ジョインズ(CX)
このページの内容
ジョインズについて
結合を使用すると、2つ以上のデータソースから、それらに共通する関連するデータ列に基づいて行を結合することができます。結合を使用することで、結合されたデータをより効率的かつ効果的に収集・分析し、より多くのインサイトを作成することができます。
例: ある顧客の解決したサポートチケットとアンケート調査データ、ディレクトリ連絡先データなどを連携させることで、ある顧客と御社とのやり取りを完全に把握することができます。
CXデータモデリングツールは、主に左外部結合をサポートしています。左外部結合のみが連続的に更新される。
Qtip:データセットとデータソースの違いについて迷っていますか?データマッパーとモデリングの見分け方がわからない?これらの用語やその他の重要な用語について詳細を見る。
参加キー
結合キーは、複数のデータセットのマッチングを助けるフィールドで、どのレコードを結合すべきかを特定する。例えば、IDやユーザー名など、ダッシュボードのデータにマッピングする一意の識別子です。ジョイン・キーは、ジョインが正しく設定されていることを確認するために重要である。
例: 同じユーザー名で複数のアンケートに同じ顧客を識別することで、すべてのフィードバックを一箇所にリンクすることができます。
例: アンケート回答から作成されたチケットは、対応するアンケート回答 ID を保存します。この回答 ID を使用して、チケット情報とアンケート調査の回答をリンクすることで、カスタマーサポートのやり取りと顧客のフィードバックを全体として表示することができます。
例: LOCATIONS IDは、顧客がどの店舗のロケーションを評価しているかを識別するために使用されます。LOCATIONS IDを使用して、店舗間のレコードを組み合わせ、店舗のパフォーマンスを比較することができます。
データモデリングツールは結合キーをサポートしていません:
- 再コード化された。
- 編集済み
- 任意のText iQフィールド(トピック、感情、行動可能性など)に入力されます。
- 50,000以上のユニークな値を持つ。
右サイドまたは左サイドに追加された結合キーは、これらのセットアップをサポートしない。
