-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Conector de entrada do XM Discover Link
Sobre o conector de entrada do XM Discover Link
Você pode usar o XM Discover Link Inbound Connector para enviar dados XM para o XM Discover por meio de um ponto de extremidade API REST e, ao mesmo tempo, aproveitar todos os recursos oferecidos pela estrutura do Connectors, como mapeamento de campos, transformações, filtros, observação de trabalhos e assim por diante.
Formatos de dados suportados
Os seguintes tipos de dados são compatíveis apenas com o formato JSON:
Antes de configurar o conector, crie um arquivo amostra que represente os campos que você gostaria de importar para o XM Discover. Consulte as páginas vinculadas acima para obter mais informações sobre os campos obrigatórios e os formatos de arquivo.
Também há arquivos de modelo disponíveis para download no conector para formatos de dados específicos:
- Chat
- Chat (padrão): Use para dados de interações digitais padrão.
- Amazon Connect: Use para interações digitais específicas do Amazon Connect Chat.
- Ligar
- Chamada (padrão): Usar para dados de transcrições de chamadas padrão.
- Verint: Use para transcrições de chamadas específicas da Verint.
- Feedback
- Dynamics 365: Use para dados do Microsoft Dynamics.
Criação de uma tarefa de conector de entrada XM Discover Link
- Na guia Jobs, clique em New Job.
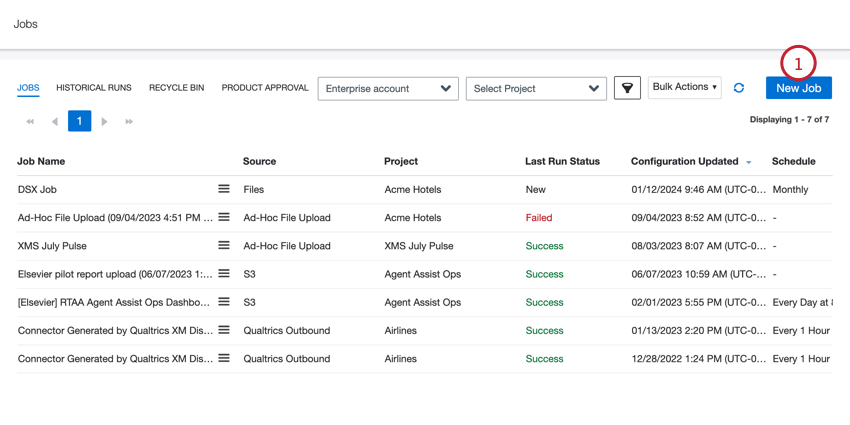
- Clique no trabalho XM Discover Link.

- Dê um nome ao seu trabalho para que você possa identificá-lo.
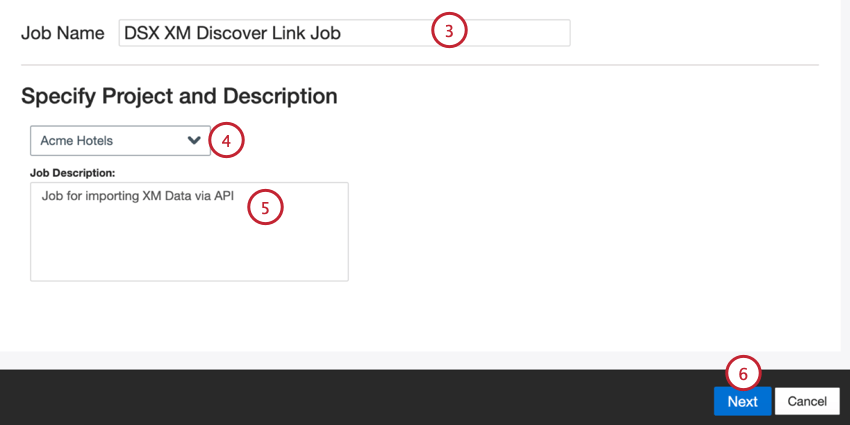
- Escolha o projeto para carregar os dados.
- Faça uma descrição do seu trabalho para que você saiba o propósito dele.
- Clique em Seguinte.
