Stats iQの概要
このページの内容
注意: Stats iQは、標準のクアルトリクスライセンスに含まれていないアドオン機能です。Stats iQセクションがない場合は、クアルトリクスの営業担当に詳細をお問い合わせください。Stats iQへのアクセス権があるかどうかを知りたい場合は、ブランド管理者に連絡先があります。適切な権限が付与されている場合、Stats iQを有効化するためにAPIトークンを生成する必要があります。
注意: デフォルトでは、ブランド管理者は、StatsiQ – Individual UserおよびUse Crosstabs – Individual User の権限をユーザータイプレベルで無効にしています。ブランド管理者は、Stats iQまたはクロス集計を利用する各ブランド管理者に対して、これらの権限を手動で有効にする必要があります。高度なパーミッションの詳細については、ここをクリックしてください。
Stats iQの紹介
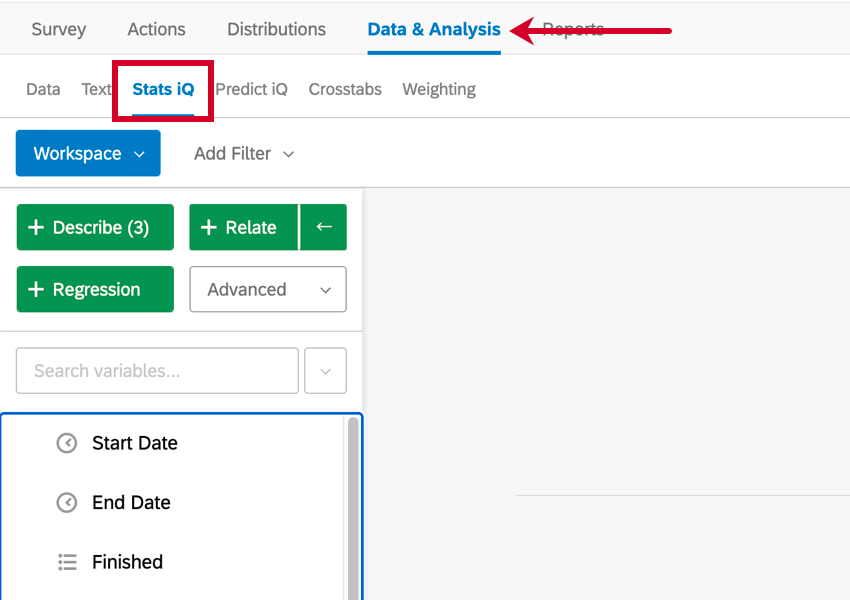