警告: 再コード化されたフィールドを結合キーとして使用することはできません。フィールドキーとして使用された後にフィールドを再コード化すると、データセットの変更を公開できなくなります。
左外部結合を理解する
左外部結合の仕組みを理解するために、例を見てみましょう。ここでは、顧客のフィードバックに店舗のLocationSに関する情報を追加します。
下のデータセットの画像を見てください。上の1つ目のデータソースが “左 “のデータソースで、下の2つ目のデータソースが “右 “のデータソースである。
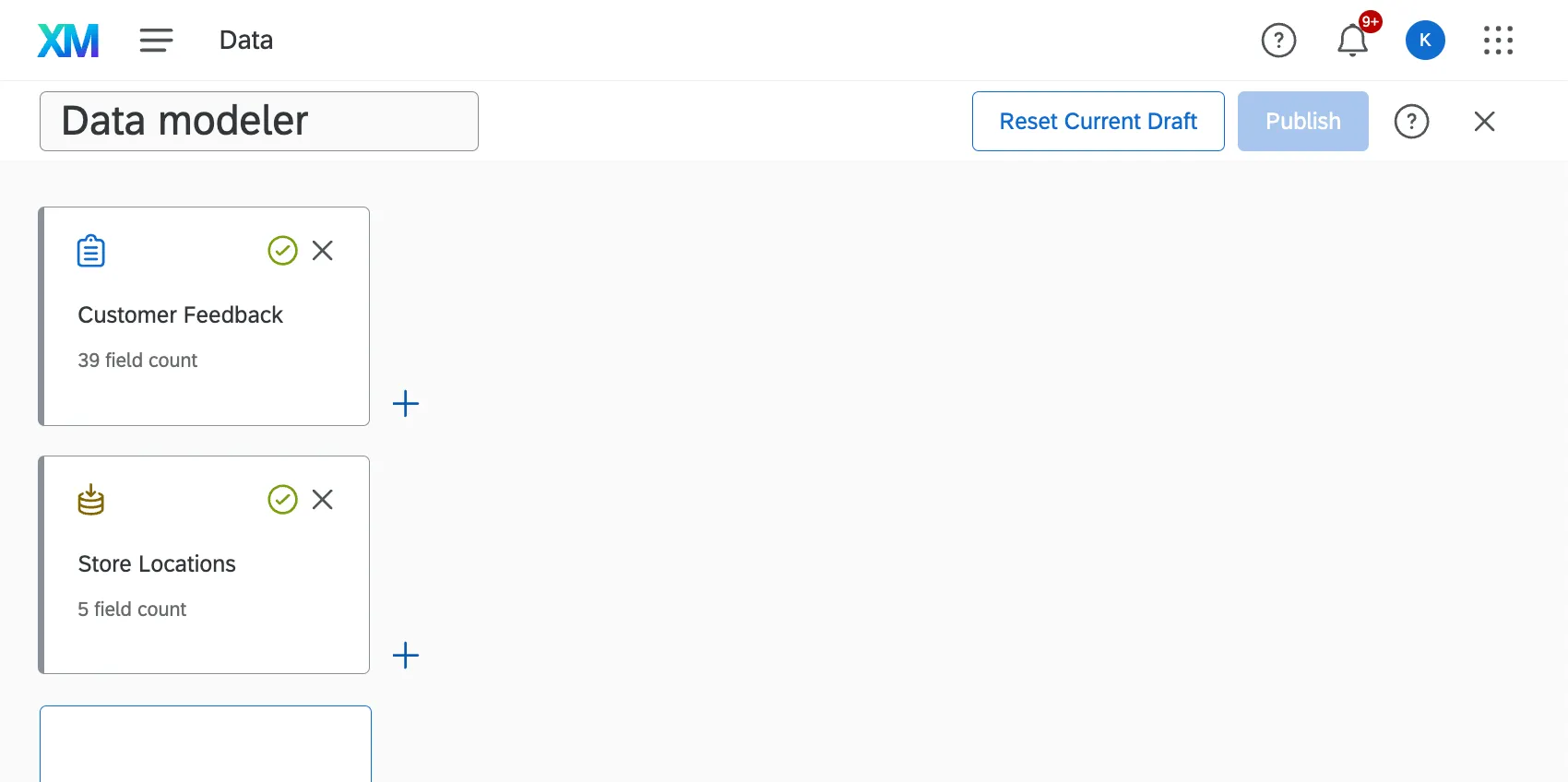
これらのテーブルが、各アンケートに含まれるデータを表しているとしましょう
。
| 顧客ID | 満足度 (1-5) | 場所ID |
|---|---|---|
| 101 | 2 | 555 |
| 102 | 4 | 777 |
| 103 | 5 | 999 |
| 104 | 5 | 222 |
| 105 | 3 | 555 |
店舗LOCATIONS(ライトソース)
| 場所ID | 位置名 |
|---|---|
| 555 | プロボ |
| 777 | ダブリン |
| 999 | シアトル |
| 1000 | 東京 |
ロケーションIDに基づいてデータを結合することを選択します。このフィールドは “結合キー “と呼ばれる。
これは2つ目(右)のデータセットに固有のデータである。これは削除されるだろう:
| 場所ID | 位置名 |
|---|---|
| 1000 | 東京 |
これは最終出力、つまり結果に含ま
れるすべてのデータである:
| 顧客ID | 満足度 (1-5) | 場所ID | 位置名 |
|---|---|---|---|
| 101 | 2 | 555 | プロボ |
| 102 | 4 | 777 | ダブリン |
| 103 | 5 | 999 | シアトル |
| 104 | 5 | 222 | ヌル |
| 105 | 3 | 555 | プロボ |
Provo、Dublin、およびSeattleの結果には、RightとLeftの両方のソースからのデータ列が含まれていることに注目してください。
