-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
組織階層 インバウンドコネクター
組織階層インバウンドコネクタについて
注意この機能を使用するには、組織独自の SFTP サーバが必要です。クアルトリクスは、プロフェッショナルサービスチームを通じて、お客様用のSftpサーバーを提供しています。このサービスには費用がかかりますが、これらのサーバーがクアルトリクスと互換性があることを保証いたします。連絡先はプロフェッショナル・サービス・チームまで。
組織階層を使用すると、XM Discoverに組織構造をアップロードして、データ分析、ユーザーパーソナライズ、データアクセスコントロールを向上させることができます。組織階層受信コネクタを使用して、組織階層をアップロードおよび更新できます。
Qtip:組織階層は、作成場所(スタジオまたはコネクター)に関係なく、同じように機能します。
組織階層ファイルの準備
組織階層の受信ジョブを設定する前に、組織階層データが適切な形式で、組織構造を含んでいることを確認する必要があります。
組織階層は、CSVまたはExcel(XLSまたはXLSX)ファイルを使用してアップロードできます。
各ファイルタイプの例とフォーマットのガイドラインについては、組織階層のベストプラクティスを参照してください。
例以下は、あるホテル会社の組織構造の例を示したエクセルファイルです。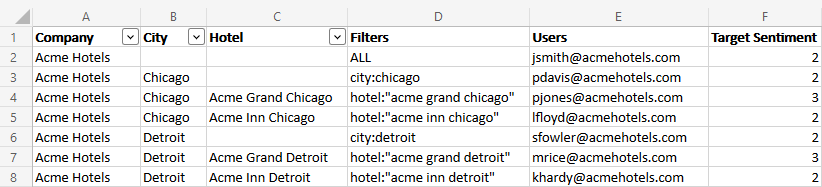
組織階層の設定 インバウンドジョブ
Qtip:この機能を使用するにはManage Jobs 権限が必要です。
組織階層インバウンドジョブを設定するには、以下の手順に従ってください。このセットアップでは、Studio で階層 API トークンを生成する必要があります。