Stats iQを使い始めるには、クアルトリクスにデータセットをアップロードするか、実行中のプロジェクトを開き、「データと分析」タブでStats iQを選択します。
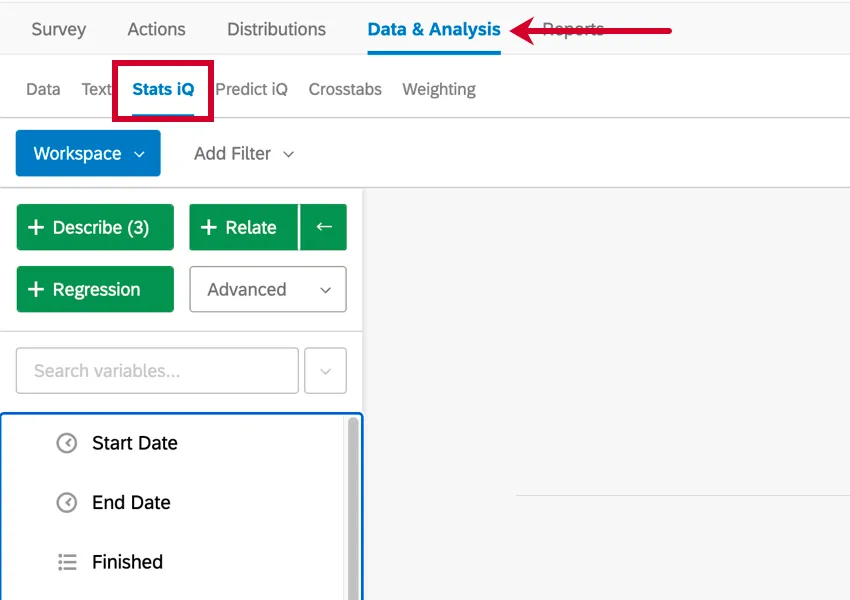
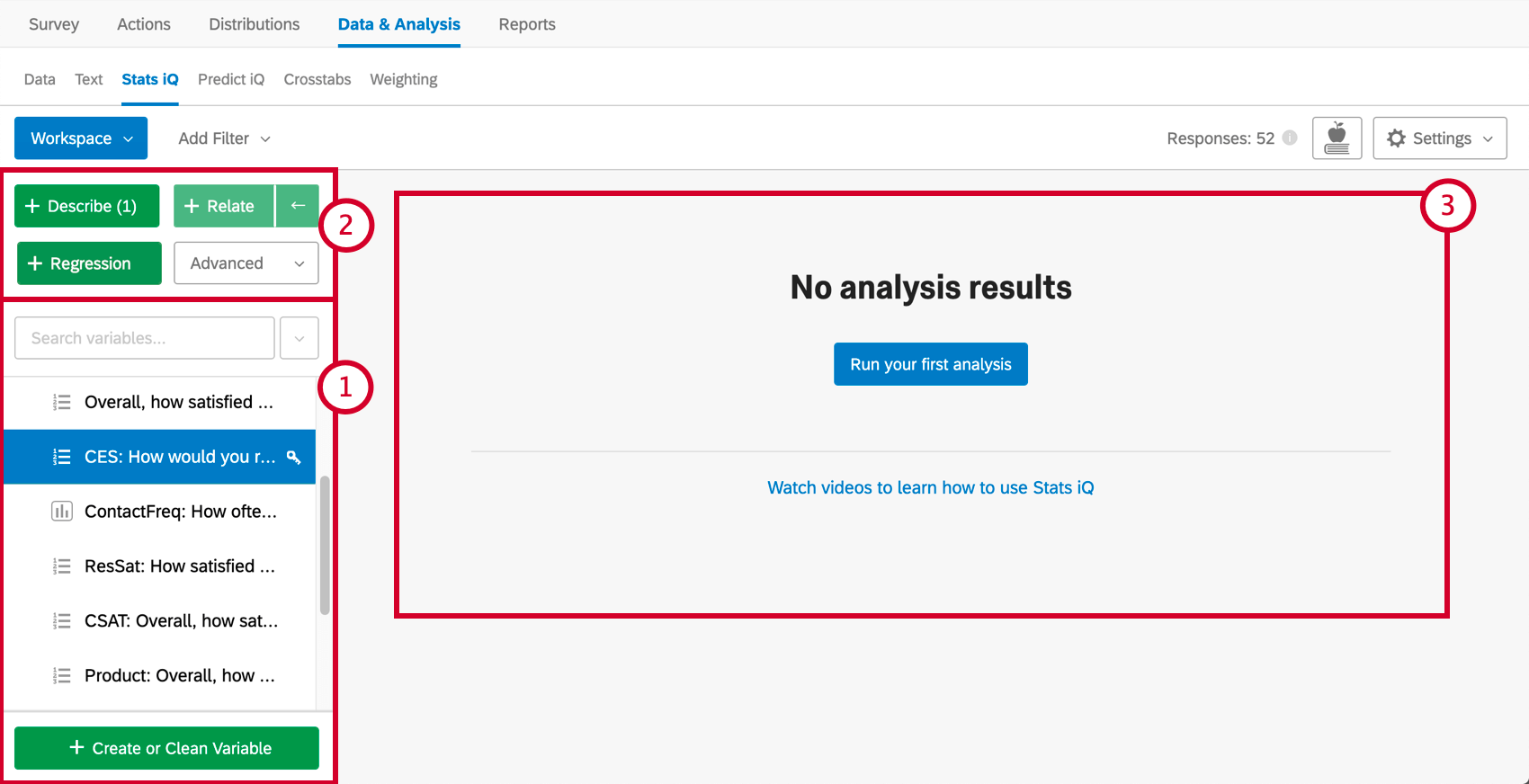
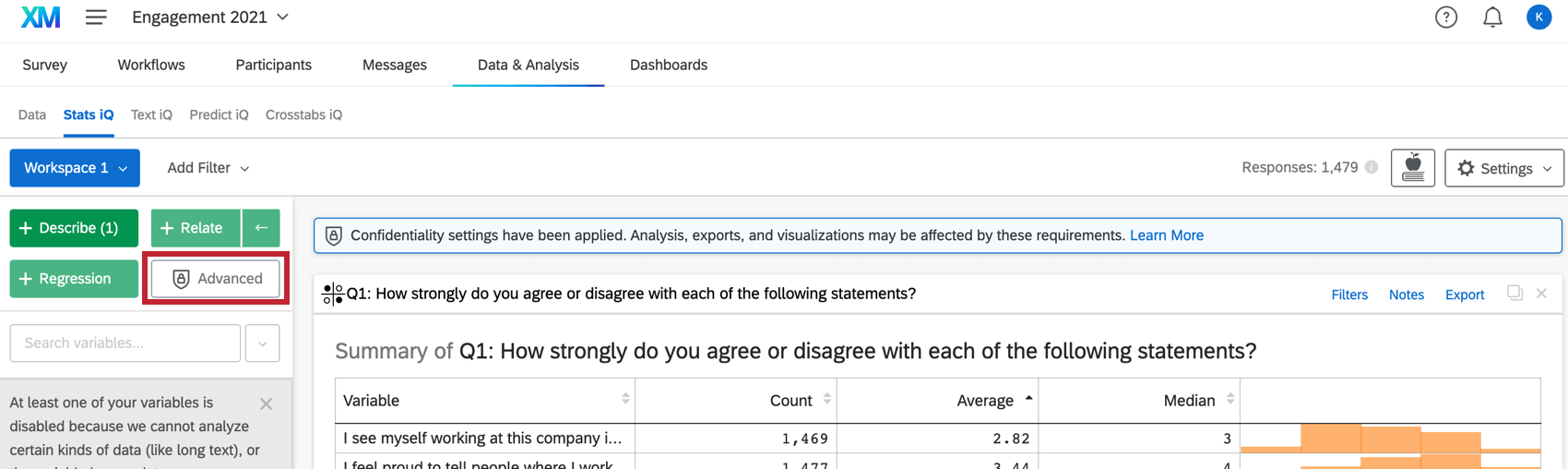
Stats iqには3つの主要な部分があり、下のスクリーンショットでは番号が振られている:
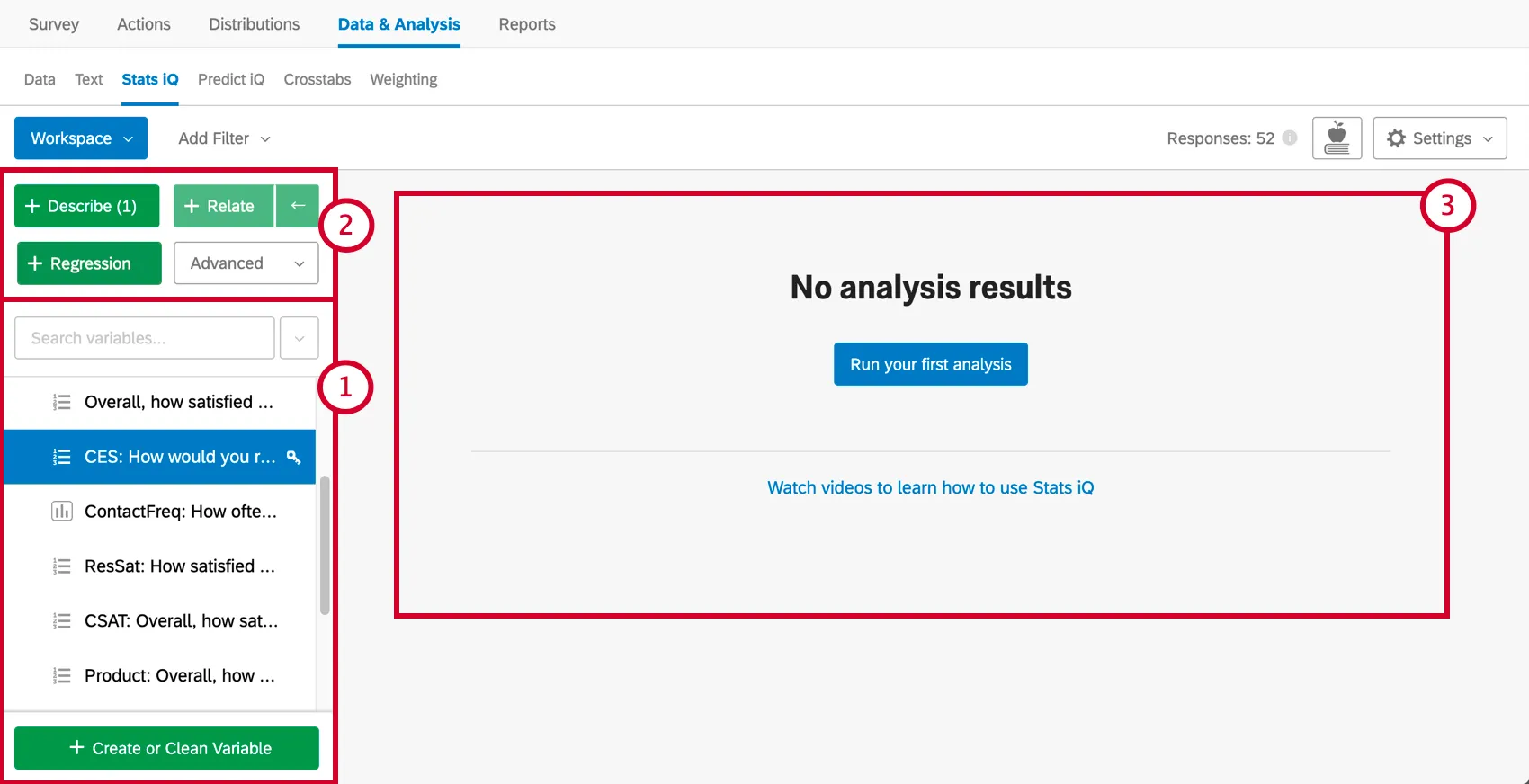
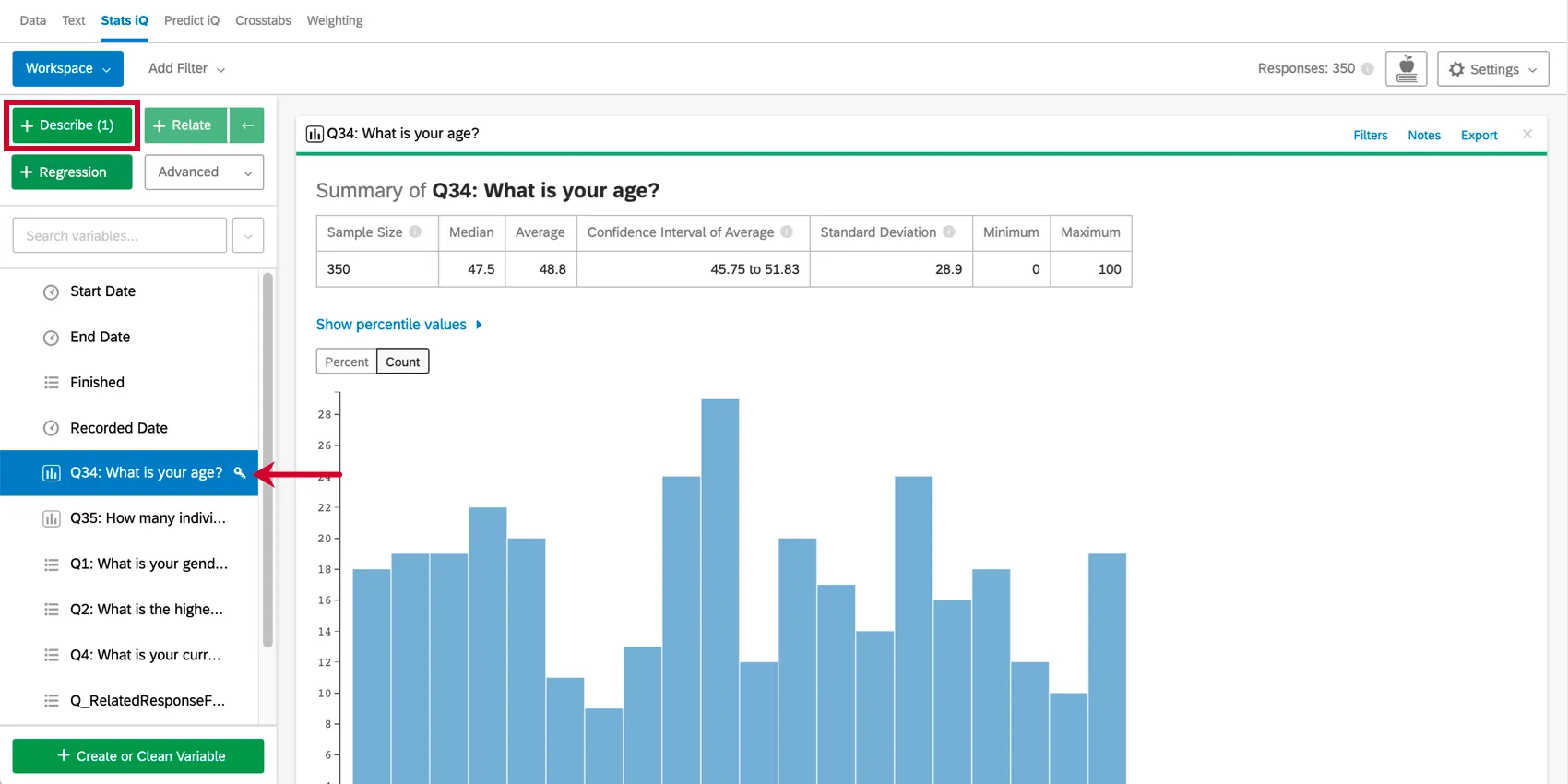
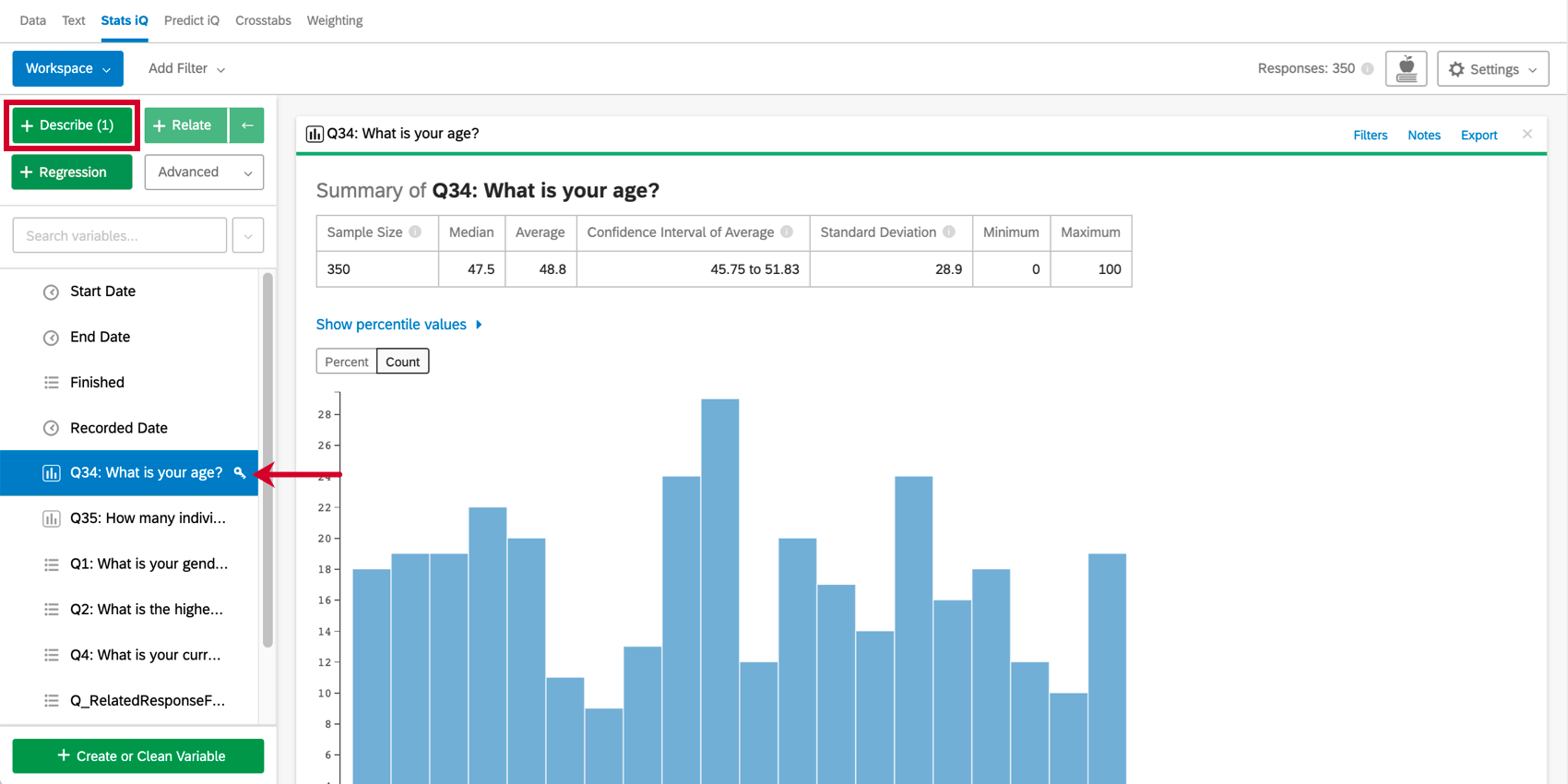
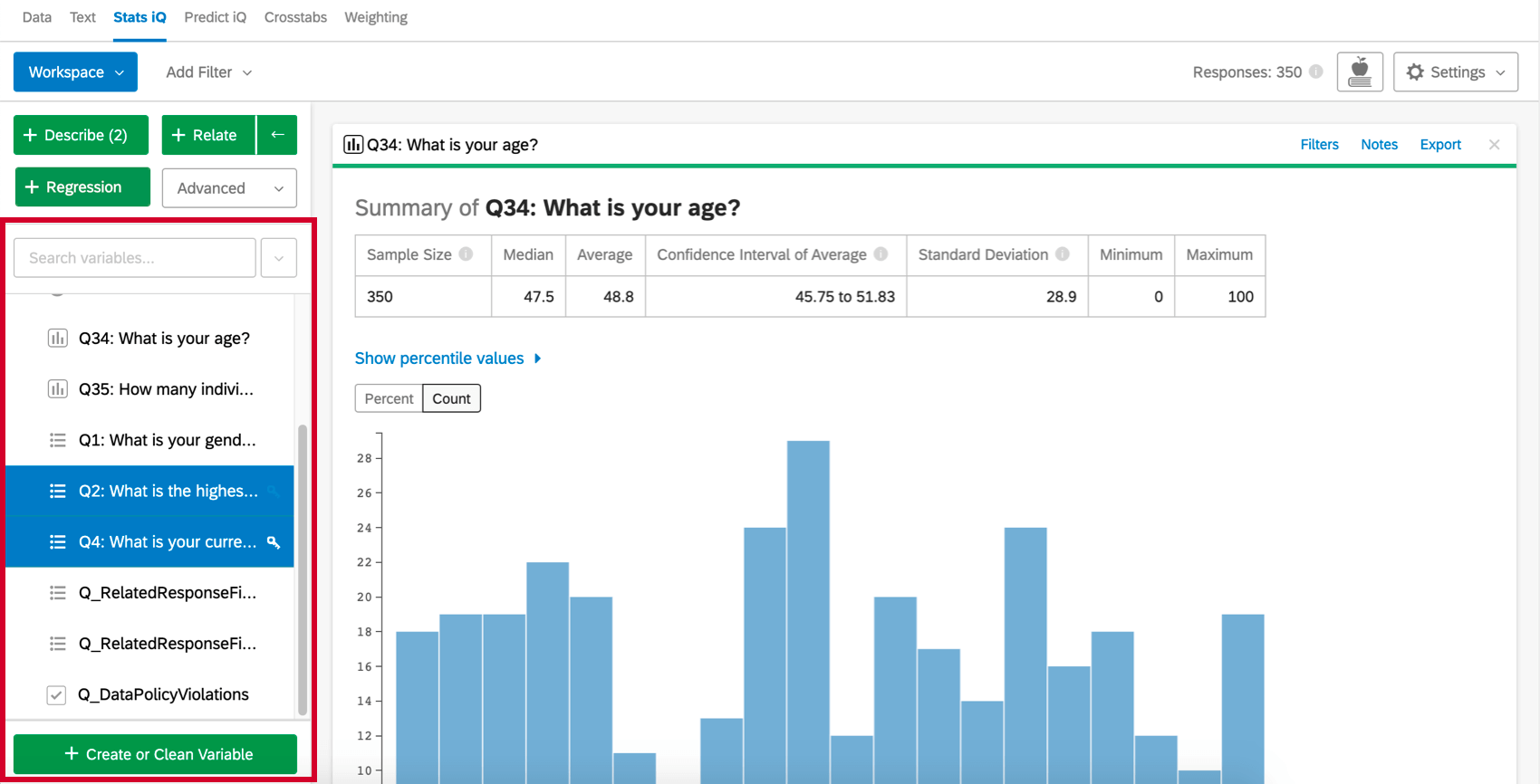
変数を要約するには、それを選択し、Describeを押す。これは数値なので、中央値や平均値などの情報が与えられる。変数タイプによって記述方法は異なる。
Qtip:複数の変数を選択してDescribeを押すと、それぞれの要約を得ることができる。