- Escolha seu modo de autorização ou como você se conectará ao XM Discover:
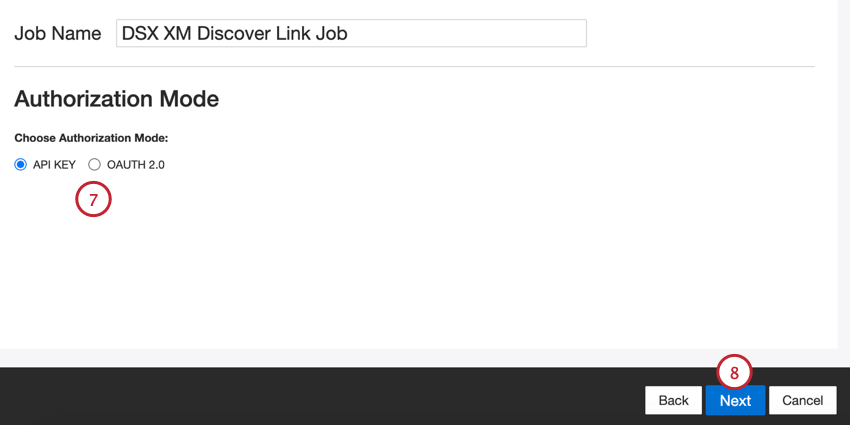
- Chave API: Conecte-se usando um token de API XM Discover.
- OAuth 2.0: Conecte-se usando um ID de cliente e um segredo de cliente fornecidos pelo serviço de autenticação XM Discover. Contato seu representante Discover para solicitar esse método.
Qdica: Você pode contato o seu representante Discover diretamente por e-mail. Se não tiver as informações contato deles, entre em contato a equipe de suporte Discover.
- Clique em Seguinte.
- Escolha o formato de seus dados: chat (digital), chamada ou feedback.
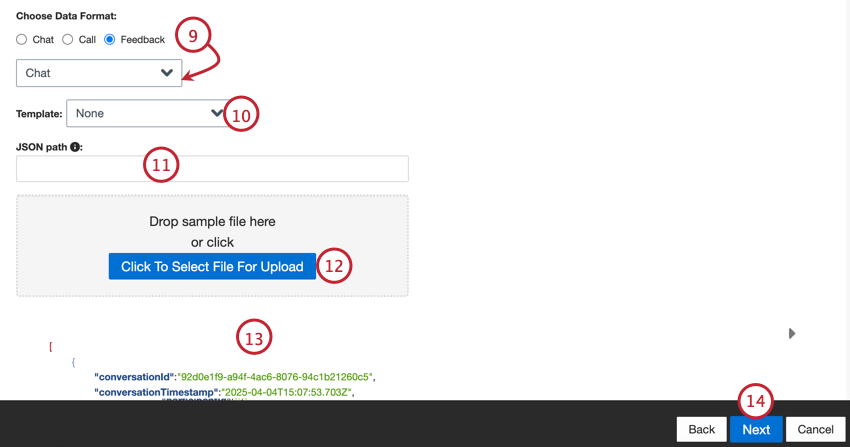 Qdica: se você selecionou “feedback”, será exibido um segundo menu para que você escolha o tipo de dados de interação incluídos no feedback. As opções incluem chamada, bate-papo, e-mail, avaliação, social e pesquisa.
Qdica: se você selecionou “feedback”, será exibido um segundo menu para que você escolha o tipo de dados de interação incluídos no feedback. As opções incluem chamada, bate-papo, e-mail, avaliação, social e pesquisa. - Se desejar, escolha um modelo e clique no link aqui para fazer o download do arquivo do modelo.
- Digite o caminho JSON para um subconjunto de JSON que contém nós de documentos. Deixe esse campo vazio se os documentos estiverem localizados no nível do nó raiz.
- Clique no botão Click To Select File For Upload e escolha o arquivo amostra em seu computador.
- Será exibida uma visualização do arquivo. Se você vir uma mensagem de erro ou o conteúdo do arquivo bruto em vez da visualização, pode haver um problema com as opções de formato de dados que você selecionou. Consulte Erros de arquivo Amostra para obter ajuda na solução de problemas do arquivo.
- Clique em Seguinte.
