Predict iQ
このページの内容
注意: あなたが読んでいるのは、すべてのユーザーがアクセシビリティを持っているわけではない機能についてです。この機能にご興味のある方は、営業担当までご連絡ください。
Predict iqについて
顧客が会社を去るとき、私たちはしばしば不意を突かれる。この顧客がリスクを抱えていることを知っていれば、私たちへの信頼を完全に失う前に手を差し伸べることができたかもしれない。顧客が離反する可能性を予測する方法があればいいのだが。
Predict iQは、回答者のアンケート調査回答と埋め込みデータから学習し、回答者が最終的に解約するかどうかを予測します。そして、新たなアンケート調査の回答が寄せられると、Predict iQは、そのアンケート調査回答者が将来的に解約する可能性を予測することができます。顧客が離反するかどうかを予測するために、Predict iqはニューラルネットワーク(そのサブセットはディープラーニングと呼ばれる)と回帰を使って候補モデルを構築する。各データセットに対して、それらの異なるモデルのバリエーションを試し、そしてデータに最も適合するモデルを選択する。
データの準備
解約予測モデルを作成する前に、データが準備できていることを確認したい。
Predict iqは、解約した回答者が少なくとも500人いる場合に最適です。しかし、5,000人以上の解約回答者がいれば、最高の結果を得ることができます。
解約変数の設定
記録データ
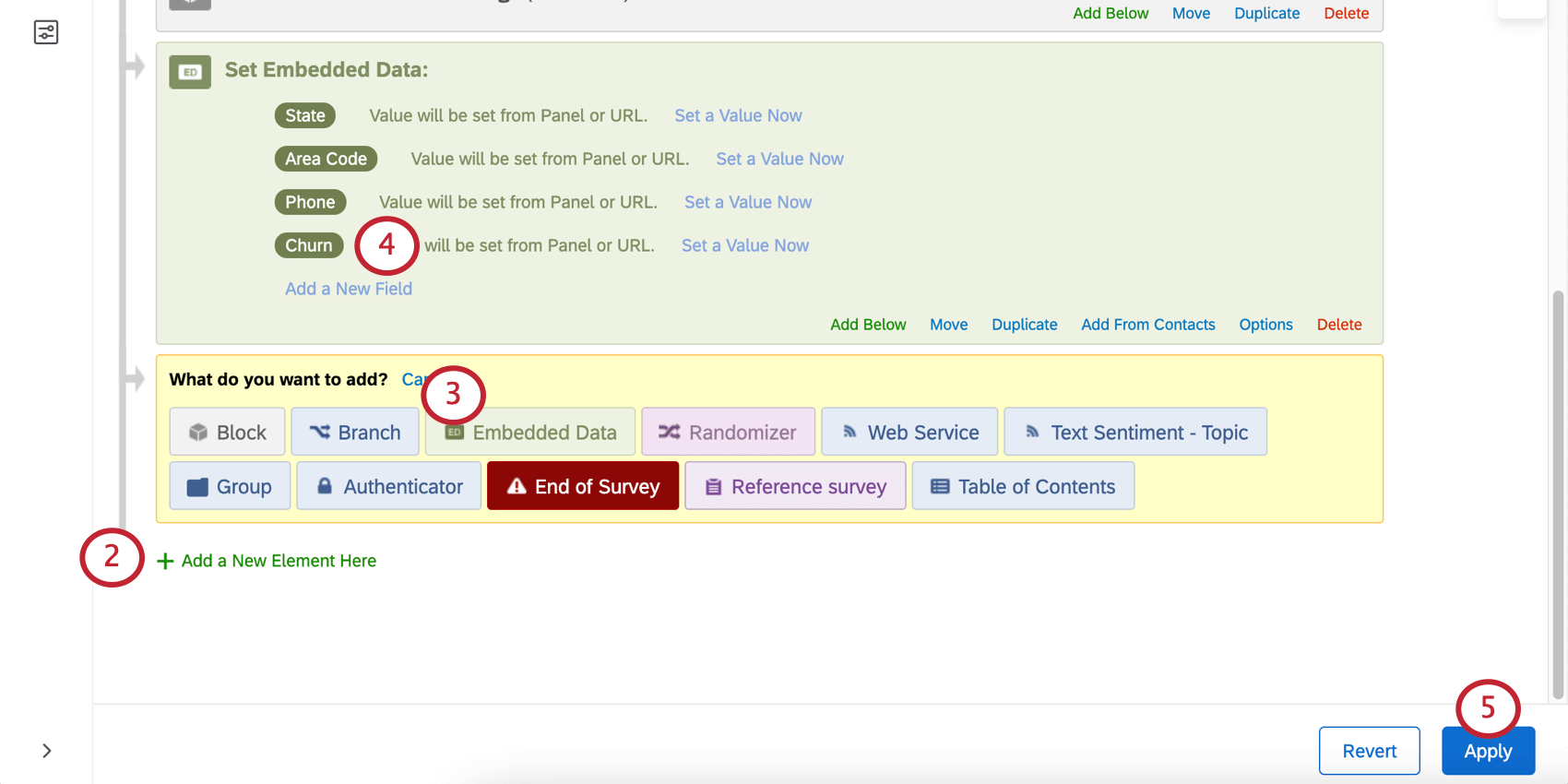
顧客離反変数を設定すると、アンケート調査に過去のデータをインポートすることができます。このデータには、顧客が離反したかどうかを「はい」または「いいえ」で示す「離反」の列が含まれます。
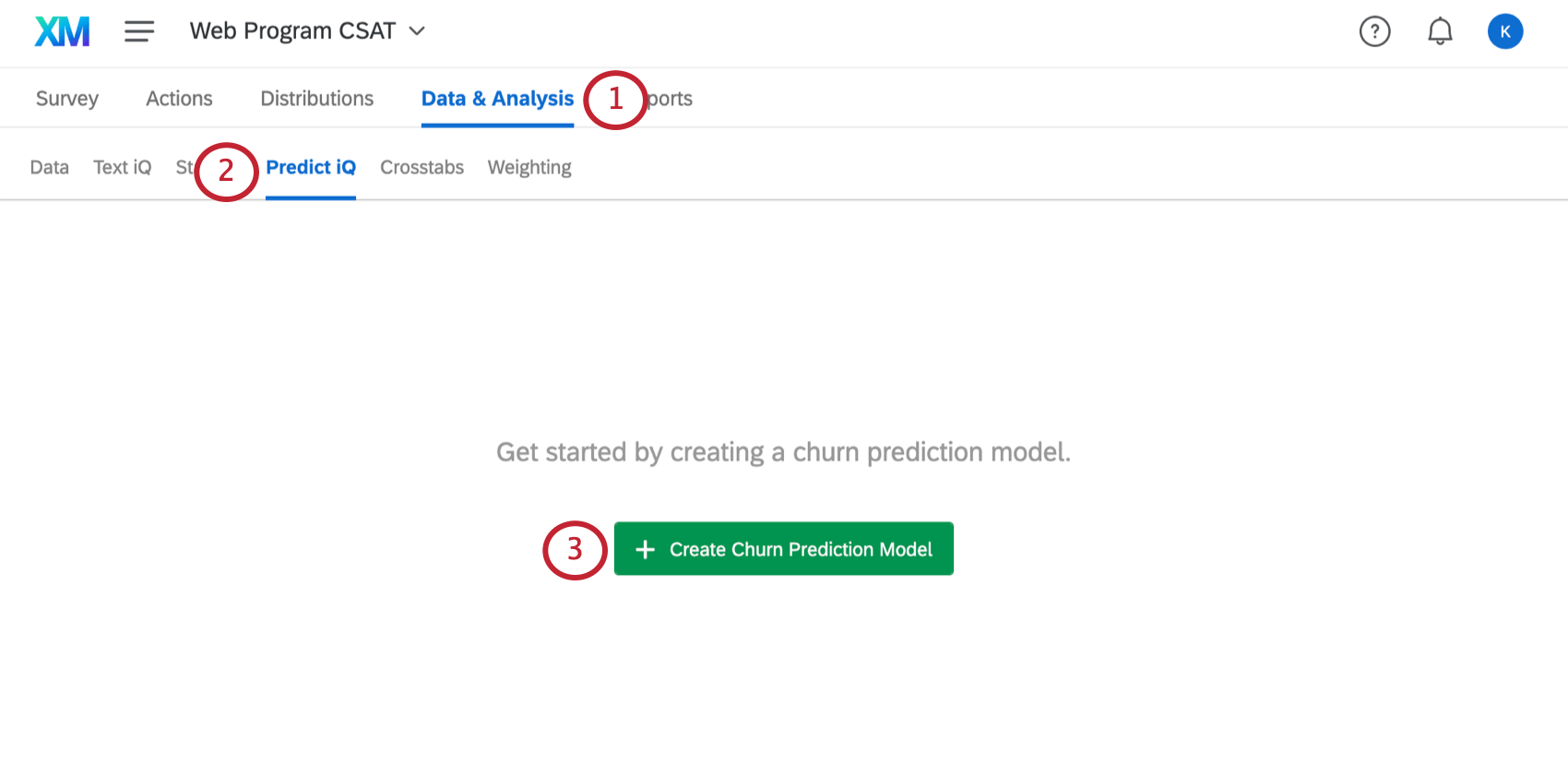
解約予測モデルの作成
解約変数を設定し、十分なデータが揃ったら、Predict iqを開く準備ができました。
Qtip: PREDICT iQは、Yes/NoやTrue/Falseのような2つの選択肢がある結果のみを予測します。数値的な結果(例:1~7段階)や、2つ以上の値を持つカテゴリー的な結果(例:Yes/Maybe/No)は予測できない。
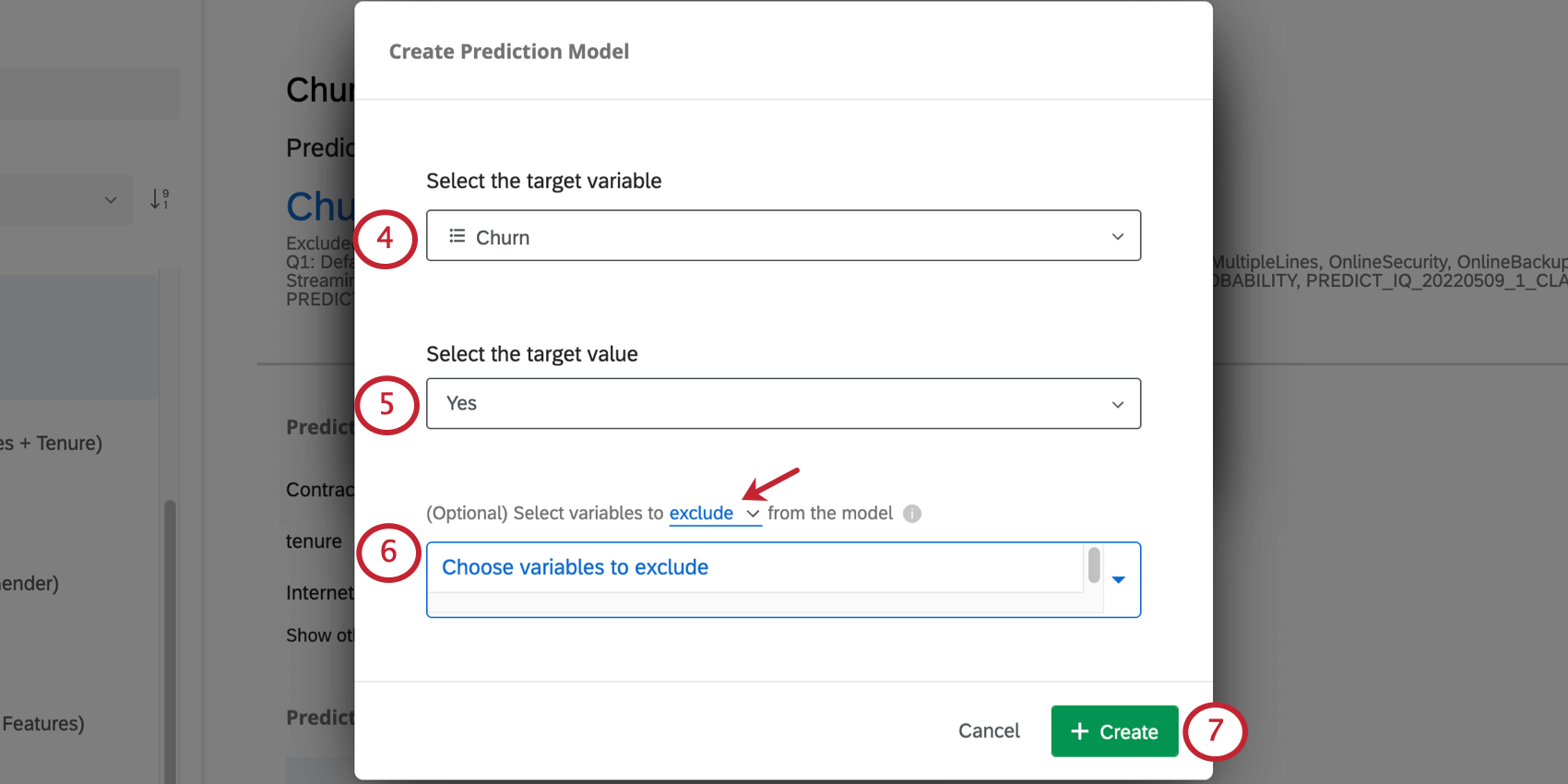
