データマッパーフィールドの再コード化(Cx)
このページの内容
データマッパーにおけるダッシュボードフィールドの再コード化について
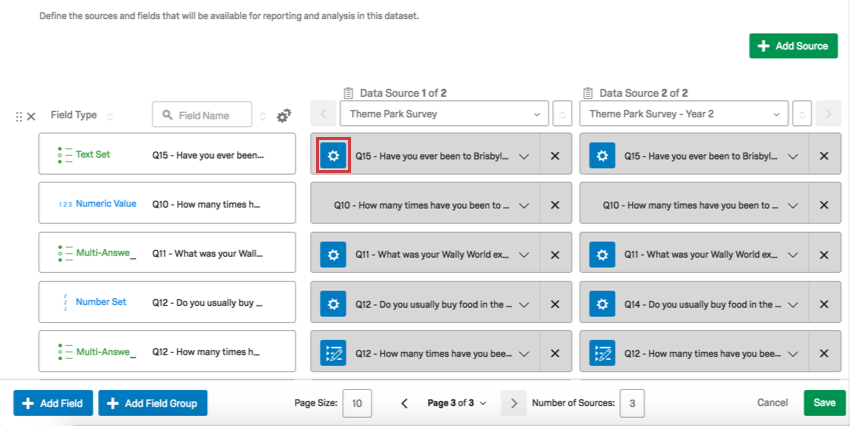
CXダッシュボードでは、ダッシュボードエディターがダッシュボード設定でテキストセット、マルチアンサーテキストセット、およびナンバーセットのデータを再コード化できます。例えば、選択肢のラベルを短くしたり、テキストを数字に変更したりすることができます。
Qtip:データマッパーで識別値を割り当てても、アンケート調査のデータには影響しません。
Qtip:データモデラーでデータを再コード化したい場合は、データモデルフィールドの再コード化(CX)を参照してください。
レコーディング・フィールド
Qtip:デフォルトのRecode Editorは以下のフィールド構成で表示されます:
- 自由記述として作成されたものではないテキストセット(例:質問文なし)。
- 自由記述欄として作成されなかった番号セット(例:自由記述の質問文がない)。
- 自由記述として作成されたものではない複数回答記述式 (例:多肢選択式の質問)。
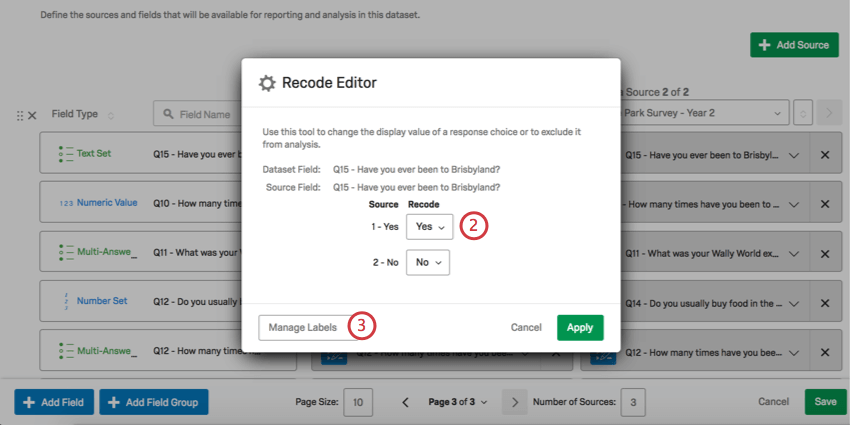
