データと分析の概要
このページの内容
データと分析について
データと分析] タブでは、回答データのフィルター、分類、マージ、クリーニング、統計分析を行うことができます:

- データ
- テキスト
- Stats iQ
- Predict iQ
- クロス集計
- 重み設定
- オーディオ&ビデオ
このサポートページでは、特にアンケート調査プロジェクトにおいて、データと分析に含まれるコア機能をご紹介します。
ヒント: これらのタブの一部(Predict iQやStats iQなど)は、アドオン機能となっています。これらの製品の有料版を購入する場合は、クアルトリクスの 営業担当 にお問い合わせください。
[データ]セクション
フィルタリング、分類、マージ、インポート、データクリーニングのほとんどは、データセクションで行われます。例:
![データと分析タブの画像。左上の[フィルタを追加]ボタンが強調表示され、右上の回答数が強調表示されます](https://www.qualtrics.com/m/assets/support/wp-content/uploads//2015/04/data-analysis-overview-1.png)
ヒント: 詳細については「 回答のフィルタリング 」ページを参照してください。
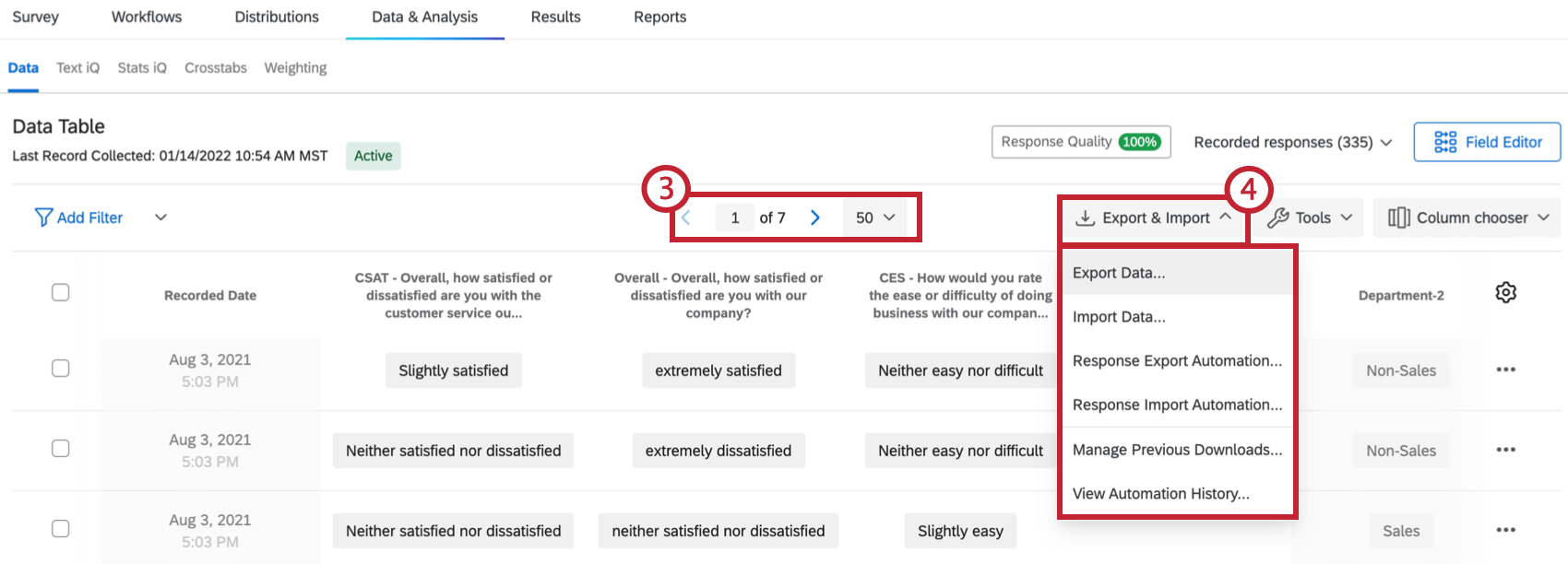
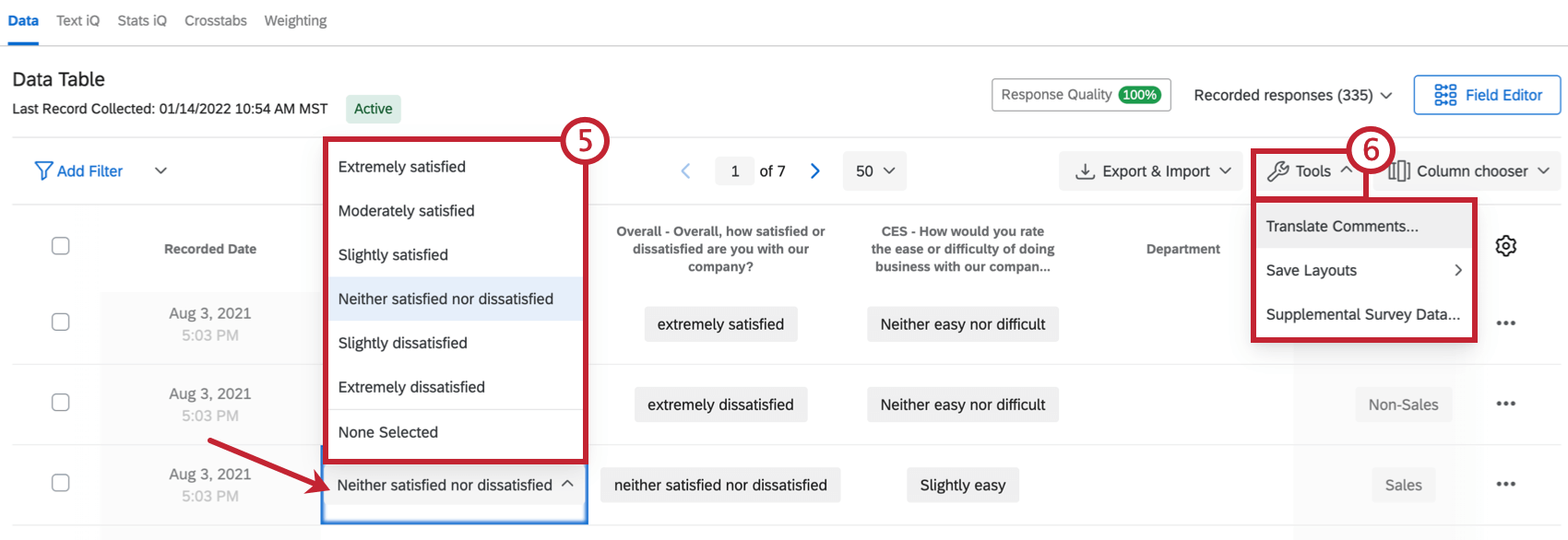
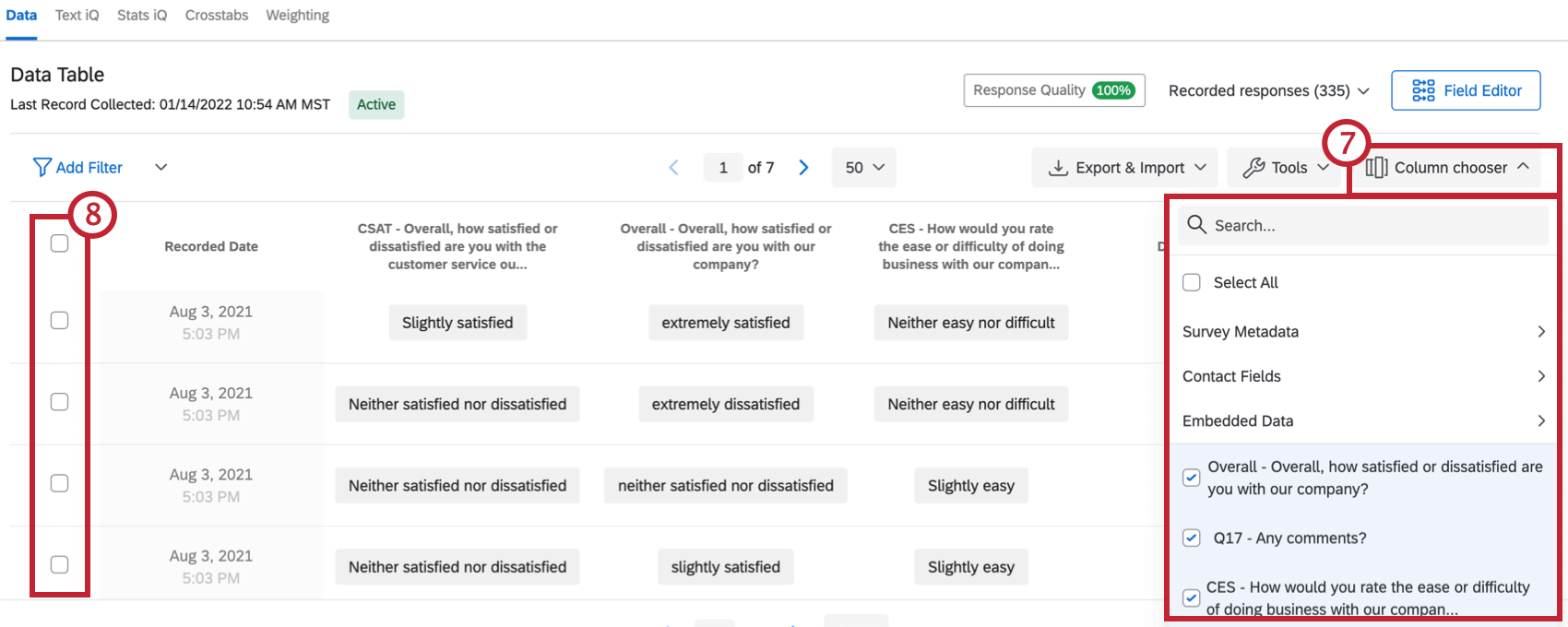
