XM Discover Link インバウンドコネクター
このページの内容
XM Discover Link Inbound Connectorについて
XM Discover Link Inbound Connectorを使用すると、フィールドマッピング、変換、フィルター、ジョブ監視など、Connectorsフレームワークが提供するすべての機能を活用しながら、REST APIエンドポイントを介してXMデータをXM Discoverにプッシュできます。
Qtip:一般的なImport APIよりもXM Discover Link Inbound Connectorの使用をお勧めします。
対応データ形式
以下のデータタイプは、JSONフォーマットでのみサポートされています:
コネクタを設定する前に、XM Discoverにインポートするフィールドを表すサンプルファイルを作成します。必須項目とファイル形式の詳細については、上記のリンク先のページをご覧ください。
また、特定のデータ形式用のテンプレートファイルもコネクタ内でダウンロード可能です:
- チャット
- チャット(デフォルト):標準的なデジタル対話データに使用する。
- Amazon Connect:Amazon Connectチャットに特化したデジタルインタラクションに使用します。
- 呼び出し
- Call(デフォルト):標準的な通話記録データに使用する。
- ベリントVerint固有の通話記録に使用します。
- フィードバック
- Dynamics 365:Microsoft Dynamicsのデータに使用します。
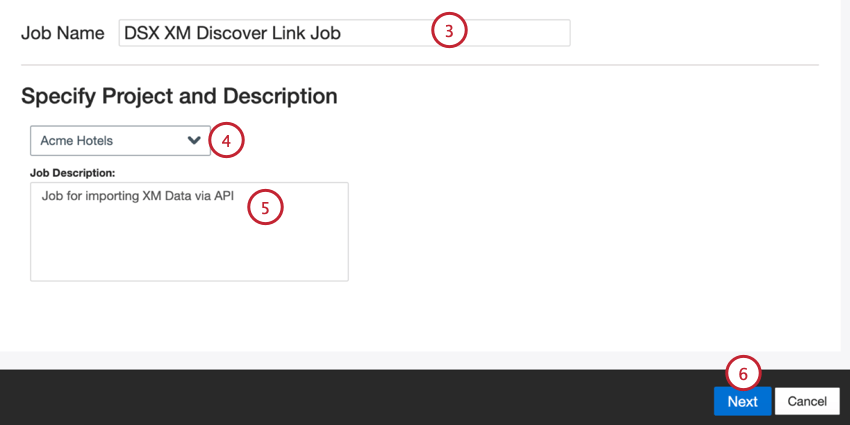
XM Discover Link Inbound Connectorジョブの作成
Qtip:この機能を使用するには、”ジョブのマネージャー “権限が必要です。

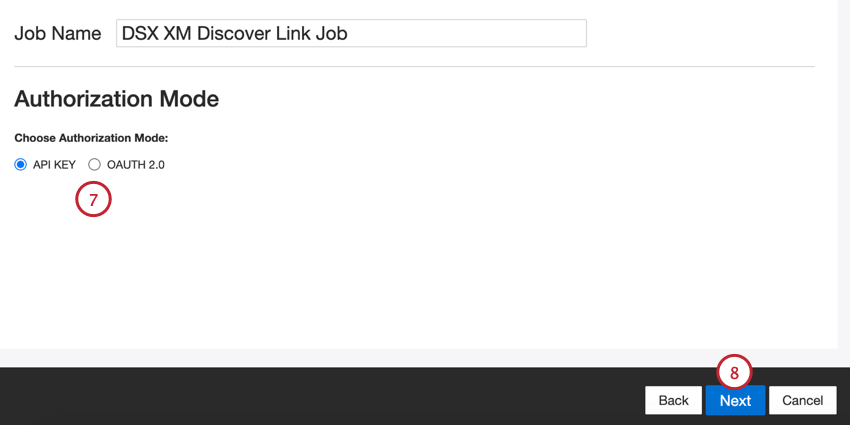
- APIキー:XM Discover API トークンを使用して接続します。
- OAuth 2.0:XM Discover認証サービスから提供されるクライアントIDとクライアントシークレットを使用して接続します。この方法をご希望の場合は、Discoverの連絡先までお問い合わせください。 Qtip: Discoverの担当者に直接Eメールでご連絡いただけます。連絡先がわからない場合は、Discoverサポートチームにお問い合わせください。