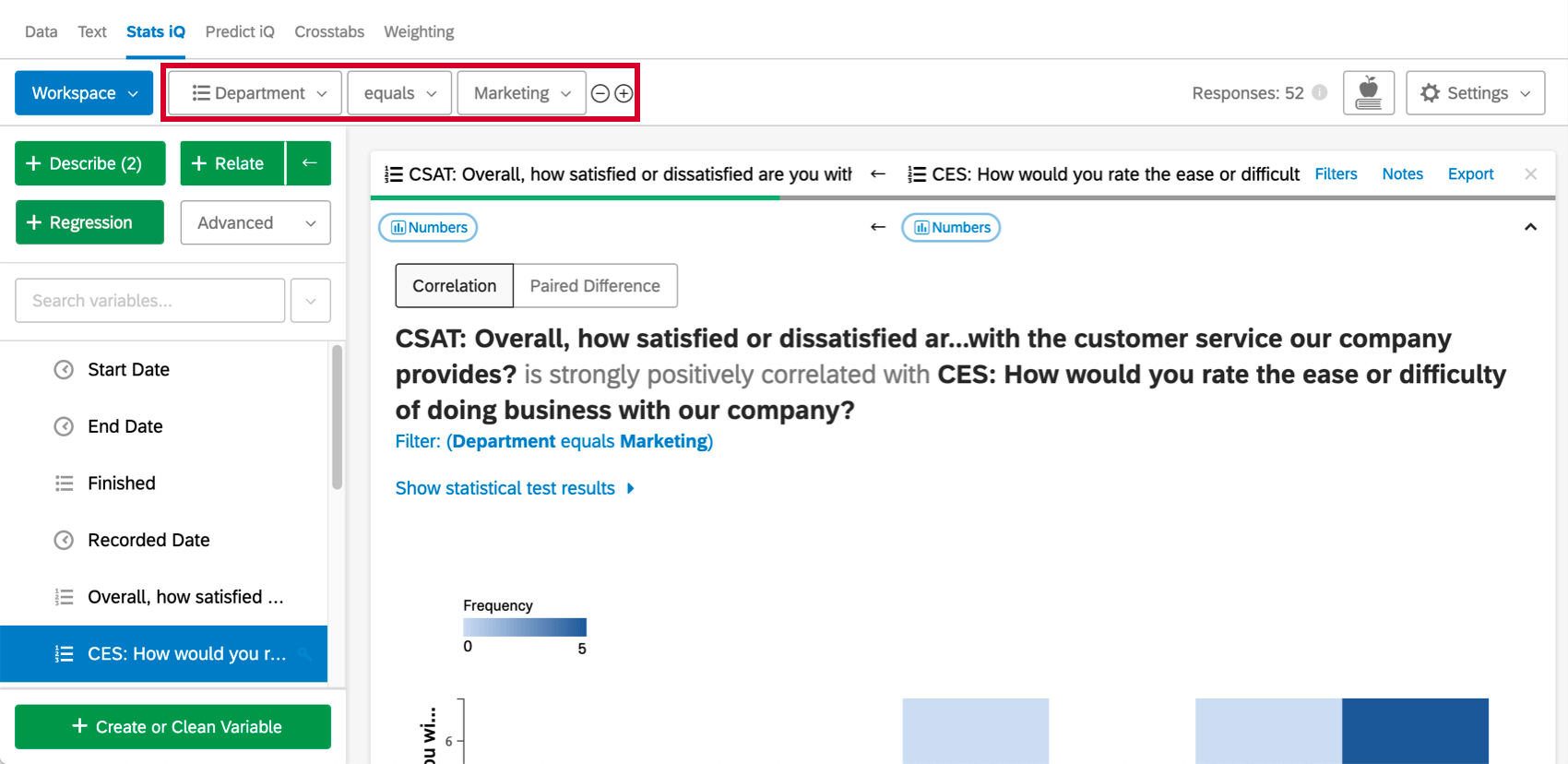
一方、Relateは、2つの変数の関係を決定することができる分析の1つです。Stats iqでは、これらの変数がどのように関係しているのか、もし関係しているのであれば、それを説明する。

多くの変数を選択して、1つのキー変数に関連付ける。Stats iQは、これらの関係に基づく一連の仮説を提供します。
Qtip:このイントロダクションは変数の記述と関連付けに焦点をあてていますが、利用可能な他の分析にもっと深く潜ることもできます。
ワークスペースの上部には、分析ニーズに合わせてデータを絞り込むためのフィルターを追加できます。
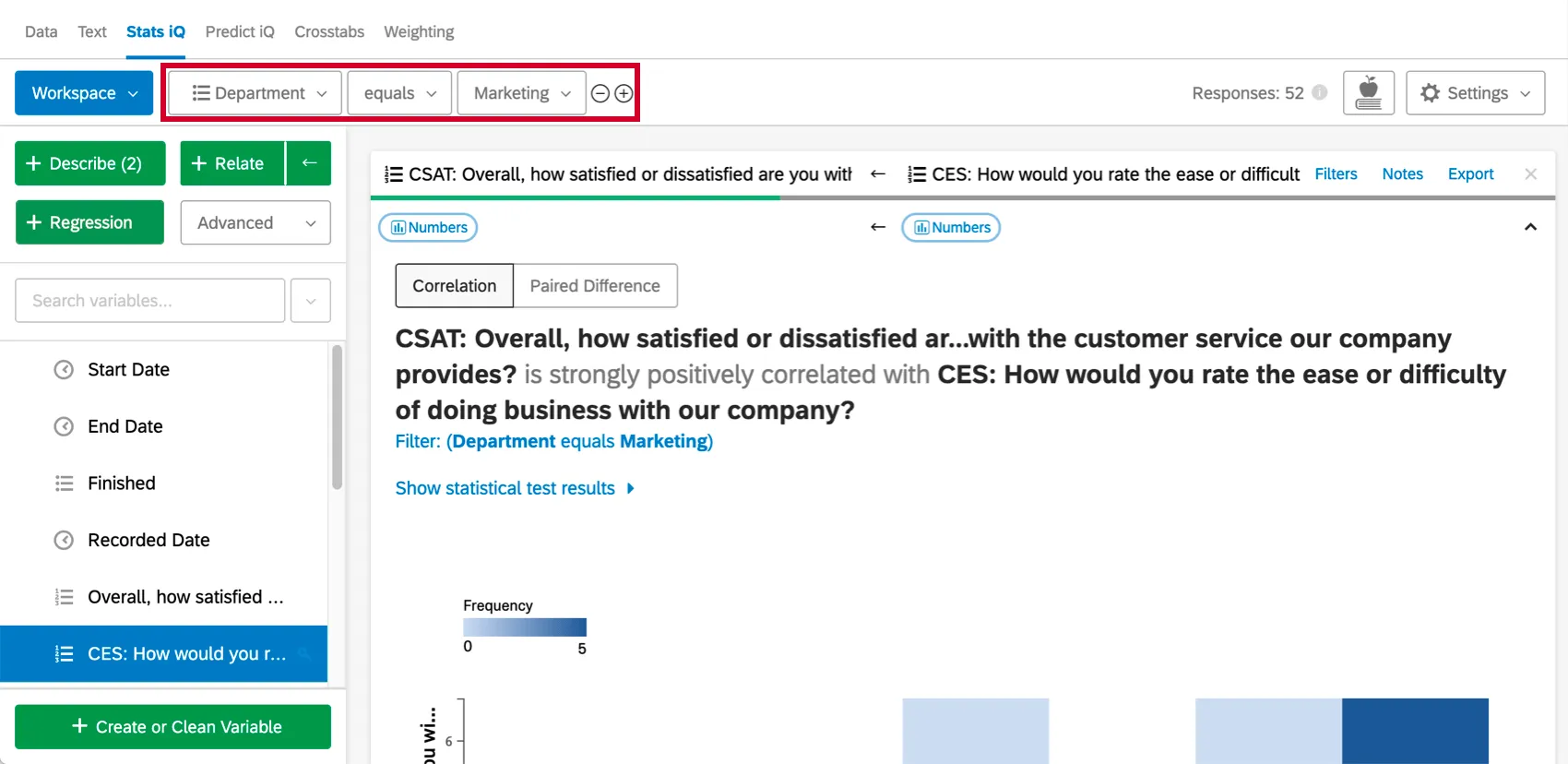
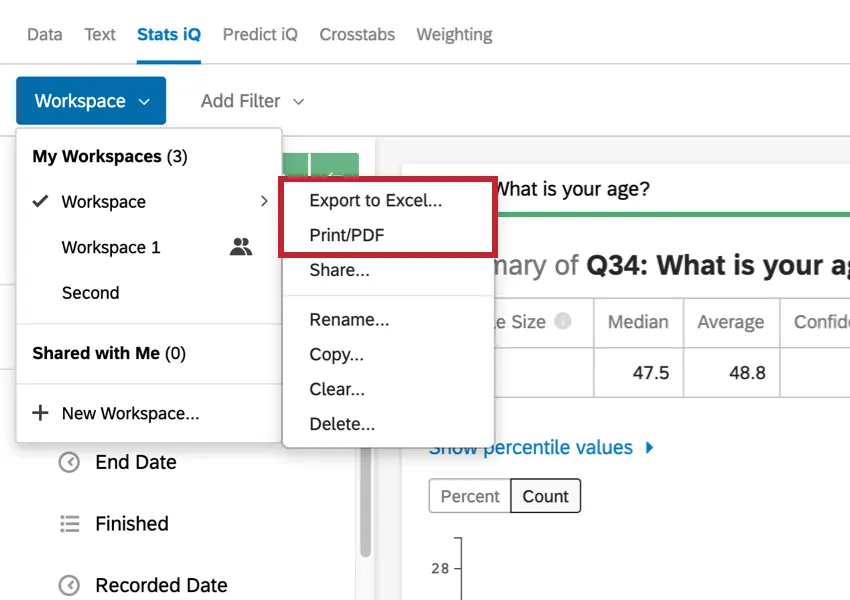
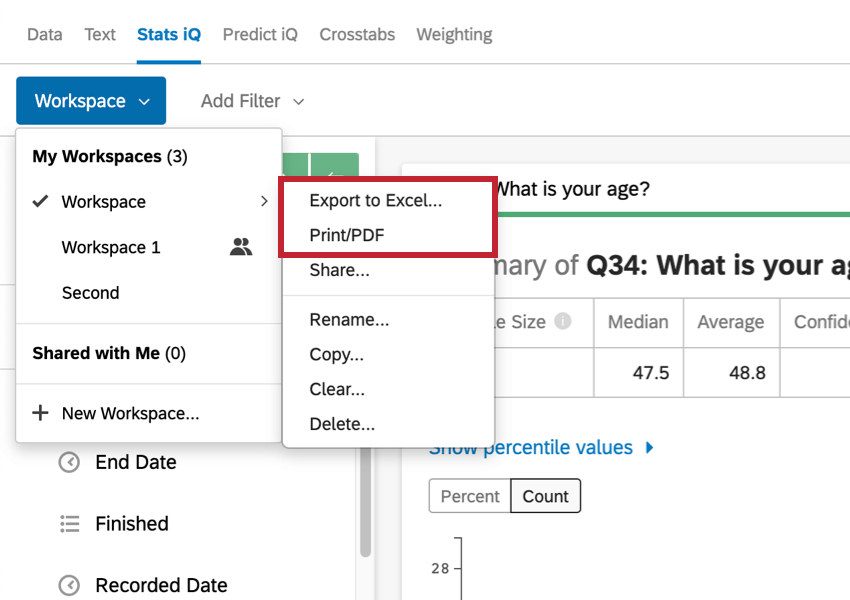
結果をエクスポートする準備ができたら、ワークスペースをExcelにエクスポートするか、PDFに保存して印刷することができます。
