感情分析
このページの内容
意見分析を有効化
クアルトリクスは、回答テキストがTEXT iQに読み込まれるとすぐに、回答テキストに「非常に否定的」、「否定的」、「中立」、「肯定的」、「非常に肯定的」、または「混合」の感情を割り当てます。この感情は、回答文と質問文の言語に基づいている。TEXT iQモデルは、大規模で多様性のある実エクスペリエンスデータセットでトレーニングされ、分類品質を大幅に向上させ、感情がそれほど強く表現されない場合の不確実性を最小限に抑えます。感情が割り当てられると、感情スコアと呼ばれる数値スコアが付きます。
感情ラベルとスコアは、データのフィルターに使用したり、「レポート」タブのビジュアライゼーションに表示することができます。
Qtip:感情分析は、Advanced Textクライアントのみご利用いただけます。
Qtip:テキストiQ分析で感情やトピックに基づいて分岐したい場合は、テキストiQ搭載のアンケート調査フローをご覧ください。
感情機能
非常に否定的」および「非常に肯定的」の感情ラベルは、最も強い感情を示し、各コメントの最も重要なフィードバックに焦点を当てるのに役立ちます。中立感情は、どちらの方向にも強い感情を示さない。感情が混在しているということは、ポジティブな感情とネガティブな感情が混在しているということだ。
ほとんどのテキストiq分析では、センチメントは回答者の回答に基づいて評価されますが、質問文自体は通常、回答のセンチメントとは関係ありません(「なぜそのスコアをつけたのか」など)。しかし、時には質問のフレーミングが、回答に対する感情を暗示することもある(例えば、”What’s one thing we could improve about our product?”)。このような場合、Text iqは正確な感情予測を行うために質問と回答の両方を必要とします。例えば、「当社のどこが好きですか」という質問だった場合、回答が明確に否定的でない限り(例えば、「何もない、御社は嫌いです」)、回答文単体では中立的に見えても(例えば、「価格設定」)、回答の感情はおそらく肯定的です。この感情分析のアップデートでは、予測される感情が可能な限り正確になるように、質問文がある場合は感情分析に組み込みます。
Qtip: CxダッシュボードでText iQを使用する場合、質問文の代わりにフィールド名が使用されます。一貫性を保つために、ダッシュボードを設定する際に、フィールド名と質問文が一致していることを確認することをお勧めします。