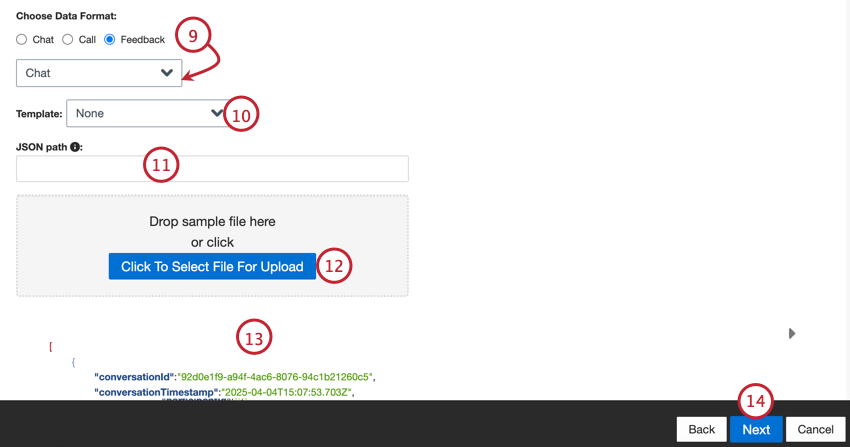
Qtip:「フィードバック」を選択した場合、フィードバックに含まれるインタラクションデータのタイプを選択するための2番目のメニューが表示されます。オプションには、電話、チャット、メール、レビュー、ソーシャル、アンケートがあります。
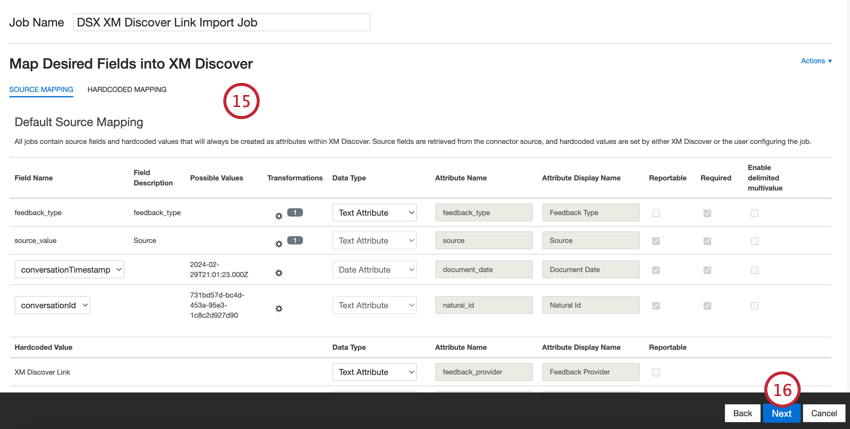
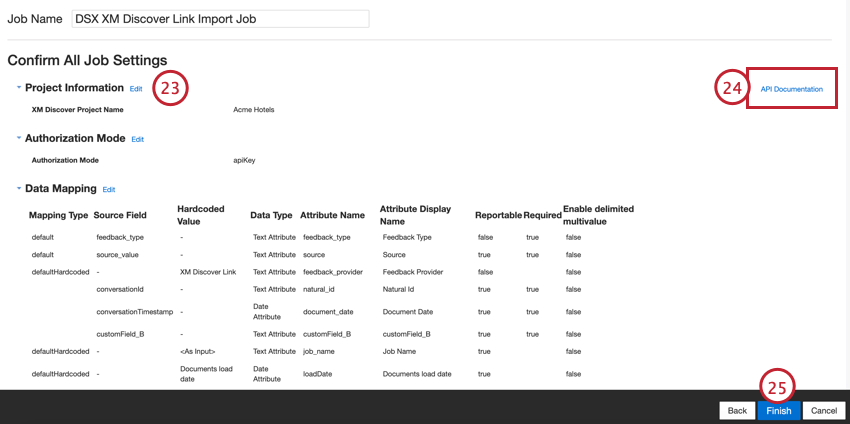
デフォルトのデータマッピング
このセクションでは、XM Discover Inbound Linkジョブのデフォルト・フィールドについて説明します。
フィールドをマッピングする際、以下のデフォルトフィールドが利用可能です:
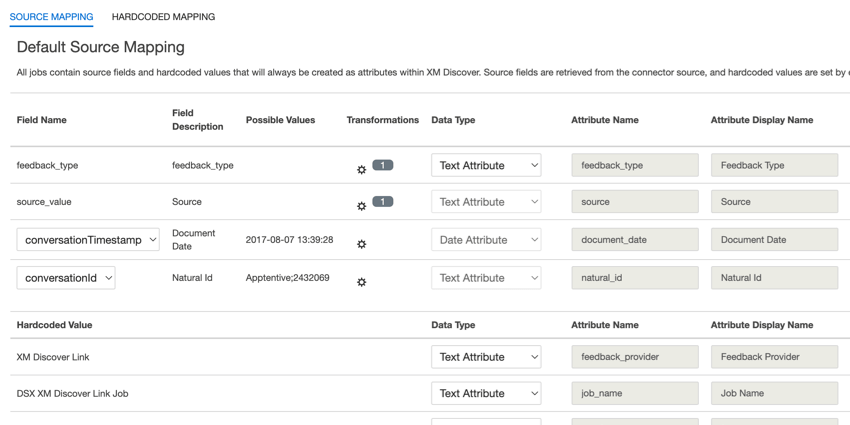{kind=link}
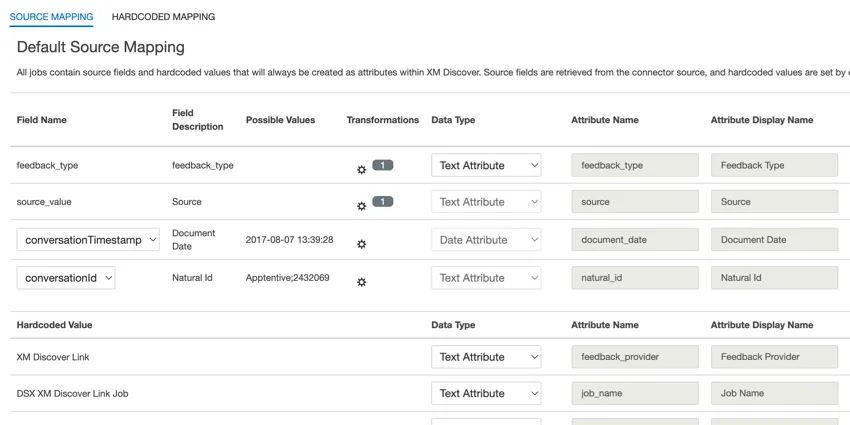
- feedback_type:フィードバック・タイプは、データの種類に基づいてデータを識別するのに役立ちます。これは、プロジェクトに異なるタイプのデータ(例えば、アンケート調査とソーシャルメディアフィードバック)が含まれている場合のレポートに便利です。このフィールドは編集可能である。デフォルトでは、この属性の値は次のように設定されている:
- 「通話記録のための「通話
- 「デジタル交流のための「チャット
- 「個別フィードバックのための「フィードバック
- カスタム変換を使ってカスタム値を設定することができます。
- ソース:ソース:特定のソースから取得したデータを識別するのに役立ちます。これは、アンケート調査やモバイルマーケティングキャンペーンの名前など、データの出所を示すものであれば何でもかまいません。このフィールドは編集可能である。デフォルトでは、この属性の値は “XM Discover Link “に設定されています。カスタム変換を使ってカスタム値を設定することができます。
- richVerbatim:このフィールドは会話データ(通話やチャットのトランスクリプトなど)に使用され、編集はできません。XM Discoverでは、richVerbatimフィールドに会話形式の逐語訳を使用しています。このフォーマットは、会話の図表(話し手の交代、沈黙、会話イベントなど)やエンリッチメント(開始時間、継続時間など)を解除するために必要な、ダイアログ固有のメタデータの取り込みをサポートします。この逐語フィールドには、クライアント側と代理人側の会話を追跡するための「子」フィールドが含まれる:
- clientVerbatimは、クライアント側の会話を追跡します。
- agentVerbatimは、代表者(エージェント)側の会話を追跡します。
- unknownは会話の未知の側面を追跡する。
- Qtip:変換は会話逐語フィールドではサポートされていません。異なるタイプの会話データに同じ逐語を使うことはできない。プロジェクトで複数のタイプの会話をホストしたい場合は、会話のタイプごとに会話文のペアを分けてください。
- clientVerbatim:このフィールドは会話データに使用され、編集可能である。このフィールドは、通話やチャットでのクライアント側の会話をトラッキングします。デフォルトでは、このフィールドは
- clientVerbatimChatでデジタル交流。
- clientVerbatimCall通話インタラクション用。
- エージェントバーベイタム:このフィールドは会話データに使用され、編集可能である。このフィールドは、通話やチャットにおける担当者側の会話をトラッキングします。デフォルトでは、このフィールドは
- agentVerbatimChatでデジタル交流。
- agentVerbatimCallはコールインタラクションのためのものです。
- unknown:このフィールドは会話データに使用され、編集可能である。このフィールドは、通話やチャットでの会話の不明な並列を追跡します。デフォルトでは、このフィールドは次のようにマップされます:
- デジタル交流のためのunknownVerbatimChat。
- unknownVerbatimCallはコールインタラクション用。
- document_date: 文書の日付は、文書に関連付けられた主要な日付フィールドです。この日付はXM Discoverのレポート、トレンド、アラートなどで使用されます。文書の日付は、以下のオプションのいずれかを選択します:
- conversationTimestamp(会話データ用):会話全体の日時。
- データソースに他の日付フィールドが含まれている場合は、フィールド名のドロップダウンメニューから選択することで、それらのフィールドのいずれかを文書の日付として設定することができます。
- カスタムフィールドを追加することで、特定の日付を設定することもできます。
- natural_id:自然IDは文書の一意な識別子として機能し、複製を正しく処理することができます。ナチュラルIDについては、以下のオプションのいずれかを選択する:
- conversationId(会話データ用):会話全体の一意なID。
- データから任意のテキストまたは数値フィールドをフィールド名で選択します。
- カスタムフィールドを追加してIDを自動生成。
- フィードバックプロバイダー:フィードバックプロバイダは、特定のプロバイダから取得したデータを識別するのに役立ちます。XM Discover Linkアップロードの場合、この属性の値は「XM Discover Link」に設定され、編集することはできません。
- job_name: ジョブ名は、データをアップロードするために使用されたジョブの名前に基づいてデータを識別するのに役立ちます。この属性の値は、ページ上部のジョブ名ボックスまたはジョブオプションメニューで変更できます。
- ロード日付:ロード日付は、ドキュメントがXM Discoverにアップロードされた日付を示します。このフィールドは自動的に設定され、編集することはできません。
上記のフィールドに加えて、インポートしたいカスタムフィールドをマッピングすることもできます。カスタムフィールドの詳細については、データマッピングのサポートページを参照してください。
APIエンドポイントへのアクセス
注意: APIエンドポイントは、APIコールごとに1つのcoverationのみをサポートしており、ペイロード例のフィールドのみを含める必要があります。
APIエンドポイントは、JSON形式のREST APIリクエストでデータを送信することにより、XM Discoverにデータをアップロードするために使用されます。
ジョブページからエンドポイントにアクセスできます:
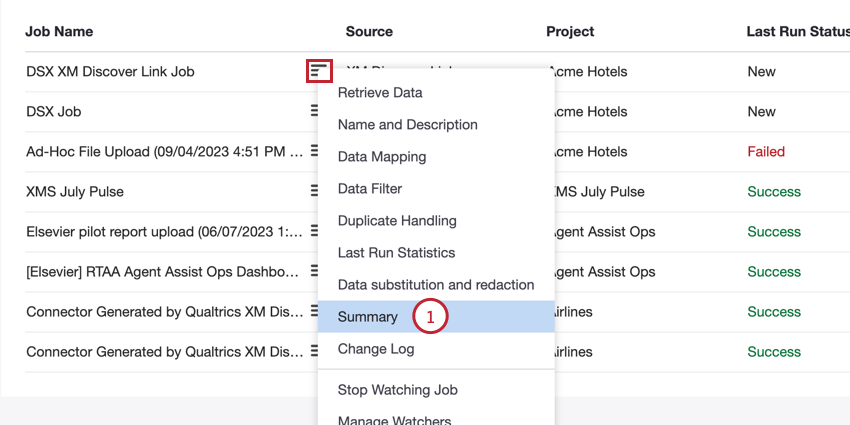

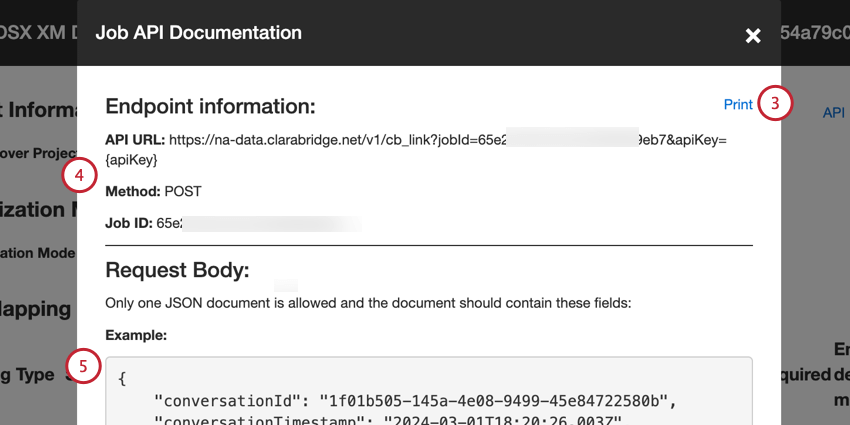
- API URL:API リクエストに使用される URL。
- メソッドを使用します:XM Discoverにデータをロードするには、POSTメソッドを使用します。
- ジョブID:現在選択されているジョブのID。
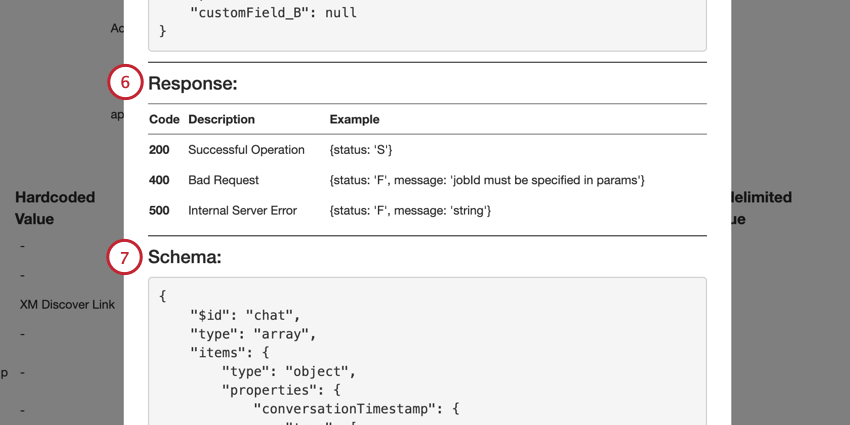
API 経由での XM Discover Link ジョブの監視
ステータスAPIエンドポイントを呼び出すことで、XM DiscoverにログインせずにXM Discover Linkジョブのステータスを監視できます。これにより、最新のジョブ実行ステータス、特定のジョブ実行のメトリクス、または特定の期間の累積メトリクスを取得できます。
