BXプログラムのベストプラクティス
このページの内容
BXプログラムのベストプラクティスについて
BXプログラムでは、主要な競合他社と比較して、ブランドの健全性を包括的かつ継続的にアセスメントすることができます。BXのアンケート調査は、ブランドトラッカーのデータソースを生成するために使用されるデータを作成し、BXの分析ツールやダッシュボードをより堅牢にするスタックデータセットとなります。ブランドトラッカーのデータソースの作成と互換性があるように、アンケートを特別にプログラムすることが重要です。
Qtip: セットアップアシスタントは、BXプログラムの作成方法を説明し、アンケート調査のテンプレートを提供します。提案されている以上にアンケートをカスタマイズした場合、BTDSに必要なアンケート調査フィールドが自動生成されない可能性があることに注意してください。
注意: BX プログラムは、通常のアンケート調査プロジェクトよりも規模が大きく、複雑です。すべての要素が正しく動作していることを確認するために、プレビューリンクを 使用することをお勧めします。さらに、小規模の母集団のサイズ(サンプルサイズの10%など)にプログラムを送り、データを評価する「ソフトローンチ」を実施することをお勧めします。
QTip: BXプログラムは通常、クアルトリクス導入チームまたはサードパーティの導入パートナーによって実施されます。導入に関するご質問は、テクニカルサクセスマネージャーまでお問い合わせください。
アンケート調査体制
警告: クアルトリクス導入チームまたはサードパーティの導入チームによって構築された BX スタディを使用している場合は、アンケートビルダーまたはアンケートフローに無断で変更を加えないでください。
ほとんどのBXアンケートは、信頼できる回答を提供し、主要な指標を測定するために設計された、同じ基本的な構造に従っています。
Qtip: 回答者のサンプルが、調査したい母集団を代表していることを確認するために、人口統計データを使用することができます。
アンケートの内容や構成を編集する際には、以下のベストプラクティスに従うことをお勧めします。
- 可能な限り、標準的な質問タイプ (単一選択、複数選択、自由回答)を使用する。その他の質問については、どのようにデータをマッピングするか、明確な計画を立てること。
- 回答者が異なる内容の同じ質問に答えることができるような設定は避けましょう。例えば、1つの質問を使って、回答者にランダムに選んだブランドに関する背景を尋ねます。
- ダッシュボードで使用したいフィルターを検討し、その情報を取得する方法を含める。例えば、年齢層でフィルタリングする必要がある場合は、必ず年齢層埋め込みデータ変数を作成してください。
- レポートに最も関連性のある日付範囲を検討する。ダッシュボードでフィルターやバケットを使用するために、最も関連性の高いフィールディング期間の情報を取得する “wave_date “埋め込みデータフィールドを作成するのが一般的です。 Qtip: フィールディング期間は、「記録日」フィールドや「終了日」フィールドと一致しない場合がある。例えば、4月のウェーブには、5月初めの回答者を含める必要があるかもしれません。

- 必要なカスタム変数があれば検討し、埋め込みデータを使って設定する。
Qtip: アンケート調査フローでは、ロジックを整理し、トラブルシューティングを容易にするために、要素をグループ化することをお勧めします。
プログラミング原理
ブランド トラッカー データソース (BTDS) をプログラムで生成するには、追加のプログラミングが必要です:
再利用可能な選択肢リスト
アンケート調査全体のブランドリストは、再利用可能な選択肢リストとして入力してください。残りのアンケート調査全体を通して、ブランド アイデンティティは再利用可能な選択肢リストに入力された名前と同一でなければなりません。詳しくは、リンク先のサポートページをご覧ください。
質問のヒント: 「その他」、「NA」、「なし」などの選択肢は、再利用可能な選択肢リストには含めないでください。
注意: ブランド名は35文字を超えることはできません。
質問文と回答文
ブランドごとに繰り返される質問(ブランド主導の質問とも呼ばれる)については、質問ラベル(例:「NPS_brandX」)と質問文(例:「友人や同僚に[ブランドX]を薦める可能性はどのくらいですか?