- Se necessário, ajuste seus mapeamentos de dados. Consulte a página de suporte do Mapeamento de dados para obter informações detalhadas sobre o mapeamento de campos no XM Discover. A seção Mapeamento de dados padrão contém orientações específicas para esse conector.
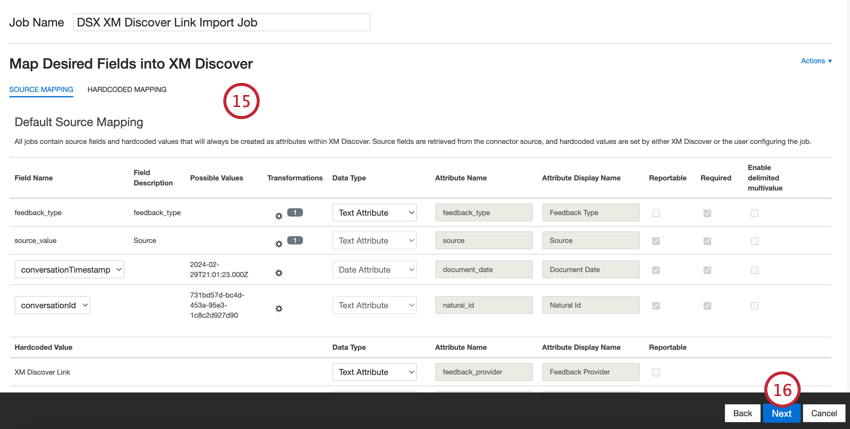
- Clique em Seguinte.
- Se desejar, você pode adicionar regras de substituição e redação de dados para ocultar dados confidenciais ou substituir automaticamente determinadas palavras e frases no feedback e nas interações do cliente. Consulte a página de suporte de Substituição e Redação de Dados para obter mais informações.
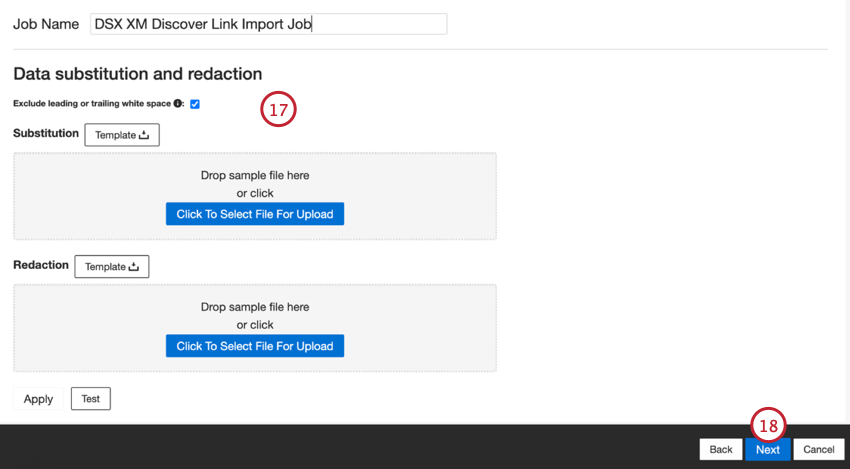
- Clique em Seguinte.
- Se desejar, você pode adicionar um filtro de conector para filtro os dados de entrada e limitar os dados importados.
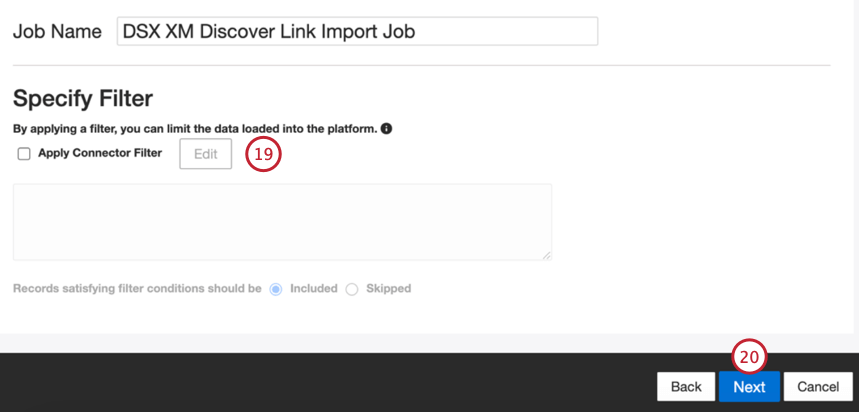
- Clique em Seguinte.