例: この例では、変数はChurnという名前なので、ChurnがYesに等しい人は解約したことになります。しかし、その代わりに変数名を「Staying with our company」としたとしよう。そうでなければ、その人は会社に留まることなく、離職したことになる。
- 除外する:たとえば、過去のデータに「解約の理由」を測定する変数がある場合、予測を行うときに新しい回答者が利用できないため、その変数を分析から除外したい場合があります。 Qtip:複数の変数を除外することができます。除外する変数のリストから削除するには、変数の次へX をクリックします。


- 含める:その他の変数は無視されます。

Qtip:チャーン予測モデルの計算が終了するまでには時間がかかる場合があります。進捗状況を失うことなく、他のプロジェクトやウェブサイトに移動することができます。
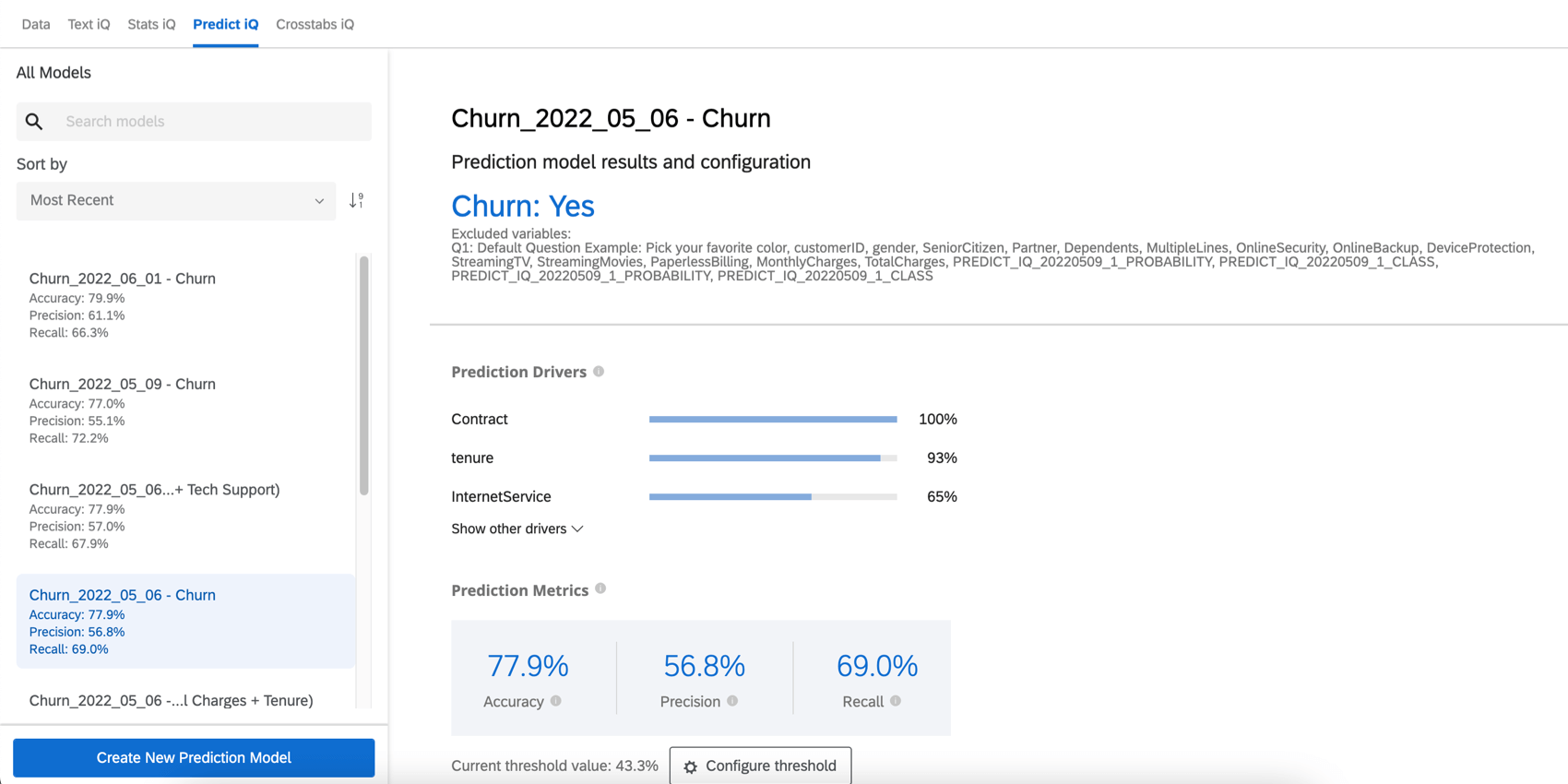
予測モデルが完成すると、Predict iqページは作成したばかりの解約予測モデルに関する情報に変わります。
{kind=link}
モデルトレーニング用のデータセットはどのように分割されていますか?