左ソースには東京の顧客フィードバックデータがなかったため、東京は最終的なデータセットには含まれていない。さらに、IDが222のLocationsは存在しないので、この店の名前は “null “として返される。
一意な結合キーの重要性
結合キーは、左右のソースから結合する必要がある行を識別するのに役立つため、使用する結合キーが一意な識別子のように機能することを確認することをお勧めします。そうでない場合、右のソースに左のソースの結合キーと一致する複数のレコードがある場合、そのうちの1つだけがランダムに取り出されます。
例: 上で説明した例を見てみよう。同じ左のソースを持っている。しかし、正しいソースにはこのような列がある:
場所ID 位置名 338 ローリー 338 シャーロット 結果の結合では、338行のうち片方だけが保存され、両方は保存されません。
結合キーが右ソースの各レコードに対して一意ではなく、右ソースと左ソースの両方からすべてのレコードを含める場合は、代わりにユニオンを使用する必要があります。ユニオンは、情報の行を組み合わせるのではなく、それぞれの記録を別々に取り込む。
インナー・ジョインを理解する
注意: インナーおよびフルアウタージョインは現在育成中であり、すべてのお客様にご利用いただけるわけではありません。クアルトリクスは、自らの裁量により責任を負うことなく、あらゆる製品機能のロールアウトのタイミングの変更、プレビュー段階または開発段階の製品機能の変更、何らかの理由により、または理由なく製品の機能をリリースしないことを選択する場合があります。この機能にご興味のある方は、アカウントサービスまでご連絡ください。
注意: 内部結合は継続的ではなく、新しいデータで定期的に更新されます。詳細はリンク先のページを参照。
内側joinでは、結果的にマージされたデータセットには、両方のデータセットでマッチした行のみが含まれます。内側joinは、どちらかのソースからデータが欠落しているレコードを除外するため、結果として得られるデータセットには空のカラムが少なくなる傾向があり、ソースの順序(左か右か)は他のjoinタイプよりも重要ではありません。
これらのテーブルが、各アンケート調査で得られるデータを表しているとしよう
。
| 顧客ID | 名前 | リワード・ティア |
|---|---|---|
| 101 | フィル・スタイン | エメラルド |