- Escolha como os documentos duplicar são tratados. Consulte Tratamento de Duplicar para obter mais informações.
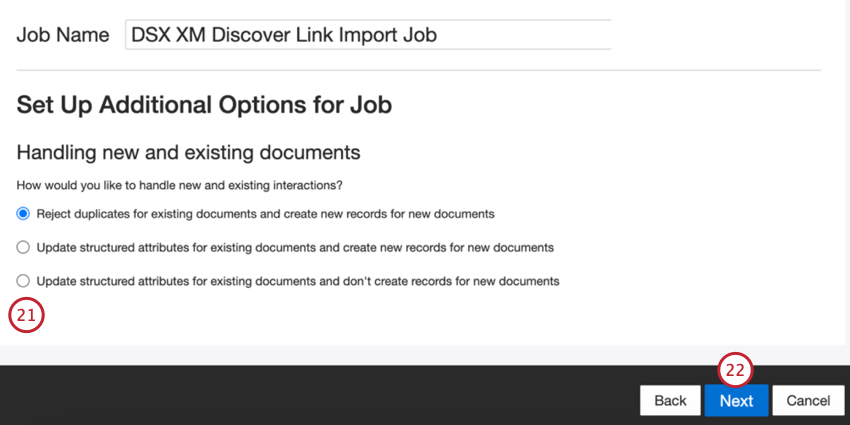
- Clique em Seguinte.
- Revise sua configuração. Se você precisar alterar uma configuração específica, clique no botão Edit (Editar ) para ser levado a essa etapa na configuração do conector.
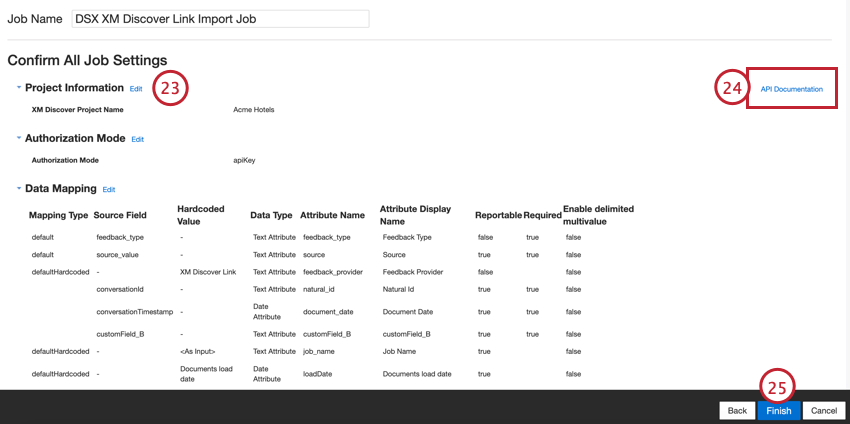
- O link Documentação API contém seu ponto de extremidade API, que será usado para enviar dados ao XM Discover. Consulte Acesso ao endpoint API para obter mais informações.
- Clique em Finish (Concluir) para salvar sua configuração.
Mapeamento de dados padrão
Esta seção contém informações sobre os campos padrão dos trabalhos XM Discover Inbound Link.