モデルをトレーニングする過程で、データセットはトレーニング、検証、テストデータに分割されます。80%のデータがトレーニングに使われます。10 %のデータが検証に使われ、10%のデータがテストに使われます。
変数情報
予測モデルの結果と設定セクションには、顧客離反埋め込みデータ変数の名前と、顧客離反の可能性を示す値が表示されます。このセクションは、除外する変数のリストでもあります。
{kind=link}

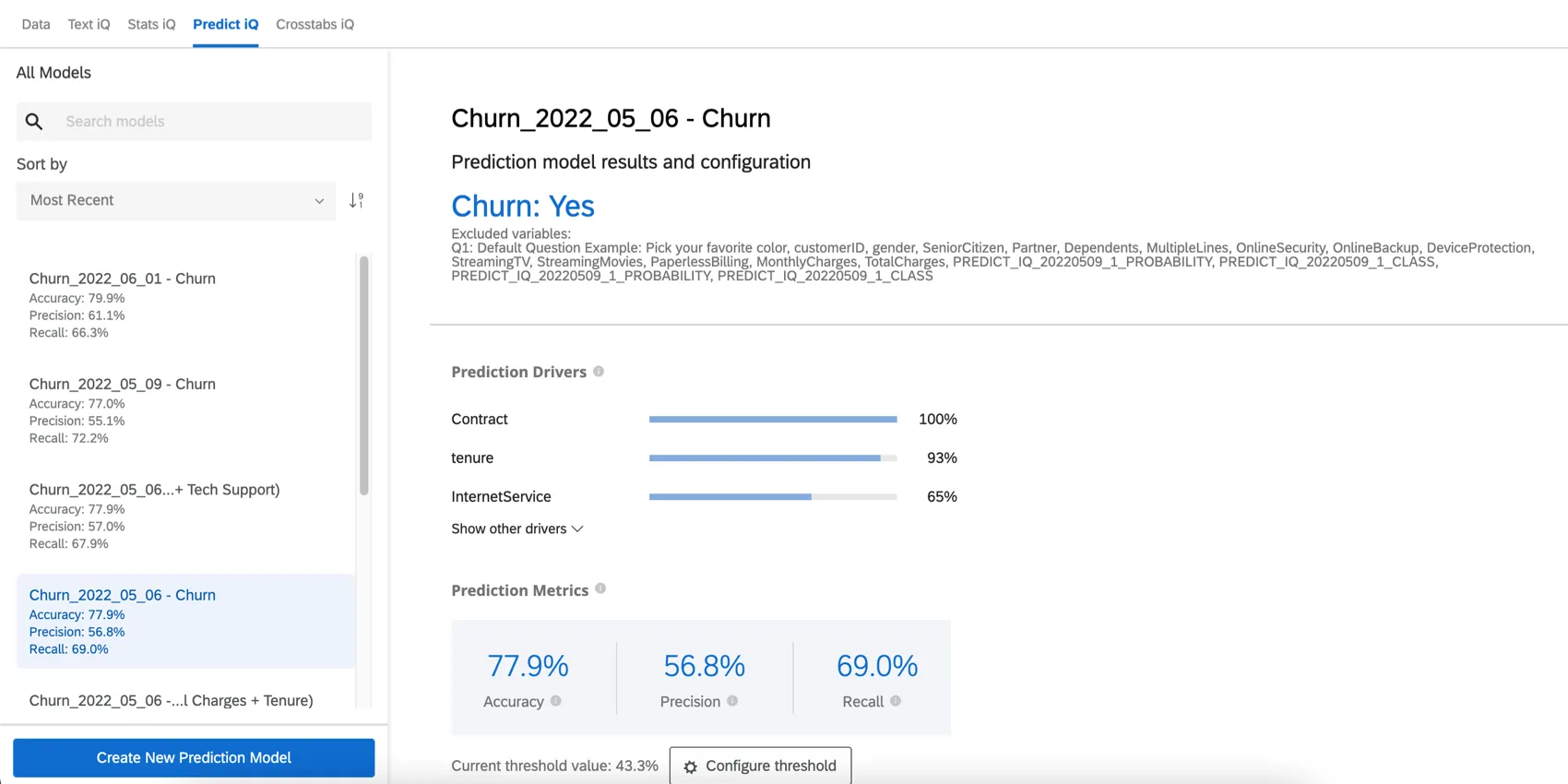
予測ドライバ
予測ドライバーとは、予測モデルを作成するために分析した変数を、解約を予測する上で重要な順に並べたものです。これには、分析から除外されなかったすべての変数が含まれる。以下の例では、NPSスコアと信頼性リングが解約予測の原動力となっている。
{kind=link}

Show other drivers(他のドライバーを表示)」をクリックして、リストを展開します。
Qtip:この標準グラフを作成するために、各変数は、解約変数に対する標準ロジスティック回帰で実行されます。最も高いr2乗の値が1に設定され、他の変数の値はそれに応じてスケーリングされる。たとえば、最高のr2乗が0.5であれば、各変数の棒の長さはr2乗*2となり、棒の長さは1となる。
したがって、このグラフは、解約の予測における変数の相対的な強さの指標であり、本質的に多変量ではない。ディープラーニング・アルゴリズムに基づくモデルの出力に対する各変数の影響の評価は、活発な学術研究の分野であり、現時点ではベストプラクティスは認められていない。
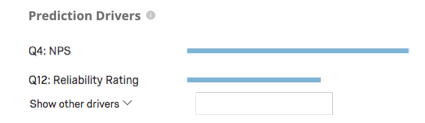
予測指標
Predict iQはモデルを作成する前に、データの10%を「保留」する。モデルが作成された後、Itはその10%の予測を作成する。そして、その予測と実際に起こったこと、つまり顧客離反の有無を比較する。これらの結果は、以下の精度指標に使用される。これはモデルの精度を推定するための効果的なベストプラクティスの方法であるが、モデルの将来の精度を保証するものではないことに注意。
{kind=link}

- 精度:モデルの予測のうち、正確である割合。
- 精度:離反すると予測された顧客のうち、実際に離反した顧客の割合。
- リコール:モデルによって事前に予測された解約者のうち、実際に解約した人の割合。
例: このスクリーンショットでは、モデルの予測は88.9%の確率で正確です。離反すると予測された顧客の82.4%が離反するというのは、十分に正確な結果である。想起指標は、モデルが実際に離反する顧客の推定29.8%を正しく識別することを示している。
Predict iqはF1スコアを最大化することで最適な閾値を算出する。モデルはデフォルトで最適な閾値に設定されますが、これを調整することができます。
Predictive Metrics表の下のAdvanced outputをクリックすると、Confusion Matrix表とAdvanced Prediction Metrics表が現れます。
