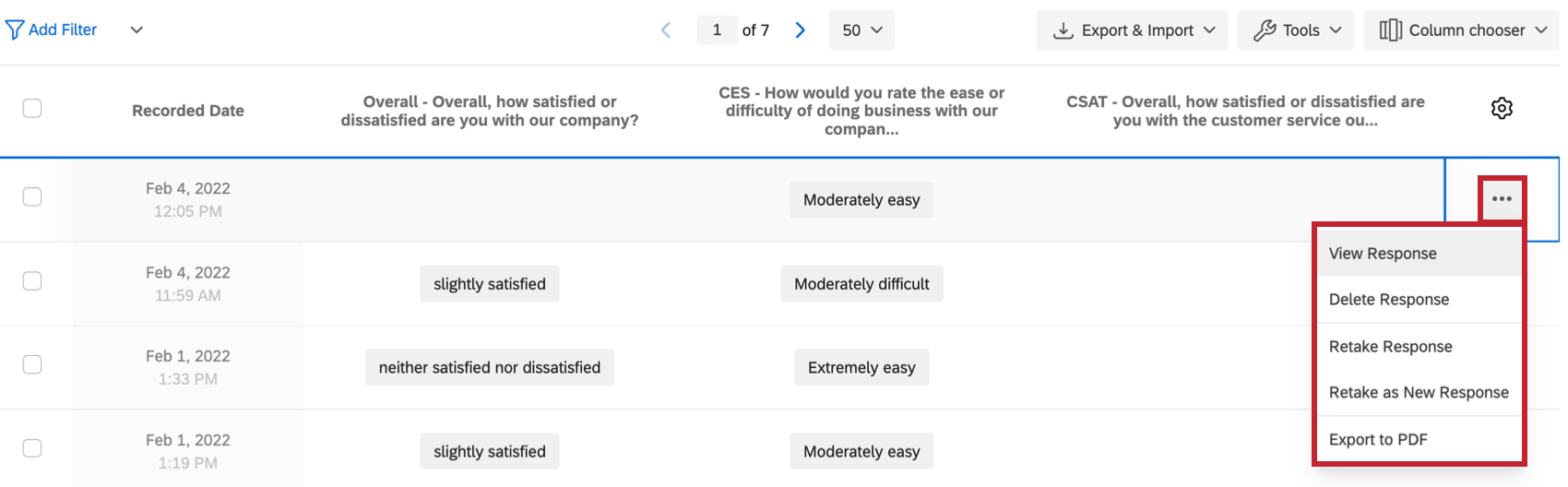
- Cliquez sur les trois points horizontaux pour accéder à d’autres options, notamment la suppression de réponses individuelles, l’exportation de données au format PDF ou l’envoi d’une resoumettre l’enquête.
 Astuce: Pour plus de détails, voir la page Lien vers l’enquête Resoumettre.
Astuce: Pour plus de détails, voir la page Lien vers l’enquête Resoumettre.
Section « Text » (Texte ; Text iQ)
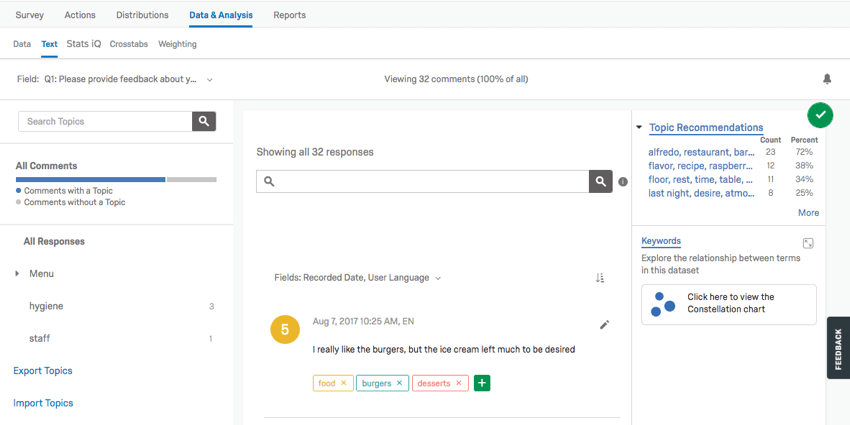
La section Text iq contient des outils Text iq. Utilisez Text iQ pour étiqueter les réponses à la saisie du texte avec des sujets d’analyse. Sur l’image ci-dessous :
- Plusieurs thèmes ont été marqués dans le volet « Topics » (Thèmes) (par ex., « food », « burgers » et « ice cream »).