| 102 | アミール・ダル | ゴールド |
| 103 | ベス・グリーン | シルバー |
| 104 | ルシア・バスケス | エメラルド |
店舗エクスペリエンス・フィードバック(ライトソース)
| 顧客ID | 満足度 (1-5) | 店舗 |
|---|---|---|
| 101 | 1 | プロボ |
| 104 | 3 | プロボ |
| 113 | 5 | スクラントン |
顧客IDに基づいてデータを結合することを選択します。このフィールドは “結合キー “と呼ばれる。
これは、最終的なデータセットから除外される各ソースからのすべてのデータである。
| 顧客ID | 名前 | リワード・ティア | 満足度 (1-5) | 店舗 |
|---|---|---|---|---|
| 102 | アミール・ダル | ゴールド | 空 | 空 |
| 103 | ベス・グリーン | シルバー | 空 | 空 |
| 113 | 空 | 空 | 5 | スクラントン |
これが最終出力、つまり結果に含まれるすべてのデータである:
| 顧客ID | 満足度 (1-5) | 名前 | 店舗 | リワード・ティア |
|---|---|---|---|---|
| 101 | 1 | フィル・スタイン | プロボ | エメラルド |
| 104 | 3 | ルシア・バスケス | プロボ | エメラルド |
これらのソースが顧客IDによって結合されているにもかかわらず、IDが102、103、113の顧客は、欠落している情報が多すぎるため、最終的なデータセットから除外されている。フィル(101)とルシア(104)だけが、両方のデータソースから完全なデータを入手できる。
フル・アウター・ジョインを理解する
注意: インナーおよびフルアウタージョインは現在育成中であり、すべてのお客様にご利用いただけるわけではありません。クアルトリクスは、自らの裁量により責任を負うことなく、あらゆる製品機能のロールアウトのタイミングの変更、プレビュー段階または開発段階の製品機能の変更、何らかの理由により、または理由なく製品の機能をリリースしないことを選択する場合があります。この機能にご興味のある方は、アカウントサービスまでご連絡ください。