Ao mapear seus campos, os seguintes campos padrão estão disponíveis:
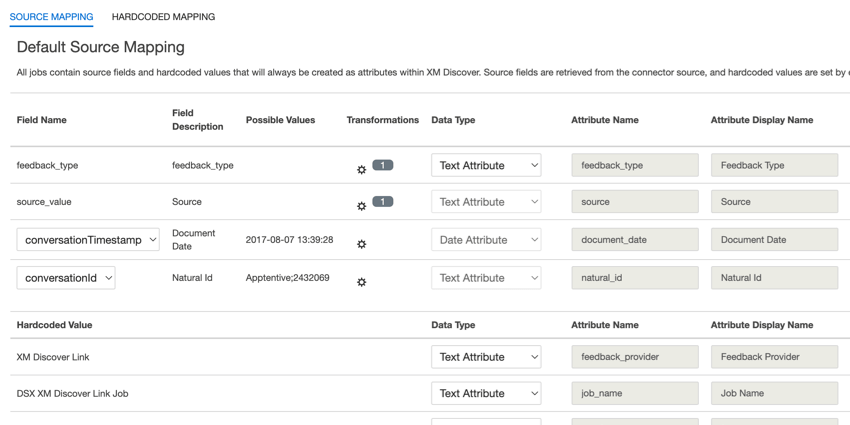
- feedback_type: O tipo de feedback ajuda a identificar os dados com base em seu tipo. Isso é útil para a geração de relatórios quando o seu projeto contém diferentes tipos de dados (por exemplo, pesquisas e feedback de mídia social). Esse campo é editável. Por padrão, o valor desse atributo é definido como:
- “call” para transcrições de chamadas
- “bate-papo” para interações digitais
- “feedback” para feedback individual
- Você pode usar transformações personalizadas para definir um valor personalizado.
- fonte: A fonte ajuda você a identificar os dados obtidos de uma fonte específica. Isso pode ser qualquer coisa que descreva a origem dos dados, como o nome de uma pesquisa ou de uma campanha de marketing móvel. Esse campo é editável. Por padrão, o valor desse atributo é definido como “XM Discover Link” Você pode usar a transformação personalizada para definir um valor personalizado.
- richVerbatim: Esse campo é usado para dados de conversação (como transcrições de chamadas e bate-papo) e não é editável. XM Discover usa um formato textual de conversação para o campo richVerbatim. Esse formato é compatível com a ingestão de metadados específicos de diálogos necessários para desbloquear visualização de conversas (turnos de falantes, silêncio, eventos de conversas, etc.) e enriquecimentos (hora de início, duração, etc.). Esse campo literal inclui campos “filhos” para rastrear o lado da conversa do cliente e do representante:
- clientVerbatim rastreia o lado da conversa do cliente.
- agentVerbatim rastreia o lado da conversa do representante (agente).
- unknown rastreia o lado desconhecido da conversa.
-
Qdica: as transformações não são compatíveis com os campos verbatim de conversação. O mesmo verbatim não pode ser usado para diferentes tipos de dados de conversação. Se quiser que seu projeto hospede vários tipos de conversação, use pares separados de verbatims de conversação por tipo de conversação.
- clientVerbatim: Esse campo é usado para dados de conversação e é editável. Esse campo rastreia o lado da conversa do cliente em interações de chamada e bate-papo. Por padrão, esse campo é mapeado para:
- clienteVerbatimChat para interações digitais.
- clientVerbatimCall para interações de chamadas.
- agentVerbatim: Esse campo é usado para dados de conversação e é editável. Esse campo rastreia o lado da conversa do representante em interações de chamada e bate-papo. Por padrão, esse campo é mapeado para:
- agentVerbatimChat para interações digitais.
- agentVerbatimCall para interações de chamadas.
- desconhecido: esse campo é usado para dados de conversação e é editável. Esse campo rastreia o lado desconhecido da conversa em interações de chamadas e bate-papo:
- unknownVerbatimChat para interações digitais.
- unknownVerbatimCall para interações de chamadas.
- document_date: a data do documento é o campo de data principal associado a um documento. Essa data é usada nos relatórios, tendências e alertas XM Discover, entre outros. Para a data do documento, escolha uma das seguintes opções:
- conversationTimestamp (para dados de conversação): Data e hora de toda a conversa.
- Se os dados de origem contiverem outros campos de data, você poderá definir um deles como data do documento, selecionando-o no menu suspenso em Nome do campo.
- Você também pode definir uma data específica adicionando um campo personalizado.
- natural_id: A ID natural serve como um identificador exclusivo de um documento e permite o processamento correto de duplicatas. Para a ID natural, escolha uma das seguintes opções:
- conversationId (para dados de conversação): Uma ID exclusiva para toda a conversa.
- Selecione qualquer campo de texto ou numérico de seus dados em Nome do campo.
- Gerar IDs automaticamente adicionando um campo personalizado.
- feedback_provider: O provedor de feedback ajuda você a identificar os dados obtidos de um provedor específico. Para uploads do XM Discover Link, o valor desse atributo é definido como “XM Discover Link” e não pode ser editado.