- Plusieurs thèmes peuvent être attribués à vos réponses.
- La lemmatisation comprend diverses formes de mots (comme “burger” et “burgers”).
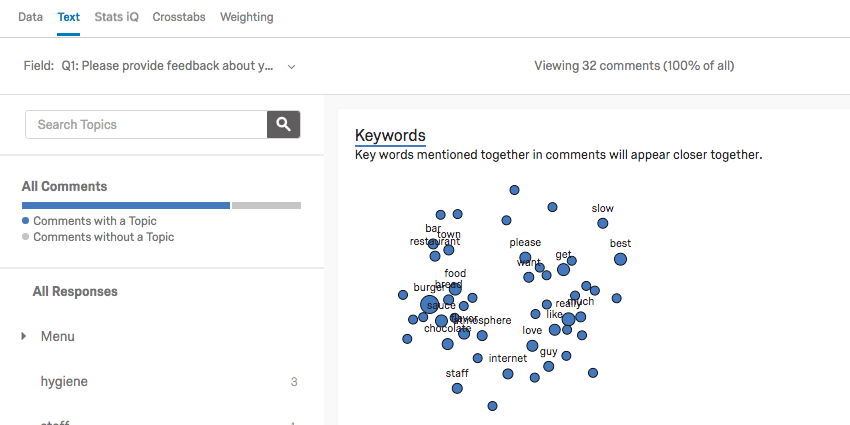
Text iQ génère divers widgets qui donnent un aperçu de votre analyse sémantique. Par exemple, ce diagramme de constellation affiche la fréquence à laquelle certains termes apparaissent dans toutes les réponses. Les points de la constellation sont d’autant plus grands que le terme apparaît fréquemment.
Créez autant de nouveaux thèmes que nécessaire pour explorer le texte de vos réponses en profondeur. La recherche Text iQ vous aidera également à identifier vos thèmes. La lemmatisation et la vérification de l’orthographe accélèrent également le marquage des sujets :
- Lemmatisation: Dissèque les mots en fonction de leur racine et les étiquette en conséquence (par exemple, car = car, cars, car’s, cars’).
- Vérification de l’orthographe: Les variantes de mots mal orthographiés tels que “ice creem” ou “icecream” seront marquées comme “ice cream”
Section Stats iQ
Lorsque vous cliquez sur la section Stats iQ, vous ouvrez Qualtrics Stats iQ. Vous pouvez y approfondir votre analyse, identifier les tendances et développer des modèles prédictifs. Stats iQ est un outil statistique puissant qui peut être apprécié par les analystes novices et experts.
Accédez à Stats iQ en sélectionnant la section Stats iQ. À partir de là :
- Utilisez le volet des variables pour sélectionner votre variable. Vous pouvez inclure une partie ou la totalité des questions dans une enquête. Le champ de recherche vous permet de localiser rapidement une variable unique.
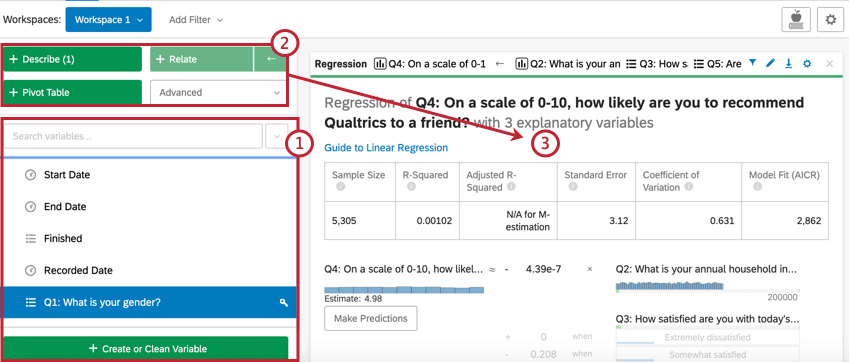
- Choisissez l’un des boutons d’analyse (Décrire, mettre en relation, régresser, ou Tableau croisé dynamique) pour déclencher des statistiques pour les variables sélectionnées.
- Chaque analyse apparaîtra sous la forme d’une carte d’analyse dans l’espace de travail, chaque nouvelle carte apparaissant au-dessus des cartes précédentes. Une série de cartes s’appelle un classeur.