精度と再現率
PrecisionとRecallは最も重要な予測指標である。そのため、どの顧客が離反するかを正確に把握することと、離反する可能性のある顧客をすべて、あるいはほとんど特定したことを把握することのトレードオフを考えなければならないことが多い。
例: もしあなたがすべての顧客をフォローアップしていたらと想像してみてください。顧客離反者全員にアプローチするのは間違いないが(100%リコール)、離反を考えていない顧客(精度が低い)には多くのリソースと時間を浪費することになる。一方、最も離反する可能性の高い1人だけをフォローアップする場合、精度は100%になる可能性が高いが、最終的に離反する多くの顧客を見逃すことになる(想起率が非常に低い)。
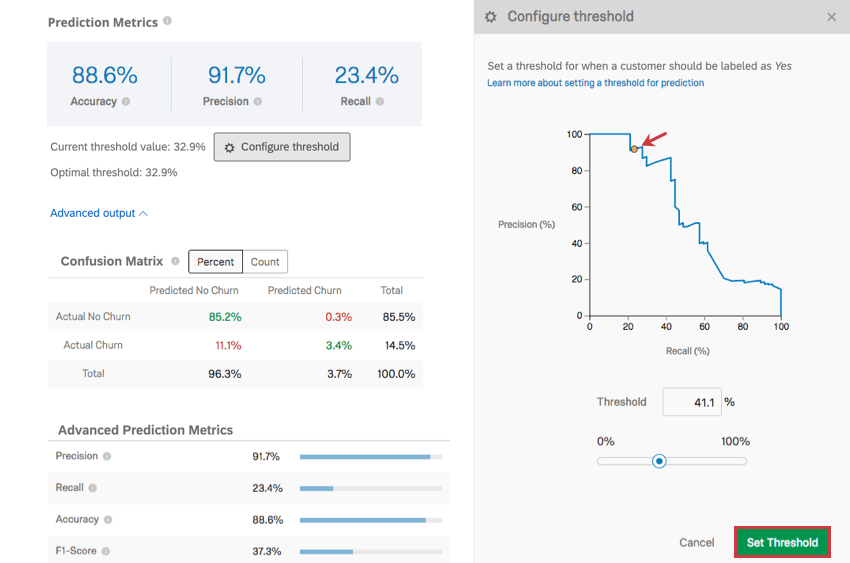
しきい値の設定
顧客離反の可能性があるとラベル付けする閾値を設定するには、閾値の設定をクリックします。この閾値のパーセンテージが、個々の解約の可能性である。
例: このモデルは、任意の1人の顧客の離反可能性の推定値を生成します。顧客離反の可能性が10%、40%、75%の3人の顧客がいるとする。しきい値が30%に設定されている場合、40%と75%の顧客はどちらも離反の可能性があると判断され、Eメールや電話を受け取ることになる。しきい値が50%に設定されている場合、75%の顧客だけが離反する可能性があるとマークされる。
{kind=link}

グラフ上の点をクリックしてドラッグして閾値を調整するか、閾値%を入力してグラフがどのように変化するかを観察する。終了したら、Set Thresholdをクリックして変更を保存します。右下の「キャンセル」または右上の「×」をクリックすると、変更をキャンセルすることもできます。
閾値を調整することで、y軸に沿った精度とx軸に沿った想起が調整される。これらの指標は逆の関係にある。測定が正確であればあるほど、リコールは低くなる。
QTip:しきい値を調整すると、Predict iQ ページの下部にある予測ストリームセクションで、新しい回答者がこのアンケートに回答するたびに予測を作成するを 選択した場合に、将来のデータがどのように収集されるかが変わります。以前のモデルのChurnデータを上書きするには、Churn変数を削除し、新しい変数を追加する必要があります。しきい値は、Yes/Noのバイナリだけで、Churn Probability変数には影響しない。
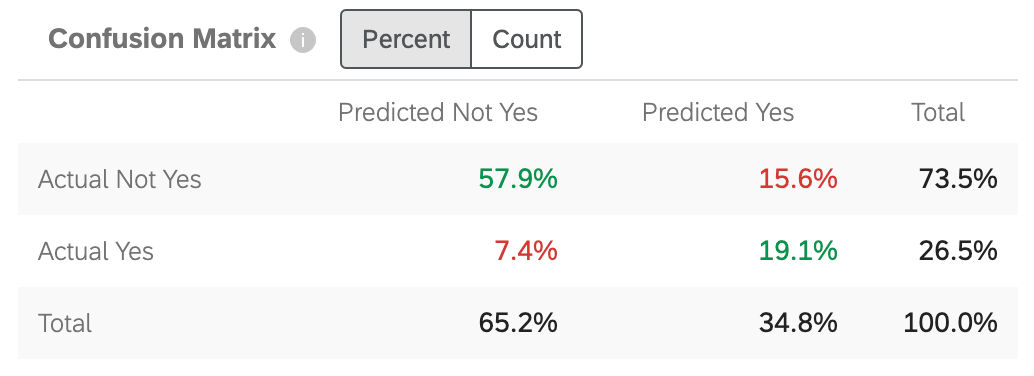
混同行列
Predict iQは予測モデルを構築する際、データの10%を “保留 “する。生成されたモデルの精度をチェックするために、新しいモデルのデータを10%のホールドアウトに対して実行する。これは、予測されたことと “実際に起こったこと “の比較となる。
{kind=link}