Qtip: 識別値を割り当てられるのは、指定したフィールドタイプに限られることに注意してください。たとえば、NPSスコアをNPSグループに識別値を割り当てたい場合、フィールドタイプはNumber SetではなくText Setでなければなりません。
注意: テキストセットの識別値を割り当てたり、テキストセットの識別値をインポートしたりすると、数値が表示されます。これらの値は選択肢ID、つまり各選択肢が作成されたときに与えられた内部IDです。これらのIDは時系列に割り当てられ、選択肢を削除してもリセットされないため、質問のID番号にずれが生じることがあります。
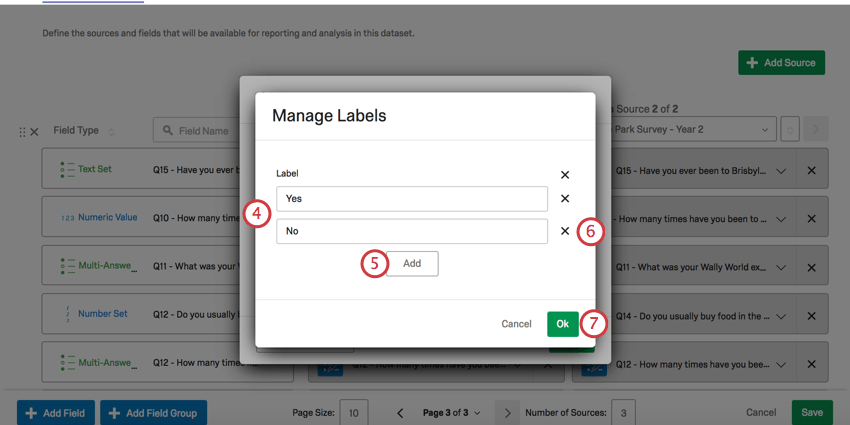
Qtip: リコードオプションはソースと異なっていなければならない。識別値を割り当てた場合、その識別値はリストから削除される。
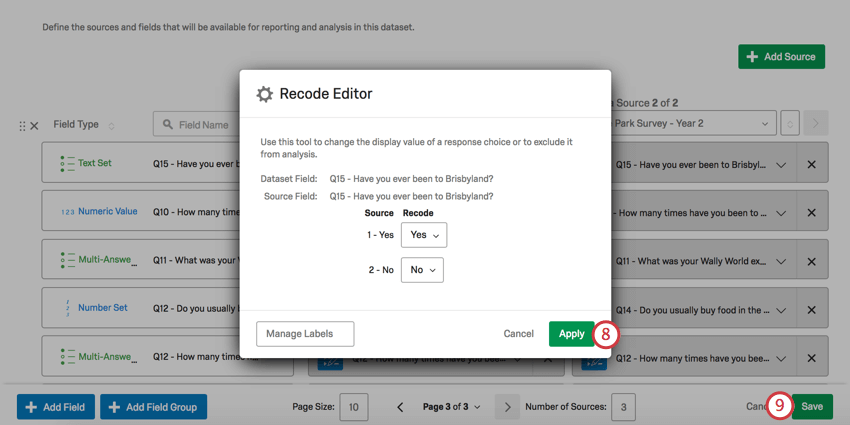
Qtip:再コード化できるのは、テキストセット、複数回答テキストセット、番号セットのみです。
Qtip:アンケートのスコアリングカテゴリ、バケットフィールド、計算式、その他のカスタムフィールドデータを再コーディングする場合は、派生データを参照してください。