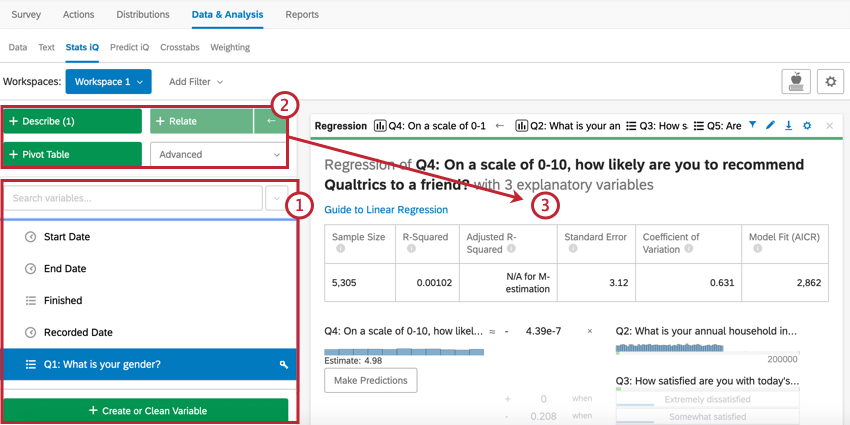
Stats iQ peut analyser les données collectées dans Qualtrics, ainsi que toutes les données externes que vous avez téléchargées en suivant les instructions des Projets de données importées. Pour plus d’informations, consultez la page Stats iQ Basic Overview.
Section Predict iQ
Predict iQ analyse les réponses de vos répondants aux enquêtes et les données intégrées pour prédire le moment où un client finira par se désabonner (abandonner l’entreprise). Une fois qu’un modèle de prédiction du désabonnement est configuré dans Predict iQ, les réponses nouvellement collectées sont évaluées en fonction de la probabilité de désabonnement du répondant, ce qui vous permet d’être proactif dans la fidélisation des clients de votre entreprise.
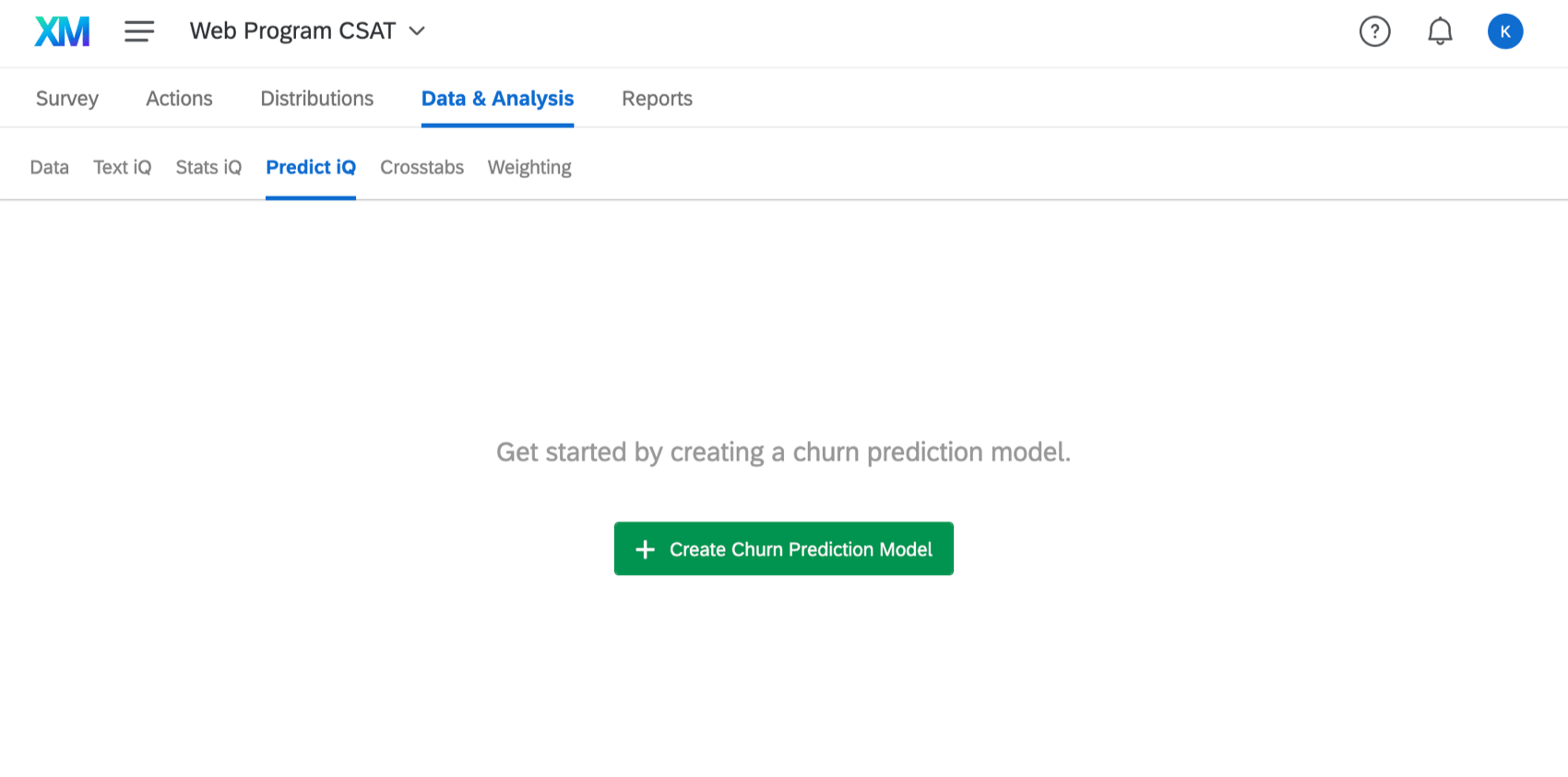
Pour des informations plus détaillées sur l’utilisation de Predict iq, voir la page d’assistance de Predict iQ.
Section des tableaux croisés
Les
tableaux croisés permettent d’effectuer des analyses multivariées (c’est-à-dire d’analyser 2 variables ou plus à la fois) tout en calculant la valeur p, le chi carré et les statistiques du test T.
