構造化データによるフィルタ(デザイナー)
このページの内容
構造化データによるフィルタリングについて
構造化データ属性を使用して、フィードバックをフィルタリングし、データセットから最も関連性の高い情報を分類して表示するモデルにします。フィルタの作成と編集については、「データのフィルタリング(Designer)」を参照してください。
Qtip: ほとんどの構造化フィルターは属性を使用して作成されます。XM Discoverでの属性の作成と編集の詳細については、「属性」を参照してください。
感情によるフィルタリング
XM Discoverは感情分析を使用して、フィードバックの全体的な感情を判断します。感情は、あらかじめ定義された帯域を持つシステム属性として利用できる:
- 否定的感情:感情スコアが-5.0~-1.0のフィードバック。
- 中立感情:感情スコアが-0.99~0.99のフィードバック。
- ポジティブ感情:感情スコアが1~5.0のフィードバック
Qtip: 感情システム属性を使用して、カスタムの感情範囲を作成できます。例えば、_degreesentimentindex:[2.51 TO 5]。
言語によるフィルター
データ型でフィルターをかけるには、以下のDiscoverシステム属性を使用します:
- CB 自動検出言語(_languagedetected ):プロジェクトが自動言語検出を使用している場合、言語フィードバックが送信されました。
- CB 処理言語(_language ):言語フィードバックが提出された。言語がXM Discoverでサポートされていない場合は、「OTHER」と表示されます。
XM Discoverは、Automatic Language Detection機能により、150以上の言語のデータを認識し、タグ付けすることができます。自動言語検出を使用しない場合、以下の言語が使用可能です:
- アラビア語
- ベンガル語
- 中国語(簡体字・繁体字)
- オランダ語
- 英語
- フランス語
- ドイツ語
- ヒンディー語
- インドネシア語
- イタリア語
- 日本語
- 韓国語
- ポーランド語
- ポルトガル語
- ルーマニア語
- ロシア語
- スペイン語
- スウェーデン語
- タガログ語
- タイ語
- トルコ人
- ベトナム語
注意: 10文字未満の動詞は英語としてタグ付けされます。
データタイプによるフィルター
提出されたデータの種類によってフィードバックをフィルタするには、以下のシステム属性を使用します:
- ソースID (_id_source ):文章のデータソース。
- Verbatim Type (_verbatimtype ):フィルターしたい逐語フィールド名。これは、複数の逐語列がある場合に便利です。
例: 2つの逐語列があるとします:評価者」と「回答者」です。verbatimtype:reviewのルールを作成し、Reviewverbatim列のデータのみを表示するモデルを返します。
コンテンツタイプによるフィルタリング
コンテンツタイプ検出が有効になっているプロジェクトでは、以下のシステム属性を使用して、広告、スパム、およびその他のアクション不可能なデータからのフィードバックをフィルタリングします:
- CBコンテンツ・タイプ (cb_content_type ):文書が、コンテンツを含むことを意味するコンテントフルとマークされるか、コンテントフルでないことを意味するノンコンテントフルとマークされるか。
- CB Content Subtype (cb_content_subtype ):非コンテントフルとマークされた文書を広告、クーポン、記事リンク、または「未定義」にグループ化します。
例: 例:コンテンツフルデータのみを分類するモデルを作成したい場合、CB Content Typeシステム属性:cb_content_type:contentfulを使用してルールを作成します。
センテンスタイプによるフィルタリング
XM Discoverは、セマンティック解析を使用して、アナリティクスに関連する意図を特定します。これらのカテゴリーは文レベルのシステム属性で使用される:CB センテンス・タイプ (cb_sentence_type). データで使用されているインテントのタイプを分析することで、カスタマーエクスペリエンスをどのように改善できるかを理解することができます。
以下の文の種類をクリックして、文の種類属性で識別される内容を確認してください:
Qtip: どの文型にもマッチしない文はUNDEFINEDとしてタグ付けされます。
単語数によるフィルター
文の単語数または文書の単語数属性を使用して、文またはレコードの単語数でデータをフィルタリングします。これらの属性に設定される範囲はインクルージョン値である。単語数がゼロの場合、その文/レコードにはテキストがないか、機能が有効になる前に読み込まれたかのどちらかです。
- CB Sentence Word Count (cb_sentence_word_count ):文レベルの属性で、文中の単語数でデータをフィルターできます。 Qtip: 10語以下の文章を表示するには、cb_sentence_word_countの範囲を使ってください:[1 TO 10].