自由記述フィールドをテキストセットまたは数値セットとして再コード化する。
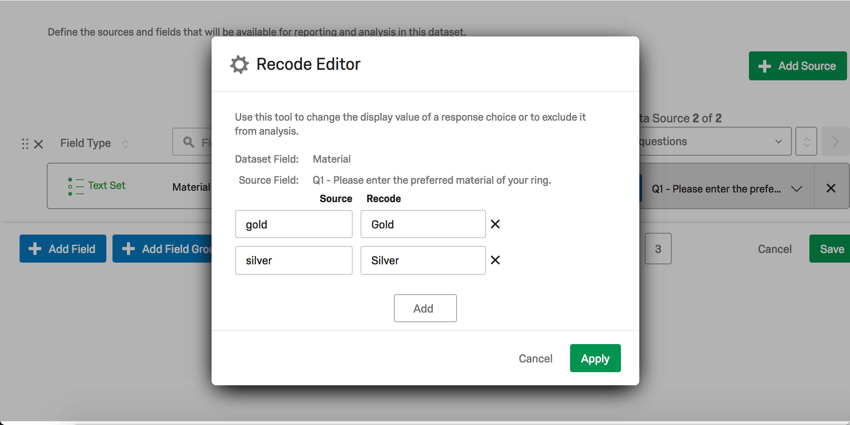
自由記述フィールドをテキスト・セットまたは数値セットにマッピングする場合、上記の再コード・エディタは表示されません。代わりに、2つの列が表示されます。
Qtip:自由記述フィールドには、テキスト入力問題、マトリックステーブルまたは他の質問タイプ上のテキスト入力フィールド、埋め込みデータフィールド、またはインポートされたデータプロジェクトのテキストなどのソースが含まれます。
{kind=link}

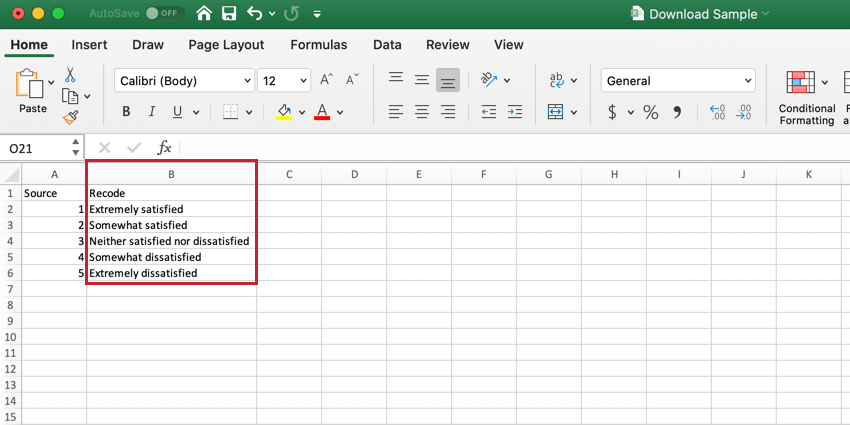
- ソース」列は、データで提供された回答の正確なテキストを指す。例えば、ジュエリーの素材を尋ねる質問なら、”ゴールド “や “シルバー “といった答えが返ってくるかもしれない。
- Recode列は、ダッシュボード・ウィジェットに表示されるときに、このデータにどのようなラベルを付けたいかを示す。