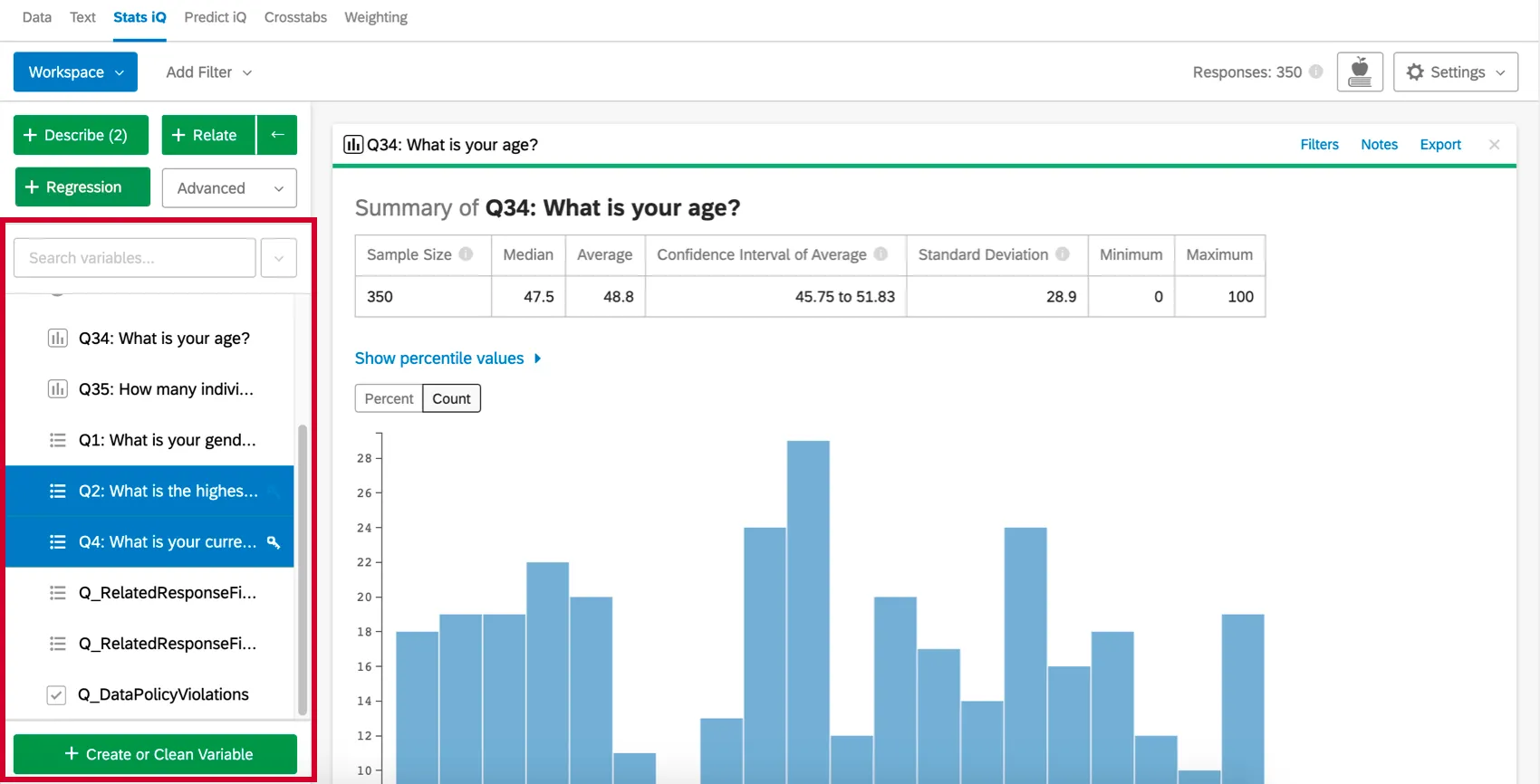
変数の選択
ワークスペース左側の変数ペインには、アンケート調査のすべての質問が入力され、これらは “変数” と呼ばれます。
変数ペインの上部にある検索ボックスで、データセットから特定の変数を検索できる。検索ボックスの右側にあるドロップダウンメニューをクリックすると、変数タイプ別に選択したり、データセット内のすべての変数を選択/選択解除することができる。
分析する1つ以上の変数を選択して開始します。
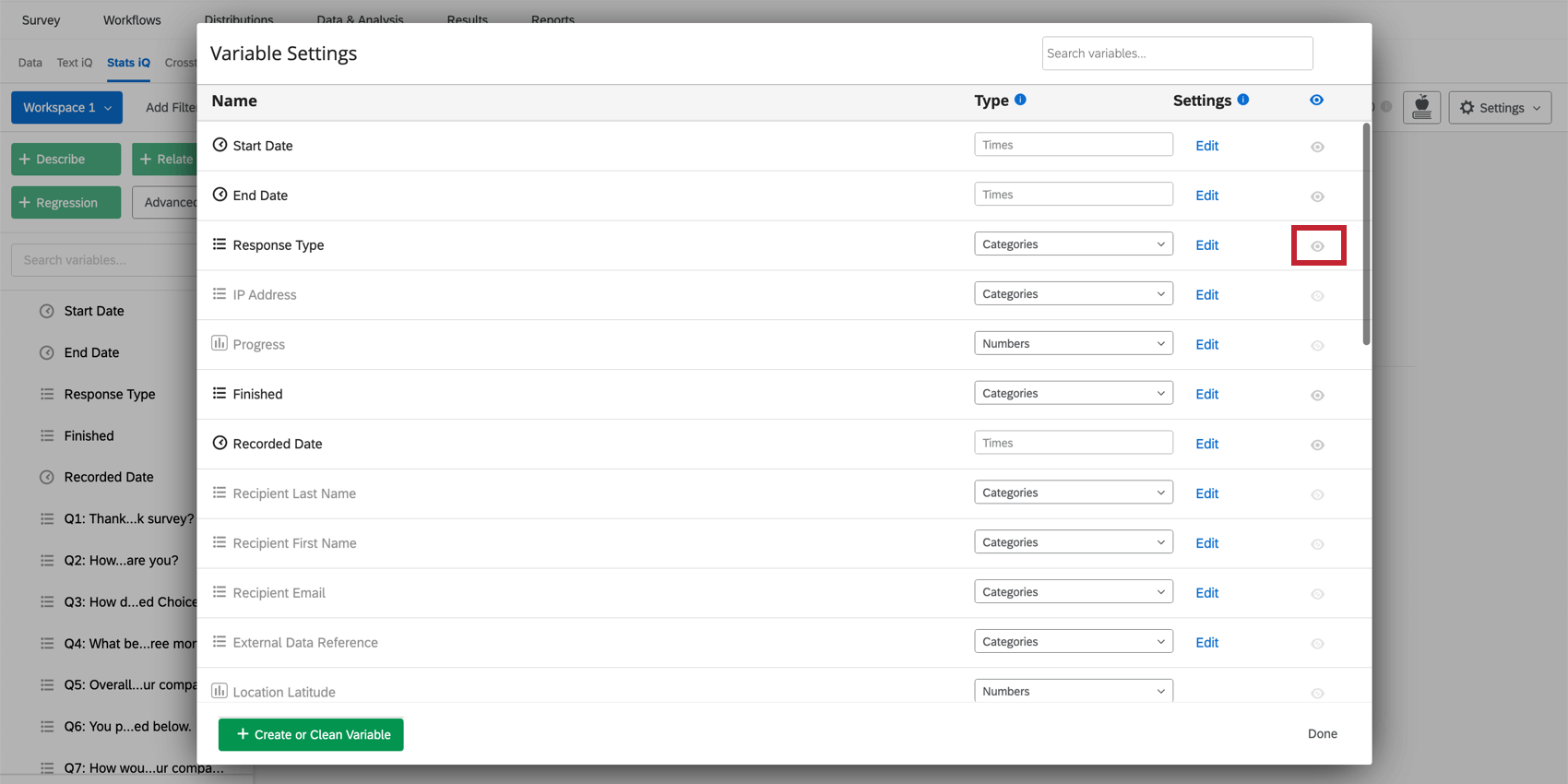
Qtip: お探しの変数が見つかりませんか?変数を変数ペインから隠すことができる。利用可能なすべての変数のリストを見るには、変数設定に向かい、目のアイコンが有効になっていることを確認する。

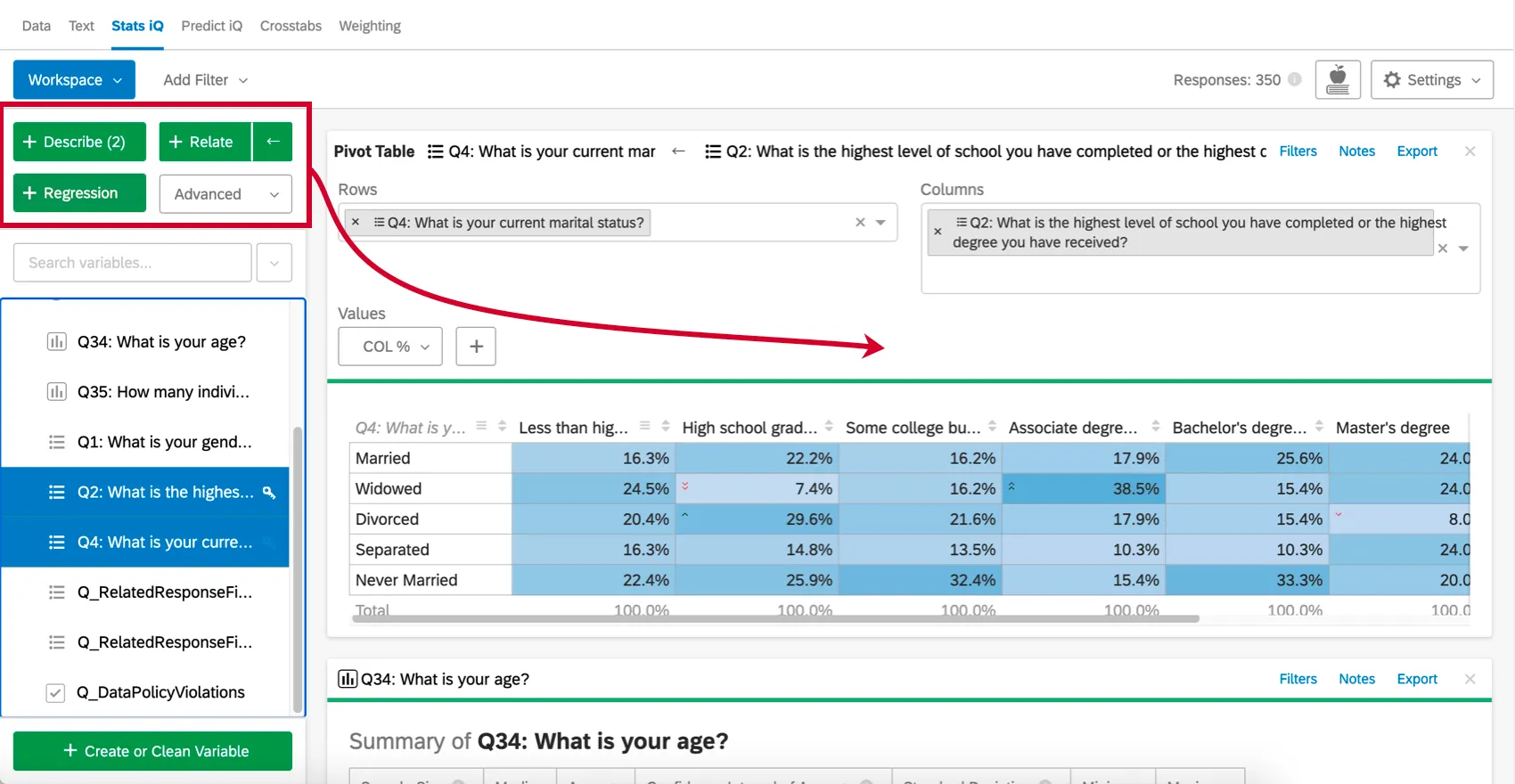
分析を実行する
変数を選択したら、4つの分析ボタン (記述、関連、回帰、 または ピボットテーブル) をクリックして、ワークスペースに新しい分析カードを作成します。