注意: 完全外部結合は、継続的ではなく定期的に新しいデータで更新されます。詳細はリンク先のページを参照。
完全な外部結合では、マージされたデータセットには両方のデータセットのすべての行が含まれます。レコードは結合キーによって照合・結合されるが、結合キーのデータが欠落しているレコードも最終的なデータセットに含まれる。
これらのテーブルが、各アンケート調査で得られるデータを表しているとしよう
。
| 顧客ID | 名前 | リワード・ティア |
|---|---|---|
| 101 | フィル・スタイン | エメラルド |
| 102 | アミール・ダル | ゴールド |
| 104 | ルシア・バスケス | エメラルド |
| 空 | ベス・グリーン | シルバー |
店舗エクスペリエンス・フィードバック(ライトソース)
| 顧客ID | 満足度 (1-5) | 店舗 |
|---|---|---|
| 101 | 1 | プロボ |
| 104 | 3 | プロボ |
| 113 | 5 | スクラントン |
顧客IDに基づいてデータを結合することを選択します。このフィールドは “結合キー “と呼ばれる。
これは最終的な出力、つまり結果に含まれるすべてのデータである。
| 顧客ID | 満足度 (1-5) | 名前 | 店舗 | リワード・ティア |
|---|---|---|---|---|
| 101 | 1 | フィル・スタイン | プロボ | エメラルド |
| 102 | 空 | アミール・ダル | 空 | ゴールド |
| 104 | 3 | ルシア・バスケス | プロボ | エメラルド |
| 113 | 5 | 空 | スクラントン | 空 |
| 空 | 空 | ベス・グリーン | 空 | シルバー |
どのデータも除外されていないことに注目してほしい。顧客IDのデータが欠落しているベス・グリーンも結果に含まれている。複数のNULL顧客ID行があった場合、それらの行はそれぞれ含まれ、個別の一意なレコードとして残る。
Qtip: 両方のデータセットのすべての行を含めるには、Unionを使います。完全外部結合は、結合キーに基づいてレコードをマッチングさせながら、両方のデータセットのデータを結合します。ITには、結合されたすべてのレコードと、両方のデータセットから結合に失敗したレコードが含まれます。