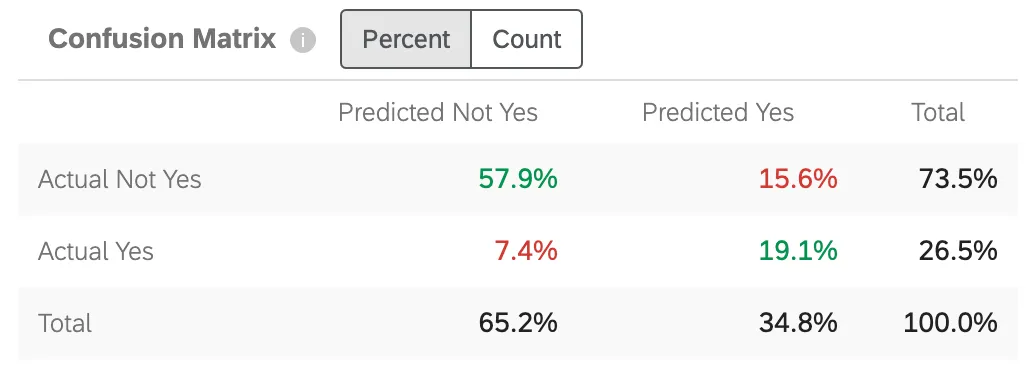
このグラフの “Yes “は、セットアップのステップ5で指定したターゲット値に置き換えられる。
- Actual Not Yes / Predicted Not Yes:モデルが離反しないと予測した顧客のうち、実際に離反しなかった顧客の割合。
- Yes / Predicted Not Yes:モデルが離反しないと予測した顧客のうち、逆に離反した顧客の割合。
- 実際の離反/予測された離反:モデルが離反すると予測した顧客のうち、逆に離反しなかった顧客の割合。
- 実際の離反/予測された離反:モデルが離反すると予測した顧客のうち、実際に離反した顧客の割合。
数字が緑色なのは、正しい推測を反映するため、その数字ができるだけ高くなることを示す。数字が赤くなっているのは、間違った推測を反映しているため、これらの数字を低くしたいことを示す。
マトリックスを調整して、パーセントまたはカウントを表示することができます。このカウントには、データセット全体ではなく、持ち出されたデータの10%が含まれます。
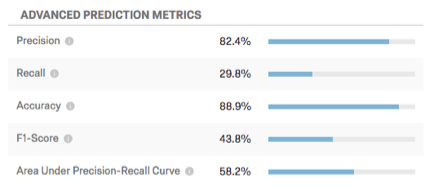
高度な予測指標
この表は、追加の予測メトリクスを表示します。
{kind=link}

- 精度:離反すると予測された顧客のうち、実際に離反した顧客の割合。
- リコール:モデルによって事前に予測された解約者のうち、実際に解約した人の割合。
- 精度:モデルの予測のうち、正確である割合。
- F1スコア: F1スコアは、精度とリコールのバランスをとる閾値を選択するために使用される。F1スコアは一般的に高い方が良いが、閾値を設定する適切な場所はビジネスゴールによって決定されるべきである。
- プレシジョン-リコール曲線下の面積:Precision-Recall曲線は、Configure thresholdをクリックしたときにグラフ上で観察される曲線である。曲線下の総面積は、モデルの全体的な精度を示す指標である(閾値をどこに設定したかに関係なく)。曲線下面積50%はランダム化機能と同じであり、100%は完全に正確である。
予測を作成
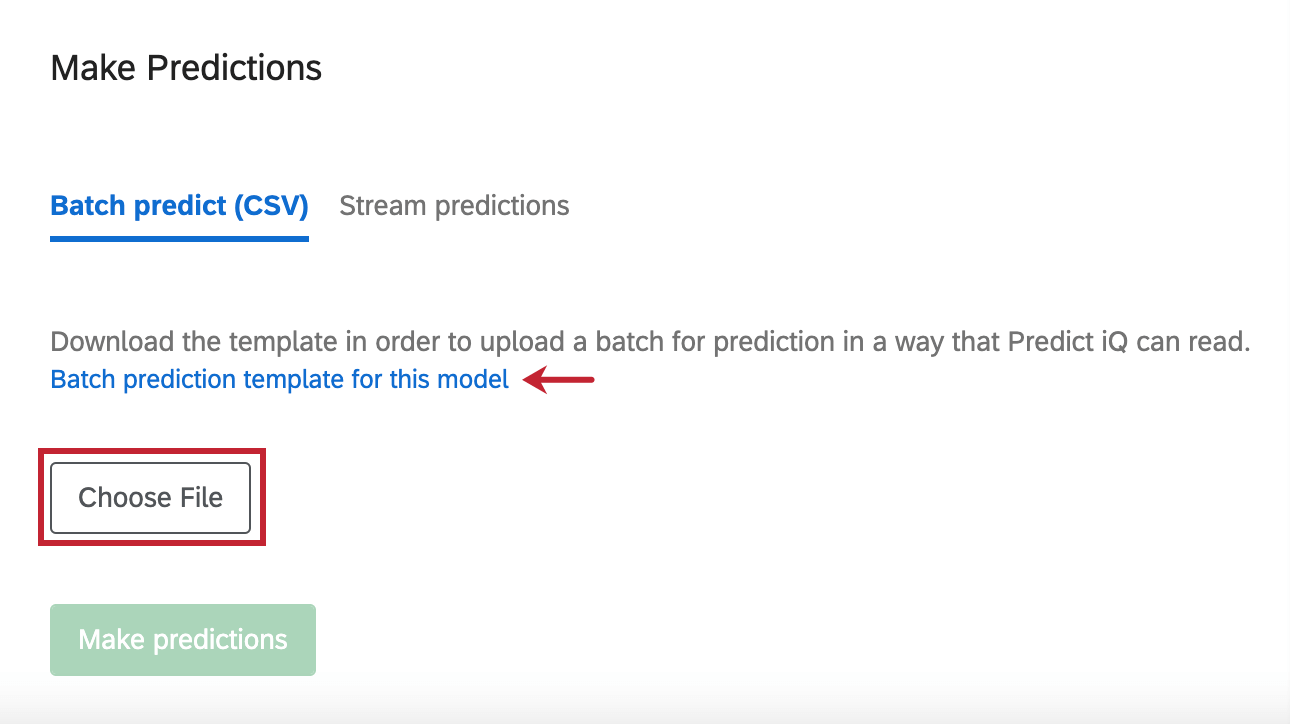
一括予測 (CSV)
アンケート調査で収集した回答を分析するだけでなく、Predict iQに評価してもらいたい特定のデータファイルをアップロードすることもできます。
{kind=link}

ファイルのテンプレートを取得するには、このモデルのバッチ予測テンプレートをクリックします。
Excelでの編集が終わり、ファイルを再アップロードする準備ができたら、Choose Fileをクリックしてファイルを選択します。そしてMake predictionsをクリックして分析を開始する。
Qtip:テンプレートファイルに問題がありますか?CSV/TSVアップロードの問題のページを参照してください。
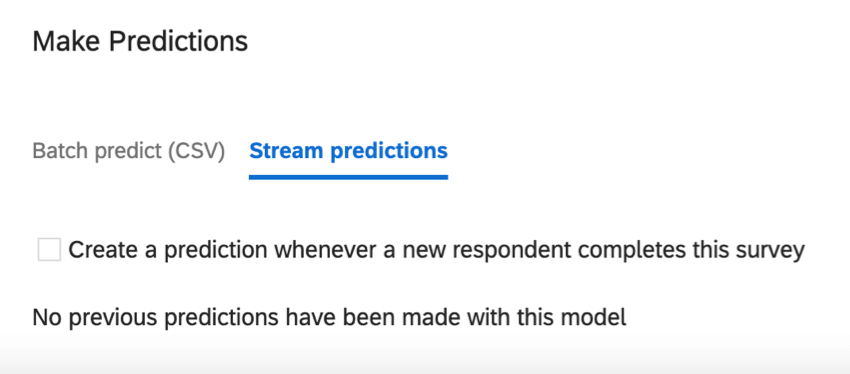