このモデルは、今後より良い感情を割り当てる方法を学習するために、感情の編集もアカウントに取り込むようになりました。ただし、これらの編集が直ちにアカウントのプロジェクトの感情割り当てに影響するわけではないことに注意してください。代わりに、これらの編集はクアルトリクス全ユーザーで定期的に分析され、感情分析モデル全体の改善に使用されます。
総合感情 vs. トピックに対する感情
トピック感情とは、テキスト回答の特定のトピックの感情スコアです。各トピックには独自のスコアが割り当てられるため、回答は複数のトピック感情スコアを持つことができます。トピック感情は、クエリに一致する回答部分を分離し、その個々の部分の感情を決定することによって計算されます。
総合感情とは、ある回答に対する感情スコアです。Text iQで分析されたすべての回答は、1つの総合感情スコアしか持ちません。
トピック感情とは、テキスト回答の特定のトピックの感情スコアです。各トピックには独自のスコアが割り当てられるため、回答は複数のトピック感情スコアを持つことができます。クエリがないトピックでは、トピック感情はデフォルトで全体的な感情になります。
Qtip:全体の感情と回答のトピックの感情の両方を編集することができます。詳しくは「感情の表示と変更」をお読みください。
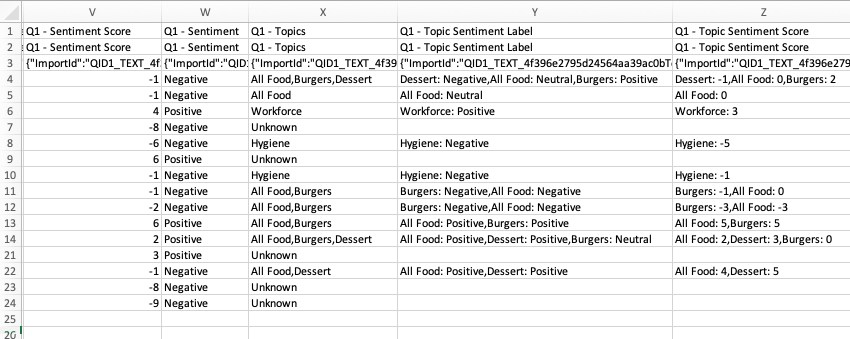
例: 例えば、”サービスも料理も素晴らしかったが、すべてが非常に割高だった “というアンケート調査の回答があったとします。この回答が「サービス」、「食事」、「価格」のトピックでタグ付けされている場合、各トピックのトピック感情は「サービス=ポジティブ」、「食事=ポジティブ」、「価格=ネガティブ」となります。ほとんどの回答がポジティブであったため、全体的な感情はポジティブである。
全体的な感情、全体的な感情スコア、トピックレベルの感情、およびトピックレベルの感情スコアは、回答エクスポートに含まれます。全体的な感情は、”感情 “と “スコアリング “として表示される。トピックレベルには、”トピック感情ラベル “と “トピック感情スコア “が付けられている。トピックレベルのフィールドは複数の値を持つことができ (複数のトピックをアカウントするため)、Topic:感情。例:デザート:否定的。回答輸出にもトピックが含まれている。