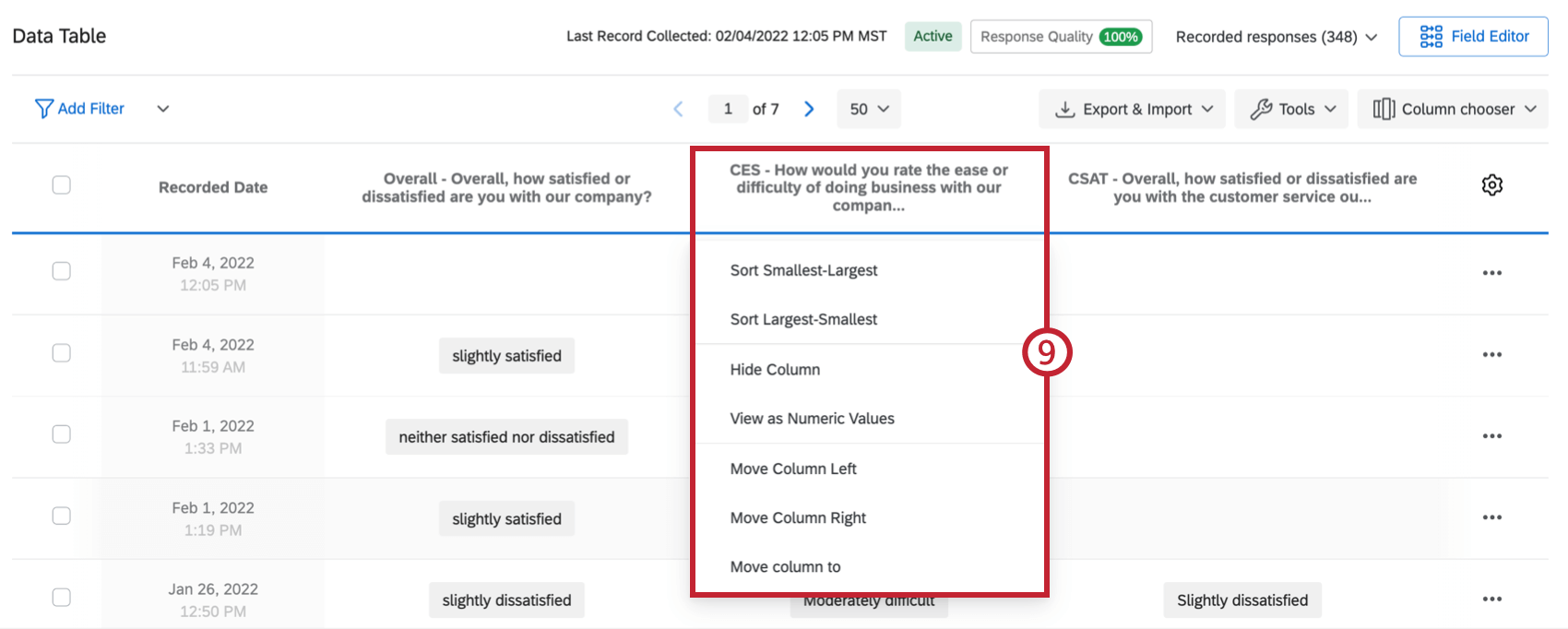
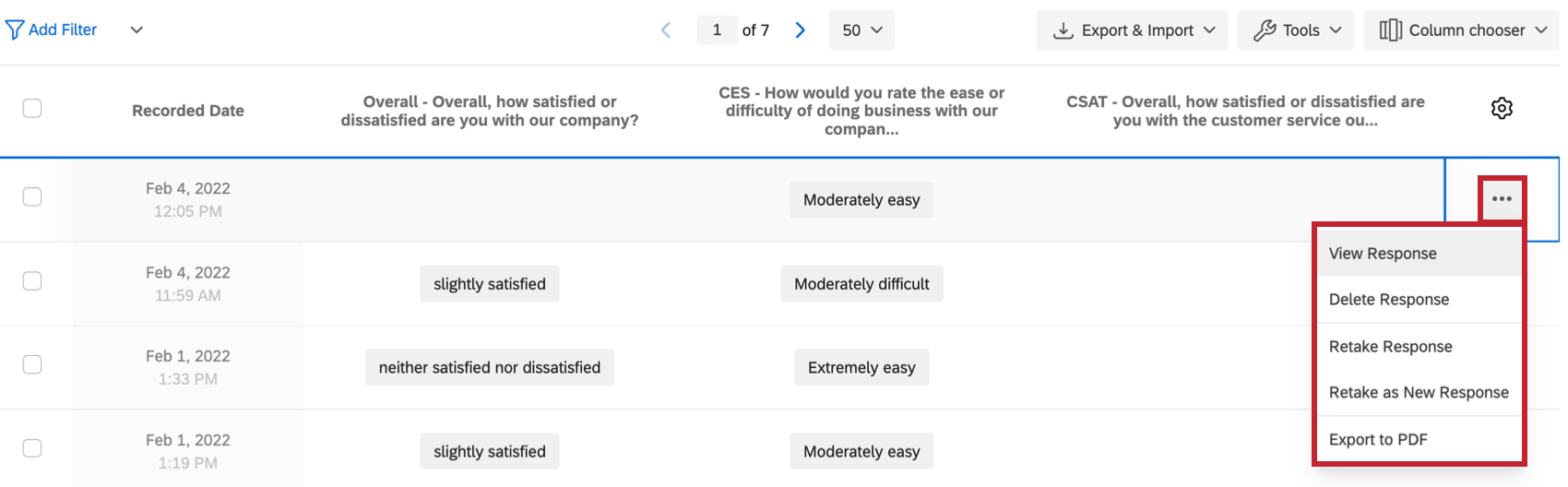
ヒント: 詳細については「 アンケートリンクのやり直し 」ページを参照してください。
[テキスト]セクション(Text iQ)

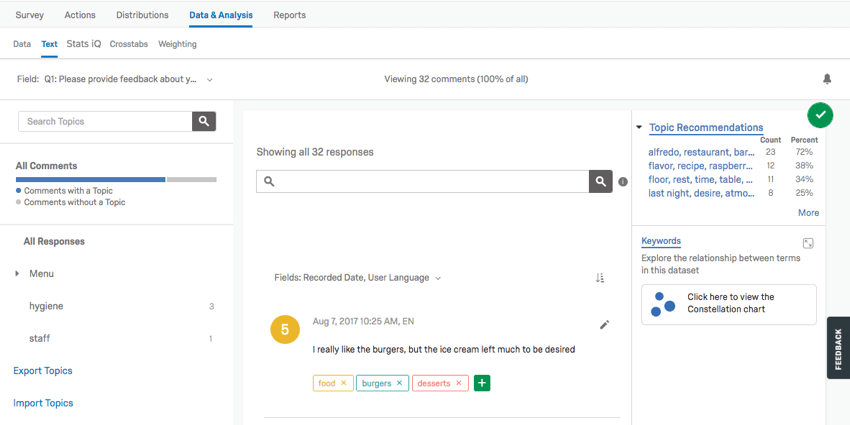
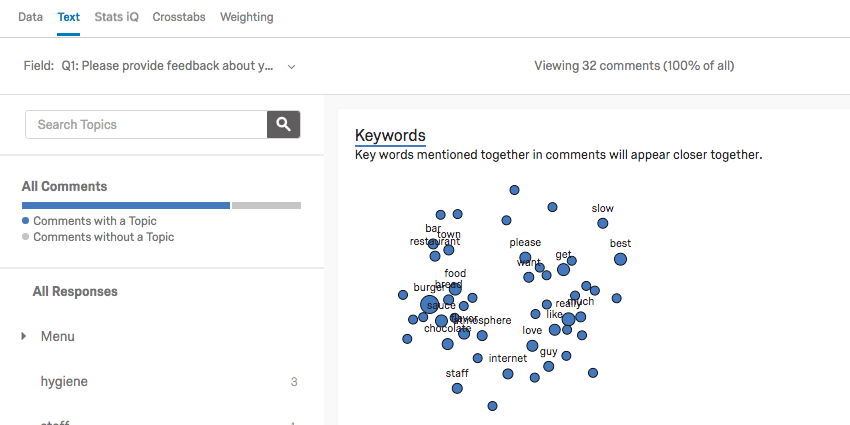
TextセクションにはText iqツールがあります。Text iQを使用して、自由回答欄による回答と解析用トピックをタグ付けします。上記の図を参照してください。
- [トピック]ペインに複数のトピックがタグ付けされています(「食品」、「バーガー」、「アイスクリーム」など)。
- 回答には複数のトピックを割り当てることができます。
- 見出し語認定では、異なる言葉を同一単語として識別します(「バーガー」や「ハンバーガー」など)。
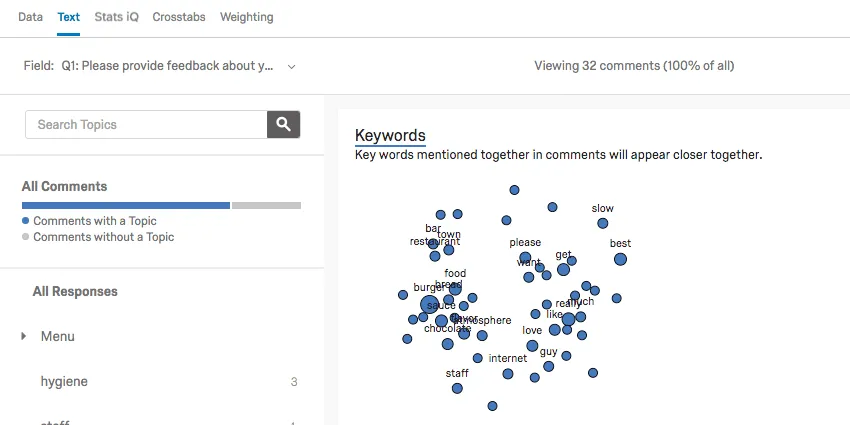
Text iQは、テキスト分析によるインサイトを読み解くさまざまなウィジェットを生成します。たとえば、このコンステレーションチャートでは、回答の中で特定の用語が出現した頻度と用語同士の関係性が見て取れます。用語の出現頻度が高くなるにつれて、星座のドットは大きくなります。
自由回答欄による解答を詳しく見るために、新しいトピックを必要なだけ作成します。さらに、Text iQの検索ではトピックを絞り込んで見つけることができます。レンマタイゼーションとスペルチェックは、トピック・タグ付けのスピードアップにもつながる:
- 見出し語認定:活用形ごとに単語を分けて(「car」という単語の場合は「car」、「cars」、「car’s」、「cars’」など)、適切にタグ付けします。
- スペルチェック:「ice creem」や「icecream」など、さまざまなスペルミスのパターンを「ice cream」としてタグ付けします。
ヒント: Text iQを最大限に活用する方法については、「 Text iQ 」ページを参照してください。
[Stats iQ]セクション
Stats iQセクションをクリックすると、クアルトリクスのStats iQが開きます。このツールを使うと詳細な分析、トレンドの特定、予測モデルの作成が可能になります。Stats iQは、初心者からエキスパートまで高く評価されている、高機能な統計ツールです。
注意: Stats iQは、標準のクアルトリクスライセンスに含まれていないアドオン機能です。Stats iQセクションをお持ちでない場合は、クアルトリクス営業担当までご連絡ください。
StatsiQセクションを選択して、Stats iQにアクセスします。この画面では次の操作を実行できます。
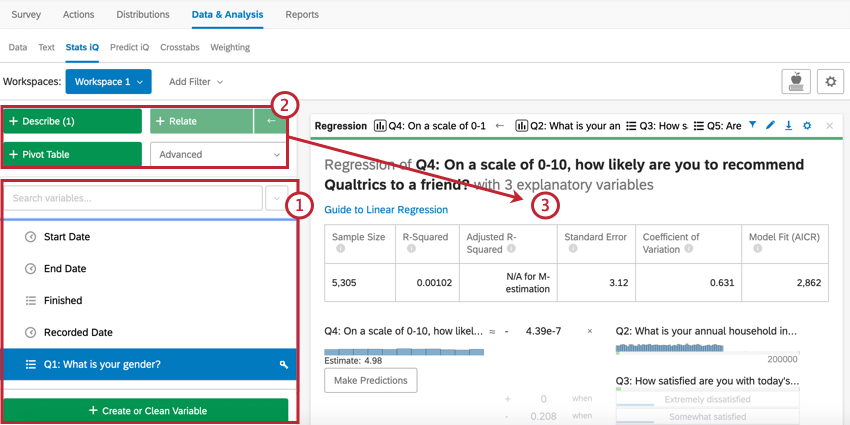
{kind=link}
{kind=link}
Stats iQは、クアルトリクスで収集したデータだけでなく、インポートされたデータプロジェクトの手順に従ってアップロードした外部データも分析できます。詳細については、「 Stats iQの概要 」ページを参照してください。