ストリーム予想
アンケート調査にデータが入ると、ストリーム予測は更新される。このセクションでは、これらの予測更新がいつ行われるかを決めることができる。
{kind=link}
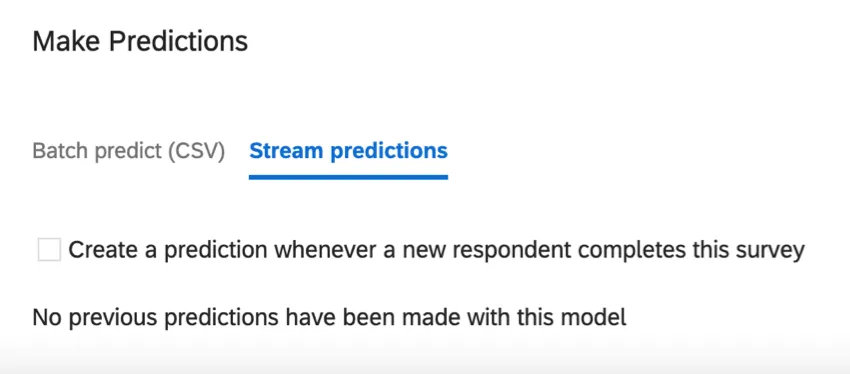
新しい回答者がこのアンケートに回答するたびに予測を作成します:この設定により、リアルタイムの予測が可能になります。データにはさらに2つの列があります:Churn Probabilityは10進数形式で解約の可能性を表し、Churn PredictionはYes/Noの変数です。解約予測は、設定されたしきい値に基づいて行われます。
QTip:データにアンケート調査以外の埋め込みデータが含まれている場合、アンケート終了後すぐにクアルトリクスにデータが届かないことがあります。もしそのデータが予測にとって重要なものであれば、それが読み込まれるまで待つとよいだろう。
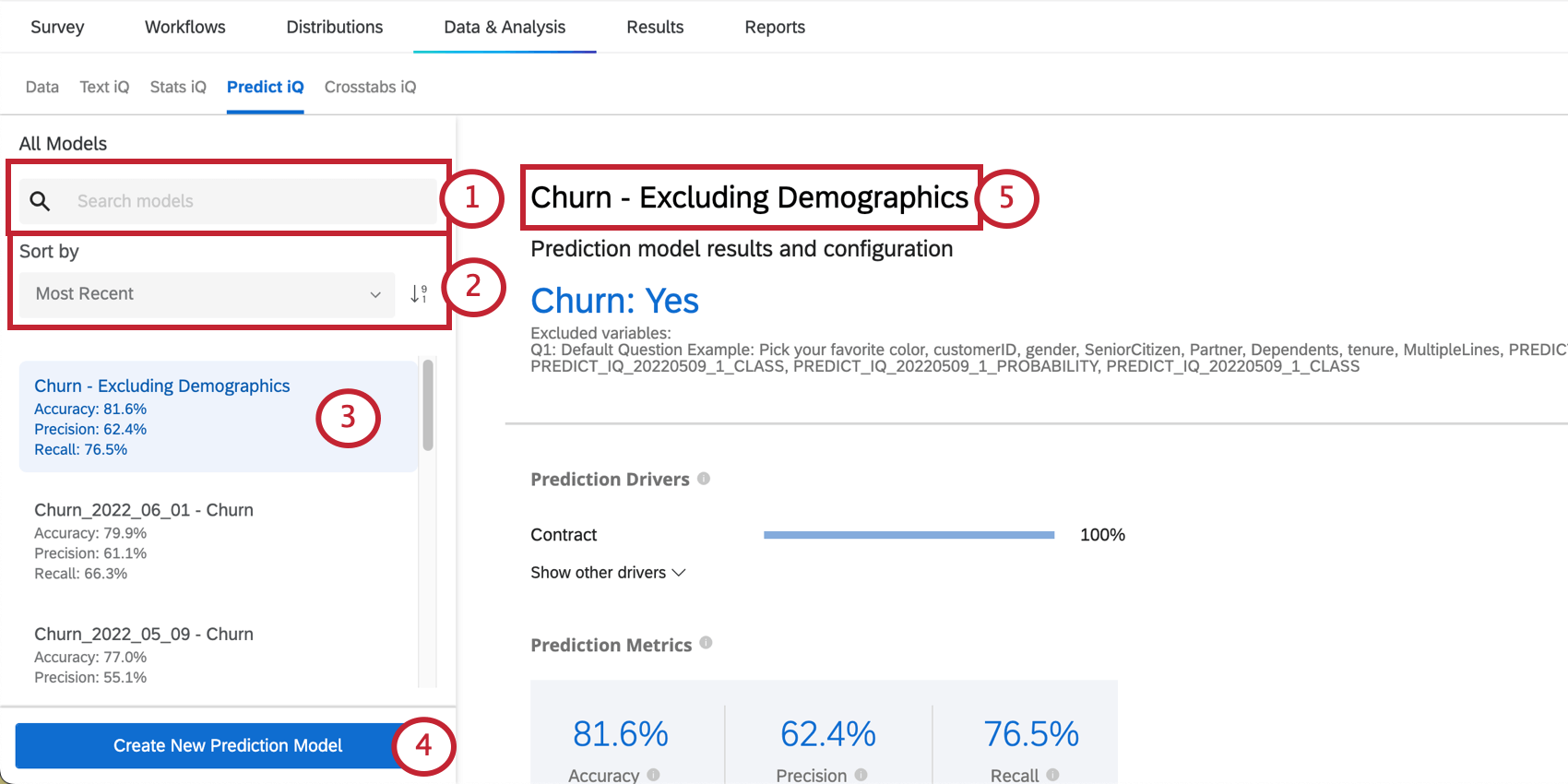
モデルのマネージャー
ページの左側には、過去に作成した予測モデルをスクロールして選択できるメニューがあります。
{kind=link}

解約データ
データと分析]タブの[データ]セクションで、データを便利なスプレッドシートとしてエクスポートできます。予測モデルがロードされると、このページに解約データの列が追加されます。
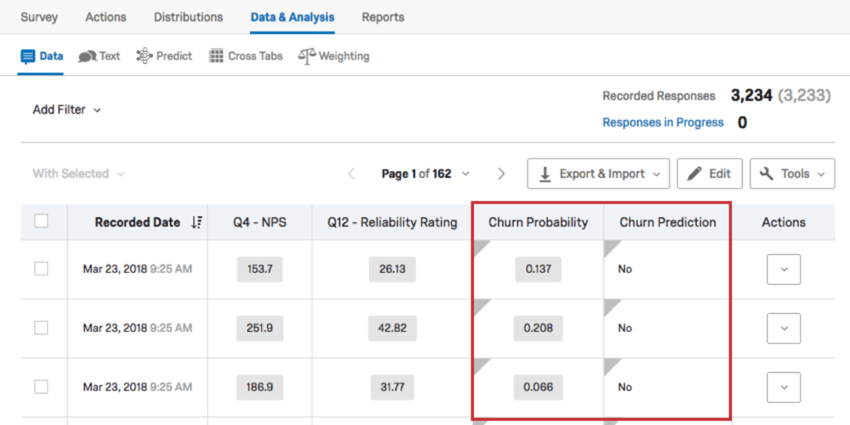{kind=link}
- 解約確率:解約の可能性を10進数で表す。ストリーム予測が有効な場合に表示され、設定されたしきい値に基づく。解約確率の列が見当たらない場合は、「[選択した解約フィールド]_PROBABILITY_PREDICT_IQ」というデータ列を探すこともできます。
- 解約予測:設定されたしきい値に基づき、解約を肯定または否定するYes/No変数。ストリーム予測が有効な場合に表示される。Churn Predictionというカラムが見当たらない場合は、”[selected churn field]_CLASS_PREDICT_IQ” というデータカラムを探すこともできます。
例: 解約予測モデルの作成時に選択した解約フィールド名が “CustomerChurnFlag “の場合、解約データカラムはCustomerChurnFlag_CLASS_PREDICT_IQとCustomerChurnFlag_PROBABILITY_PREDICT_IQのようになります。
カラム名には、MMDDYYYY形式でモデルがトレーニングされた日付も含まれる。例えば、2022年1月14日は01142022とカラム名で表される。
なお、解約確率と予測は新規アンケート調査結果にのみ適用される。既存の回答には、解約確率や予測は追加されません。
Qtip:これらの変数を作成したら、他の変数と同様に、結果レポートまたは詳細レポートを使用して分析することができます。