Qtip:オプションを追加したり識別値を割り当てたりする必要はありません。データはダッシュボードに表示されるために再コード化される必要はありません。再コード化エディターは、ウィジェットでラベル付けされる方法をフォーマットするだけです。
注意: Htmlはrecodeエディタではサポートされていませんので、自動的に削除されます。
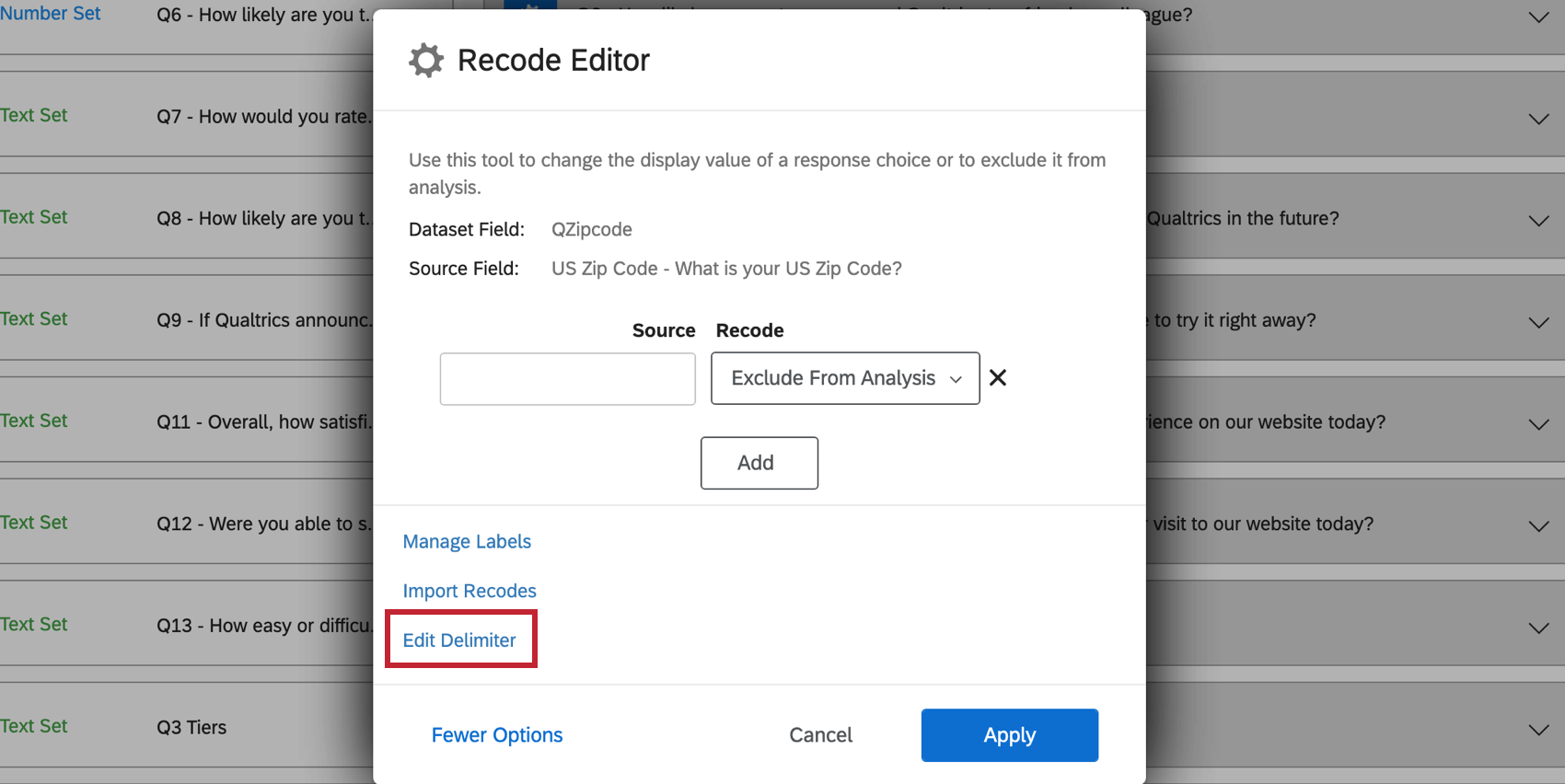
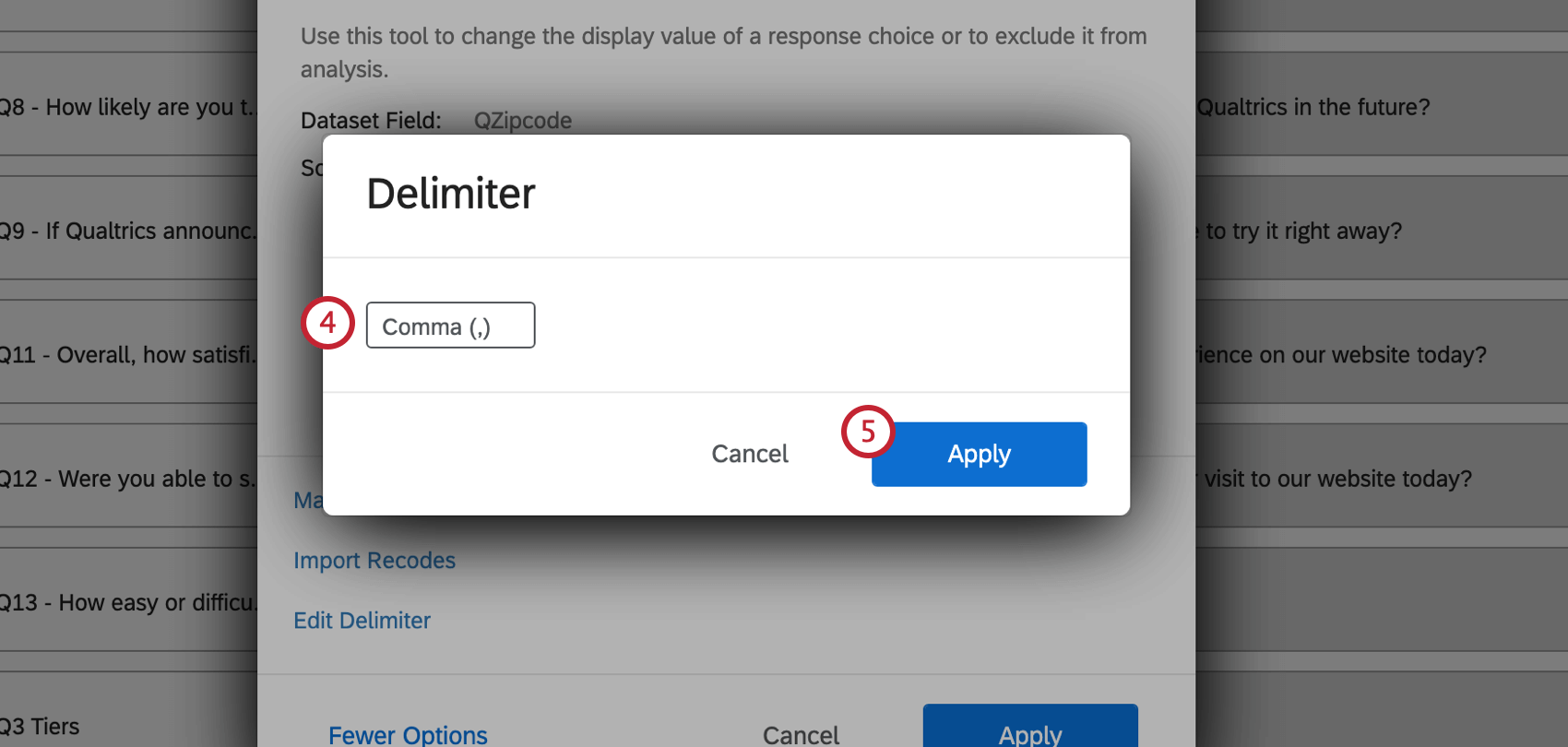
デリミターのマネージャー
自由記述フィールド(自由回答質問文や埋め込みデータフィールドなど)を複数回答テキストセットにマッピングする場合、Recode Editorで区切り文字を定義するオプションがあります。デリミタは、自由形式フィールドに入力された異なる回答間の部署を決定するためのものです。例えば、回答者に子供の名前をコンマで区切ってリストしてもらった場合、区切り文字はコンマになります。
識別値を割り当てる
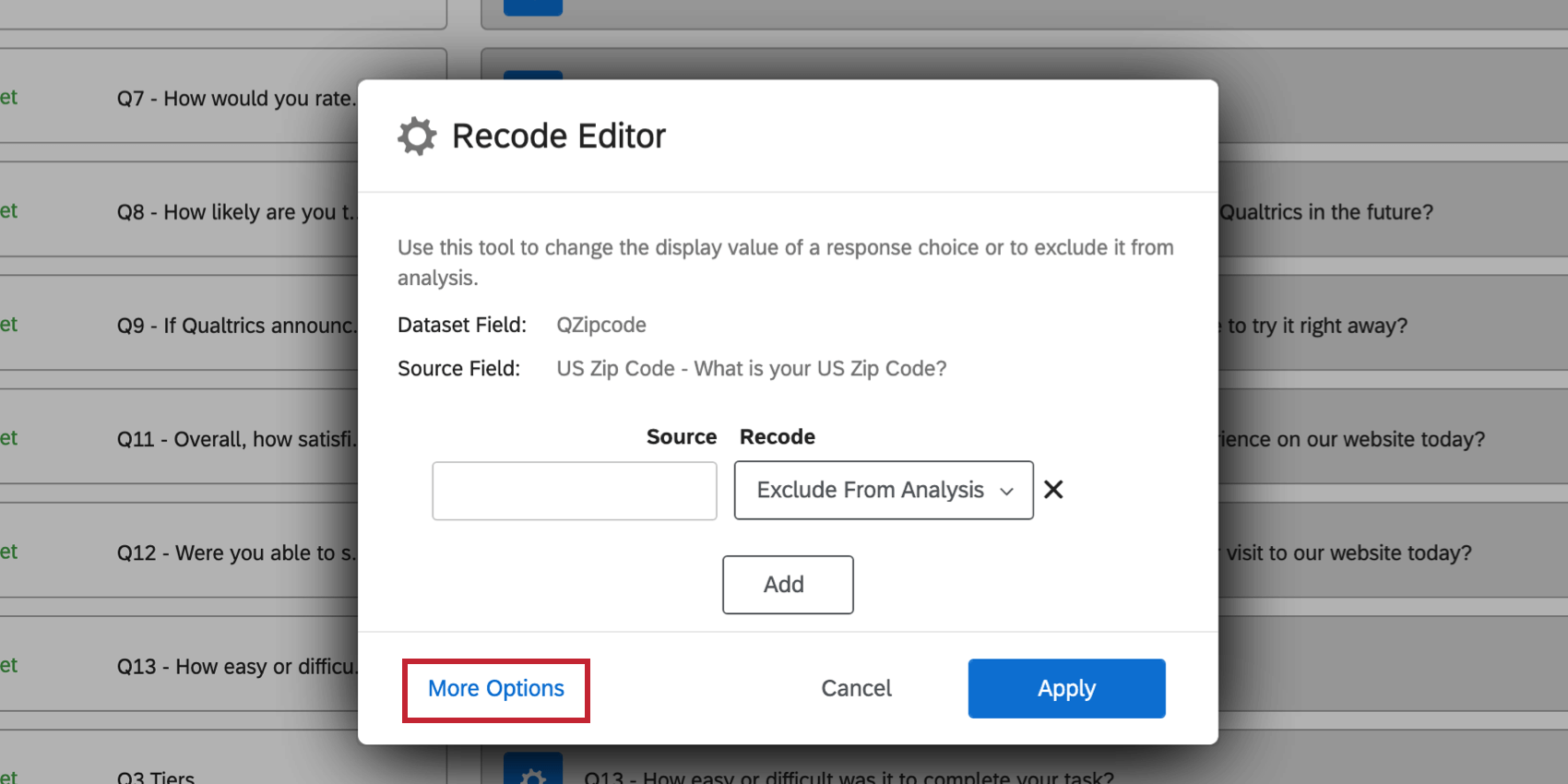
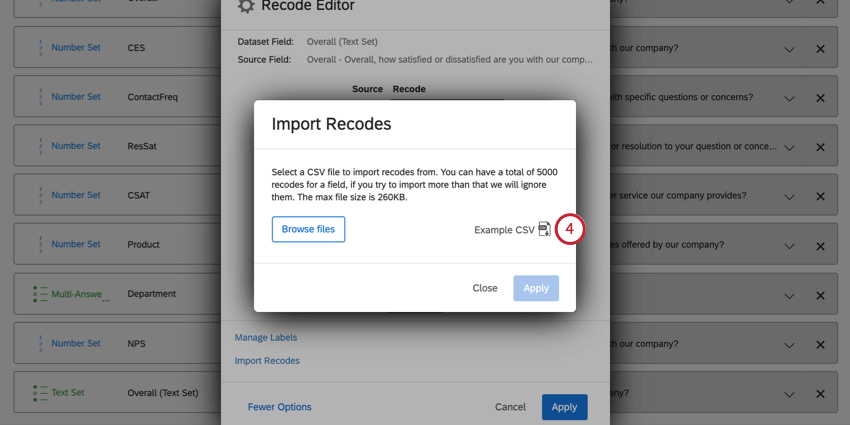
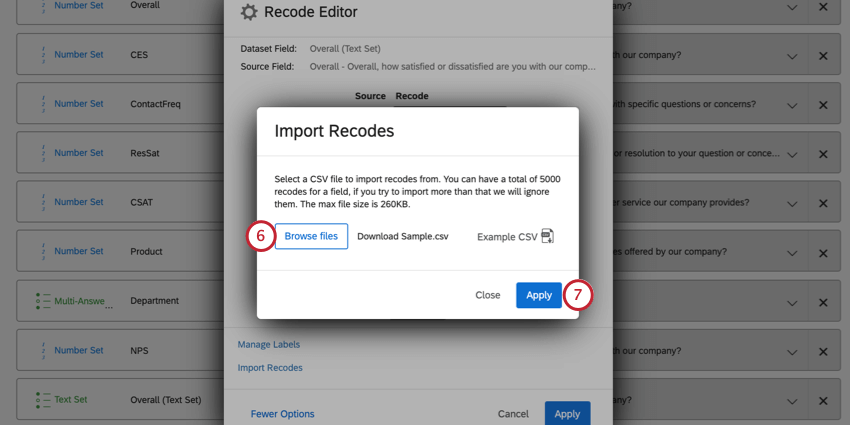