[Predict iQ]セクション
ご注意: Predict iqはすべてのユーザーで利用できるわけではありません。この機能に関心がある場合は、Qualtricsの営業担当までご連絡ください。
Predict iQは、回答者のアンケート回答と埋め込みデータを分析し、顧客がいつ離反するかを予測します。Predict iQで顧客離れの予測モデルが設定されると、新たに収集された回答において、回答者の顧客離れが生じる可能性について分析を行い、顧客維持に積極的な対応ができるようになります。
{kind=link}

Predict iQの使用に関する詳細情報については、Predict iQサポートページをご覧ください。
[クロス集計]セクション
クロス集計は、P値、カイ2乗、T検定統計量を計算しながら、多変量解析(つまり、2つ以上の変数を同時に分析する)を実行します。
通常、多肢選択式やマトリックステーブルの問題で使用されますが、埋め込みデータをクロス集計に追加することもできます。
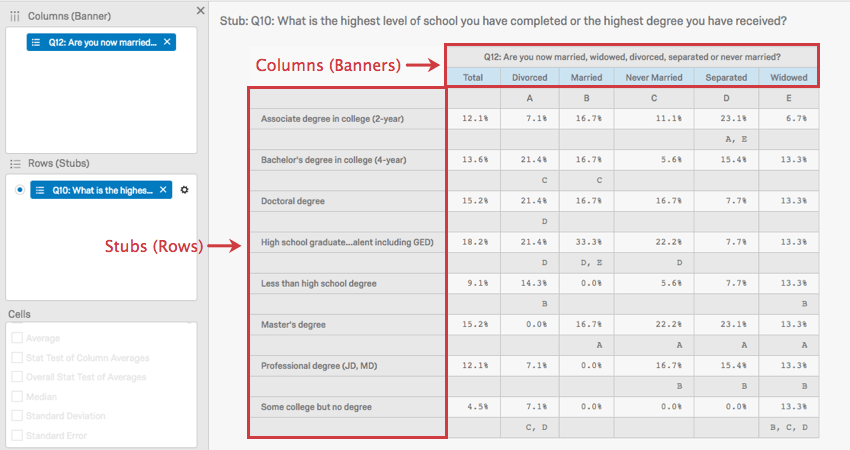
クロスタブの表で、行はスタブと呼ばれ、列はバナーと呼ばれます。
{kind=link}

上の図では、婚姻状況が教育レベルに関連付けられていることがわかります。
この画像の大文字は列間の統計比較を表しています。「離婚」の欄が「学士号」の列に交わるところで、大文字のCがあります。つまり、離婚した回答者は、C列の未婚の回答者よりも学士号をより多く持っていることを示しています。