ステータス・エンドポイント情報
ステータス・エンドポイントを呼び出すには、以下のものが必要だ:
- API URL: https://na-data.clarabridge.net/v1/public/job/status/<jobID>?apiKey=<apiKey>
- <jobId> はモニターしたいXM Discover LinkジョブのIDです。
- <apiKey> はAPIトークンです。
- タイプREST HTTPを使用します。
- HTTPメソッド:データを取得するにはGETメソッドを使用します。
入力要素
以下のオプションの入力要素を使用して、ジョブに関する追加のメトリクスを取得できます:
- historicalRunId:特定のアップロードセッションのID。この要素が省略され、日付範囲が提供されない場合、APIコールは最新のジョブ実行ステータスを返します。この要素を省略し、日付範囲を指定すると、API 呼び出しは指定された期間の累積メトリッ クスを返します。
- 開始日:データを返す開始日を定義します。
- endDate:最後のアップロードに基づくデータを返す終了日を定義します。この要素が省略され、startDateが指定された場合、endDateは自動的に現在の日付に設定される。
Qtip:historicalRunId が指定された場合、指定された historicalRunId のデータが蓄積されます。startDate と endDate が指定されている場合は、指定された日付範囲のデータが蓄積され、指定されていない場合は、最新の historicalRunId のデータが蓄積されます。
出力要素
必要な入力要素が入力されていれば、以下の出力要素が返される:
- job_status:ジョブのステータス。
- job_failure_reason: ジョブに失敗した場合、失敗の理由。
- run_metrics:ジョブが処理したドキュメントに関する情報。以下の指標が含まれる:
- 正常に作成されたドキュメントの数:正常に作成されたドキュメントの数。
- 正常に更新されたドキュメントの数:正常に更新されたドキュメントの数。
- skipped_as_duplicates:複製としてスキップされたドキュメントの数。
- FILTERED_OUT:ソース固有のフィルターまたはコネクターフィルターのいずれかによってフィルタリングされたドキュメントの数。