分析を実行したことがある場合、新しい分析は古い分析の上に表示されます。
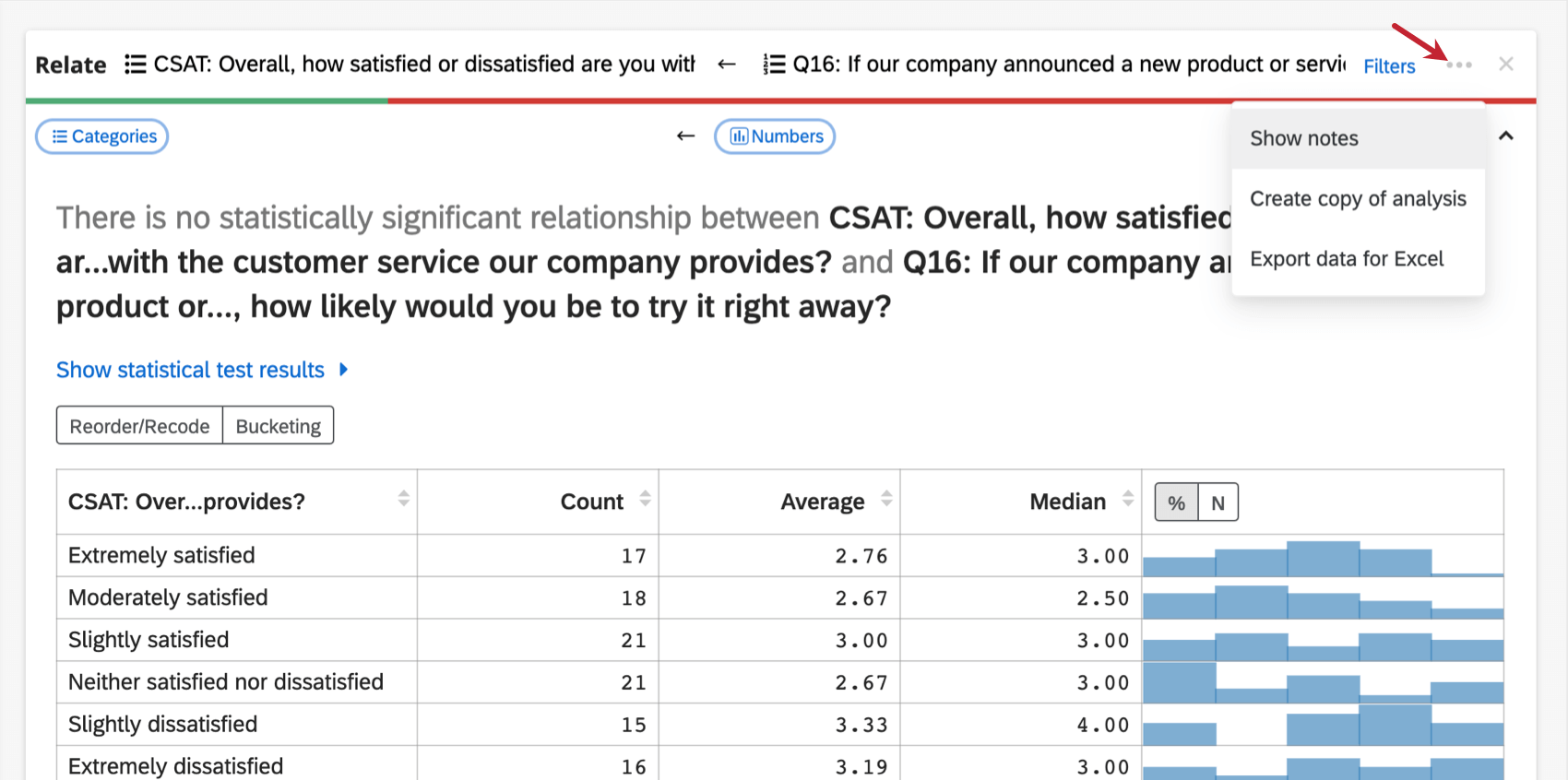
カードが作成されると、上部にボタンが表示され、その下にいくつかのオプションが表示されます。
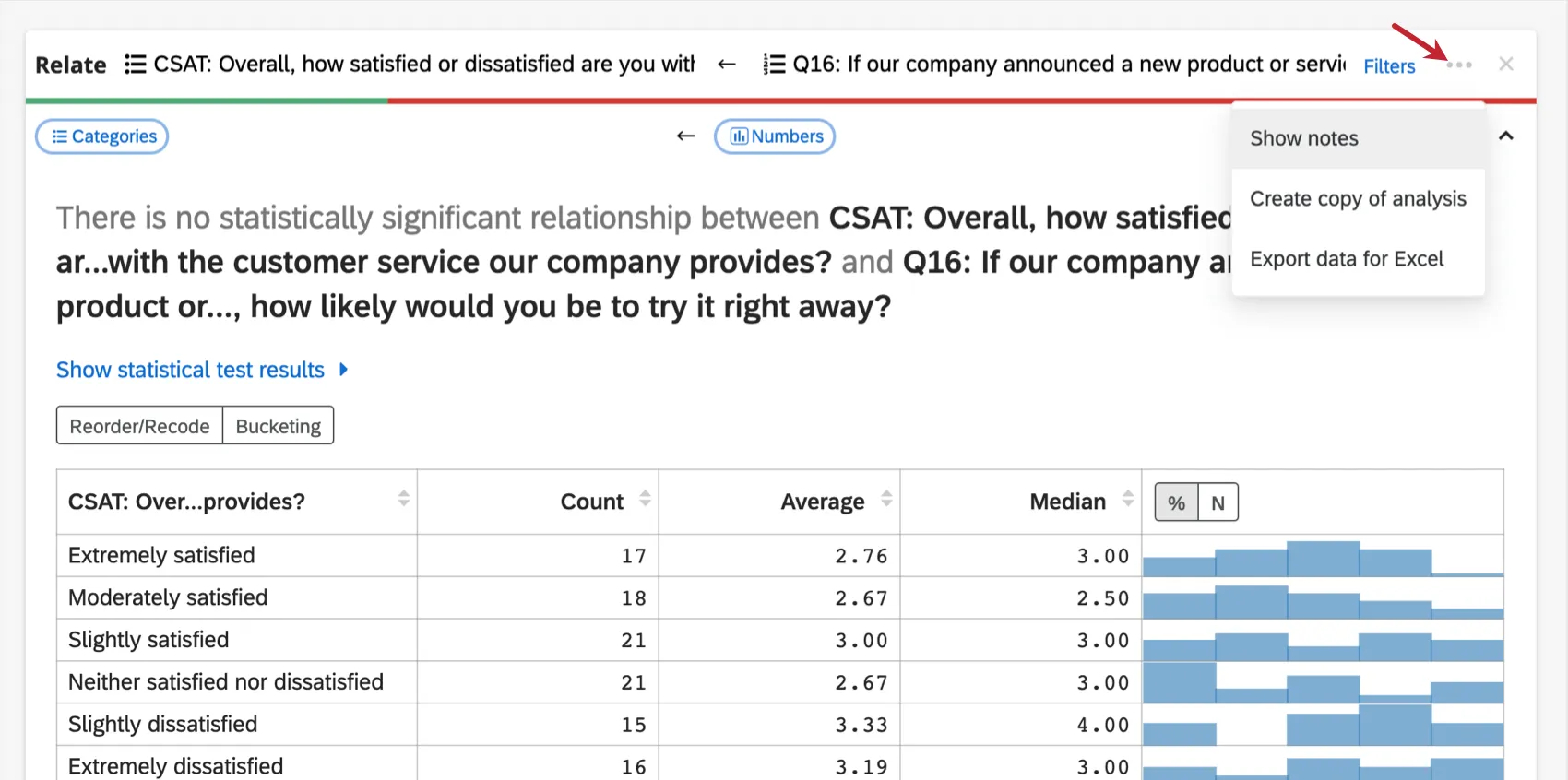
- ノートを表示する:分析のメモを入力するフィールドタイプが表示されます。メモは自動的に保存されます。ノートを再び非表示にするには、オプションボタンをクリックし、ノートを非表示にします。
- 分析のコピーを作成する:ワークスペースにある既存の分析カードをコピーします。複製されたカードは元のカードの上に表示されます。
- Excel用にデータをエクスポートします:データをExcelスプレッドシートにエクスポートします。これはXLSXファイルになります。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一般的な分析ワークフロー