ヒント: 上の例は、列のパーセンテージ(回答)と列統計テスト(回答)の計算例です。計算の実行方法に関する詳細な手順については、「クロス集計」ページを参照してください。
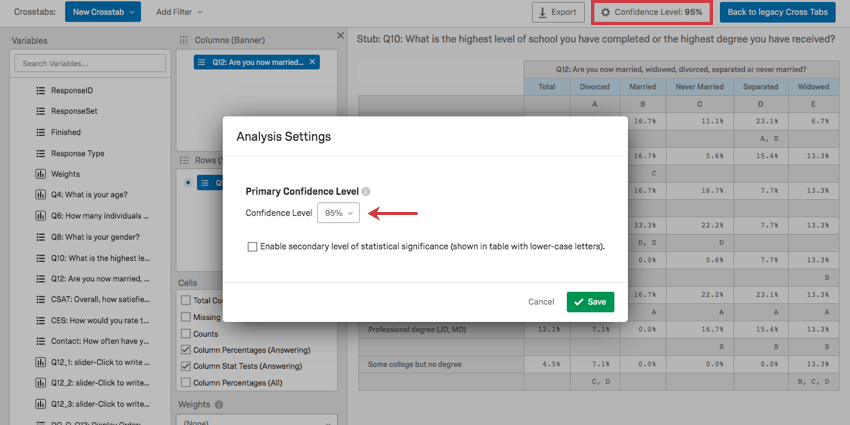
有意性は信頼水準を調整することによって決定される。右上にあるボタンをクリックして、差異が統計的に有意とみなされるしきい値を変更します。
{kind=link}

ヒント: 計算を通知できる追加オプションの手順については「 クロスタブ・オプション 」ページを参照してください。
重み設定セクション
アンケートでは多数の人からサンプルを回収することがあります。[重み設定]セクションでは、少数派層の回答が反映されるようにサンプルを調整することができます。
ヒント: 重みの適用の詳細な手順については「 回答の重み設定 」ページを参照してください。
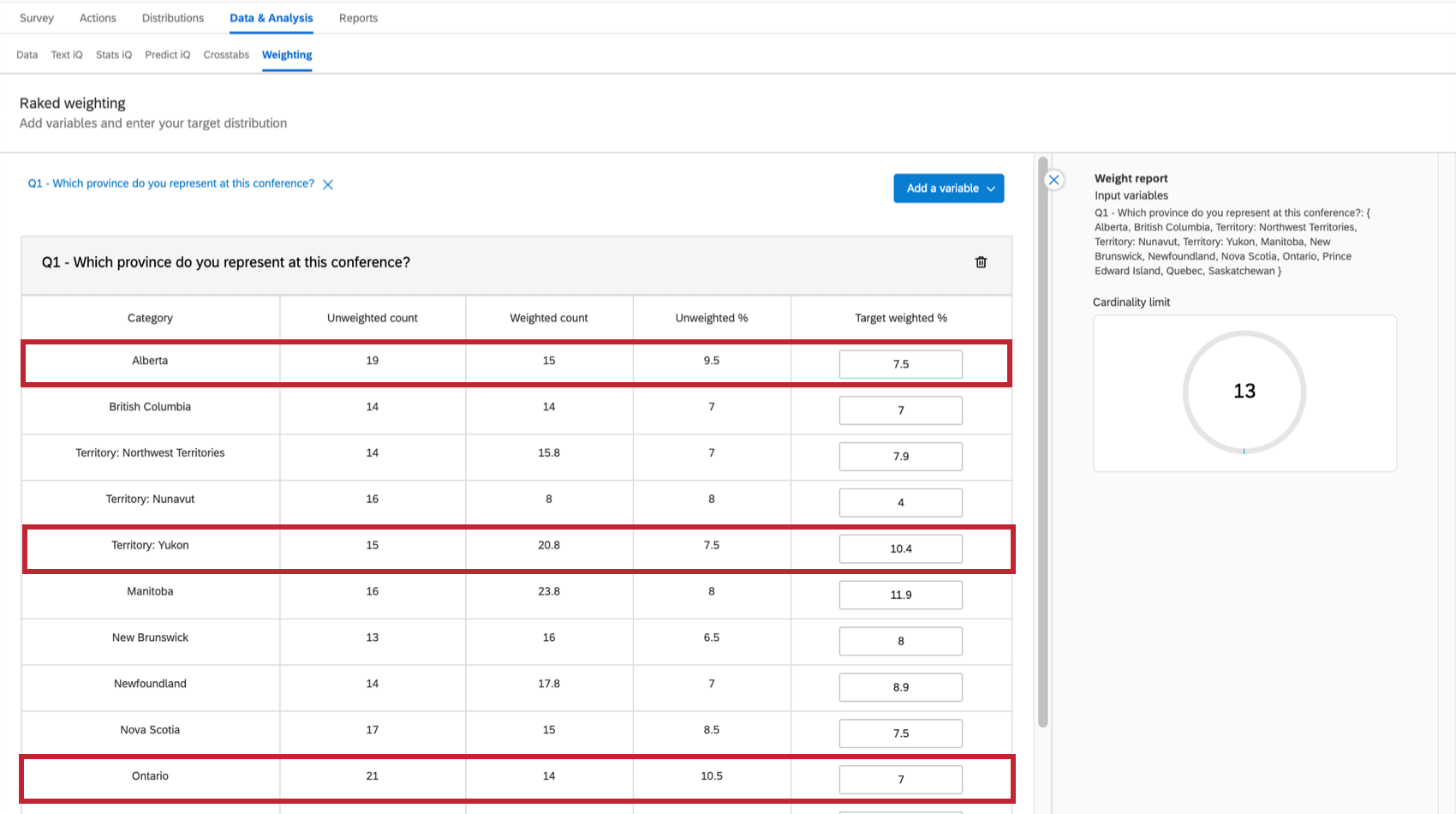
たとえばカナダ中から集まった会議の出席者に対してアンケートを実施しようとしているとします。また、州ごとの参加者数と人口が異なっていても、均等に回答が反映されるようにしたいとも考えています。アンケートの重みを再設定することで、目的の比率を反映することができます。以下の画像では次のような操作を行っています。
- アルバータ州は、アンケート調査対象者の7.5%に過ぎないが、カナダの人口の11.57%を占めている。