Généralement utilisé pour les questions à choix multiple et les tableaux matriciels, vous pouvez également ajouter des données intégrées à vos tableaux croisés.
Dans tout tableau croisé, les lignes sont appelées “stubs” et les colonnes sont appelées “bannières”.
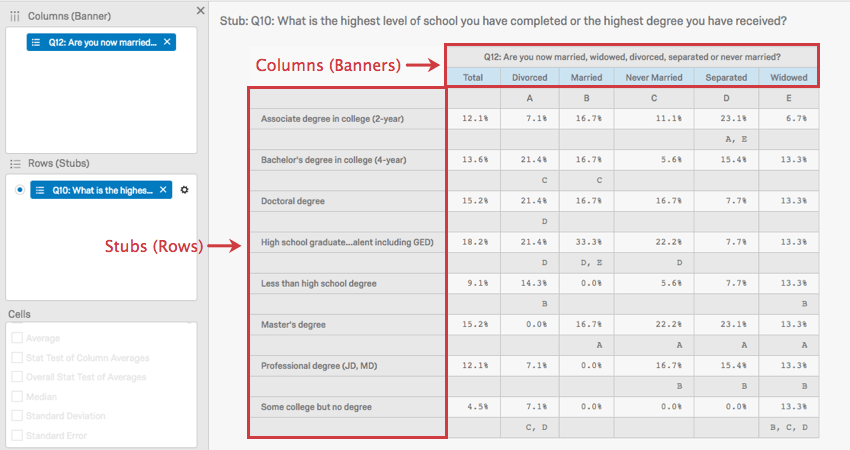
L’image ci-dessus montre que l’état civil est associé au niveau d’éducation.
Les lettres majuscules dans cette image représentent des comparaisons statistiques entre les colonnes. Dans le cas où la colonne “Divorcé” croise la ligne “Baccalauréat”, il y a un C majuscule. Cela signifie que les répondants divorcés sont significativement plus susceptibles que ceux de la colonne C, les répondants jamais mariés, d’indiquer qu’ils sont titulaires d’un baccalauréat.
L’importance est déterminée en ajustant le Niveau de confiance. Cliquez sur le bouton en haut à droite pour modifier le seuil à partir duquel les différences sont considérées comme statistiquement significatives.