- ジョブ]タブで[新規ジョブ]をクリックします。
- 組織階層を選択します。
- 自分の仕事に名前をつけて、ITと識別できるようにする。
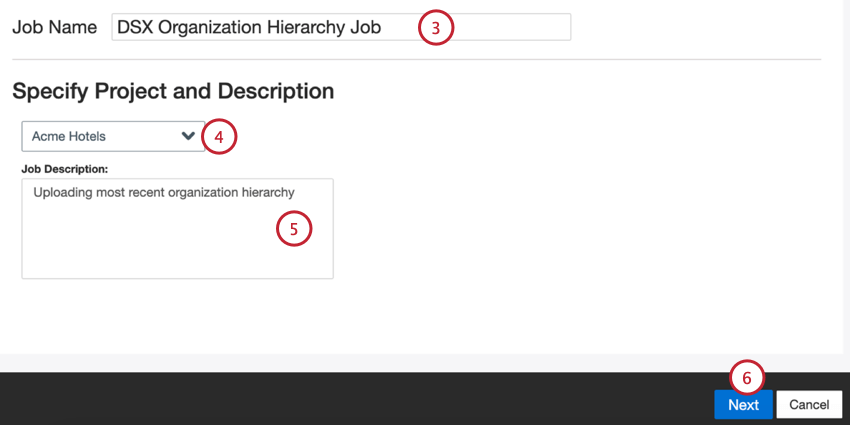
- データをロードするプロジェクトを選択します。
- 自分の仕事を説明し、その目的がわかるようにする。
- [次へ]をクリックします。
- SFTP サーバの認証機能を選択します:
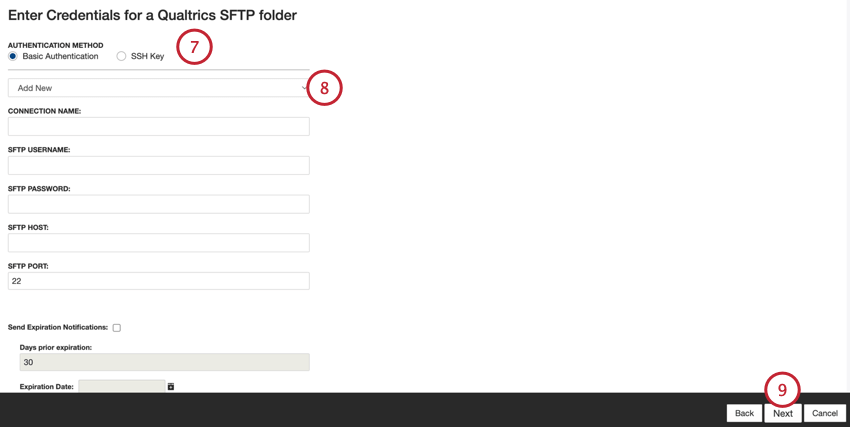
- 基本認証機能:ユーザー名とパスワードを使用して接続します。
- SSHキー:お客様が用意したSSHキー、またはクアルトリクスが用意したSSHキーを使用して接続します。
- ドロップダウンを使用して既存の接続を選択するか、[新規追加] を選択して新しい接続を設定します。新しい接続の作成の詳細については、「Sftp アカウントの追加」を参照してください。
- [次へ]をクリックします。
- 階層のタイプを選択します:
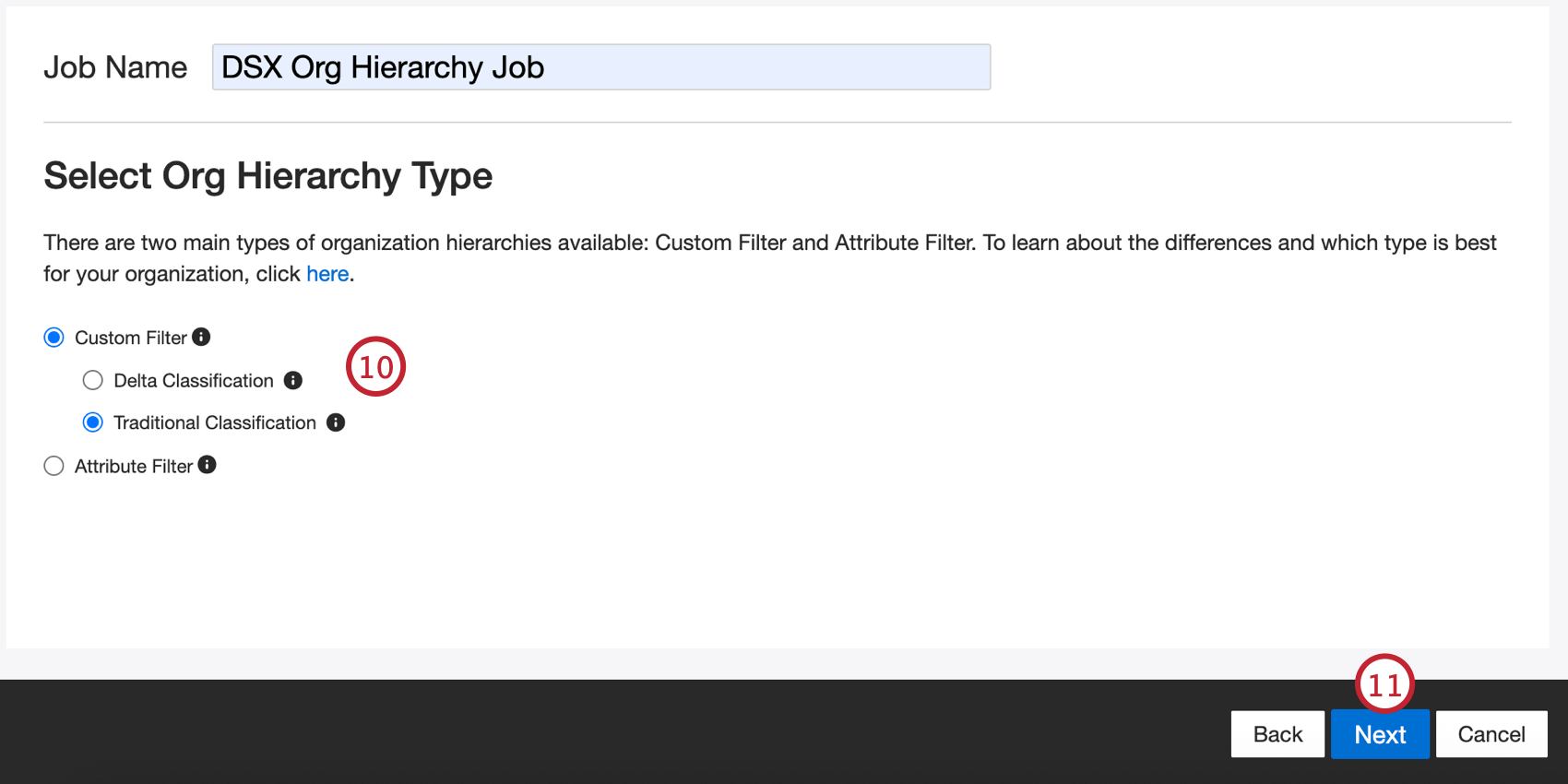
- カスタムフィルター
- デルタ分類
- 伝統的な分類
- 属性フィルタ
Qtip:階層名の隣にある情報アイコンにカーソルを合わせると、その階層と使用例について知ることができます。
- カスタムフィルター
- [次へ]をクリックします。
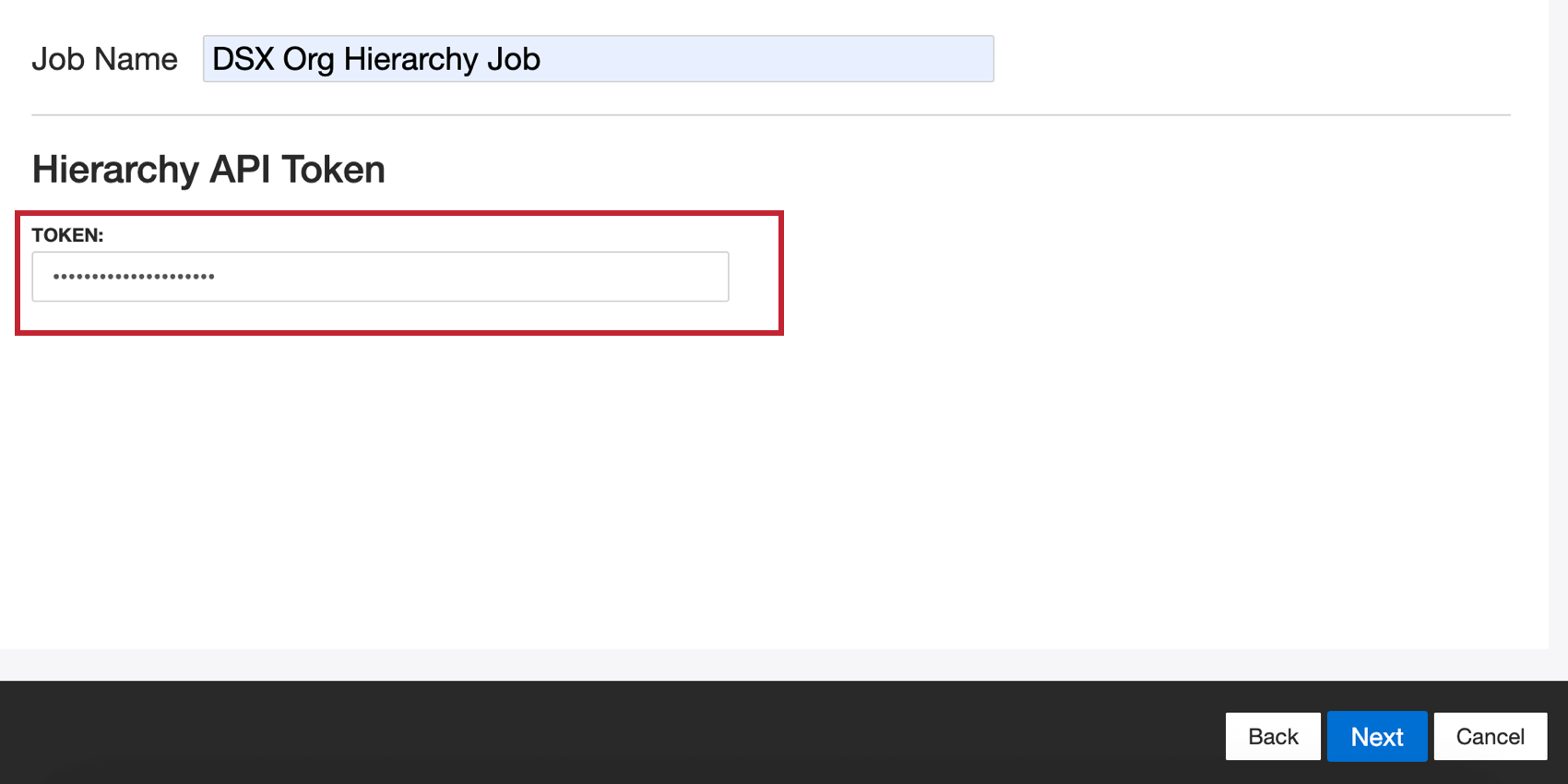
- 伝統的な分類 “階層タイプを使用する場合は、”Traditional Classification “階層タイプも入力する必要がある。 階層APIトークン. そうでなければ次へ進む。