- また、オンタリオ州は人口の38.26%を占めているにもかかわらず、アンケート調査回答者の7%しか占めていない。
- ユーコン準州は、アンケート調査参加者の10.4%を占め、カナダ人口の0.10%に過ぎない。
{kind=link}

重みは[目的の比率]列で、パーセントを設定して簡単に変更できます。パーセントの合計は100%になるようにします。
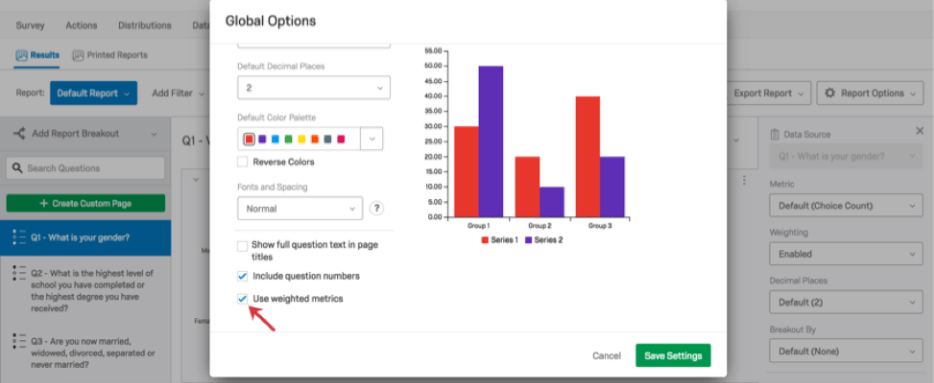
回答の重み設定は、結果レポートに適用できます。重み設定は全体(レポート全体)に対して、または単一の表示(グラフや表)で有効にしたり無効にできます。
{kind=link}
![[結果レポートのグローバルオプション] の [重み付け測定基準を使用する] オプション](https://www.qualtrics.com/sites/default/files/styles/standard_xl_retina/public/migrations/dsx/content/DataAnalysis13_4.png.webp?itok=ArynVh1i)
複数の変数への重み設定
複数の変数の重み設定には2つのオプションがあります:
- 重み設定:2つ(またはそれ以上)の変数を独立して計算し、それらを並べて表示します。
- 連動重み設定:2つ以上の人口統計を重ね合わせる。たとえば、「経験年数」という変数を「州」という変数と併合します。
ヒント: 連結重み設定とレイキング重み設定の詳細については、「 回答の重み設定 」ページを参照してください。
重み設定に関する意思決定