再利用可能な選択肢にブランドが設定されている問題では、再利用可能な選択肢リストにおいて、質問 文がブランド名と異なる場合 (画像や追加テキストのHTMLがある場合など)、必ず変数名をブランド名に設定してください。
パラレルアンケート調査ブロック
並行アンケートブロックとは、1つのブランドに関する一連の質問をアンケートブロックにまとめたもので、各ブランドごとにアンケートブロックがあります。各ブロック名は同じ命名パターンに従うべきであり、そうすることでブロック内の問題は並列とみなされる。クアルトリクスは、並列の質問をまとめてスタックします。
例: ブランド購入実態の障壁を尋ねるブロックを作りたいとします。各ブロックに「バリア – [ブランド名]」という名前を付けると(例:「バリア – 最高の朝食」、「バリア – ヘルシーなシリアル」)、機械アルゴリズムはこれらのブロックを並列に考え、質問を一緒に積み重ねる。ブロックの命名規則が異なる場合(例:「バリア – ウェルビーイング」、「バリア – ヘルシーシリアル(キッズ)」)、マシンアルゴリズムはブロックを並列とみなさず、スタックしない可能性がある。
埋め込みデータのスタッキング
デフォルトでは、埋め込みデータフィールドはスタックされない。しかし、埋め込みデータフィールドを積み重ねることは、ブランドデータを計算・測定するカスタムブランド変数ではしばしば必要です。
埋め込みデータフィールドは、 アンケートフロー上部に “0 “と以下の名で追加してください:
gbt__v1__[スタックタイプ]__[カラム名]__[ブランド名]。 例: 例えば、「ブランド選好度」を、回答者がそのブランドを利用したことがあるかどうか、または利用したいブランドがない場合に利用するかどうか、と定義するとよいでしょう。スタック埋め込みデータ変数を作成することで、ダッシュボードフィルターやウィジェットで使用できる1つのフィールドに、これらの条件を組み合わせることができます。
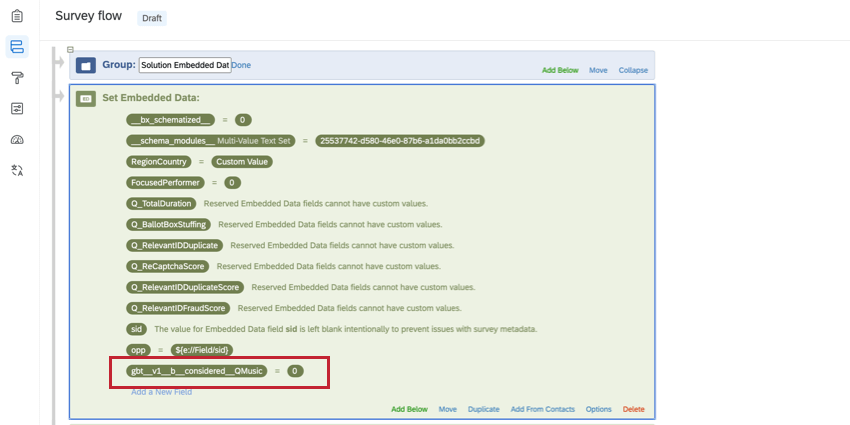
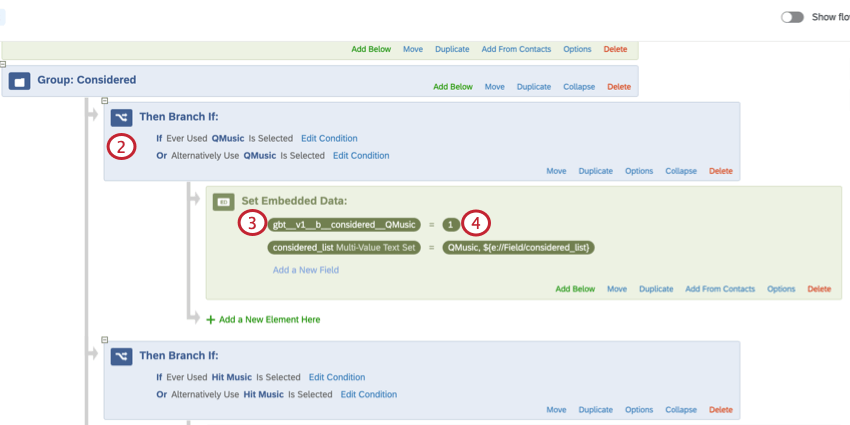
埋め込みデータ変数の作成に関する詳細は、以下のセクションを参照してください。
スタック・タイプ
スタックタイプは、この埋め込みデータで参照される変数のタイプを指す。スタックには2種類ある:
- バイナリ (b): 変数には2つの潜在値しかない。例えば、変数 “Consideration “では、ブランドは考慮される(1)か、考慮されない(0)かのどちらかである。
- 通常 (n):この変数には無制限の数値オプションがあり、計算された値または回答者が質問に対して選択した値を含みます。