{kind=link}

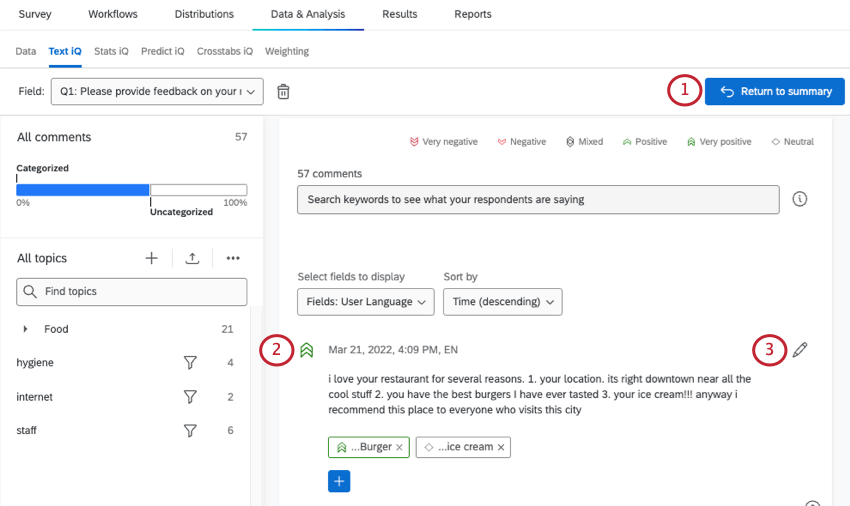
感情の見方と変化
-
2つの赤い下向き矢印: 非常にネガティブ

-
1つの赤い下向き矢印: ネガティブ

-
重なり合うグレーのダイヤモンド: 混合だ。
-
緑の上向き矢印1本: ポジティブ
-
2つの緑の上向き矢印: 非常にポジティブ

-
灰色のダイヤモンド: どちらでもない
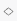
Qtip:あなたは回答全体の「コメント全体の感情」を編集していることに注意してください。
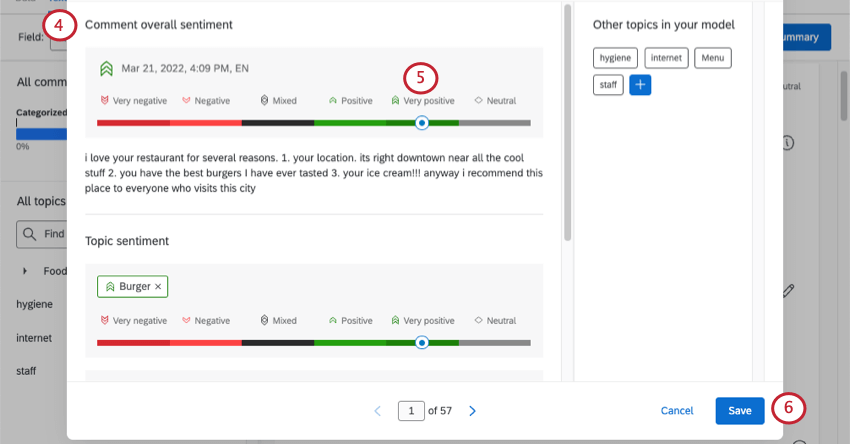
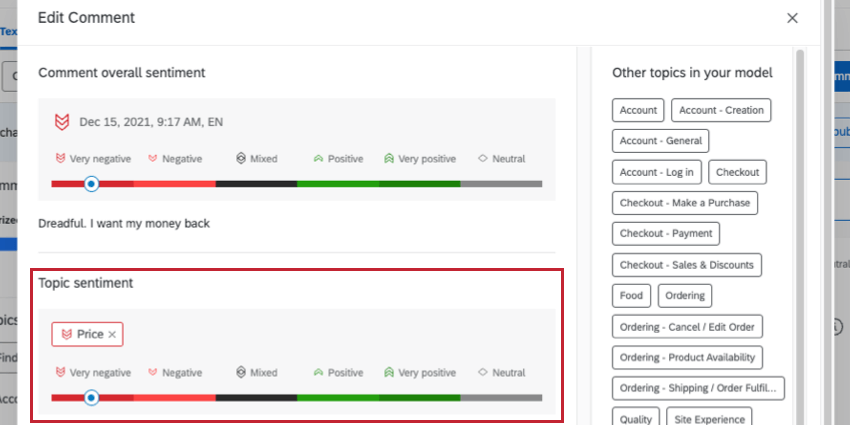
トピックに対する感情
トピックの感情] を選択すると、回答にタグ付けされた各トピックの感情を指定できます。これは、全体的な感情が混在している場合や、回答者が取り上げたトピックごとに感情の強さが異なる場合に特に役立ちます。
{kind=link}
各トピック名で感情とスコアリングを選択できます。
例: 例えば、ある回答者はレストランの料理は好きだが、店員は酷使されていると考えているかもしれません。そのため、「すべての料理」というトピックは肯定的な感情を持っていますが、「労働力」というトピックはそうではありません。この2つの感情が互いに影響し合っているため、全体的な感情は複雑である。
{kind=link}

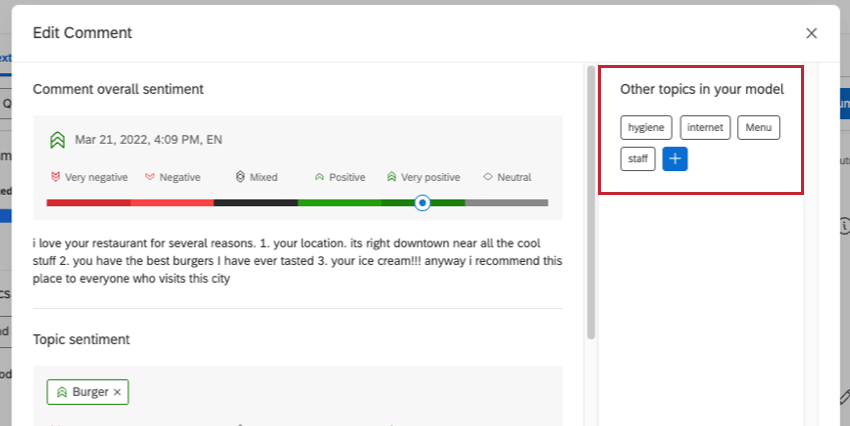
モデルの [その他のトピック] では、トピックタグと感情を回答に直接追加するオプションもあります。提案されたトピックをクリックするか、青いプラス (+ ) 記号を使用して独自のトピックを作成します。
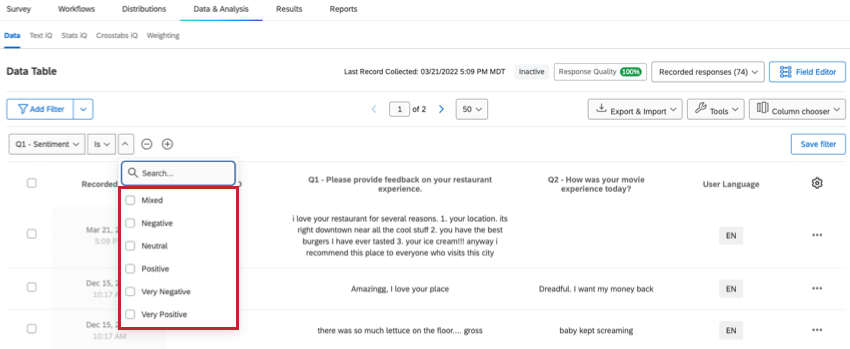
感情によるフィルタリング
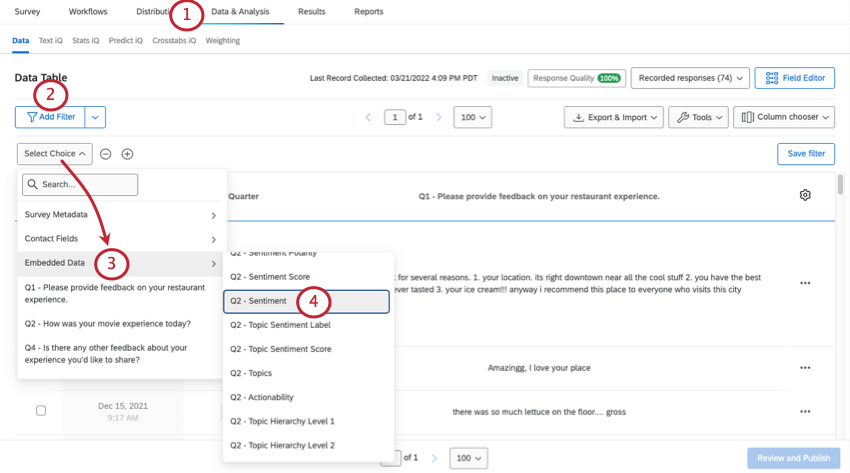
感情スコア
肯定的、否定的、混合的、または中立的なコメントにラベルを付けることに加えて、それぞれの感情に数値が割り当てられます。
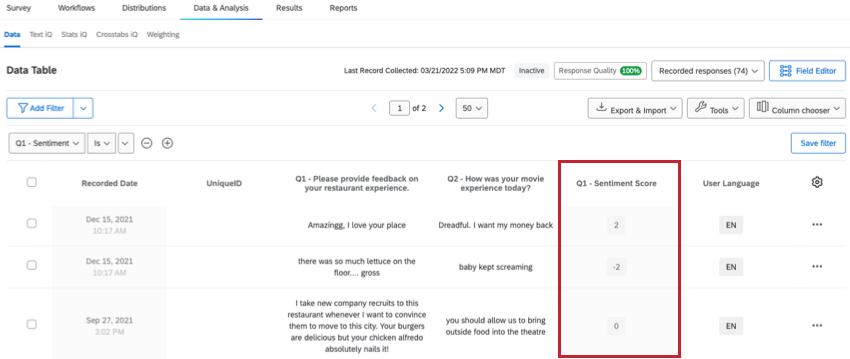