Stats iQは、好みに合わせて使用できる柔軟なツールです。以下に、一般的な分析ワークフローの開始手順を示します。
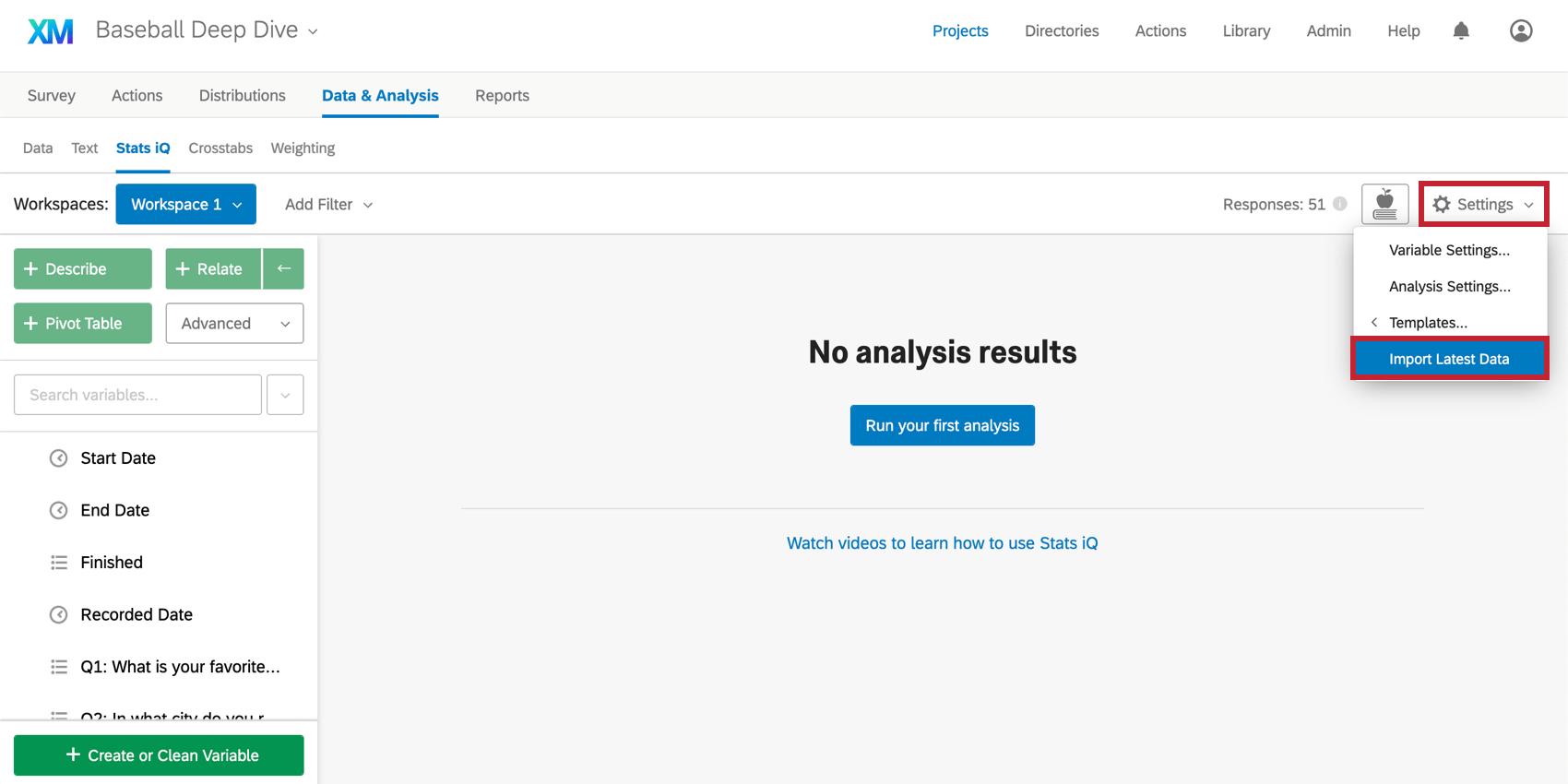
最新データのインポート
Stats iQへの初回アクセス時に、アンケートに対する現在の回答はすべてインポートされますが、その後さらに回答を収集する場合があります。これらの新しい回答をインポートするには、ワークスペース右上の[設定] メニューをクリックし、[ 最新データのインポート] を選択します。
{kind=link}
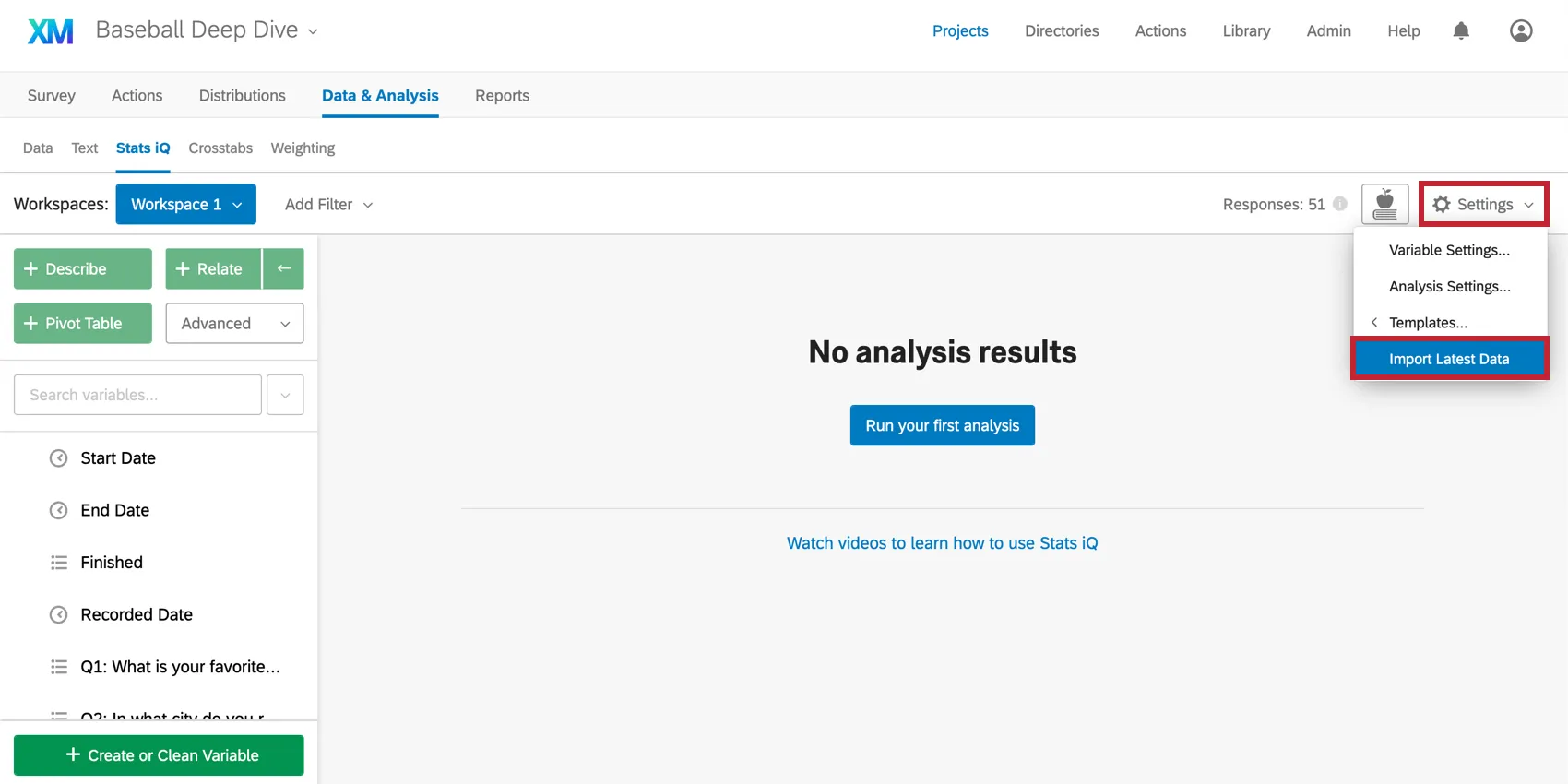
注意: Stats iQおよびクロス集計は、100万行を超えるデータセットのデータを自動的にインポートしません。このサイズのデータセットの場合は、[最新データのインポート]をクリックして、利用可能なデータの更新をワークスペースに取り込みます。
ワークスペース
ワークスペースは、スプレッドシートのタブのようなもので、関連する分析を保管するための独立したエリアだと考えてください。Stats iQを初めて開くと、空白のワークスペースが新規作成されます。