ジョインの作成
Qtip: データセットに関係なく、結合で使用できるソースは15回までです。マージタスクの結合はこの制限にカウントされます。(同じソースを追加のユニオンに使用することは可能である。ただし、合計で15回を超えない限りである)
Qtip:1つのデータセットにつき最大6つの結合が可能です。(結合が合計6回を超えない限り、結合制限に達してもそのデータセットに結合を追加することができる)。
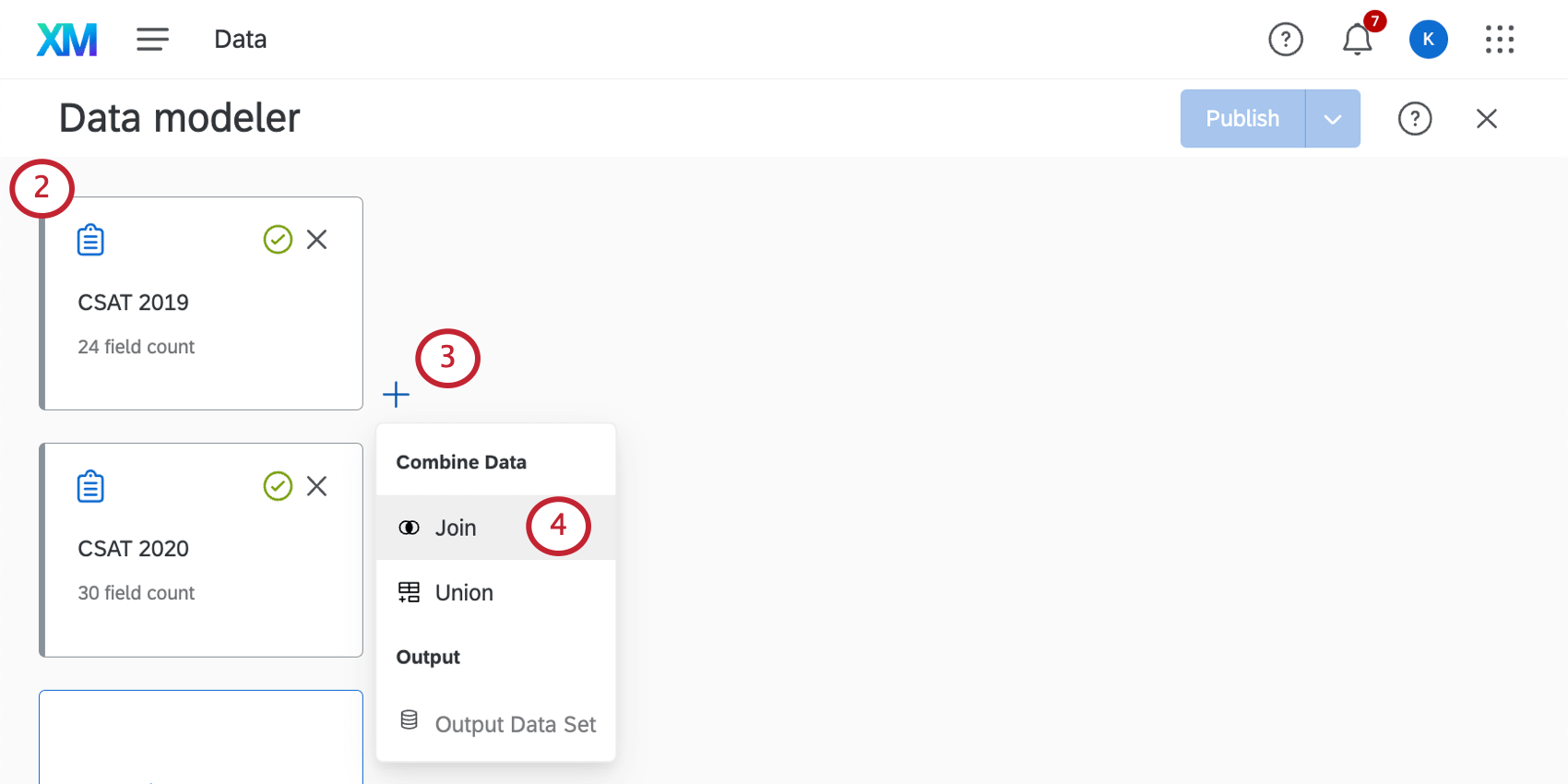
Qtip:データソースには、データ結合に使用する共通フィールド(ユニークIDなど)を含め、必要なフィールドをすべて含めるようにしてください。
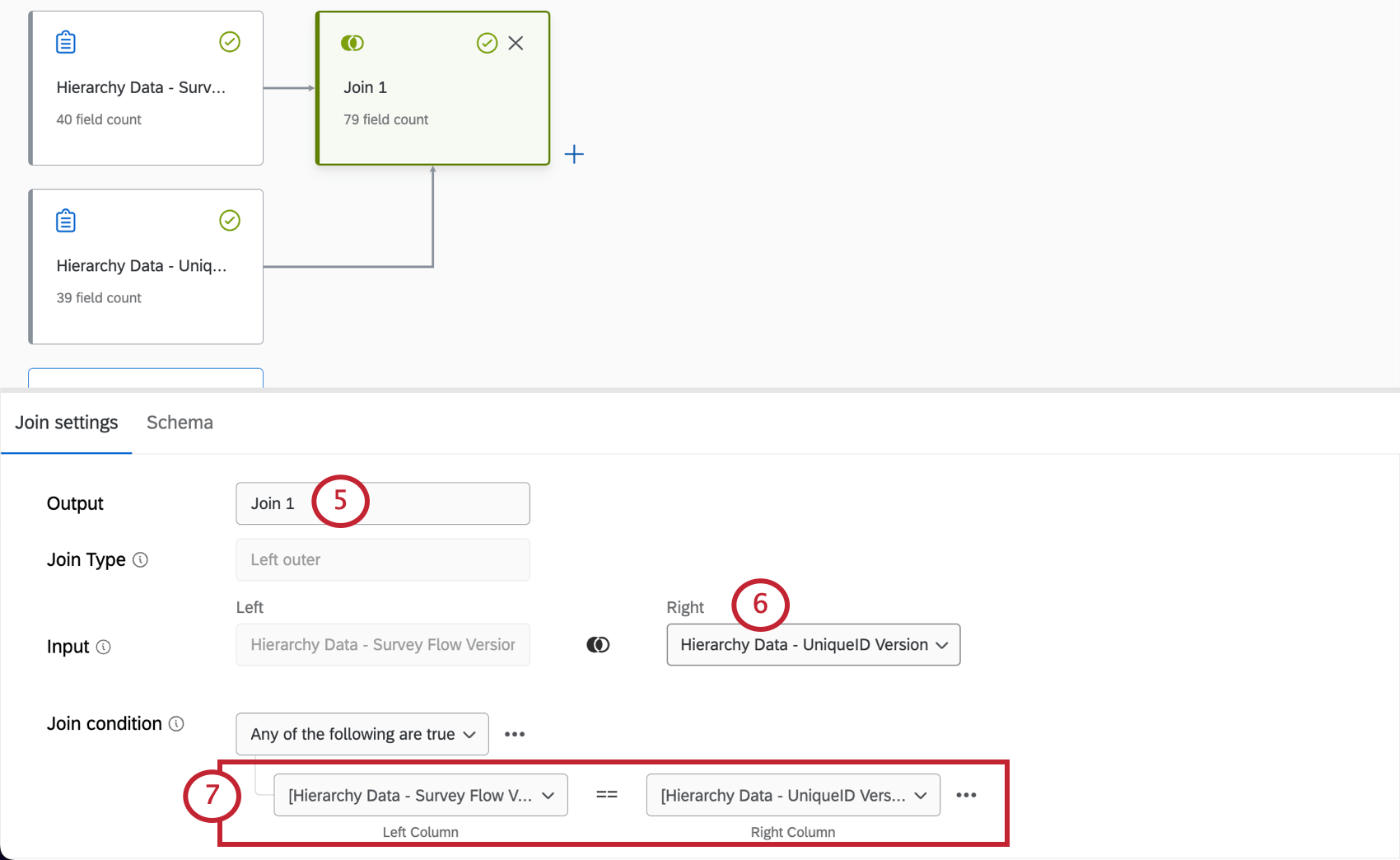
例: ここでは、各データソースのユニークIDフィールドを相互にマッピングしています。
Qtip:DateフィールドとMulti-Answer Text Setフィールドを除き、ほとんどすべてのフィールドタイプを結合条件で使用できます。両方のデータソースで一致する一意の識別子を使用することを強くお勧めします。
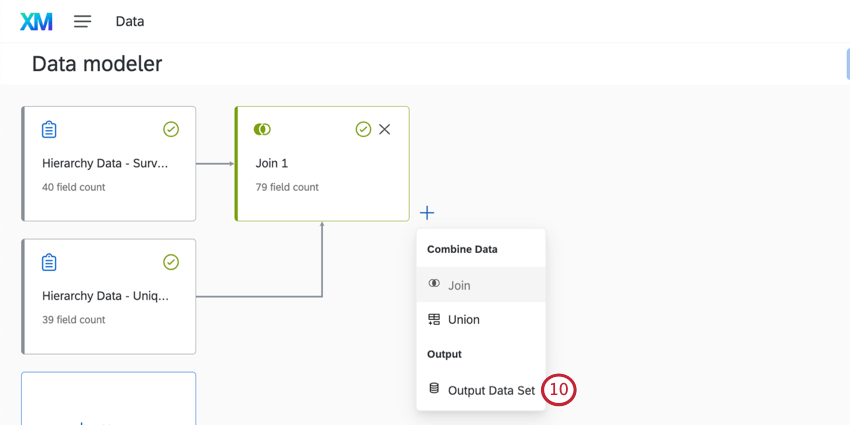
{kind=link}
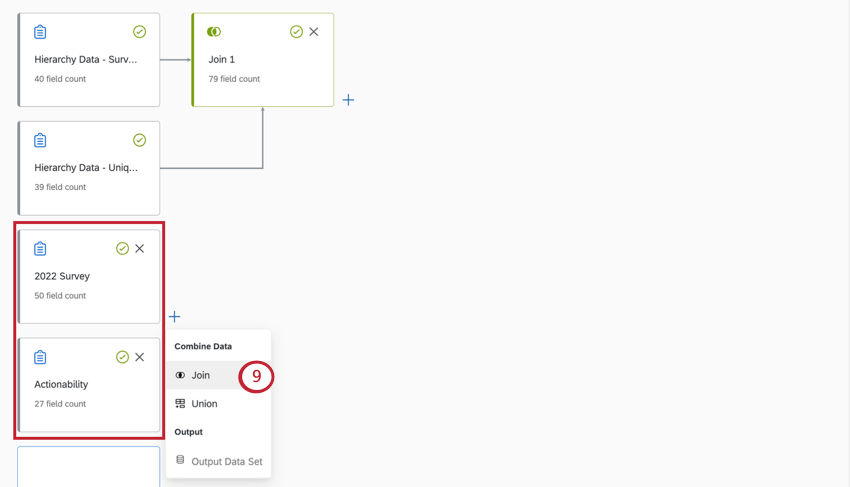
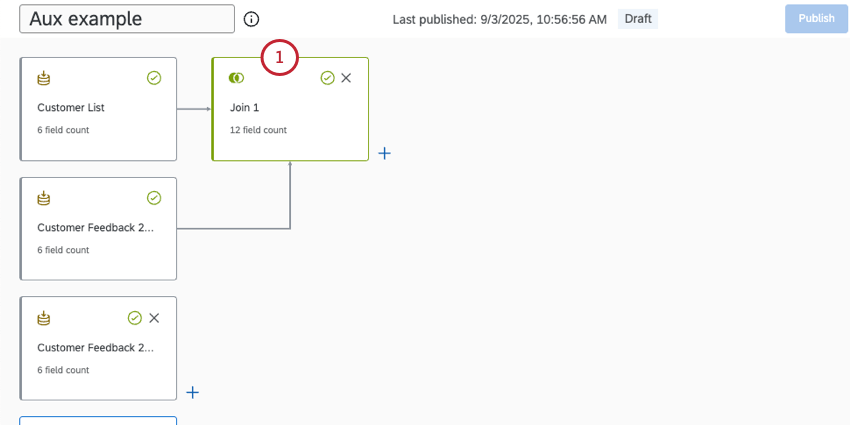
補助結合の使用
補助結合を使用すると、同じ結合条件で複数のソースを結合できます。したがって、同じデータソースを使用して複数の重複した結合を作成する場合に便利です。
先に、左外部結合が2つのソース(右ソースと左ソース)でどのように機能するかについて説明しました。補助ジョインでは、同じ左ソースに複数の右ソースを設定することができます。
補助ジョインの例
IDにリンクされた名前を持つ顧客データベースがあるとします。顧客からのフィードバックを収集するアンケート調査を2年間実施していますね。以下の例では、2020年と2021年に提出されたフィードバックの満足度と顧客名を見つける。
顧客リスト(左ソース)
| 顧客ID | 顧客名 |
|---|---|
| 101 | ジミー・ホロウィッツ |