| スタック・タイプ | フォーマット例 | ユースケースの例 |
|---|---|---|
| b(バイナリ) | gbt__v1__b__Consideration__QMusic | お気に入り、計算された考察 |
| n(ノーマル) | gbt__v1__n__Share of Wallet__QMusic | ブランドエクイティ、ウォレットシェア |
列名
列名は、BTDSの埋め込みデータ変数として表示させたいものです。
| スタック・タイプ | フォーマット例 | ユースケースの例 |
|---|---|---|
| b(バイナリ) | gbt__v1__b__Consideration__QMusic | お気に入り、計算された考察 |
| n(ノーマル) | gbt__v1__n__Shareof Wallet__QMusic | ブランドエクイティ、ウォレットシェア |
ブランド名
ブランド名は、変数内のデータがどのブランドを参照しているかを示す。
注意: ブランド名は再利用可能な選択肢リストの対応するブランドと一致していなければなりません。ブランド名が完全に一致しない場合、データは正しくスタックされません。これには、スペース、アポストロフィ、ハイフンなどの特殊文字が含まれます。
| スタック・タイプ | フォーマット例 | ユースケースの例 |
|---|---|---|
| b(バイナリ) | gbt__v1__b__Consideration__QMusic | お気に入り、計算された考察 |
| n(ノーマル) | gbt__v1__n__Share ofWallet__QMusic | ブランド・エクイティ、ウォレットシェア |
オートコード純粋想起
純粋ブランド想起は、特定のカテゴリーについて言及したときに、どのブランドが思い浮かぶかを測定する(例えば、「[カテゴリー]といえば、まずどのブランドが思い浮かびますか?)自動コード化された純粋想起(AUA)により、スペル、大文字、または一般的な略語のばらつきが修正され、データを適切にグループ分けできるようになります。これは、アンケートフローにウェブサービスを作成することで行います。
Qtip: オートコード純粋想起の設定に興味がある場合は、実装パートナーにお問い合わせください。
AUAウェブサービスは入力されたオープンテキストのデータを見て、あなたが作成したブランド辞書と比較します。エントリがブランド名に類似している場合、わずかな文字数のずれの範囲内で、ウェブサービスはエントリをブランド辞書に一致するように再コード化します。
例: クアルトリクス」を含むブランドリストがあるとします。AUAを有効にすると、クアルトリクス(「クアトリクス」など)のバリエーションはすべて「クアルトリクス」と再コード化されます。ただし、回答者が「QXM」と入力した場合、「クアルトリクス」のバリエーションではないため、これは含まれない。