- 階層に名前をつける。
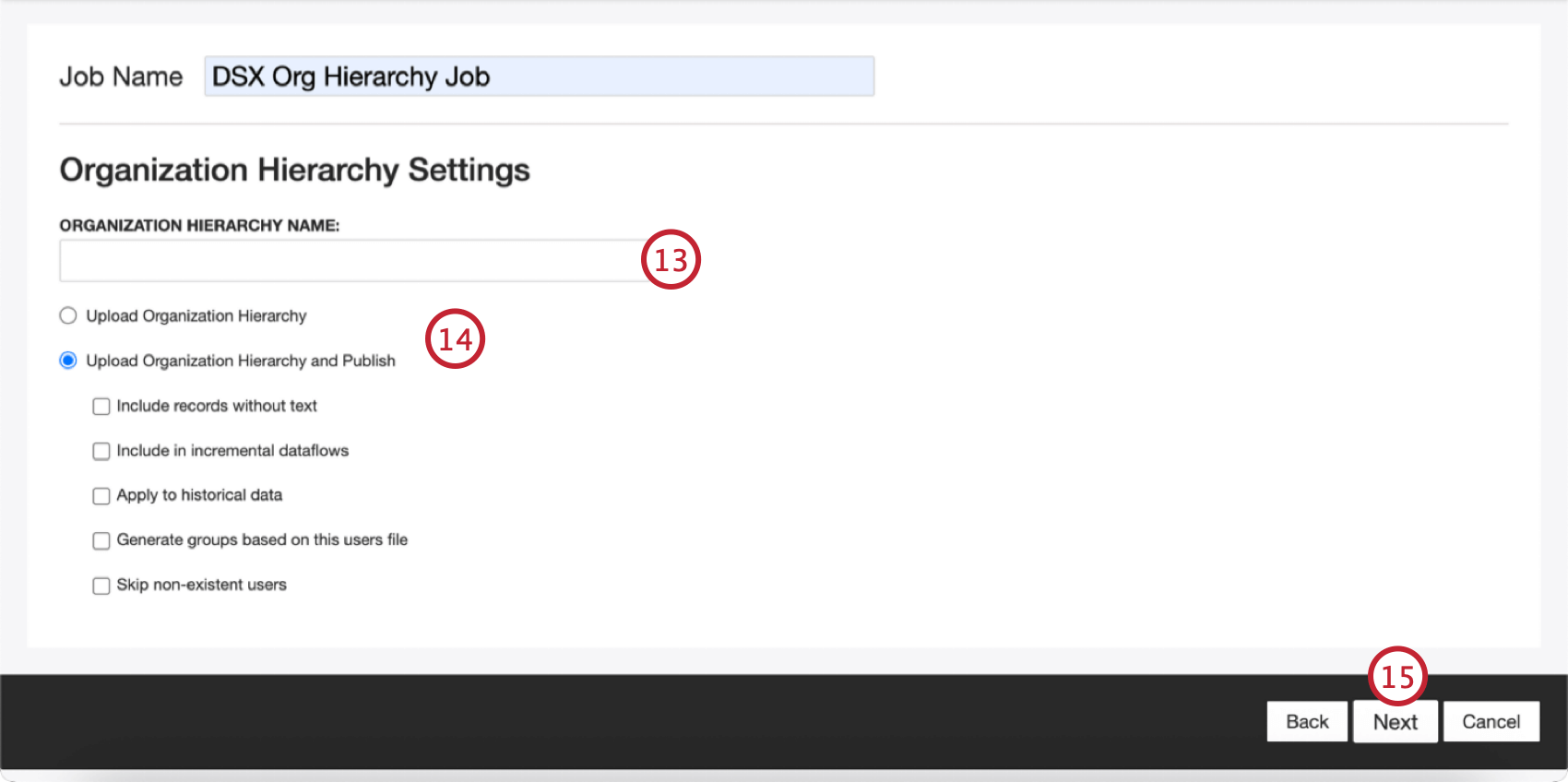 Qtip:ここで入力する名前が既存の階層名と完全に一致していることを確認することで、既存の階層を更新することができます。
Qtip:ここで入力する名前が既存の階層名と完全に一致していることを確認することで、既存の階層を更新することができます。 - 階層設定を選択します。ここでのオプションは、ステップ10で選択した階層タイプによって異なります:
- デルタ分類
- 組織階層をアップロードします:組織階層を作成し、アクティブにします。デフォルトでは、アクティブ化された組織階層は未公開であり、ダッシュボードのパーソナライゼーションのみが有効になります。有効にすると、以下のサブオプションも利用できる:
- このユーザーファイルに基づいてグループを生成します:組織階層ファイルに基づいてグループを作成します。
- 存在しないユーザーをスキップする:既存のDiscoverユーザーに該当しないユーザーをスキップします。
- 組織階層をアップロードします:組織階層を作成し、アクティブにします。デフォルトでは、アクティブ化された組織階層は未公開であり、ダッシュボードのパーソナライゼーションのみが有効になります。有効にすると、以下のサブオプションも利用できる:
- 組織階層のアップロードと公開:組織階層の作成、有効化、公開。組織階層を公開することで、レベル別にデータをグループ化することができます。これはピアレポート、ペアレントレポート、ターゲットレポート、バリアンスレポートの前提条件である。これはまた、追加のユースケースをサポートするための隠れたカテゴリーモデルを作成する。このモデルは、組織階層の構造とフィルターを反映している。有効にすると、以下のサブオプションも利用できる:
- テキストのないレコードを含める:組織階層に空の逐語訳を持つレコードを含めます。
- インクリメンタルデータフローに含める:インクリメンタルデータフローに
組織階層を含めるQtip:組織階層を公開することで、他のデータフローと競合することが予想される場合は、このオプションの選択を解除することをお勧めします。このオプションが無効の場合、作成され、その後分類されるモデルは、他のデータフローをブロックしない。 - 過去のデータに適用する:過去のデータに組織階層を適用する。
- このユーザーファイルに基づいてグループを生成します:組織階層ファイルに基づいてグループを作成します。
- 存在しないユーザーをスキップする:既存のDiscoverユーザーに該当しないユーザーをスキップします。
- 伝統的な分類:
- 組織階層をアップロードします:組織階層を作成し、アクティブにします。デフォルトでは、アクティブ化された組織階層は未公開であり、ダッシュボードのパーソナライゼーションのみが有効になります。有効にすると、以下のサブオプションも利用できる:
- このユーザーファイルに基づいてグループを生成します:組織階層ファイルに基づいてグループを作成します。
- 組織階層のアップロードと公開:組織階層の作成、有効化、公開。組織階層を公開することで、レベル別にデータをグループ化することができます。これはピアレポート、ペアレントレポート、ターゲットレポート、バリアンスレポートの前提条件である。これはまた、追加のユースケースをサポートするための隠れたカテゴリーモデルを作成する。このモデルは、組織階層の構造とフィルターを反映している。有効にすると、以下のサブオプションも利用できる:
- テキストのないレコードを含める:組織階層に空の逐語訳を持つレコードを含めます。