| 102 | ディープティ・パタン |
| 103 | ジーナ・チョン |
| 104 | ダニエル・ワグナー |
カスタマー・フィードバック2020(ライトソース)
| 顧客ID | 満足度 (1-5) |
|---|---|
| 101 | 2 |
| 102 | 4 |
| 103 | 5 |
カスタマー・フィードバック2021(補助的権利源)
| 顧客ID | 満足度 (1-5) |
|---|---|
| 101 | 3 |
| 104 | 5 |
| 838 | 4 |
ロケーションIDに基づいてデータを結合する。
これは最終出力、つまり結果に含ま
れるすべてのデータである:
| 顧客ID | 顧客名 | 満足度2020 | 満足度2021 |
|---|---|---|---|
| 101 | ジミー・ホロウィッツ | 2 | 3 |
| 102 | ディープティ・パタン | 4 | ヌル |
| 103 | ジーナ・チョン | 5 | ヌル |
| 104 | ダニエル・ワグナー | ヌル | 5 |
2020年と2021年のデータが、同じ出力データセットの中で別々の 列になっていることに注目してほしい。
ジミーは両年ともフィードバックを提出した唯一の顧客である。それ以外の選手には、見逃したフィードバックの年の下に空欄の “null “セルがある。
顧客ID “838 “のレコードは、顧客リストにそのIDに対応する名前/レコードがなかったため、最終データソースから除外された。データがどのように除外されるかについては、左外部結合を理解するを参照のこと。
補助ジョインの作成
注意: 各個人ジョインにつき、最大6つの補助ジョインを追加できます。これは、1つのデータセットにつき6回の結合という全体的な制限にカウントされる。
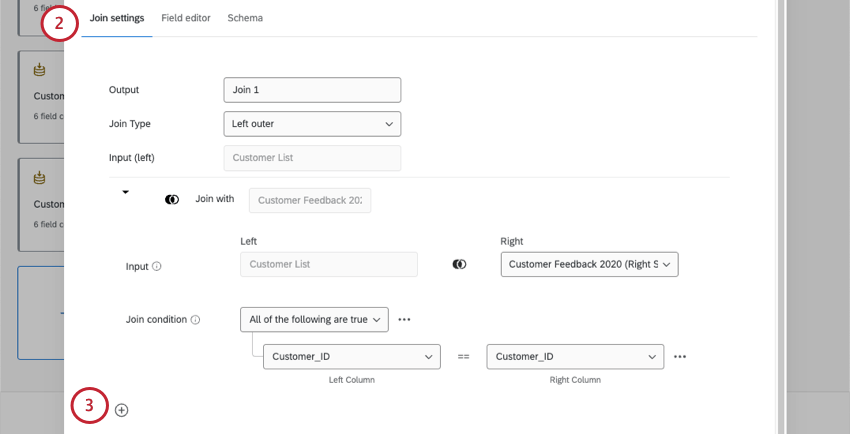
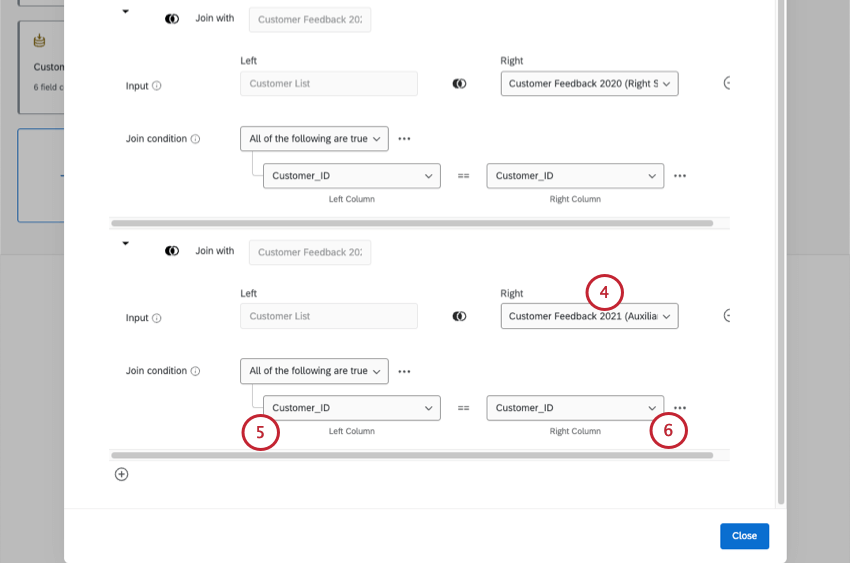
例: 左のソースに接続する2つ目のソースです。上記の例では、2021年の顧客フィードバック調査になります。
必要に応じて手順を繰り返し、補助ジョインを追加する。
連鎖結合を避ける