- job_name: o nome do trabalho ajuda você a identificar os dados com base no nome do trabalho usado para carregá-los. Você pode modificar o valor desse atributo na caixa Nome do trabalho na parte superior da página ou usando o menu de opções do trabalho.
- loadDate: A data de carregamento indica quando um documento foi carregado no XM Discover. Esse campo é definido automaticamente e não pode ser editado.
Além dos campos acima, você também pode mapear quaisquer campos personalizados que queira importar. Consulte a página de suporte do Data Mapping para obter mais informações sobre campos personalizados.
Acesso ao ponto de extremidade API
O ponto de extremidade API é usado para fazer upload de dados para o XM Discover, enviando os dados por meio de uma solicitação API REST no formato JSON.
Você pode acessar o endpoint na página Jobs:
- Selecione Summary (Resumo ) no menu de opções de trabalho para seu trabalho.
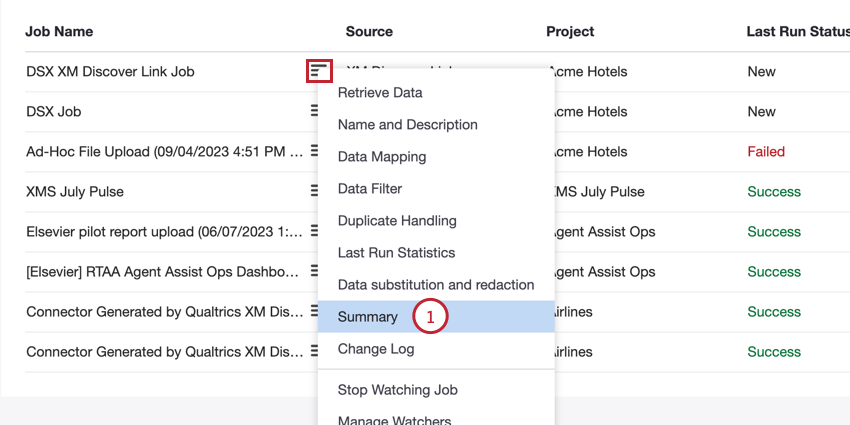
- Clique no link Documentação API.

- Clique no botão Imprimir para fazer o download de todas as informações dessa janela como um PDF para impressão.
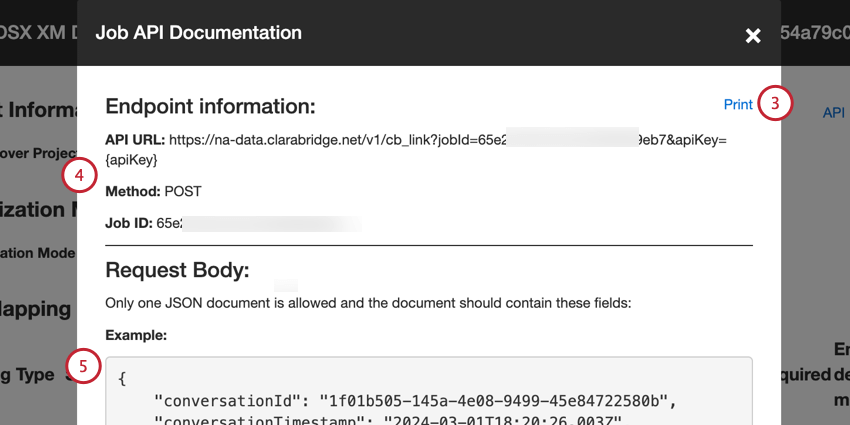
- Suas informações de endpoint incluem:
- URL API: O URL usado para a solicitação de API.
- Método: Use o método POST para carregar dados no XM Discover.
- ID do trabalho: A ID do trabalho selecionado no momento.
- Um exemplo de carga útil JSON está incluído na seção Corpo da solicitação. Uma solicitação API deve conter apenas um documento e incluir somente os campos no exemplo de carga útil.
- A seção Respostas lista as possíveis respostas de sucesso e erro da solicitação de API.