- インクリメンタルデータフローに含める:インクリメンタルデータフローに
組織階層を含めるQtip:組織階層を公開することで、他のデータフローと競合することが予想される場合は、このオプションの選択を解除することをお勧めします。このオプションが無効の場合、作成され、その後分類されるモデルは、他のデータフローをブロックしない。 - このユーザーファイルに基づいてグループを生成します:組織階層ファイルに基づいてグループを作成します。
- 組織階層をアップロードします:組織階層を作成し、アクティブにします。デフォルトでは、アクティブ化された組織階層は未公開であり、ダッシュボードのパーソナライゼーションのみが有効になります。有効にすると、以下のサブオプションも利用できる:
- 属性フィルタ
- 存在しないユーザーをスキップする:既存のDiscoverユーザーに該当しないユーザーをスキップします。
- デルタ分類
- [次へ]をクリックします。
- アップロードするファイルの種類を選択します:
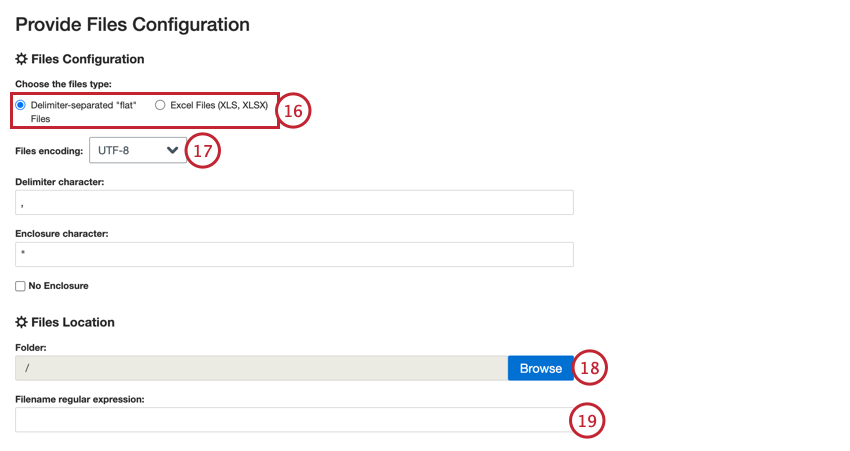
- デリミタ区切りの “フラット “ファイル
- エクセルファイル(XLS、XLSx)
- 区切り文字で区切られたフラットファイルには、さらに選択できる設定があります:
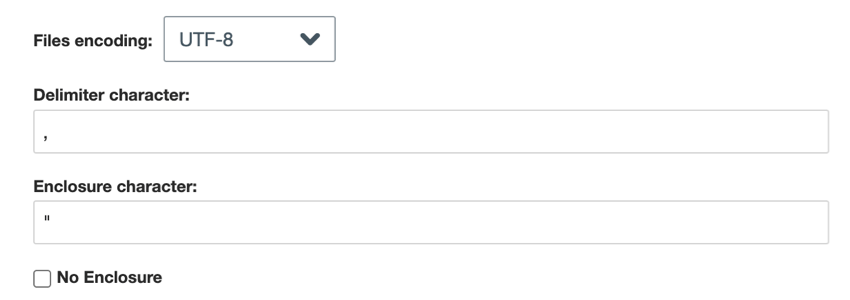
- ファイルのエンコーディング:ファイルのエンコード方式を選択します(UTF-8、ASCIIなど)。
- 区切り文字:データエントリの区切りに使用する文字を入力します。デフォルトでは、CSVファイルの場合はカンマです。
- 囲み文字:データ入力を囲む文字を入力します。No enclosure “を選択した場合、このフィールドは空白のままにする。