- BAD_RECORD:クアルトリクスの会話フォーマットと一致しなかったデジタル対話の数。
- SKIPPED_NO_ACTION: 複製でないとしてスキップされた文書の数。
- failed_to_load:読み込みに失敗したドキュメントの数。
- TOTAL: このジョブの実行中に処理されたドキュメントの総数。
エラーメッセージ
ステータスAPIリクエストでは、以下のエラーメッセージが表示される可能性があります:
- 401 認証されていません:自分らしくいられること認証に失敗しました。別のAPIキーを使用してください。
- 404 見つかりません:指定されたIDのジョブが存在しません。別のジョブIDを使用してください。
サンプルリクエスト
以下は、ジョブのステータスを取得するリクエストの例で
ある:curl --location --request GET 'https://na-data.clarabridge.net/v1/public/job/status/62da736987c9788b830918e0?apiKey=02e7a0e26b592632dd50f623e974fff6'
サンプル回答
以下は失敗したジョブの回答サンプルで
ある:{
"job_status":"Failed",
"job_failure_reason":"{"problem":[{"requestId": "RQ-MOB-f339aa58-71b6-4a1d-a67c-12b8d3439321", "severity": "ERROR", "description": "Length limit of 900 characters for attribute supportexperienceresp has been exceeded, length is 1043"}], "status": "ERROR"}",
"run_metrics":{
"successfully_created":10,
"failed_to_load":1,
"total": 11
}
}.
ペイロードの例
このセクションには、サポートされる構造化データのタイプ (フィードバック、チャット、コール) ごとに、1 つの JSON ペイロード例が含まれています。
注意: このセクションのペイロードはデモンストレーションのみを目的としています。ペイロードのフィールドは、特定の設定によって異なります。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!