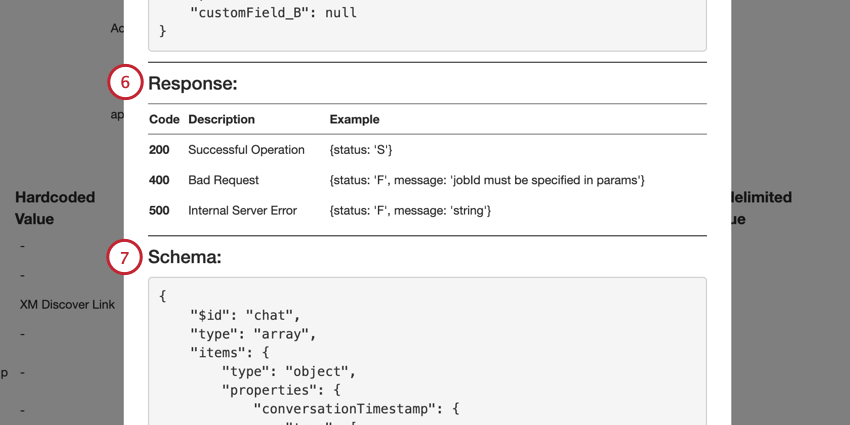
- A seção Schema exibe o esquema de dados. Os campos obrigatórios estão na matriz obrigatória.
Monitoramento de um trabalho XM Discover Link via API
Você pode monitorar o status dos trabalhos XM Discover Link sem fazer login no XM Discover, chamando o endpoint API de status. Isso permite que você obtenha o status mais recente da execução do trabalho, métricas para uma execução de trabalho específica ou métricas acumuladas para um período de tempo específico.
Informações do ponto de extremidade de status
Para chamar o endpoint de status, você precisará do seguinte:
- URL API https://na-data.clarabridge.net/v1/public/job/status/<jobID>?apiKey=<apiKey>
- <jobId> é a ID do trabalho XM Discover Link que você deseja monitorar.
- <apiKey> é o token de API.
- Tipo: Use o REST HTTP
- Método HTTP: Use o método GET para recuperar dados.
Elementos de entrada
Os seguintes elementos de entrada opcionais podem ser usados para recuperar métricas adicionais sobre seu trabalho:
- historicalRunId: O ID da sessão de upload específica. Se esse elemento for omitido e nenhum intervalo de datas for fornecido, a chamada de API retornará o status mais recente da execução do trabalho. Se esse elemento for omitido e um intervalo de datas for fornecido, a chamada de API retornará métricas acumuladas para o período de tempo especificado.
- startDate: Defina a data inicial a partir da qual os dados serão retornados.
- endDate: Defina a data final para retornar dados com base no último upload. Se esse elemento for omitido e a startDate for fornecida, a endDate será automaticamente definida como a data atual.
Elementos de saída
Os seguintes elementos de saída serão retornados, desde que você tenha inserido os elementos de entrada necessários:
- job_status: O status do trabalho.
- job_failure_reason: Se o trabalho falhou, o motivo da falha.
- run_metrics: Informações sobre os documentos processados pelo trabalho. As seguintes métricas estão incluídas:
- SUCCESSFULLY_CREATED: O número de documentos criados com sucesso.
- SUCCESSFULLY_UPDATED: O número de documentos atualizados com sucesso.
- SKIPPED_AS_DUPLICATES: O número de documentos ignorados como duplicatas.
- FILTERED_OUT: O número de documentos filtrados por um filtro específico da fonte ou por um filtro de conector.
- BAD_RECORD: O número de interações digitais enviadas para processamento que não correspondem ao formato de conversação do Qualtrics.
- SKIPPED_NO_ACTION: o número de documentos ignorados como não duplicados.
- FAILED_TO_LOAD: O número de documentos que não foram carregados.
- TOTAL: O número total de documentos processados durante a execução desse trabalho.
Mensagens de erro
As seguintes mensagens de erro são possíveis para a solicitação de status API:
- 401 Não autorizado: Falha na autenticação. Use uma chave API diferente.
- 404 Não encontrado: Não existe um trabalho com a ID especificada. Use um ID de trabalho diferente.