以下のように、アンケート結果をゆがめるさまざまな要因があります。
- 無回答:特定のデモグラフィックがアンケートに回答しない。
- パネルのデザイン:パネル(ターゲット回答者リスト)が適切に選択されていない。
- 自己選択:アンケート調査にオプトインした人は、ターゲット層を反映していません。
- サンプルサイズ:有意な回答者が足りない可能性があります。
このような場合に[重み設定]セクションが役に立ちます。ここで、回答配信に基づいて信頼できる結論に到達することを困難にする可能性のある、データの代表性の問題を調査し、解釈することができます。
ヒント: 統計の解釈の詳細については、「統計の理解」ページを参照してください。
オーディオ・ビデオ部門
アンケートにビデオ回答の質問が含まれている場合、データと分析の「音声とビデオ」タブで音声とビデオ回答を表示および編集することができます。ここから、トランスクリプトの表示、音声やビデオの回答からのクリップの作成、ハイライトリールの作成を実行できます。AI が生成したインサイトを活用して、ビデオの回答のテーマを特定することもできます。
詳しくはAudio & Video Editorをご覧ください。
FAQs
回答をフィルタリングするにはどうすればよいですか?
回答をフィルタリングするにはどうすればよいですか?
実際にどのような回答がライセンス取得につながるのでしょうか?
実際にどのような回答がライセンス取得につながるのでしょうか?
レスポンスビューワに表示する列を設定するにはどうしたらよいですか?
レスポンスビューワに表示する列を設定するにはどうしたらよいですか?
参加者がアンケートを再受信することはできますか?
参加者がアンケートを再受信することはできますか?
アンケートの再受信のリンクでは、参加者の元の回答がすべて事前に入力されていることに注意してください。その間に新しい質問が追加された場合、それらの質問は空欄になります。
自分で作成したデータをQualtricsに取り込むことはできますか?
自分で作成したデータをQualtricsに取り込むことはできますか?
クロス集計機能はどこから利用できますか?
クロス集計機能はどこから利用できますか?
回答者が回答を変更したり、回答できなかった質問を記入したりできるように、回答のリテイクリンクを取得するにはどうしたらよいですか?
回答者が回答を変更したり、回答できなかった質問を記入したりできるように、回答のリテイクリンクを取得するにはどうしたらよいですか?
データと分析」タブに表示される情報が2、3列しかないのですが。異なる列のデータを選択することはできますか?
データと分析」タブに表示される情報が2、3列しかないのですが。異なる列のデータを選択することはできますか?
このページに記載されているタブがないのですが!?どうしたらいいんだろう?
このページに記載されているタブがないのですが!?どうしたらいいんだろう?
連絡先欄が "******"に置き換わっているのはなぜですか?
連絡先欄が "******"に置き換わっているのはなぜですか?
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!