自動データクリーニング
モデルをトレーニングする際、Predict iQは予測に役立たない変数タイプを自動的に無視し、その他の変数は自動的に変換します。
カーディナリティの高い変数
変数が50以上のユニークな値を持つ場合、または記録された値の20%以上がユニークな場合、モデルのトレーニング中にそれは無視される。ユニークな値が多すぎる機能は、予測に適していない。
例: たとえば、County – USAという変数がある場合、この変数はモデルトレーニング中に無視されます。
例: 別の例として、Favorite Ice Cream Flavorのような変数を考え、この変数のデータが100行あるとします。100行のうち、アイスクリームのフレーバーには21のユニークな値があることをDiscoverは発見した。この変数は、記録された値の20%以上が一意であるため、モデルトレーニング中は無視される。
数値列の欠測値
モデルに含まれる数値変数の場合、欠損値は常に0(ゼロ)にインプットされる。
カテゴリカルのワンホットエンコーディング
カテゴリ変数は、変数が再コード化されないか、変数がそのカテゴリの順序関係を持っていない場合、ワンホット・エンコードされる。
Qtip:Predict iQは、Stats iQで使用されたのと同じ変数設定を引き継ぎます。
不変変数
記録された値に分散がない変数は、モデルトレーニングでは無視される。つまり、一意な値しか持たない変数がある場合、それはモデルの一部にはならない。予測に有用な変数は、ユニークな値が少なすぎることと、ユニークな値が多すぎることのバランスがうまく取れている。上記の「カーディナリティの高い変数」を参照。
データ・クリーニング中に不変変数が除外された場合、それらはPrediction model results and configuration セクションにリストされる。
Predict iQを使用できるプロジェクト
Predict iqはすべてのライセンスに含まれているわけではありません。しかし、この機能があれば、いくつかの異なるタイプのプロジェクトでアクセシビリティを発揮できる:
Predict iQは、EngagementプロジェクトやLifecycleプロジェクトにも登場させることができるが、これらのプロジェクトタイプで通常収集されるデータの性質に基づけば、データセットは必ずしもPredict iQに最適ではないだろう。
Predict iqはConjointとMaxdiffに表示されますが、これらを併用することはお勧めしません。ConjointおよびMaxdiff固有のコンテンツはPredict iqと互換性がないため、人口統計データのみを分析することができます。
その他のプロジェクト・タイプには対応していない。
Qtip:このセクションにリストされているプロジェクトは、すべてのライセンスで利用できるわけではありません。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!