Solicitação Amostra
Veja a seguir um exemplo de solicitação para obter o status de um trabalho
:curl --location --request GET 'https://na-data.clarabridge.net/v1/public/job/status/62da736987c9788b830918e0?apiKey=02e7a0e26b592632dd50f623e974fff6'
Resposta Amostra
Abaixo está um amostra resposta de um trabalho com falha
:{
"job_status": "Failed",
"job_failure_reason": "{\"problem\":[{\"requestId": "RQ-MOB-f339aa58-71b6-4a1d-a67c-12b8d3439321", "severity": "ERROR", "description": "O limite de comprimento de 900 caracteres para o atributo supportexperienceresp foi excedido, o comprimento é 1043\"}],\"status\":\"ERROR\"}",
"run_metrics": {
"successfully_created": 10,
"failed_to_load": 1,
"total": 11
}
}
Exemplos de carga útil
Esta seção contém um exemplo de carga útil JSON para cada tipo de dados estruturados suportados (feedback, chat, chamada).
- Clique aqui para ver o exemplo de carga útil de feedback.
curl --location --request POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4e583f9142ae48a1090a76' \
--header 'Content-Type: application/json' \
--data-raw '{
"dataSource": "Standard JSON",
"Row_ID": "id43682",
"store_number": "226,1,1,0,0",
"address": "5916 W Loop 289 Lubbock, TX 79424",
"phone_number": "806-791-4384",
"reviewer_name": "Mariposa",
"review_rating": 2,
"Review_Date": "03.03.2019",
"Employee_Knowledge": 2,
"Price_value": 3,
"Checkout_process": 1,
"Comments": "Uma das melhores experiências que tive na Best Buy em um longo tempo. Continue com o bom trabalho.",
"LTR": 10,
"state": "TX",
"Rewards_Member": "MyBestBuy"
}'
- Clique aqui para ver o exemplo de carga útil do chat.
curl --location --request POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4d77656afa99b0396ef959' \
--header 'Content-Type: application/json' \
--data-raw '{
"conversationId": "37854",
"conversationTimestamp": "2020-07-30T12:42:15.000Z",
"content": {
"contentType": "CHAT",
"participants": [
{
"participantId": "1",
"participantType": "AGENT",
"is_bot": true
},
{
"participantId": "2",
"participantType": "CLIENT",
"is_bot": false
}
],
"conversationContent": [
{
"participantId": "1",
"text": "Hello, how may I help you?" (Olá, como posso ajudá-lo?),
"timestamp" (registro de data e hora): "2020-07-30T12:42:15.000Z",
"id": "3785201"
},
{
"participantId": "2",
"text": "Hi, are you open today?" (Olá, você está aberto hoje?),
"timestamp" (registro de data e hora): "2020-07-30T12:42:15.000Z",
"id": "3785202"
},
{
"participantId": "1",
"text": "Estamos abertos das 17:00 às 23:00.",
"timestamp": "2020-07-30T12:42:15.000Z",
"id": "3785203"
},
{
"participantId": "2",
"text": "I would like to make a reservation." (Gostaria de fazer uma reserva),
"timestamp" (registro de data e hora): "2020-07-30T12:42:15.000Z",
"id": "3785204"
},
{
"participantId": "1",
"text": "Absolutamente! Que nome posso usar?",
"timestamp": "2020-07-30T12:42:15.000Z",
"id": "3785205"
}
]
},
"city": "Boston",
"source": "Facebook"
}'
- Clique aqui para ver o exemplo de carga útil da chamada.
curl --location --request POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4e564d9242ae6e6308ff04' \
--header 'Content-Type: application/json' \
--data-raw '{
"conversationId": "462896",
"conversationTimestamp": "2020-07-30T10:15:45.000Z",
"content": {
"contentType": "CALL",
"participants": [
{
"participant_id": "1",
"type": "AGENT",
"is_ivr": false
},
{
"participant_id": "2",
"type": "CLIENT",
"is_ivr": false
}
],
"conversationContent": [
{
"participant_id": "1",
"text": "This is Emily, how may I help you?",
"start": 22000,
"end": 32000
},
{
"participant_id": "2",
"text": "Hi, I have a couple of questions." (Olá, tenho algumas perguntas),
"start" (início): 32000,
"end": 42000
}
],
"contentSegmentType": "TURN"
},
"city": "Boston",
"source": "Call Center"
}'