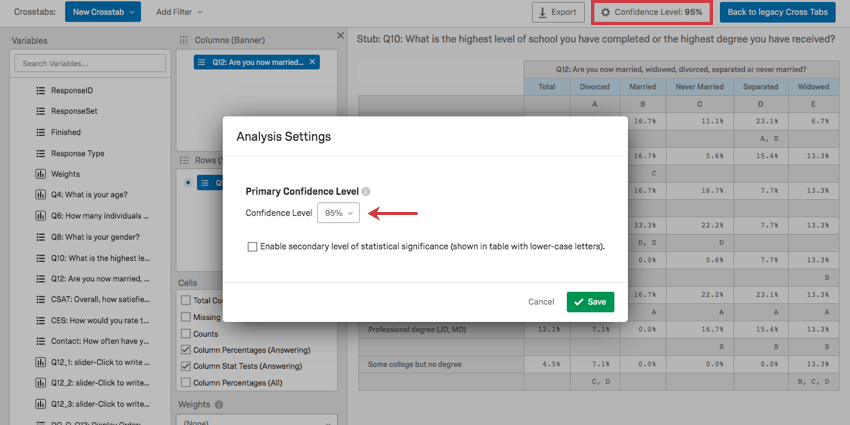
Section Pondération
Les enquêtes portent sur des populations plus importantes. La section « Weighting » (Pondération) vous permet d’ajuster votre échantillon pour tenir compte des populations sous-représentées.
Imaginons, par exemple, que vous interrogez des participants à une conférence qui viennent de tout le Canada, mais que vous avez besoin que votre échantillon reflète chaque province de manière proportionnelle. Vous souhaiterez peut-être pondérer à nouveau l’enquête pour refléter la répartition souhaitée. Sur l’image ci-dessous :
- L’Alberta est sous-représentée, puisqu’elle n’accueille que 7,5 % des participants à l’enquête, alors qu’elle représente 11,57 % de la population du Canada.
- L’Ontario est également sous-représenté, puisqu’il représente 38,26 % de la population, mais seulement 7 % des personnes interrogées dans le cadre de l’enquête.
- Le territoire du Yukon est surreprésenté avec 10,4 % des participants à l’enquête, alors qu’il ne représente que 0,10 % de la population canadienne.
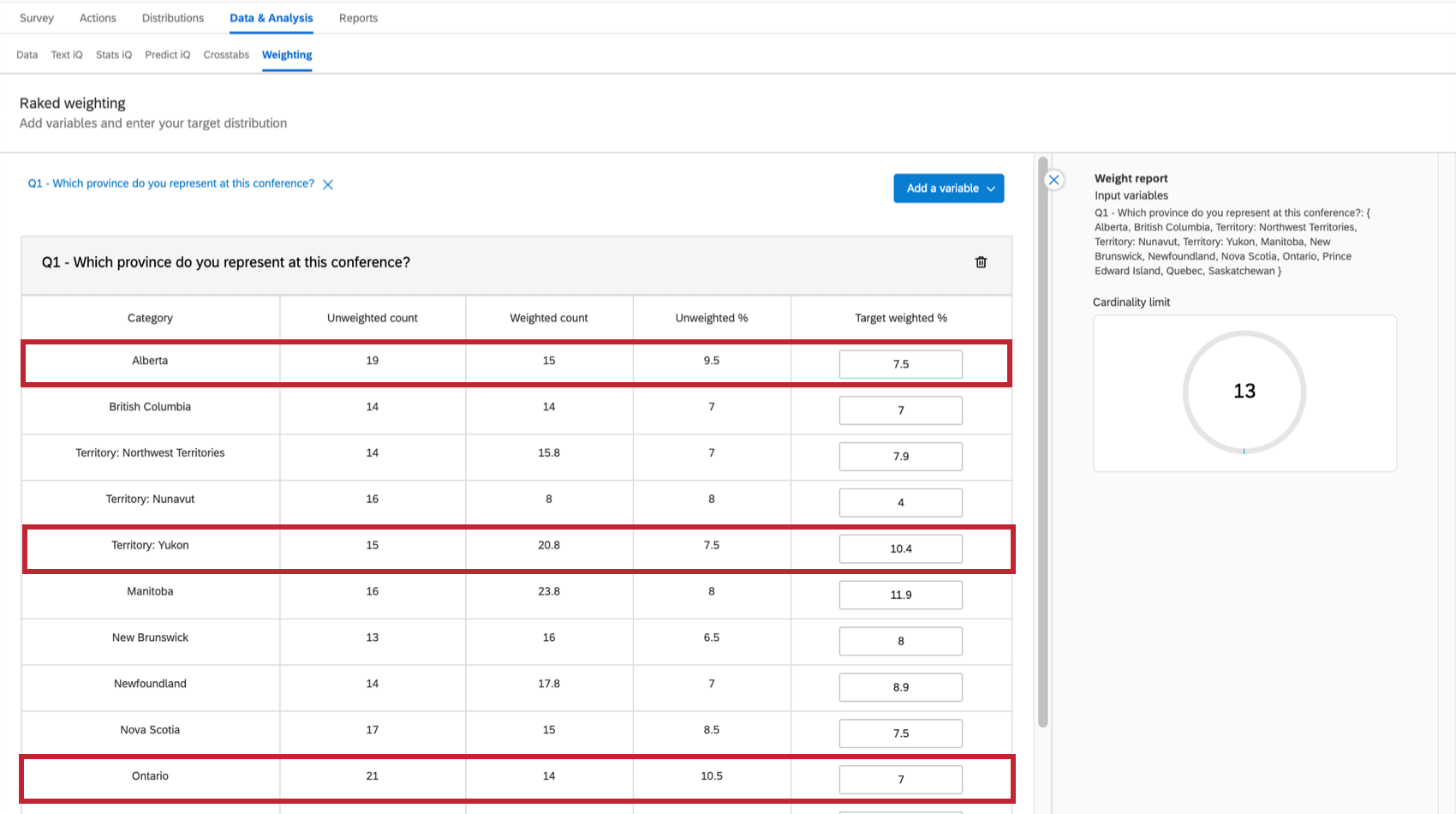
Il est facile de modifier la pondération (en pourcentage) dans la colonne Cible pondérée. Au final, vos pourcentages seront égaux à 100 %.
La pondération des réponses peut être appliquée à vos Rapports de Résultats. Vous pouvez activer ou désactiver les pondérations globalement (pour un rapport entier) ou pour une seule visualisation (graphique ou tableau).
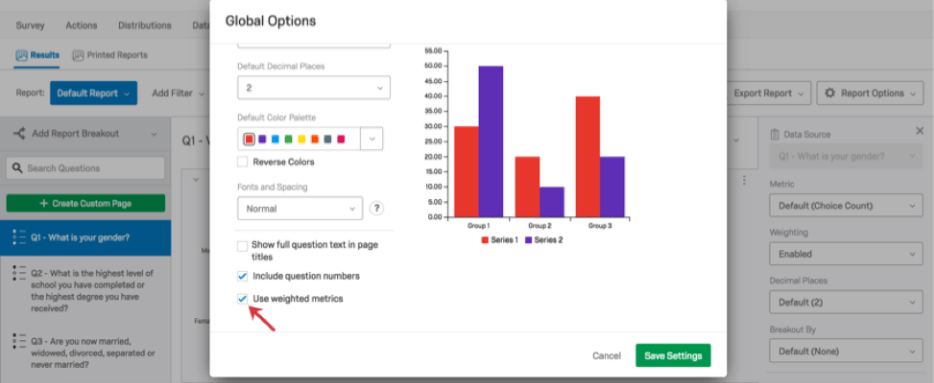
Variables multiples
Il existe deux options pour la pondération de plusieurs variables :