- CB Document Word Count (cb_document_word_count ):レコードレベルの属性で、レコード内の単語数でデータをフィルターできます。これはまた、すべての文の単語数の合計でもある。 Qtip: 50語以上のレコードを表示するには、cb_document_word_countを使用してください:[50 TO 200]を使う。
文の四分位数によるフィルタリング
CB Sentence Quartile (cb_sentence_quartile ) 属性は、文が逐語的に続く部分を識別する。数値は1~4で、各セクションは逐語的長さの25%に相当する。レコードに複数の逐語訳がある場合は、レコード内の逐語訳ごとに四分位数が設定される。
QTip: この属性は、顧客が電話をかけてくる理由(通常、逐語録の第1四分位( 1 )で議論される)に志向を絞りたい場合に役立ちます。また、担当者がどのようにコールを終了しているかに興味がある場合は、レポートを最後の四分位値(4)に限定することもできます。
センテンス四分位の適用
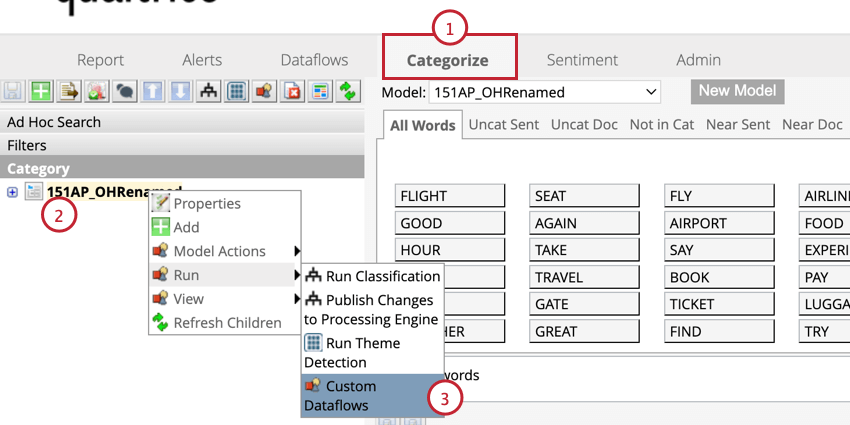
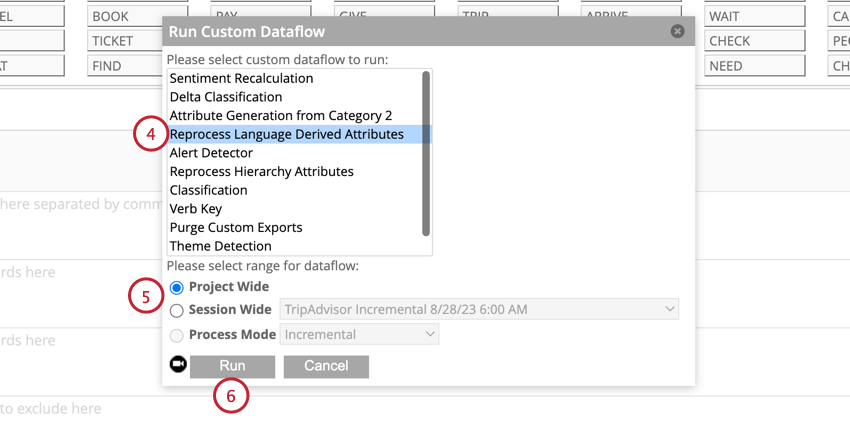
過去のデータに文の四分位データがない場合は、Itを追加することができます。
努力によるフィルター
カスタマーエクスペリエンスは 、カスタマーエクスペリエンス中にカスタマーが表現した努力のレベルを測定する。この属性は、文レベルで-5から5までの評価が可能で、-5は最も困難なエクスペリエンス、5は最も容易なエクスペリエンスを示す。範囲はインクルージョン値である。
Qtip: 努力のレベルが非常に高い文章を表示するには、cb_sentence_ease_score:[-5 to -3].
Qtip: CB Effortは整数のみに対応しています。
ロイヤルティ期間によるフィルタリング
CBロイヤルティ・テニュアでは、顧客がサービスを利用した年数や製品を所有した年数でデータをフィルターすることができます。この属性は、テニュア文型を持つ文の文レベルで利用できる。範囲はインクルージョン値である。
例: I’ve been a customer for 10 years “と入力すると、ロイヤルティは10となります。在職期間が10年までの判決を表示するには、次の範囲を使用する:cb_loyalty_tenure:[1 TO 10].
交流タイプによるフィルタリング
CB インタラクション型 (cb_interaction_type) は、XM インタラクションの型によってデータを定義します。これにより、通常のフィードバックと対話型のデータを区別することができます。この属性は、文書レベル、逐語レベル、文レベルで利用できる。
インタラクションタイプには以下の値がある:
- チャット:デジタルチャネルからの会話データ。
- フィードバック:定期的なフィードバックデータ(オンラインでの言及、評価者など)。
- アンケート調査:アンケート調査の回答データ。
- 声:音声に書き起こされた会話データ。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!