Qtip:なぜText iQではなくAUAを使うのですか?
- AUAは固有名詞や人名を扱いますが、TEXT iQは長文回答の一般用語や文法構造に重点を置いています。
- AUAはアンケートセッション中にリアルタイムでテキスト回答を割り当てますので、値を確認するために処理を待つ必要はありません。また、必要に応じてアンケートロジックで結果を使用することもできます。
- AUAの結果をスタックして、クアルトリクスの分析およびダッシュボードの有意性検定やその他の分析オプションを活用できます。
AUA詳細
- AUAに対応しているのは、クアルトリクスプラットフォームがサポートしている言語のみです。カスタム言語はサポートされていません。
- あるブランドは、複数のエントリーを含むことができる(例えば、「クアルトリクス」は、「クアルトリクス」、「クアルトリクスソフトウェア」、「クアルトリクスリサーチ」、「クアルトリクスXM」のエントリーを含むことができ、これらすべてのバリエーションが「クアルトリクス」として再コード化されるようにすることができる)。
- ブランド名の長さは、回答者のスペルがブランドディクショナリーのブランドエントリーとどの程度ずれるかに影響します。
- 3文字以下の回答は逸脱が許されず、ブランドエントリーと完全に一致する必要があります。例えば、”Ivy “は正確に “Ivy “と綴る必要がある。
- 回答が4文字の場合、偏差値は1です。例えば、”QHub “は “Qub “や “QHb “といったバリエーションを受け入れる。
- 5文字の回答は、2つの偏差値が許されます。例えば、”Flanel “は “Flannel “や “Flnl “のようなバリエーションを受け入れる。
- 6文字以上の回答は、3回の偏差値が許される。例えば、”BeatDrop “は “BeatD “や “BetDrp “のようなバリエーションを受け入れる。
Qtip:ブランド辞書の評価や更新をご希望の場合は、インプリメンテーション・パートナーにご相談ください。
ブランドエクイティ、ウォレットシェア、チャンスギャップ
Qtip: ブランドエクイティ、ウォレットシェア、またはオポチュニティ・ギャップ分析の設定に興味がある場合は、実施パートナーにお問い合わせください。
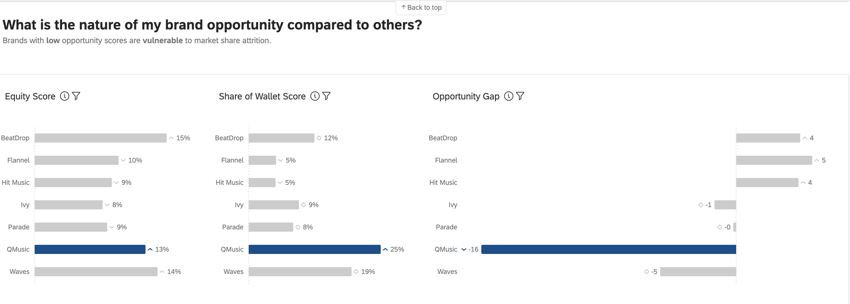
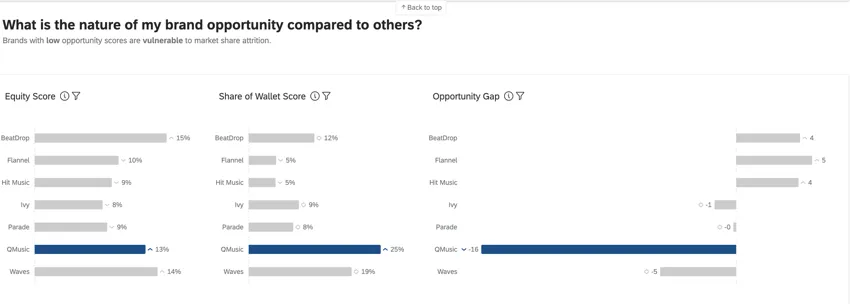
ブランド・エクイティ、ウォレット・シェア、オポチュニティ・ギャップの各メトリクスは、BXダッシュボードで使用され、ブランド・パフォーマンスに関する高度なインサイトを提供します。