感情スコアは、コメントの感情を-2~+2のスコアリングで表します。例えば、”I love LOVE YOUR COMPANY!”のような非常にポジティブな回答はスコアリング+2となります。御社を心から非難します!」といった非常に否定的な回答は-2点。中立的なコメントはスコアリング0。
感情スコアは、「データと分析」および「レポート」タブのフィールドに表示されます。ほとんどのテキスト分析変数と同様、埋め込みデータ・カテゴリーにあります。
{kind=link}

Qtip:もしまだなら、列選択ツールを使って、これらの変数をデータと分析タブに持ってきてください。
感情モデルのアップデート
クアルトリクスは、時間の経過とともに感情モデルの改良を行い、マイナーバージョンのアップデートをリリースしています。私たちは、感情予測精度の一貫性または向上を保証するために、これらの更新について集中的な品質保証を行っています。
新しいモデルのバージョンがリリースされると、TEXT iqの新しいコメントの分析にのみ使用されます。過去にTEXT iQが分析したコメントは、新モデルのリリースに伴って更新されることはありません。
PEDICT iQをプロジェクトやダッシュボードのコピーに適用すると、過去の回答に対する感情予測に違いが見られることがあります。これは、元のプロジェクトまたはダッシュボードの回答が分析された時点で、以前のバージョンの感情モデルが使用されていたためです。コピーされたプロジェクトまたはダッシュボードでは、感情予測は現在のモデルを使用して再計算されます。
多言語感情分析
他の言語での感情分析は、感情分析を持っているすべてのユーザー、つまりすべてのAdvanced Textクライアントが利用できます。
クアルトリクスの感情モデルは、最新のディープラーニング技術を活用したトランスフォーマーベースのクロスリンガルモデルです。私たちのモデルは、英語、フランス語、スペイン語、ドイツ語、韓国語、イタリア語、オランダ語、日本語、ポルトガル語、繁体字中国語、簡体字中国語、ポーランド語、スウェーデン語、タイ語、インドネシア語、ロシア語に最適化されています。私たちのモデルはすべての言語の感情予測を行うことができますが、最適化された言語の予測と同じレベルの品質を保証することはできません。
感情分析モデルの育成方法については、こちらのブログ記事をご覧ください。
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!