Filtrado por datos estructurados (Diseñador)
Contenidos de la página
Acerca del filtrado por datos estructurados
Utilice atributos de datos estructurados para filtro los opinión en modelos que categorizan y muestran la información más relevante de su conjunto de datos. Para obtener información sobre cómo crear y editar filtros, consulte Filtrado de datos (Diseñador).
Consejo Q: La mayoría de los filtros estructurados se crean mediante el uso de atributos. Para obtener más información sobre la creación y edición de atributos en XM Discover, consulte Atributos.
Filtrado por Sentimiento
XM Discover utiliza el análisis de sentimiento para determinar el sentimiento general de los opinión. El Sentimiento está disponible como un atributo del sistema con bandas predefinidas:
- Sentimiento negativo: Opinión con una puntuación de sentimiento de -5,0 a -1,0
- Sentimiento neutral: Opinión con una puntuación de sentimiento de -0,99 a 0,99
- Sentimiento positivo: Opinión con una puntuación de sentimiento de 1 a 5,0
Consejo Q: Puede crear rangos de sentimiento personalizados utilizando el atributo del sistema de sentimiento . Por ejemplo, Índice de sentimiento de grado:[2,51 a 5].
Filtrar por idioma
Utilice los siguientes atributos del sistema de discover para filtro por tipo de datos:
- Idioma detectado automáticamente por CB ( _languagedetected ): Los opinión sobre el idioma se enviaron si su proyecto utiliza detección automática de idioma.
- Lenguaje procesado CB ( _language ): Los opinión sobre el idioma se enviaron en. Si el idioma no es compatible con XM Discover, se marcará como “OTRO”.
XM Discover es capaz de reconocer y etiquetar datos con más de 150 idiomas utilizando la función de Detección automática de idioma. Sin detección automática de idioma, están disponibles los siguientes idiomas:
- Árabe
- Bengalí
- Chino (simplificado y tradicional)
- Holandés
- Inglés
- Francés
- Alemán
- Hindi
- Indonesio
- Italiano
- Japonés
- Coreano
- Polaco
- Portugués
- Rumano
- Ruso
- Español
- Sueco
- Tagalo
- Tailandés
- Turco
- Vietnamita
Atención: Los textos literales con menos de 10 caracteres se etiquetan como inglés.
Filtrado por tipo de datos
Para filtro los opinión según el tipo de datos enviados, utilice los siguientes atributos del sistema:
- Identificación de la fuente ( _id_source ): La fuente de datos de las oraciones.
- Tipo Verbatim ( _verbatimtype ): El nombre del campo textual por el que desea filtro . Esto es útil si tiene varias columnas textuales.
Ejemplo: Digamos que tiene dos columnas textuales: Revisión y Respuesta. Crear una regla para _verbatimtype:revisiónpara devolver un modelo que solo muestre datos de la columna Revisar textualmente.
Filtrado por tipo de contenido
Para los proyectos con detección de tipo de contenido habilitada, use los siguientes atributos del sistema para filtro opinión de anuncios, spam y otros datos no procesables:
- Tipo de contenido CB ( cb_content_type ): Si los documentos están marcados como con contenido, es decir, que contienen contenido, o sin contenido.
- Subtipo de contenido CB ( cb_content_subtype ): Agrupa los documentos marcados como sin contenido en anuncios, cupones, enlaces a artículos o “indefinidos”.
Ejemplo: Si desea crear un modelo que solo categorice datos con contenido, cree una regla utilizando el atributo de sistema Tipo de contenido de CB: tipo_contenido_cb:contenido.
Filtrar por tipo de oración
XM Discover utiliza análisis semántico para identificar intenciones que sean relevantes para sus análisis. Estas categorías se utilizan en el atributo del sistema a nivel de oración: Tipo de oración CB ( tipo_de_oración_cb ). Analizar el tipo de intención utilizada en sus datos puede ayudar a comprender cómo se puede mejorar la experiencia del cliente .
Haga clic en los siguientes tipos de oraciones para ver qué se identifica utilizando el atributo de tipo de oración:
Consejo Q: Las oraciones que no coinciden con ninguno de los tipos de oraciones se etiquetan como INDEFINIDAS.
Filtrar por recuento de palabras
Utilice los atributos de recuento de palabras de la oración o del documento para filtro sus datos por la cantidad de palabras en su oración o registro. El rango establecido en estos atributos incluye valores. Si el recuento de palabras es cero, la oración/registro no tiene texto o se cargó antes de que se habilitara la función .
- Recuento de palabras de oraciones CB ( cb_sentence_word_count ): El atributo a nivel de oración le permite filtro datos por la cantidad de palabras en una oración. Consejo Q: Para ver oraciones con 10 palabras o menos, use el rango recuento_de_palabras_de_la_sentencia_cb: [1 A 10].

- Recuento de palabras del documento CB ( cb_document_word_count ): El atributo a nivel de registro le permite filtro datos por la cantidad de palabras en un registro. Esta es también la suma del número de palabras de todas las oraciones. Consejo Q: Para ver registros con 50 palabras o más, utilice recuento de palabras del documento cb: [50 a 200].