Recode Editorでは、識別値をマッピングされたフィールドにインポートすることができます。これは、識別値をたくさん割り当てたい場合や、複数のデータソースにわたって同じフィールドを再コード化する場合に便利です。
Qtip:フィールドは最大5000識別値を割り当てられます。
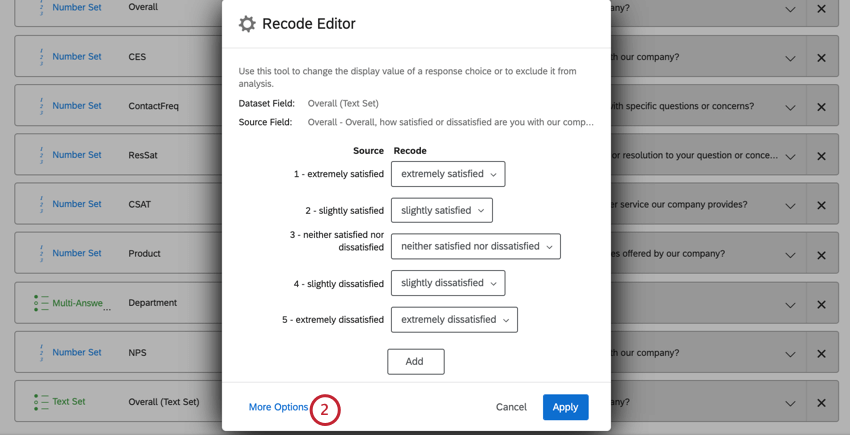
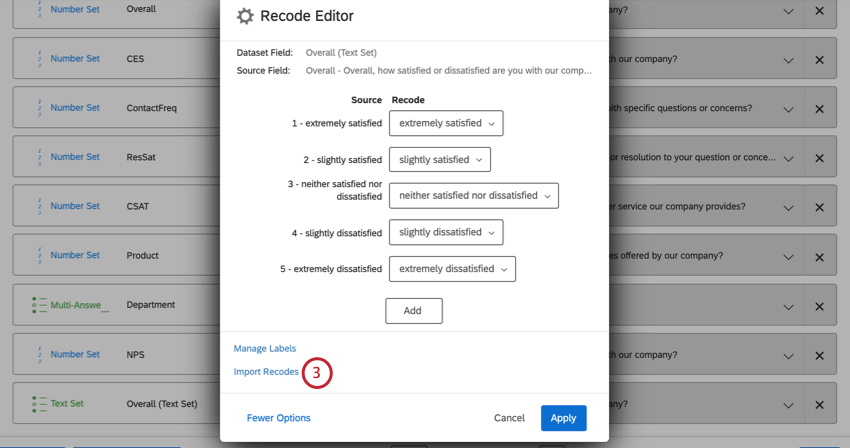
Qtip:識別値を割り当てない場合、選択肢は「分析から除外」として再コード化されます。
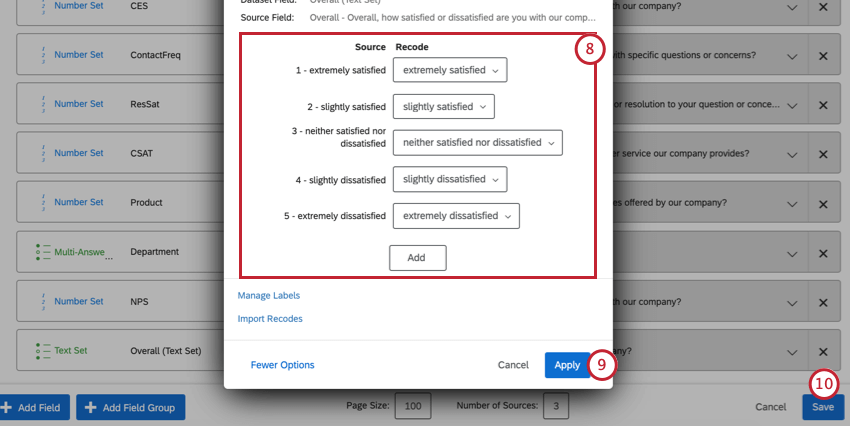
グループ化フィールド
識別値を割り当てる最も一般的なユースケースの一つは、似たような選択肢をグループ化することである。例えば、NPSの質問はすべて0~10の尺度で評価され、この尺度から回答者は批判者、中立者、推奨者に分類される。
以下、同じような例の実装方法を順を追って説明する。
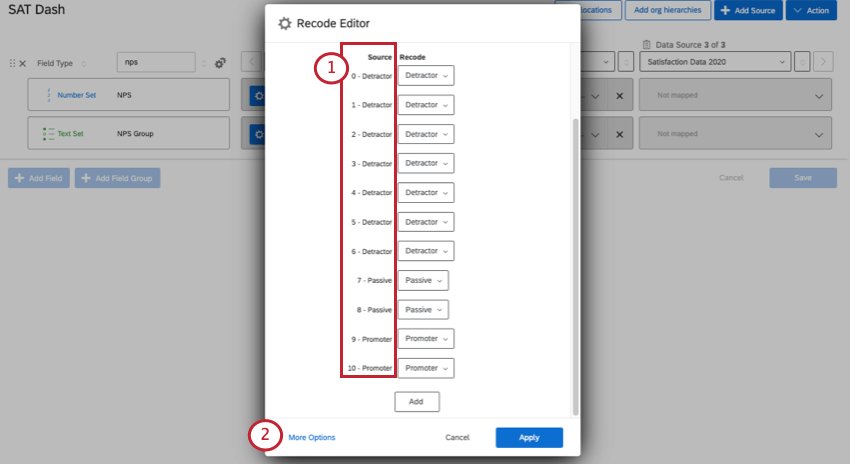
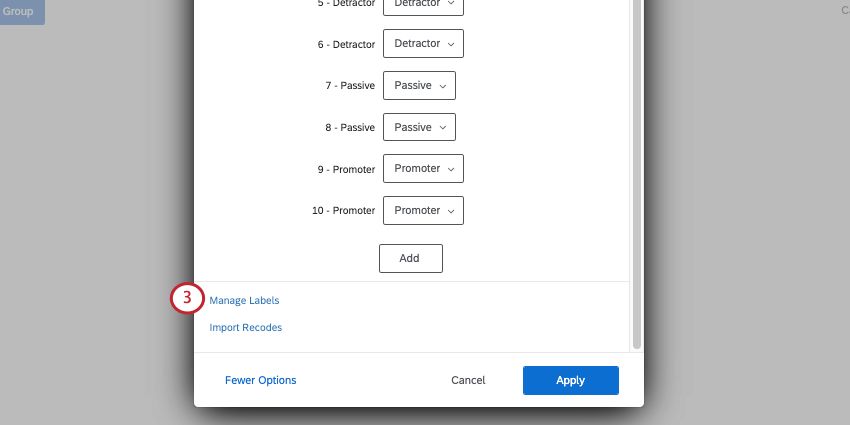
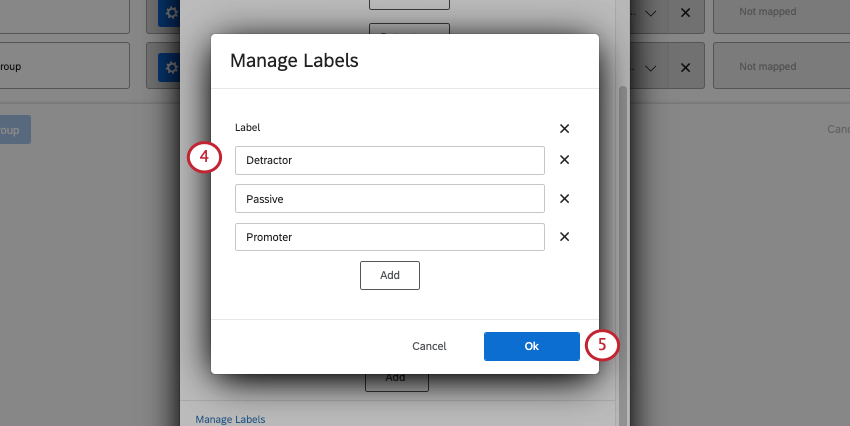