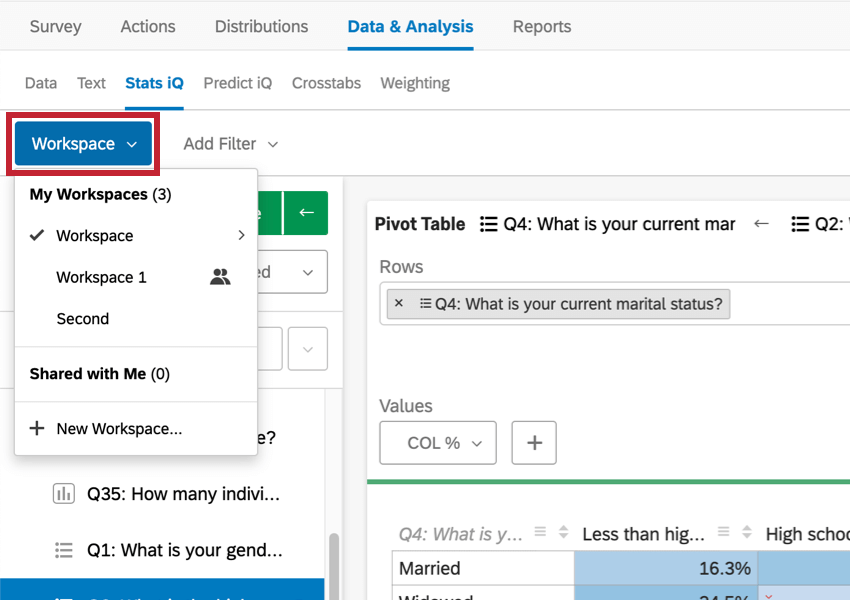
新しいワークスペースを作成したり、別のワークスペースに切り替えたり、現在のワークスペースの名前を変更、クリア、または削除するには、左上の青いボックス「ワークスペース1」をクリックします。
{kind=link}

Qtip:ワークスペースには750枚までカードを置くことができます。この制限に達した場合、新しいカードを作成しようとするとエラーが表示され、最も古いカードが削除されることを警告します。
変数タイプ
Stats iQで使用できる変数タイプは、次のとおりです。
- 数字:数値:10段階の尺度など、数値で構成されるデータ。
- カテゴリー:性別や政党などのカテゴリーに分類される値で構成されるデータ。
- タイミング:年(2010年)、日付(1984年1月27日)、タイムスタンプ(2014年4月7日19時8分)、継続時間(3時9分2秒)、または時間帯(午前5時34分)で構成されるデータ。
- チェックボックス:複数選択可能な質問からのデータ(例:「これらの色のうちどれが好きですか?)