Filtrado por cuartil de oración
El Cuartil de oraciones CB ( cb_sentence_quartile ) El atributo identifica la parte del texto literal a la que sigue una oración. Los valores son de 1 a 4, y cada sección representa el 25% de la longitud del texto literal. Si un registro tiene múltiples verbatims, habrá cuartiles para cada verbatim en el registro.
Consejo Q: Este atributo puede ser útil si desea centrarse en el motivo por el cual los clientes llaman, lo cual generalmente se analiza en el primer cuartil (1) del texto textual. Alternativamente, si está interesado en saber cómo los representantes finalizan sus llamadas, puede limitar sus informes al último cuartil (4).
Aplicación del cuartil de oraciones
Si a sus datos históricos les faltan datos de cuartiles de oraciones, puede agregarlos a sus datos.
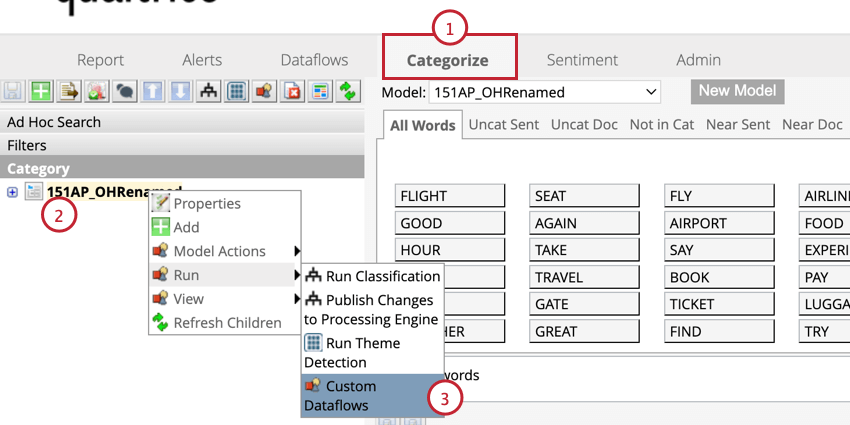
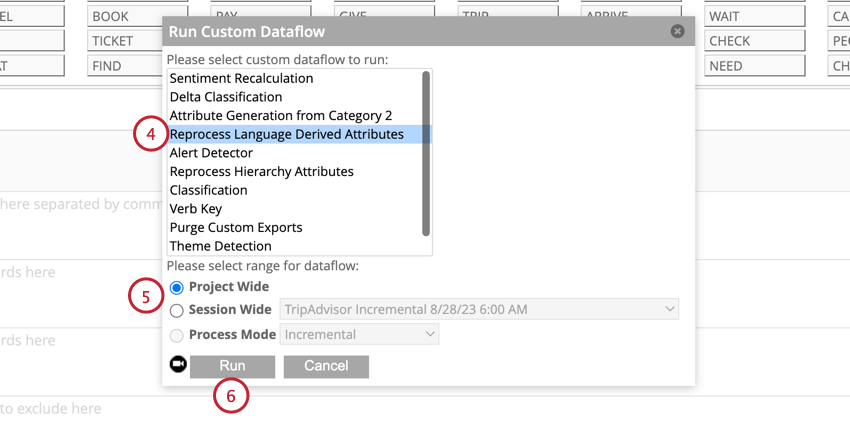
Filtrado por esfuerzo
Esfuerzo del CB mide el nivel de esfuerzo expresado por los clientes durante su experiencia. Este atributo está disponible a nivel de oración en una escala de -5 a 5, donde -5 indica la experiencia más difícil y 5 indica la experiencia más fácil. El rango incluye valores.
Consejo Q: Para visualizar frases donde el nivel de esfuerzo expresado es muy alto, puedes utilizar el rango: cb_sentence_ease_score:[-5 to -3].
Consejo Q: CB Effort solo es compatible con números enteros.
Filtrar por duración de la lealtad
Duración de la lealtad del CB Le permite filtro datos según el período en años que un cliente ha utilizado un servicio o ha tenido un producto. Este atributo está disponible a nivel de oración en oraciones con el tipo de oración de tenencia. El rango incluye valores.
Ejemplo: La frase “He sido cliente durante 10 años” devolverá un valor de Período de lealtad de 10. Para ver sentencias con una duración de hasta 10 años, utilice el siguiente rango: cb_loyalty_tenure:[1 TO 10].
Filtrado por tipo de interacción
Tipo de interacción CB ( tipo_interacción_cb ) define los datos según el tipo de interacción XM , lo que permite distinguir la opinión regular de los datos conversacionales. Este atributo está disponible a nivel de documento, texto textual y oración.
El tipo de interacción puede tener los siguientes valores:
- Charlar:Datos conversacionales de canales digitales.
- Opinión:Datos de opinión regulares (como menciones en línea, reseñas, etc.).
- Encuesta:Datos de respuesta de una encuesta.
- Voz:Datos conversacionales de conversaciones transcritas en audio.
¡Genial! ¡Gracias por tus comentarios!
¡Gracias por tus comentarios!