1つのデータモデルで複数の結合を持つことができます。しかし、これらのジョインがどのように相互作用するか(あるいは相互作用しないか)に注意することが重要である。データモデリングは現在、連鎖結合をサポートしていない。
連鎖結合は補助結合とは異なる。連結結合では、結合の中に別の結合を作成する。
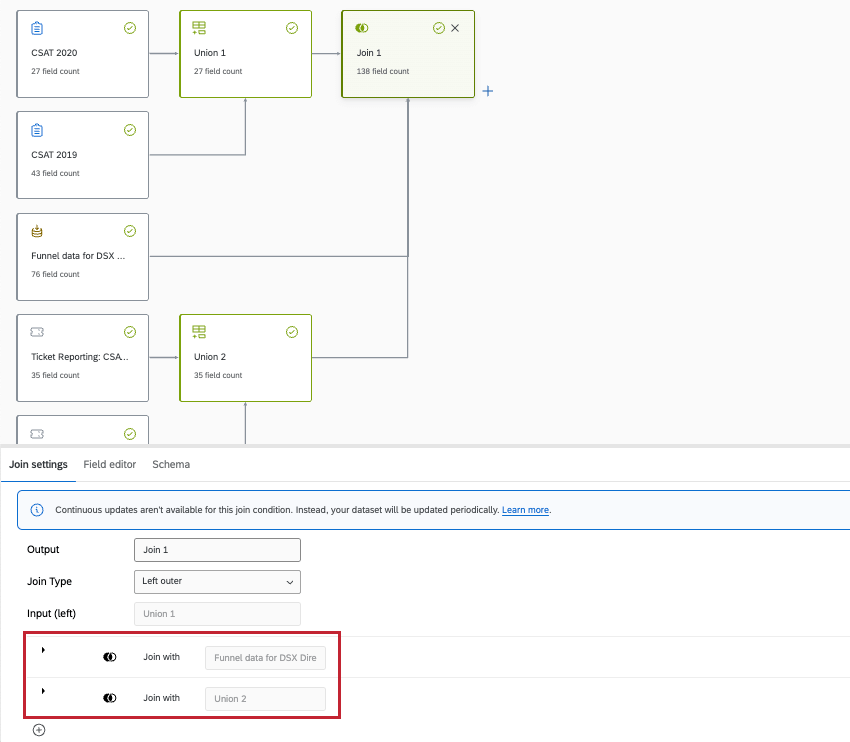
以下の例は補助結合であり、サポートされている。ジョインが同じ1つのノードの内部で定義され、ソースが重複していることに注意してください:
{kind=link}
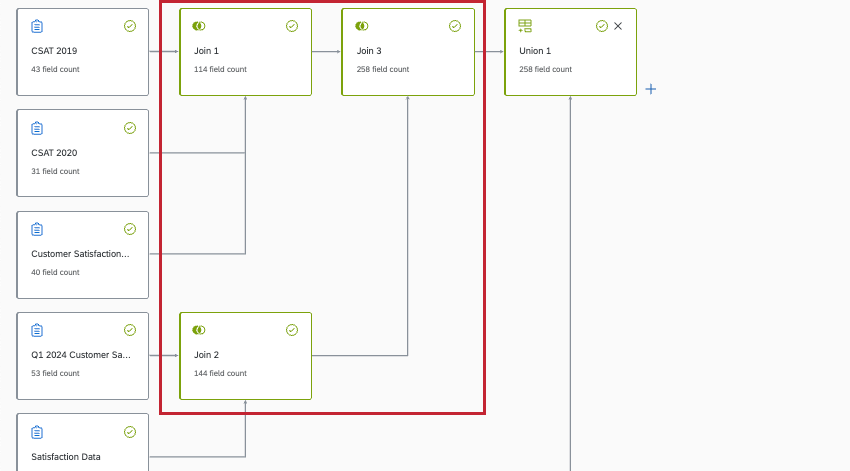
以下の例は連鎖結合であり、サポートされていません。別の結合の中に別の結合があることに注意。
{kind=link}
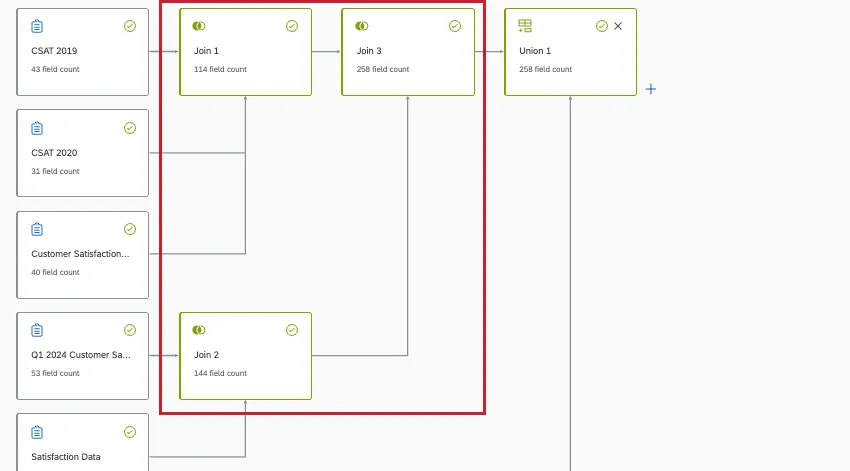
Qtip:一般的に、最初にユニオンノードを作成し、次に結合を作成することをお勧めします。最初に結合を行う必要がある場合、結果的にデータが遅くなりますが、結合ノードが別の結合ノードではなく、ユニオンノードにまとまっていれば問題ありません。
FAQs
Are changes to data models reflected immediately in dashboards?
Are changes to data models reflected immediately in dashboards?
If you have multiple sources of the same type in your dataset (such as tickets and surveys), we generally recommend creating unions before you create joins.
What happens if I edit a field that’s being used to join 2 data sources together?
What happens if I edit a field that’s being used to join 2 data sources together?
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!