{kind=link}
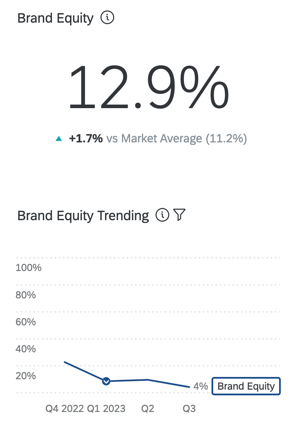
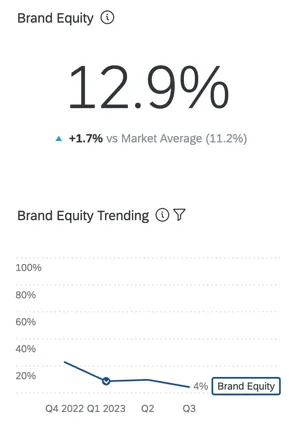
ブランド エクイティ
ブランド態度エクイティは、消費者が製品の購入や使用に障壁がない場合、どのブランドを選ぶかを測定するものである。ブランド・エクイティは、全体として見た場合、ブランドの期待市場シェアを反映しています。これは、合計が100になるようなパーセンテージです(例えば、消費者の75%はできれば私のブランドを購入したいが、25%は[x]ブランドを購入したい)。
ITのアプローチはシンプルで、いくつかの質問(所有、検討、ブランド評価)をするだけでよい。相対的なブランド評価は “ランク “に変換され、さらに “予測シェア “に変換される。これらの指標は行動と強い相関関係がある。
{kind=link}
Qtip: ブランドエクイティは、BXアンケート調査において、アンケートフローにウェブサービスを作成することで算出されます。
Qtip: ブランドエクイティには多くの概念がありますが、クアトリクスのアプローチはブランド態度的エクイティと呼ばれています。この検証は一般に公開されており、広範に検証されている。
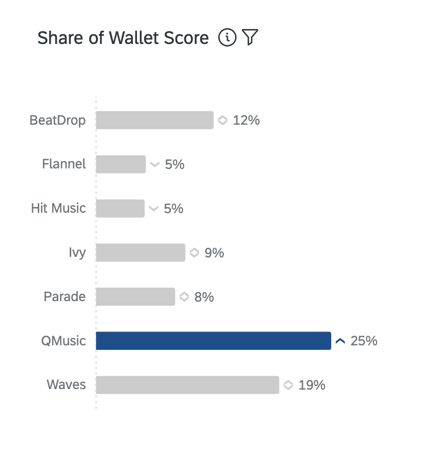
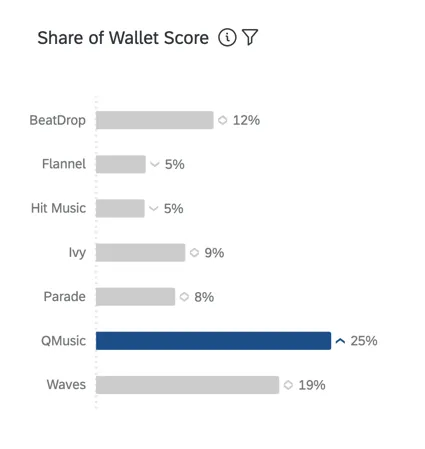
ウォレットシェア(推定市場シェア
ウォレットシェアは、「推定市場シェア」とも呼ばれ、回答者の最近の使用実態のうち、どの程度が各ブランドに帰属するかを測定する。これは通常、合計を100とするパーセンテージです(例:過去6ヶ月間、私の[カテゴリー]購入実態の75%は[x]ブランド、25%は[y]ブランド)。
{kind=link}
Qtip: BXアンケートでは、アンケートフローに演算機能を作成することで、ウォレットシェアを計算することができます。
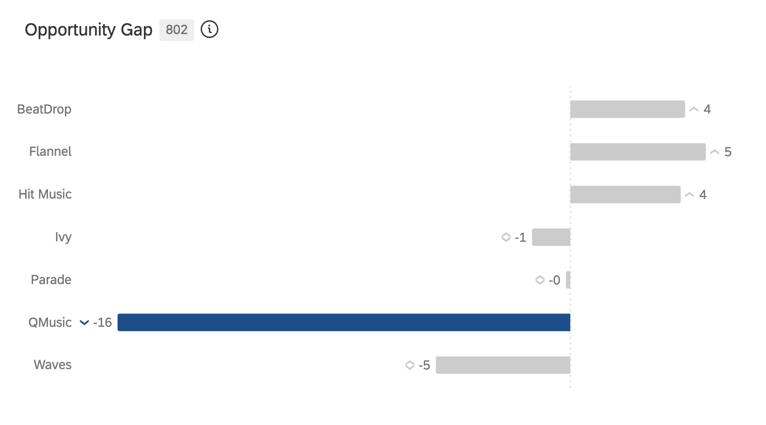
機会格差
つまり、ブランドに対する欲求と実際の購入行動とのギャップである。公平性/エクイティがシェアより大きいとき(プラススコア)には機会が存在し、公平性/エクイティがシェアより小さいとき(マイナススコア)には脆弱性が存在する。
{kind=link}
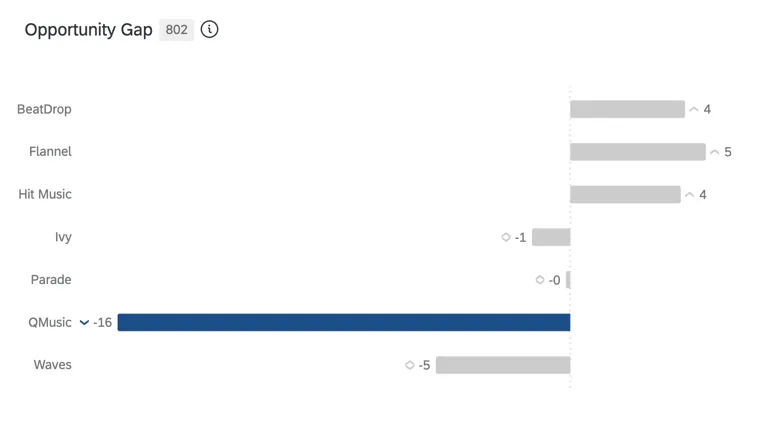
Qtip: オポチュニティギャップは、BXアンケート調査において、アンケートフローに演算機能を作成することで算出されます。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!