- ID:一意な値で構成されるデータ、例えば学生ID。分析には使用できない。
- テキスト:テキストフィールドで構成されるデータ。分析には使用できない。
アンケートデータの使用
Stats iQによるQualtricsアンケートで収集されたデータを使用する場合、アンケートの設定方法について考慮すべきことがあります。
回答者データと追加変数
アンケートを実施する前から存在していた一部のデータをStats iQ分析に含める場合があります。この情報は、連絡先リストに埋め込みデータとして保存し、データを収集する前にアンケートフローに追加してください。
クエリ文字列や連絡先リストに埋め込みデータがあり、データを収集する前に追加し忘れた場合は、埋め込みデータ要素をアンケートフローに追加し、新しい回答をインポートします。
Stats iQで変数を作成できますが、これらの変数は他の既存フィールドで作成されます。詳しくは、ロジック変数、バケット変数、数式変数のサポートページをご覧ください。
匿名のしきい値(EX)
組織管理者が組織全体の匿名のしきい値を 有効にしている場合、EXデータセットに対してDescribe、Relate、Regression分析を実行すると、Stats iQは自動的にこれらのしきい値を尊重します。これらの分析に含まれるサンプルは、設定された最小回答数のしきい値以上の回答数を持つデータのみとなる。その結果、他のダッシュボードやウィジェットと比べて、分析結果に表示されるデータが少なくなる可能性があります。
回答しきい値は、データポイントに対する回答に基づく。これは、質問に対する総回答数ではなく、各回答オプションに対する回答数に基づいてデータが非表示になることを意味します。その他の例については、「基本的な匿名性」を参照のこと。
例:
- 回答者にTシャツのサイズはスモール、ミディアム、ラージのいずれかを尋ねます。
- 匿名のしきい値は4です。
- 10人が質問に答える。この質問を表示すると、ダッシュボードウィジェットに表示されます。
- しかし、「小さい」と答えた人は10人中1人に過ぎない。
- たとえ質問の選択肢全体が匿名のしきい値を満たしていたとしても、この選択肢は匿名のしきい値を満たしていないため、”Small “はStats iQから除外される。
Qtip:Stats iQは、組織全体でのコメント表示に必要な最小回答数の設定をサポートしていません。
{kind=link}
Qtip:サンプルサイズが回答のしきい値未満の場合、匿名のしきい値を維持するため、分析はできません。

インポートされたデータプロジェクト
XMプラットフォームでは、インポートされたデータプロジェクトを使用して、他の外部ソースからデータをアップロードし、Stats iQを使用して分析することができます。
詳しくはインポートされたデータプロジェクトのページをご覧ください。
基本対基本高度なStats iQ
ブランドのタイプによって、Stats iQツールは2種類に分かれます。このセクションでは、Basic StatsクライアントとAdvanced Statsクライアントでアクセシビリティが異なる機能について説明します。
| 基本的なStats iQ | 高度なStats iQ | |
|---|---|---|
| ベーシック | 高度 | |
| 説明する | はい | はい |
| 相関分析 | はい | はい |
| 回帰 | はい | はい |
| クラスタ分析 | いいえ | はい |
| ピボット | いいえ | はい |
| Rコードカード | いいえ | はい |
Stats iQに対応するプロジェクトの種類
すべてのライセンスにStats iQが含まれているわけではありません。しかし、Stats iQにアクセシビリティがあれば、以下のタイプのプロジェクトとそのデータに使用することができます:
技術的には、コンジョイントプロジェクトやMaxDiffプロジェクトでStats iQを使用することができますが、これを行うことはお勧めしません。コンジョイントやMaxdiff固有のデータを使用することはできず、デモグラフィックやスクリーニングのような特別なアンケート調査のみを使用することができます。
FAQs
Stats iQの変数を新規に作成する方法を教えてください。
Stats iQの変数を新規に作成する方法を教えてください。
Stats iQで値を「再コード化」するにはどうすればよいですか?
Stats iQで値を「再コード化」するにはどうすればよいですか?
直接再コード化できない変数については、作成 またはクリーン変数 メニューで値を再コード化することができます。Create Variable ウィンドウで、Logic メソッドを使用して、変数の既存の各値に数値を割り当てます。新しい変数を作成するか、左下の「既存の変数を置換」を選択して、新しい数値で変数を更新することができます。
変数作成の Logic 方式については、サポートページ Variable Creation をご覧ください。
Stats iQに対応した問題形式は?
Stats iQに対応した問題形式は?
Stats iQでデータを分析する際のオプションは何ですか?
Stats iQでデータを分析する際のオプションは何ですか?
- Describe:リストから変数を選択し、Describe をクリックすると、その変数に含まれるデータを視覚化することができます。ある変数のデータがどのように分布しているかを確認したい場合に使用します。
- Relate:2つの変数を選択し、Relateをクリックすると、2つの変数間の関係の統計分析が実行されます。2つの変数がどの程度強く相関しているかを知りたいときに使用します。
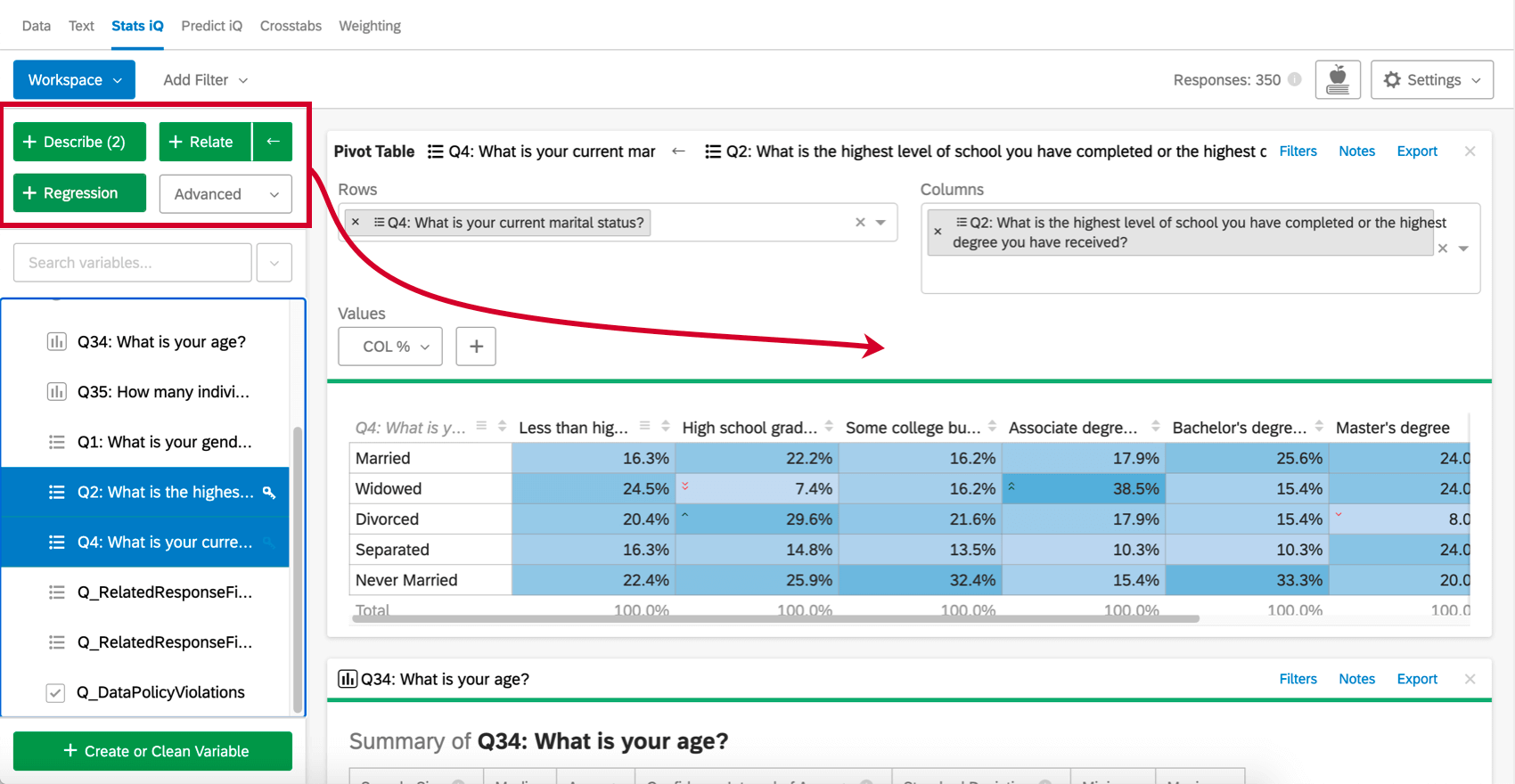
- ピボットテーブル:2 つ以上の変数を選択してピボットテーブルをクリックすると、変数の値を行と列で表示する表が作成されます。セルには、列や行のパーセンテージ、Sum、Varianceなど、さまざまな情報を表示するように設定することができます。変数の特定の値間の重なりを比較したい場合に使用します。
- Regression:2つの変数を選択し、回帰をクリックすると、変数間の数学的関係が表示されます。ある変数の値から別の変数の値を予測したい場合に使用します。
- クラスター:2~10個の人口統計変数を選択し、「クラスタ」をクリックすると、一緒に発生する可能性が最も高い形質のグループ分けが表示され、データに含まれる人口層が明らかにされます。
Stats iQの変数の種類にはどのような意味があるのでしょうか?
Stats iQの変数の種類にはどのような意味があるのでしょうか?
この統計用語の意味がわからない。教えてもらえますか?
この統計用語の意味がわからない。教えてもらえますか?
- 統計テスト:ANOVA、T-test、カイ二乗はすべてStats iQが2つの変数間の関係が有意であるかどうかを検定するために行う統計検定です。これらの検定はP-Valueを生成するために使用されます。
- P-Value:この値は、変数間に相関が存在しない場合に、観測された結果が見られる確率を表しています。P-Valueが低いほど、相関のあるデータであることを意味する。
- 効果量:効果量とは、2つの変数間の相関がどの程度大きいかを示す指標である。これは、実施した統計検定の種類によって異なる方法で測定されます。例えば、Cohenのd、Pearsonのr、Cramerのvなどがあり、効果量の数値が大きいほど、変数の相関が高いことを意味する。
Stats iQに表示されるデータをフィルタリングする方法を教えてください。
Stats iQに表示されるデータをフィルタリングする方法を教えてください。
Stats iQに新しい回答を表示させるにはどうしたらよいですか?
Stats iQに新しい回答を表示させるにはどうしたらよいですか?
アカウントにStats iQが表示されないのですが。Stats iQにアクセスするにはどうしたらいいですか?
アカウントにStats iQが表示されないのですが。Stats iQにアクセスするにはどうしたらいいですか?
Stats iQ Workspaceでは、分析カードはどのように並べられるのですか?
Stats iQ Workspaceでは、分析カードはどのように並べられるのですか?
Stats iQって何?/ スタットウィングはどこ?
Stats iQって何?/ スタットウィングはどこ?
このページに記載されているタブがないのですが!?どうしたらいいんだろう?
このページに記載されているタブがないのですが!?どうしたらいいんだろう?
データがありません」と表示された場合はどうすればよいですか?
データがありません」と表示された場合はどうすればよいですか?
Qualtricsの新機能をいち早く知るにはどうすればよいですか?
Qualtricsの新機能をいち早く知るにはどうすればよいですか?
これらのリリースノートにアクセスするには、XMコミュニティーのアカウントが必要です。これらのアカウントは、Qualtricsのアカウントをお持ちのユーザーであれば、無料でご利用いただけます。このサポートページ には、XM コミュニティーのアカウント登録方法について記載されています。
XM コミュニティにログイン後、 Weekly Product Updates Introduction Post にアクセスしてください。この記事には、製品アップデートの購読を始めるために必要な情報がすべて含まれています。
What is the largest size dataset I can analyze?
What is the largest size dataset I can analyze?
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!