Qtip:必要であれば、Addをクリックしてフィールドを追加したり、Xをクリックしてフィールドを削除することができます。
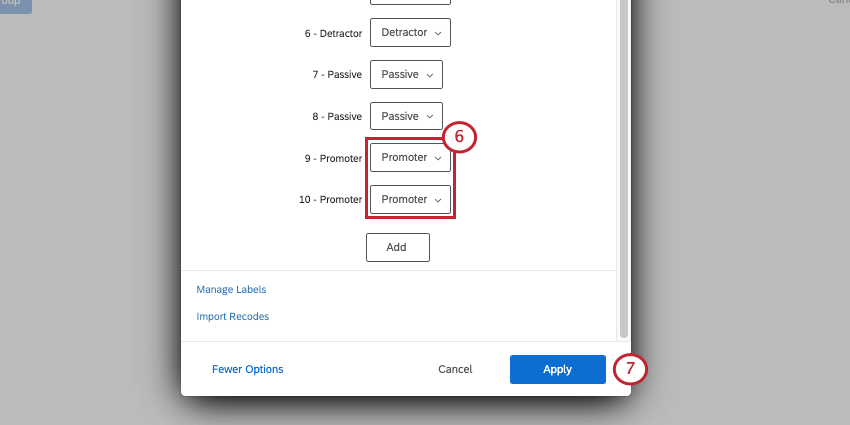
データのクリーンアップ
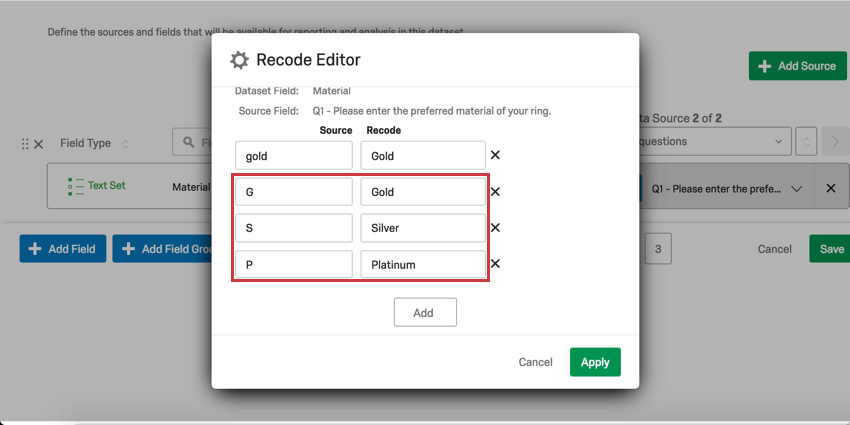
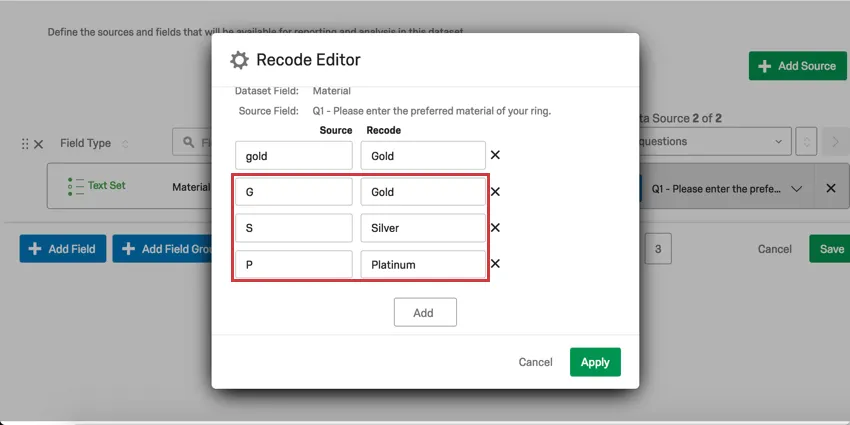
識別値を割り当てるもう一つのユースケースは、一貫性のないデータの整理と統合である。例えば、1つの埋め込みデータフィールドの値のいくつかが「G」であり、いくつかが「Gold」であり、いくつかが「gold」である場合、CXダッシュボードはこれらを3つの異なる値として解釈します。これらの識別値をすべて “Gold “に割り当て直すことで、一貫性のない値を修正またはグループ化することができる。
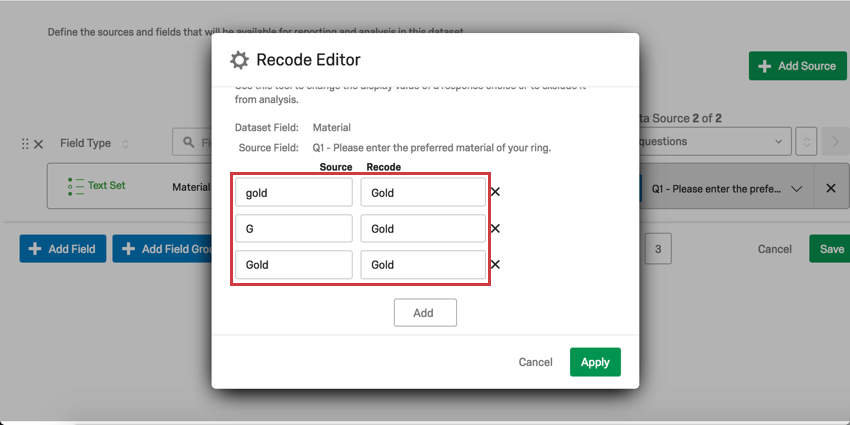{kind=link}
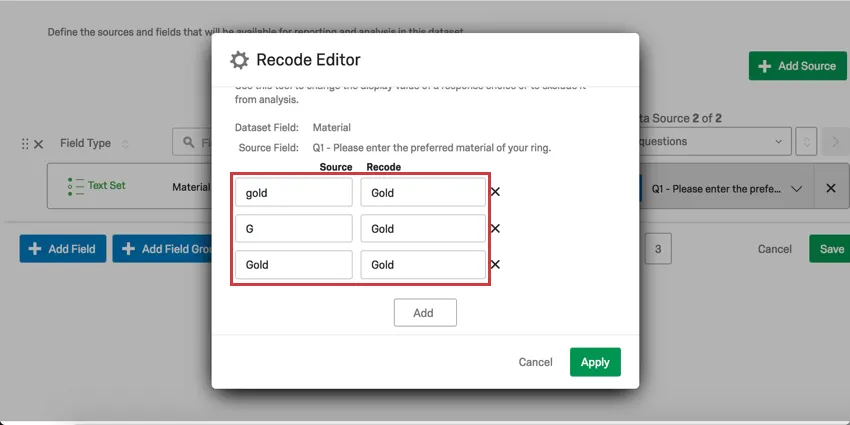
また、埋め込みデータフィールドの識別値を “G”、”S”、”P “と割り当てていた場合は、”Gold”、”Silver”、”Platinum “と割り当てて、ユーザーにわかりやすくすることもできます。