- No enclosure:ファイルに囲み文字が含まれていない場合、このオプションを有効にします。
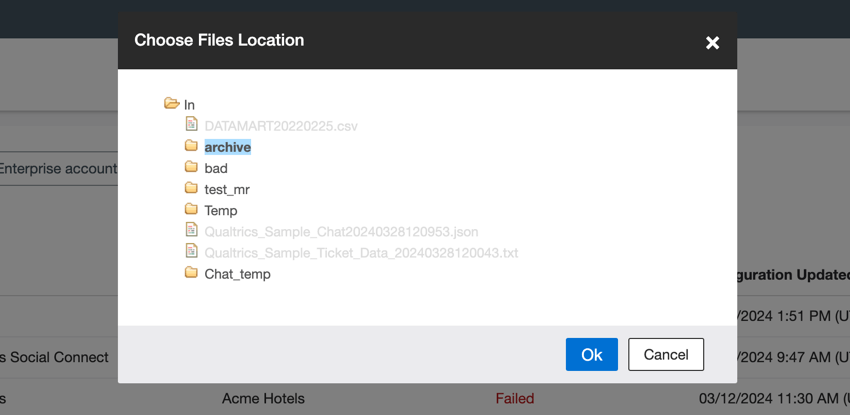
- Browse(参照)」をクリックし、アップロードするファイルが格納されている SFTP サーバ上のフォルダパスを選択します。
Qtip:フォルダーパスを選択する際、フォルダーアイコンをクリックするとそのフォルダーを展開することができます。フォルダ名をクリックしてそのフォルダを選択し、完了したらOkをクリックします。
- アップロードするファイルにマッチするファイル名の正規表現を入力します。
- ファイルが圧縮されている場合は、Unzip file(s)を有効にし、解凍するファイルにマッチするZipped Filename正規表現を入力します。
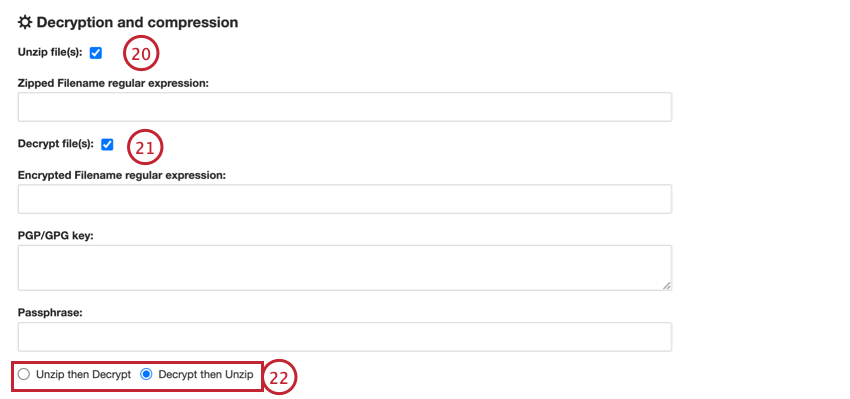
- ファイルが復号化されている場合は、Decrypt file(s)を有効にし、以下のように入力します:
- 暗号化されたファイル名の正規表現:復号化するファイル名の正規表現を入力します。
- PGP/GPGキー:暗号化に使用するPGP/GPGキーを入力します。
- パスフレーズ:復号化のためのパスフレーズを入力します。
- ファイルが圧縮と暗号化の両方を行っている場合、どちらを先に行うかを選択する必要があります:
- 解凍してから復号化:ファイルを解凍してから復号化する。
- 復号化してから解凍ファイルの暗号化を解除してから解凍します。
- サンプルファイルを提供する必要があります。サンプルファイルは、コンピュータまたはSftpサーバーに保存できます:
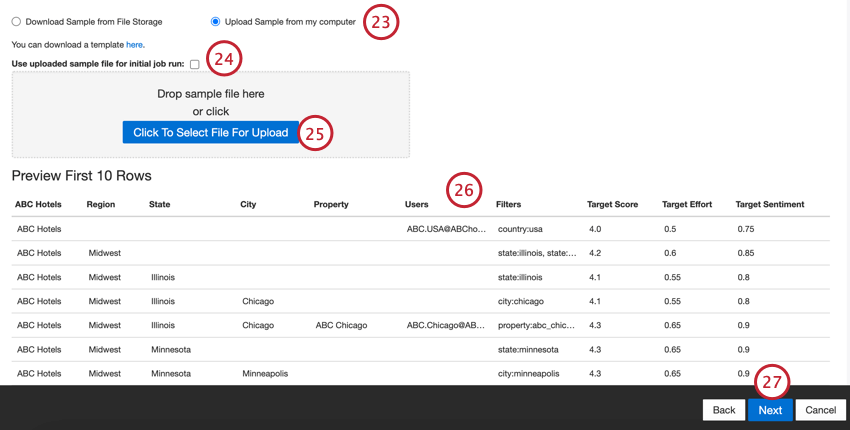
- サンプルファイルがSftpサーバーに保存されている場合は、「Download Sample from File Storage(ファイルストレージからサンプルをダウンロード)」を選択します。
- サンプルがコンピュータに保存されている場合は、「Upload sample from my computer」を選択します。
Qtip:必要であれば、ジョブセットアップに表示されるこちらのリンクをクリックして、テンプレートファイルをダウンロードすることができます。
- デフォルトでは、サンプルファイルは組織階層の生成には使用されません。サンプルファイルを最初のジョブ実行に使用したい場合は、Use uploaded sample file for initial job run(アップロードされたサンプルファイルを最初のジョブ実行に使用する)を有効にしてください。
- Select File(ファイル選択)」ボタンをクリックし、コンピュータまたはSftpサーバ上のサンプルファイルを選択します。
- ファイルのプレビューが表示されます。プレビューではなく、エラーメッセージや未加工データの内容が表示される場合は、選択したデータ形式オプションに問題がある可能性があります。ファイルのトラブルシューティングについては、サンプルファイルエラーを参照してください。
- [次へ]をクリックします。
- サンプルファイルのフィールドをXM Discoverの組織階層フィールドにマッピングし始めます。マッピング 列のボックスをクリックして、インポートしたフィールドにマッピングするXM Discover組織階層フィールドを選択します。可能な組織階層フィールドには以下が含まれる:
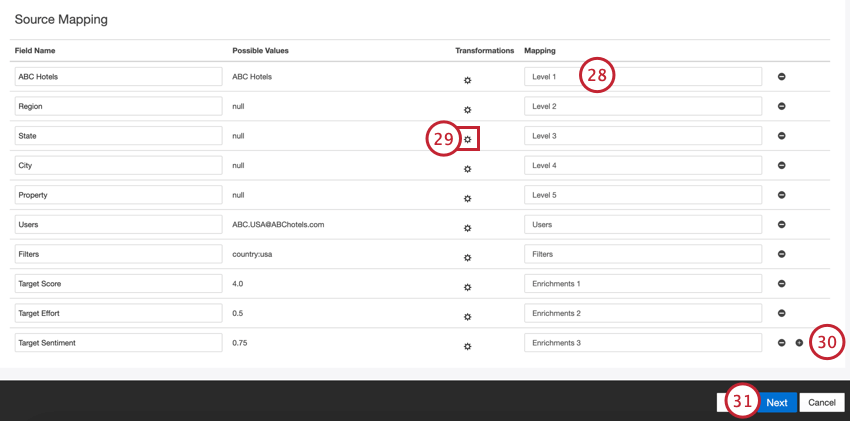
- レベル1からレベル10:階層構造を定義する。階層レベルの最大数は10である。
- ユーザー:ユーザーを階層にマッピングします。
- フィルター:階層のフィルターを定義します。
- エンリッチメント:階層のエンリッチメント・パラメータを作成する。エンリッチメントの最大数は6。
- 必要に応じて、Transformations列の歯車アイコンをクリックして、受信データを変換することができます。
- プラス記号(+)をクリックしてフィールドを追加したり、フィールドの横にあるマイナス記号(-)をクリックしてフィールドを削除することができます。
- フィールドのマッピングが終わったら次へをクリックします。
- 通知設定を選択します。
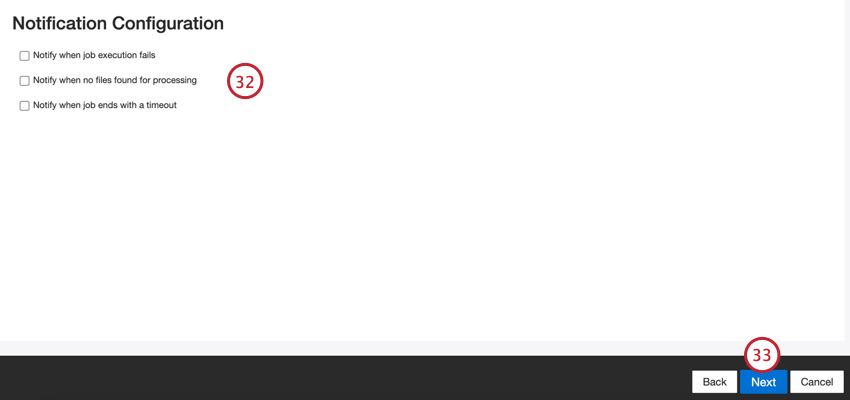
- [次へ]をクリックします。
- ジョブをスケジュールで定期的に実行したい場合はSchedule Incremental Runsを選択し、ジョブを一度だけ実行したい場合はSet Up One-Time Pullを選択します。詳細はジョブ・スケジューリングを参照。
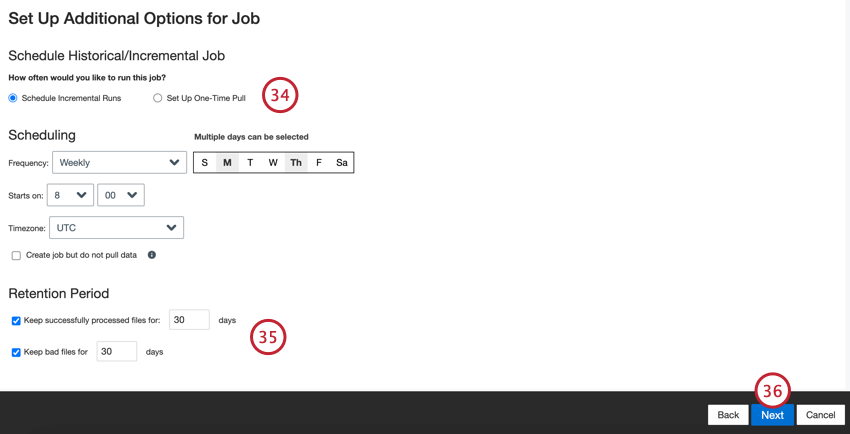
- 処理されたファイルの保持/定着率/離職防止期間を選択します。設定した期間が経過するとファイルは削除される。
- [次へ]をクリックします。
- セットアップを評価する。特定の設定を変更する必要がある場合は、[Edit]ボタンをクリックして、コネクタ設定のそのステップに移動します。
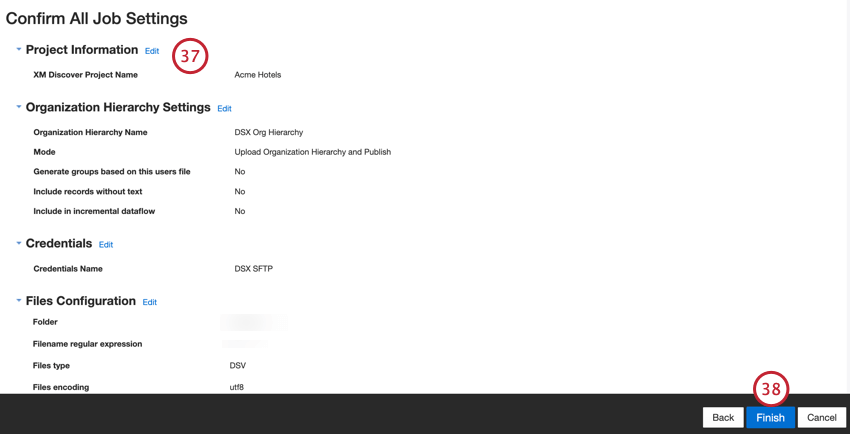
- Finishをクリックしてジョブを保存する。