- Pondération en dents de scie: Calculez 2 variables (ou plus) indépendamment et affichez-les côte à côte.
- Pondération imbriquée: Superposition de deux données démographiques ou plus. Par exemple, vous pouvez fusionner une variable « Années d’expérience » avec une variable « Province ».
Décisions concernant la pondération
Les causes potentielles d’une enquête faussée sont nombreuses :
- La non-réponse: Certains groupes démographiques ne répondent pas à votre enquête.
- Conception du panel: Votre panel (liste des personnes ciblées) n’a pas été correctement sélectionné.
- Autosélection: Les personnes qui s’inscrivent à votre enquête ne reflètent pas votre cible démographique.
- La taille de l’échantillon: Il se peut que le nombre de répondants soit insuffisant pour être significatif.
C’est là que la section « Weighting » (Pondération) est utile. C’est ici que vous pouvez étudier et interpréter les problèmes de représentativité de vos données qui peuvent rendre difficile l’obtention de conclusions fiables sur la base de la distribution de vos réponses.
Section audio et vidéo
Si votre enquête contient une question à réponse vidéo, vous pouvez afficher et éditer les réponses audio et vidéo dans l’onglet Audio & ; Vidéo dans Données et analyse. À partir de là, vous pouvez afficher les transcriptions, créer des vidéos à partir des réponses audio et vidéo et les assembler en séquences de moments forts. Vous pouvez également exploiter les informations optimisées par l’IA pour identifier les thèmes dans vos réponses vidéo.
Pour plus d’informations, voir Audio & ; Video Editor.