{kind=link}
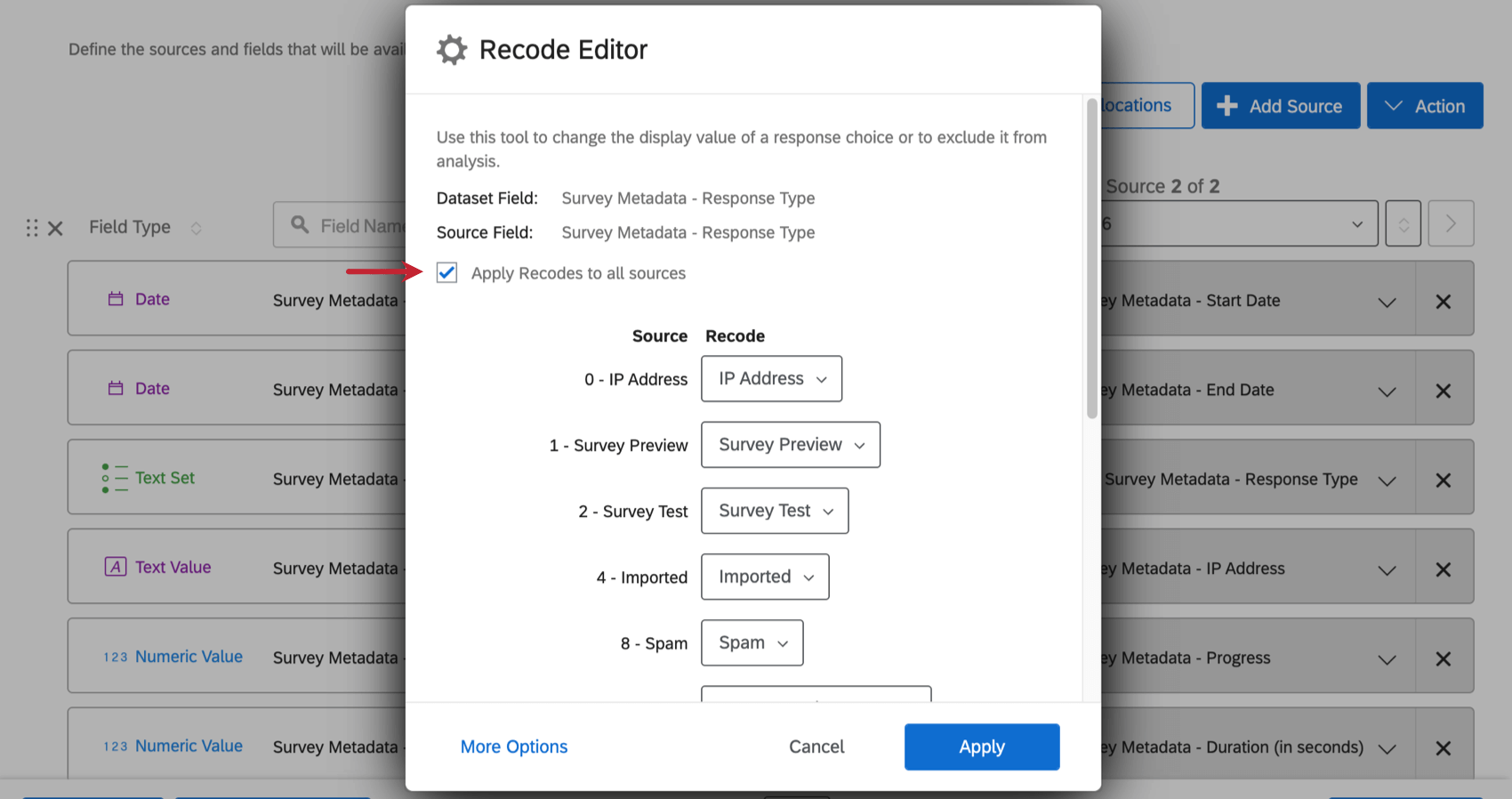
すべてのソースにリコードを適用
あるタイプのフィールドの識別値を割り当てて編集しているときに、ダッシュボードに複数のソースを追加した場合、すべてのソースにわたって同じフィールドに変更を簡単に適用することができます。変更を保存する前に、すべてのソースに適用を 選択します。
{kind=link}

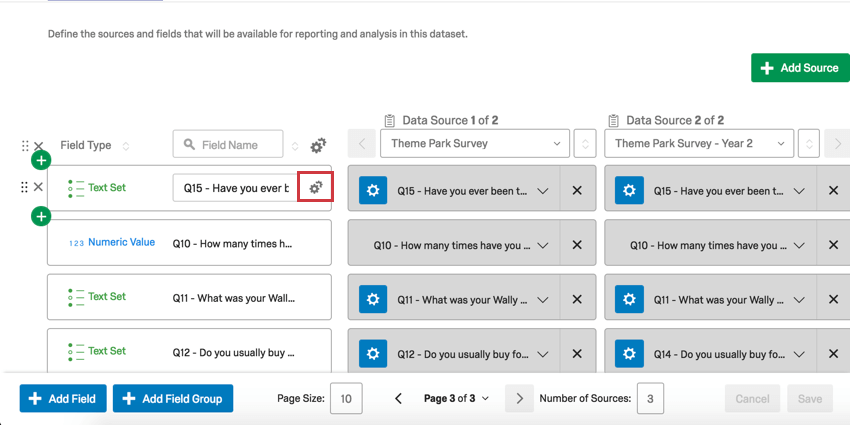
マッピングと記録エディター
ダッシュボードに複数のソースを追加した場合、複数のソース間で同じフィールドをマッピングするのがより簡単になる、追加のリコードエディタがあります。
{kind=link}
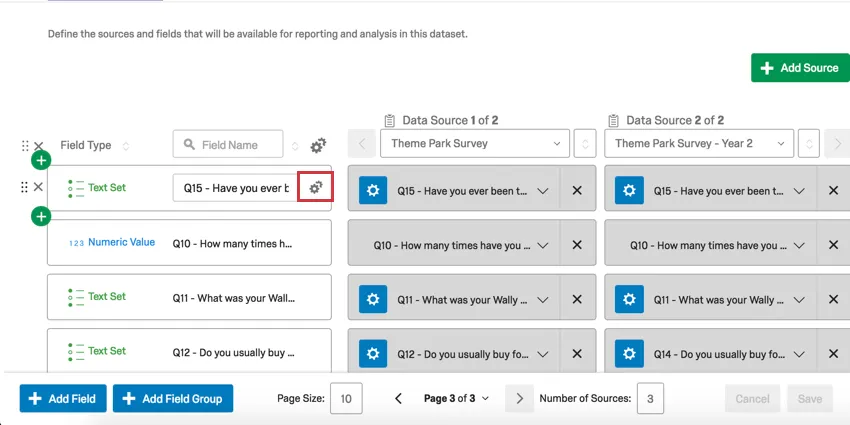
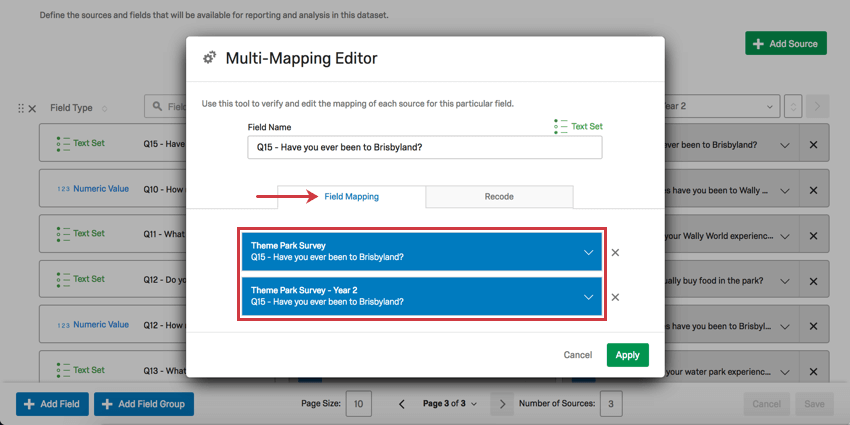
フィールドマッピング・タブ
青いドロップダウンを使用して、同じダッシュボードフィールドに対応するフィールドを各ソースから選択できます。
{kind=link}
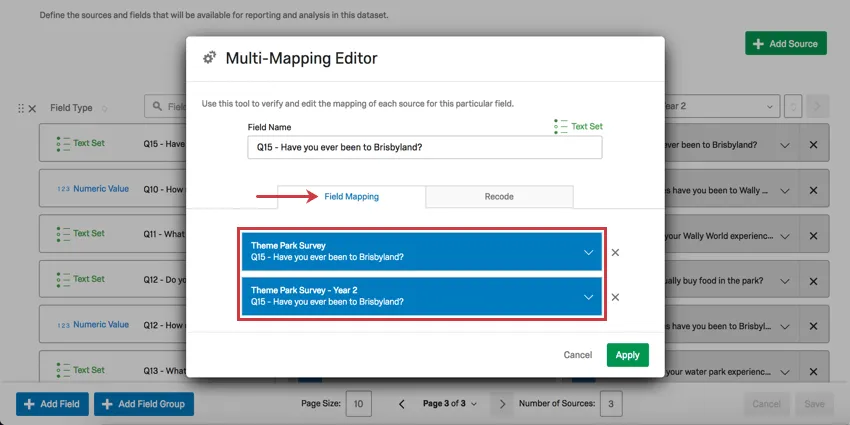
Qtip:Xをクリックするとマッピングが削除されます。
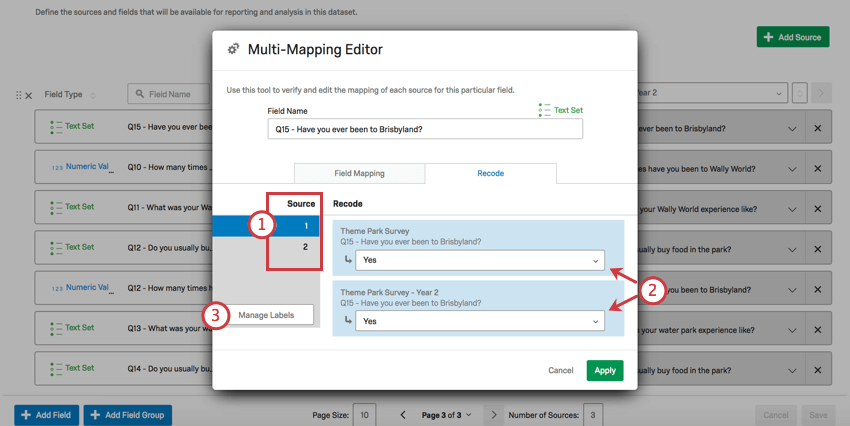
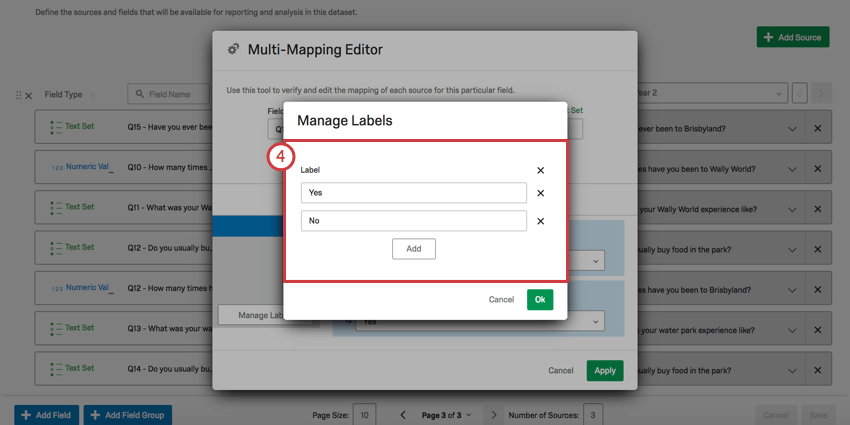
リコード・タブ
ここで、マッピングされる各フィールドの識別値を同じにすることができる。
FAQs
CX Dashboardsのrecode editorを使用して、回答の選択肢をグループ化するにはどうすればよいですか?
CX Dashboardsのrecode editorを使用して、回答の選択肢をグループ化するにはどうすればよいですか?
回答の選択肢をグループ化する手順については、 Recoding Dashboard Fields サポートページをご覧ください。
CXダッシュボードで回答の選択肢を変更するために、リコードエディタを使用するにはどうすればよいですか?
CXダッシュボードで回答の選択肢を変更するために、リコードエディタを使用するにはどうすればよいですか?
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!